(數據科學學習手札78)基於geopandas的空間數據分析——基礎可視化
- 2020 年 3 月 4 日
- 筆記
本文對應代碼和數據已上傳至我的
Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
通過前面的文章,我們已經對geopandas中的數據結構、坐標參考系以及文件IO有了較為深入的學習,在拿到一份矢量數據開始分析時,對其進行可視化無疑是探索了解數據階段重要的步驟。
作為基於geopandas的空間數據分析系列文章的第四篇,通過本文你將會學習到基於geopandas的基礎可視化。
2 基礎可視化
geopandas使用matplotlib作為繪圖後端,使用plot()方法對GeoSeries或GeoDataFrame進行可視化,簡簡單單即可完成基本的可視化,再結合上matplotlib的一些額外元素補充,便可以創建出更加精美的可視化作品,下面我們分別進行介紹。
2.1 GeoSeries
GeoSeries由於僅有單獨一列幾何對象,無對應的數值故不涉及數值向視覺元素的映射,因此可視化相對簡單,下面我們先來看看GeoSeries.plot()的常用的參數有哪些,如果你已經對matplotlib有一定了解,想必理解這些參數起來會更加輕鬆:
figsize:傳入(寬度, 高度)形式的元組或列表,用於控制繪製出圖像的寬度和高度,單位均為英寸 facecolor:設置幾何對象的填充色,可接受顏色名稱和十六進制色彩,設置為'none'時不填充顏色 edgecolor:設置幾何對象的邊界色,對面數據和點數據效果較為明顯,不建議對線數據設置該參數,傳入格式同facecolor linewidth:設置幾何對象邊界寬度,對面數據和點數據效果較為明顯,不建議對線數據設置該參數 linestyle:字符串類型,用於設置幾何對象邊界及線數據的線型 markersize:設置點數據的大小 marker:字符串類型,用於設置點數據的形狀 alpha:設置對應幾何對象全局的色彩透明度,0-1,越大越不透明 label:適用於純粹的線數據或點數據,在需要添加圖例時適用,用作各個對象在圖例中顯示的名稱 hatch:字符型,用於設置面數據內部的填充線樣式下文的例子中將具體舉例說明 ax:
matplotlib坐標軸對象,如果需要在同一個坐標軸內疊加多個圖層就需要用這個參數傳入先前待疊加的ax
下面我們從實際例子上手,深入理解上述各參數,我們使用到的數據china-shapefiles.zip為中國國土+南海九段線,你可以在本文開頭列出的Github倉庫對應本文的路徑下找到它。
首先利用上一篇文章介紹的讀取.zip文件中數據的方法,將我們所需的陸地及九段線數據分別讀入(其中由於原始數據china.shp中每個要素不是單獨的省份而是面,即有的包含眾多島嶼的省份會由若干行共同構成,因此使用geopandas地理操作中的融合dissolve()按照OWNER列融合分離的面為多面,從而使得每一行是對應的完整的省份,關於更多地理操作將會在後續的對應的文章介紹):
import geopandas as gpd import matplotlib.pyplot as plt # 設置matplotlib繪圖模式為嵌入式 %matplotlib inline plt.rcParams["font.family"] = "SimHei" # 設置全局中文字體為黑體 # 讀入中國領土面數據 china = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles/china.shp', encoding='utf-8') # 由於每行數據是單獨的面,因此按照其省份列OWNER融合 china = china.dissolve(by='OWNER').reset_index(drop=False) # 讀入南海九段線線數據 nine_lines = gpd.read_file('zip://china-shapefiles.zip!china-shapefiles/china_nine_dotted_line.shp', encoding='utf-8')
用plot()方法疊加繪製不帶任何個性化參數的原始地圖(CRS為EPSG:4326即WGS84):
# 初始化圖床 fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.plot(ax=ax) ax = nine_lines.geometry.plot(ax=ax) fig.savefig('圖1.png', dpi=300)

圖1
接下來我們一步一步,將適用於GeoSeries.plot()的參數展示運用:
- Step1:選擇合適的投影
在之前關於坐標參考系的文章中我們了解過繪製地圖時投影的重要性,參考超圖對繪製中國地圖投影選用方面的建議(http://support.supermap.com.cn/datawarehouse/webdochelp/idesktop/features/Visualization/MapSetting/ChooseAMapProjection.htm),我們使用繪製中國地圖常用的Albers Equal Area作為投影,在https://proj.org/operations/projections/aea.html查詢到其信息說明:

圖2
將其proj信息傳入to_crs()方法中(注意按照將添加上中央經線105度和標準緯度範圍25到47度),統一到所有圖層中:
# 定義CRS albers_proj = '+proj=aea +lat_1=25 +lat_2=47 +lon_0=105' fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax) fig.savefig('圖3.png', dpi=300)

圖3
這時的形狀較為接近真實情況,看起來也比較自然。
- Step2:修改顏色
下面我們來調整面數據的填充色與輪廓色,線數據(九段線)的色彩,並分別設置透明度alpha,這裡為了美觀,將坐標軸順便移除:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', alpha=0.4) ax.axis('off') # 移除坐標軸 fig.savefig('圖4.png', dpi=300)

圖4
- Step3:修改線型與線寬
接下來我們在圖4的基礎上,修改線型和線寬,其中線型參數linestyle與matplotlib完全一致,不同選擇對應樣式如圖5:

圖5
參考圖5,我們維持九段線線型不變但適當增大其寬度為3,面數據的輪廓則設置為'--':
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') # 移除坐標軸 fig.savefig('圖6.png', dpi=300)

圖6
- Step4:修改面填充陰影線樣式
接下來我們利用hatch參數來修改面數據填充陰影樣式,主要樣式對應如下,如'-'代表橫線填充:

圖7
參考圖7,我們設置面數據的填充陰影樣式為'x',值得一提的是,hatch參數對於同一種陰影模式,可以通過增加字符數量來提高陰影密度,如下圖是hatch='x'時:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', hatch='x', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') # 移除坐標軸 fig.savefig('圖8.png', dpi=300)

圖8
而hatch='xxxx'時繪製出的地圖如下:

圖9
更有意思的是,不同陰影模式可以混合在一起,譬如我們下面設置hatch='x**':
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', hatch='x**', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') # 移除坐標軸 fig.savefig('圖10.png', dpi=300)

圖10
- Step5:點數據個性化
GeoSeries.plot()中的markersize和marker專門針對點數據進行配置,可是我們的數據里並沒有點數據,為了舉例說明,下面我們來從已有的數據中生成點數據,我最開始的想法是為每個面生成重心,作為每個省份的中心點:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', hatch='xxxx', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax = china.geometry.centroid.to_crs(albers_proj).plot(ax=ax, facecolor='black') ax.axis('off') # 移除坐標軸 fig.savefig('圖11.png', dpi=300)

圖11
但是細心觀察可以發現,有些省份的重心很尷尬地落在外面,譬如甘肅省,因為它是一個非常典型的非凸多邊形(凸多邊形內部任意兩點間連線都不會穿過其邊界),因此計算出來的重心落在了外部,好在geopandas為我們提供了representative_point()方法,用於求出任意多邊形內部的一個典型點:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', hatch='xxxx', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax = china.geometry.representative_point() .to_crs(albers_proj) .plot(ax=ax, facecolor='black') ax.axis('off') # 移除坐標軸 fig.savefig('圖12.png', dpi=300)

圖12
這時可以發現生成的點符合了我們的需求,下面我們為此基礎上,利用marker調整點數據的樣式,參考圖13:
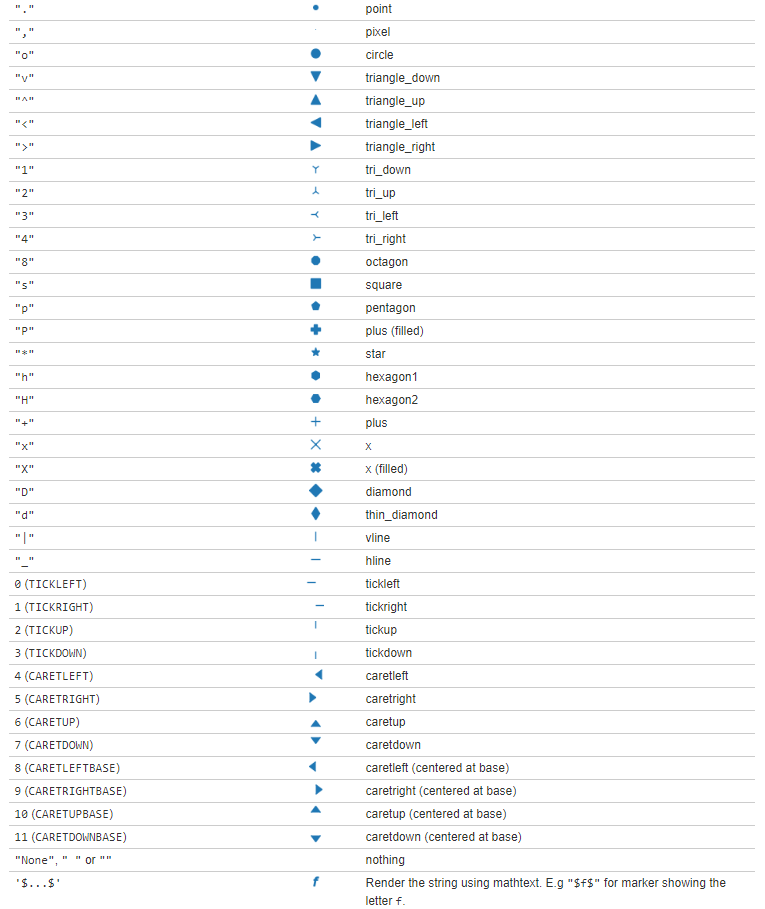
圖13
譬如我們將marker修改為'*',並調整相關的其他參數使得點看起來更加明顯,
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', hatch='xxxx', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax = china.geometry.representative_point() .to_crs(albers_proj) .plot(ax=ax, facecolor='white', edgecolor='black', marker='*', markersize=200, linewidth=0.5) ax.axis('off') # 移除坐標軸 fig.savefig('圖14.png', dpi=300)

圖14
- Step6:圖例與文字標註
接下來我們來學習如何為地圖添加圖例和文字標註,為了看着清楚我們移除陰影填充並降低點的大小,然後為九段線與點數據添加參數label,最後使用ax.legend()添加圖例並設置相應參數:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4, label='南海九段線') ax = china.geometry.representative_point() .to_crs(albers_proj) .plot(ax=ax, facecolor='white', edgecolor='black', marker='*', markersize=100, linewidth=0.5, label='省級單位') # 單獨提前設置圖例標題大小 plt.rcParams['legend.title_fontsize'] = 14 # 設置圖例標題,位置,排列方式,是否帶有陰影 ax.legend(title="圖例", loc='lower left', ncol=1, shadow=True) ax.axis('off') # 移除坐標軸 fig.savefig('圖15.png', dpi=300)

圖15
接下來我們把標記每個省級單位的星星換成名稱文字,這裡使用到matplolib中的text()方法,其以此傳入對應循環到的點的x、y、文字內容,ha與va用於調整文字水平和豎直對齊方式,size調整文字大小,更具體的參數可以去matplotlib官網搜索查看,本文不做重點介紹:
fig, ax = plt.subplots(figsize=(12, 8)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4, label='南海九段線') # 根據轉換過投影的代表點,循環添加文字至地圖上對應位置 for idx, _ in enumerate(china.geometry.representative_point().to_crs(albers_proj)): # 提取省級單位簡稱 if ('自' in china.loc[idx, 'OWNER'] or '特' in china.loc[idx, 'OWNER']) and china.loc[idx, 'OWNER'] != '內蒙古自治區': region = china.loc[idx, 'OWNER'][:2] else: region = china.loc[idx, 'OWNER'].replace('省', '') .replace('市', '') .replace('自治區', '') ax.text(_.x, _.y, region, ha="center", va="center", size=6) # 單獨提前設置圖例標題大小 plt.rcParams['legend.title_fontsize'] = 14 # 設置圖例標題,位置,排列方式,是否帶有陰影 ax.legend(title="圖例", loc='lower left', ncol=1, shadow=True) ax.axis('off') # 移除坐標軸 fig.savefig('圖16.png', dpi=300)

圖16
- Step7:添加小地圖
大家平時如果留意會記得,我們一般看到的中國地圖其南海區域都是單獨在右下角的小地圖裡顯示出來的,在geopandas里製作這種地圖非常簡單,我們只需要結合matplotlib中添加子圖區域的add_axes(),即可完成製作,先來認識一下add_axes()的功能,它最重要的參數是rect,通過傳入形如(bottom, left, width, height)來實現在圖床中開闢子區域,讓我們從下面簡單的例子出發好好理解,首先我們使用plt.figure()創建一個方形畫布,並在畫布上使用add_axes((0, 0, 1, 1)):

圖17
發現原理了嗎?我們傳入的(0, 0, 1, 1),其前兩位其實代表着子圖區域左下角坐標在整個畫布中的比例坐標!而後兩位則代表則代表着子圖區域的相對於整個畫布的比例寬度與長度!接着我們再為fig開闢新的子區域,並在新開闢的子區域正中心寫上文字:

圖18
新的子圖區域左下角坐標位於畫布的底邊中點,比例長寬均為0.5,所以得到了如圖所示的效果,搞明白了這些之後,下面我們就可以來畫帶小地圖的中國地圖啦:
首先我們需要分別對中國地圖以及南海插圖的經緯度範圍進行限定,因為並沒有找到嚴格的範圍規定,所以這裡我們大致定義一下中國地圖和南海插圖的最小最大經緯度,生成GeoDataFrame並添加矢量信息,最後進行合適的投影轉換:
from shapely.geometry import Point bound = gpd.GeoDataFrame({ 'x': [80, 150, 106.5, 123], 'y': [15, 50, 2.8, 24.5] }) # 添加矢量列 bound.geometry = bound.apply(lambda row: Point([row['x'], row['y']]), axis=1) # 初始化CRS bound.crs = 'EPSG:4326' # 再投影 bound.to_crs(albers_proj, inplace=True) bound

圖19
接下來的步驟就一目了然了,只需要把前文繪製地圖部分的手法分別移植到兩個子圖上即可:
fig = plt.figure(figsize=(8, 8)) # 創建覆蓋整個畫布的子圖1 ax = fig.add_axes((0, 0, 1, 1)) ax = china.geometry.to_crs(albers_proj).plot(ax=ax, facecolor='grey', edgecolor='white', linestyle='--', alpha=0.8) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4, label='南海九段線') # 單獨提前設置圖例標題大小 plt.rcParams['legend.title_fontsize'] = 14 # 設置圖例標題,位置,排列方式,是否帶有陰影 ax.legend(title="圖例", loc='lower left', ncol=1, shadow=True) ax.axis('off') # 移除坐標軸 ax.set_xlim(bound.geometry[0].x, bound.geometry[1].x) ax.set_ylim(bound.geometry[0].y, bound.geometry[1].y) # 創建南海插圖對應的子圖,這裡的位置和大小信息是我調好的,你可以試着調節看看有什麼不同 ax_child = fig.add_axes([0.75, 0.15, 0.2, 0.2]) ax_child = china.geometry.to_crs(albers_proj).plot(ax=ax_child, facecolor='grey', edgecolor='white', linestyle='--', alpha=0.8) ax_child = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax_child, edgecolor='grey', linewidth=3, alpha=0.4, label='南海九段線') ax_child.set_xlim(bound.geometry[2].x, bound.geometry[3].x) ax_child.set_ylim(bound.geometry[2].y, bound.geometry[3].y) # 移除子圖坐標軸刻度,因為這裡的子圖需要有邊框,所以只移除坐標軸刻度 ax_child.set_xticks([]) ax_child.set_yticks([]) fig.savefig('圖20.png', dpi=300)

圖20
2.2 GeoDataFrame
介紹完了圍繞GeoSeries展開的繪圖方法,下面我們來學習geopandas中圍繞GeoDataFrame展開的可視化方法。
與GeoSeries相比,GeoDataFrame擁有多列數據,即我們可以將輔助列的數值信息映射到地圖的視覺元素上,因此在GeoSeries常用參數的基礎上,新增了更多參數:
column:用於指定映射地圖視覺元素的數值信息,可以是對應
GeoDataFrame的列名,或是直接傳入與幾何對象一一對應得數值序列,默認為None cmap:傳入映射視覺元素時的色彩方案,具體使用方式下文中會做詳細介紹 categorical:bool型,True表示指定映射目標列採取離散表示,對於數值型的列有意義,當對應目標列為類別型時自動變為True legend:bool型,為True時會為地圖添加圖例 scheme:str型,用於指定地區分佈圖分層設色的數值劃分方案,下文中會做詳細介紹 k:int型,用於指定分層設色的色階數量 vmin:None或float,用於指定分層設色的數值範圍下限,默認為None即以對應數據中的最小值為下限 vmax:None或float,用於指定分層設色的數值範圍上限,默認為None即以對應數據中的最大值為上限 legend_kwds:字典型,傳入與圖例相關的個性化參數 classification_kwds:字典型,傳入與分層設色相關的個性化參數 missing_kwds:字典型,傳入與缺失值處理相關的個性化參數,用於對缺失值部分的視覺映射做個性化設置
同樣的,我們以實際例子出發,這裡我們使用新冠肺炎疫情數據,數據來源:https://github.com/BlankerL/DXY-COVID-19-Data ,同樣地你可以在本文開頭列出的Github倉庫中對應本文的路徑下找到下文所使用的數據,首先我們先對原數據做一些預處理,以得到每個省份最新一次更新記錄的數據:

圖21
這樣就得到我們所需的數據。
2.2.1 地區分佈圖與分層設色
地區分佈圖(Choropleth Map),指的是依據指定屬性進行層次劃分,並將對應的層次映射到對應幾何對象的色彩之上,下面我們先將上面處理好的表格數據與china相關聯,因為geopandas支持pandas的連接操作,所以我們使用pd.merge()以省級單位名稱為鍵來連接兩張表(由於連接之後的表格會變成pandas.DataFrame,所以這裡將其轉換回GeoDataFrame):
data_with_geometry = pd.merge(left=temp.replace('澳門', '澳門特別行政區'), right=china, left_on='provinceName', right_on='OWNER', how='right' ).loc[:, ['provinceName', 'provinceEnglishName', 'province_confirmedCount', 'province_suspectedCount', 'province_curedCount', 'province_deadCount', 'geometry' ]] # 將數據從DataFrame轉換為GeoDataFrame data_with_geometry = gpd.GeoDataFrame(data_with_geometry, crs='EPSG:4326') data_with_geometry.head()

圖22
有了數據,我們先很「愚蠢魯莽」地直接將province_confirmedCount即地區確診數作為映射值傳入參數column,並選擇cmap為經典的Reds紅色漸變配色,以及調整一些前文中我們已經很熟悉的參數,看看得到什麼樣的結果:

圖23
為什麼會得到這樣奇怪的結果?讓我們逐一來分析一下問題所在:
- 台灣省跑哪裡去了?
細心的你一定會發現,我們的寶島台灣不見了,這並不是我們的幾何對象中缺失了它,一個中國一寸土地都不可缺少,真正使得它消失的原因在於我們的原始數據中其實缺失香港和台灣的數據,我們前面連接過程使用的右連接的方法使得我們保留了所有的土地,但是台灣和香港由於數據缺失,對應數據位置是NaN,因此在數值映射到色彩的過程中變成了默認的白色,這時候missing_kwds參數就起到大用處了:
fig, ax = plt.subplots(figsize=(12, 12)) # 新增缺失值處理參數 ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax, column='province_confirmedCount', cmap='Reds', missing_kwds={ "color": "lightgrey", "edgecolor": "black", "hatch": "////" }) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') fig.savefig('圖24.png', dpi=300)

圖24
在字典格式的missing_kwds參數中,我們用color設置了缺失值區域的底色,用edgecolor設置了缺失值區域的線條顏色,並且用hatch設置了陰影填充樣式,這樣一來哪些地方缺失數據記錄就一目了然了。
- 為什麼只有湖北省顏色這麼深?
的確,這樣的地圖給我們的感覺就是:湖北省很嚴重,其他地方沒什麼區別嘛,我們在圖24的基礎上加上數值-色彩參考:
fig, ax = plt.subplots(figsize=(12, 12)) ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax, column='province_confirmedCount', cmap='Reds', missing_kwds={ "color": "lightgrey", "edgecolor": "black", "hatch": "////" }, legend=True) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') fig.savefig('圖25.png', dpi=300)

圖25
這下我們搞清楚了,原來是因為湖北省的數據過於大,使得數值在均勻向有序色階上映射時,除湖北省之外的其他數據都被壓縮到非常淺色的區域,這時就到了本小結的主題——分層設色,這裡就涉及到相關的核心參數scheme以及k,其中scheme決定了數據分層的方法,其通過調用第三方包mapclassify中用於給數據分層的方法),來實現geopandas中的分層設色,譬如下面我們在圖25的基礎上,使用我們喜聞樂見的自然斷點法對應的'NaturalBreaks'作為參數,選擇分段數量k=5,來看看會有什麼樣的效果:
fig, ax = plt.subplots(figsize=(12, 12)) ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax, column='province_confirmedCount', cmap='Reds', missing_kwds={ "color": "lightgrey", "edgecolor": "black", "hatch": "////" }, legend=True, scheme='NaturalBreaks', k=5) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') fig.savefig('圖26.png', dpi=300)

圖26
這時可以看到,區域顏色的分佈更加溫和,也使得我們看出了不同地區在疫情嚴重程度上的區別,且因為這時變成了離散的分層,所以圖例也由比色卡變為更為標準的分類圖例,但是這個圖例默認在右上角,對地圖造成了較為明顯的遮擋,下面我們在圖26的基礎上,利用參數legend_kwds,以及missing_kwds參數下的label,對其進行美化:
fig, ax = plt.subplots(figsize=(12, 12)) ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax, column='province_confirmedCount', cmap='Reds', missing_kwds={ "color": "lightgrey", "edgecolor": "black", "hatch": "////", "label": "缺失值" }, legend=True, scheme='NaturalBreaks', k=5, legend_kwds={ 'loc': 'lower left', 'title': '確診數量分級', 'shadow': True }) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') fig.savefig('圖27.png', dpi=300)
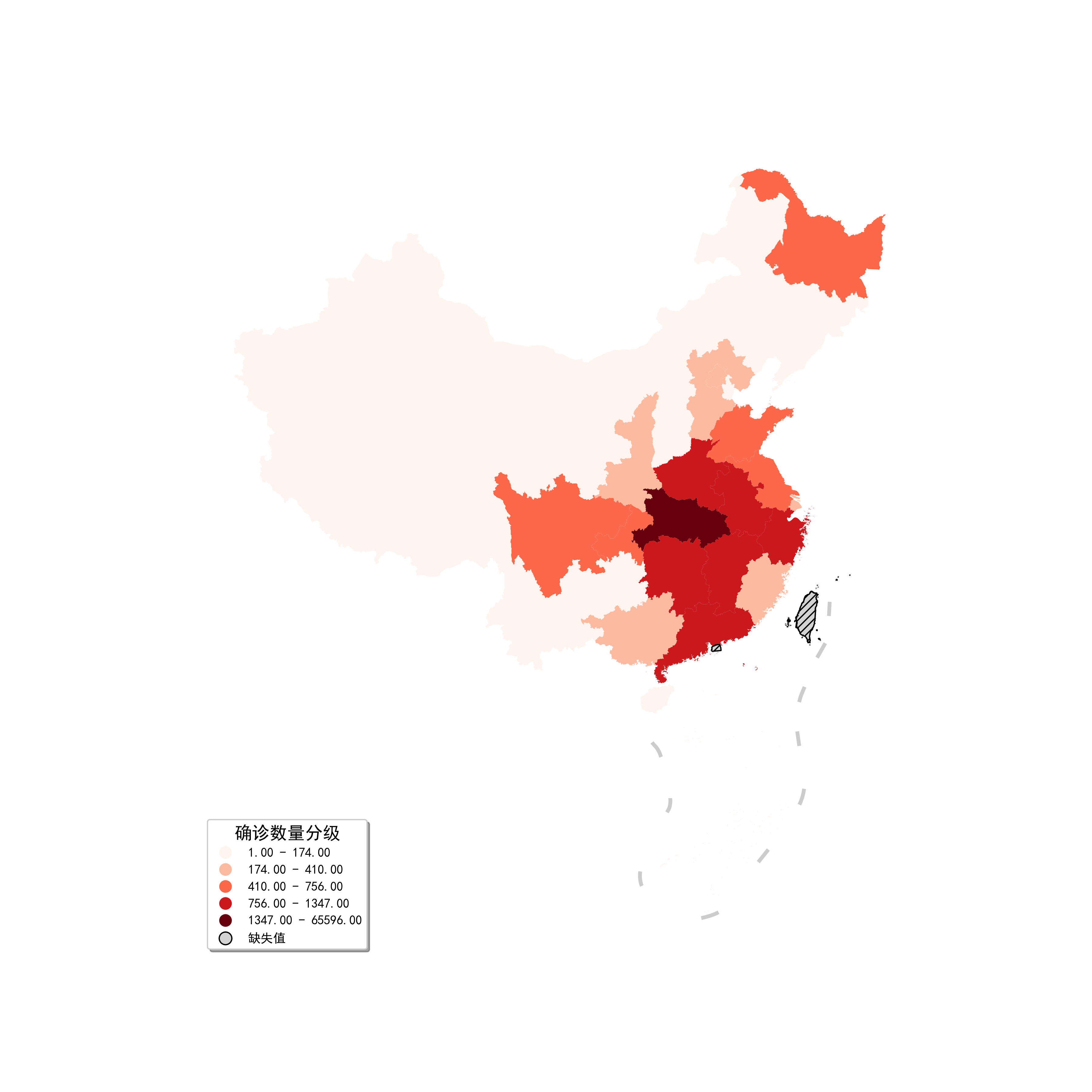
圖27
至此我們的地圖已經比最開始美觀了很多,再為其添加大標題、小標題和數據說明文字,這樣一張談不上好看但還湊合的疫情地圖便製作完畢:
fig, ax = plt.subplots(figsize=(12, 12)) ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax, column='province_confirmedCount', cmap='Reds', missing_kwds={ "color": "lightgrey", "edgecolor": "black", "hatch": "////", "label": "缺失值" }, legend=True, scheme='NaturalBreaks', k=5, legend_kwds={ 'loc': 'lower left', 'title': '確診數量分級', 'shadow': True }) ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax, edgecolor='grey', linewidth=3, alpha=0.4) ax.axis('off') plt.suptitle('新型冠狀肺炎累計確診數量地區分佈', fontsize=24) # 添加最高級別標題 plt.title('截至2020年02月27日', fontsize=18) # 添加大標題 plt.tight_layout(pad=4.5) # 調整不同標題之間間距 ax.text(-2800000, 1000000, '* 原始數據來源:丁香園,n其中台灣及香港數據缺失') # 添加數據說明 fig.savefig('圖28.png', dpi=300)

圖28
2.2.2 搭配matplotlib實現創作
geopandas雖然自帶了如此豐富的地圖繪製功能,但很多時候作圖僅僅靠它是不夠的,想要實現更加個性化的效果,需要結合matplotlib中豐富的功能,如下圖是我隨意結合matplotlib中的若干功能實現的個性化可視化,疊加了較多元素,由於篇幅有限,代碼不在此放出,你可以去文章開頭的Github倉庫查看本文所有代碼,嘗試用你喜歡的顏色來對地圖調色:
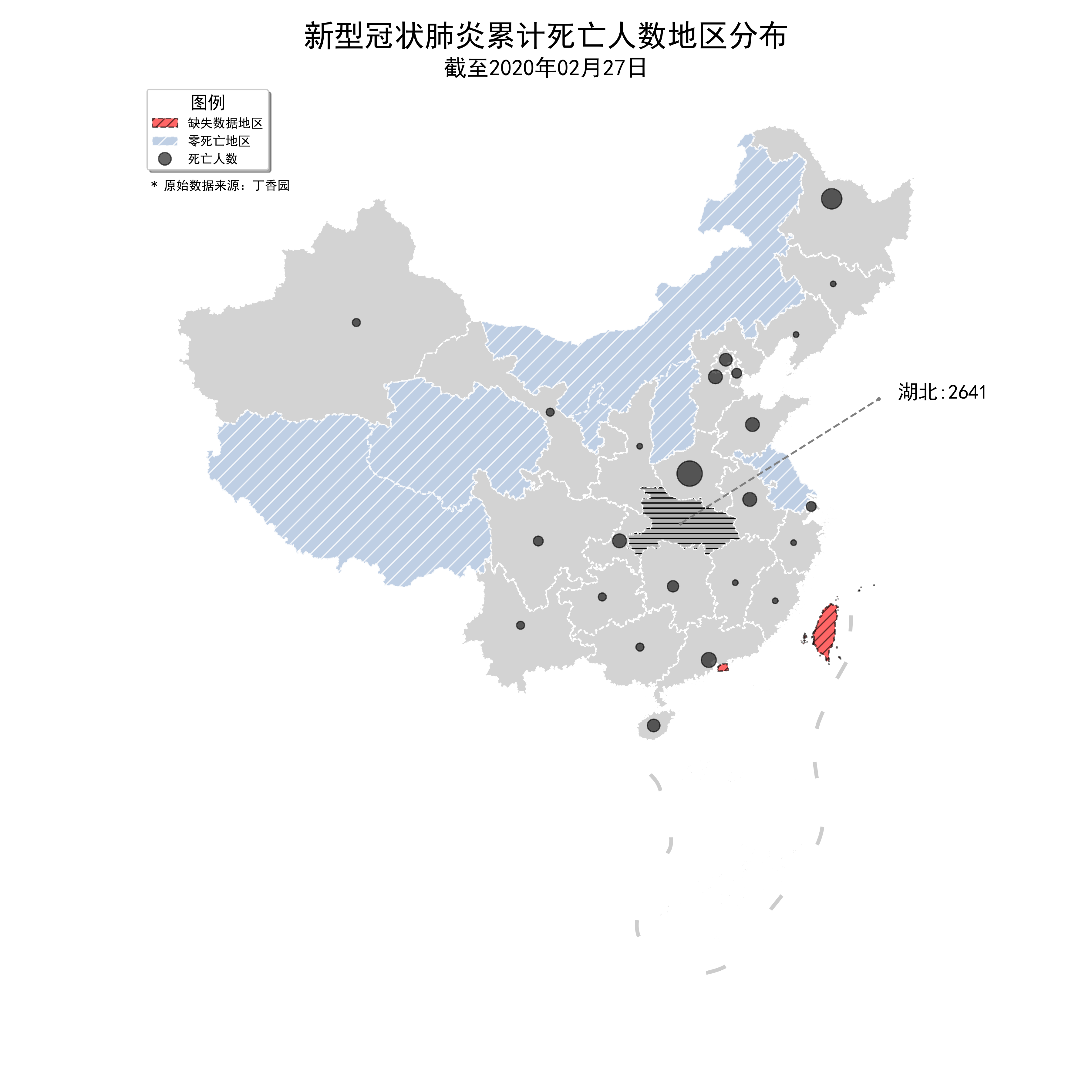
圖29
2.2.3 在模仿中學習
成為數據可視化專家不是一件容易的事,但我們可以先從模仿其他大師的優秀作品出發,譬如圖30來自於Github倉庫https://github.com/Z3tt/TidyTuesday ,這個倉庫包含了眾多基於R的優秀作品,而圖30就是其中之一,對澳洲大火造成的影響進行可視化:

圖30
而下面的圖31就是我利用geopandas對圖30的大致模仿,其中字體部分原始的R腳本中使用ggtext實現方便的富文本生成,而Python中我暫時沒找到類似功能的輪子,所以這裡文字部分比較簡陋:

圖31
對應的代碼如下,其中使用到的矢量數據是我搜集到的精度較高的世界地圖數據:
world = gpd.read_file('world') world['SOVEREI'] smoke_list = ['Denmark', 'France', 'Spain', 'Sweden', 'Norway', 'Germany', 'Finland', 'Poland', 'Italy', 'Greenland'] burnt_list = ['Latvia'] fig, ax = plt.subplots(figsize=(8, 8)) crs = '+proj=moll +lon_0=0 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs' # 繪製過煙區域 ax = world[world['SOVEREI'].isin(smoke_list)] .to_crs(crs) .plot(ax=ax, facecolor='#d9c09e', edgecolor='#c49c67', linewidth=0.2) # 繪製拉脫維亞 ax = world[world['SOVEREI'].isin(burnt_list)] .to_crs(crs) .plot(ax=ax, facecolor='#c82626', edgecolor='#9d1e1e', linewidth=0.2) # 繪製剩餘國家 ax = world[-(world['SOVEREI'].isin(smoke_list) | world['SOVEREI'].isin(burnt_list))] .to_crs(crs) .plot(ax=ax, facecolor='lightgrey', edgecolor='grey', linewidth=0.05, alpha=0.7) ax.set_xlim([-3200000, 2300000]) ax.set_ylim([4100000, 9000000]) ax.axis('off') # 添加文字 plt.text(-3*10**6, 5.5*10**6, ''' 由2019/20澳洲大火所導致 的灌木叢、森林以及公園焚 毀面積比拉脫維亞國土還要 大,產生的濃煙也已經覆蓋 了丹麥全境(包括格陵蘭島 和法羅群島)島嶼)、法國、 西班牙、瑞典、挪威、德國、 芬蘭、波蘭和意大利 ''', fontdict={ 'color': 'black', 'weight': 'bold', 'size': 13 }) plt.savefig('圖31.png', dpi=500)
以上就是本文的全部內容,如有筆誤望指出,接下來的文章我將會繼續介紹更高級的地圖可視化方法,敬請期待!

