cuckoo沙箱技術分析全景圖
- 2020 年 3 月 11 日
- 筆記
導言
本文總計四千餘字,十餘張圖,瀏覽時間較長,建議先mark
從事信息安全技術行業的小夥伴們都知道沙箱技術(有些也稱沙盒),用來判斷一個程序或者文件是否是惡意的病毒、木馬、漏洞攻擊exp或其他惡意軟件。其原理簡單來說就是提供了一個虛擬的環境,把分析目標放到這個虛擬環境中,通過一系列技術來「觀測」其行為,根據觀測結果來判定這是一個正常良民(合法文件)還是一個不懷好意的壞傢伙(惡意文件)。
說起沙箱技術,最出名的當屬國外的FireEye。國內也有許多廠商推出沙箱產品,不過,這其中有相當部分廠商和團隊都弘揚了拿來主義精神:基於開源的cuckoo進行二次開發,小軒也不例外

。但網絡上關於cuckoo的介紹實在有限,於是花了點時間將cuckoo代碼進行了粗淺分析,整理繪製了cuckoo技術全景圖,分享出來,歡迎探討。
Cuckoo架構概覽
在看全景圖前,先看看cuckoo官網的一張技術架構圖:

整個cuckoo分為兩部分:
Cuckoo Host:
Cuckoo的核心服務端,負責分析任務的啟動和分析結果報告的生成,還要負責管理多個虛擬機。
Analysis Guest:
分析客戶機,可以理解為一台虛擬機,負責提供虛擬環境供目標樣本運行,檢測目標的運行情況,並將檢測到的數據彙報給Cuckoo Host。
兩者之間通過虛擬網絡連接,多台虛擬機與Cuckoo Host組成一個局域網。
官網對於Cuckoo的技術架構描述就這麼多了,接下來是小軒的分析。我們從cuckoo的啟動和一次分析任務的發起,來看看Cuckoo的整體流程是如何運轉的。
Host啟動運行與初始化
首先是host部分,Cuckoo Host是採用Python開發,最初的啟動流程如圖:

啟動是從main.py中的main()開始,首先進行cuckoo_init()初始化,然後進入cuckoo_main()。進入之後,最主要的兩件事:
1、通過socket啟動一個ResultServer(),用於接收虛擬機中guest發送過來的監測結果,這個後面會用到:

2、緊接着創建任務調度器Scheduler,並調用start方法啟動之。啟動之後就進入主執行循環,不斷的從任務數據庫中提取任務並執行。任務的來源通過submit()提交寫入數據庫,分析的目標可以是文件,可以是域名,也可以是一個目錄。
任務的執行部分主要是AnalysisManager類在負責,這個類是繼承自Thread,調用start啟動該任務。

在AnalysisManager的線程執行函數run()中,主要幹了兩件事:啟動分析和處理分析結果。處理分析結果後面再說,先看啟動分析的過程。
通過launch_analysis()函數發起分析,首先申請虛擬機,得到一個Machiney,然後啟動虛擬機,順便提一句,Machinery是一個抽象類,具體實現可以是VirtualBox,也可以是VMware或者其他虛擬機,這取決於你的安裝配置文件。
啟動虛擬機以後,進入內部函數guest_manage()。

真正向Guest虛擬機發起任務執行的動作,是由類GuestManager完成的,在guest_manage()中間首先調用GuestManger的start_analysis()方法啟動分析,啟動完成後,再調用其wait_for_complement()進入循環檢測,等待分析的完成。
而start_analysis()進來之後,做了4件事:
1、upload_analyzer(): 把虛擬機對應平台(windows/linux/···)的分析器程序代碼傳上去
2、add_config(): 將本次分析的一些參數設置到guest中去
3、上傳待分析的目標樣本
4、讓虛擬機guest機器執行analyzer.py腳本,流程轉入到Guest虛擬機中去
Guest中啟動分析流程
上面四步是如何實現的呢?
原來,Guest機器中安裝時會事先安裝一個代理程序Agent,也是python編寫,這個程序隨虛擬機自啟動,這個Agent用於Guest和Cuckoo Host之間的通信,其主要邏輯就是開啟一個web服務,提供RESTful接口,Host通過這些接口來和Agent進行通信,上面的文件上傳,就是通過Agent提供的RESTful接口完成的:
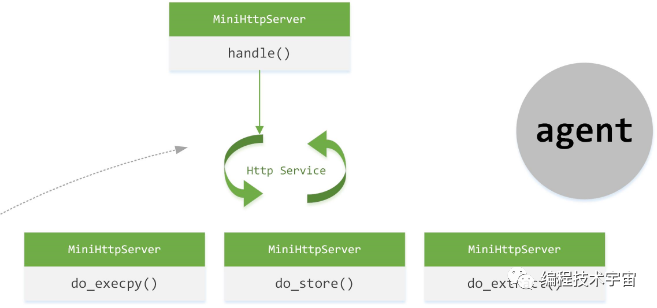
在上面提到的第四步,通過Agent來啟動analyzer.py腳本(通過do_execpy()完成),開啟在Guest機器上的分析執行。

analyzer.py腳本啟動後,通過Analyzer類的run方法,啟動分析。在啟動目標樣本運行前,有許多前置工作需要做:
1、prepare():
- 準備工作,提升當前進程(Analyzer所屬的python進程)權限,獲得SeDebugPrivilege和SeLoadDriverPrivilege權限,用於後續操作樣本所在進程和加載驅動使用。
- 啟動兩個管道服務器,分別用於和目標樣本進程的代碼日誌傳輸和函數執行記錄傳輸 2、啟動一系列輔助分析工具,Auxiliary為抽象基類,遍歷所有該類的子類並啟動之,主要包括截屏工具、驅動加載工具等 3、選擇package,所謂package,是cuckoo為不同擴展名的文件選定不同的命令來啟動分析,比如exe文件,是直接啟動,如果是doc,就是office進程,如果是url,就是打開瀏覽器等等。這些不同的邏輯通過引入一個Package的概念作為基類,使用多態的形式為不同擴展名的文件實現不同的啟動方式。 4、調用驅動功能,實現對當前進程(Analyzer進程)和父進程(Agent)的隱藏,防止目標檢測到cuckoo的存在。
選定package之後,調用其start方法,正式啟動:

目標樣本進程的啟動過程還挺複雜,通過一系列的函數封裝,進入Process的execute()函數。在這裡分為兩步進行:
第一步:啟動inject-x86/x64.exe作為中間人,它的任務是負責把目標樣本的進程給啟動,但是將主線程給掛起來suspend,同時把目標樣本進程的pid和主線程tid通過print輸出,隨後便退出。
第二步:再次啟動inject-x86/x64.exe作為中間人,這一次它的主要任務是執行注入功能,將cuckoo的核心模塊monitor-x86/x64.dll注入到目標樣本的進程,注入方式有兩種:遠程線程注入和apc注入。最後,通過喚醒目標樣本進程的主線程,真正讓樣本run起來了。
注入模塊monitor
在目標樣本進程中的monitor.dll,在注入的時候做了哪些事情呢?需要注意的是,從inject.exe開始到monitor.dll,其源代碼開始使用C語言編寫。

首先是執行monitor_init(),裏面有一堆初始化:
1、配置讀取初始化
2、hook初始化
3、管道初始化,連接前面Analyzer進程開啟的兩個管道
4、sleep初始化,針對sleep函數進行特殊處理
5、monitor模塊的自我隱藏:抹去PE頭數據+從PEB中的模塊鏈表中將自己摘掉
這一系列初始化完成之後,進入monitor_hook()函數:

這個函數要做的事情便是非常核心的安裝HOOK。
Cuckoo採用了一種非常聰明的方式,將要HOOK的函數定義在rst文件中,根據不同功能分為了file.rst、process.rst、network.rst等等,這些rst文件中羅列了所有需要HOOK的函數的信息,包括函數所在的模塊名,函數名稱、函數的所有參數信息、函數的返回值等。在monitor.dll在編譯之前,先通過提供的工具腳本process.py,將所有rst文件通過一個hooks.c的代碼模板渲染出來,得到完整的hooks.c文件,該代碼文件裏面定義了一個全局的g_hooks的數組,來記錄所有待hook的函數信息。
回到monitor_hook()函數,它要做的事情就是遍歷這個數組,依次安裝HOOK。HOOK後的函數要做的事情也大體類似,首先調用原來真實的函數,然後調用log_api()將這次函數的調用信息記錄下來形成日誌,轉換成bson格式,最終調用log_raw()將數據通過之前Analyzer開闢的管道,發送出去。
在monitor中代碼執行的日誌和上面api調用記錄日誌通過不同的管道送到了Analyzer進程,該進程又通過socket連接發送到Cuckoo Host最開始啟動的ResultServer中去,至此,完成了目標樣本進程的運行信息被虛擬機外的Host服務器掌控。
運行結果分析與處理
樣本的運行就說到這裡,回到文章最開始說的,cuckoo_main的兩件事,第二件就是對運行結果的分析了。
上面說到,Cuckoo Host通過ResultServer獲取到了樣本執行的情況,它將這些信息寫入了Cuckoo工作目錄下的storage/analyse/{task_id}下面了,接下來就是對這些數據的分析處理。

對運行結果的分析是通過process_results()進入。該函數通過三個核心類完成分析處理:
1、RunProcessing,執行處理過程。Cuckoo提供了Processing框架,通過Processing基類派生了很多處理模塊,我們可以添加自己的分析模塊,繼承自Processing即可。每個模塊可以對數據進行分析,並選擇性的可以產生自己的分析結果,Cuckoo框架會拿到你的結果最終彙集到總的處理結果字典中。
2、RunSignatures,執行特徵匹配。Cuckoo提供了特徵匹配框架,通過Signature基類派生了很多特徵匹配模塊,我們同樣可以添加自己的特徵匹配模塊,繼承自Signature即可。特徵匹配模塊提供了豐富的外部調用接口,供Cuckoo框架本身回調。
3、RunReporting,執行結果上報,經過上面兩步的分析處理,最終得到的結果需要上報處理了。我們可以選擇生成json到文件,也可以選擇上傳到ElasticSearch非關係型數據庫,還可以有我們自定義的上報方式。Cuckoo提供了強大的框架接口供我們實現。
至此,Cuckoo整體的工作流程就分析的差不多了,下面是上面所有流程的全景圖:



