訓練網絡像是買彩票?神經網絡剪枝最新進展之彩票假設解讀
- 2019 年 10 月 5 日
- 筆記
機器之心原創
作者:朱梓豪
編輯:Haojin Yang
神經網絡剪枝技術可以極大的減少網絡的參數,並降低存儲要求,和提高推理的計算性能。而且目前這方面最好的方法通常能保持很高的準確性。因此對通過修剪產生的稀疏架構的研究是一個很重要的方向。本選題的思路是對以下兩篇論文做深度解讀,一探當今最好的剪枝方法的究竟。
深度神經網絡已經在計算機視覺領域取得了巨大的成功,如 AlexNet、VGG 等。這些模型動輒就有上億的參數,傳統的 CPU 對如此龐大的網絡一籌莫展,只有具有高計算能力的 GPU 才能相對快速的訓練神經網絡。如 2012 年 ImageNet 比賽中奪冠的 AlexNet 模型使用了 5 個卷積層和 3 個全連接層的 6000 萬參數的網絡,即使使用當時頂級的 K40 來訓練整個模型,仍需要花費兩到三天時間。卷積層的出現解決了全連接層的參數規模問題,但疊加若干個卷積層後,模型的訓練開銷仍然很大。
現在有了性能更強的 GPU,計算一個更深的神經網絡、參數更多的神經網絡根本不成問題。但事實上並不是每個人都是人手幾張卡的,對於具有更多層和節點的神經網絡,減少其存儲和計算成本變得至關重要。並且,隨着移動設備和可穿戴設備的普及,如何讓這些模型在計算能力並不強的移動端也能很好地應用,也成為亟待解決的問題。因此越來越多的研究者開始研究神經網絡模型壓縮。
綜合現有的模型壓縮方法,它們主要分為四類:參數剪枝和共享(parameter pruning and sharing)、低秩分解(low-rank factorization)、轉移和緊湊卷積核(transferred/compact convolutional filters)、知識蒸餾(knowledge distillation)[1]。
本篇文章主要解讀神經網絡剪枝方面的兩篇論文,第一篇《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》是 MIT 團隊發表在 ICLR'19 上的,提出了彩票假設:密集、隨機初始化的前饋網絡包含子網絡(「中獎彩票」),當獨立訓練時,這些子網絡能夠在相似的迭代次數內達到與原始網絡相當的測試準確率,此文榮獲了最佳論文獎。第二篇《Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask》是 Uber AI 團隊對彩票假設的深度解構。
論文1:The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks


原文鏈接:https://arxiv.org/abs/1803.03635
介紹
訓練機器學習模型是數據科學領域計算成本最高的方面之一。數十年來,研究人員已經提出上百種方法來改進機器學習模型的訓練過程,這些方法都基於一個公理假設,即訓練應該覆蓋整個模型。最近,來自 MIT 的研究人員發表了一篇論文來挑戰這一假設,提出了一種更簡單的通過關注子網絡來訓練神經網絡的方法,MIT 研究員起了一個很容易記住的名字——「彩票假設」(Lottery Ticker Hypothesis)。
機器學習的訓練過程,是數據科學家在理論與現實之間面臨的妥協之一。通常情況下,對於特定問題而言,由於訓練成本的限制,理想的神經網絡架構不能完全實現。一般而言,神經網絡最初的訓練需要大量的數據集和昂貴的計算成本,其結果得到一個隱藏層之間充滿複雜連接的龐大的神經網絡結構。這種結構往往需要經過優化技術,移除某些連接來調整模型的大小。數十年來困擾研究者的一個問題是我們是否真的需要這樣的龐大的神經網絡結構。很明顯,如果我們連接網絡中的每個神經元,可以解決特定的問題,但可能因為高昂的成本而被迫止步。難道我們不能從更小、更精簡的網絡開始訓練嗎?這就是彩票假設的本質。
以博彩來類比,訓練機器學習模型就相當於通過購買每一張可能的彩票來獲得中獎彩票。但是如果我們知道中獎彩票長什麼樣子,那麼是不是就可以更聰明地來選擇彩票?在機器學習模型中,訓練過程得到的巨大的神經網絡結構相當於一大袋彩票。在初始訓練之後,模型需要進行優化,例如剪枝,刪除網絡中不必要的權重,從而在不犧牲性能的情況下減小模型的大小。這就相當於在袋子中尋找中獎彩票,然後扔掉剩下的彩票。通常情況下,經過剪枝後的網絡結構要比原始的小 90% 左右。那麼問題來了,如果網絡結構可以縮小,那麼為了提高訓練效率為什麼不一開始就訓練這個更小的網絡呢?然而,已經有許多實驗證明了,如果從頭開始訓練剪枝後的網絡,得到的準確率要比原始網絡低很多。
MIT 的彩票假設背後的思想是,一個大型的神經網絡包含一個小的子網絡,如果一開始就訓練,那麼會得到和原始網絡相似的準確率。
彩票假設
文章中對彩票假設的正式定義為:一個隨機初始化的密集神經網絡包含一個初始化的子網絡,在單獨訓練時,最多經過相同的迭代次數,可以達到和原始網絡一樣的測試準確率。
我們將一個複雜網絡的所有參數當做獎池,上述一組子參數對應的子網絡就是中獎彩票。
更正式的,考慮一個密集的前饋神經網絡 f(x;θ),其中初始化參數 θ=θ_0~D_θ,當在訓練集上用隨機梯度下降時,f 可以在 j 次迭代後達到損失 l 和準確率 a。此外,考慮對參數θ作用一個 01 掩模 m∈{0,1}^|θ|,在相同的數據集上訓練 f(x;m⊙θ), f 在 j' 次迭代後達到損失 l' 和準確率 a'。彩票假設指出存在 m, 使得 j』<=j (訓練時間更快), a』>=a (準確率更高), ||m||_0 << |θ| (更少的參數)。
如何找到中獎彩票
如果彩票假設是正確的,那麼下一個問題就是如何設計一種策略來找出中獎彩票。作者提出一種通過迭代找到中獎彩票的方法:
1. 隨機初始化一個複雜神經網絡
2. 訓練這個網絡 j 次直到收斂
3. 剪掉部分權重參數
4. 將剩下的子網絡用第 1 步的權重進行初始化,創建中獎彩票
5. 為了評估第 4 步得到的子網絡是否是中獎彩票,訓練子網絡,比較準確率
上述過程可以進行一次或者多次,在只有一次剪枝時,網絡訓練一次,p% 的權重被剪掉。論文中迭代進行 n 次剪枝,每一次剪掉 p^(1/n)% 的權重。


實驗分析
作者分別在針對 MNIST 的全連接神經網絡和針對 CIFAR10 的卷積神經網絡上做了大量實驗。這裡以 MNIST 實驗為例:

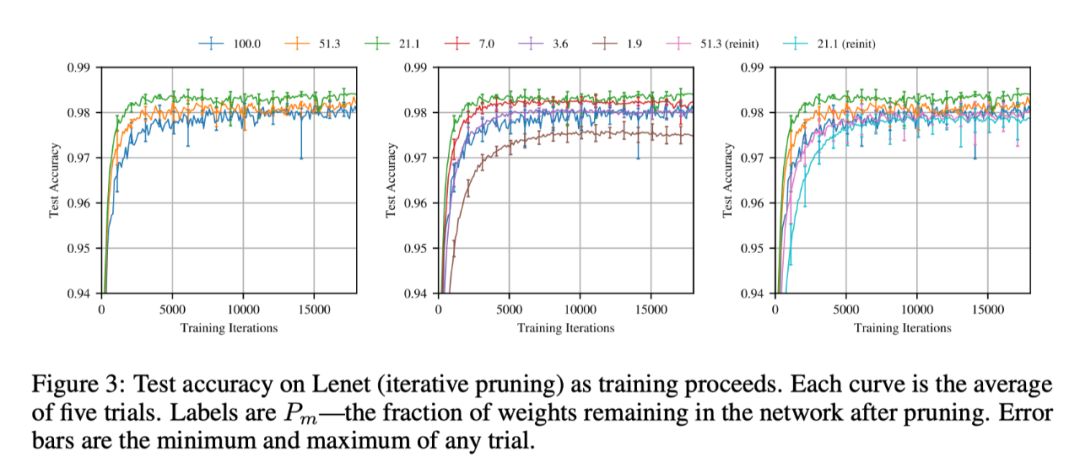
Pm 代表網絡還剩下多少的參數。從圖 3 可以觀察到,不同剪枝率的子網絡的性能不一樣,當 Pm>21.2% 時,Pm 越小,即剪枝的參數越多,準確率越高,當 Pm<21.1% 時,Pm 越小,準確率會下降。中獎彩票要比原始網絡收斂的更快,同時具有更高的準確率和泛化能力。


由圖 4 可以觀察到,迭代剪枝要比 oneshot 剪枝更快找到中獎彩票,而且在子網絡規模較小的情況下依然可以達到較高的準確率。為了衡量中獎彩票中初始化的重要性,作者保留了中獎彩票的結構然後使用隨機初始化重新訓練。與中獎彩票不同的是,重新初始化的網絡學習速度比原來的網絡越來越慢,並且在進行少量剪枝之後就會失去測試精度。
總結
本文中,作者提出了彩票假設並給出一種尋找中獎彩票的方法,通過迭代非結構化剪枝的方式可以找到一個子網絡,用原始網絡的初始化參數來初始化,可以在性能不下降的情況下更快的訓練這個子網絡,但是如果用隨機初始化方法卻達不到同樣的性能。
作者也在文章中指出這項工作存在的一些問題。例如,迭代剪枝的計算量太大,需要對一個網絡進行連續 15 次或 15 次以上的多次訓練。未來可以探索更加高效的尋找中獎彩票的方法。
論文2:Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask


原文鏈接:https://arxiv.org/abs/1905.01067
彩票假設回顧
Frankle 和 Carbin 在彩票假設(LT)論文中提出一種模型剪枝方法:對網絡訓練後,對所有小於某個閾值的權重置 0(即剪枝),然後將剩下的權重重置成原始網絡初始的權重,最後重新訓練網絡。基於這種方法,得到了兩個有趣的結果。
一方面經過大量剪枝的網絡(刪掉 85%-95% 的權重)與原網絡相比性能並沒有明顯的下降,而且,如果僅僅剪掉 50%-90% 的權重後的網絡性能往往還會高於原網絡。另一方面,對於訓練好的普通網絡,如果重新隨機初始化權重然後再訓練,得到的結果與之前的相當。而對於彩票假設的網絡並沒有這個特點,只有當網絡使用和原網絡一樣的初始化權重,才能很好地訓練,如果重新初始化會導致結果變差。剪枝掩模(如果刪掉權重置 0,否則為 1)和權重的特定組合構成了中獎彩票。
存在的問題
雖然上篇論文里證明了彩票假設是有效的,然而許多潛在的機制尚未得到很好的理解。例如:LT 網絡如何使他們表現出更好的性能?為什麼掩模和初始權重集如此緊密地耦合在一起,以至於重新初始化網絡會降低它的可訓練性?為什麼簡單地選擇大的權重構成了選擇掩模的有效標準?其他選擇掩模的標準也會起作用嗎?本篇論文提出了對這些機制的解釋,揭示了這些子網絡的特殊模式,引入了與彩票算法相抗衡的變體,並獲得了意外發現的衍生品:超級掩模(supermask)。
掩模準則
作者將每個權重的掩模值設為初始權值和訓練後的權值的函數 M(w_i,w_f),可以將這個函數可視化為二維空間中的一組決策邊界,如圖 1 所示。不同的掩碼標準可以認為是將二維 (wi =初始權值,wf =最終權值) 空間分割成掩碼值為 1 vs 0 的區域。


如圖所示的掩碼準則由兩條水平線標識,這兩條水平線將整個區域劃分為掩碼=1(藍色) 區域和掩碼=0(灰色) 區域,對應於上篇論文中使用的掩模準則:保留最終較大的權重,並剪掉接近於零的權重。作者將這種稱為 large_final mask, M(w_i,w_f)=|w_f|。作者還提出了另外 8 種掩模準則,對應的公式都在下圖表示出來了,保留橢圓中彩色部分的權重,將灰色部分的權重剪掉。


作者對這些掩模準則做了一系列對比試驗,對於全連接和 Conv4 網絡結果如下圖所示。可以發現,magnitude increase 和 large_final 相比不相上下,在 Conv4 網絡中還要表現的更好一些。


以隨機掩模為基線,我們可以發現那些傾向於保留具有較大最終值的權重的準則能更好的發現子網絡,而保留小權值的效果較差。
正負號的重要性
現在已經探索了對哪些權重進行減值效果較好。接下來的問題是該將保留下來的權重重置為何值。作者主要是想研究上篇論文中的一個有趣的結果,當重置為原網絡初值的時候效果很好,但當隨機初始化時,效果會變差。為什麼重新初始化效果會變差以及初始化的哪些條件最重要?為了找到問題的答案,作者做了一系列初始化的實驗。
- Reinit:基於原始的初始化分佈來初始化保留的權重
- Reshuffle:基於保留權重的原始分佈進行初始化
- Constant:將保留的權重設為正或負的常數,即每層原初始值的標準差


可以發現保留權重的初始值並沒有保留正負號這麼重要。如果使用其他的初始化方法,但是忽略正負號,那麼效果很差,和隨機初始化差不多(圖中虛線)。而如果和原來的權重保持一樣的正負號,三種方法和 LT 網絡的初始化效果相差無幾(圖中實線)。只要保持正負號一致,即使將剩下的權重都設為常量也不會影響網絡的表現。
超級掩模
在開頭提到了超級掩模的概念,它是一種二值掩模,當作用到隨機初始化的網絡上時,即使不重新訓練,也可以得到更高的準確率。下面介紹如何找到最佳的超級掩模。
基於上述對初始符號重要性的洞察以及讓權重更接近最終值的考慮,作者引入了一種新的掩模準則,選擇較大的權重,而且這些權重在訓練後也保持相同的正負號,作者將其稱為 large_final, same sign。並且用 large_final, diff sign 作為對照,兩者的區別如下圖所示。


通過使用這一掩模準則,可以在 MNIST 上取得 80% 的測試準確率,而上一篇文章 large_final 方法在最好的剪枝率下只有 30% 的準確率(注意這是在沒有進行重新訓練的情況下)。


總結
這篇文章對上一篇文章進行了深度的解釋。通過比較不同的掩模準則和初始化方案來回答為什麼彩票假設可以表現的很好。並且有意思的是提出了一種新的「超級掩模」,通過它可以在不重新訓練子網絡的情況下得到很高的準確率。這為我們提供了一種新的神經網絡壓縮方法,只需要保存掩模和隨機數種子就可以重構網絡的權重。
參考文獻
1. Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
2. Frankle, Jonathan, and Michael Carbin. "The lottery ticket hypothesis: Finding sparse, trainable neural networks." ICLR (2019).
3. Zhou, Hattie, et al. "Deconstructing lottery tickets: Zeros, signs, and the supermask." arXiv preprint arXiv:1905.01067(2019).
4. https://eng.uber.com/deconstructing-lottery-tickets/
5. https://towardsdatascience.com/how-the-lottery-ticket-hypothesis-is-challenging-everything-we-knew-about-training-neural-networks-e56da4b0da27
作者介紹:朱梓豪,目前是中國科學院信息工程研究所的碩士研究生,主要研究方向為圖神經網絡、多模態機器學習、視覺對話等方向。愛好科研,喜歡分享,希望能通過機器之心和大家一起學習交流。
本文為機器之心原創,轉載請聯繫本公眾號獲得授權。

