MySQL 【優化寶典】
- 2020 年 3 月 17 日
- 筆記
概述
為什麼要優化
- 系統的吞吐量瓶頸往往出現在數據庫的訪問速度上
- 隨着應用程序的運行,數據庫的中的數據會越來越多,處理時間會相應變慢
- 數據是存放在磁盤上的,讀寫速度無法和內存相比
如何優化
- 設計數據庫時:數據庫表、字段的設計,存儲引擎
- 利用好MySQL自身提供的功能,如索引等
- 橫向擴展:MySQL集群、負載均衡、讀寫分離
- SQL語句的優化(收效甚微)
字段設計
- 字段類型的選擇,設計規範,範式,常見設計案例
原則:盡量使用整型表示字符串
- 存儲IP
# INET_ATON(str),address to number # INET_NTOA(number),number to address
- MySQL內部的枚舉類型(單選)和集合(多選)類型
- 但是因為維護成本較高因此不常使用,使用關聯表的方式來替代
enum
- 但是因為維護成本較高因此不常使用,使用關聯表的方式來替代
原則:定長和非定長數據類型的選擇
# decimal不會損失精度,存儲空間會隨數據的增大而增大。double佔用固定空間,較大數的存儲會損失精度。非定長的還有varchar、text
-
金額
# 對數據的精度要求較高,小數的運算和存儲存在精度問題(不能將所有小數轉換成二進制)
- 定點數decimal
# price decimal(8,2)有2位小數的定點數,定點數支持很大的數(甚至是超過int,bigint存儲範圍的數)
- 小單位大數額避免出現小數
- 元->分
- 字符串存儲
# 定長char,非定長varchar、text(上限65535,其中varchar還會消耗1-3位元組記錄長度,而text使用額外空間記錄長度)
原則:儘可能選擇小的數據類型和指定短的長度
- 原則:儘可能使用 not null
- 非
null字段的處理要比null字段的處理高效些!且不需要判斷是否為null。 null在MySQL中,不好處理,存儲需要額外空間,運算也需要特殊的運算符。如select null = null和select null <> null(<>為不等號)有着同樣的結果,只能通過is null和is not null來判斷字段是否為null。- 如何存儲?MySQL中每條記錄都需要額外的存儲空間,表示每個字段是否為
null。因此通常使用特殊的數據進行佔位,比如int not null default 0、string not null default ‘’
- 非
原則:字段注釋要完整,見名知意
原則:單表字段不宜過多
- 二三十個就極限了
原則:可以預留字段
# 在使用以上原則之前首先要滿足業務需求
關聯表的設計
# 外鍵foreign key只能實現一對一或一對多的映射
- 一對多
- 使用外鍵
- 多對多
- 單獨新建一張表將多對多拆分成兩個一對多
- 一對一
- 如商品的基本信息(
item)和商品的詳細信息(item_intro),通常使用相同的主鍵或者增加一個外鍵字段(item_id)
- 如商品的基本信息(
範式 Normal Format
# 數據表的設計規範,一套越來越嚴格的規範體系(如果需要滿足N範式,首先要滿足N-1範式)。N
- 第一範式1NF:字段原子性
- 字段原子性,字段不可再分割。
- 關係型數據庫,默認滿足第一範式
- 注意比較容易出錯的一點,在一對多的設計中使用逗號分隔多個外鍵,這種方法雖然存儲方便,但不利於維護和索引(比如查找帶標籤
java的文章)
-
第二範式:消除對主鍵的部分依賴
- 即在表中加上一個與業務邏輯無關的字段作為主鍵
- 主鍵:可以唯一標識記錄的字段或者字段集合。
| course_name | course_class | weekday(周幾) | course_teacher |
|---|---|---|---|
| MySQL | 教育大樓1525 | 周一 | 張三 |
| Java | 教育大樓1521 | 周三 | 李四 |
| MySQL | 教育大樓1521 | 周五 | 張三 |
-
- 依賴:A字段可以確定B字段,則B字段依賴A字段。比如知道了下一節課是數學課,就能確定任課老師是誰。於是周幾和下一節課和就能構成複合主鍵,能夠確定去哪個教室上課,任課老師是誰等。但我們常常增加一個
id作為主鍵,而消除對主鍵的部分依賴。 - 對主鍵的部分依賴:某個字段依賴複合主鍵中的一部分。
- 解決方案:新增一個獨立字段作為主鍵。
- 依賴:A字段可以確定B字段,則B字段依賴A字段。比如知道了下一節課是數學課,就能確定任課老師是誰。於是周幾和下一節課和就能構成複合主鍵,能夠確定去哪個教室上課,任課老師是誰等。但我們常常增加一個
-
第三範式:消除對主鍵的傳遞依賴
- 傳遞依賴:B字段依賴於A,C字段又依賴於B。比如上例中,任課老師是誰取決於是什麼課,是什麼課又取決於主鍵
id。因此需要將此表拆分為兩張表日程表和課程表(獨立數據獨立建表):
- 傳遞依賴:B字段依賴於A,C字段又依賴於B。比如上例中,任課老師是誰取決於是什麼課,是什麼課又取決於主鍵
| id | weekday | course_class | course_id |
|---|---|---|---|
| 1001 | 周一 | 教育大樓1521 | 3546 |
| course_id | course_name | course_teacher |
|---|---|---|
| 3546 | Java | 張三 |
-
- 這樣就減少了數據的冗餘(即使周一至周日每天都有Java課,也只是
course_id:3546出現了7次)
- 這樣就減少了數據的冗餘(即使周一至周日每天都有Java課,也只是
存儲引擎選擇
# 早期問題:如何選擇MyISAM和Innodb? # 現在不存在這個問題了,Innodb不斷完善,從各個方面趕超MyISAM,也是MySQL默認使用的。
存儲引擎Storage engine:MySQL中的數據、索引以及其他對象是如何存儲的,是一套文件系統的實現。
- 功能差異
show engines
| Engine | Support | Comment |
|---|---|---|
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys |
| MyISAM | YES | MyISAM storage engine |
- 存儲差異
| MyISAM | Innodb | |
|---|---|---|
| 文件格式 | 數據和索引是分別存儲的,數據.MYD,索引.MYI |
數據和索引是集中存儲的,.ibd |
| 文件能否移動 | 能,一張表就對應.frm、MYD、MYI3個文件 |
否,因為關聯的還有data下的其它文件 |
| 記錄存儲順序 | 按記錄插入順序保存 | 按主鍵大小有序插入 |
空間碎片(刪除記錄並flush table 表名之後,表文件大小不變) |
產生。定時整理:使用命令optimize table 表名實現 |
不產生 |
| 事務 | 不支持 | 支持 |
| 外鍵 | 不支持 | 支持 |
| 鎖支持(鎖是避免資源爭用的一個機制,MySQL鎖對用戶幾乎是透明的) | 表級鎖定 | 行級鎖定、表級鎖定,鎖定力度小並發能力高 |
鎖擴展
- 表級鎖(
table-level lock):lock tables <table_name1>,<table_name2>... read/write,unlock tables <table_name1>,<table_name2>...。其中read是共享鎖,一旦鎖定任何客戶端都不可讀;write是獨佔/寫鎖,只有加鎖的客戶端可讀可寫,其他客戶端既不可讀也不可寫。鎖定的是一張表或幾張表。 - 行級鎖(
row-level lock):鎖定的是一行或幾行記錄。共享鎖:select * from <table_name> where <條件> LOCK IN SHARE MODE;,對查詢的記錄增加共享鎖;select * from <table_name> where <條件> FOR UPDATE;,對查詢的記錄增加排他鎖。這裡值得注意的是:innodb的行鎖,其實是一個子範圍鎖,依據條件鎖定部分範圍,而不是就映射到具體的行上,因此還有一個學名:間隙鎖。比如select * from stu where id < 20 LOCK IN SHARE MODE會鎖定id在20左右以下的範圍,你可能無法插入id為18或22的一條新紀錄。
選擇依據
- 如果沒有特別的需求,使用默認的
Innodb即可。 - MyISAM:以讀寫插入為主的應用程序,比如博客系統、新聞門戶網站。
- Innodb:更新(刪除)操作頻率也高,或者要保證數據的完整性;並發量高,支持事務和外鍵保證數據完整性。比如OA自動化辦公系統。
索引
- 關鍵字與數據的映射關係稱為索引(==包含關鍵字和對應的記錄在磁盤中的地址==)。關鍵字是從數據當中提取的用於標識、檢索數據的特定內容。
-
索引檢索為什麼快?
- 關鍵字相對於數據本身,==數據量小==
- 關鍵字是==有序==的,二分查找可快速確定位置
- 圖書館為每本書都加了索引號(類別-樓層-書架)、字典為詞語解釋按字母順序編寫目錄等都用到了索引。
- MySQL中索引類型
- 普通索引(
key),唯一索引(unique key),主鍵索引(primary key),全文索引(fulltext key)
- 普通索引(
- 三種索引的索引方式是一樣的,只不過對索引的關鍵字有不同的限制:
- 普通索引:對關鍵字沒有限制
- 唯一索引:要求記錄提供的關鍵字不能重複
- 主鍵索引:要求關鍵字唯一且不為null
索引管理語法
- 查看索引
show create table 表名:
desc 表名
創建索引
- 創建表之後建立索引
create TABLE user_index( id int auto_increment primary key, first_name varchar(16), last_name VARCHAR(16), id_card VARCHAR(18), information text ); # -- 更改表結構 alter table user_index # -- 創建一個first_name和last_name的複合索引,並命名為name add key name (first_name,last_name), # -- 創建一個id_card的唯一索引,默認以字段名作為索引名 add UNIQUE KEY (id_card), # -- 雞肋,全文索引不支持中文 add FULLTEXT KEY (information);
show create table user_index:
- 創建表時指定索引
CREATE TABLE user_index2 ( id INT auto_increment PRIMARY KEY, first_name VARCHAR (16), last_name VARCHAR (16), id_card VARCHAR (18), information text, KEY name (first_name, last_name), FULLTEXT KEY (information), UNIQUE KEY (id_card) );
- 刪除索引
- 根據索引名刪除普通索引、唯一索引、全文索引:
alter table 表名 drop KEY 索引名
- 根據索引名刪除普通索引、唯一索引、全文索引:
alter table user_index drop KEY name; alter table user_index drop KEY id_card; alter table user_index drop KEY information;
- 刪除主鍵索引:
alter table 表名 drop primary key(因為主鍵只有一個)。這裡值得注意的是,如果主鍵自增長,那麼不能直接執行此操作(自增長依賴於主鍵索引):
- 需要取消自增長再行刪除:
alter table user_index # -- 重新定義字段 MODIFY id int, drop PRIMARY KEY
- 但通常不會刪除主鍵,因為設計主鍵一定與業務邏輯無關。
執行計劃explain
CREATE TABLE innodb1 ( id INT auto_increment PRIMARY KEY, first_name VARCHAR (16), last_name VARCHAR (16), id_card VARCHAR (18), information text, KEY name (first_name, last_name), FULLTEXT KEY (information), UNIQUE KEY (id_card) ); insert into innodb1 (first_name,last_name,id_card,information) values ('張','三','1001','華山派');
- 我們可以通過
explain selelct來分析SQL語句執行前的執行計劃:
- 由上圖可看出此SQL語句是按照主鍵索引來檢索的。
- 執行計劃是:當執行SQL語句時,首先會分析、優化,形成執行計劃,在按照執行計劃執行。
索引使用場景(重點)
-
where
- 上圖中,根據
id查詢記錄,因為id字段僅建立了主鍵索引,因此此SQL執行可選的索引只有主鍵索引,如果有多個,最終會選一個較優的作為檢索的依據。
# -- 增加一個沒有建立索引的字段 alter table innodb1 add sex char(1); # -- 按sex檢索時可選的索引為null EXPLAIN SELECT * from innodb1 where sex='男';
- 可以嘗試在一個字段未建立索引時,根據該字段查詢的效率,然後對該字段建立索引(
alter table 表名 add index(字段名)),同樣的SQL執行的效率,你會發現查詢效率會有明顯的提升(數據量越大越明顯)。 - order by
- 當我們使用
order by將查詢結果按照某個字段排序時,如果該字段沒有建立索引,那麼執行計劃會將查詢出的所有數據使用外部排序(將數據從硬盤分批讀取到內存使用內部排序,最後合併排序結果),這個操作是很影響性能的,因為需要將查詢涉及到的所有數據從磁盤中讀到內存(如果單條數據過大或者數據量過多都會降低效率),更無論讀到內存之後的排序了。 - 但是如果我們對該字段建立索引
alter table 表名 add index(字段名),那麼由於索引本身是有序的,因此直接按照索引的順序和映射關係逐條取出數據即可。而且如果分頁的,那麼只用取出索引表某個範圍內的索引對應的數據,而不用像上述那取出所有數據進行排序再返回某個範圍內的數據。(從磁盤取數據是最影響性能的)
- 當我們使用
- join
- 對
join語句匹配關係(on)涉及的字段建立索引能夠提高效率
- 對
- 索引覆蓋
- 如果要查詢的字段都建立過索引,那麼引擎會直接在索引表中查詢而不會訪問原始數據(否則只要有一個字段沒有建立索引就會做全表掃描),這叫索引覆蓋。因此我們需要儘可能的在
select後==只寫必要的查詢字段==,以增加索引覆蓋的幾率。 - 這裡值得注意的是不要想着為每個字段建立索引,因為優先使用索引的優勢就在於其體積小。
- 如果要查詢的字段都建立過索引,那麼引擎會直接在索引表中查詢而不會訪問原始數據(否則只要有一個字段沒有建立索引就會做全表掃描),這叫索引覆蓋。因此我們需要儘可能的在
- 語法細節(要點)
- 在滿足索引使用的場景下(
where/order by/join on或索引覆蓋),索引也不一定被使用
- 在滿足索引使用的場景下(
- 字段要獨立出現
- 比如下面兩條SQL語句在語義上相同,但是第一條會使用主鍵索引而第二條不會。
select * from user where id = 20-1; select * from user where id+1 = 20;
like查詢,不能以通配符開頭- 比如搜索標題包含
mysql的文章:
- 比如搜索標題包含
# select * from article where title like '%mysql%';
-
- 這種SQL的執行計劃用不了索引(
like語句匹配表達式以通配符開頭),因此只能做全表掃描,效率極低,在實際工程中幾乎不被採用。而一般會使用第三方提供的支持中文的全文索引來做。
- 這種SQL的執行計劃用不了索引(
- 但是 關鍵字查詢 熱搜提醒功能還是可以做的,比如鍵入
mysql之後提醒mysql 教程、mysql 下載、mysql 安裝步驟等。用到的語句是:
# select * from article where title like 'mysql%';
- 這種
like是可以利用索引的(當然前提是title字段建立過索引)。
複合索引只對第一個字段有效
- 建立複合索引:
# alter table person add index(first_name,last_name);
- 其原理就是將索引先按照從
first_name中提取的關鍵字排序,如果無法確定先後再按照從last_name提取的關鍵字排序,也就是說該索引表只是按照記錄的first_name字段值有序。 - 因此
select * from person where first_name = ?是可以利用索引的,而select * from person where last_name = ?無法利用索引。 - 那麼該複合索引的應用場景是什麼?==組合查詢==
- 比如對於
select * person from first_name = ? and last_name = ?,複合索引就比對first_name和last_name單獨建立索引要高效些。很好理解,複合索引首先二分查找與first_name = ?匹配的記錄,再在這些記錄中二分查找與last_name匹配的記錄,只涉及到一張索引表。而分別單獨建立索引則是在first_name索引表中二分找出與first_name = ?匹配的記錄,再在last_name索引表中二分找出與last_name = ?的記錄,兩者取交集。
or,兩邊條件都有索引可用
- 一但有一邊無索引可用就會導致整個SQL語句的全表掃描
狀態值,不容易使用到索引
- 如性別、支付狀態等狀態值字段往往只有極少的幾種取值可能,這種字段即使建立索引,也往往利用不上。這是因為,一個狀態值可能匹配大量的記錄,這種情況MySQL會認為利用索引比全表掃描的效率低,從而棄用索引。索引是隨機訪問磁盤,而全表掃描是順序訪問磁盤,這就好比有一棟20層樓的寫字樓,樓底下的索引牌上寫着某個公司對應不相鄰的幾層樓,你去公司找人,與其按照索引牌的提示去其中一層樓沒找到再下來看索引牌再上樓,不如從1樓挨個往上找到頂樓。
如何創建索引
- 建立基礎索引:在
where、order by、join字段上建立索引。 - 優化,組合索引:基於業務邏輯
- 如果條件經常性出現在一起,那麼可以考慮將多字段索引升級為==複合索引==
- 如果通過增加個別字段的索引,就可以出現==索引覆蓋==,那麼可以考慮為該字段建立索引
- 查詢時,不常用到的索引,應該刪除掉
前綴索引
- 語法:
index(field(10)),使用字段值的前10個字符建立索引,默認是使用字段的全部內容建立索引。 - 前提:前綴的標識度高。比如密碼就適合建立前綴索引,因為密碼幾乎各不相同。
- ==實操的難度==:在於前綴截取的長度。
- 我們可以利用
select count(*)/count(distinct left(password,prefixLen));,通過從調整prefixLen的值(從1自增)查看不同前綴長度的一個平均匹配度,接近1時就可以了(表示一個密碼的前prefixLen個字符幾乎能確定唯一一條記錄)
索引的存儲結構
-
BTree
- btree(多路平衡查找樹)是一種廣泛應用於==磁盤上實現索引功能==的一種數據結構也是大多數數據庫索引表的實現。
- 以
add index(first_name,last_name)為例:
-
- BTree的一個node可以存儲多個關鍵字,node的大小取決於計算機的文件系統,因此我們可以通過減小索引字段的長度使結點存儲更多的關鍵字。如果node中的關鍵字已滿,那麼可以通過每個關鍵字之間的子節點指針來拓展索引表,但是不能破壞結構的有序性,比如按照
first_name第一有序、last_name第二有序的規則,新添加的韓香就可以插到韓康之後。白起 < 韓飛 < 韓康 < 李世民 < 趙奢 < 李尋歡 < 王語嫣 < 楊不悔。這與二叉搜索樹的思想是一樣的,只不過二叉搜索樹的查找效率是log(2,N)(以2為底N的對數),而BTree的查找效率是log(x,N)(其中x為node的關鍵字數量,可以達到1000以上)。 - 從
log(1000+,N)可以看出,少量的磁盤讀取即可做到大量數據的遍歷,這也是btree的設計目的。
- BTree的一個node可以存儲多個關鍵字,node的大小取決於計算機的文件系統,因此我們可以通過減小索引字段的長度使結點存儲更多的關鍵字。如果node中的關鍵字已滿,那麼可以通過每個關鍵字之間的子節點指針來拓展索引表,但是不能破壞結構的有序性,比如按照
- B+Tree聚簇結構
- 聚簇結構(也是在BTree上升級改造的)中,關鍵字和記錄是存放在一起的。
- 在MySQL中,僅僅只有
Innodb的==主鍵索引為聚簇結構==,其它的索引包括Innodb的非主鍵索引都是典型的BTree結構。
-
哈希索引
- 在索引被載入內存時,使用哈希結構來存儲。
查詢緩存
- 緩存
select語句的查詢結果
在配置文件中開啟緩存
- windows上是
my.ini,linux上是my.cnf - 在
[mysqld]段中配置query_cache_type:- 0:不開啟
- 1:開啟,默認緩存所有,需要在SQL語句中增加
select sql-no-cache提示來放棄緩存 - 2:開啟,默認都不緩存,需要在SQL語句中增加
select sql-cache來主動緩存(==常用==)
- 更改配置後需要重啟以使配置生效,重啟後可通過
show variables like ‘query_cache_type’;來查看:
# show variables like 'query_cache_type'; # query_cache_type DEMAND
- 在客戶端設置緩存大小
- 通過配置項
query_cache_size來設置:
- 通過配置項
# show variables like 'query_cache_size'; # query_cache_size 0 # set global query_cache_size=64*1024*1024; # show variables like 'query_cache_size'; # query_cache_size 67108864
將查詢結果緩存
# select sql_cache * from user;
-
重置緩存
# reset query cache;
-
緩存失效問題(大問題)
- 當數據表改動時,基於該數據表的任何緩存都會被刪除。(表層面的管理,不是記錄層面的管理,因此失效率較高)
-
注意事項
- 應用程序,不應該關心
query cache的使用情況。可以嘗試使用,但不能由query cache決定業務邏輯,因為query cache由DBA來管理。 - 緩存是以SQL語句為key存儲的,因此即使SQL語句功能相同,但如果多了一個空格或者大小寫有差異都會導致匹配不到緩存。
分區
- 一般情況下我們創建的表對應一組存儲文件,使用
MyISAM存儲引擎時是一個.MYI和.MYD文件,使用Innodb存儲引擎時是一個.ibd和.frm(表結構)文件。 - 當數據量較大時(一般千萬條記錄級別以上),MySQL的性能就會開始下降,這時我們就需要將數據分散到多組存儲文件,==保證其單個文件的執行效率==。
- 最常見的分區方案是按
id分區,如下將id的哈希值對10取模將數據均勻分散到10個.ibd存儲文件中:
create table article( id int auto_increment PRIMARY KEY, title varchar(64), content text )PARTITION by HASH(id) PARTITIONS 10
- 查看
data目錄:
- ==服務端的表分區對於客戶端是透明的==,客戶端還是照常插入數據,但服務端會按照分區算法分散存儲數據。
MySQL提供的分區算法
- ==分區依據的字段必須是主鍵的一部分==,分區是為了快速定位數據,因此該字段的搜索頻次較高應作為強檢索字段,否則依照該字段分區毫無意義
- hash(field)
- 相同的輸入得到相同的輸出。輸出的結果跟輸入是否具有規律無關。==僅適用於整型字段==
- key(field)
- 和
hash(field)的性質一樣,只不過key是==處理字符串==的,比hash()多了一步從字符串中計算出一個整型在做取模操作。
- 和
create table article_key( id int auto_increment, title varchar(64), content text, PRIMARY KEY (id,title) # -- 要求分區依據字段必須是主鍵的一部分 )PARTITION by KEY(title) PARTITIONS 10
- range算法
- 是一種==條件分區==算法,按照數據大小範圍分區(將數據使用某種條件,分散到不同的分區中)。
- 如下,按文章的發佈時間將數據按照2018年8月、9月、10月分區存放:
create table article_range( id int auto_increment, title varchar(64), content text, created_time int, # -- 發佈時間到1970-1-1的毫秒數 PRIMARY KEY (id,created_time) # -- 要求分區依據字段必須是主鍵的一部分 )charset=utf8 PARTITION BY RANGE(created_time)( PARTITION p201808 VALUES less than (1535731199), -- select UNIX_TIMESTAMP('2018-8-31 23:59:59') PARTITION p201809 VALUES less than (1538323199), -- 2018-9-30 23:59:59 PARTITION p201810 VALUES less than (1541001599) -- 2018-10-31 23:59:59 );
- 注意:條件運算符只能使用==less than==,這以為著較小的範圍要放在前面,比如上述
p201808,p201819,p201810分區的定義順序依照created_time數值範圍從小到大,不能顛倒。
insert into article_range values(null,'MySQL優化','內容示例',1535731180); flush tables; # -- 使操作立即刷新到磁盤文件
- 由於插入的文章的發佈時間
1535731180小於1535731199(2018-8-31 23:59:59),因此被存儲到p201808分區中,這種算法的存儲到哪個分區取決於數據狀況。 - list算法
- 也是一種條件分區,按照列表值分區(
in (值列表))。
- 也是一種條件分區,按照列表值分區(
create table article_list( id int auto_increment, title varchar(64), content text, status TINYINT(1), # -- 文章狀態:0-草稿,1-完成但未發佈,2-已發佈 PRIMARY KEY (id,status) # -- 要求分區依據字段必須是主鍵的一部分 )charset=utf8 PARTITION BY list(status)( PARTITION writing values in(0,1), # -- 未發佈的放在一個分區 PARTITION published values in (2) # -- 已發佈的放在一個分區 );
insert into article_list values(null,'mysql優化','內容示例',0); flush tables;
分區管理語法
- range/list
- 增加分區
- 前文中我們嘗試使用
range對文章按照月份歸檔,隨着時間的增加,我們需要增加一個月份:
alter table article_range add partition( partition p201811 values less than (1543593599) -- select UNIX_TIMESTAMP('2018-11-30 23:59:59') -- more );
- 刪除分區
# alter table article_range drop PARTITION p201808
- 注意:==刪除分區後,分區中原有的數據也會隨之刪除!==
- key/hash
- 新增分區
# alter table article_key add partition partitions 4
- 銷毀分區
# alter table article_key coalesce partition 6
-
key/hash分區的管理不會刪除數據,但是每一次調整(新增或銷毀分區)都會將所有的數據重寫分配到新的分區上。==效率極低==,最好在設計階段就考慮好分區策略。
- 分區的使用
- 當數據表中的數據量很大時,分區帶來的效率提升才會顯現出來。
- 只有檢索字段為分區字段時,分區帶來的效率提升才會比較明顯。因此,==分區字段的選擇很重要==,並且==業務邏輯要儘可能地根據分區字段做相應調整==(盡量使用分區字段作為查詢條件)。
水平分割和垂直分割
- 水平分割:通過建立結構相同的幾張表分別存儲數據
- 垂直分割:將經常一起使用的字段放在一個單獨的表中,分割後的表記錄之間是一一對應關係。
分表原因
- 為數據庫減壓
- 分區算法局限
- 數據庫支持不完善(
5.1之後mysql才支持分區操作)
id重複的解決方案
- 借用第三方應用如
memcache、redis的id自增器 - 單獨建一張只包含
id一個字段的表,每次自增該字段作為數據記錄的id
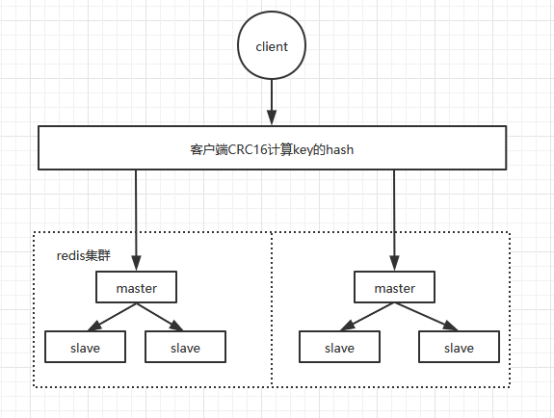
集群
- 橫向擴展:從根本上(單機的硬件處理能力有限)提升數據庫性能 。由此而生的相關技術:==讀寫分離、負載均衡==
安裝和配置主從複製
- 環境
Red Hat Enterprise Linux Server release 7.0 (Maipo)(虛擬機)mysql5.7(下載地址)
- 安裝和配置
- 解壓到對外提供的服務的目錄(我自己專門創建了一個
/export/server來存放)
- 解壓到對外提供的服務的目錄(我自己專門創建了一個
# tar xzvf mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz -C /export/server # cd /export/server # mv mysql-5.7.23-linux-glibc2.12-x86_64 mysql
- 添加
mysql目錄的所屬組和所屬者:
# groupadd mysql # useradd -r -g mysql mysql # cd /export/server # chown -R mysql:mysql mysql/ # chmod -R 755 mysql/
- 創建
mysql數據存放目錄(其中/export/data是我創建專門用來為各種服務存放數據的目錄)
# mkdir /export/data/mysql
- 初始化
mysql服務
# cd /export/server/mysql # ./bin/mysqld --basedir=/export/server/mysql --datadir=/export/data/mysql --user=mysql
--pid-file=/export/data/mysql/mysql.pid --initialize
- 如果成功會顯示
mysql的root賬戶的初始密碼,記下來以備後續登錄。如果報錯缺少依賴,則使用yum instally依次安裝即可
- 配置
my.cnf
vim /etc/my.cnf [mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 # 服務id,在集群時必須唯一,建議設置為IP的第四段 port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
- 將服務添加到開機自動啟動
# cp /export/server/mysql/support-files/mysql.server /etc/init.d/mysqld
- 啟動服務
# service mysqld start
- 配置環境變量,在
/etc/profile中添加如下內容
# mysql env MYSQL_HOME=/export/server/mysql MYSQL_PATH=$MYSQL_HOME/bin PATH=$PATH:$MYSQL_PATH export PATH
- 使配置即可生效
# source /etc/profile
- 使用
root登錄
mysql -uroot -p # 這裡填寫之前初始化服務時提供的密碼
- 登錄上去之後,更改
root賬戶密碼(我為了方便將密碼改為root),否則操作數據庫會報錯
set password=password('root'); flush privileges;
- 設置服務可被所有遠程客戶端訪問
use mysql; update user set host='%' where user='root'; flush privileges;
- 這樣就可以在宿主機使用
navicat遠程連接虛擬機linux上的mysql了
配置主從節點
- 配置master
- 以
linux(192.168.10.10)上的mysql為master,宿主機(192.168.10.1)上的mysql為slave配置主從複製。 - 修改
master的my.cnf如下
- 以
[mysqld] basedir=/export/server/mysql datadir=/export/data/mysql socket=/tmp/mysql.sock user=mysql server-id=10 port=3306 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd log-bin=mysql-bin # 開啟二進制日誌 expire-logs-days=7 # 設置日誌過期時間,避免佔滿磁盤 binlog-ignore-db=mysql # 不使用主從複製的數據庫 binlog-ignore-db=information_schema binlog-ignore-db=performation_schema binlog-ignore-db=sys binlog-do-db=test #使用主從複製的數據庫 [mysqld_safe] log-error=/export/data/mysql/error.log pid-file=/export/data/mysql/mysql.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
- 重啟
master
# service mysqld restart
- 登錄
master查看配置是否生效(ON即為開啟,默認為OFF):
mysql> show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
- 在
master的數據庫中建立備份賬號:backup為用戶名,%表示任何遠程地址,用戶back可以使用密碼1234通過任何遠程客戶端連接master
# grant replication slave on *.* to 'backup'@'%' identified by '1234'
- 查看
user表可以看到我們剛創建的用戶:
mysql> use mysql mysql> select user,authentication_string,host from user; +---------------+-------------------------------------------+-----------+ | user | authentication_string | host | +---------------+-------------------------------------------+-----------+ | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | % | | mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | localhost | | backup | *A4B6157319038724E3560894F7F932C8886EBFCF | % | +---------------+-------------------------------------------+-----------+
- 新建
test數據庫,創建一個article表以備後續測試
CREATE TABLE `article` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(64) DEFAULT NULL, `content` text, PRIMARY KEY (`id`) ) CHARSET=utf8;
- 重啟服務並刷新數據庫狀態到存儲文件中(
with read lock表示在此過程中,客戶端只能讀數據,以便獲得一個一致性的快照)
[root@zhenganwen ~]# service mysqld restart Shutting down MySQL.... SUCCESS! Starting MySQL. SUCCESS! [root@zhenganwen mysql]# mysql -uroot -proot mysql> flush tables with read lock; Query OK, 0 rows affected (0.00 sec)
- 查看
master上當前的二進制日誌和偏移量(記一下其中的File和Position)
mysql> show master status G *************************** 1. row *************************** File: mysql-bin.000002 Position: 154 Binlog_Do_DB: test Binlog_Ignore_DB: mysql,information_schema,performation_schema,sys Executed_Gtid_Set: 1 row in set (0.00 sec)
File表示實現複製功能的日誌,即上圖中的Binary log;Position則表示Binary log日誌文件的偏移量之後的都會同步到slave中,那麼在偏移量之前的則需要我們手動導入。- 主服務器上面的任何修改都會保存在二進制日誌Binary log裏面,從服務器上面啟動一個I/O thread(實際上就是一個主服務器的客戶端進程),連接到主服務器上面請求讀取二進制日誌,然後把讀取到的二進制日誌寫到本地的一個Realy log裏面。從服務器上面開啟一個SQL thread定時檢查Realy log,如果發現有更改立即把更改的內容在本機上面執行一遍。
- 如果一主多從的話,這時主庫既要負責寫又要負責為幾個從庫提供二進制日誌。此時可以稍做調整,將二進制日誌只給某一從,這一從再開啟二進制日誌並將自己的二進制日誌再發給其它從。或者是乾脆這個從不記錄只負責將二進制日誌轉發給其它從,這樣架構起來性能可能要好得多,而且數據之間的延時應該也稍微要好一些
- 手動導入,從
master中導出數據
# mysqldump -uroot -proot -hlocalhost test > /export/data/test.sql
- 將
test.sql中的內容在slave上執行一遍。
配置slave
- 修改
slave的my.ini文件中的[mysqld]部分
# log-bin=mysql # server-id=1 #192.168.10.1
- 保存修改後重啟
slave,WIN+R->services.msc->MySQL5.7->重新啟動 - 登錄
slave檢查log_bin是否以被開啟:
# show VARIABLES like 'log_bin';
- 配置與
master的同步複製:
stop slave; change master to master_host='192.168.10.10', # -- master的IP master_user='backup', # -- 之前在master上創建的用戶 master_password='1234', master_log_file='mysql-bin.000002', # -- master上 show master status G 提供的信息 master_log_pos=154;
- 啟用
slave節點並查看狀態
mysql> start slave; mysql> show slave status G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.10.10 Master_User: backup Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000002 Read_Master_Log_Pos: 154 Relay_Log_File: DESKTOP-KUBSPE0-relay-bin.000002 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 154 Relay_Log_Space: 537 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 10 Master_UUID: f68774b7-0b28-11e9-a925-000c290abe05 Master_Info_File: C:ProgramDataMySQLMySQL Server 5.7Datamaster.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec)
- 注意查看第4、14、15三行,若與我一致,表示
slave配置成功
測試
- 關閉
master的讀取鎖定
# mysql> unlock tables; # Query OK, 0 rows affected (0.00 sec)
- 向
master中插入一條數據
# mysql> use test # mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)'); # Query OK, 1 row affected (0.00 sec)
- 查看
slave是否自動同步了數據
# mysql> insert into article (title,content) values ('mysql master and slave','record the cluster building succeed!:)'); # Query OK, 1 row affected (0.00 sec)
- 至此,主從複製的配置成功!:)
典型SQL
線上DDL
- DDL(Database Definition Language)是指數據庫表結構的定義(
create table)和維護(alter table)的語言。在線上執行DDL,在低於MySQL5.6版本時會導致全表被獨佔鎖定,此時表處於維護、不可操作狀態,這會導致該期間對該表的所有訪問無法響應。但是在MySQL5.6之後,支持Online DDL,大大縮短了鎖定時間。 - 優化技巧是採用的維護表結構的DDL(比如增加一列,或者增加一個索引),是==copy==策略。思路:創建一個滿足新結構的新表,將舊錶數據==逐條==導入(複製)到新表中,以保證==一次性鎖定的內容少==(鎖定的是正在導入的數據),同時舊錶上可以執行其他任務。導入的過程中,將對舊錶的所有操作以日誌的形式記錄下來,導入完畢後,將更新日誌在新表上再執行一遍(確保一致性)。最後,新表替換舊錶(在應用程序中完成,或者是數據庫的rename,視圖完成)。
- 但隨着MySQL的升級,這個問題幾乎淡化了。
數據庫導入語句
- 在恢複數據時,可能會導入大量的數據。此時為了快速導入,需要掌握一些技巧:
- 導入時==先禁用索引和約束==:
# alter table table-name disable keys
- 待數據導入完成之後,再開啟索引和約束,一次性創建索引
# alter table table-name enable keys
- 數據庫如果使用的引擎是
Innodb,那麼它==默認會給每條寫指令加上事務==(這也會消耗一定的時間),因此建議先手動開啟事務,再執行一定量的批量導入,最後手動提交事務。 - 如果批量導入的SQL指令格式相同只是數據不同,那麼你應該先
prepare==預編譯==一下,這樣也能節省很多重複編譯的時間。
limit offset,rows
- 盡量保證不要出現大的
offset,比如limit 10000,10相當於對已查詢出來的行數棄掉前10000行後再取10行,完全可以加一些條件過濾一下(完成篩選),而不應該使用limit跳過已查詢到的數據。這是一個==offset做無用功==的問題。對應實際工程中,要避免出現大頁碼的情況,盡量引導用戶做條件過濾。
select * 要少用
- 即盡量選擇自己需要的字段
select,但這個影響不是很大,因為網絡傳輸多了幾十上百位元組也沒多少延時,並且現在流行的ORM框架都是用的select *,只是我們在設計表的時候注意將大數據量的字段分離,比如商品詳情可以單獨抽離出一張商品詳情表,這樣在查看商品簡略頁面時的加載速度就不會有影響了。
order by rand()不要用
- 它的邏輯就是隨機排序(為每條數據生成一個隨機數,然後根據隨機數大小進行排序)。如
select * from student order by rand() limit 5的執行效率就很低,因為它為表中的每條數據都生成隨機數並進行排序,而我們只要前5條。 - 解決思路:在應用程序中,將隨機的主鍵生成好,去數據庫中利用主鍵檢索。
單表和多表查詢
- 多表查詢:
join、子查詢都是涉及到多表的查詢。如果你使用explain分析執行計劃你會發現多表查詢也是一個表一個表的處理,最後合併結果。因此可以說單表查詢將計算壓力放在了應用程序上,而多表查詢將計算壓力放在了數據庫上。 - 現在有ORM框架幫我們解決了單表查詢帶來的對象映射問題(查詢單表時,如果發現有外鍵自動再去查詢關聯表,是一個表一個表查的)。
count(*)
- 在
MyISAM存儲引擎中,會自動記錄表的行數,因此使用count(*)能夠快速返回。而Innodb內部沒有這樣一個計數器,需要我們手動統計記錄數量,解決思路就是單獨使用一張表:
|
id |
table |
count |
|---|---|---|
| 1 | student | 100 |
limit 1
- 如果可以確定僅僅檢索一條,建議加上
limit 1,其實ORM框架幫我們做到了這一點(查詢單條的操作都會自動加上limit 1)。
慢查詢日誌
- 用於記錄執行時間超過某個臨界值的SQL日誌,用於快速定位慢查詢,為我們的優化做參考。
開啟慢查詢日誌
- 配置項:
slow_query_log - 可以使用
show variables like ‘slov_query_log’查看是否開啟,如果狀態值為OFF,可以使用set GLOBAL slow_query_log = on來開啟,它會在datadir下產生一個xxx-slow.log的文件。
設置臨界時間
- 配置項:
long_query_time - 查看:
show VARIABLES like 'long_query_time',單位秒 - 設置:
set long_query_time=0.5 - 實操時應該從長時間設置到短的時間,即將最慢的SQL優化掉
查看日誌
- 一旦SQL超過了我們設置的臨界時間就會被記錄到
xxx-slow.log中
profile信息
- 配置項:
profiling
開啟profile
set profiling=on- 開啟後,所有的SQL執行的詳細信息都會被自動記錄下來
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | OFF | +---------------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> set profiling=on; Query OK, 0 rows affected, 1 warning (0.00 sec)
查看profile信息
show profiles
mysql> show variables like 'profiling'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | profiling | ON | +---------------+-------+ 1 row in set, 1 warning (0.00 sec) mysql> insert into article values (null,'test profile',':)'); Query OK, 1 row affected (0.15 sec) mysql> show profiles; +----------+------------+-------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------+ | 1 | 0.00086150 | show variables like 'profiling' | | 2 | 0.15027550 | insert into article values (null,'test profile',':)') | +----------+------------+-------------------------------------------------------+
通過Query_ID查看某條SQL所有詳細步驟的時間
show profile for query Query_ID- 上面
show profiles的結果中,每個SQL有一個Query_ID,可以通過它查看執行該SQL經過了哪些步驟,各消耗了多場時間
典型的服務器配置
- 以下的配置全都取決於實際的運行環境
-
max_connections,最大客戶端連接數mysql> show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+
-
table_open_cache,表文件句柄緩存(表數據是存儲在磁盤上的,緩存磁盤文件的句柄方便打開文件讀取數據)mysql> show variables like 'table_open_cache'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | table_open_cache | 2000 | +------------------+-------+
-
key_buffer_size,索引緩存大小(將從磁盤上讀取的索引緩存到內存,可以設置大一些,有利於快速檢索)mysql> show variables like 'key_buffer_size'; +-----------------+---------+ | Variable_name | Value | +-----------------+---------+ | key_buffer_size | 8388608 | +-----------------+---------+
-
innodb_buffer_pool_size,Innodb存儲引擎緩存池大小(對於Innodb來說最重要的一個配置,如果所有的表用的都是Innodb,那麼甚至建議將該值設置到物理內存的80%,Innodb的很多性能提升如索引都是依靠這個)mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+---------+ | Variable_name | Value | +-------------------------+---------+ | innodb_buffer_pool_size | 8388608 | +-------------------------+---------+
-
innodb_file_per_table(innodb中,表數據存放在.ibd文件中,如果將該配置項設置為ON,那麼一個表對應一個ibd文件,否則所有innodb共享表空間) - 壓測工具mysqlslap
- 安裝MySQL時附帶了一個壓力測試工具
mysqlslap(位於bin目錄下)
自動生成sql測試
C:Userszaw>mysqlslap --auto-generate-sql -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 1.219 seconds Minimum number of seconds to run all queries: 1.219 seconds Maximum number of seconds to run all queries: 1.219 seconds Number of clients running queries: 1 Average number of queries per client: 0
並發測試
C:Userszaw>mysqlslap --auto-generate-sql --concurrency=100 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 3.578 seconds Minimum number of seconds to run all queries: 3.578 seconds Maximum number of seconds to run all queries: 3.578 seconds Number of clients running queries: 100 Average number of queries per client: 0 C:Userszaw>mysqlslap --auto-generate-sql --concurrency=150 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 5.718 seconds Minimum number of seconds to run all queries: 5.718 seconds Maximum number of seconds to run all queries: 5.718 seconds Number of clients running queries: 150 Average number of queries per client: 0
多輪測試
C:Userszaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=10 -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Average number of seconds to run all queries: 5.398 seconds Minimum number of seconds to run all queries: 4.313 seconds Maximum number of seconds to run all queries: 6.265 seconds Number of clients running queries: 150 Average number of queries per client: 0
存儲引擎測試
C:Userszaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=innodb -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine innodb Average number of seconds to run all queries: 5.911 seconds Minimum number of seconds to run all queries: 5.485 seconds Maximum number of seconds to run all queries: 6.703 seconds Number of clients running queries: 150 Average number of queries per client: 0
C:Userszaw>mysqlslap --auto-generate-sql --concurrency=150 --iterations=3 --engine=myisam -uroot -proot mysqlslap: [Warning] Using a password on the command line interface can be insecure. Benchmark Running for engine myisam Average number of seconds to run all queries: 53.104 seconds Minimum number of seconds to run all queries: 46.843 seconds Maximum number of seconds to run all queries: 60.781 seconds Number of clients running queries: 150 Average number of queries per client: 0
讀寫分離
- 讀寫分離是依賴於主從複製,而主從複製又是為讀寫分離服務的。因為主從複製要求
slave不能寫只能讀(如果對slave執行寫操作,那麼show slave status將會呈現Slave_SQL_Running=NO,此時你需要按照前面提到的手動同步一下slave)。 - 方案一、定義兩種連接
- 就像我們在學JDBC時定義的
DataBase一樣,我們可以抽取出ReadDataBase,WriteDataBase implements DataBase,但是這種方式無法利用優秀的線程池技術如DruidDataSource幫我們管理連接,也無法利用Spring AOP讓連接對DAO層透明。
- 就像我們在學JDBC時定義的
-
方案二、使用Spring AOP
- 如果能夠使用
Spring AOP解決數據源切換的問題,那麼就可以和Mybatis、Druid整合到一起了。 - 我們在整合
Spring1和Mybatis時,我們只需寫DAO接口和對應的SQL語句,那麼DAO實例是由誰創建的呢?實際上就是Spring幫我們創建的,它通過我們注入的數據源,幫我們完成從中獲取數據庫連接、使用連接執行SQL語句的過程以及最後歸還連接給數據源的過程。 - 如果我們能在調用DAO接口時根據接口方法命名規範(增
addXXX/createXXX、刪deleteXX/removeXXX、改updateXXXX、查selectXX/findXXX/getXX/queryXXX)動態地選擇數據源(讀數據源對應連接master而寫數據源對應連接slave),那麼就可以做到讀寫分離了。
- 如果能夠使用
項目結構
- 引入依賴
- 其中,為了方便訪問數據庫引入了
mybatis和druid,實現數據源動態切換主要依賴spring-aop和spring-aspects
- 其中,為了方便訪問數據庫引入了


<dependencies> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.6</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-core</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aop</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.6</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>6.0.2</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aspects</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.22</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>5.0.8.RELEASE</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
引入依賴
-
數據類
package top.zhenganwen.mysqloptimize.entity; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor public class Article { private int id; private String title; private String content; }
-
spring配置文件
- 其中
RoutingDataSourceImpl是實現動態切換功能的核心類,稍後介紹。
- 其中
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <context:property-placeholder location="db.properties"></context:property-placeholder> <context:component-scan base-package="top.zhenganwen.mysqloptimize"/> <bean id="slaveDataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="${db.driverClass}"/> <property name="url" value="${master.db.url}"></property> <property name="username" value="${master.db.username}"></property> <property name="password" value="${master.db.password}"></property> </bean> <bean id="masterDataSource" class="com.alibaba.druid.pool.DruidDataSource"> <property name="driverClassName" value="${db.driverClass}"/> <property name="url" value="${slave.db.url}"></property> <property name="username" value="${slave.db.username}"></property> <property name="password" value="${slave.db.password}"></property> </bean> <bean id="dataSourceRouting" class="top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl"> <property name="defaultTargetDataSource" ref="masterDataSource"></property> <property name="targetDataSources"> <map key-type="java.lang.String" value-type="javax.sql.DataSource"> <entry key="read" value-ref="slaveDataSource"/> <entry key="write" value-ref="masterDataSource"/> </map> </property> <property name="methodType"> <map key-type="java.lang.String" value-type="java.lang.String"> <entry key="read" value="query,find,select,get,load,"></entry> <entry key="write" value="update,add,create,delete,remove,modify"/> </map> </property> </bean> <!-- Mybatis文件 --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="configLocation" value="classpath:mybatis-config.xml" /> <property name="dataSource" ref="dataSourceRouting" /> <property name="mapperLocations" value="mapper/*.xml"/> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="top.zhenganwen.mysqloptimize.mapper" /> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" /> </bean> </beans>
spring配置文件
dp.properties
master.db.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC master.db.username=root master.db.password=root slave.db.url=jdbc:mysql://192.168.10.10:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC slave.db.username=root slave.db.password=root db.driverClass=com.mysql.jdbc.Driver
dp.properties
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <typeAliases> <typeAlias type="top.zhenganwen.mysqloptimize.entity.Article" alias="Article"/> </typeAliases> </configuration>
mybatis-config.xml
mapper接口和配置文件
ArticleMapper.java
package top.zhenganwen.mysqloptimize.mapper; import org.springframework.stereotype.Repository; import top.zhenganwen.mysqloptimize.entity.Article; import java.util.List; @Repository public interface ArticleMapper { List<Article> findAll(); void add(Article article); void delete(int id); }
ArticleMapper.java
ArticleMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="top.zhenganwen.mysqloptimize.mapper.ArticleMapper"> <select id="findAll" resultType="Article"> select * from article </select> <insert id="add" parameterType="Article"> insert into article (title,content) values (#{title},#{content}) </insert> <delete id="delete" parameterType="int"> delete from article where id=#{id} </delete> </mapper>
ArticleMapper.xml
核心類
-
RoutingDataSourceImpl
package top.zhenganwen.mysqloptimize.dataSource; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; import java.util.*; /** * RoutingDataSourceImpl class * 數據源路由 * * @author zhenganwen, blog:zhenganwen.top * @date 2018/12/29 */ public class RoutingDataSourceImpl extends AbstractRoutingDataSource { /** * key為read或write * value為DAO方法的前綴 * 什麼前綴開頭的方法使用讀數據員,什麼開頭的方法使用寫數據源 */ public static final Map<String, List<String>> METHOD_TYPE_MAP = new HashMap<String, List<String>>(); /** * 由我們指定數據源的id,由Spring切換數據源 * * @return */ @Override protected Object determineCurrentLookupKey() { System.out.println("數據源為:"+DataSourceHandler.getDataSource()); return DataSourceHandler.getDataSource(); } public void setMethodType(Map<String, String> map) { for (String type : map.keySet()) { String methodPrefixList = map.get(type); if (methodPrefixList != null) { METHOD_TYPE_MAP.put(type, Arrays.asList(methodPrefixList.split(","))); } } } }
RoutingDataSourceImpl
- 它的主要功能是,本來我們只配置一個數據源,因此
Spring動態代理DAO接口時直接使用該數據源,現在我們有了讀、寫兩個數據源,我們需要加入一些自己的邏輯來告訴調用哪個接口使用哪個數據源(讀數據的接口使用slave,寫數據的接口使用master。這個告訴Spring該使用哪個數據源的類就是AbstractRoutingDataSource,必須重寫的方法determineCurrentLookupKey返回數據源的標識,結合spring配置文件(下段代碼的5,6兩行)
<bean id="dataSourceRouting" class="top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl"> <property name="defaultTargetDataSource" ref="masterDataSource"></property> <property name="targetDataSources"> <map key-type="java.lang.String" value-type="javax.sql.DataSource"> <entry key="read" value-ref="slaveDataSource"/> <entry key="write" value-ref="masterDataSource"/> </map> </property> <property name="methodType"> <map key-type="java.lang.String" value-type="java.lang.String"> <entry key="read" value="query,find,select,get,load,"></entry> <entry key="write" value="update,add,create,delete,remove,modify"/> </map> </property> </bean>
結合spring配置文件
- 如果
determineCurrentLookupKey返回read那麼使用slaveDataSource,如果返回write就使用masterDataSource。 -
DataSourceHandler
package top.zhenganwen.mysqloptimize.dataSource; /** * DataSourceHandler class * <p> * 將數據源與線程綁定,需要時根據線程獲取 * * @author zhenganwen, blog:zhenganwen.top * @date 2018/12/29 */ public class DataSourceHandler { /** * 綁定的是read或write,表示使用讀或寫數據源 */ private static final ThreadLocal<String> holder = new ThreadLocal<String>(); public static void setDataSource(String dataSource) { System.out.println(Thread.currentThread().getName()+"設置了數據源類型"); holder.set(dataSource); } public static String getDataSource() { System.out.println(Thread.currentThread().getName()+"獲取了數據源類型"); return holder.get(); } }
DataSourceHandler
-
DataSourceAspect
package top.zhenganwen.mysqloptimize.dataSource; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.aspectj.lang.annotation.Pointcut; import org.springframework.context.annotation.EnableAspectJAutoProxy; import org.springframework.stereotype.Component; import java.util.List; import java.util.Set; import static top.zhenganwen.mysqloptimize.dataSource.RoutingDataSourceImpl.METHOD_TYPE_MAP; /** * DataSourceAspect class * * 配置切面,根據方法前綴設置讀、寫數據源 * 項目啟動時會加載該bean,並按照配置的切面(哪些切入點、如何增強)確定動態代理邏輯 * @author zhenganwen,blog:zhenganwen.top * @date 2018/12/29 */ @Component //聲明這是一個切面,這樣Spring才會做相應的配置,否則只會當做簡單的bean注入 @Aspect @EnableAspectJAutoProxy public class DataSourceAspect { /** * 配置切入點:DAO包下的所有類的所有方法 */ @Pointcut("execution(* top.zhenganwen.mysqloptimize.mapper.*.*(..))") public void aspect() { } /** * 配置前置增強,對象是aspect()方法上配置的切入點 */ @Before("aspect()") public void before(JoinPoint point) { String className = point.getTarget().getClass().getName(); String invokedMethod = point.getSignature().getName(); System.out.println("對 "+className+"$"+invokedMethod+" 做了前置增強,確定了要使用的數據源類型"); Set<String> dataSourceType = METHOD_TYPE_MAP.keySet(); for (String type : dataSourceType) { List<String> prefixList = METHOD_TYPE_MAP.get(type); for (String prefix : prefixList) { if (invokedMethod.startsWith(prefix)) { DataSourceHandler.setDataSource(type); System.out.println("數據源為:"+type); return; } } } } }
DataSourceAspect
- 測試讀寫分離
- 如何測試讀是從
slave中讀的呢?可以將寫後複製到slave中的數據更改,再讀該數據就知道是從slave中讀了。==注意==,一但對slave做了寫操作就要重新手動將slave與master同步一下,否則主從複製就會失效。
- 如何測試讀是從
package top.zhenganwen.mysqloptimize.dataSource; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; import top.zhenganwen.mysqloptimize.entity.Article; import top.zhenganwen.mysqloptimize.mapper.ArticleMapper; (SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:spring-mybatis.xml") public class RoutingDataSourceTest { ArticleMapper articleMapper; public void testRead() { System.out.println(articleMapper.findAll()); } public void testAdd() { Article article = new Article(0, "我是新插入的文章", "測試是否能夠寫到master並且複製到slave中"); articleMapper.add(article); } public void testDelete() { articleMapper.delete(2); } }
測試讀寫分離
負載均衡
負載均衡算法
- 輪詢
- 加權輪詢:按照處理能力來加權
- 負載分配:依據當前的空閑狀態(但是測試每個節點的內存使用率、CPU利用率等,再做比較選出最閑的那個,效率太低)
高可用
- 在服務器架構時,為了保證服務器7×24不宕機在線狀態,需要為每台單點服務器(由一台服務器提供服務的服務器,如寫服務器、數據庫中間件)提供冗餘機。
- 對於寫服務器來說,需要提供一台同樣的寫-冗餘服務器,當寫服務器健康時(寫-冗餘通過心跳檢測),寫-冗餘作為一個從機的角色複製寫服務器的內容與其做一個同步;當寫服務器宕機時,寫-冗餘服務器便頂上來作為寫服務器繼續提供服務。對外界來說這個處理過程是透明的,即外界僅通過一個IP訪問服務。
詳細流程圖