PGL圖學習之圖神經網絡GraphSAGE、GIN圖採樣算法[系列七]
0. PGL圖學習之圖神經網絡GraphSAGE、GIN圖採樣算法[系列七]
本項目鏈接://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1
相關項目參考:更多資料見主頁
關於圖計算&圖學習的基礎知識概覽:前置知識點學習(PGL)[系列一] //aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1
圖機器學習(GML)&圖神經網絡(GNN)原理和代碼實現(前置學習系列二)://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1
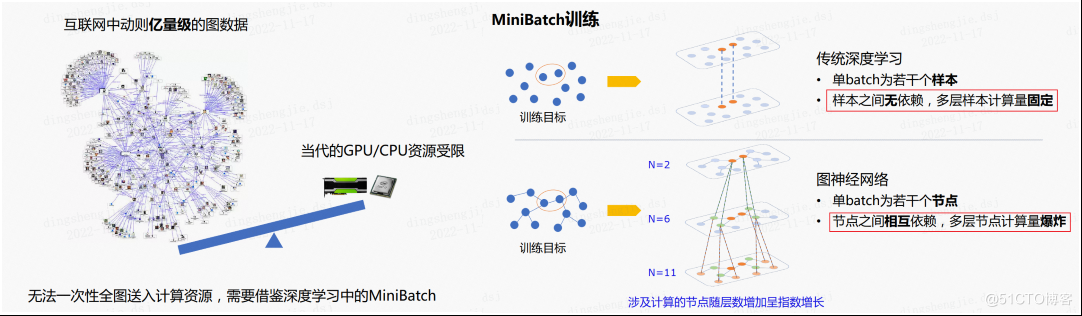
在圖神經網絡中,使用的數據集可能是億量級的數據,而由於GPU/CPU資源有限無法一次性全圖送入計算資源,需要借鑒深度學習中的mini-batch思想。
傳統的深度學習mini-batch訓練每個batch的樣本之間無依賴,多層樣本計算量固定;而在圖神經網絡中,每個batch中的節點之間互相依賴,在計算多層時會導致計算量爆炸,因此引入了圖採樣的概念。
GraphSAGE也是圖嵌入算法中的一種。在論文Inductive Representation Learning on Large Graphs 在大圖上的歸納表示學習中提出。github鏈接和官方介紹鏈接。
與node2vec相比較而言,node2vec是在圖的節點級別上進行嵌入,GraphSAGE則是在整個圖的級別上進行嵌入。之前的網絡表示學習的transductive,難以從而提出了一個inductive的GraphSAGE算法。GraphSAGE同時利用節點特徵信息和結構信息得到Graph Embedding的映射,相比之前的方法,之前都是保存了映射後的結果,而GraphSAGE保存了生成embedding的映射,可擴展性更強,對於節點分類和鏈接預測問題的表現也比較突出。
0.1提出背景
現存的方法需要圖中所有的頂點在訓練embedding的時候都出現;這些前人的方法本質上是transductive,不能自然地泛化到未見過的頂點。文中提出了GraphSAGE,是一個inductive的框架,可以利用頂點特徵信息(比如文本屬性)來高效地為沒有見過的頂點生成embedding。GraphSAGE是為了學習一種節點表示方法,即如何通過從一個頂點的局部鄰居採樣並聚合頂點特徵,而不是為每個頂點訓練單獨的embedding。
這個算法在三個inductive頂點分類benchmark上超越了那些很強的baseline。文中基於citation和Reddit帖子數據的信息圖中對未見過的頂點分類,實驗表明使用一個PPI(protein-protein interactions)多圖數據集,算法可以泛化到完全未見過的圖上。
0.2 回顧GCN及其問題
在大型圖中,節點的低維向量embedding被證明了作為各種各樣的預測和圖分析任務的特徵輸入是非常有用的。頂點embedding最基本的基本思想是使用降維技術從高維信息中提煉一個頂點的鄰居信息,存到低維向量中。這些頂點嵌入之後會作為後續的機器學習系統的輸入,解決像頂點分類、聚類、鏈接預測這樣的問題。
- GCN雖然能提取圖中頂點的embedding,但是存在一些問題:
- GCN的基本思想: 把一個節點在圖中的高緯度鄰接信息降維到一個低維的向量表示。
- GCN的優點: 可以捕捉graph的全局信息,從而很好地表示node的特徵。
- GCN的缺點: Transductive learning的方式,需要把所有節點都參與訓練才能得到node embedding,無法快速得到新node的embedding。
1.圖採樣算法
1.1 GraphSage: Representation Learning on Large Graphs
圖採樣算法:顧名思義,圖採樣算法就是在一張圖中進行採樣得到一個子圖,這裡的採樣並不是隨機採樣,而是採取一些策略。典型的圖採樣算法包括GraphSAGE、PinSAGE等。
文章碼源鏈接:
//cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf
//github.com/williamleif/GraphSAGE
前面 GCN 講解的文章中,我使用的圖節點個數非常少,然而在實際問題中,一張圖可能節點非常多,因此就沒有辦法一次性把整張圖送入計算資源,所以我們應該使用一種有效的採樣算法,從全圖中採樣出一個子圖 ,這樣就可以進行訓練了。
GraphSAGE與GCN對比:
既然新增的節點,一定會改變原有節點的表示,那麼為什麼一定要得到每個節點的一個固定的表示呢?何不直接學習一種節點的表示方法。去學習一個節點的信息是怎麼通過其鄰居節點的特徵聚合而來的。 學習到了這樣的「聚合函數」,而我們本身就已知各個節點的特徵和鄰居關係,我們就可以很方便地得到一個新節點的表示了。
GCN等transductive的方法,學到的是每個節點的一個唯一確定的embedding; 而GraphSAGE方法學到的node embedding,是根據node的鄰居關係的變化而變化的,也就是說,即使是舊的node,如果建立了一些新的link,那麼其對應的embedding也會變化,而且也很方便地學到。

在了解圖採樣算法前,我們至少應該保證採樣後的子圖是連通的。例如上圖圖中,左邊採樣的子圖就是連通的,右邊的子圖不是連通的。
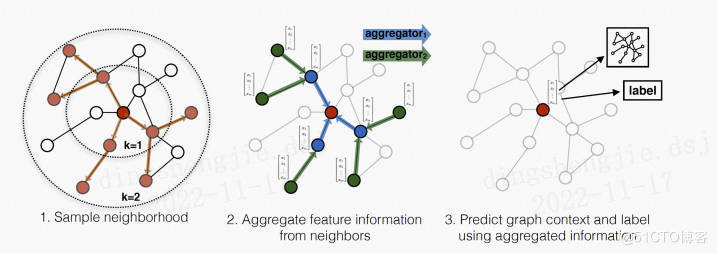
GraphSAGE的核心:GraphSAGE不是試圖學習一個圖上所有node的embedding,而是學習一個為每個node產生embedding的映射。 GraphSage框架中包含兩個很重要的操作:Sample採樣和Aggregate聚合。這也是其名字GraphSage(Graph SAmple and aggreGatE)的由來。GraphSAGE 主要分兩步:採樣、聚合。GraphSAGE的採樣方式是鄰居採樣,鄰居採樣的意思是在某個節點的鄰居節點中選擇幾個節點作為原節點的一階鄰居,之後對在新採樣的節點的鄰居中繼續選擇節點作為原節點的二階節點,以此類推。
文中不是對每個頂點都訓練一個單獨的embeddding向量,而是訓練了一組aggregator functions,這些函數學習如何從一個頂點的局部鄰居聚合特徵信息(見圖1)。每個聚合函數從一個頂點的不同的hops或者說不同的搜索深度聚合信息。測試或是推斷的時候,使用訓練好的系統,通過學習到的聚合函數來對完全未見過的頂點生成embedding。
GraphSAGE 是Graph SAmple and aggreGatE的縮寫,其運行流程如上圖所示,可以分為三個步驟:
- 對圖中每個頂點鄰居頂點進行採樣,因為每個節點的度是不一致的,為了計算高效, 為每個節點採樣固定數量的鄰居
- 根據聚合函數聚合鄰居頂點蘊含的信息
- 得到圖中各頂點的向量表示供下游任務使用
鄰居採樣的優點:
- 極大減少計算量
- 允許泛化到新連接關係,個人理解類似dropout的思想,能增強模型的泛化能力
採樣的階段首先選取一個點,然後隨機選取這個點的一階鄰居,再以這些鄰居為起點隨機選擇它們的一階鄰居。例如下圖中,我們要預測 0 號節點,因此首先隨機選擇 0 號節點的一階鄰居 2、4、5,然後隨機選擇 2 號節點的一階鄰居 8、9;4 號節點的一階鄰居 11、12;5 號節點的一階鄰居 13、15
聚合具體來說就是直接將子圖從全圖中抽離出來,從最邊緣的節點開始,一層一層向里更新節點
上圖展示了鄰居採樣的優點,極大減少訓練計算量這個是毋庸置疑的,泛化能力增強這個可能不太好理解,因為原本要更新一個節點需要它周圍的所有鄰居,而通過鄰居採樣之後,每個節點就不是由所有的鄰居來更新它,而是部分鄰居節點,所以具有比較強的泛化能力。
1.1.1 論文角度看GraphSage
聚合函數的選取
在圖中頂點的鄰居是無序的,所以希望構造出的聚合函數是對稱的(即也就是對它輸入的各種排列,函數的輸出結果不變),同時具有較高的表達能力。 聚合函數的對稱性(symmetry property)確保了神經網絡模型可以被訓練且可以應用於任意順序的頂點鄰居特徵集合上。
**a. Mean aggregator **:
mean aggregator將目標頂點和鄰居頂點的第$k−1$層向量拼接起來,然後對向量的每個維度進行求均值的操作,將得到的結果做一次非線性變換產生目標頂點的第$k$層表示向量。
卷積聚合器Convolutional aggregator:
文中用下面的式子替換算法1中的4行和5行得到GCN的inductive變形:
原始算法1中的第4,5行是
論文提出的均值聚合器Mean aggregator:
- 均值聚合近似等價在transducttive GCN框架中的卷積傳播規則
- 這個修改後的基於均值的聚合器是convolutional的。但是這個卷積聚合器和文中的其他聚合器的重要不同在於它沒有算法1中第5行的CONCAT操作——卷積聚合器沒有將頂點前一層的表示$\mathbf{h}{k-1}_{v}$聚合的鄰居向量$\mathbf{h}k_{\mathcal{N}(v)}$拼接起來
- 拼接操作可以看作一個是GraphSAGE算法在不同的搜索深度或層之間的簡單的skip connection[Identity mappings in deep residual networks]的形式,它使得模型的表徵性能獲得了巨大的提升
- 舉個簡單例子,比如一個節點的3個鄰居的embedding分別為[1,2,3,4],[2,3,4,5],[3,4,5,6]按照每一維分別求均值就得到了聚合後的鄰居embedding為[2,3,4,5]
b. LSTM aggregator
文中也測試了一個基於LSTM的複雜的聚合器[Long short-term memory]。和均值聚合器相比,LSTMs有更強的表達能力。但是,LSTMs不是對稱的(symmetric),也就是說不具有排列不變性(permutation invariant),因為它們以一個序列的方式處理輸入。因此,需要先對鄰居節點隨機順序,然後將鄰居序列的embedding作為LSTM的輸入。
- 排列不變性(permutation invariance):指輸入的順序改變不會影響輸出的值。
c. Pooling aggregator
pooling聚合器,它既是對稱的,又是可訓練的。Pooling aggregator 先對目標頂點的鄰居頂點的embedding向量進行一次非線性變換,之後進行一次pooling操作(max pooling or mean pooling),將得到結果與目標頂點的表示向量拼接,最後再經過一次非線性變換得到目標頂點的第k層表示向量。
一個element-wise max pooling操作應用在鄰居集合上來聚合信息:
有了GCN為啥還要GraphSAGE?
GCN靈活性差、為新節點產生embedding要求 額外的操作 ,比如「對齊」:
GCN是 直推式(transductive) 學習,無法直接泛化到新加入(未見過)的節點;
GraphSAGE是 歸納式(inductive) 學習,可以為新節點輸出節點特徵。
GCN輸出固定:
GCN輸出的是節點 唯一確定 的embedding;
GraphSAGE學習的是節點和鄰接節點之間的關係,學習到的是一種 映射關係 ,節點的embedding可以隨着其鄰接節點的變化而變化。
GCN很難應用在超大圖上:
無論是拉普拉斯計算還是圖卷積過程,因為GCN其需要對 整張圖 進行計算,所以計算量會隨着節點數的增加而遞增。
GraphSAGE通過採樣,能夠形成 minibatch 來進行批訓練,能用在超大圖上
GraphSAGE有什麼優點?
採用 歸納學習 的方式,學習鄰居節點特徵關係,得到泛化性更強的embedding;
採樣技術,降低空間複雜度,便於構建minibatch用於 批訓練 ,還讓模型具有更好的泛化性;
多樣的聚合函數 ,對於不同的數據集/場景可以選用不同的聚合方式,使得模型更加靈活。
採樣數大於鄰接節點數怎麼辦?
設採樣數量為K:
若節點鄰居數少於K,則採用 有放回 的抽樣方法,直到採樣出K個節點。
若節點鄰居數大於K,則採用 無放回 的抽樣。
訓練好的GraphSAGE如何得到節點Embedding?
假設GraphSAGE已經訓練好,我們可以通過以下步驟來獲得節點embedding,具體算法請看下圖的算法1。
訓練過程則只需要將其產生的embedding扔進損失函數計算並反向梯度傳播即可。
對圖中每個節點的鄰接節點進行 採樣 ,輸入節點及其n階鄰接節點的特徵向量
根據K層的 聚合函數 聚合鄰接節點的信息
就產生了各節點的embedding

minibatch的子圖是怎麼得到的?

那和DeepWalk、Node2vec這些有什麼不一樣?
DeepWalk、Node2Vec這些embedding算法直接訓練每個節點的embedding,本質上依然是直推式學習,而且需要大量的額外訓練才能使他們能預測新的節點。同時,對於embedding的正交變換(orthogonal transformations),這些方法的目標函數是不變的,這意味着生成的向量空間在不同的圖之間不是天然泛化的,在再次訓練(re-training)時會產生漂移(drift)。
與DeepWalk不同的是,GraphSAGE是通過聚合節點的鄰接節點特徵產生embedding的,而不是簡單的進行一個embedding lookup操作得到。
論文仿真結果:
實驗對比了四個基線:隨機分類,基於特徵的邏輯回歸(忽略圖結構),DeepWalk算法,DeepWork+特徵;同時還對比了四種GraphSAGE,其中三種在3.3節中已經說明,GraphSAGE-GCN是GCNs的歸納版本。具體超參數為:K=2,s1=25,s2=10。程序使用TensorFlow編寫,Adam優化器。
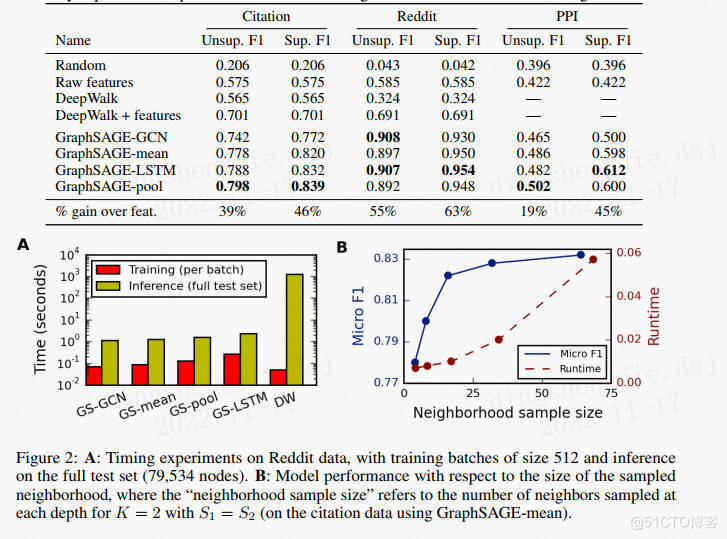
對於跨圖泛化的任務,需要學習節點角色而不是訓練圖的結構。使用跨各種生物蛋白質-蛋白質相互作用(PPI)圖,對蛋白質功能進行分類。在20個圖表上訓練算法,2個圖用於測試,2個圖用於驗證,平均每圖包含2373個節點,平均度為28.8。從實驗結果可以看出LSTM和池化方法比Mean和GCN效果更好。
對比不同聚合函數:
如表-1所示,LSTM和POOL方法效果最好,與其它方法相比有顯著差異,LSTM和POOL之間無顯著差異,但LSTM比POOL慢得多(≈2x),使POOL聚合器在總體上略有優勢。
1.1.2 更多問題
採樣
為什麼要採樣?
採樣數大於鄰接節點數怎麼辦?
採樣的鄰居節點數應該選取多大?
每一跳採樣需要一樣嗎?
適合有向邊嗎?
採樣是隨機的嗎?
聚合函數
聚合函數的選取有什麼要求?
GraphSAGE論文中提供多少種聚合函數?
均值聚合的操作是怎樣的?
pooling聚合的操作是怎樣的?
使用LSTM聚合時需要注意什麼?
均值聚合和其他聚合函數有啥區別?
max-和mean-pooling有什麼區別?
這三種聚合方法,哪種比較好?
一般聚合多少層?層數越多越好嗎?
什麼時候和GCN的聚合形式「等價」?
無監督學習
GraphSAGE怎樣進行無監督學習?
GraphSAGE如何定義鄰近和遠處的節點?
如何計算無監督GraphSAGE的損失函數?
GraphSAGE是怎麼隨機遊走的?
GraphSAGE什麼時候考慮邊的權重了?
訓練
如果只有圖、沒有節點特徵,能否使用GraphSAGE?
訓練好的GraphSAGE如何得到節點Embedding?
minibatch的子圖是怎麼得到的?
增加了新的節點來訓練,需要為所有「舊」節點重新輸出embeding嗎?
GraphSAGE有監督學習有什麼不一樣的地方嗎?
參考鏈接://zhuanlan.zhihu.com/p/184991506
//blog.csdn.net/yyl424525/article/details/100532849
1.2 PinSAGE
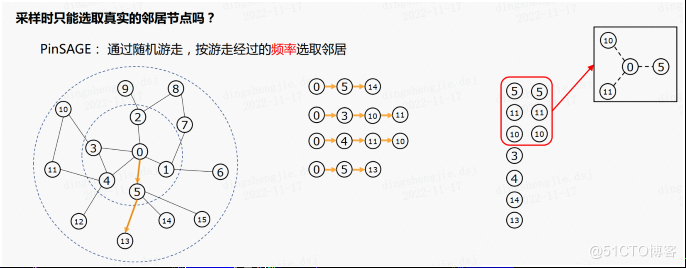
採樣時只能選取真實的鄰居節點嗎?如果構建的是一個與虛擬鄰居相連的子圖有什麼優點?PinSAGE 算法將會給我們解答,PinSAGE 算法通過多次隨機遊走,按遊走經過的頻率選取鄰居,上圖右側為進行隨機遊走得到的節點序列,統計序列的頻數可以發現節點5,10,11的頻數為2,其餘為1,當我們希望採樣三個節點時,我們選取5,10,11作為0號節點的虛擬鄰居。之後如果希望得到0號節點的二階虛擬鄰居則在已採樣的節點繼續進行隨機遊走即可。
回到上述問題,採樣時選取虛擬鄰居有什麼好處?這種採樣方式的好處是我們能更快的聚合到遠處節點的信息。。實際上如果是按照 GraphSAGE 算法的方式生成子圖,在聚合的過程中,非一階鄰居的信息可以通過消息傳遞逐漸傳到中心,但是隨着距離的增大,離中心越遠的節點,其信息在傳遞過程中就越困難,甚至可能無法傳遞到;如果按照 PinSAGE 算法的方式生成子圖,有一定的概率可以將非一階鄰居與中心直接相連,這樣就可以快速聚合到多階鄰居的信息
1.2.1論文角度看PinSAGE
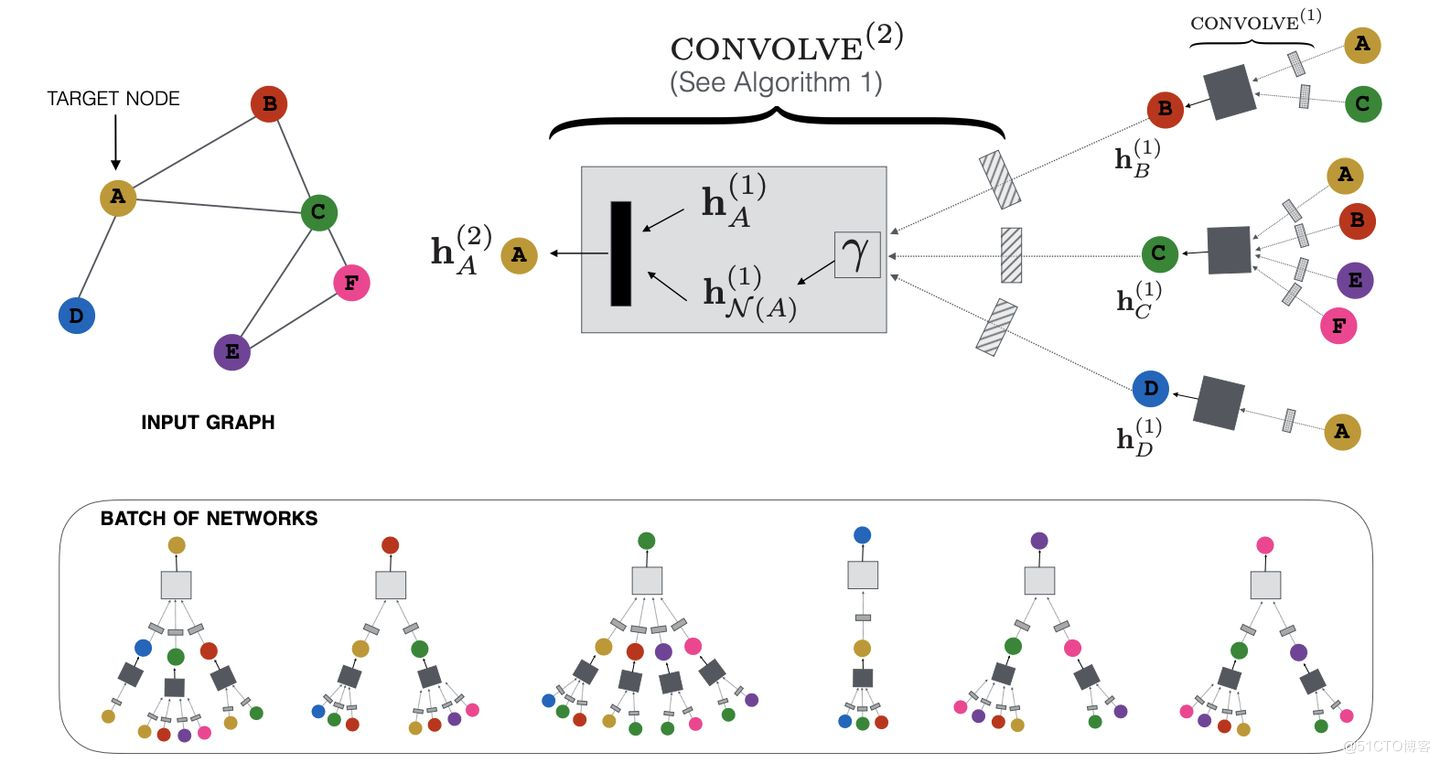
和GraphSAGE相比,PinSAGE改進了什麼?
- 採樣 :使用重要性採樣替代GraphSAGE的均勻採樣;
- 聚合函數 :聚合函數考慮了邊的權重;
- 生產者-消費者模式的minibatch構建 :在CPU端採樣節點和構建特徵,構建計算圖;在GPU端在這些子圖上進行卷積運算;從而可以低延遲地隨機遊走構建子圖,而不需要把整個圖存在顯存中。
- 高效的MapReduce推理 :可以分佈式地為百萬以上的節點生成embedding,最大化地減少重複計算。
這裡的計算圖,指的是用於卷積運算的局部圖(或者叫子圖),通過採樣來形成;與TensorFlow等框架的計算圖不是一個概念。
PinSAGE使用多大的計算資源?
訓練時,PinSAGE使用32核CPU、16張Tesla K80顯卡、500GB內存;
推理時,MapReduce運行在378個d2.8xlarge Amazon AWS節點的Hadoop2集群。
PinSAGE和node2vec、DeepWalk這些有啥區別?
node2vec,DeepWalk是無監督訓練;PinSAGE是有監督訓練;
node2vec,DeepWalk不能利用節點特徵;PinSAGE可以;
node2vec,DeepWalk這些模型的參數和節點數呈線性關係,很難應用在超大型的圖上;
PinSAGE的單層聚合過程是怎樣的?
和GraphSAGE一樣,PinSAGE的核心就是一個 局部卷積算子 ,用來學習如何聚合鄰居節點信息。
如下圖算法1所示,PinSAGE的聚合函數叫做CONVOLVE。主要分為3部分:
- 聚合 (第1行):k-1層鄰居節點的表徵經過一層DNN,然後聚合(可以考慮邊的權重),是聚合函數符號,聚合函數可以是max/mean-pooling、加權求和、求平均;
- 更新 (第2行): 拼接 第k-1層目標節點的embedding,然後再經過另一層DNN,形成目標節點新的embedding;
- 歸一化 (第3行): 歸一化 目標節點新的embedding,使得訓練更加穩定;而且歸一化後,使用近似最近鄰居搜索的效率更高。

PinSAGE是如何採樣的?
如何採樣這個問題從另一個角度來看就是:如何為目標節點構建鄰居節點。
和GraphSAGE的均勻採樣不一樣的是,PinSAGE使用的是重要性採樣。
PinSAGE對鄰居節點的定義是:對目標節點 影響力最大 的T個節點。
PinSAGE的鄰居節點的重要性是如何計算的?
其影響力的計算方法有以下步驟:
從目標節點開始隨機遊走;
使用 正則 來計算節點的「訪問次數」,得到重要性分數;
目標節點的鄰居節點,則是重要性分數最高的前T個節點。
這個重要性分數,其實可以近似看成Personalized PageRank分數。
關於隨機遊走,可以閱讀《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》
重要性採樣的好處是什麼?
和GraphSAGE一樣,可以使得 鄰居節點的數量固定 ,便於控制內存/顯存的使用。
在聚合鄰居節點時,可以考慮節點的重要性;在PinSAGE實踐中,使用的就是 加權平均 (weighted-mean),原文把它稱作 importance pooling 。
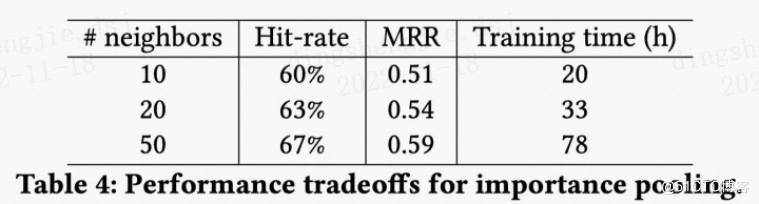
採樣的大小是多少比較好?
從PinSAGE的實驗可以看出,隨着鄰居節點的增加,而收益會遞減;
並且兩層GCN在 鄰居數為50 時能夠更好的抓取節點的鄰居信息,同時保持運算效率。
PinSage論文中還介紹了落地過程中採用的大量工程技巧。
-
負樣本生成:首先是簡單採樣:在每個minibatch包含節點的範圍之外隨機採樣500個item作為minibatch所有正樣本共享的負樣本集合。但考慮到實際場景中模型需要從20億的物品item集合中識別出最相似的1000個,即要從2百萬中識別出最相似的那一個,只是簡單採樣會導致模型分辨的粒度過粗,分辨率只到500分之一,因此增加一種「hard」負樣本,即對於每個 對,和物品q有些相似但和物品i不相關的物品集合。這種樣本的生成方式是將圖中節點根據相對節點q的個性化PageRank分值排序,隨機選取排序位置在2000~5000的物品作為「hard」負樣本,以此提高模型分辨正負樣本的難度。
-
漸進式訓練(Curriculum training:如果訓練全程都使用hard負樣本,會導致模型收斂速度減半,訓練時長加倍,因此PinSage採用了一種Curriculum訓練的方式,這裡我理解是一種漸進式訓練方法,即第一輪訓練只使用簡單負樣本,幫助模型參數快速收斂到一個loss比較低的範圍;後續訓練中逐步加入hard負樣本,讓模型學會將很相似的物品與些微相似的區分開,方式是第n輪訓練時給每個物品的負樣本集合中增加n-1個hard負樣本。
-
樣本的特徵信息:Pinterest的業務場景中每個pin通常有一張圖片和一系列的文字標註(標題,描述等),因此原始圖中每個節點的特徵表示由圖片Embedding(4096維),文字標註Embedding(256維),以及節點在圖中的度的log值拼接而成。其中圖片Embedding由6層全連接的VGG-16生成,文字標註Embedding由Word2Vec訓練得到。
-
基於random walk的重要性採樣:用於鄰居節點採樣,這一技巧在上面的算法理解部分已經講解過,此處不再贅述。
-
基於重要性的池化操作:這一技巧用於上一節Convolve算法中的 函數中,聚合經過一層dense層之後的鄰居節點Embedding時,基於random walk計算出的節點權重做聚合操作。據論文描述,這一技巧在離線評估指標中提升了46%。
-
on-the-fly convolutions:快速卷積操作,這個技巧主要是相對原始GCN中的卷積操作:特徵矩陣與全圖拉普拉斯矩陣的冪相乘。涉及到全圖的都是計算量超高,這裡GraphSage和PinSage都是一致地使用採樣鄰居節點動態構建局部計算圖的方法提升訓練效率,只是二者採樣的方式不同。
-
生產者消費者模式構建minibatch:這個點主要是為了提高模型訓練時GPU的利用率。保存原始圖結構的鄰居表和數十億節點的特徵矩陣只能放在CPU內存中,GPU執行convolve卷積操作時每次從CPU取數據是很耗時的。為了解決這個問題,PinSage使用re-index技術創建當前minibatch內節點及其鄰居組成的子圖,同時從數十億節點的特徵矩陣中提取出該子圖節點對應的特徵矩陣,注意提取後的特徵矩陣中的節點索引要與前面子圖中的索引保持一致。這個子圖的鄰接列表和特徵矩陣作為一個minibatch送入GPU訓練,這樣一來,convolve操作過程中就沒有GPU與CPU的通信需求了。訓練過程中CPU使用OpenMP並設計了一個producer-consumer模式,CPU負責提取特徵,re-index,負採樣等計算,GPU只負責模型計算。這個技巧降低了一半的訓練耗時。
-
多GPU訓練超大batch:前向傳播過程中,各個GPU等分minibatch,共享一套參數,反向傳播時,將每個GPU中的參數梯度都聚合到一起,執行同步SGD。為了適應海量訓練數據的需要,增大batchsize從512到4096。為了在超大batchsize下快速收斂保證泛化精度,採用warmup過程:在第一個epoch中將學習率線性提升到最高,後面的epoch中再逐步指數下降。
-
使用MapReduce高效推斷:模型訓練完成後生成圖中各個節點的Embedding過程中,如果直接使用上述PinSage的minibatch算法生Embedding,會有大量的重複計算,如計算當前target節點的時候,其相當一部分鄰居節點已經計算過Embedding了,而當這些鄰居節點作為target節點的時候,當前target節點極有可能需要再重新計算一遍,這一部分的重複計算既耗時又浪費。
1.2.2更多問題
聚合函數
PinSAGE的單層聚合過程是怎樣的?
為什麼要將鄰居節點的聚合embedding和當前節點的拼接?
採樣
PinSAGE是如何採樣的?
PinSAGE的鄰居節點的重要性是如何計算的?
重要性採樣的好處是什麼?
採樣的大小是多少比較好?
MiniBatch
PinSAGE的minibatch和GraphSAGE有啥不一樣?
batch應該選多大?
訓練
PinSAGE使用什麼損失函數?
PinSAGE如何定義標籤(正例/負例)?
PinSAGE用什麼方法提高模型訓練的魯棒性和收斂性?
負採樣
PinSAGE如何進行負採樣?
訓練時簡單地負採樣,會有什麼問題?
如何解決簡單負採樣帶來的問題?
如果只使用「hard」負樣本,會有什麼問題?
如何解決只使用「hard」負採樣帶來的問題?
如何區分採樣、負採樣、」hard「負採樣?
推理
直接為使用訓練好的模型產生embedding有啥問題?
如何解決推理時重複計算的問題?
下游任務如何應用PinSAGE產生的embedding?
如何為用戶進行個性化推薦?
工程性技巧
pin樣本的特徵如何構建?
board樣本的特徵如何構建?
如何使用多GPU並行訓練PinSAGE?
PinSAGE為什麼要使用生產者-消費者模式?
PinSAGE是如何使用生產者-消費者模式?
//zhuanlan.zhihu.com/p/195735468
//zhuanlan.zhihu.com/p/133739758?utm_source=wechat_session&utm_id=0
1.3 小結
學習大圖、不斷擴展的圖,未見過節點的表徵,是一個很常見的應用場景。GraphSAGE通過訓練聚合函數,實現優化未知節點的表示方法。之後提出的GAN(圖注意力網絡)也針對此問題優化。
論文中提出了:傳導性問題和歸納性問題,傳導性問題是已知全圖情況,計算節點表徵向量;歸納性問題是在不完全了解全圖的情況下,訓練節點的表徵函數(不是直接計算向量表示)。
圖工具的處理過程每輪迭代( 一次propagation)一般都包含:收集信息、聚合、更新,從本文也可以更好地理解,其中聚合的重要性,及優化方法。
GraohSage主要貢獻如下:
- 針對問題:大圖的節點表徵
- 結果:訓練出的模型可應用於表徵沒見過的節點
- 核心方法:改進圖卷積方法;從鄰居節點中採樣;考慮了節點特徵,加入更複雜的特徵聚合方法
一般情況下一個節點的表式通過聚合它k跳之內的鄰近節點計算,而全圖的表示則通過對所有節點的池化計算。GIN使用了WL-test方法,即圖同構測試,它是一個區分網絡結構的強效方法,也是通過迭代聚合鄰居的方法來更新節點,它的強大在於使用了injective(見後)聚合更新方法。而這裡要評測GNN是否能達到類似WL-test的效果。文中還使用了多合集multiset的概念,指可能包含重複元素的集合。
GIN主要貢獻如下:
- 展示了GNN模型可達到與WL-test類似的圖結構區分效果
- 設計了聚合函數和Readout函數,使GNN能達到更好的區分效果
- 發現GCN及GraphSAGE無法很好表達圖結構,而GNN可以
- 開發了簡單的網絡結構GIN(圖同構網絡),它的區分和表示能力與WL-test類似。
2.鄰居聚合
在圖採樣之後,我們需要進行鄰居聚合的操作。經典的鄰居聚合函數包括取平均、取最大值、求和。
評估聚合表達能力的指標——單射(一對一映射),在上述三種經典聚合函數中,取平均傾向於學習分佈,取最大值傾向於忽略重複值,這兩個不屬於單射,而求和能夠保留鄰居節點的完整信息,是單射。單射的好處是可以保證對聚合後的結果可區分。

2.1 GIN模型的聚合函數
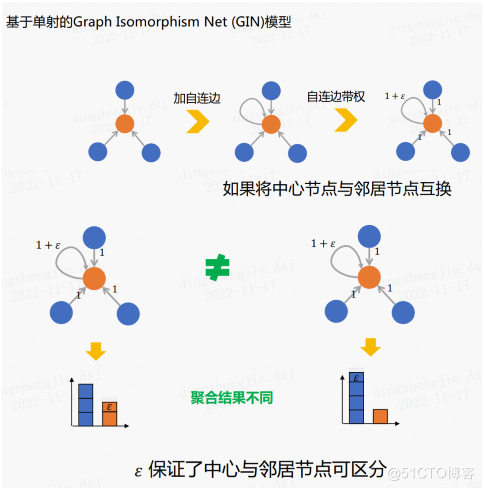
Graph Isomorphic Net(GIN)的聚合部分是基於單射的。
如上圖所示,GIN的聚合函數使用的是求和函數,它特殊的一點是在中心節點加了一個自連邊(自環),之後對自連邊進行加權。
這樣做的好處是即使我們調換了中心節點和鄰居節點,得到的聚合結果依舊是不同的。所以帶權重的自連邊能夠保證中心節點和鄰居節點可區分。
2.2其他複雜的聚合函數
2.3 令居聚合語義場景
3.數據集介紹
數據源://snap.stanford.edu/graphsage/ 斯坦福
3.1 Citation數據集
使用科學網引文數據集,將學術論文分類為不同的主題。數據集共包含302424個節點,平均度9.15,使用2000-2004年數據作為訓練集,2005年數據作為測試集。使用節點的度以及論文摘要的句嵌入作為特徵。
3.2 Reddit數據集
//aistudio.baidu.com/aistudio/datasetdetail/177810
將Reddit帖子歸類為屬於不同社區。數據集包含232965個帖子,平均度為492。使用現成的300維GloVe Common Crawl單詞向量;對於每個帖子,使用特徵包含:(1) 帖子標題的平均嵌入 (2) 帖子所有評論的平均嵌入 (3) 帖子的分數 (4)帖子的評論數量
為了對社區進行抽樣,根據 2014 年的評論總數對社區進行了排名,並選擇了排名 [11,50](含)的社區。省略了最大的社區,因為它們是大型的通用默認社區,大大扭曲了類分佈。選擇了在這些社區的聯合上定義的圖中最大的連通分量。
更多數據資料見:
//files.pushshift.io/reddit/comments/
//github.com/dingidng/reddit-dataset
最新數據已經更新到2022.10了
3.3 PPI(Protein–protein interactions)蛋白質交互作用
//aistudio.baidu.com/aistudio/datasetdetail/177807
PPI 網絡是蛋白質相互作用(Protein-Protein Interaction,PPI)網絡的簡稱,在GCN中主要用於節點分類任務
PPI是指兩種或以上的蛋白質結合的過程,通常旨在執行其生化功能。
一般地,如果兩個蛋白質共同參與一個生命過程或者協同完成某一功能,都被看作這兩個蛋白質之間存在相互作用。多個蛋白質之間的複雜的相互作用關係可以用PPI網絡來描述。
PPI數據集共24張圖,每張圖對應不同的人體組織,平均每張圖有2371個節點,共56944個節點818716條邊,每個節點特徵長度為50,其中包含位置基因集,基序集和免疫學特徵。基因本體基作為label(總共121個),label不是one-hot編碼。
-
alid_feats.npy文件保存節點的特徵,shape為(56944, 50)(節點數目,特徵維度),值為0或1,且1的數目稀少
-
ppi-class_map.json為節點的label文件,shape為(121, 56944),每個節點的label為121維
-
ppi-G.json文件為節點和鏈接的描述信息,節點:{“test”: true, “id”: 56708, “val”: false}, 表示節點id為56708的節點是否為test集或者val集,鏈接:”links”: [{“source”: 0, “target”: 372}, {“source”: 0, “target”: 1101}, 表示節點id為0的節點和為1101的節點之間有links,
-
ppi-walks.txt文件中為鏈接信息
-
ppi-id_map.json文件為節點id信息
參考鏈接:
//blog.csdn.net/ziqingnian/article/details/112979175
4 基於PGL算法實踐
4.1 GraphSAGE
GraphSAGE是一個通用的歸納框架,它利用節點特徵信息(例如,文本屬性)為以前看不見的數據有效地生成節點嵌入。GraphSAGE 不是為每個節點訓練單獨的嵌入,而是學習一個函數,該函數通過從節點的本地鄰域中採樣和聚合特徵來生成嵌入。基於PGL,我們重現了GraphSAGE算法,在Reddit Dataset中達到了與論文同等水平的指標。此外,這是PGL中子圖採樣和訓練的一個例子。
超參數
epoch: Number of epochs default (10)
normalize: Normalize the input feature if assign normalize.
sample_workers: The number of workers for multiprocessing subgraph sample.
lr: Learning rate.
symmetry: Make the edges symmetric if assign symmetry.
batch_size: Batch size.
samples: The max neighbors for each layers hop neighbor sampling. (default: [25, 10])
hidden_size: The hidden size of the GraphSAGE models.
parser = argparse.ArgumentParser(description='graphsage')
parser.add_argument(
"--normalize", action='store_true', help="normalize features") # normalize:歸一化節點特徵
parser.add_argument(
"--symmetry", action='store_true', help="undirect graph") # symmetry:聚合函數的對稱性
parser.add_argument("--sample_workers", type=int, default=5) # sample_workers:多線程數據讀取器的線程個數
parser.add_argument("--epoch", type=int, default=10)
parser.add_argument("--hidden_size", type=int, default=128)
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--lr", type=float, default=0.01)
parser.add_argument('--samples', nargs='+', type=int, default=[25, 10]) # samples_1:第一級鄰居採樣時候選擇的最大鄰居個數(默認25)#,samples_2:第而級鄰居採樣時候選擇的最大鄰居個數(默認10)
部分結果展示:
[INFO] 2022-11-18 16:45:44,177 [ train.py: 63]: Batch 800 train-Loss [0.5213774] train-Acc [0.9140625]
[INFO] 2022-11-18 16:45:45,783 [ train.py: 63]: Batch 900 train-Loss [0.65641916] train-Acc [0.875]
[INFO] 2022-11-18 16:45:47,385 [ train.py: 63]: Batch 1000 train-Loss [0.57411766] train-Acc [0.921875]
[INFO] 2022-11-18 16:45:48,977 [ train.py: 63]: Batch 1100 train-Loss [0.68337256] train-Acc [0.890625]
[INFO] 2022-11-18 16:45:50,434 [ train.py: 160]: Runing epoch:9 train_loss:[0.58635516] train_acc:[0.90786038]
[INFO] 2022-11-18 16:45:57,836 [ train.py: 165]: Runing epoch:9 val_loss:0.55885834 val_acc:0.9139818
[INFO] 2022-11-18 16:46:05,259 [ train.py: 169]: Runing epoch:9 test_loss:0.5578749 test_acc:0.91468066
100%|███████████████████████████████████████████| 10/10 [06:02<00:00, 36.29s/it]
[INFO] 2022-11-18 16:46:05,260 [ train.py: 172]: Runs 0: Model: graphsage Best Test Accuracy: 0.918849
目前官網最佳性能是95.7%,我這裡沒有調參
| Aggregator | Accuracy_me_10 epochs | Accuracy_200 epochs | Reported in paper_200 epochs |
|---|---|---|---|
| Mean | 91.88% | 95.70% | 95.0% |
其餘聚合器下官網和論文性能對比:
| Aggregator | Accuracy_200 epochs | Reported in paper_200 epochs |
|---|---|---|
| Meanpool | 95.60% | 94.8% |
| Maxpool | 94.95% | 94.8% |
| LSTM | 95.13% | 95.4% |
4.2 Graph Isomorphism Network (GIN)
圖同構網絡(GIN)是一個簡單的圖神經網絡,期望達到Weisfeiler-Lehman圖同構測試的能力。基於 PGL重現了 GIN 模型。
超參數
- data_path:數據集的根路徑
- dataset_name:數據集的名稱
- fold_idx:拆分的數據集摺疊。這裡我們使用10折交叉驗證
- train_eps:是否參數是可學習的。
parser.add_argument('--data_path', type=str, default='./gin_data')
parser.add_argument('--dataset_name', type=str, default='MUTAG')
parser.add_argument('--batch_size', type=int, default=32)
parser.add_argument('--fold_idx', type=int, default=0)
parser.add_argument('--output_path', type=str, default='./outputs/')
parser.add_argument('--use_cuda', action='store_true')
parser.add_argument('--num_layers', type=int, default=5)
parser.add_argument('--num_mlp_layers', type=int, default=2)
parser.add_argument('--feat_size', type=int, default=64)
parser.add_argument('--hidden_size', type=int, default=64)
parser.add_argument(
'--pool_type',
type=str,
default="sum",
choices=["sum", "average", "max"])
parser.add_argument('--train_eps', action='store_true')
parser.add_argument('--init_eps', type=float, default=0.0)
parser.add_argument('--epochs', type=int, default=350)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--dropout_prob', type=float, default=0.5)
parser.add_argument('--seed', type=int, default=0)
args = parser.parse_args()
GIN github代碼復現含數據集下載:How Powerful are Graph Neural Networks? //github.com/weihua916/powerful-gnns
//github.com/weihua916/powerful-gnns/blob/master/dataset.zip
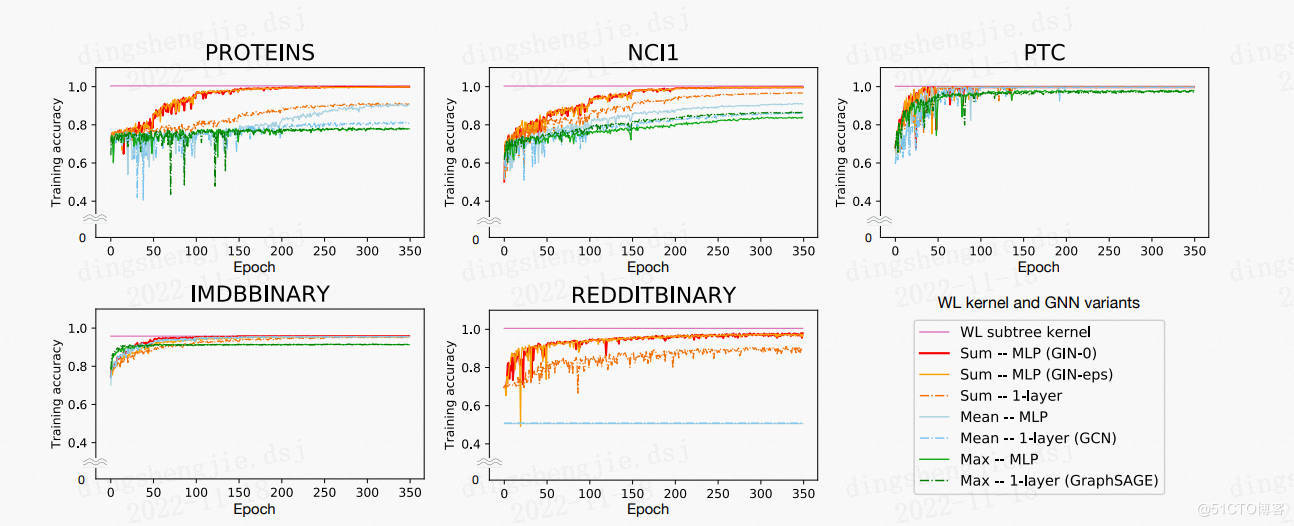
論文使用 9 個圖形分類基準:4 個生物信息學數據集(MUTAG、PTC、NCI1、PROTEINS) 和 5 個社交網絡數據集(COLLAB、IMDB-BINARY、IMDB-MULTI、REDDITBINARY 和 REDDIT-MULTI5K)(Yanardag & Vishwanathan,2015)。 重要的是,我目標不是讓模型依賴輸入節點特徵,而是主要從網絡結構中學習。因此,在生物信息圖中,節點具有分類輸入特徵,但在社交網絡中,它們沒有特徵。 對於社交網絡,按如下方式創建節點特徵:對於 REDDIT 數據集,將所有節點特徵向量設置為相同(因此,這裡的特徵是無信息的); 對於其他社交圖,我們使用節點度數的 one-hot 編碼。
社交網絡數據集。
-
IMDB-BINARY 和 IMDB-MULTI 是電影協作數據集。每個圖對應於每個演員/女演員的自我網絡,其中節點對應於演員/女演員,如果兩個演員/女演員出現在同一部電影中,則在兩個演員/女演員之間繪製一條邊。每個圖都是從預先指定的電影類型派生的,任務是對其派生的類型圖進行分類。
-
REDDIT-BINARY 和 REDDIT-MULTI5K 是平衡數據集,其中每個圖表對應一個在線討論線程,節點對應於用戶。如果其中至少一個節點回應了另一個節點的評論,則在兩個節點之間繪製一條邊。任務是將每個圖分類到它所屬的社區或子版塊。
-
COLLAB 是一個科學協作數據集,源自 3 個公共協作數據集,即高能物理、凝聚態物理和天體物理。每個圖對應於來自每個領域的不同研究人員的自我網絡。任務是將每個圖分類到相應研究人員所屬的領域。
生物信息學數據集。
-
MUTAG 是一個包含 188 個誘變芳香族和雜芳香族硝基化合物的數據集,具有 7 個離散標籤。
-
PROTEINS 是一個數據集,其中節點是二級結構元素 (SSE),如果兩個節點在氨基酸序列或 3D 空間中是相鄰節點,則它們之間存在一條邊。 它有 3 個離散標籤,代表螺旋、薄片或轉彎。
-
PTC 是一個包含 344 種化合物的數據集,報告了雄性和雌性大鼠的致癌性,它有 19 個離散標籤。
-
NCI1 是由美國國家癌症研究所 (NCI) 公開提供的數據集,是經過篩選以抑制或抑制一組人類腫瘤細胞系生長的化學化合物平衡數據集的子集,具有 37 個離散標籤。
部分結果展示:
[INFO] 2022-11-18 17:12:34,203 [ main.py: 98]: eval: epoch 347 | step 2082 | | loss 0.448468 | acc 0.684211
[INFO] 2022-11-18 17:12:34,297 [ main.py: 98]: eval: epoch 348 | step 2088 | | loss 0.393809 | acc 0.789474
[INFO] 2022-11-18 17:12:34,326 [ main.py: 92]: train: epoch 349 | step 2090 | loss 0.401544 | acc 0.8125
[INFO] 2022-11-18 17:12:34,391 [ main.py: 98]: eval: epoch 349 | step 2094 | | loss 0.441679 | acc 0.736842
[INFO] 2022-11-18 17:12:34,476 [ main.py: 92]: train: epoch 350 | step 2100 | loss 0.573693 | acc 0.7778
[INFO] 2022-11-18 17:12:34,485 [ main.py: 98]: eval: epoch 350 | step 2100 | | loss 0.481966 | acc 0.789474
[INFO] 2022-11-18 17:12:34,485 [ main.py: 103]: best evaluating accuracy: 0.894737
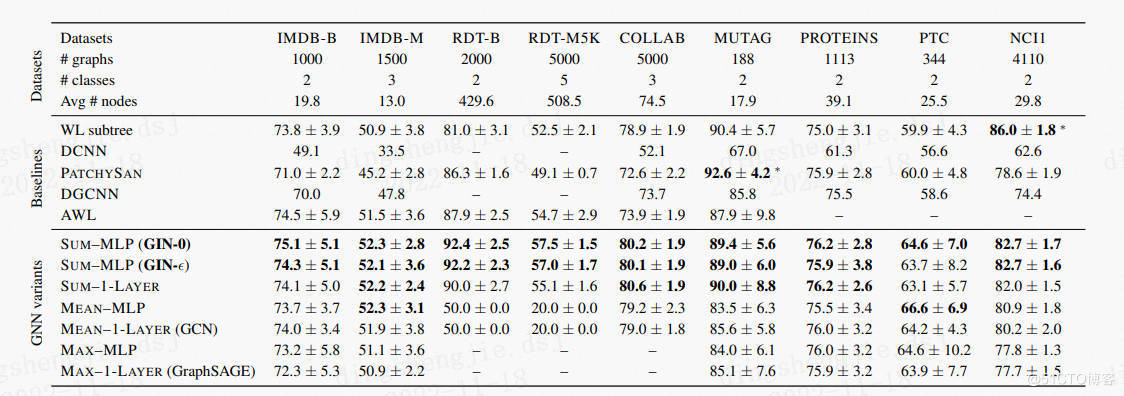
結果整合:(這裡就不把數據集一一跑一遍了)
| MUTAG | COLLAB | IMDBBINARY | IMDBMULTI | |
|---|---|---|---|---|
| PGL result | 90.8 | 78.6 | 76.8 | 50.8 |
| paper reuslt | 90.0 | 80.0 | 75.1 | 52.3 |
原論文所有結果: