Python 【基礎常識概念】
- 2020 年 3 月 12 日
- 筆記
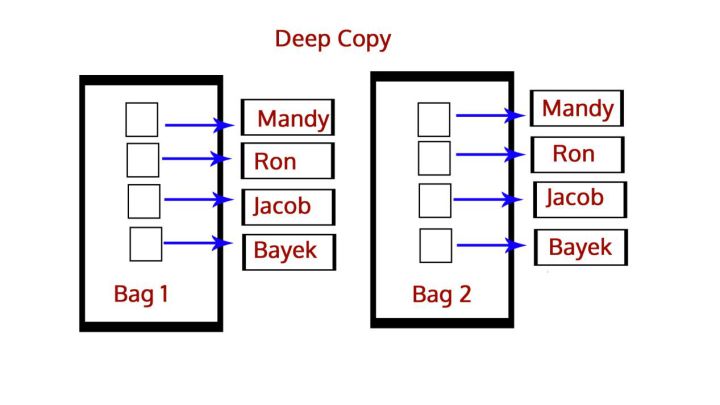
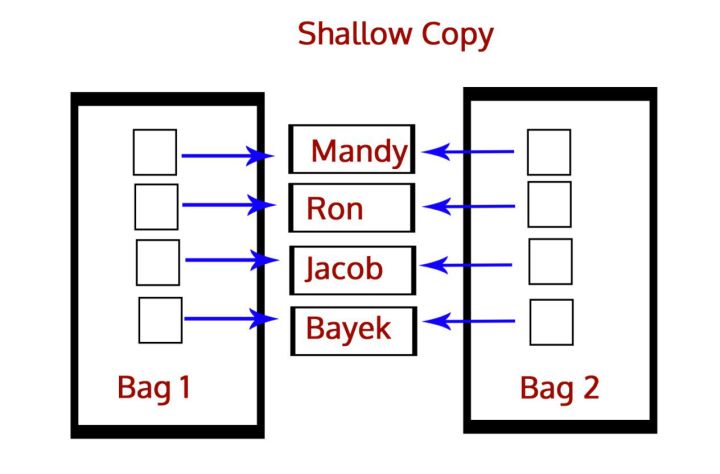
深淺拷貝
淺copy與deepcopy
-
- 淺copy: 不管多麼複雜的數據結構,淺拷貝都只會copy一層
- deepcopy : 深拷貝會完全複製原變量相關的所有數據,在內存中生成一套完全一樣的內容,我們對這兩個變量中任意一個修改都不會影響其他變量

深淺拷貝之間的區別?
- 對象的賦值就是簡單的引用,a = [1,2,3], b=a, 在上述情況下,a和b是一樣的,他們指向同一片內存,b不過是a的別名,是引用,我們可以使用b is a 去判斷,返回True,表名他們地址相同內容也相同,也可以使用id()函數來查看.看兩個列表地址是否相同.
- 深拷貝就是將一個對象拷貝到另一個對象中,這意味着如果你對一個對象的拷貝做出改變時,不會影響原對象。在Python中,我們使用函數deepcopy()執行深拷貝
import copy b=copy.deepcopy(a)
- 而淺拷貝則是將一個對象的引用拷貝到另一個對象上,所以如果我們在拷貝中改動,會影響到原對象。我們使用函數function()執行淺拷貝、切片操作是淺拷貝
b=copy.copy(a)
可變與不可變
- 可變類型(mutable):列表,字典
- 不可變類型(unmutable):數字,字符串,元組
- 這裡的可變不可變,是指內存中的那塊內容(value)是否可以被改變。如果是不可變類型,在對對象本身操作的時候,必須在內存中新申請一塊區域(因為老區域#不可變#)。如果是可變類型,對對象操作的時候,不需要再在其他地方申請內存,只需要在此對象後面連續申請(+/-)即可,也就是它的address會保持不變,但區域會變長或者變短。
copy.copy() # 淺拷貝 copy.deepcopy() # 深拷貝
- 淺拷貝是新創建了一個跟原對象一樣的類型,但是其內容是對原對象元素的引用。這個拷貝的對象本身是新的,但內容不是。拷貝序列類型對象(列表元組)時,默認是淺拷貝。
垃圾回收機制
引計數
- 原理
- 當一個對象的引用被創建或者複製時,對象的引用計數加1;當一個對象的引用被銷毀時,對象的引用計數減1.
- 當對象的引用計數減少為0時,就意味着對象已經再沒有被使用了,可以將其內存釋放掉。
- 優點
- 引用計數有一個很大的優點,即實時性,任何內存,一旦沒有指向它的引用,就會被立即回收,而其他的垃圾收集技術必須在某種特殊條件下才能進行無效內存的回收。
- 缺點
- 引用計數機制所帶來的維護引用計數的額外操作與Python運行中所進行的內存分配和釋放,引用賦值的次數是成正比的,
- 顯然比其它那些垃圾收集技術所帶來的額外操作只是與待回收的內存數量有關的效率要低。
- 同時,因為對象之間相互引用,每個對象的引用都不會為0,所以這些對象所佔用的內存始終都不會被釋放掉。
標記-清除
- 它分為兩個階段:第一階段是標記階段,GC會把所有的活動對象打上標記,第二階段是把那些沒有標記的對象非活動對象進行回收。
- 對象之間通過引用(指針)連在一起,構成一個有向圖
- 從根對象(root object)出發,沿着有向邊遍歷對象,可達的(reachable)對象標記為活動對象,不可達的對象就是要被清除的非活動對象。
- 根對象就是全局變量、調用棧、寄存器。

- 在上圖中,可以從程序變量直接訪問塊1,並且可以間接訪問塊2和3,程序無法訪問塊4和5
- 第一步將標記塊1,並記住塊2和3以供稍後處理。
- 第二步將標記塊2,第三步將標記塊3,但不記得塊2,因為它已被標記。
- 掃描階段將忽略塊1,2和3,因為它們已被標記,但會回收塊4和5。
分代回收
- 分代回收是建立在標記清除技術基礎之上的,是一種以空間換時間的操作方式。
- Python將內存分為了3“代”,分別為年輕代(第0代)、中年代(第1代)、老年代(第2代)
- 他們對應的是3個鏈表,它們的垃圾收集頻率與對象的存活時間的增大而減小。
- 新創建的對象都會分配在年輕代,年輕代鏈表的總數達到上限時,Python垃圾收集機制就會被觸發
- 把那些可以被回收的對象回收掉,而那些不會回收的對象就會被移到中年代去,依此類推
- 老年代中的對象是存活時間最久的對象,甚至是存活於整個系統的生命周期內。
三次握手四次揮手
TCP協議
- 可靠傳輸, TCP數據包沒有長度限制, 理論上可以無限長, 但是為了保證網絡的效率,
- 通常TCP數據包的長度不會超過IP數據包的長度, 以確保單個TCP數據包不必再分割
UDP協議
- 不可靠傳輸, “”報頭””部分一共只有8個位元組, 總長度不超過65535位元組, 正好放進一個IP數據包
三次握手
- 置位概念: 根據TCP的包頭字段, 存在3個重要的表示ACK, SYN, FIN
- ACK: 表示驗證字段
- SYN: 位數置1, 表示建立TCP連接
- FIN:位數置1,表示斷開TCP連接

三次握手過程說明
- 由客戶端發送建立TCP連接的請求報文, 其中報文中包含seq序列號, 是由發送端隨機生成的,並且將報文中的SYN字段置為1, 表示需要建立TCP連接 (SYN=1, seq=x, x為隨機生成數值)
- 由服務端回復客戶端發送的TCP連接請求報文, 其中包含seq序列號, 是由回復端隨機生成的, 並且將SYN置為1,而且會產生ACK字段, ACK字段數值是在客戶端發送過來的序列號seq的基礎上加1進行回復,以便客戶端收到信息時,知曉自己的TCP建立請求已得到驗證 (SYN=1, ACK=x+1, seq=y, y為隨機生成數值) 這裡的ACK加1可以理解為是確認和誰建立連接
- 客戶端收到服務端發送的TCP建立驗證請求後, 會使自己的序列號加1表示, 並且再次回復ACK驗證請求, 在服務端發過來的seq上加1進行回復(SYN=1, ACK=y+1, seq=x+1)
四次揮手

四次揮手過程說明
- 客戶端發送斷開TCP連接請求的報文, 其中報文中包含seq序列號, 是由發送端隨機生成的, 並且還將報文中的FIN字段置為1, 表示需要斷開TCP連接 (FIN=1, seq=x, x由客戶端隨機生成)
- 服務端會回復客戶端發送的TCP斷開請求報文, 其包含seq序列號, 是由回復端隨機生成的,而且會產生ACK字段, ACK字段數值是在客戶端發過來的seq序列號基礎上加1進行回復,以便客戶端收到信息時, 知曉自己的TCP斷開請求已經得到驗證 (FIN=1, ACK=x+1, seq=y, y由服務端隨機生成)
- 服務端在回復完客戶端的TCP斷開請求後,不會馬上進行TCP連接的斷開,服務端會先確保斷開前,所有傳輸到A的數據是否已經傳輸完畢,一旦確認傳輸數據完畢,就會將回復報文的FIN字段置1,並且產生隨機seq序列號。(FIN=1,ACK=x+1,seq=z,z由服務端隨機生成)
- 客戶端收到服務端的TCP斷開請求後,會回復服務端的斷開請求,包含隨機生成的seq字段和ACK字段,ACK字段會在服務端的TCP斷開請求的seq基礎上加1,從而完成服務端請求的驗證回復。(FIN=1,ACK=z+1,seq=h,h為客戶端隨機生成)至此TCP斷開的4次揮手過程完畢
11種狀態
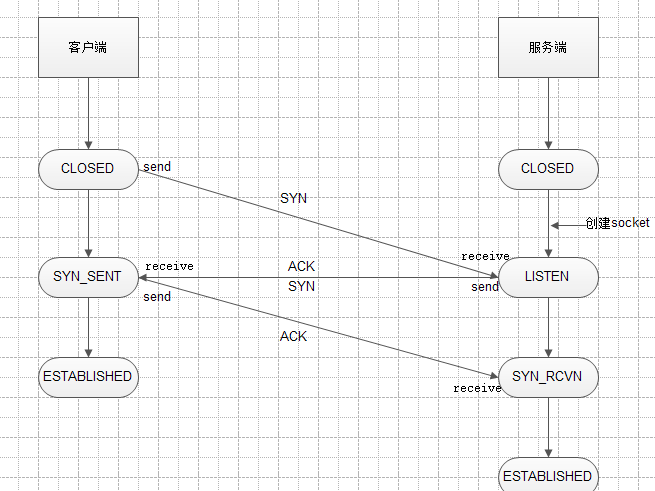
- 一開始,建立連接之前服務器和客戶端的狀態都為CLOSED;
- 服務器創建socket後開始監聽,變為LISTEN狀態;
- 客戶端請求建立連接,向服務器發送SYN報文,客戶端的狀態變味SYN_SENT;
- 服務器收到客戶端的報文後向客戶端發送ACK和SYN報文,此時服務器的狀態變為SYN_RCVD;
- 然後,客戶端收到ACK、SYN,就向服務器發送ACK,客戶端狀態變為ESTABLISHED;
- 服務器端收到客戶端的ACK後變為ESTABLISHED。此時3次握手完成,連接建立!
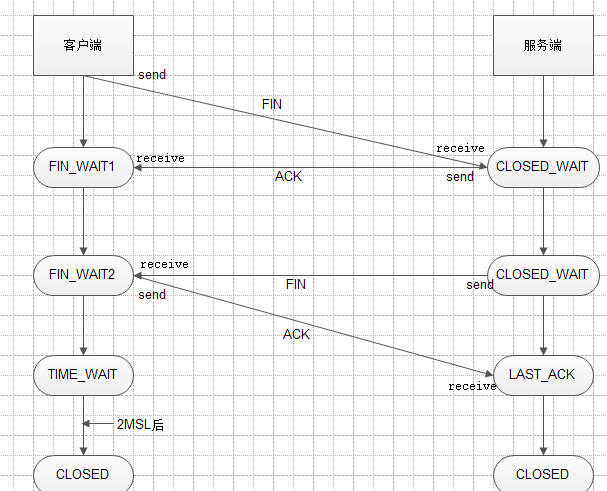
由於TCP連接是全雙工的,斷開連接會比建立連接麻煩一點點。
- 客戶端先向服務器發送FIN報文,請求斷開連接,其狀態變為FIN_WAIT1;
- 服務器收到FIN後向客戶端發送ACK,服務器的狀態圍邊CLOSE_WAIT;
- 客戶端收到ACK後就進入FIN_WAIT2狀態,此時連接已經斷開了一半了如果服務器還有數據要發送給客戶端,就會繼續送;
- 直到發完數據,就會發送FIN報文,此時服務器進入LAST_ACK狀態;
- 客戶端收到服務器的FIN後,馬上發送ACK給服務器,此時客戶端進入TIME_WAIT狀態;
- 再過了2MSL長的時間後進入CLOSED狀態。服務器收到客戶端的ACK就進入CLOSED狀態。
- 至此,還有一個狀態沒有出來:CLOSING狀態。
CLOSING狀態表示:
- 客戶端發送了FIN,但是沒有收到服務器的ACK,卻收到了服務器的FIN,這種情況發生在服務器發送的ACK丟包的時候,因為網絡傳輸有時會有意外。


LISTEN --------------- # 等待從任何遠端TCP 和端口的連接請求。 SYN_SENT ----------- # 發送完一個連接請求後等待一個匹配的連接請求。 SYN_RECEIVED ------ # 發送連接請求並且接收到匹配的連接請求以後等待連接請求確認。 ESTABLISHED -------- # 表示一個打開的連接,接收到的數據可以被投遞給用戶。連接的數據傳輸階段的正常狀態。 FIN_WAIT_1 ----------- # 等待遠端TCP 的連接終止請求,或者等待之前發送的連接終止請求的確認。 FIN_WAIT_2 ---------- # 等待遠端TCP 的連接終止請求。 CLOSE_WAIT --------- # 等待本地用戶的連接終止請求。 CLOSING ------------- # 等待遠端TCP 的連接終止請求確認。 LAST_ACK ------------ # 等待先前發送給遠端TCP 的連接終止請求的確認(包括它位元組的連接終止請求的確認) TIME_WAIT ----------- # 等待足夠的時間過去以確保遠端TCP 接收到它的連接終止請求的確認。 CLOSED --------------- # 不在連接狀態(這是為方便描述假想的狀態,實際不存在)
11種狀態解析
TIME_WAIT 兩個存在的理由:
- 可靠的實現tcp全雙工連接的終止;
- 允許老的重複分節在網絡中消逝。
高階函數
- map函數
- 一般情況map()函數接收兩個參數,一個函數(該函數接收一個參數),一個序列,將傳入的函數依次作用到序列的每個元素,並返回一個新的Iterator(迭代器)。 例如有這樣一個list:[‘pYthon’, ‘jaVa’, ‘kOtlin’],現在要把list中每個元素首字母改為大寫,其它的改為小寫,可以這樣操作:
>>> def f(s): ... return s.title() ... >>> l = map(f, ['pYthon', 'jaVa', 'kOtlin']) >>> list(l) ['Python', 'Java', 'Kotlin']
map
lists= [11,22,33,44,55] ret = map(lambda x:x if x % 2 != 0 else x + 100,lists) print(list(ret)) # 運行結果: [11, 122, 33, 144, 55]
利用map,lambda表達式將所有偶數元素加100
lists= [11,22,33,44,55] def add(num): if num%2 == 0: return num else: return num + 100 rs = map(add, lists)
自定義函數代替lambda實現相同功能
- reduce函數
- 和map()用法類似,reduce把傳入的函數作用在一個序列上,但傳入的函數需要接收兩個參數,傳入函數的計算結果繼續和序列的下一個元素做累積計算。
# 例如有一個list,裡邊的元素都是字符串,要把它拼接成一個字符串: >>> from functools import reduce >>> def f(x, y): ... return x + y ... >>> reduce(f, ['ab', 'c', 'de', 'f']) 'abcdef'
reduce
from functools import reduce def f(x, y): return x + y print(reduce(f, [1, 3, 5, 7, 9])) # 25 # 1、先計算頭兩個元素:f(1, 3),結果為4; # 2、再把結果和第3個元素計算:f(4, 5),結果為9; # 3、再把結果和第4個元素計算:f(9, 7),結果為16; # 4、再把結果和第5個元素計算:f(16, 9),結果為25; # 5、由於沒有更多的元素了,計算結束,返回結果25。 print( reduce(lambda x, y: x + y, [1, 3, 5, 7, 9]) ) # 25
使用reduce進行求和運算
'''使用reduce將字符串反轉''' s = 'Hello World' from functools import reduce result = reduce(lambda x,y:y+x,s) # 1、第一次:x=H,y=e => y+x = eH # 2、第二次:x=l,y=eH => y+x = leH # 3、第三次:x=l,y=leH => y+x = lleH print( result ) # dlroW olleH
使用reduce將字符串反轉
- filter函數
- filter()同樣接收一個函數和一個序列,然後把傳入的函數依次作用於序列的每個元素,如果傳入的函數返回true則保留元素,否則丟棄,最終返回一個Iterator。
例如一個list中元素有純字母、純數字、字母數字組合的,我們要保留純字母的: >>> def f(s): ... return s.isalpha() ... >>> l = filter(f, ['abc', 'xyz', '123kg', '666']) >>> list(l) ['abc', 'xyz']
filter
- sorted函數
- sorted()函數就是用來排序的,同時可以自己定義排序的規則。
>>> sorted([6, -2, 4, -1]) [-2, -1, 4, 6] >>> sorted([6, -2, 4, -1], key=abs) [-1, -2, 4, 6] >>> sorted([6, -2, 4, -1], key=abs, reverse=True) [6, 4, -2, -1] >>> sorted(['Windows', 'iOS', 'Android']) ['Android', 'Windows', 'iOS'] >>> d = [('Tom', 170), ('Jim', 175), ('Andy', 168), ('Bob', 185)] >>> def by_height(t): ... return t[1] ... >>> sorted(d, key=by_height) [('Andy', 168), ('Tom', 170), ('Jim', 175), ('Bob', 185)]
sorted
sorted和sort區別
- sort 是應用在 list 上的方法,sorted 可以對所有可迭代的對象進行排序操作。
- sort 是對已經存在的列表進行操作,無返回值,而 sorted 方法返回的是一個新的 list,而不是在原來的基礎上進行的操作。
sorted使用
- sorted 語法:sorted(iterable, cmp=None, key=None, reverse=False)
- iterable — 可迭代對象。
- cmp — 比較的函數
- key — 主要是用來進行比較的元素,只有一個參數,具體的函數的參數就是取自於可迭代對象中,指定可迭代對象中的一個元素來進行排序。
- reverse — 排序規則,reverse = True 降序 , reverse = False 升序(默認)。
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)] print( sorted(students, key=lambda s: s[2], reverse=False) ) # 按年齡排序 # 結果:[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
sorted對列表排序
d = {'k1':1, 'k3': 3, 'k2':2} # d.items() = [('k1', 1), ('k3', 3), ('k2', 2)] a = sorted(d.items(), key=lambda x: x[1]) print(a) # [('k1', 1), ('k2', 2), ('k3', 3)]
sorted對字典排序
is和==區別
- is不僅數據一樣內存地址也一樣
- == 只判斷數據和數據類型一樣即可
- 首先要知道Python中對象包含的三個基本要素,分別是:id(身份標識)、type(數據類型)和value(值)。
- is和==都是對對象進行比較判斷作用的,但對對象比較判斷的內容並不相同。下面來看看具體區別在哪。
- ==比較操作符和is同一性運算符區別
- ==是python標準操作符中的比較操作符,用來比較判斷兩個對象的value(值)是否相等,例如下面兩個字符串間的比較:
>>> a = 'cheesezh' >>> b = 'cheesezh' >>> a == b True
示例1
- is也被叫做同一性運算符,這個運算符比較判斷的是對象間的唯一身份標識,也就是id是否相同。通過對下面幾個list間的比較,你就會明白is同一性運算符的工作原理:
>>> x = y = [4,5,6] >>> z = [4,5,6] >>> x == y True >>> x == z True >>> x is y True >>> x is z False >>> >>> print id(x) 3075326572 >>> print id(y) 3075326572 >>> print id(z) 3075328140
示例2
- 前二個例子都是True,這什麼最後一個是False呢?x、y和z的值是相同的,所以前兩個是True沒有問題。至於最後一個為什麼是False,看看三個對象的id分別是什麼就會明白了。
下面再來看一個例子,例3中同一類型下的a和b的(a==b)都是為True,而(a is b)則不然。
>>> a = 1 #a和b為數值類型 >>> b = 1 >>> a is b True >>> id(a) 14318944 >>> id(b) 14318944 >>> a = 'cheesezh' #a和b為字符串類型 >>> b = 'cheesezh' >>> a is b True >>> id(a) 42111872 >>> id(b) 42111872 >>> a = (1,2,3) #a和b為元組類型 >>> b = (1,2,3) >>> a is b False >>> id(a) 15001280 >>> id(b) 14790408 >>> a = [1,2,3] #a和b為list類型 >>> b = [1,2,3] >>> a is b False >>> id(a) 42091624 >>> id(b) 42082016 >>> a = {'cheese':1,'zh':2} #a和b為dict類型 >>> b = {'cheese':1,'zh':2} >>> a is b False >>> id(a) 42101616 >>> id(b) 42098736 >>> a = set([1,2,3])#a和b為set類型 >>> b = set([1,2,3]) >>> a is b False >>> id(a) 14819976 >>> id(b) 14822256
示例3
通過例3可看出,只有數值型和字符串型的情況下,a is b才為True,當a和b是tuple,list,dict或set型時,a is b為False。
讀寫文件
open函數用來打開文件
- open(name[, mode[, buffering]]) 打開文件可傳的參數
- open函數使用一個文件名作為唯一的強制參數,然後返回一個文件對象。
- 模式(mode)和緩衝(buffering)參數都是可選的
- 打開文件的模式有
- r — 只讀模式(默認)。
- w — 只寫模式。【不可讀;不存在則創建;存在則刪除內容;】
- a — 追加模式。【可讀; 不存在則創建;存在則只追加內容;】
- 註: “+” 表示可以同時讀寫某個文件
- w — 只寫模式。【不可讀;不存在則創建;存在則刪除內容;】
- w+ — 寫讀
- a+ — 同a
- with語句
- 作用:將打開文件寫在with中當對文件操作完成後with語句會自動幫關閉文件,避免忘記寫f.close()
with open("data1.txt",'r',encoding = 'utf-8') as f: for line in f: print(line)
with讀文件
三種讀操作比較
- readline()每次讀取一行,當前位置移到下一行
- readlines()讀取整個文件所有行,保存在一個列表(list)變量中,每行作為一個元素
- read(size)從文件當前位置起讀取size個位元組,如果不加size會默認一次性讀取整個文件(適用於讀取小文件)
#1. read()一次讀取所有內容 '''aaa111 bbb222''' f = open(r"data.txt") print(f.read()) f.close() #2. readline(),每次只讀取一行,光標下移 ''' 0: aaa111 1: bbb222 ''' f = open(r"data.txt") for i in range(2): print(str(i) + ": " + f.readline(),) #3. 一次讀取所有,每行作為列表的一個值 '''['aaa111n', 'bbb222n']''' f = open(r"data.txt") print(f.readlines())
三種讀操作舉例
讀取大文件正確方式
- 我們使用了一個 while 循環來讀取文件內容,每次最多讀取 8kb 大小
- 這樣可以避免之前需要拼接一個巨大字符串的過程,把內存佔用降低非常多。
#!/usr/bin/python # -*- coding: utf-8 -*- def read_big_file_v(fname): block_size = 1024 * 8 with open(fname,encoding="utf8") as fp: while True: chunk = fp.read(block_size) # 當文件沒有更多內容時,read 調用將會返回空字符串 '' if not chunk: break print(chunk) path = r'C:aaalutingedc-backendtttt.py' read_big_file_v(path)
python讀取大文件
使用read()讀文件
- read(n)讀取指定長度的文件
f = open(r"somefile.txt") print(f.read(7)) # Welcome 先讀出 7 個字符 print(f.read(4)) #‘ to ‘ 接着上次讀出 4 個字符 f.close()
read讀取指定長度字符串
- seek(offset[, whence]) 隨機訪問
- 作用:從文件指定位置讀取或寫入
f = open(r"somefile.txt", "w") f.write("01234567890123456789") f.seek(5) f.write("Hello, World!") f.close() f = open(r"somefile.txt") print(f.read()) # 01234Hello, World!89
從指定位置寫入
- tell 返回當前讀取到文件的位置下標
f = open(r"somefile.txt") f.read(1) f.read(2) print(f.tell()) # 3 3就是讀取到文件的第三個字符
返回讀取位置下標
readline()讀文件
- 作用:readline 的用法,速度是fileinput的3倍左右,每秒3-4萬行,好處是 一行行讀 ,不佔內存,適合處理比較大的文件,比如超過內存大小的文件
f1 = open('test02.py','r') f2 = open('test.txt','w') while True: line = f1.readline() if not line: break f2.write(line) f1.close() f2.close()
readline讀取大文件
readlines()讀文件
- 作用:readlines會把文件都讀入內存,速度大大增加,但是木有這麼大內存,那就只能乖乖的用readline
f1=open("readline.txt","r") for line in f1.readlines(): print(line)
readlines讀文件
將data1.txt中內容讀取並寫入到data2.txt中
f1 = open('data1.txt','r') f2 = open('data2.txt','w') for line in f1: f2.write(line) f1.close() f2.close()
將data1.txt內容讀取到data2.txt
使用eval()方法將文件讀取成字典
f = open('data1.txt') f1 = (f.read()) data = eval(f1) f.close() print(data) # 運行結果: {'k2': 'v2', 'k3': 'v3', 'k1': 'v1'}
將文件讀取成字典
將文件內容讀取成列表
lock = [] f = open("password.txt") for name in f.readlines(): lock.append(name.strip('n')) print(lock) 運行結果: ['aaa 111', 'bbb 222', 'ccc 333']
內容讀取成列表
閉包
閉包概念
- 在一個外函數中定義了一個內函數,內函數里運用了外函數的臨時變量,並且外函數的返回值是內函數的引用,這樣就構成了一個閉包
- 一般情況下,在我們認知當中,如果一個函數結束,函數的內部所有東西都會釋放掉,還給內存,局部變量都會消失。
- 但是閉包是一種特殊情況,如果外函數在結束的時候發現有自己的臨時變量將來會在內部函數中用到,就把這個臨時變量綁定給了內部函數,然後自己再結束。
閉包特點
- 必須有一個內嵌函數
- 內嵌函數必須引用外部函數中的變量
- 外部函數的返回值必須是內嵌函數
#閉包函數的實例 def outer( a ): b = 10 def inner(): # 在內函數中 用到了外函數的臨時變量 print(a+b) # 外函數的返回值是內函數的引用 return inner if __name__ == '__main__': demo = outer(5) demo() # 15 # 在這裡我們調用外函數傳入參數5 # 此時外函數兩個臨時變量 a是5 b是10 ,並創建了內函數,然後把內函數的引用返回存給了demo # 外函數結束的時候發現內部函數將會用到自己的臨時變量,這兩個臨時變量就不會釋放,會綁定給這個內部函數 # 我們調用內部函數,看一看內部函數是不是能使用外部函數的臨時變量 # demo存了外函數的返回值,也就是inner函數的引用,這裡相當於執行inner函數
閉包實例
閉包中內函數修改外函數局部變量
- 在基本的python語法當中,一個函數可以隨意讀取全局數據,但是要修改全局數據的時候有兩種方法:
- global 聲明全局變量
- 全局變量是可變類型數據的時候可以修改
- 在閉包情況下使用下面兩種方法修改
- 在python3中,可以用nonlocal 關鍵字聲明 一個變量, 表示這個變量不是局部變量空間的變量,需要向上一層變量空間找這個變量。
- 在python2中,沒有nonlocal這個關鍵字,我們可以把閉包變量改成可變類型數據進行修改,比如列表。
#修改閉包變量的實例 def outer( a ): b = 10 # a和b都是閉包變量 c = [a] # 這裡對應修改閉包變量的方法2 def inner(): # 方法一: nonlocal關鍵字聲明(python3) nonlocal b b+=1 # 方法二: 把閉包變量修改成可變數據類型 比如列表(python2) c[0] += 1 print(c[0]) print(b) return inner # 外函數的返回值是內函數的引用 if __name__ == '__main__': demo = outer(5) demo() # 6 11
閉包中內函數修改外函數局部變量
上下文管理with
什麼是with語句
- with是一種上下文管理協議,目的在於從流程圖中把 try,except 和finally 關鍵字和資源分配釋放相關代碼統統去掉,簡化try….except….finlally的處理流程。
- 所以使用with處理的對象必須有enter()和exit()這兩個方法
- with通過enter方法初始化(enter方法在語句體執行之前進入運行)
- 然後在exit中做善後以及處理異常(exit()方法在語句體執行完畢退出後運行)
with語句使用場景
- with 語句適用於對資源進行訪問的場合,確保不管使用過程中是否發生異常都會執行必要的“清理”操作,釋放資源
- 比如文件使用後自動關閉、線程中鎖的自動獲取和釋放等。
with處理文件操作的實例
with open('/etc/passwd') as f: for line in f: print(line) # 這段代碼的作用:打開一個文件,如果一切正常,把文件對象賦值給f,然後用迭代器遍歷文件中每一行,當完成時,關閉文件; # 而無論在這段代碼的任何地方,如果發生異常,此時文件仍會被關閉。
字符編碼
各種編碼由來
- ASCII : 不支持中文(一個字母一個位元組:a/b/c)
- GBK : 是中國的中文字符,其包含了簡體中文和繁體中文的字符
- Unicode : 萬國編碼(Unicode 包含GBK)
Unicode(每個字母需要用兩個位元組:a/b/c)
- 存儲所有字符串都用連個位元組
- Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一併且唯一的二進制編碼
- 規定所有的字符和符號最少由 16 位來表示(2個位元組),即:2 **16 = 65536
- 這裡還有個問題:使用的位元組增加了,那麼造成的直接影響就是使用的空間就直接翻倍了
Utf-8 : 可變長碼, 是Unicode 的擴展集
- UTF-8編碼:是對Unicode編碼的壓縮和優化,他不再使用最少使用2個位元組,而是將所有的字符和符號進行分類
- ascii碼中的內容用1個位元組保存、歐洲的字符用2個位元組保存,東亞的字符用3個位元組保存…
- 存一個a字母用一個位元組,存一個中文用三個位元組
python2與python3的區別
- Python2默認 編碼方式為ASCII, Python3 默認編碼方式為UTF-8(是Unicode 的擴展集)
- python2中字符串有str和unicode兩種類型, python3 中字符串有str和位元組(bytes) 兩種類型
- python3中不再支持u中文的語法格式
- 異常處理 Python2中try:…except Exception, e:…,在Python3中改為了try:…except Exception as e:…
- Python3中不再使用xrange方法,只有range方法。
- range在Python2中返回列表,而在Python3中返回range可迭代對象。
- 在Python2中有兩個不等運算符!=和<>,在Python3中去掉了<>,只有!=符號表示不等
- 在Python2中雙反引號`可以替代repr函數,在Python3中去掉了雙反引號的表是方法,只能用repr`方法。
- 在Python2中long是比int取值範圍更大的整數,Python3中取消了long類型,int的取值範圍擴大到之前的long類型範圍。
- 列表推導 不再支持[n for n in a,b]語法,改為[n for n in (a,b)]或[n for n in [a,b]]
- python 2 中通過input輸入的類型是int,只有通過raw_input()輸入的類型才是str。
- python 3中通過input輸入的類型都是str,去掉了row_input()方法。
-
python2和python3中編碼轉換
- 在python3中字符串默認是unicode所以不需要decode(),直接encode成想要轉換的編碼如gb2312
- 在python2中默認是ASCII編碼,必須先轉換成Unicode,Unicode 可以作為各種編碼的轉換的中轉站
常用模塊
re模塊(一)
- 常用正則表達式符號
- 通配符( . )
- 作用:點(.)可以匹配除換行符以外的任意一個字符串
- 例如:‘.ython’ 可以匹配‘aython’ ‘bython’ 等等,但只能匹配一個字符串
- 通配符( . )
- 轉義字符( )
- 作用:可以將其他有特殊意義的字符串以原本意思表示
- 例如:‘python.org’ 因為字符串中有一個特殊意義的字符串(.)所以如果想將其按照普通意義就必須使用這樣表示: ‘python.org’ 這樣就只會匹配‘python.org’ 了
- 註:如果想對反斜線()自身轉義可以使用雙反斜線(\)這樣就表示 ’’
- 字符集
- 作用:使用中括號來括住字符串來創建字符集,字符集可匹配他包括的任意字串
- ‘[pj]ython’ 只能夠匹配‘python’ ‘jython’
- ‘[a-z]’ 能夠(按字母順序)匹配a-z任意一個字符
- ‘[a-zA-Z0-9]’ 能匹配任意一個大小寫字母和數字
- ‘[^abc]’ 可以匹配任意除a,b和c 之外的字符串
- 作用:使用中括號來括住字符串來創建字符集,字符集可匹配他包括的任意字串
- 管道符
- 作用:一次性匹配多個字符串
- 例如:’python|perl’ 可以匹配字符串‘python’ 和 ‘perl’
- 可選項和重複子模式(在子模式後面加上問號?)
- 作用:在子模式後面加上問號,他就變成可選項,出現或者不出現在匹配字符串中都是合法的
- 例如:r’(aa)?(bb)?ccddee’ 只能匹配下面幾種情況
- ‘aabbccddee’
- ‘aaccddee’
- ‘bbccddee’
- ‘ccddee’
- 字符串的開始和結尾
- ‘w+’ 匹配以w開通的字符串
- ‘^http’ 匹配以’http’ 開頭的字符串
- ‘ $com’ 匹配以‘com’結尾的字符串
- 最常用的匹配方法
- d 匹配任何十進制數;它相當於類 [0-9]。
- D 匹配任何非數字字符;它相當於類 [^0-9]。
- s 匹配任何空白字符;它相當於類 [ fv]。
- S 匹配任何非空白字符;它相當於類 [^ fv]。
- w 匹配任何字母數字字符;它相當於類 [a-zA-Z0-9_]。
- W 匹配任何非字母數字字符;它相當於類 [^a-zA-Z0-9_]。
- w* 匹配所有字母字符
- w+ 至少匹配一個字符
'.' # 默認匹配除n之外的任意一個字符,若指定flag DOTALL,則匹配任意字符,包括換行 2 '^' # 匹配字符開頭,若指定flags MULTILINE,這種也可以匹配上(r"^a","nabcneee",flags=re.MULTILINE) 3 '$' # 匹配字符結尾,或e.search("foo$","bfoonsdfsf",flags=re.MULTILINE).group()也可以 4 '*' # 匹配*號前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 結果為['abb', 'ab', 'a'] 5 '+' # 匹配前一個字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 結果['ab', 'abb'] 6 '?' # 匹配前一個字符1次或0次 7 '{m}' # 匹配前一個字符m次 8 '{n,m}' # 匹配前一個字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 結果'abb', 'ab', 'abb'] 9 '|' # 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 結果'ABC' 10 '(...)' # 分組匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 結果 abcabca456c 11 12 'A' # 只從字符開頭匹配,re.search("Aabc","alexabc") 是匹配不到的 13 'Z' # 匹配字符結尾,同$ 14 'd' # 匹配數字0-9 15 'D' # 匹配非數字 16 'w' # 匹配[A-Za-z0-9] 17 'W' # 匹配非[A-Za-z0-9] 18 's' # 匹配空白字符、t、n、r , re.search("s+","abtc1n3").group() 結果 't' 19 b # 匹配一個單詞邊界,也就是指單詞和空格間的位置,如,“erb”可以匹配“never”中的“er”,但不能匹配“verb”中的“er” 20 B # 匹配非單詞邊界。“erB”能匹配“verb”中的“er”,但不能匹配“never”中的“er”
re模塊更詳細表達式符號
函數 描述 compile(pattern[, flags]) # 根據正則表達式字符串創建模式對象 search(pattern, string[, flags]) # 在字符串中尋找模式 match(pattern, 常用模塊[, flags]) # 在字符串的開始處匹配模式 split(pattern, string[, maxsplit=0]) # 根據模式的匹配項來分割字符串 findall(pattern, string) # 列出字符串中模式的所有匹配項並以列表返回 sub(pat, repl, string[, count=0]) # 將字符串中所有pat的匹配項用repl替換 escape(string) # 將字符串中所有特殊正則表達式字符轉義
re.compile(pattern[, flags])
- 把一個正則表達式pattern編譯成正則對象,以便可以用正則對象的match和search方法
- 用了re.compile以後,正則對象會得到保留,這樣在需要多次運用這個正則對象的時候,效率會有較大的提升
import re mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$') ret = re.match(mobile_re,'18538762511') print(ret) # <_sre.SRE_Match object; span=(0, 11), match='18538652511'>
re.compile使用
search(pattern, string[, flags]) 和 match(pattern, string[, flags])
- match :只從字符串的開始與正則表達式匹配,匹配成功返回matchobject,否則返回none;
- search :將字符串的所有字串嘗試與正則表達式匹配,如果所有的字串都沒有匹配成功,返回none,否則返回matchobject;
import re a =re.match('www.bai', 'www.baidu.com') b = re.match('bai', 'www.baidu.com') print(a.group()) # www.bai print(b) # None # 無論有多少個匹配的只會匹配一個 c = re.search('bai', 'www.baidubaidu.com') print(c) # <_sre.SRE_Match object; span=(4, 7), match='bai'> print(c.group()) # bai
match與search使用比較
split(pattern, string[, maxsplit=0])
- 作用:將字符串以指定分割方式,格式化成列表
import re text = 'aa 1bb###2cc3ddd' print(re.split('W+', text)) # ['aa', '1bb', '2cc3ddd'] print(re.split('W', text)) # ['aa', '1bb', '', '', '2cc3ddd'] print(re.split('d', text)) # ['aa ', 'bb###', 'cc', 'ddd'] print(re.split('#', text)) # ['aa 1bb', '', '', '2cc3ddd'] print(re.split('#+', text)) # ['aa 1bb', '2cc3ddd']
split使用
findall(pattern, string)
- 作用:正則表達式 re.findall 方法能夠以列表的形式返回能匹配的子串
import re p = re.compile(r'd+') print(p.findall('one1two2three3four4')) # ['1', '2', '3', '4'] print(re.findall('o','one1two2three3four4')) # ['o', 'o', 'o'] print(re.findall('w+', 'he.llo, wo#rld!')) # ['he', 'llo', 'wo', 'rld']
findall使用
sub(pat, repl, string[, count=0])
- 替換,將string里匹配pattern的部分,用repl替換掉,最多替換count次然後返回替換後的字符串
- 如果string里沒有可以匹配pattern的串,將被原封不動地返回
- repl可以是一個字符串,也可以是一個函數
- 如果repl是個字符串,則其中的反斜桿會被處理過,比如 n 會被轉成換行符,反斜桿加數字會被替換成相應的組,比如 6 表示pattern匹配到的第6個組的內容
import re test="Hi, nice to meet you where are you from?" print(re.sub(r's','-',test)) # Hi,-nice-to-meet-you-where-are-you-from? print(re.sub(r's','-',test,5)) # Hi,-nice-to-meet-you-where are you from? print(re.sub('o','**',test)) # Hi, nice t** meet y**u where are y**u fr**m?
sub使用
escape(string)
- re.escape(pattern) 可以對字符串中所有可能被解釋為正則運算符的字符進行轉義的應用函數。
- 如果字符串很長且包含很多特殊技字符,而你又不想輸入一大堆反斜杠,或者字符串來自於用戶(比如通過raw_input函數獲取輸入的內容),且要用作正則表達式的一部分的時候,可以用這個函數
import re print(re.escape('www.python.org'))
escape使用
re模塊中的匹配對象和組 group()
- group方法返回模式中與給定組匹配的字符串,如果沒有給定匹配組號,默認為組0
- m.group() == m.group(0) == 所有匹配的字符
import re a = "123abc321efg456" print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) # 123abc321 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).groups()) # ('123', 'abc', '321') print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) # 123 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) # abc print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) # 321 import re m = re.match('(..).*(..)(..)','123456789') print(m.group(0)) # 123456789 print(m.group(1)) # 12 print(m.group(2)) # 67 print(m.group(3)) # 89
group(0)與group(1)區別比較
import re m = re.match('www.(.*)..*','www.baidu.com') print(m.group(1)) # baidu print(m.start(1)) # 4 print(m.end(1)) # 9 print(m.span(1)) # (4, 9)
group()匹配之返回匹配索引
import re test = 'dsfdf 22 g2323 GigabitEthernet0/3 10.1.8.1 YES NVRAM up eee' # print(re.match('(w.*d)s+(d{1,3}.d{1,3}.d{1,3}.d{1,3})s+YESs+NVRAMs+(w+)s+(w+)s*', test).groups()) ret = re.search( r'(w*/d+).*s(d{1,3}.d{1,3}.d{1,3}.d{1,3}).*(s+ups+)',test ).groups() print(ret) # 運行結果: ('GigabitEthernet0/3', '10.1.8.1', ' up ') #1. (w*d+/d+) 匹配結果為:GigabitEthernet0/3 #1.1 w*: 匹配所有字母數字 #1.2 /d+:匹配所有斜杠開頭後根數字 (比如:/3 ) #2. (d{1,3}.d{1,3}.d{1,3}.d{1,3}) 匹配結果為:10.1.8.1 #3. s+ups+ 匹配結果為: up 這個單詞,前後都為空格
group()匹配ip,狀態以元組返回
re模塊其他知識點
import re #匹配時忽略大小寫 print(re.search("[a-z]+","abcdA").group()) #abcd print(re.search("[a-z]+","abcdA",flags=re.I).group()) #abcdA #連同換行符一起匹配: #'.'默認匹配除n之外的任意一個字符,若指定flag DOTALL,則匹配任意字符,包括換行 print(re.search(r".+","naaanbbbnccc").group()) #aaa print(re.search(r".+","naaanbbbnccc",flags=re.S)) #<_sre.SRE_Match object; span=(0, 12), match='naaanbbbnccc'> print(re.search(r".+","naaanbbbnccc",flags=re.S).group()) aaa bbb ccc
re匹配忽略大小寫,匹配換行
1)init_l=[i for i in re.split('(-d+.*d*)',expression) if i] a. 按照類似負數的字符串分割成列表 b. -d+.*d*是為了可以匹配浮點數(比如:3.14) c. (if i)是為了去除列表中的空元素 d. 分割結果:['-1', '-2', '*((', '-60', '+30+(', 2)re.search('[+-*/(]$',expression_l[-1]) a. 匹配expression_l列表最後一個元素是 +,-,*,/,( 這五個符號就是負數 3)new_l=[i for i in re.split('([+-*/()])',exp) if i] a. 將字符串按照+,-,*,/,(,)切分成列表(不是正真的負數就切分) 4)print(re.split('([+-])','-1+2-3*(2*2+3)')) #按照加號或者減號分割成列表 運行結果: ['', '-', '1', '+', '2', '-', '3*(2*2', '+', '3)']
計算器用到的幾個知識點
paramiko模塊(二)
在windows中安裝paramiko: pip3 install paramiko
linux中scp命令的使用
ssh [email protected] #ssh遠程登錄 scp -rp aa.txt [email protected]:/tmp/ #將本地aa.txt文件複製到10.1.0.50的/tmp文件夾中
Paramiko模塊作用
- 如果需要使用SSH從一個平台連接到另外一個平台,進行一系列的操作時,
- 比如:批量執行命令,批量上傳文件等操作,paramiko是最佳工具之一。
- paramiko是用python語言寫的一個模塊,遵循SSH2協議,支持以加密和認證的方式,進行遠程服務器的連接
- 由於使用的是python這樣的能夠跨平台運行的語言,所以所有python支持的平台,如Linux, Solaris, BSD,MacOS X, Windows等,paramiko都可以支持
- 如果需要使用SSH從一個平台連接到另外一個平台,進行一系列的操作時,paramiko是最佳工具之一
- 現在如果需要從windows服務器上下載Linux服務器文件:
- a. 使用paramiko可以很好的解決以上問題,它僅需要在本地上安裝相應的軟件(python以及PyCrypto)
- b. 對遠程服務器沒有配置要求,對於連接多台服務器,進行複雜的連接操作特別有幫助。
paramiko基於用戶名密碼連接
import paramiko # 1 創建SSH對象 ssh = paramiko.SSHClient() # 2 允許連接不在know_hosts文件中的主機 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 3 連接服務器 ssh.connect(hostname='1.1.1.3', port=22, username='root', password='chnsys@2016') # 4 執行命令 #stdin標準輸入: 自己輸入的命令 stdin, stdout, stderr = ssh.exec_command('pwd') # stdout標準輸出: 命令執行結果 # 5 獲取命令結果 #stderr標準錯誤: 命令執行報錯的結果 res, err = stdout.read(), stderr.read() result = res if res else err print(result.decode()) #運行結果: /root # 6 關閉連接 ssh.close()
遠程執行命令
import paramiko #1 連接客戶端 transport = paramiko.Transport(('10.1.0.50',22)) transport.connect(username='root',password='chnsys@2016') #2 定義與客戶端交互 將剛剛定義的transport當參數傳遞給他 sftp = paramiko.SFTPClient.from_transport(transport) #3 將location.py 上傳至服務器 /tmp/test.py sftp.put(r'C:bbbfile.txt', '/tmp/file.txt') #4 將remove_path 下載到本地 local_path sftp.get('/tmp/file.txt',r'C:bbbfile.txt') #5 關閉連接 transport.close()
SFTPClient實現對Linux服務器上傳和下載
在兩台Linux中演示無密碼ssh登陸對方
- 使用ssh-copy-id命令將公鑰copy到被管理服務器中(法1:簡單)
- 操作目的:在10.1.0.50的tom用戶下生成秘鑰對,將生成的私鑰用ssh-copy-id拷貝給10.1.0.51的root用戶,那麼root用戶就可以使用ssh[email protected]遠程登陸了
[tom@localhost .ssh]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/tom/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/tom/.ssh/id_rsa. Your public key has been saved in /home/tom/.ssh/id_rsa.pub.
ssh-keygen生成秘鑰
- 執行完上面命令後再 /home/tom/.ssh 文件夾下生成了公鑰私鑰連個文件: id_rsa id_rsa.pub
- 將在10.1.0.50中生成的公鑰複製到10.1.0.51的root加目錄下:
- ssh-copy-id [email protected]
- 執行完成後就會在10.1.0.51中生成 /home/zhangsan/.ssh/ authorized_keys 文件
- 此時輸入: ssh [email protected] 就可以直接不用密碼登陸了
手動創建秘鑰並手動copy到被管理服務器(法2:較複雜)
- 使用10.1.0.51在不輸入密碼的情況下ssh鏈接到10.1.0.50,使用10.1.0.50的tom用戶身份進行登錄
- 在 10.1.0.51上創建用於認證的秘鑰對
[root@localhost /]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. #存放私鑰 的路徑 Your public key has been saved in /root/.ssh/id_rsa.pub. #存放公約 的路徑 註:將10.1.0.51上生成的密鑰對中的公鑰放到10.1.0.50的服務器tom用戶家目錄/home/tom/.ssh/authorized_keys 中,就可以在10.1.0.51中無密碼登陸10.1.0.50了
ssh-keygen生成秘鑰對
- 在10.1.0.51中生成的私鑰路徑:cat ~/.ssh/id_rsa.pub
- 在被登錄服務器中創建用戶tom,將剛剛在10.1.0.51上生成的私鑰內容放到10.1.0.50的/home/tom/.ssh/authorized_keys中,
- 新創建用戶沒用ssh登錄過時沒有,可以手動創建
1、mkdir /home/tom/.ssh #創建/home/tom/.ssh目錄 2、chmod 700 /home/tom/.ssh/ #將目錄權限改為 700 3、touch /home/tom/.ssh/authorized_keys #創建/home/tom/.ssh/authorized_keys文件 4、chmod 600 /home/tom/.ssh/authorized_keys #將文件權限改為600 5、將10.1.0.51的公鑰文件粘貼到10.1.0.50的/home/tom/.ssh/authorized_keys中
手動創建.ssh中的文件
- 完成上面幾步後就可以在10.1.0.51上無密碼登陸10.1.0.50了
- 登陸命令: ssh [email protected]
paramiko基於公鑰密鑰連接:(ssh_rsa)
- 操作目的:在10.1.0.50中生成公鑰和私鑰,然後將生成的公鑰放到10.1.0.51的winuser的/home/zhangsan/.ssh/ authorized_keys 目錄下
- 第一步:在10.1.0.50中創建anyuser,在10.1.0.51中創建winuser
- 在10.1.0.50中使用anyuser登陸,然後生成公鑰和私鑰
[anyuser@localhost ~]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/anyuser/.ssh/id_rsa): Created directory '/home/anyuser/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/anyuser/.ssh/id_rsa. Your public key has been saved in /home/anyuser/.ssh/id_rsa.pub.
anyuser生成秘鑰對
- 將在10.1.0.50中生成的公鑰複製到10.1.0.51的winuser目錄下: ssh-copy-id [email protected]
- 執行完ssh-copy-id命令後就可以看到在10.1.0.51中新加了這樣的目錄和文件/home/zhangsan/.ssh/ authorized_keys # authorized_keys就是剛剛在10.1.0.50中生成的私鑰
- 將10.1.0.50中生成秘鑰文件內容放到windows的PyCharm運行文件同目錄,隨便命名為:id_rsa50.txt
import paramiko # 1 指定公鑰所在本地的路徑 private_key = paramiko.RSAKey.from_private_key_file('id_rsa50.txt') # 2 創建SSH對象 ssh = paramiko.SSHClient() # 3 允許連接不在know_hosts文件中的主機 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 4 連接服務器 ssh.connect(hostname='10.1.0.51', port=22, username='winuser', pkey=private_key) # 5 執行命令 stdin, stdout, stderr = ssh.exec_command('pwd') # stdout標準輸出: 命令執行結果 # 6 獲取命令結果 #stderr標準錯誤: 命令執行報錯的結果 res, err = stdout.read(), stderr.read() result = res if res else err print(result.decode()) # 7 關閉連接 ssh.close()
用PyCharm基於公鑰密鑰執行命令
複製代碼 import paramiko #1 指定公鑰所在本地的路徑 private_key = paramiko.RSAKey.from_private_key_file('id_rsa50.txt') #2 連接客戶端 transport = paramiko.Transport(('10.1.0.51', 22)) transport.connect(username='winuser', pkey=private_key ) #3 定義與客戶端交互 sftp = paramiko.SFTPClient.from_transport(transport) #4上傳 將本地test1.py 上傳至服務器 /tmp/test1.py sftp.put('test1.py', '/tmp/test1.py') #5下載 將服務器/tmp/test1.py文件 下載到本地C:bbbtest1.txt sftp.get('/tmp/test1.py', r'C:bbbtest1.txt') transport.close()
用PyCharm基於公鑰密鑰上傳下載
subprocess模塊(三)
subprocess原理以及常用的封裝函數
- 運行python的時候,我們都是在創建並運行一個進程。像Linux進程那樣,一個進程可以fork一個子進程,並讓這個子進程exec另外一個程序
- 在Python中,我們通過標準庫中的subprocess包來fork一個子進程,並運行一個外部的程序。
- subprocess包中定義有數個創建子進程的函數,這些函數分別以不同的方式創建子進程,所以我們可以根據需要來從中選取一個使用
- 另外subprocess還提供了一些管理標準流(standard stream)和管道(pipe)的工具,從而在進程間使用文本通信。
#1、返回執行狀態:0 執行成功 retcode = subprocess.call(['ping', 'www.baidu.com', '-c5']) #2、返回執行狀態:0 執行成功,否則拋異常 subprocess.check_call(["ls", "-l"]) #3、執行結果為元組:第1個元素是執行狀態,第2個是命令結果 >>> ret = subprocess.getstatusoutput('pwd') >>> ret (0, '/test01') #4、返回結果為 字符串 類型 >>> ret = subprocess.getoutput('ls -a') >>> ret '.n..ntest.py' #5、返回結果為'bytes'類型 >>> res=subprocess.check_output(['ls','-l']) >>> res.decode('utf8') '總用量 4n-rwxrwxrwx. 1 root root 334 11月 21 09:02 test.pyn'
subprocess常用函數
subprocess.check_output(['chmod', '+x', filepath]) subprocess.check_output(['dos2unix', filepath])
將dos格式文件轉換成unix格式
subprocess.Popen()
- 實際上,上面的幾個函數都是基於Popen()的封裝(wrapper),這些封裝的目的在於讓我們容易使用子進程
- 當我們想要更個性化我們的需求的時候,就要轉向Popen類,該類生成的對象用來代表子進程
- 與上面的封裝不同,Popen對象創建後,主程序不會自動等待子進程完成。我們必須調用對象的wait()方法,父進程才會等待 (也就是阻塞block)
- 從運行結果中看到,父進程在開啟子進程之後並沒有等待child的完成,而是直接運行print。
#1、先打印'parent process'不等待child的完成 import subprocess child = subprocess.Popen(['ping','-c','4','www.baidu.com']) print('parent process') #2、後打印'parent process'等待child的完成 import subprocess child = subprocess.Popen('ping -c4 www.baidu.com',shell=True) child.wait() print('parent process')
child.wait()等待子進程執行
child.poll() # 檢查子進程狀態 child.kill() # 終止子進程 child.send_signal() # 向子進程發送信號 child.terminate() # 終止子進程
subprocess.PIPE 將多個子進程的輸入和輸出連接在一起
- subprocess.PIPE實際上為文本流提供一個緩存區。child1的stdout將文本輸出到緩存區,隨後child2的stdin從該PIPE中將文本讀取走
- child2的輸出文本也被存放在PIPE中,直到communicate()方法從PIPE中讀取出PIPE中的文本。
- 注意:communicate()是Popen對象的一個方法,該方法會阻塞父進程,直到子進程完成
import subprocess #下面執行命令等價於: cat /etc/passwd | grep root child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) child2 = subprocess.Popen(["grep","root"],stdin=child1.stdout, stdout=subprocess.PIPE) out = child2.communicate() #返回執行結果是元組 print(out) #執行結果: (b'root:x:0:0:root:/root:/bin/bashnoperator:x:11:0:operator:/root:/sbin/nologinn', None)
分步執行cat /etc/passwd | grep root命
import subprocess list_tmp = [] def main(): p = subprocess.Popen(['ping', 'www.baidu.com', '-c5'], stdin = subprocess.PIPE, stdout = subprocess.PIPE) while subprocess.Popen.poll(p) == None: r = p.stdout.readline().strip().decode('utf-8') if r: # print(r) v = p.stdout.read().strip().decode('utf-8') list_tmp.append(v) main() print(list_tmp[0])
獲取ping命令執行結果


