ML-Agents(五)GridWorld
- 2020 年 4 月 5 日
- 筆記
ML-Agents(五)GridWorld
GridWorld這個例子比較有意思,它還是運用了Reinforcement Learning來進行學習的,不同的是它運用了視覺觀察值(Visual Observations)來訓練agent。
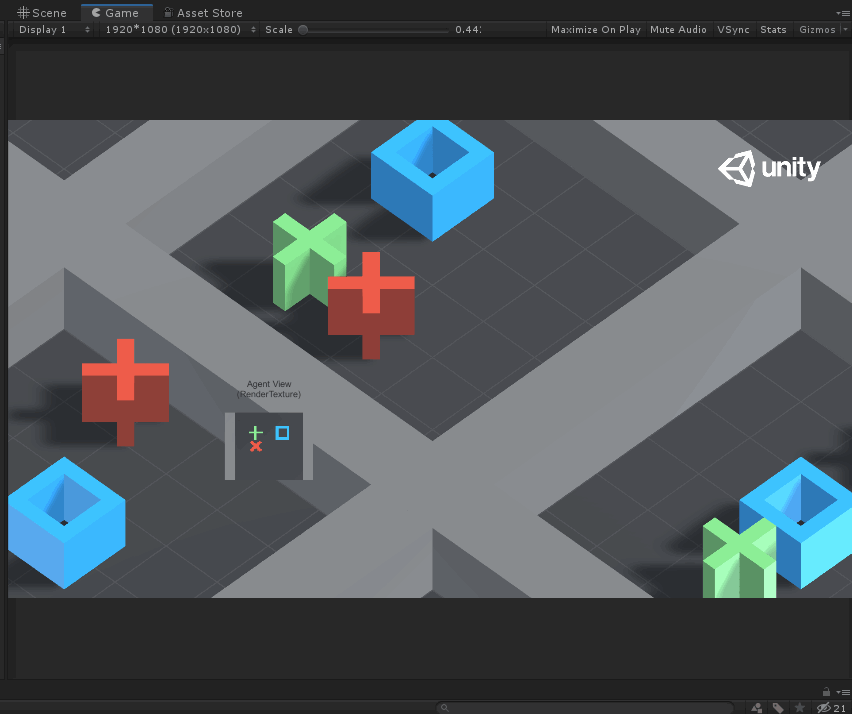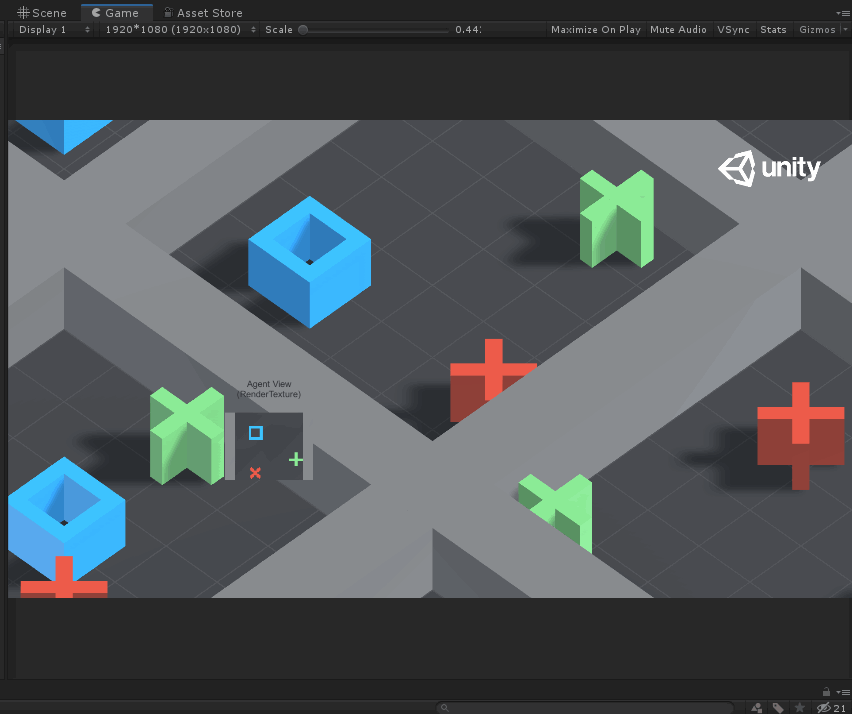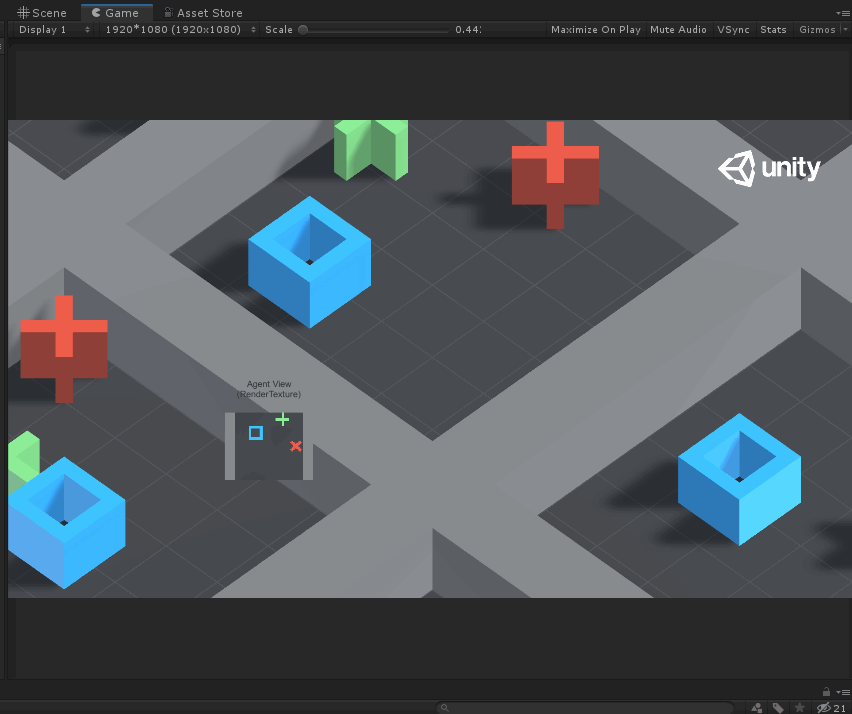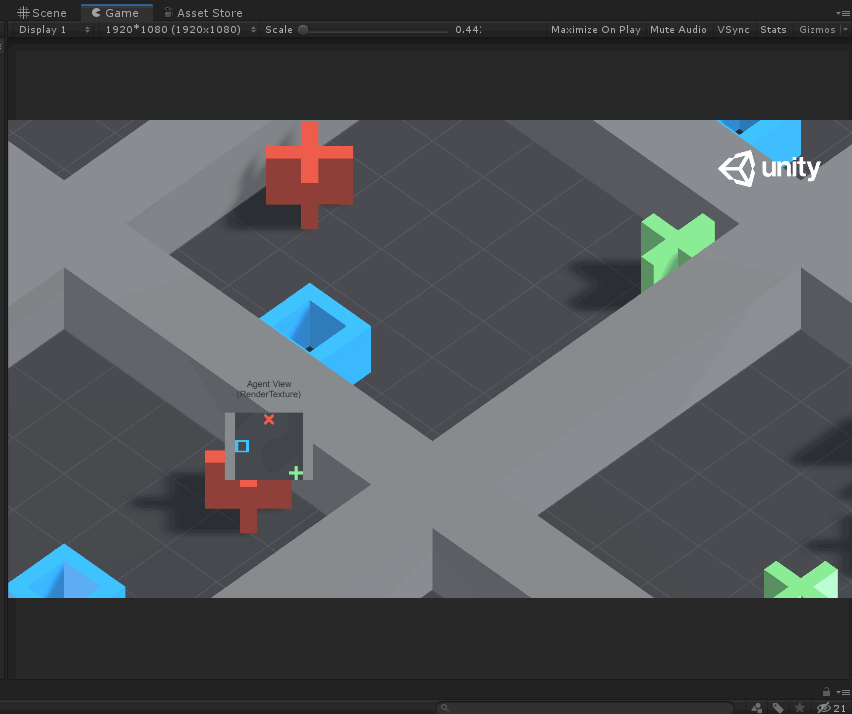
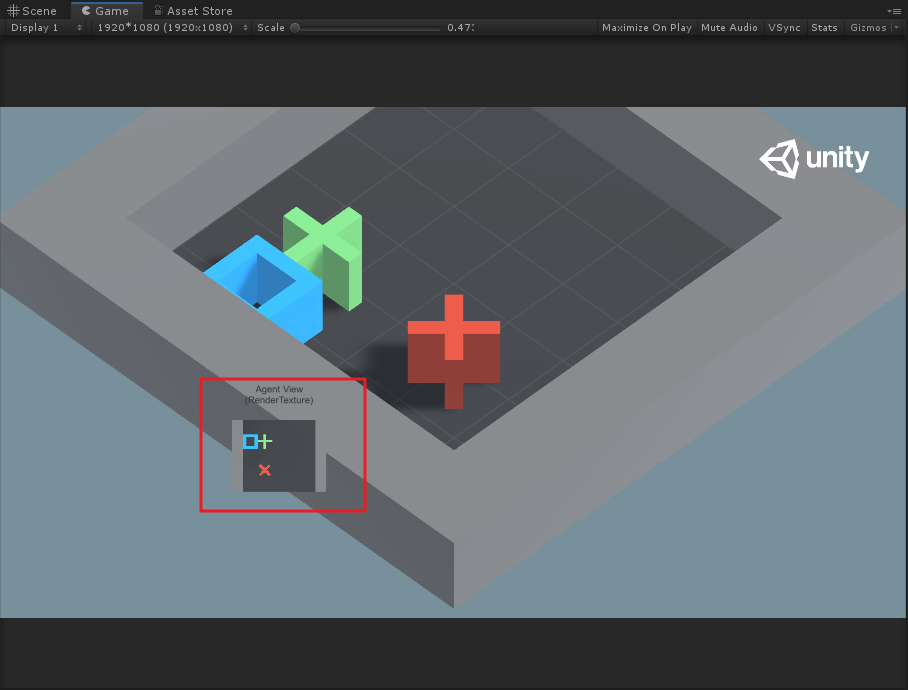
如上圖所示,Agent就是藍色的方塊,每次它可以移動一格(上、下、左、右),要求不能碰到紅叉,最終到達綠色加號目標。
Visual Observations
先來了解一下視覺觀察值是怎麼回事。在ml-agents里主要通過CameraSensor或RenderTextureSensor兩種方式來向Agent提供視覺觀察。通過這兩個組件收集的圖像信息輸入到agent policy的CNN(卷積神經網絡)中,這使得agent可以從觀察圖像的圖像規律中學習。Agent可以同時使用視覺觀察值( Visual Observations)和矢量觀察值( Vector Observations)。
使用視覺觀察可以使得Agent可以捕獲任意複雜的狀態,並且在難以用數字描述的狀態時非常有用。當然,視覺觀察訓練相比矢量觀察訓練,效率低、速度慢,而且有時完全不能成功。因此,只有當使用vector observations或者ray-cast observations(之後會研究到,是射線觀察)不能解決問題時,才使用visual observations。
視覺觀察結果可以從場景中的Cameras或者RenderTextures獲得。為了給agent添加視覺觀察組件,需要在agent上添加Camera Sensor Component或者Render Texture Sensor Component組件,然後將Camera或者RenderTexture拖入相應的地方(如下圖)。同時給一個Agent可以加一個以上的camera或者render texture組件,甚至可以兩種組件進行組合。對於每個視覺觀察組件,需要設置圖像的寬度和高度(以像素為單位),以及觀察值是彩色還是灰色。
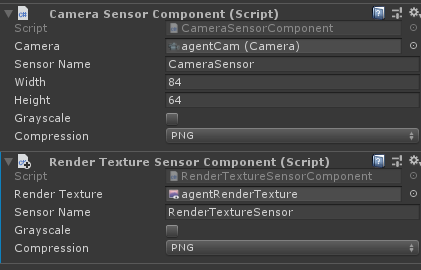
使用相同策略的Agent必須有相同數量的visual observations,並且這些視覺組件需要有相同的分辨率(包括灰度設置)。另外,在Agent的Sensor Component必須有自己單獨的Sensor Name以便可以確定地對其排序(名稱對於該Agent必須是唯一的,但是多個Agent可以具有同名的Sensor組件)。
當使用Render Texture Sensor Component組件時,可以利用Canvas來調試,需要將在Canvas下建立帶有Raw Image組件的物體,然後將Agent的RenderTexture設置到Raw Image的Texture中,例如下圖。
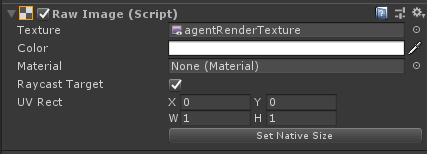
Grid World示例則是展示了怎樣去使用RenderTexture組件去調試和觀察。注意,在此示例中,將Camera渲染為RenderTexture,然後將其用於觀察和調試。為了更新RenderTexture,Camera必須在代碼中要求每次做出決定時,都需要進行畫面渲染。當直接使用Camera作為觀察值時,Agent會自動完成此操作。
- Visual Observation總結&最佳實踐
- 為了收集視覺觀察值,需要給GameObject添加
CameraSensor組件或RenderTextureSensor組件 - 除非vector observations不充分,否則通常應使用visual observation
- Image的大小應該儘可能小,不丟失決策所需的細節
- 對於不需要顏色信息來做出決策的情況下,Image應該使用
Greyscale(灰度圖)
- 為了收集視覺觀察值,需要給GameObject添加
Masking Discrete Actions
除了Visual Observation,在這個示例中還使用了action mask。下面也先來介紹一下這個概念。
當我們使用離散動作反饋(Discrete Actions)時,可以指定某些動作對於下一決策是不可能發生的。即當Agent被神經網絡控制時,agent將無法執行指定的操作。注意,當agent被人為控制時(Heuristic Type),agent仍然能夠決定執行被屏蔽的操作。為了屏蔽某些動作,需要在Agent腳本中重寫Agent.CollectDiscreteActionMasks()虛函數,同時需要在函數中調用DiscreteActionMasker.SetMask(),如下圖
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker){ actionMasker.SetMask(branch, actionIndices) } 其中:
branch:你想屏蔽操作分支的索引(從0開始)actionIndices:對應於agent無法執行操作的索引相對應的int列表
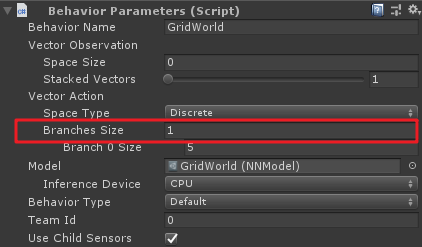
上面的branch就是Behviour Parameters組件中Vector Action中Branches Sizes屬性。
例如,如果一個Agent有兩個branch,第一個branch(branch 0)有四個動作枚舉:"do nothing", "jump", "shoot" and "change weapon",分別對應索引值0,1,2,3。如果Agent需要在shoot時不可以jump且change weapon,則代碼如下:
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker){ if(agent.action==3) //偽代碼,意思是當agent動作為shoot時 actionMasker.SetMask(0, new int[2]{1,3}); //重點是這句 } Notes:
- 如果你想在多個branch上遮罩,你可以使用
Set Mask多次 - 不可以將一個branch上的所有動作都遮罩
- 不能遮罩
Continuous Type中的連續動作
OK,有以上基礎,下面就來研究一下Grid World示例。
環境與訓練參數
先來根據官方文檔參數翻譯一下項目參數:
-
設定:場景包含代理、目標和障礙
-
目標:agent必須在找到目標的同時,避開障礙
-
Agent:環境中包含九個具有相同行為參數的Agent
-
Agent獎勵設定
- 每一步都-0.01f(為了使得代理以最短路徑找到目標)
- 如果agent找到目標(綠色加號)的位置,則+1,同時重新開始下一次
- 如果agent導航到障礙物(紅色叉)處,則-1,同時重新開始下一次
-
行為參數
- 矢量觀察值(Vector Observations):無
- 矢量動作空間:(離散
Discrete類型)Size為4,對應代理上下左右四個方向運動。此外,在環境中,默認情況下會啟動動作遮罩(action masking,可以在對應組件上進行勾選開啟或關閉)。源工程中提供的訓練模型是在啟動屏蔽的情況下生成的。這裡利用action mask其實就是限制藍色方塊代理不要走出grid的範圍,後面看代碼就知道了。 - 視覺觀察值(Visual Observations):對應GridWorld自頂向下的視圖
-
泛化參數:gridSize,障礙物數量(numObstacles)和目標數量(numGoals)三個。具體關於泛化的解釋請查看之前的文章
-
基準平均獎勵:0.8
場景基本結構
以一個基本的Agent為單位,先看一下在Scene視圖中:
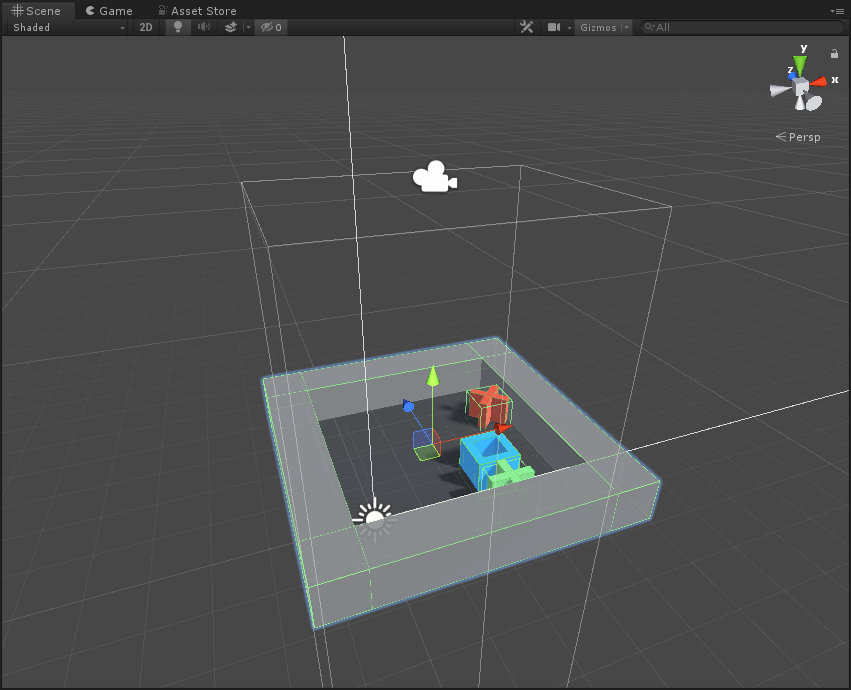
其Hierarchy層級為:
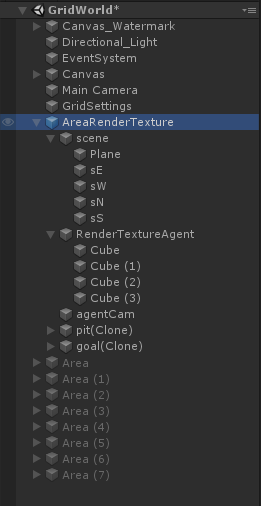
其中scene為組成Grid範圍的父物體,包括一個plane和四個牆體;RenderTextureAgent則是藍色方塊,即為agent;agentCam為渲染相機,通過該相機觀察而渲染得到的Texture就作為CNN的輸入數據;pit和goal分別代表了障礙物和目標,這裡是在運行時才在grid中隨機位置生成。
注意這裡的父節點AreaRenderTexutre上掛有Grid Area腳本,該腳本主要是初始化環境(包括牆體生成,目標、障礙隨機生成等)、重置Agent以及環境的作用。
此外,你會發現這個AreaRenderTexutres單元和其他訓練單元不同,因為該訓練單元的Camera負責渲染輸出了RenderTexture,即在運行時的小畫面。
代碼分析
環境初始化代碼
GridArea.cs
using System.Collections.Generic; using UnityEngine; using System.Linq; using MLAgents; using MLAgents.SideChannels; public class GridArea : MonoBehaviour { [HideInInspector] public List<GameObject> actorObjs;//障礙物和目標物GameObjects List [HideInInspector] public int[] players;//障礙物和目標物數組,其中「1」的個數代表障礙物個數,「0」的個數代表目標個數 public GameObject trueAgent;//代理 public GameObject goalPref;//目標預製體 public GameObject pitPref;//障礙物預製體 IFloatProperties m_ResetParameters;//泛化參數 Camera m_AgentCam;//基本單元的相機,需要設置相機的位置和orthographicSize GameObject[] m_Objects;//存儲目標和障礙的預製體 //地面以及四個牆面 GameObject m_Plane; GameObject m_Sn; GameObject m_Ss; GameObject m_Se; GameObject m_Sw; Vector3 m_InitialPosition;//父預製體初始位置 public void Start() { //參數初始化 m_ResetParameters = Academy.Instance.FloatProperties; m_Objects = new[] { goalPref, pitPref }; m_AgentCam = transform.Find("agentCam").GetComponent<Camera>(); actorObjs = new List<GameObject>(); var sceneTransform = transform.Find("scene"); m_Plane = sceneTransform.Find("Plane").gameObject; m_Sn = sceneTransform.Find("sN").gameObject; m_Ss = sceneTransform.Find("sS").gameObject; m_Sw = sceneTransform.Find("sW").gameObject; m_Se = sceneTransform.Find("sE").gameObject; m_InitialPosition = transform.position; } /// <summary> /// 設置環境 /// </summary> public void SetEnvironment() { //初始化父結點位置,因為場景中有9個訓練單元,根據gridSize來使各個訓練單元分佈開來 transform.position = m_InitialPosition * (m_ResetParameters.GetPropertyWithDefault("gridSize", 5f) + 1); //初始化players數組,其中「1」代表障礙物,「0」代表目標物 var playersList = new List<int>(); for (var i = 0; i < (int)m_ResetParameters.GetPropertyWithDefault("numObstacles", 1f); i++) { playersList.Add(1); } for (var i = 0; i < (int)m_ResetParameters.GetPropertyWithDefault("numGoals", 1f); i++) { playersList.Add(0); } players = playersList.ToArray(); //初始化地面和牆體的位置以及比例,gridSize代表場景中格子數 var gridSize = (int)m_ResetParameters.GetPropertyWithDefault("gridSize", 5f); m_Plane.transform.localScale = new Vector3(gridSize / 10.0f, 1f, gridSize / 10.0f); m_Plane.transform.localPosition = new Vector3((gridSize - 1) / 2f, -0.5f, (gridSize - 1) / 2f); m_Sn.transform.localScale = new Vector3(1, 1, gridSize + 2); m_Ss.transform.localScale = new Vector3(1, 1, gridSize + 2); m_Sn.transform.localPosition = new Vector3((gridSize - 1) / 2f, 0.0f, gridSize); m_Ss.transform.localPosition = new Vector3((gridSize - 1) / 2f, 0.0f, -1); m_Se.transform.localScale = new Vector3(1, 1, gridSize + 2); m_Sw.transform.localScale = new Vector3(1, 1, gridSize + 2); m_Se.transform.localPosition = new Vector3(gridSize, 0.0f, (gridSize - 1) / 2f); m_Sw.transform.localPosition = new Vector3(-1, 0.0f, (gridSize - 1) / 2f); //初始化正交相機 m_AgentCam.orthographicSize = (gridSize) / 2f;//相機正交視野 m_AgentCam.transform.localPosition = new Vector3((gridSize - 1) / 2f, gridSize + 1f, (gridSize - 1) / 2f);//相機位置 } /// <summary> /// 環境重置 /// </summary> public void AreaReset() { var gridSize = (int)m_ResetParameters.GetPropertyWithDefault("gridSize", 5f);//網格數 foreach (var actor in actorObjs) {//銷毀當前所有目標和障礙 DestroyImmediate(actor); } SetEnvironment();//環境重置 actorObjs.Clear(); //利用HashSet,計算出players.Length+1個(所有障礙和目標數量+1個Agent)不重複的隨機值 var numbers = new HashSet<int>(); while (numbers.Count < players.Length + 1) { numbers.Add(Random.Range(0, gridSize * gridSize)); } var numbersA = Enumerable.ToArray(numbers); //採用x=randomNum/gridSize,y=randomNum%gridSize來確定每個物體的位置 for (var i = 0; i < players.Length; i++) {//障礙物與目標物隨機放置 var x = (numbersA[i]) / gridSize; var y = (numbersA[i]) % gridSize; var actorObj = Instantiate(m_Objects[players[i]], transform); actorObj.transform.localPosition = new Vector3(x, -0.25f, y); actorObjs.Add(actorObj); } //Agent位置隨機重置 var xA = (numbersA[players.Length]) / gridSize; var yA = (numbersA[players.Length]) % gridSize; trueAgent.transform.localPosition = new Vector3(xA, -0.25f, yA); } } 環境重置代碼總體來講比較簡單,以上代碼加註釋基本大多都沒問題。
Agent腳本
初始化與重置
在之前3D Ball中,初始化在InitializeAgent()中,重置在AgentReset()中,從某種意義上講,初始化與重置其實是一樣的。在本示例Grid World中,將環境和Agent的初試化重置都放到了GridArea.cs腳本中,除此之外,可以來看一下Agent腳本初始化的變量。
public class GridAgent : Agent { [FormerlySerializedAs("m_Area")]//[FormerlySerializedAs(name)]特性可以防止當「area」變量改名時,導致原序列化對象丟失,具體操作見後文 [Header("Specific to GridWorld")]//[Header(string)]使該變量前有一個說明型標題 public GridArea area;//環境重置腳本 public float timeBetweenDecisionsAtInference;//代理行動速度,每隔timeBetweenDecisionsAtInference秒移動一次 float m_TimeSinceDecision;//決策時間計時器 public Camera renderCamera;//要輸出RenderTexture的相機 public bool maskActions = true;//動作遮罩開關,若禁用,可能會使得有動作遮罩的訓練模型達不到最佳訓練效果 //方塊代理的動作值 const int k_NoAction = 0;//無動作 const int k_Up = 1;//向上移動 const int k_Down = 2;//向下移動 const int k_Left = 3;//向左移動 const int k_Right = 4;//向右移動 public override void InitializeAgent() {//為空 } public override void AgentReset() { area.AreaReset();//代理重置 } } 以上代碼大多數都有注釋,問題不大,下面說裏面兩個Unity中的特性。
-
[FormerlySerializedAs(string name)]
這個特性可以使得腳本中被序列化的屬性或變量在保持引用對象不丟失的情況下重命名。具體使用方式如下,假設有腳本Test.cs:
Test.cs
using UnityEngine; public class Test : MonoBehaviour { public GridArea Area; void Start() { } }將其放到場景中某物體上,並且將任意符合腳本拖到「Area」變量上。
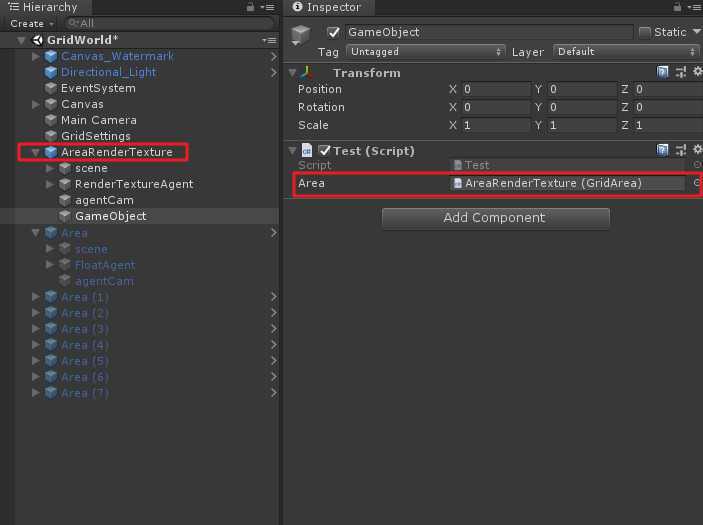
如果此時若改變Area變量名為Area_1,會出現以下現象:
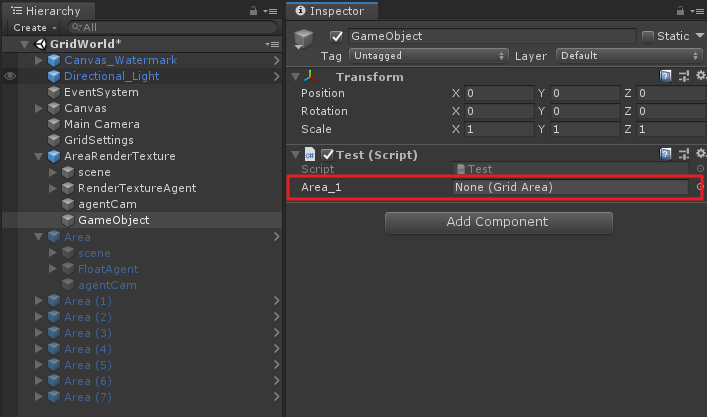
會發現原先的引用變量丟失,為了防止如上情況,則需要使用[FormerlySerializedAs]特性來避免,例如這裡我們繼續將原來的引用賦給Area_1里去。
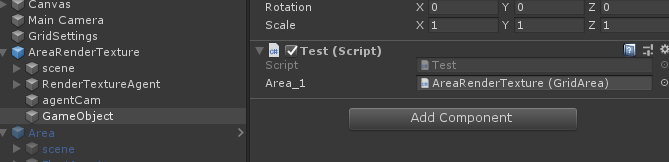
然後在重命名Area_1前,給它加上FormerlySerializedAs特性,如下:
using UnityEngine; using UnityEngine.Serialization; public class Test : MonoBehaviour { [FormerlySerializedAs("Area_1")] public GridArea Area; void Start() { } }再來看原先變量的引用:
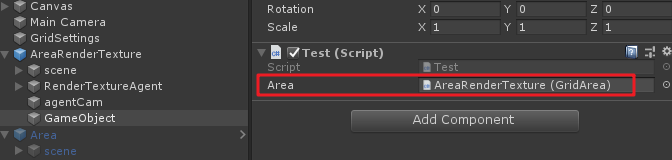
會返現該引用存在,當然若此處的引用還有許多參數變量,也可以使得這些變量序列化不丟失。不過這種拖物體到腳本上的方法其實在開發中一般是不推薦的,如果一個工程較大,許多物體都採用這種方式來引用的話,場景中的物體引用丟失就很難統一管理。
-
[Header(string content)]
直接看效果就行,這個特性比較簡單。

動作遮罩
關於動作遮罩上文中已介紹,來看一下Grid World中對於遮罩的設置。
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker) { if (maskActions)//動作遮罩開關 { //防止agent碰到牆體 var positionX = (int)transform.position.x;//agent的x位置 var positionZ = (int)transform.position.z;//agent的z位置 //agent移動的最大位置 var maxPosition = (int)Academy.Instance.FloatProperties.GetPropertyWithDefault("gridSize", 5f) - 1; if (positionX == 0) {//當agent在最左邊時,不能再向左 actionMasker.SetMask(0, new int[] { k_Left }); } if (positionX == maxPosition) {//當agent在最右邊時,不能再向右 actionMasker.SetMask(0, new int[] { k_Right }); } if (positionZ == 0) {//當agent在最下邊時,不能再向下 actionMasker.SetMask(0, new int[] { k_Down }); } if (positionZ == maxPosition) {//當agent在最上邊時,不能再向上 actionMasker.SetMask(0, new int[] { k_Up }); } } } 配合以下圖:
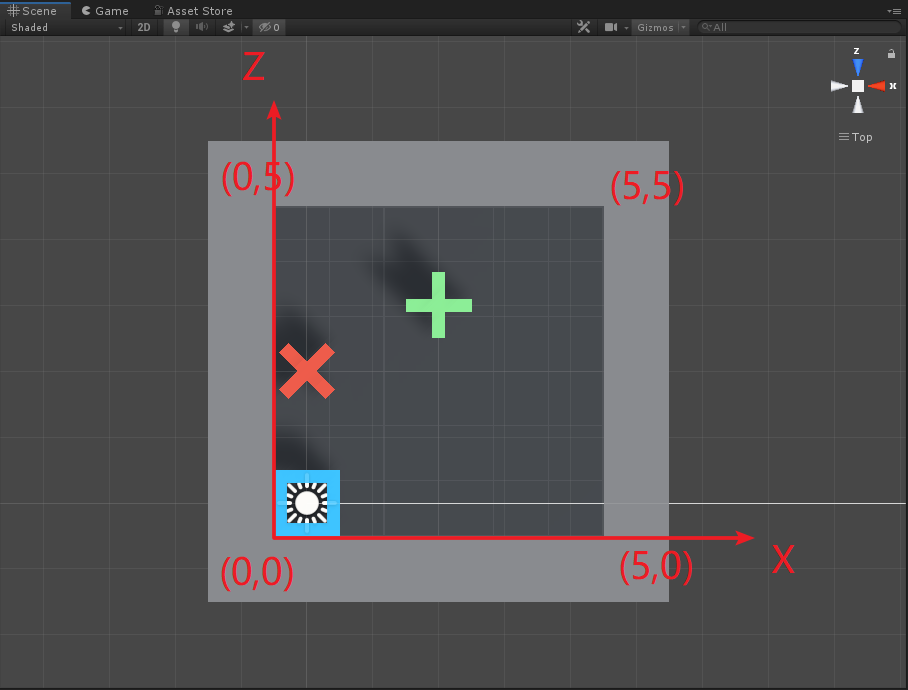
基本上代碼配合圖,動作遮罩就明白了,此外動作遮罩只適用於Discrete Type,即離散空間反饋時才可以使用動作遮罩。
Agent動作反饋
下面看一下agent的動作反饋函數AgentAction()。
public override void AgentAction(float[] vectorAction) { AddReward(-0.01f); //每一步都懲罰0.01,為使得agent可以儘快找到目標 //反饋參數轉換為整數 var action = Mathf.FloorToInt(vectorAction[0]); //根據action參數計算agent將要移動的下一個位置targetPos var targetPos = transform.position; switch (action) { case k_NoAction: // do nothing break; case k_Right: targetPos = transform.position + new Vector3(1f, 0, 0f); break; case k_Left: targetPos = transform.position + new Vector3(-1f, 0, 0f); break; case k_Up: targetPos = transform.position + new Vector3(0f, 0, 1f); break; case k_Down: targetPos = transform.position + new Vector3(0f, 0, -1f); break; default: throw new ArgumentException("Invalid action value"); } //定義Box型射線檢測,在agent將要移動的下一個位置生成一個Box射線檢測 var hit = Physics.OverlapBox( targetPos, new Vector3(0.3f, 0.3f, 0.3f)); if (hit.Where(col => col.gameObject.CompareTag("wall")).ToArray().Length == 0) {//若agent的下一個位置沒有碰到牆體("wall"標籤的物體),則移動agent transform.position = targetPos; if (hit.Where(col => col.gameObject.CompareTag("goal")).ToArray().Length == 1) {//如果移動的下一個位置是目標(goal),則獎勵1,此次訓練完成 SetReward(1f); Done(); } else if (hit.Where(col => col.gameObject.CompareTag("pit")).ToArray().Length == 1) {//如果移動的下一個位置是障礙物(pit),則懲罰1,此次訓練完成 SetReward(-1f); Done(); } } } 以上代碼經過注釋後,也沒有太難理解的地方。注意以下兩點:
-
形參
vectorAction代表了agent的運動矢量空間,grid world的agent每次只有一個離散的動作運動,即Branches Size為1,而這個運動可以包括五個選擇k_NoAction、k_Right、k_Left、k_Up和k_Down,因此Branch 0 Size為5.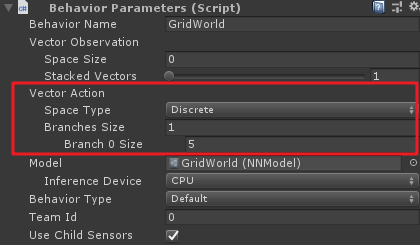
-
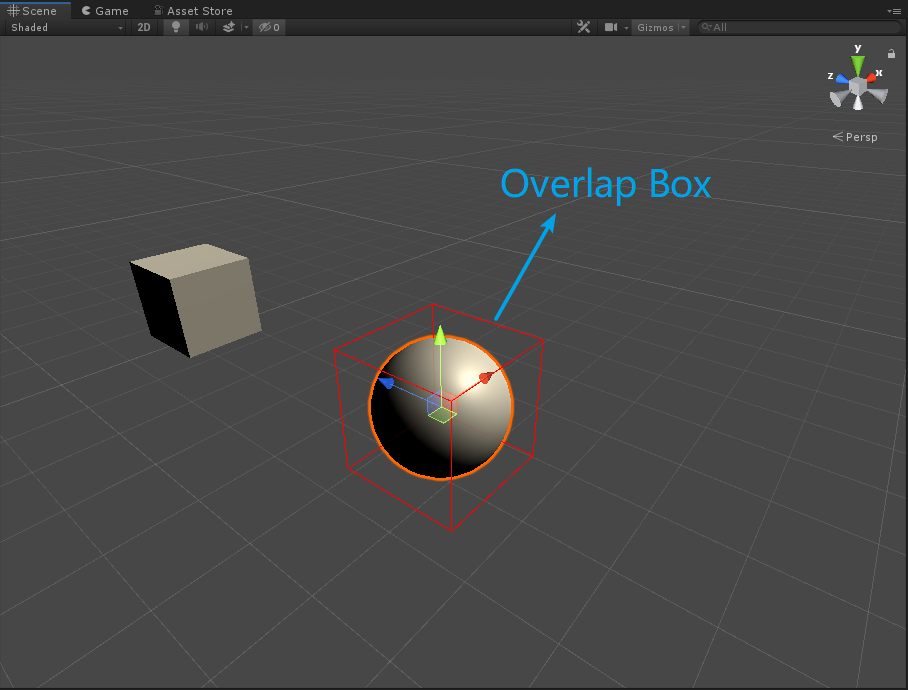
Physics.OverlapBox為Box型射線,如下圖。此外,這裡可以提供一個思路,可以在計算出來的下一個位置先生成一個射線檢測或者碰撞體來檢測下一個位置是否是符合條件的位置。
FixedUpdate()
在Agent腳本中,還注意到運用了FixedUpdate()來影響agent的brain做出決策:
public void FixedUpdate() { WaitTimeInference();//每幀調用 } void WaitTimeInference() { if (renderCamera != null) {//若渲染相機不為空,則每幀手動使相機渲染 renderCamera.Render(); } if (Academy.Instance.IsCommunicatorOn) {//判斷是否環境是否與Python相連,若相連,則每幀使agent的brain做出決策 RequestDecision(); } else {//若未與外界相連,則timeBetweenDecisionsAtInference秒後,使得brain做出決策 if (m_TimeSinceDecision >= timeBetweenDecisionsAtInference) { m_TimeSinceDecision = 0f; RequestDecision(); } else { m_TimeSinceDecision += Time.fixedDeltaTime;//決策計時器 } } } 手動操作代碼
手動操作代碼具體如下:
public override float[] Heuristic() { if (Input.GetKey(KeyCode.D)) { return new float[] { k_Right }; } if (Input.GetKey(KeyCode.W)) { return new float[] { k_Up }; } if (Input.GetKey(KeyCode.A)) { return new float[] { k_Left }; } if (Input.GetKey(KeyCode.S)) { return new float[] { k_Down }; } return new float[] { k_NoAction }; } 這裡代碼比較好理解,但是如果要是調到手動操作模式,會發現在場景中你的操作並不能得到反饋,這是由於Agent上沒有添加Decision Requester組件,添加後,然後將Behavior Type改為Heuristic Only,即可手動操作。雖然操作起來沒那麼舒爽= =。
關於GridSetting
在場景中還能發現在Main Camera上有GridSetting.cs腳本,如下:
using UnityEngine; using MLAgents; public class GridSettings : MonoBehaviour { public Camera MainCamera; public void Awake() { Academy.Instance.FloatProperties.RegisterCallback("gridSize", f => { MainCamera.transform.position = new Vector3(-(f - 1) / 2f, f * 1.25f, -(f - 1) / 2f); MainCamera.orthographicSize = (f + 5f) / 2f; }); //測試 //MainCamera.transform.position = new Vector3(-(10 - 1) / 2f, 10 * 1.25f, -(10 - 1) / 2f); //MainCamera.orthographicSize = (10 + 5f) / 2f; } } 其實這裡用處就是根據gridSize來初始化主相機的位置,不知道為啥源碼中對於這裡的回調調用有問題,於是我直接使的gridSize變為10(這裡同時需要修改GridArea和GridAgent中相關的gridSize數值為10),然後利用上述代碼測試注釋部分來調整相機位置,得出如下效果:
可以發現相機會根據gridSize動態調整合適的位置。
關於其他
工程看到一半,發現該示例中其實兩個類型的Visual Observation Sensor都用到了:
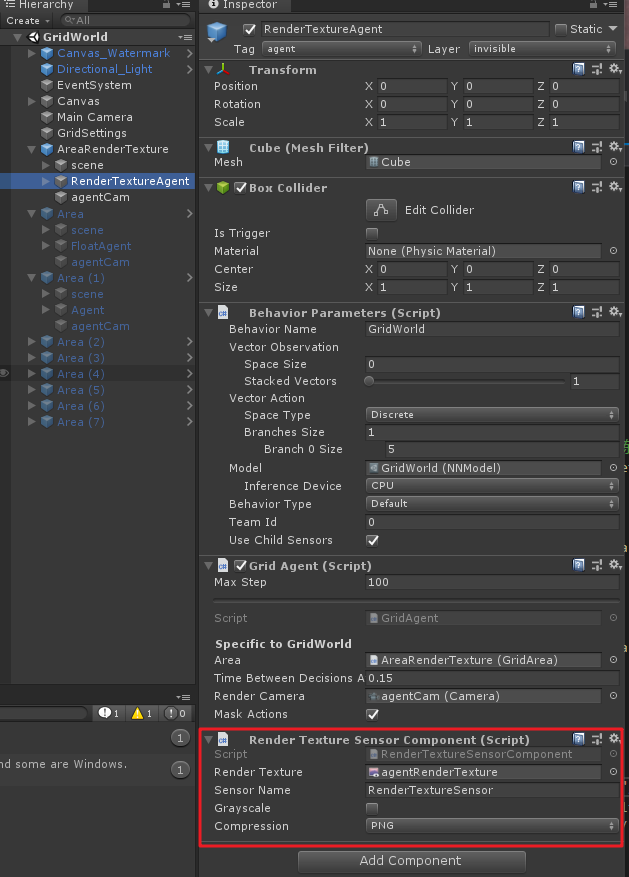
另一個

在工程中AreaRenderTexture訓練單元使用了Render Texture Sensor Component,而其他Agent單元卻使用的是Camera Sensor Component。這裡你會發現在AreaRenderTexture訓練單元中,如果將agentCam去掉,也對輸出沒啥影響,因為它使用RenderTextureSensor來訓練的。不知道這是是我理解錯了,還是說官方就是想用兩個Sensor來在這裡教(迷惑?)大家使用。。。。
訓練模型
OK,以上就是示例代碼部分的分析,下面我們來實操試試訓練該工程。首先試驗一下將障礙物和目標物的數量改為3和2試一下原先工程的訓練模型有沒有訓練泛化參數。
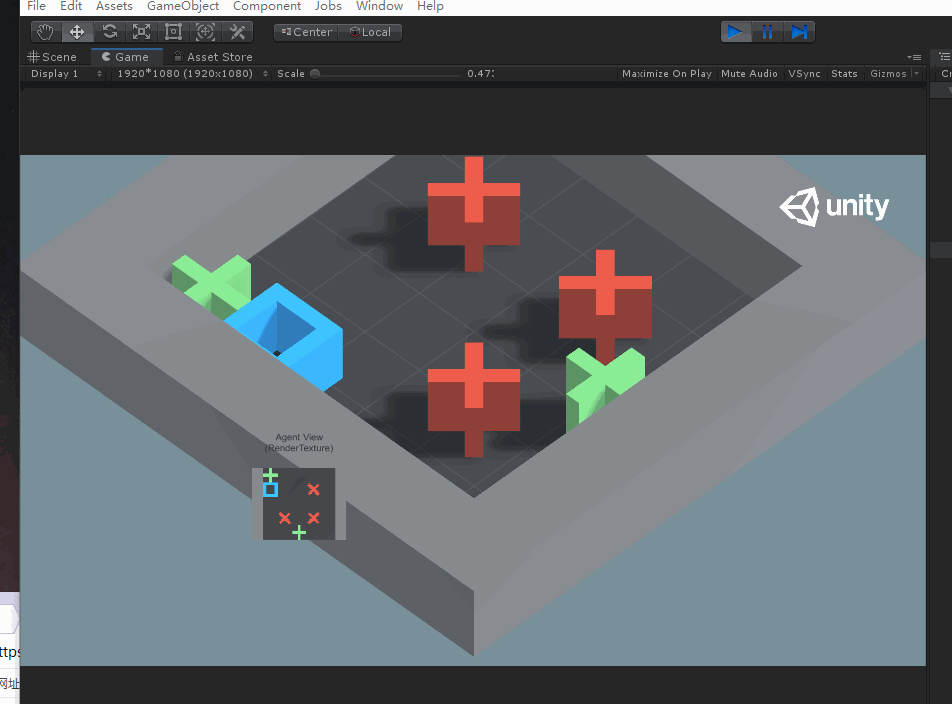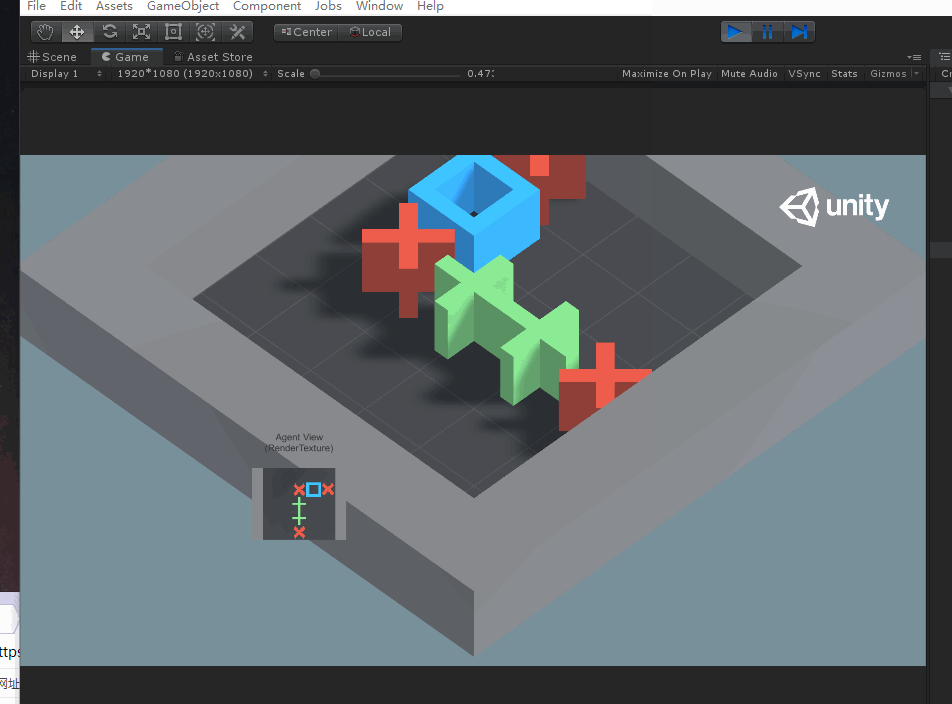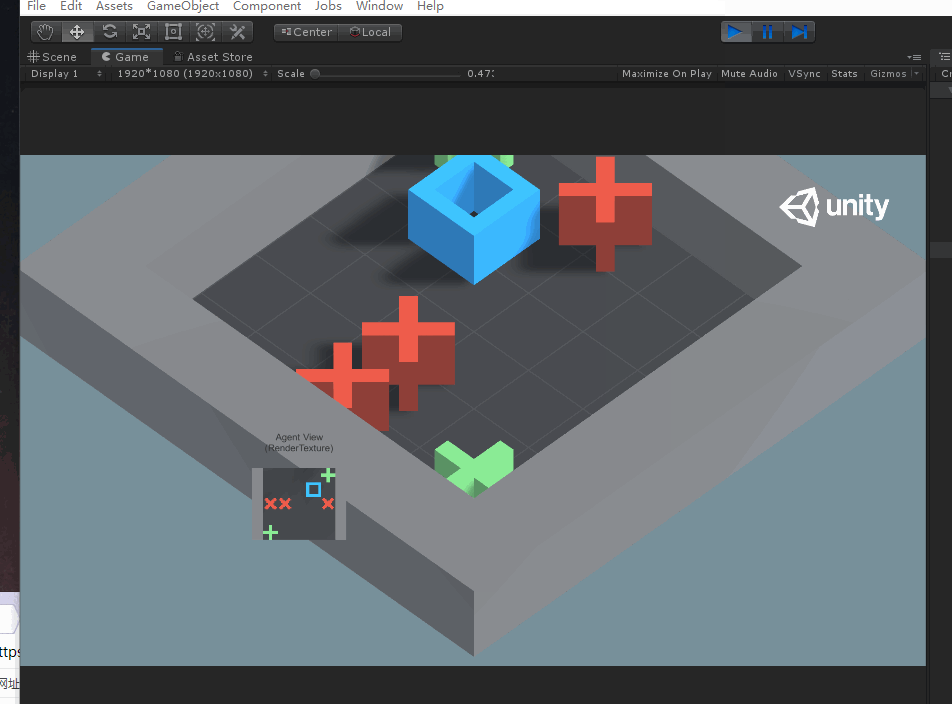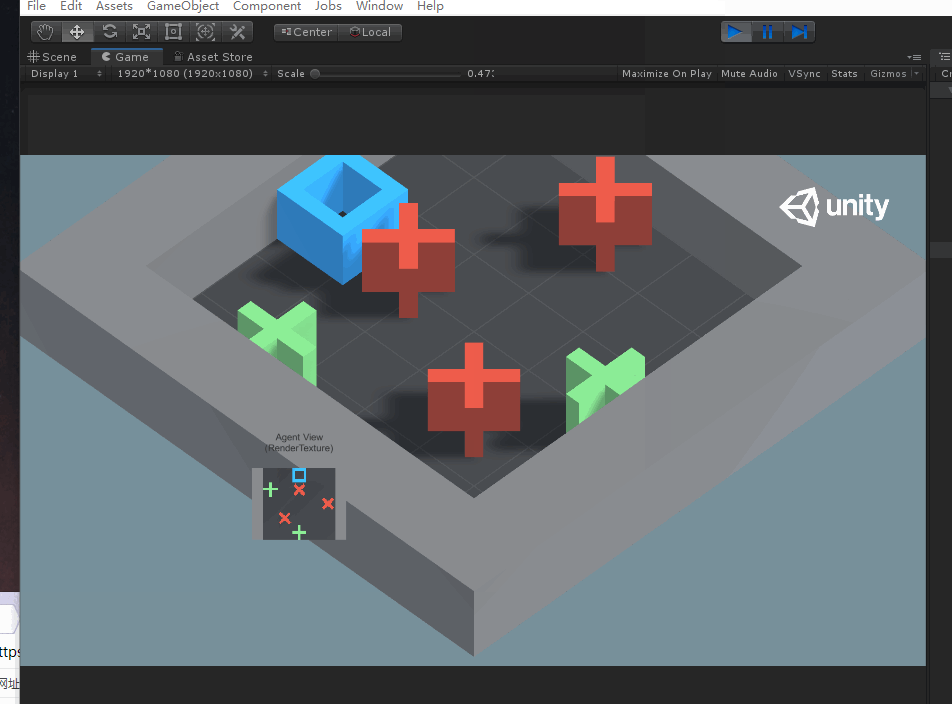
根據以上畫面可以發現,代理有點笨,不能立馬找到目標物,說明原先的訓練模型可能沒有引入泛化參數,因此我們訓練的時候引入泛化參數來對其進行訓練。
泛化參數配置
根據本示例中的泛化參數,我們在ml-agentconfig新建gridworld_generalize.yaml配置文件:
resampling-interval: 5000 gridSize: sampler-type: "uniform" min_value: 5 max_value: 15 numObstacles: sampler-type: "uniform" min_value: 1 max_value: 5 numGoals: sampler-type: "uniform" min_value: 1 max_value: 3 這裡配置文件的含義是,gridSize最小為5格,最大為15格;障礙物最少有1個,最多有5個;目標物最少有1個,最多有3個。
當然這裡的配置我也是試一下,對於這裡參數的配置我也還沒有多少經驗,不過可以以此來看一下能不能使得訓練模型在一定可變範圍內具有通用性。
開始訓練
基於之前的文章,這裡就不詳細寫訓練過程了,只將關鍵步驟做以說明,cd到ml-agent的d目錄,然後輸入以下訓練命令:
mlagents-learn config/trainer_config.yaml --sampler=config/gridworld_generalize.yaml --run-id=GridWolrd_Gen --train
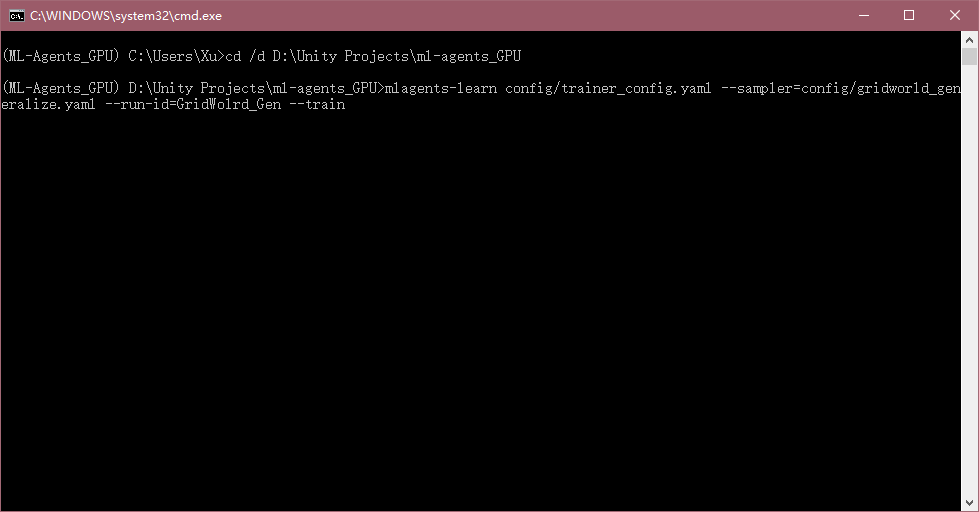
這一次的訓練過程相比3D Ball來說就比較卡了,等一段時間,在cmd里應該會有相應訓練步驟輸出,等待它訓練完成即可。我這裡訓練大概花了35分鐘。坑爹的是。。。這裡對於三個參數的泛化訓練,訓練的結果並不好,甚至連最基本的要求都沒達到。
試着只泛化一個參數,選擇障礙物可以有1-4個,然後進行訓練再看看,又是30分鐘等待= =,發現就算有一個障礙物參數隨機變化,訓練效果也不好。
下面附上三次訓練的tenserboard(三個泛化參數,一個泛化參數和無泛化參數)。
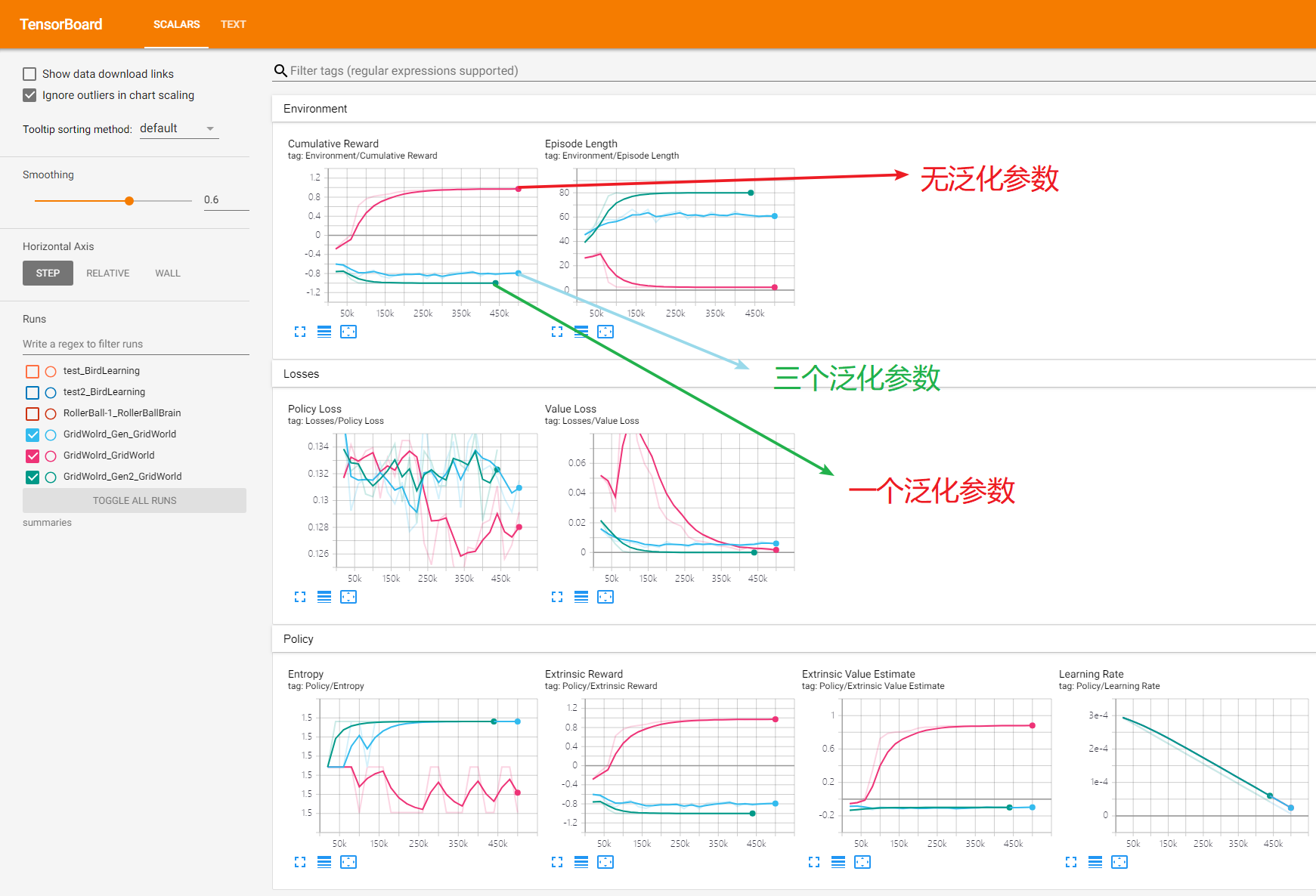
根據圖表就可以看出來,兩個加入泛化參數的訓練是失敗的,具體為什麼可能之後了解更多ml-agent才能知道。實際上把加入泛化參數的兩個模型放到Unity中去跑,也會發現訓練結果並不理想。
總結
Grid World這個示例還是比較有趣的,主要它利用了Visual Observations視覺觀察值來輸出圖像進行訓練,更加像人類用眼睛去學習的過程。當然不足的地方就是沒有把訓練的模型進行泛化,這點之後再研究吧。
寫文不易~因此做以下申明:
1.博客中標註原創的文章,版權歸原作者 煦陽(本博博主) 所有;
2.未經原作者允許不得轉載本文內容,否則將視為侵權;
3.轉載或者引用本文內容請註明來源及原作者;
4.對於不遵守此聲明或者其他違法使用本文內容者,本人依法保留追究權等。

