DataFrame簡介(一)
- 2020 年 3 月 16 日
- 筆記
1. DataFrame
本片將介紹Spark RDD的限制以及DataFrame(DF)如何克服這些限制,從如何創建DataFrame,到DF的各種特性,以及如何優化執行計劃。最後還會介紹DF有哪些限制。

2. 什麼是 Spark SQL DataFrame?
從Spark1.3.0版本開始,DF開始被定義為指定到列的數據集(Dataset)。DFS類似於關係型數據庫中的表或者像R/Python 中的data frame 。可以說是一個具有良好優化技術的關係表。DataFrame背後的思想是允許處理大量結構化數據。DataFrame包含帶schema的行。schema是數據結構的說明。
在Apache Spark 裏面DF 優於RDD,但也包含了RDD的特性。RDD和DataFrame的共同特徵是不可性、內存運行、彈性、分佈式計算能力。它允許用戶將結構強加到分佈式數據集合上。因此提供了更高層次的抽象。我們可以從不同的數據源構建DataFrame。例如結構化數據文件、Hive中的表、外部數據庫或現有的RDDs。DataFrame的應用程序編程接口(api)可以在各種語言中使用。示例包括Scala、Java、Python和R。在Scala和Java中,我們都將DataFrame表示為行數據集。在Scala API中,DataFrames是Dataset[Row]的類型別名。在Java API中,用戶使用數據集<Row>來表示數據流。
3. 為什麼要用 DataFrame?
DataFrame優於RDD,因為它提供了內存管理和優化的執行計劃。總結為一下兩點:
a.自定義內存管理:當數據以二進制格式存儲在堆外內存時,會節省大量內存。除此之外,沒有垃圾回收(GC)開銷。還避免了昂貴的Java序列化。因為數據是以二進制格式存儲的,並且內存的schema是已知的。
b.優化執行計劃:這也稱為查詢優化器。可以為查詢的執行創建一個優化的執行計劃。優化執行計劃完成後最終將在RDD上運行執行。
4. Apache Spark DataFrame 特性
Spark RDD 的限制-
- 沒有任何內置的優化引擎
- 不能處理結構化數據.
因此為了克服這些問題,DF的特性如下:
i. DataFrame是一個按指定列組織的分佈式數據集合。它相當於RDBMS中的表.
ii. 可以處理結構化和非結構化數據格式。例如Avro、CSV、彈性搜索和Cassandra。它還處理存儲系統HDFS、HIVE表、MySQL等。
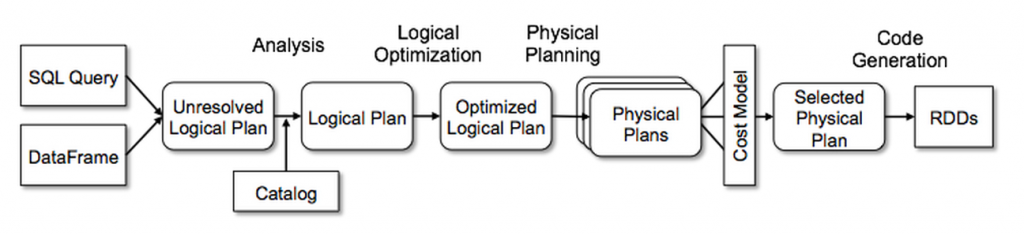
iii. Catalyst的通用樹轉換框架分為四個階段,如下所示:(1)分析解決引用的邏輯計劃,(2)邏輯計劃優化,(3)物理計劃,(4)代碼生成用於編譯部分查詢生成Java位元組碼。 在物理規劃階段,Catalyst可能會生成多個計劃並根據成本進行比較。 所有其他階段完全是基於規則的。 每個階段使用不同類型的樹節點; Catalyst包括用於表達式、數據類型以及邏輯和物理運算符的節點庫。 這些階段如下所示:
5. 創建DataFrames
對於所有的Spark功能,SparkSession類都是入口。所以創建基礎的SparkSession只需要使用:
SparkSession.builder()
使用Spark Session 時,應用程序能夠從現存的RDD裏面或者hive table 或者 Spark 數據源 裏面創建DataFrame。Spark SQL能對多種數據源使用DataFrame接口。使用SparkSQL DataFrame 可以創建臨時視圖,然後我們可以在視圖上運行sql查詢。
6. Spark中DataFrame的缺點
- Spark SQL DataFrame API 不支持編譯時類型安全,因此,如果結構未知,則不能操作數據
- 一旦將域對象轉換為Data frame ,則域對象不能重構。
7. 總結
綜上,DataFrame API能夠提高spark的性能和擴展性。避免了構造每行在dataset中的對象,造成GC的代價。不同於RDD API,能構建關係型查詢計劃。更加有有利於熟悉執行計劃的開發人員,同理不一定適用於所有人。


