Python進階練習與爬取豆瓣T250的影片相關信息
- 2020 年 3 月 12 日
- 筆記
(一)Python進階練習
正所謂要將知識進行實踐,才會真正的掌握
於是就練習了幾道題:求素數,求奇數,求九九乘法表,字符串練習


import re #求素數 i=1; flag=0 while(i<=100): flag=0 j=2; while(j<i): if(i%j==0): flag=1 break; j=j+1 if(flag==0): print(i,end=' ') i=i+1 #求奇數 for i in range(1,101): if(i%2==1): print(i,end=' ') #字符串練習 str="你好$$$我正在學 Python@#@#現在需要&*&*&修改字符串" k=str.replace('$$$','').replace('@#@#',' ').replace('&*&*&',' ') print(k) p=re.sub('[$@#&*]',' ',str) print(p) #九九乘法表 for i in range(1,10): for j in range(1,i+1): print("%d*%d=%dt" %(j,i,i*j),end="") print("")
View Code
(二)爬取靜態網頁
這次我們練習的實戰是爬取靜態網頁,豆瓣T250電影的名字
首先我們分析一頁有25個電影,我們想要250個,進行下一頁的時候他的鏈接地址變成“https://movie.douban.com/top250?start=25”同理每翻一頁就會增加25.我們就可以對這250個數據進行爬取了
我們要獲取的信息是:電影名字,導演與主演以及時間類型,豆瓣評分,多少人評價
將這些信息存入到txt裏面
import requests from bs4 import BeautifulSoup def get_movie(): url = 'https://movie.douban.com/top250' #請求地址 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#創建頭部信息 movie_list=[] for i in range(0,10): url = 'https://movie.douban.com/top250?start='+str(i*25) response=requests.get(url,headers=headers) soup=BeautifulSoup(response.text,"html.parser") div_list = soup.find_all('div', class_='info') for each in div_list: title = each.find('div', class_="hd").span.text.strip() info = each.find('div', class_='bd').p.text.strip() info = info.replace('\n', '').replace('\xa0', '') info = ' '.join(info.split()) star = each.find('span', class_='rating_num').text.strip() people = each.find('div', class_='star').contents[7].text.strip() movie_list.append([title, info, star, people]) return movie_list movie=[] movie=get_movie() with open("Top_movie_250.txt","a+",encoding="utf-8") as f: for i in range(len(movie)): f.write(str(movie[i])) f.write("n") f.close()
View Code
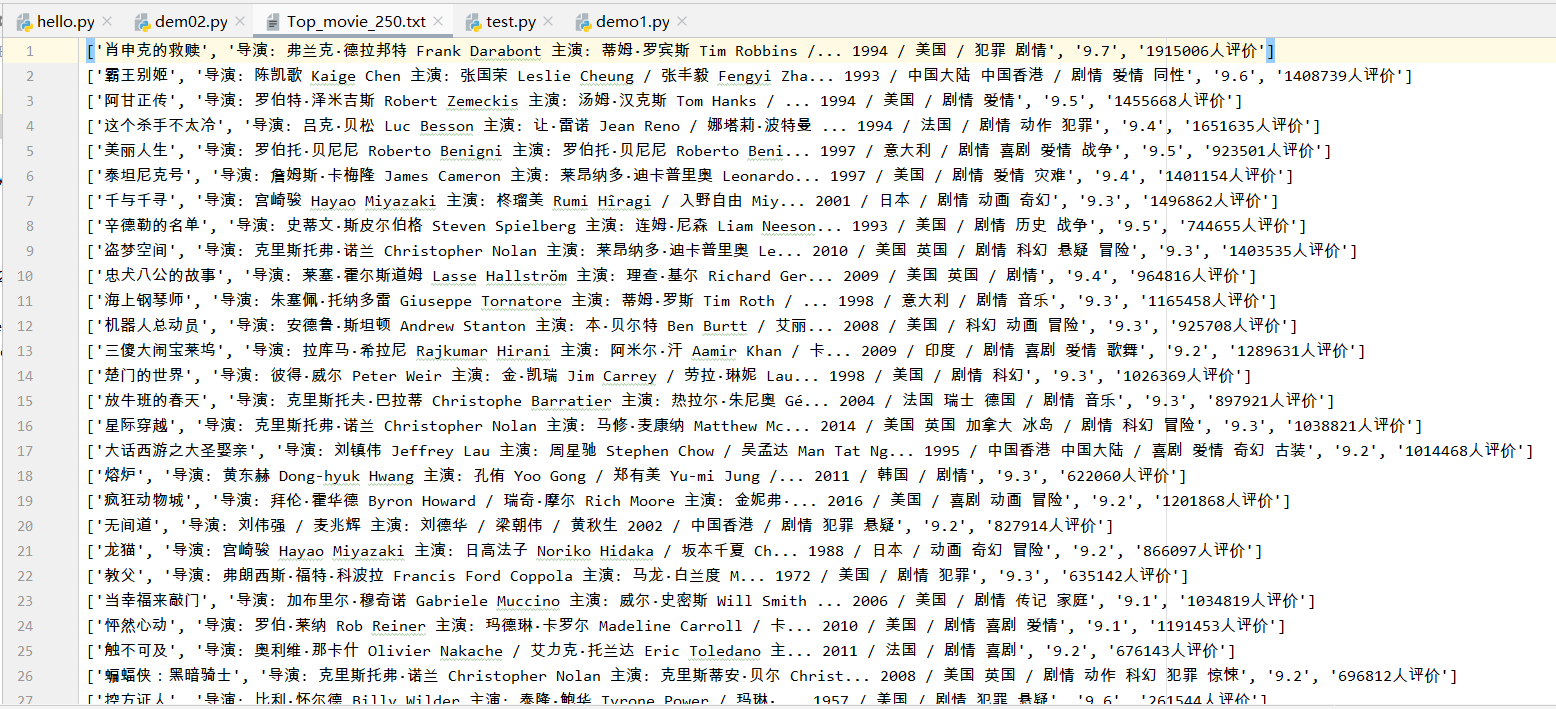
txt展示:
| 日期 | 開始時間 | 結束時間 | 中斷時間 | 凈時間 | 活動 |
| 3/12 | 20:30 | 21:45 | 0 | 75 | python練習與爬取T25的名字 |
| 3/12 | 22:00 | 22:30 | 5 | 25 | 爬取T250電影的名字,導演,評分等 |
總學習時長:100分鐘,凈代碼行數:90行


