深入理解計算機系統cp1:存儲單位與編碼
- 2019 年 10 月 6 日
- 筆記
**摘要:** 理解計算機是如何存儲數據的。
– 原文:[深入理解計算機系統cp1:存儲單位與編碼](https://chorer.github.io/2019/09/16/CB-%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%B3%BB%E7%BB%9Fcp1/)
– 作者:[Chor](https://chorer.github.io/)
**[Fundebug](https://www.fundebug.com/)經授權轉載,版權歸原作者所有。**

### 1. 存儲單位
– 位:即 bit,表示二進制位,要麼是 0 ,要麼是 1。它是計算機內部數據存儲的最小單位。比如 11010100 共有8個二進制位,是一個8位二進制數。
– 位元組:即 byte,它由8個二進制位構成,即 1byte=8bit,是計算機內部計量的基本單位。一個英文字符佔1個位元組(8位),一個漢字佔2個位元組(16位)
– 字:即word,它由若干個位元組構成,是計算機內部進行數據處理和運算的基本單位。字的總的位數稱為字長,不同檔次的計算機字長是不一樣的,比如32位機,它的1個字由4個位元組構成,字長為32位,也就是說其CPU一次操作處理的實際位數是32位。同理,64位機可以處理64位。由此可見,計算機的字長越大,其性能越優越。
– KB,MB:1024byte = 1KB,1024KB = 1MB。往上還有GB,TB。
PS:數據傳輸大多以 bit 為單位,比如我們常說的網速100M/s,M/s其實Mbit/s,也就是兆比特每秒,我們還可以寫成100Mbps。
### 2. 編碼
#### 2.1 為什麼需要編碼?
– 計算機只能理解0和1,無法理解英文、字母、漢字和其他特殊字符,這些字符需要經過編碼才能成為計算機可以理解的二進制數。
– 由字符到二進制數稱為編碼,反過來則是解碼。
– 從字符到二進制數,需要有一個一一對應的映射,這個映射通過編碼規則來實現。
– 通常所說的編碼其實包括編碼+字符集(即字符的集合體),比如 Unicode 字符集,就有 UTF-8,UTF-16 等多種編碼。
#### 2.2 編碼規則的演變
– **ASCII:**
1) `/ˈæski/`,即 American Standard Code for Information Interchange,美國信息交換標準代碼。本來一個位元組有8位,每一位有0和1兩種狀態,則一個位元組共有2^8=256種狀態,可以表示256種字符。但是美國佬比較自私,覺得只要可以表示自己的字母和一些特殊字符就足夠了,所以 ASCII 沒有佔用最高位(而是固定為0),實際只用到了後面7位,它可以表示 2^7=128 種狀態,也就是表示128個字符。
2) 很顯然,這用來表示字母是足夠的,但要想表示其它語言的字符,128還是太少了。
PS:附送 ASCII 對照表一張:
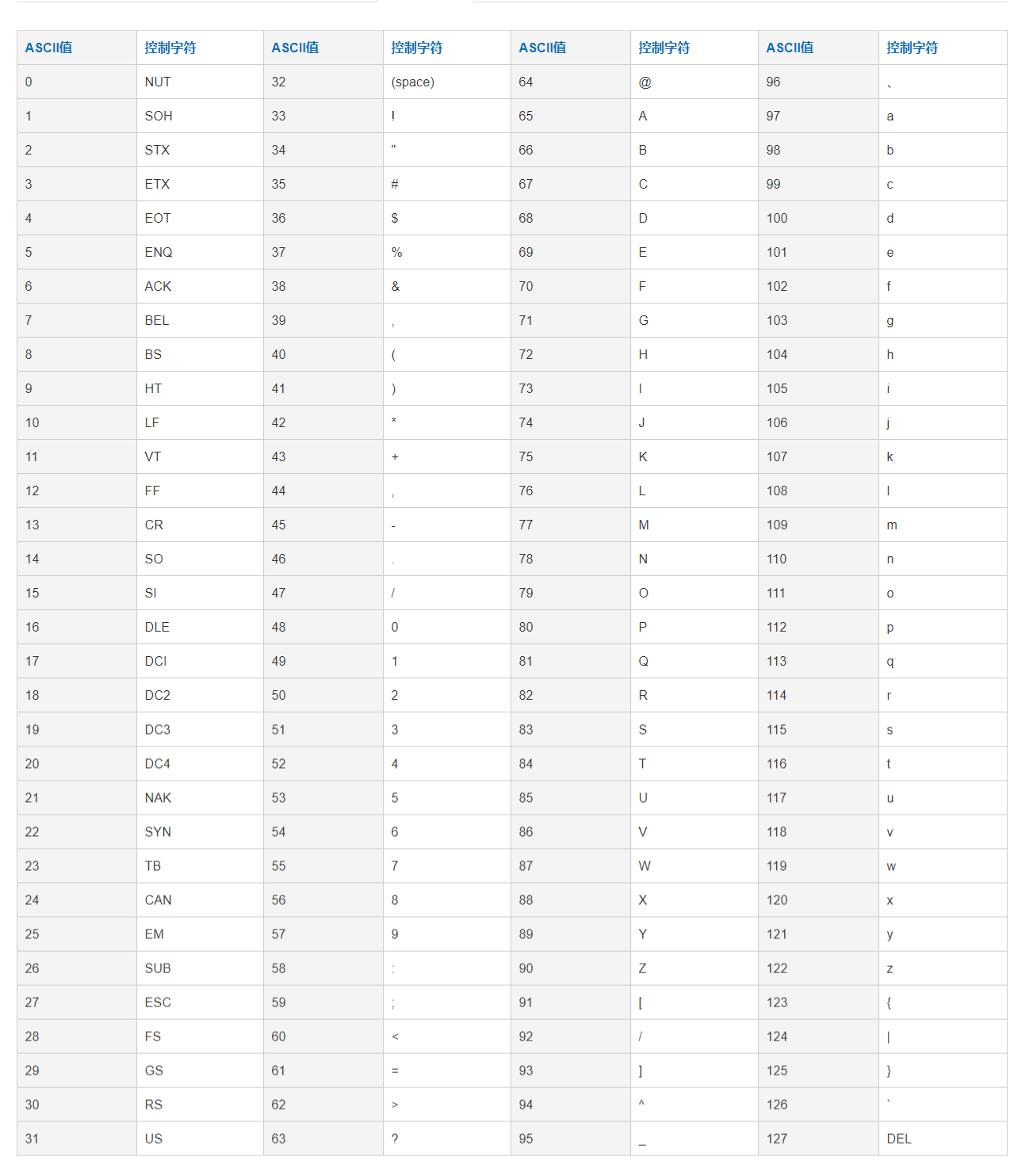
– **GB2312:**
1) 既然美國佬只解決了字母和特殊符號的編碼問題,那麼我們中國人只好實現自己的編碼,從而來表示漢字了。所以這時候出現了 GB2312 編碼(國標碼)。
2) 問題:不幸的是,各個國家都是這麼想的,所以小日本有了 Shift_JIS 編碼,棒子有了 Euc-kr 編碼…..一時之間各國都有了自己的標準,那麼對於一個多語言混合的文本來說,存在着不同的編碼規則,最終必然導致亂碼。
– **Unicode:**
1) Unicode 解決了編碼統一的問題。每種語言的每個字符在 Unicode 的規則下,都只有統一且唯一的對應二進制編碼。它的表示方法是`U+[16進制數]`。例如,大寫字母 A 編碼為 `U+0041`,漢字「嚴」編碼為 `U+4E25`。
2) 問題:Unicode 一般用2個位元組(也就是16位)表示一個字符,這在表示 ASCII 字符的時候會出現問題。我們知道,ASCII 字符實際只需要一個位元組就夠了,並且最高位甚至都還不需要用到,但是 Unicode 又規定表示一個字符至少需要2個位元組,那麼一個 ASCII 字符前面就必須要補0以滿足這個規則,例如字母 A 就需要用 `00000000 01000001` 表示,這些多餘的0是一個極大的資源浪費。
– **UTF-8:**
1) UTF:實際傳輸過程中,基於不同的系統平台,對 Unicode 會有不不同的實現方式,其實現方式稱為 Unicode Transformation Format,即 UTF。
2) 作為 Unicode 的一種實現方式,UTF-8 展現了一定的靈活性——它是一種變長編碼,會根據具體字符來改變所需要的表示位元組。其編碼規則只有兩條:
> i>. 對於 128 個 ASCII 字符只需一個位元組表示,位元組的第一位補 0,後面 7 位為這個字符的 ASCII 二進制數。Unicode 範圍為 U+0000 至U+007F。
> ii>. 對於 n 位元組的符號(n>1),第一個位元組的前 n 位都設為 1,第 n+1 位設為 0,後面位元組的前兩位一律設為 10。剩下的沒有提及的二進制位,全部為這個符號的 Unicode 碼二進制數。Unicode 範圍由 U+0080 起。
也可以看下面這張圖:
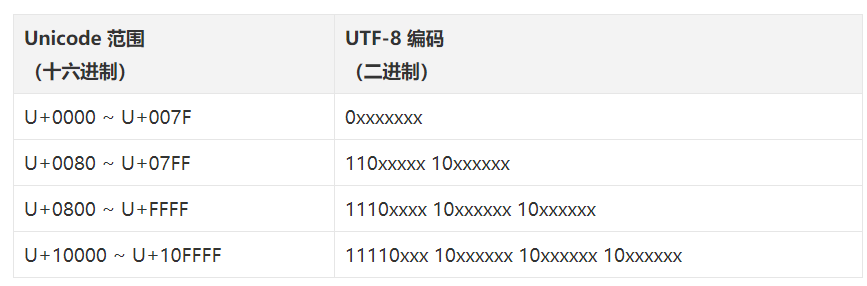
以漢字「嚴」為例,演示如何實現 UTF-8 編碼。
「嚴」的 Unicode 是 `U+4E25`(二進制數 100111000100101),據表,`U+4E25` 處在第三行的範圍內(`U+0800` ~ `U+FFFF`),因此「嚴」的UTF-8 編碼需要三個位元組,即格式 `1110xxxx 10xxxxxx 10xxxxxx`。然後,從「嚴」的最後一個二進制位開始,依次從後向前填入格式中的 x,多出的位補 0。這樣就得到 UTF-8 編碼(二進制)是 `11100100 10111000 10100101`,轉換成十六進制就是 `E4B8A5`。
### 參考:
– [基礎:ASCII,Unicode 和 UTF-8](https://segmentfault.com/a/1190000005936800)
– [字符串和編碼](https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896)
### 關於Fundebug
[Fundebug](https://www.fundebug.com/)專註於JavaScript、微信小程序、微信小遊戲、支付寶小程序、React Native、Node.js和Java線上應用實時BUG監控。 自從2016年雙十一正式上線,Fundebug累計處理了20億+錯誤事件,付費客戶有陽光保險、核桃編程、荔枝FM、掌門1對1、微脈、青團社等眾多品牌企業。歡迎大家[免費試用](https://www.fundebug.com/team/create)!
