人工神經網絡是什麼
- 2020 年 4 月 1 日
- 筆記
一、人工神經網絡

人工智能的主流研究方法是連接主義,通過人工構建神經網絡的方式模擬人類智能。
人工神經網絡(Artificial Neural Network,即ANN ),是20世紀80 年代以來人工智能領域興起的研究熱點。它從信息處理角度對人腦神經元網絡進行抽象, 建立某種簡單模型,按不同的連接方式組成不同的網絡。
人工神經網絡借鑒了生物神經網絡的思想,是超級簡化版的生物神經網絡。以工程技術手段模擬人腦神經系統的結構和功能,通過大量的非線性並行處理器模擬人腦中眾多的神經元,用處理器複雜的連接關係模擬人腦中眾多神經元之間的突觸行為。
二、生物神經網絡
人腦由大約千億個神經細胞及億億個神經突觸組成,這些神經細胞及其突觸共同構成了龐大的生物神經網絡
- 每個神經元伸出的突起分為樹突和軸突。
- 樹突分支比較多,每個分支還可以再分支,長度一般比較短,作用是接受信號。
- 軸突只有一個,長度一般比較長,作用是把從樹突和細胞表面傳入細胞體的神經信號傳出到其他神經元。
- 大腦中的神經元接受神經樹突的興奮性突觸後電位和抑制性突觸後電位,產生出沿其軸突傳遞的神經元的動作電位。

生物神經網絡大概有以下特點:
- 每個神經元都是一個多輸入單輸出的信息處理單元,神經元輸入分興奮性輸入和抑制性輸入兩種類型
- 神經細胞通過突觸與其他神經細胞進行連接與通信,突觸所接收到的信號強度超過某個閾值時,神經細胞會進入激活狀態,並通過突觸向上層神經細胞發送激活細號
- 神經元具有空間整合特性和閾值特性, 較高層次的神經元加工出了較低層次不具備的「新功能」
- 神經元輸入與輸出間有固定的時滯,主要取決於突觸延擱
外部事物屬性一般以光波、聲波、電波等方式作為輸入,刺激人類的生物傳感器。
三、硅基智能與碳基智能
人類智能建立在有機物基礎上的碳基智能,而人工智能建立在無機物基礎上的硅基智能。
碳基智能與硅基智能的本質區別是架構,決定了數據的傳輸與處理是否能夠同時進行。
計算機:硅基智能

數據的傳輸與處理無法同步進行。
馮·諾伊曼結構體系的一個核心特徵是運算單元和存儲單元的分離,兩者由數據總線連接。運算單元需要從數據總線接收來自存儲單元的數據,運算完成後再將運算結果通過數據總線傳回給存儲單元
數據不是為了存儲而存儲,而是為了在需要時能夠快速提取而存儲,存儲的作用是提升數據處理的有效性
人腦:碳基智能
數據的傳輸和處理是同步進行的。
數據的傳輸和處理由突觸和神經元之間的交互完成,並且是同時進行的,不存在先傳輸後處理的順序。
在同樣的時間和空間上,哺哺乳動物的大腦能夠在分佈式的神經系統上交換和處理信息,這是計算機達不到的。
另外生物記憶是一個保留精華的過程,無法用簡單的存儲模擬生物記憶。
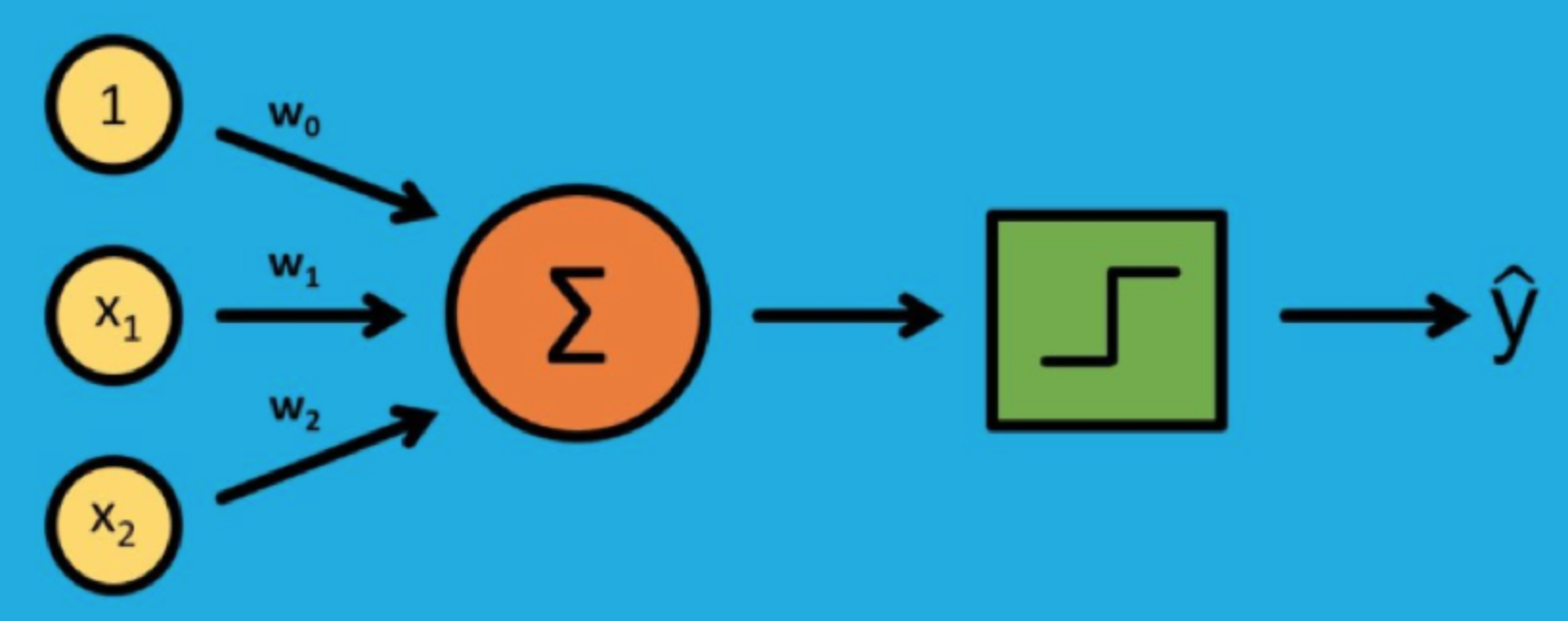
MP模型

M-P模型,是按照生物神經元的結構和工作原理構造出來的一個抽象和簡化了的模型。
MP神經元接受一個或多個輸入,並對輸入的線性加權進行非線性處理以產生輸出。
假定MP神經元輸入信號是N+1維向量((x_0,x_1,…,x_N)),第i個分量的權重為(w_i),則輸出可以寫成
(y=ϕ(sum_{i=0}^Nw_ix_i))
(ϕ(⋅))是傳遞函數,用於將加權後的輸入轉換為輸出,通常被設計成連續且有界的非線性增函數。
在MP神經元中,麥卡洛克和皮茨將輸入和輸出都限定為二進制信號,使用的傳遞函數則是不連續的符號函數,符號函數以預先設定的閾值作為參數:當輸入大於閾值時,符號函數輸出 1,反之則輸出 0
這樣MP神經元工作就類似數字電路中的邏輯門,能夠實現「邏輯與」或者「邏輯或」的功能.
感知器——最簡單的神經網絡結構

在1958年,美國心理學家Frank Rosenblatt提出一種具有單層計算單元的神經網絡,稱為感知器(Perceptron)。它其實就是基於M-P模型的結構。
Frank受到1949 年加拿大心理學家唐納德·赫布提出的「赫布理論」,核心觀點是學習的過程主要是通過神經元之間突觸的形成和變化來實現的。
兩個神經元細胞之間進行交流的越多,它們之間的聯繫就越來越強化,學習的效果也在聯繫不斷強化的過程中逐漸產生。
從人工神經網絡的角度,這個理論的意義在於給出了改變模型神經元之間權重的準則
- 如果兩個神經元同時被激活,它們的權重應該增加
- 如果兩個神經元分別被激活,兩者的權重應該降低

感知器不是真實的器件,而是一種二分類的監督學習算法,能夠決定向量表示的輸入是不屬於某個特定類別。
感知器由輸入導和輸出導組成,輸入導負責接收外界信號,輸出導是MP神經元,也就是閾值邏輯單元。
每個輸入信號(特徵)都以一定的權重送入MP神經元中,MP神經元則利用符號將特徵的線性組合映射為分類輸出。
給一個包含若干輸入輸出對應關係實例的訓練集,學習步驟為:
- 初始化權重w(0)和閾值,其中權重可以初始化為0或較小的隨機婁
- 對訓練集中的第j個樣本,將其輸入向量(x_j)送入已經初始化的感知器,得到輸出(y_j(t))
- 根據(y_j(t))和樣本(j)的給定輸出結果(d_j),按以規則更新權重向量:
(w_i(t+1)=w_i(t)+η[d_j-y_j(t)]⋅x_{j,i}) - 重複以上兩個步驟,直到訓練次數達到預設值
第三步要對感知器的權重進行更新,是學習算法的核心步驟,其中0<η≤1 被稱為學習率參數,是修正誤差的一個比例係數。
如果分類結果和真實結果相同,則保持權重不變;如果輸出值應該為0但實際為1,就要減少(x_j)中輸入值為1的分量的權重;如果輸出值應該為1但實際為0,則增加(x_j)中輸入值為1的分量的權重
感知器能夠學習的前提是它具有收斂性。感知器學習算法能夠在有限次的迭代後收斂,得到決策面位於兩類之間的超平面。
本質上在執行二分類問題時,感知器以所有誤差分類點到超平面的總距離為損失函數,用隨機梯度下降法不斷使損失函數下降,直到得到正確的分類結果
除了優良的收斂性能外,感知器還有自適應性,只要給定訓練數據集,算法就可以基於誤差修正自適應地調整參數而無需人工介入,這在MP神經元的有了很大的進步。
單層感知器——無法處理異或問題
只能解決線性分類問題,沒有辦法處理異或問題
所謂線性分類意指所有的正例和負例可以通過高維空間中的一個超平面完全分開而不產生錯誤。
如果一個圓形被分成一黑一白兩個半圓,這就是個線性可分的問題;
可如果是個太極圖的話,單單一條直線就沒法把黑色和白色完全區分開來了,這對應着線性不可分問題。
如果訓練數據集不是線性可分的,也就是正例不能通過超平面與負例分離,那麼感知器就不可能將所有輸入向量正確分類。
多層感知器——隱藏層、反向傳播

-
隱藏層
多層感知器的核心結構是隱藏層,用於特徵檢測。
之所以被稱為隱藏層,是因為這些神經元並不屬於網絡的輸入或輸出。
隱藏的神經元將訓練數據變換到新的特徵空間上,並識別出訓練數據的突出特徵。
不同層之間,多導感知器具有全連接性,即任意層中的每個神經元都與它前一層中的所有神經元或者節點相連接,連接的強度由網絡中的權重系統決定。 -
反向傳播
將輸出和真實值相減得到誤差函數,最後根據誤差函數更新權重。
訓練過程中,雖然信號的流向是輸出方向,但是計算的誤差函數和信號傳播的方向相反,這種學習方式叫反向傳播。
通過求解誤差函數關於每個權重係數的偏導數,以此使誤差最小化來訓練整個網絡。


