反向傳播算法詳解
- 2020 年 3 月 14 日
- 筆記

作者:Great Learning Team
- 神經網絡
- 什麼是反向傳播?
- 反向傳播是如何工作的?
- 損失函數
- 為什麼我們需要反向傳播?
- 前饋網絡
- 反向傳播的類型
- 案例研究
在典型的編程中,我們輸入數據,執行處理邏輯並接收輸出。 如果輸出數據可以某種方式影響處理邏輯怎麼辦? 那就是反向傳播算法。 它對以前的模塊產生積極影響,以提高準確性和效率。
讓我們來深入研究一下。
神經網絡(Neural network)
神經網絡是連接單元的集合。每個連接都有一個與其相關聯的權重。該系統有助於建立基於海量數據集的預測模型。它像人類的神經系統一樣工作,有助於理解圖像,像人類一樣學習,合成語音等等。
什麼是反向傳播(What is backpropagation?)
我們可以將反向傳播算法定義為在已知分類的情況下,為給定的輸入模式訓練某些給定的前饋神經網絡的算法。當示例集的每一段都顯示給網絡時,網絡將查看其對示例輸入模式的輸出反應。之後,測量輸出響應與期望輸出與誤差值的比較。之後,我們根據測量的誤差值調整連接權重。
在深入研究反向傳播之前,我們應該知道是誰引入了這個概念以及何時引入。它最早出現在20世紀60年代,30年後由大衛·魯梅爾哈特、傑弗里·辛頓和羅納德·威廉姆斯在1986年的著名論文中推廣。在這篇論文中,他們談到了各種神經網絡。今天,反向傳播做得很好。神經網絡訓練是通過反向傳播實現的。通過這種方法,我們根據前一次運行獲得的錯誤率對神經網絡的權值進行微調。正確地採用這種方法可以降低錯誤率,提高模型的可靠性。利用反向傳播訓練鏈式法則的神經網絡。簡單地說,每次前饋通過網絡後,該算法根據權值和偏差進行後向傳遞,調整模型的參數。典型的監督學習算法試圖找到一個將輸入數據映射到正確輸出的函數。反向傳播與多層神經網絡一起工作,學習輸入到輸出映射的內部表示。
反向傳播是如何工作的?(How does backpropagation work?)
讓我們看看反向傳播是如何工作的。它有四層:輸入層、隱藏層、隱藏層II和最終輸出層。
所以,主要的三層是:
1.輸入層
2.隱藏層
3.輸出層
每一層都有自己的工作方式和響應的方式,這樣我們就可以獲得所需的結果並將這些情況與我們的狀況相關聯。 讓我們討論有助於總結此算法所需的其他細節。
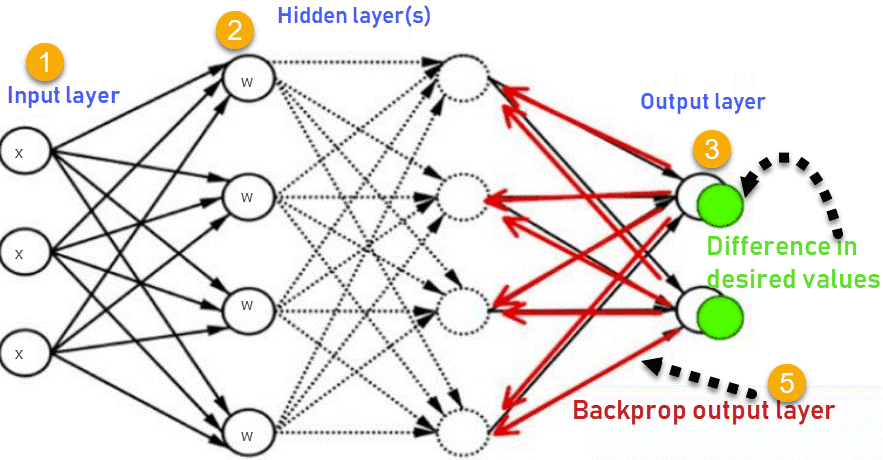
這張圖總結了反向傳播方法的機能。
1.輸入層接收x
2.使用權重w對輸入進行建模
3.每個隱藏層計算輸出,數據在輸出層準備就緒
4.實際輸出和期望輸出之間的差異稱為誤差
5.返回隱藏層並調整權重,以便在以後的運行中減少此錯誤
這個過程一直重複,直到我們得到所需的輸出。訓練階段在監督下完成。一旦模型穩定下來,就可以用於生產。
損失函數(Loss function)
一個或多個變量被映射到實數,這些實數表示與這些變量值相關的某個數值。為了進行反向傳播,損失函數計算網絡輸出與其可能輸出之間的差值。
為什麼我們需要反向傳播?(Why do we need backpropagation?)
反向傳播有許多優點,下面列出一些重要的優點:
•反向傳播快速、簡單且易於實現
•沒有要調整的參數
•不需要網絡的先驗知識,因此成為一種靈活的方法
•這種方法在大多數情況下都很有效
•模型不需要學習函數的特性
前饋網絡(Feed forward network)
前饋網絡也稱為MLN,即多層網絡。 之所以稱為前饋,是因為數據僅在NN(神經網絡)中通過輸入節點,隱藏層並最終到達輸出節點。 它是最簡單的人工神經網絡。
反向傳播的類型(Types of backpropagation)
有兩種類型的反向傳播網絡。
•靜態反向傳播(Static backpropagation)
•循環反向傳播(Recurrent backpropagation)
- 靜態反向傳播(Static backpropagation)
在這個網絡中,靜態輸入的映射生成靜態輸出。像光學字符識別這樣的靜態分類問題將是一個適合於靜態反向傳播的領域。
- 循環反向傳播(Recurrent backpropagation)
反覆進行反向傳播,直到達到某個閾值為止。 在到達閾值之後,將計算誤差並向後傳播。
這兩種方法的區別在於,靜態反向傳播與靜態映射一樣快。
案例研究(Case Study)
讓我們使用反向傳播進行案例研究。 為此,我們將使用Iris數據(鳶尾花卉數據集),該數據包含諸如萼片和花瓣的長度和寬度之類的特徵。 在這些幫助下,我們需要確定植物的種類。
為此,我們將構建一個多層神經網絡,並使用sigmoid函數,因為它是一個分類問題。
讓我們看一下所需的庫和數據。
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split為了忽略警告,我們將導入另一個名為warnings的庫。
import warnings warnings.simplefilter(action='ignore', category=FutureWarning)接着讓我們讀取數據。
iris = pd.read_csv("iris.csv") iris.head()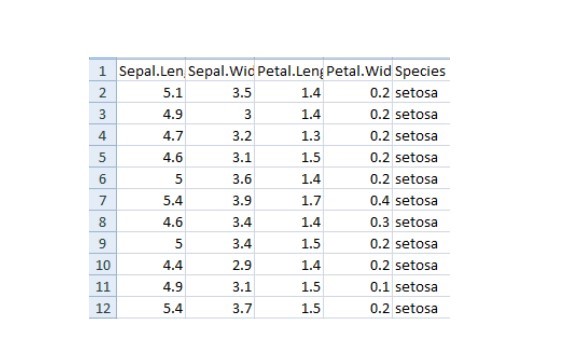
現在我們將把類標記為0、1和2。
iris. replace (, , inplace=True)我們現在將定義函數,它將執行以下操作。
1.對輸出執行獨熱編碼(one hot encoding)。
2.執行sigmoid函數
3.標準化特徵
對於獨熱編碼,我們定義以下函數。
def to_one_hot(Y): n_col = np.amax(Y) + 1 binarized = np.zeros((len(Y), n_col)) for i in range(len(Y)): binarized ] = 1. return binarized現在我們來定義一個sigmoid函數
def sigmoid_func(x): return 1/(1+np.exp(-x)) def sigmoid_derivative(x): return sigmoid_func(x)*(1 – sigmoid_func(x))現在我們將定義一個用於標準化的函數。
def normalize (X, axis=-1, order=2): l2 = np. atleast_1d (np.linalg.norm(X, order, axis)) l2 = 1 return X / np.expand_dims(l2, axis)現在我們將對特徵進行規範化,並對輸出應用獨熱編碼。
x = pd.DataFrame(iris, columns=columns) x = normalize(x.as_matrix()) y = pd.DataFrame(iris, columns=columns) y = y.as_matrix() y = y.flatten() y = to_one_hot(y)現在是時候應用反向傳播了。為此,我們需要定義權重和學習率。讓我們這麼做吧。但在那之前,我們需要把數據分開進行訓練和測試。
#Split data to training and validation data(將數據拆分為訓練和驗證數據) X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.33) #Weights w0 = 2*np.random.random((4, 5)) - 1 #for input - 4 inputs, 3 outputs w1 = 2*np.random.random((5, 3)) - 1 #for layer 1 - 5 inputs, 3 outputs #learning rate n = 0.1我們將為錯誤設置一個列表,並通過可視化查看訓練中的更改如何減少錯誤。
errors = []讓我們執行前饋和反向傳播網絡。對於反向傳播,我們將使用梯度下降算法。
for i in range (100000): #Feed forward network layer0 = X_train layer1 = sigmoid_func(np.dot(layer0, w0)) layer2 = sigmoid_func(np.dot(layer1, w1)) Back propagation using gradient descent layer2_error = y_train - layer2 layer2_delta = layer2_error * sigmoid_derivative(layer2) layer1_error = layer2_delta.dot (w1.T) layer1_delta = layer1_error * sigmoid_derivative(layer1) w1 += layer1.T.dot(layer2_delta) * n w0 += layer0.T.dot(layer1_delta) * n error = np.mean(np.abs(layer2_error)) errors.append(error)準確率將通過從訓練數據中減去誤差來收集和顯示
accuracy_training = (1 - error) * 100現在讓我們直觀地看一下如何通過減少誤差來提高準確度。(可視化)
plt.plot(errors) plt.xlabel('Training') plt.ylabel('Error') plt.show()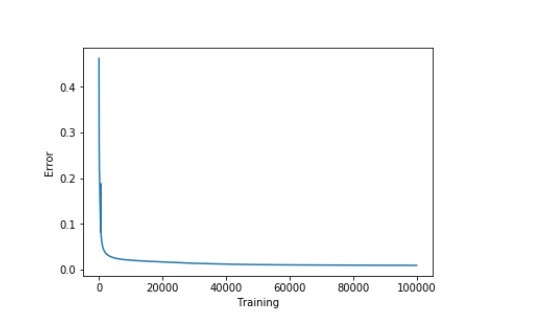
現在讓我們查看一下準確率。
print ("Training Accuracy of the model " + str (round(accuracy_training,2)) + "%")Output: Training Accuracy of the model 99.04%
我們的訓練模型表現很好。現在讓我們看看驗證的準確性。
#Validate layer0 = X_test layer1 = sigmoid_func(np.dot(layer0, w0)) layer2 = sigmoid_func(np.dot(layer1, w1)) layer2_error = y_test - layer2 error = np.mean(np.abs(layer2_error)) accuracy_validation = (1 - error) * 100 print ("Validation Accuracy of the model "+ str(round(accuracy_validation,2)) + "%")Output: Validation Accuracy 92.86%
這個性能符合預期。
應遵循的最佳實踐準則(Best practices to follow)
下面討論一些獲得好模型的方法:
•如果約束非常少,則系統可能不起作用
•過度訓練,過多的約束會導致過程緩慢
•只關注少數方面會導致偏見
反向傳播的缺點(Disadvantages of backpropagation)
•輸入數據是整體性能的關鍵
•有噪聲的數據會導致不準確的結果
•基於矩陣的方法優於小批量方法(mini-batch)
綜上所述,神經網絡是具有輸入和輸出機制的連接單元的集合,每個連接都有相關聯的權值。反向傳播是”誤差的反向傳播”,對訓練神經網絡很有用。它快速、易於實現且簡單。反向傳播對於處理語音或圖像識別等易出錯項目的深度神經網絡非常有益。

