Dive into TensorFlow系列(2)- 解析TF核心抽象op算子
本文作者:李傑
TF計算圖從邏輯層來講,由op與tensor構成。op是項點代表計算單元,tensor是邊代表op之間流動的數據內容,兩者配合以數據流圖的形式來表達計算圖。那麼op對應的物理層實現是什麼?TF中有哪些op,以及各自的適用場景是什麼?op到底是如何運行的?接下來讓我們一起探索和回答這些問題。
一、初識op
1.1 op定義
op代表計算圖中的節點,是tf.Operation對象,代表一個計算單元。用戶在創建模型和訓練代碼時,會創建一系列op及其依賴關係,並將這些op和依賴添加到tf.Graph對象中(一般為默認圖)。比如:tf.matmul()就是一個op,它有兩個輸入tensor和一個輸出tensor。
1.2 op分類
op的分類一般有多個視角,比如按是否內置劃分、按工作類型劃分。
按是否內置劃分,一般分為:內置op和自定義op(見「二、自定義op」部分介紹)。
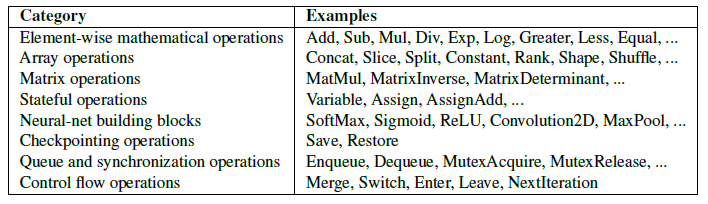
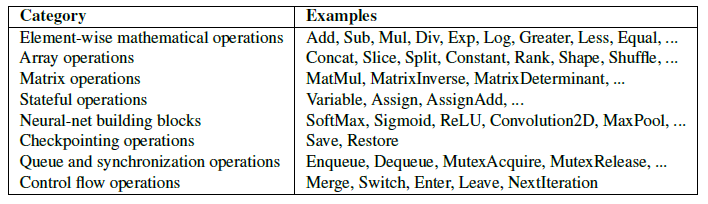
按工作類型劃分,一般分為:常見數學op、數組op、矩陣op、有狀態op、神經網絡op、檢查點op、隊列與同步op、控制流op。TF白皮書對內置op的分類總結如下:
1.3 op與kernel
op一般都有名稱且代表一個抽象的計算過程。op可以設置若干屬性,但這些屬性必須在編譯期提供或推理得到,因為它們用來實例化一個節點對象從而執行真正的計算。屬性的經典用法就是拿來支持類型多態,比如兩個浮點張量的矩陣乘法與兩個整型張量的矩陣乘法。
kernel是op在指定設備類型(CPU/GPU)上的具體實現。TF二進制庫通過註冊機制定義了一系列op及對應的kernel實現,用戶可以提供額外的op定義與kernel實現進行擴充。一般來說,一個op對應多個kernel實現。
接下來讓我們一起用矩陣乘法MatMul算子的相關代碼來理解op與kernel的關係(此處不必糾結代碼細節,只需體會op與kernel關係即可):
// 首先給出op註冊的定義。其中輸入輸出支持泛型,其合法類型在Attr中進行枚舉。 // 代碼位置 tensorflow1.15.5\tensorflow\core\ops\math_ops.cc REGISTER_OP("MatMul") .Input("a: T") .Input("b: T") .Output("product: T") .Attr("transpose_a: bool = false") .Attr("transpose_b: bool = false") .Attr( "T: {bfloat16, half, float, double, int32, int64, complex64, " "complex128}") .SetShapeFn(shape_inference::MatMulShape); // MatMul的實現,採用類模板機制 // 代碼位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cc template <typename Device, typename T, bool USE_CUBLAS> class MatMulOp : public OpKernel { public: explicit MatMulOp(OpKernelConstruction* ctx) : OpKernel(ctx), algorithms_set_already_(false) { OP_REQUIRES_OK(ctx, ctx->GetAttr("transpose_a", &transpose_a_)); OP_REQUIRES_OK(ctx, ctx->GetAttr("transpose_b", &transpose_b_)); LaunchMatMul<Device, T, USE_CUBLAS>::GetBlasGemmAlgorithm( ctx, &algorithms_, &algorithms_set_already_); use_autotune_ = MatmulAutotuneEnable(); } // 省略了很多代碼... private: std::vector<int64> algorithms_; bool algorithms_set_already_; bool use_autotune_; bool transpose_a_; bool transpose_b_; }; // MatMul的op定義與kernel實現綁定處理 // 代碼位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cc #define REGISTER_CPU_EIGEN(T) /*cpu與eigen組合對應實現*/ \ REGISTER_KERNEL_BUILDER( \ Name("MatMul").Device(DEVICE_CPU).TypeConstraint<T>("T").Label("eigen"), \ MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>); #define REGISTER_CPU(T) /*cpu對應實現(eigen與非eigen)*/ \ REGISTER_KERNEL_BUILDER( \ Name("MatMul").Device(DEVICE_CPU).TypeConstraint<T>("T"), \ MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>); \ REGISTER_CPU_EIGEN(T); #define REGISTER_GPU(T) /*gpu對應實現(cublas與非cublas)*/ \ REGISTER_KERNEL_BUILDER( \ Name("MatMul").Device(DEVICE_GPU).TypeConstraint<T>("T"), \ MatMulOp<GPUDevice, T, true /* cublas, true by default */>); \ REGISTER_KERNEL_BUILDER(Name("MatMul") \ .Device(DEVICE_GPU) \ .TypeConstraint<T>("T") \ .Label("cublas"), \ MatMulOp<GPUDevice, T, true /* cublas */>)
二、自定義op
用戶編寫的模型訓練代碼一般由TF原生的op算子及其依賴關係組成,但有時候我們定義的計算邏輯在TF中沒有相應的op實現。根據TensorFlow官網的建議,我們應當先組合python op算子或python函數進行嘗試。完成嘗試之後再決定要不要自定義op。
2.1 自定義op場景
一般來說,需要自定義op的場景有如下3個:
在此舉個例子方便大家理解。假如我們要實現一個新計算實邏:中位數池化(median pooling),過程中要在滑動窗口不斷求得中位數。檢索TF文檔沒有發現對應op,因此我們先考慮用TF python op組合來實現它,果然通過ExtractImagePatches and TopK就可以實現這個功能。經測試前述組合方案並不是計算和存儲高效的,因此我們就有必要將median pooling在一個op中進行高效實現。
2.2 自定義op流程
自定義op一般遵循5個基本步驟:
接下來我們就以官網最簡單的ZeroOut同步式自定義op(繼承OpKernel)為例,結合代碼來講述上述5個步驟。下面先給出步驟1和步驟2用C++實現的代碼(官方推薦用bazel編譯so文件):
// 步驟1:註冊op REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c->set_output(0, c->input(0)); //c's input and output type is std::vector<ShapeHandle> return Status::OK(); }); // 步驟2:定義kernel(常規CPU設備),並把kernel與op綁定 class ZeroOutOp : public OpKernel { public: explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) {} void Compute(OpKernelContext* context) override { // Grab the input tensor from OpKernelContext instance const Tensor& input_tensor = context->input(0); auto input = input_tensor.flat<int32>(); // Create an output tensor Tensor* output_tensor = NULL; OP_REQUIRES_OK(context, context->allocate_output(0, input_tensor.shape(), &output_tensor)); // OP_REQUIRES_OK第二個參數一般為方法調用,此處為輸出張量分配內存空間 auto output_flat = output_tensor->flat<int32>(); // Set all but the first element of the output tensor to 0. const int N = input.size(); for (int i = 1; i < N; i++) { output_flat(i) = 0; } // Preserve the first input value if possible. if (N > 0) output_flat(0) = input(0); } }; REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);
步驟3加載上述so文件(自動完成前後端op映射);步驟4是可選項,此處不需要;步驟5基於python api測試op功能。相應代碼如下:
import tensorflow as tf zero_out_module = tf.load_op_library('./zero_out.so') # 加載so文件生成python module with tf.Session(''): zero_out_module.zero_out([[1, 2], [3, 4]]).eval() # Prints array([[1, 0], [0, 0]], dtype=int32)
2.3 高級話題
關於op的技術話題還有很多,我們在此簡述一些要點:
三、op工作原理
3.1 op運行框架
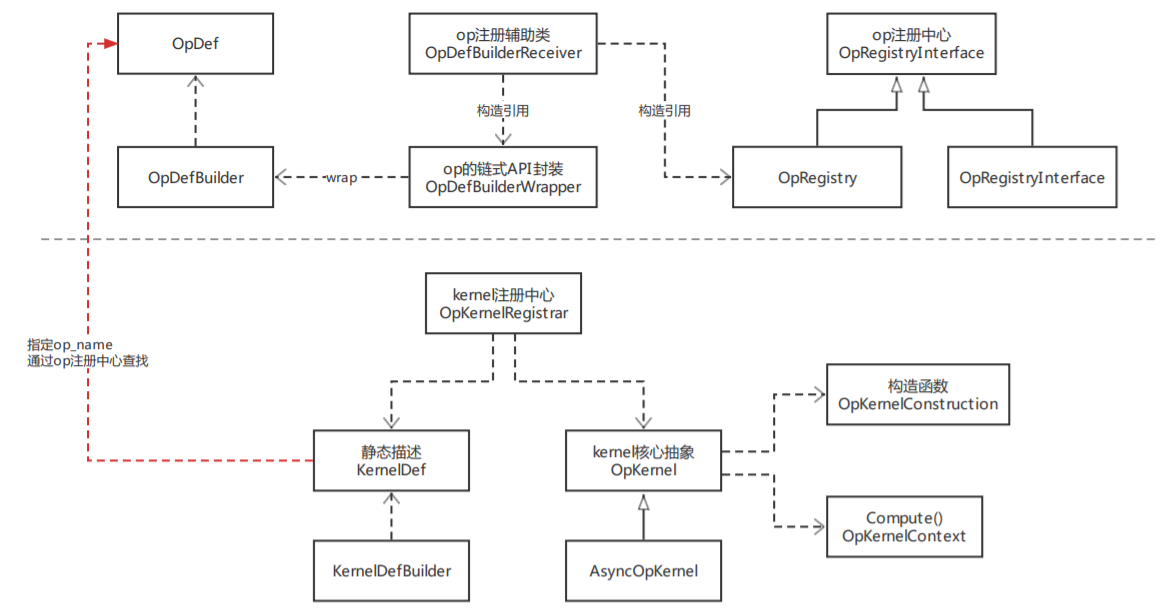
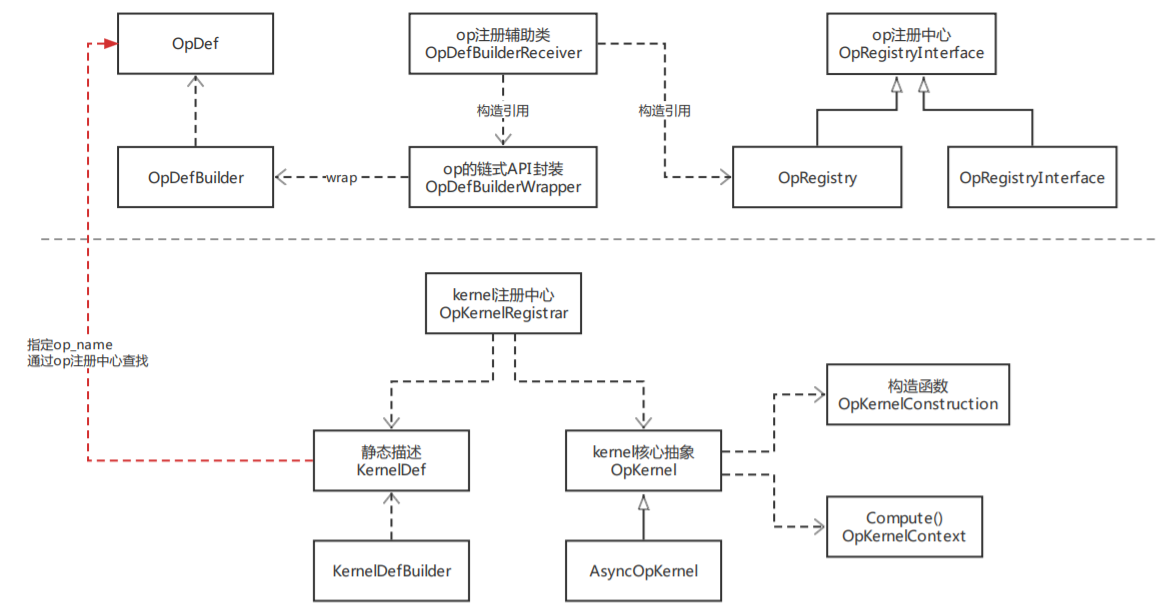
整體來看,op與kernel都有其結構描述與統一的註冊管理中心。而OpDefBuilder有兩個包裝類OpDefBuilderWrapper和OpDefBuilderReceiver,前者支持op構建的鏈式語法,後者接受op構建結果並進行註冊。眾所周知,op是編譯期概念,而kernel是運行期概念,在AI編譯器的後端處理流程中會進行op的算子選擇,此過程會基於一系列策略為op匹配最合適的kernel實現。
3.2 若干技術細節
首先,我們來看一下大家在使用TensorFlow過程中經常碰到的libtensorflow_framework.so。按照tf1.15.5/tensorflow/BUILD中的描述,libtensorflow_framework.so定義了op和kernel的註冊機制而不涉及具體實現。
// rootdir=tensorflow1.15.5 // ${rootdir}/tensorflow/BUILD /* # A shared object which includes registration mechanisms for ops and # kernels. Does not include the implementations of any ops or kernels. Instead, # the library which loads libtensorflow_framework.so # (e.g. _pywrap_tensorflow_internal.so for Python, libtensorflow.so for the C # API) is responsible for registering ops with libtensorflow_framework.so. In # addition to this core set of ops, user libraries which are loaded (via # TF_LoadLibrary/tf.load_op_library) register their ops and kernels with this # shared object directly. */ tf_cc_shared_object( name = "tensorflow_framework", framework_so = [], linkopts = select({ "//tensorflow:macos": [], "//tensorflow:windows": [], "//tensorflow:freebsd": [ "-Wl,--version-script,$(location //tensorflow:tf_framework_version_script.lds)", "-lexecinfo", ], "//conditions:default": [ "-Wl,--version-script,$(location //tensorflow:tf_framework_version_script.lds)", ], }), linkstatic = 1, per_os_targets = True, soversion = VERSION, visibility = ["//visibility:public"], deps = [ "//tensorflow/cc/saved_model:loader_lite_impl", "//tensorflow/core:core_cpu_impl", "//tensorflow/core:framework_internal_impl", /* 展開此target進行查看 */ "//tensorflow/core:gpu_runtime_impl", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry_impl", "//tensorflow/core:lib_internal_impl", "//tensorflow/stream_executor:stream_executor_impl", "//tensorflow:tf_framework_version_script.lds", ] + tf_additional_binary_deps(), ) // ${rootdir}/tensorflow/core/BUILD tf_cuda_library( name = "framework_internal_impl", srcs = FRAMEWORK_INTERNAL_PRIVATE_HEADERS + glob( // 可以查看FRAMEWORK_INTERNAL_PRIVATE_HEADERS內容 [ "example/**/*.cc", "framework/**/*.cc", "util/**/*.cc", "graph/edgeset.cc", "graph/graph.cc", "graph/graph_def_builder.cc", "graph/node_builder.cc", "graph/tensor_id.cc", "graph/while_context.h", "graph/while_context.cc", ], // 省略了諸多代碼 ) // FRAMEWORK_INTERNAL_PRIVATE_HEADERS的內容 FRAMEWORK_INTERNAL_PRIVATE_HEADERS = [ "graph/edgeset.h", "graph/graph.h", "graph/graph_def_builder.h", "graph/node_builder.h", "graph/tensor_id.h", ] + glob( [ "example/**/*.h", "framework/**/*.h", // 這裡就是重點,查看${rootdir}/tensorflow/core/framework/op.h和opkernel.h "util/**/*.h", ] ) // 先來看op.h #define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name) #define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name) #define REGISTER_OP_UNIQ(ctr, name) \ static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \ TF_ATTRIBUTE_UNUSED = \ ::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \ name)>(name) // 再來看看opkernel.h #define REGISTER_KERNEL_BUILDER(kernel_builder, ...) \ REGISTER_KERNEL_BUILDER_UNIQ_HELPER(__COUNTER__, kernel_builder, __VA_ARGS__) #define REGISTER_KERNEL_BUILDER_UNIQ_HELPER(ctr, kernel_builder, ...) \ REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, __VA_ARGS__) #define REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, ...) \ constexpr bool should_register_##ctr##__flag = \ SHOULD_REGISTER_OP_KERNEL(#__VA_ARGS__); \ static ::tensorflow::kernel_factory::OpKernelRegistrar \ registrar__body__##ctr##__object( \ should_register_##ctr##__flag \ ? ::tensorflow::register_kernel::kernel_builder.Build() \ : nullptr, \ #__VA_ARGS__, \ [](::tensorflow::OpKernelConstruction* context) \ -> ::tensorflow::OpKernel* { \ return new __VA_ARGS__(context); \ }); 參照上述同樣的流程,我們可以發現libtensorflow.so中涉及op與kernel的具體實現,同時也包括Session的具體實現。 最後,我們再來講講REGISTER_OP宏背後的具體原理。我們在上面已經給出了此宏的定義,此處針對它的實現展開談談: // 先來看op.h #define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name) #define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name) #define REGISTER_OP_UNIQ(ctr, name) \ static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \ TF_ATTRIBUTE_UNUSED = \ ::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \ name)>(name) // REGISTER_OP的一般用法如下 REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c->set_output(0, c->input(0)); return Status::OK(); }); // op定義的鏈式規則是通過OpDefBuilderWrapper類實現的 class OpDefBuilderWrapper<true> { public: explicit OpDefBuilderWrapper(const char name[]) : builder_(name) {} OpDefBuilderWrapper<true>& Input(string spec) { builder_.Input(std::move(spec)); return *this; // 顯而易見,調用Input仍然返回OpDefBuilderWrapper<true>本身 } OpDefBuilderWrapper<true>& Output(string spec) { builder_.Output(std::move(spec)); return *this; } OpDefBuilderWrapper<true>& SetShapeFn( Status (*fn)(shape_inference::InferenceContext*)) { builder_.SetShapeFn(fn); return *this; } const ::tensorflow::OpDefBuilder& builder() const { return builder_; } private: mutable ::tensorflow::OpDefBuilder builder_; }; // 當通過鏈式規劃構建好op後,再通過OpDefBuilderReceiver完成op的註冊 // op.h struct OpDefBuilderReceiver { // To call OpRegistry::Global()->Register(...), used by the // REGISTER_OP macro below. // Note: These are implicitly converting constructors. OpDefBuilderReceiver( const OpDefBuilderWrapper<true>& wrapper); // NOLINT(runtime/explicit) constexpr OpDefBuilderReceiver(const OpDefBuilderWrapper<false>&) { } // NOLINT(runtime/explicit) }; // op.cc,然後在OpDefBuilderReceiver構造函數內部完成OpDefBuilderWrapper的全局註冊 OpDefBuilderReceiver::OpDefBuilderReceiver( const OpDefBuilderWrapper<true>& wrapper) { OpRegistry::Global()->Register( [wrapper](OpRegistrationData* op_reg_data) -> Status { return wrapper.builder().Finalize(op_reg_data); }); }
四、總結
本文為大家系統講解了TensorFlow的核心抽象op及其kernel實現。需要自定義op的具體場景,以及op的運行框架及若干技術細節。讀罷此文,讀者應該有如下幾點收穫:
參考資料
1.《TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems》: //arxiv.org/abs/1603.04467
2.Graphs and Sessions: //github.com/tensorflow/docs/blob/master/site/en/r1/guide/graphs.md
3.Adding a New Op: //github.com/tensorflow/docs/blob/master/site/en/r1/guide/extend/op.md
4.跨設備通信send/recv: //github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/sendrecv_ops.h
5.OpKernel definition: //github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_kernel.h
6.tensorflow源碼解析之framework-resource: //www.cnblogs.com/jicanghai/p/9535504.html
7.tensorflow源碼解析之framework-op: //www.cnblogs.com/jicanghai/p/9539513.html
**本文作者:李傑**
TF計算圖從邏輯層來講,由op與tensor構成。op是項點代表計算單元,tensor是邊代表op之間流動的數據內容,兩者配合以數據流圖的形式來表達計算圖。那麼op對應的物理層實現是什麼?TF中有哪些op,以及各自的適用場景是什麼?op到底是如何運行的?接下來讓我們一起探索和回答這些問題。
## 一、初識op
### 1.1 op定義
op代表計算圖中的節點,是tf.Operation對象,代表一個計算單元。用戶在創建模型和訓練代碼時,會創建一系列op及其依賴關係,並將這些op和依賴添加到tf.Graph對象中(一般為默認圖)。比如:tf.matmul()就是一個op,它有兩個輸入tensor和一個輸出tensor。
### 1.2 op分類
op的分類一般有多個視角,比如按是否內置劃分、按工作類型劃分。
按是否內置劃分,一般分為:內置op和自定義op(見「二、自定義op」部分介紹)。
按工作類型劃分,一般分為:常見數學op、數組op、矩陣op、有狀態op、神經網絡op、檢查點op、隊列與同步op、控制流op。TF白皮書對內置op的分類總結如下:
### 1.3 op與kernel
op一般都有名稱且代表一個抽象的計算過程。op可以設置若干屬性,但這些屬性必須在編譯期提供或推理得到,因為它們用來實例化一個節點對象從而執行真正的計算。屬性的經典用法就是拿來支持類型多態,比如兩個浮點張量的矩陣乘法與兩個整型張量的矩陣乘法。
kernel是op在指定設備類型(CPU/GPU)上的具體實現。TF二進制庫通過註冊機制定義了一系列op及對應的kernel實現,用戶可以提供額外的op定義與kernel實現進行擴充。一般來說,一個op對應多個kernel實現。
接下來讓我們一起用矩陣乘法MatMul算子的相關代碼來理解op與kernel的關係(此處不必糾結代碼細節,只需體會op與kernel關係即可):
“`// 首先給出op註冊的定義。其中輸入輸出支持泛型,其合法類型在Attr中進行枚舉。// 代碼位置 tensorflow1.15.5\tensorflow\core\ops\math_ops.ccREGISTER_OP(“MatMul”) .Input(“a: T”) .Input(“b: T”) .Output(“product: T”) .Attr(“transpose_a: bool = false”) .Attr(“transpose_b: bool = false”) .Attr( “T: {bfloat16, half, float, double, int32, int64, complex64, ” “complex128}”) .SetShapeFn(shape_inference::MatMulShape); // MatMul的實現,採用類模板機制// 代碼位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cctemplate <typename Device, typename T, bool USE_CUBLAS>class MatMulOp : public OpKernel { public: explicit MatMulOp(OpKernelConstruction* ctx) : OpKernel(ctx), algorithms_set_already_(false) { OP_REQUIRES_OK(ctx, ctx->GetAttr(“transpose_a”, &transpose_a_)); OP_REQUIRES_OK(ctx, ctx->GetAttr(“transpose_b”, &transpose_b_));
LaunchMatMul<Device, T, USE_CUBLAS>::GetBlasGemmAlgorithm( ctx, &algorithms_, &algorithms_set_already_); use_autotune_ = MatmulAutotuneEnable(); } // 省略了很多代碼… private: std::vector<int64> algorithms_; bool algorithms_set_already_; bool use_autotune_; bool transpose_a_; bool transpose_b_;};
// MatMul的op定義與kernel實現綁定處理// 代碼位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cc#define REGISTER_CPU_EIGEN(T) /*cpu與eigen組合對應實現*/ \ REGISTER_KERNEL_BUILDER( \ Name(“MatMul”).Device(DEVICE_CPU).TypeConstraint<T>(“T”).Label(“eigen”), \ MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>);
#define REGISTER_CPU(T) /*cpu對應實現(eigen與非eigen)*/ \ REGISTER_KERNEL_BUILDER( \ Name(“MatMul”).Device(DEVICE_CPU).TypeConstraint<T>(“T”), \ MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>); \ REGISTER_CPU_EIGEN(T);
#define REGISTER_GPU(T) /*gpu對應實現(cublas與非cublas)*/ \ REGISTER_KERNEL_BUILDER( \ Name(“MatMul”).Device(DEVICE_GPU).TypeConstraint<T>(“T”), \ MatMulOp<GPUDevice, T, true /* cublas, true by default */>); \ REGISTER_KERNEL_BUILDER(Name(“MatMul”) \ .Device(DEVICE_GPU) \ .TypeConstraint<T>(“T”) \ .Label(“cublas”), \ MatMulOp<GPUDevice, T, true /* cublas */>)“`
## 二、自定義op
用戶編寫的模型訓練代碼一般由TF原生的op算子及其依賴關係組成,但有時候我們定義的計算邏輯在TF中沒有相應的op實現。根據TensorFlow官網的建議,我們應當先組合python op算子或python函數進行嘗試。完成嘗試之後再決定要不要自定義op。
### 2.1 自定義op場景
一般來說,需要自定義op的場景有如下3個:
•用TF原生op組合來表達新計算邏輯的過程比較複雜或不可能
•用TF原生op組合來表達新計算邏輯,其計算性能較低
•在新版編譯器中也較難實現op融合的計算邏輯需要我們手動實現融合
在此舉個例子方便大家理解。假如我們要實現一個新計算實邏:中位數池化(median pooling),過程中要在滑動窗口不斷求得中位數。檢索TF文檔沒有發現對應op,因此我們先考慮用TF python op組合來實現它,果然通過**ExtractImagePatches** and **TopK**就可以實現這個功能。經測試前述組合方案並不是計算和存儲高效的,因此我們就有必要將median pooling在一個op中進行高效實現。
### 2.2 自定義op流程
自定義op一般遵循5個基本步驟:
1.註冊op,具體包括:指定名稱、輸入/輸出聲明、形狀函數。
2.定義kernel(即op的實現)並與op綁定。一個op有多個kernel實現,具體由輸入輸出類型、硬件(CPU、GPU)決定。
3.創建python包裝器,一般由op註冊機制自動完成。
4.編寫op的梯度計算函數(可選項)。
5.測試op,通過python測試較為方便,當然也可通過C++進行測試。
接下來我們就以官網最簡單的ZeroOut同步式自定義op(繼承OpKernel)為例,結合代碼來講述上述5個步驟。下面先給出步驟1和步驟2用C++實現的代碼(官方推薦用bazel編譯so文件):
“`// 步驟1:註冊opREGISTER_OP(“ZeroOut”).Input(“to_zero: int32”).Output(“zeroed: int32”).SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c->set_output(0, c->input(0)); //c’s input and output type is std::vector<ShapeHandle> return Status::OK(); });
// 步驟2:定義kernel(常規CPU設備),並把kernel與op綁定class ZeroOutOp : public OpKernel {public: explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) {}
void Compute(OpKernelContext* context) override { // Grab the input tensor from OpKernelContext instance const Tensor& input_tensor = context->input(0); auto input = input_tensor.flat<int32>();
// Create an output tensor Tensor* output_tensor = NULL; OP_REQUIRES_OK(context, context->allocate_output(0, input_tensor.shape(), &output_tensor)); // OP_REQUIRES_OK第二個參數一般為方法調用,此處為輸出張量分配內存空間 auto output_flat = output_tensor->flat<int32>();
// Set all but the first element of the output tensor to 0. const int N = input.size(); for (int i = 1; i < N; i++) { output_flat(i) = 0; }
// Preserve the first input value if possible. if (N > 0) output_flat(0) = input(0); }};
REGISTER_KERNEL_BUILDER(Name(“ZeroOut”).Device(DEVICE_CPU), ZeroOutOp);“`
步驟3加載上述so文件(自動完成前後端op映射);步驟4是可選項,此處不需要;步驟5基於python api測試op功能。相應代碼如下:
“`import tensorflow as tfzero_out_module = tf.load_op_library(‘./zero_out.so’) # 加載so文件生成python modulewith tf.Session(”): zero_out_module.zero_out([[1, 2], [3, 4]]).eval()
# Printsarray([[1, 0], [0, 0]], dtype=int32)“`
### 2.3 高級話題
關於op的技術話題還有很多,我們在此簡述一些要點:
1.如果實現了一個多線程CPU kernel,則可以利用work_sharder.h中的Shard函數。
2.大多數op以同步方式工作,只需繼承OpKernel改寫Compute()方法,且此方法必須線程安全。
3.如果一個op因為其它op的運行而阻塞,則這個op可以採用異步方式工作,繼承AsyncOpKernel改寫ComputeAsync()方法,且此方法必須線程安全。異步op最經典的例子就是跨設備通信send/recv pair中的RecvOp。
4.如果要為op配置一些靜態屬性,可使用Attr,它有一套特有的支持類型。典型應用是支持泛型。
5.實現GPU kernel有兩部分內容:OpKernel和CUDA kernel,相應的加載代碼。
6.編譯自定義op,首先要配置頭文件搜索路徑與庫文件搜索路徑,接着指定編譯和鏈接選項,最後還要確保ABI兼容性。
7.Resource(資源)代表相同設備上op共享的內容,比如:張量值、kv存儲表、隊列、讀取器、網絡連接等。代表資源的類必須繼承ResourceBase,然後註冊ResourceHandleOp生成資源句柄,普通op以resouce類型的Input進行引入。
## 三、op工作原理
### 3.1 op運行框架
整體來看,op與kernel都有其結構描述與統一的註冊管理中心。而OpDefBuilder有兩個包裝類OpDefBuilderWrapper和OpDefBuilderReceiver,前者支持op構建的鏈式語法,後者接受op構建結果並進行註冊。眾所周知,op是編譯期概念,而kernel是運行期概念,在AI編譯器的後端處理流程中會進行op的算子選擇,此過程會基於一系列策略為op匹配最合適的kernel實現。
### 3.2 若干技術細節
首先,我們來看一下大家在使用TensorFlow過程中經常碰到的libtensorflow_framework.so。按照tf1.15.5/tensorflow/BUILD中的描述,libtensorflow_framework.so定義了op和kernel的註冊機制而不涉及具體實現。
“`// rootdir=tensorflow1.15.5// ${rootdir}/tensorflow/BUILD/*# A shared object which includes registration mechanisms for ops and# kernels. Does not include the implementations of any ops or kernels. Instead,# the library which loads libtensorflow_framework.so# (e.g. _pywrap_tensorflow_internal.so for Python, libtensorflow.so for the C# API) is responsible for registering ops with libtensorflow_framework.so. In# addition to this core set of ops, user libraries which are loaded (via# TF_LoadLibrary/tf.load_op_library) register their ops and kernels with this# shared object directly.*/tf_cc_shared_object( name = “tensorflow_framework”, framework_so = [], linkopts = select({ “//tensorflow:macos”: [], “//tensorflow:windows”: [], “//tensorflow:freebsd”: [ “-Wl,–version-script,$(location //tensorflow:tf_framework_version_script.lds)”, “-lexecinfo”, ], “//conditions:default”: [ “-Wl,–version-script,$(location //tensorflow:tf_framework_version_script.lds)”, ], }), linkstatic = 1, per_os_targets = True, soversion = VERSION, visibility = [“//visibility:public”], deps = [ “//tensorflow/cc/saved_model:loader_lite_impl”, “//tensorflow/core:core_cpu_impl”, “//tensorflow/core:framework_internal_impl”, /* 展開此target進行查看 */ “//tensorflow/core:gpu_runtime_impl”, “//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry_impl”, “//tensorflow/core:lib_internal_impl”, “//tensorflow/stream_executor:stream_executor_impl”, “//tensorflow:tf_framework_version_script.lds”, ] + tf_additional_binary_deps(),)
// ${rootdir}/tensorflow/core/BUILDtf_cuda_library( name = “framework_internal_impl”, srcs = FRAMEWORK_INTERNAL_PRIVATE_HEADERS + glob( // 可以查看FRAMEWORK_INTERNAL_PRIVATE_HEADERS內容 [ “example/**/*.cc”, “framework/**/*.cc”, “util/**/*.cc”, “graph/edgeset.cc”, “graph/graph.cc”, “graph/graph_def_builder.cc”, “graph/node_builder.cc”, “graph/tensor_id.cc”, “graph/while_context.h”, “graph/while_context.cc”, ], // 省略了諸多代碼)
// FRAMEWORK_INTERNAL_PRIVATE_HEADERS的內容FRAMEWORK_INTERNAL_PRIVATE_HEADERS = [ “graph/edgeset.h”, “graph/graph.h”, “graph/graph_def_builder.h”, “graph/node_builder.h”, “graph/tensor_id.h”,] + glob( [ “example/**/*.h”, “framework/**/*.h”, // 這裡就是重點,查看${rootdir}/tensorflow/core/framework/op.h和opkernel.h “util/**/*.h”, ])
// 先來看op.h#define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name)#define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name)#define REGISTER_OP_UNIQ(ctr, name) \ static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \ TF_ATTRIBUTE_UNUSED = \ ::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \ name)>(name) // 再來看看opkernel.h#define REGISTER_KERNEL_BUILDER(kernel_builder, …) \ REGISTER_KERNEL_BUILDER_UNIQ_HELPER(__COUNTER__, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ_HELPER(ctr, kernel_builder, …) \ REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, …) \ constexpr bool should_register_##ctr##__flag = \ SHOULD_REGISTER_OP_KERNEL(#__VA_ARGS__); \ static ::tensorflow::kernel_factory::OpKernelRegistrar \ registrar__body__##ctr##__object( \ should_register_##ctr##__flag \ ? ::tensorflow::register_kernel::kernel_builder.Build() \ : nullptr, \ #__VA_ARGS__, \ [](::tensorflow::OpKernelConstruction* context) \ -> ::tensorflow::OpKernel* { \ return new __VA_ARGS__(context); \ });“`
參照上述同樣的流程,我們可以發現libtensorflow.so中涉及op與kernel的具體實現,同時也包括Session的具體實現。
最後,我們再來講講REGISTER_OP宏背後的具體原理。我們在上面已經給出了此宏的定義,此處針對它的實現展開談談:
“`// 先來看op.h#define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name)#define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name)#define REGISTER_OP_UNIQ(ctr, name) \ static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \ TF_ATTRIBUTE_UNUSED = \ ::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \ name)>(name)
// REGISTER_OP的一般用法如下REGISTER_OP(“ZeroOut”) .Input(“to_zero: int32”) .Output(“zeroed: int32”) .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c->set_output(0, c->input(0)); return Status::OK(); });
// op定義的鏈式規則是通過OpDefBuilderWrapper類實現的class OpDefBuilderWrapper<true> { public: explicit OpDefBuilderWrapper(const char name[]) : builder_(name) {}
OpDefBuilderWrapper<true>& Input(string spec) { builder_.Input(std::move(spec)); return *this; // 顯而易見,調用Input仍然返回OpDefBuilderWrapper<true>本身 } OpDefBuilderWrapper<true>& Output(string spec) { builder_.Output(std::move(spec)); return *this; }
OpDefBuilderWrapper<true>& SetShapeFn( Status (*fn)(shape_inference::InferenceContext*)) { builder_.SetShapeFn(fn); return *this; } const ::tensorflow::OpDefBuilder& builder() const { return builder_; }
private: mutable ::tensorflow::OpDefBuilder builder_;};
// 當通過鏈式規劃構建好op後,再通過OpDefBuilderReceiver完成op的註冊// op.hstruct OpDefBuilderReceiver { // To call OpRegistry::Global()->Register(…), used by the // REGISTER_OP macro below. // Note: These are implicitly converting constructors. OpDefBuilderReceiver( const OpDefBuilderWrapper<true>& wrapper); // NOLINT(runtime/explicit) constexpr OpDefBuilderReceiver(const OpDefBuilderWrapper<false>&) { } // NOLINT(runtime/explicit)};
// op.cc,然後在OpDefBuilderReceiver構造函數內部完成OpDefBuilderWrapper的全局註冊OpDefBuilderReceiver::OpDefBuilderReceiver( const OpDefBuilderWrapper<true>& wrapper) { OpRegistry::Global()->Register( [wrapper](OpRegistrationData* op_reg_data) -> Status { return wrapper.builder().Finalize(op_reg_data); });}“`
## 四、總結
本文為大家系統講解了TensorFlow的核心抽象op及其kernel實現。需要自定義op的具體場景,以及op的運行框架及若干技術細節。讀罷此文,讀者應該有如下幾點收穫:
•TensorFlow中op是編譯期概念,kernel是運行期概念,兩者各自的定義與註冊方式,以及相應的映射邏輯。
•掌握TensorFlow的高階玩法:自定義op。這將使你之前工作的不可能變為可能,由低效轉化為高效。
•掌握op與kernel註冊的宏定義來自何方,以及宏定義背後具體的運行框架。
## 參考資料
1.《TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems》: <//arxiv.org/abs/1603.04467>
2.Graphs and Sessions: <//github.com/tensorflow/docs/blob/master/site/en/r1/guide/graphs.md>
3.Adding a New Op: <//github.com/tensorflow/docs/blob/master/site/en/r1/guide/extend/op.md>
4.跨設備通信send/recv: <//github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/sendrecv_ops.h>
5.OpKernel definition: <//github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_kernel.h>
6.tensorflow源碼解析之framework-resource: <//www.cnblogs.com/jicanghai/p/9535504.html>
7.tensorflow源碼解析之framework-op: <//www.cnblogs.com/jicanghai/p/9539513.html>


