IO多路復用的理解/演變過程
目錄
阻塞IO
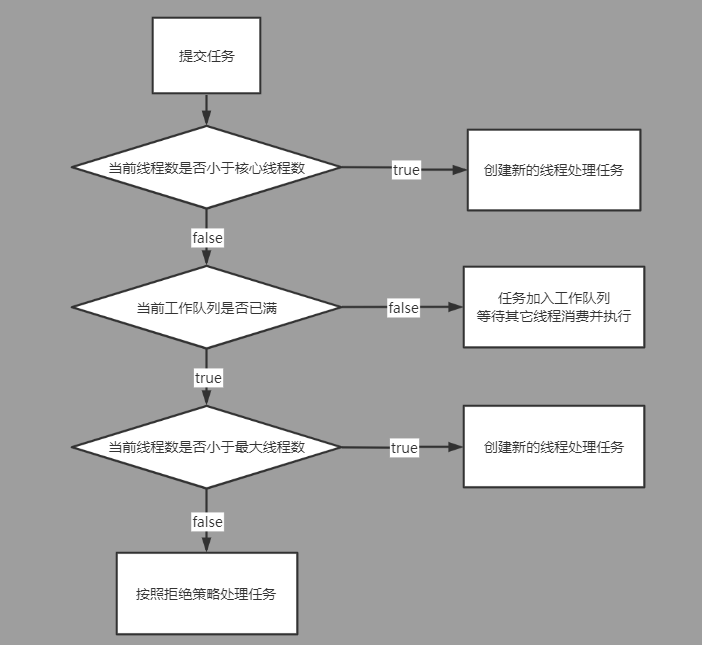
服務端為了處理客戶端的連接和請求的數據,寫了如下代碼。
- listenfd = socket(); // 打開一個網絡通信端口
- bind(listenfd); // 綁定
- listen(listenfd); // 監聽
- while(1) {
- connfd = accept(listenfd); // 阻塞建立連接
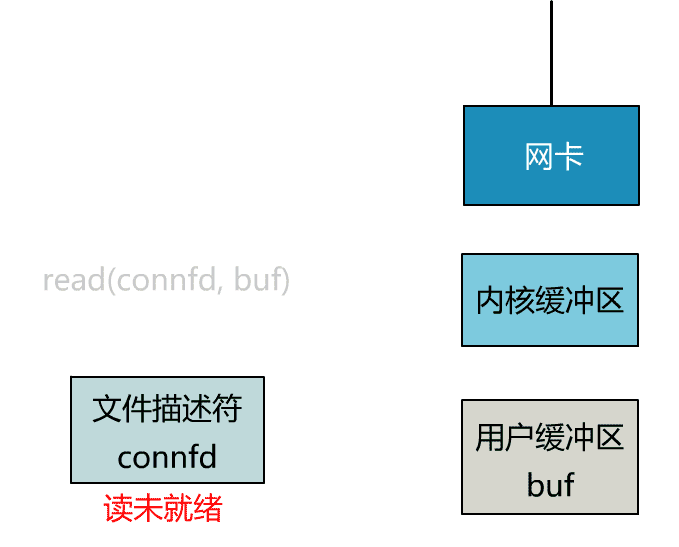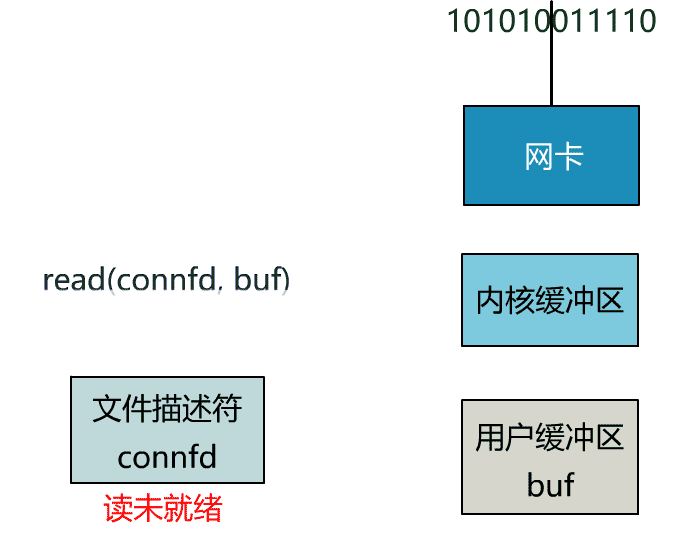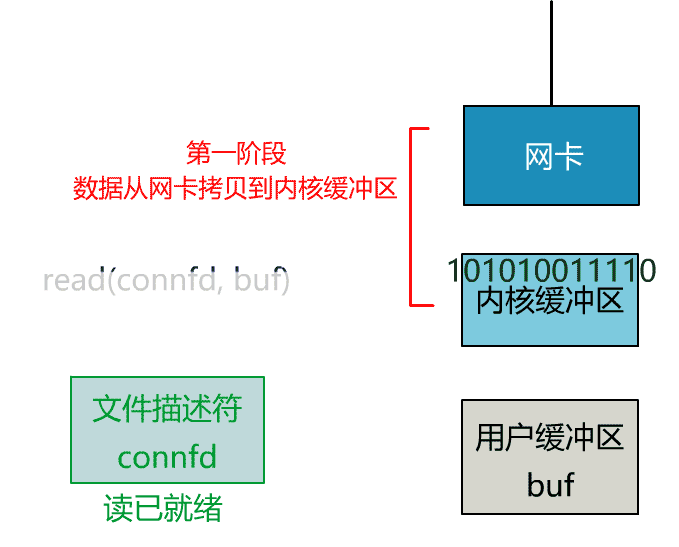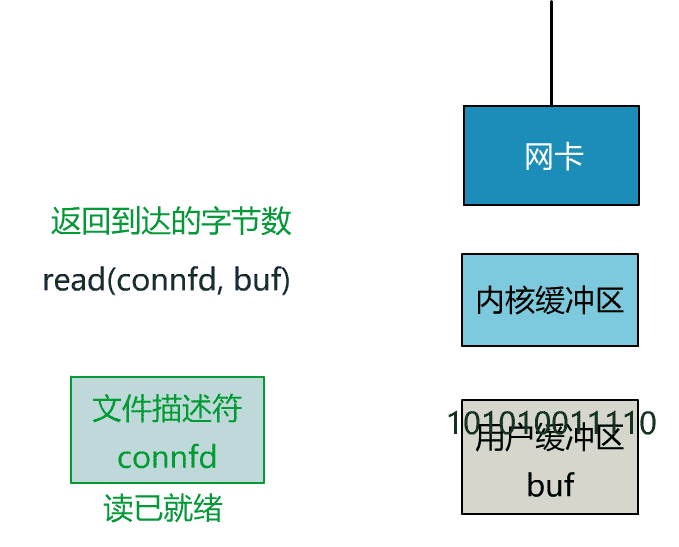
- int n = read(connfd, buf); // 阻塞讀數據
- doSomeThing(buf); // 利用讀到的數據做些什麼
- close(connfd); // 關閉連接,循環等待下一個連接
- }
這段代碼會執行得磕磕絆絆,就像這樣。

可以看到,服務端的線程阻塞在了兩個地方,一個是 accept 函數,一個是 read 函數。
如果再把 read 函數的細節展開,我們會發現其阻塞在了兩個階段。
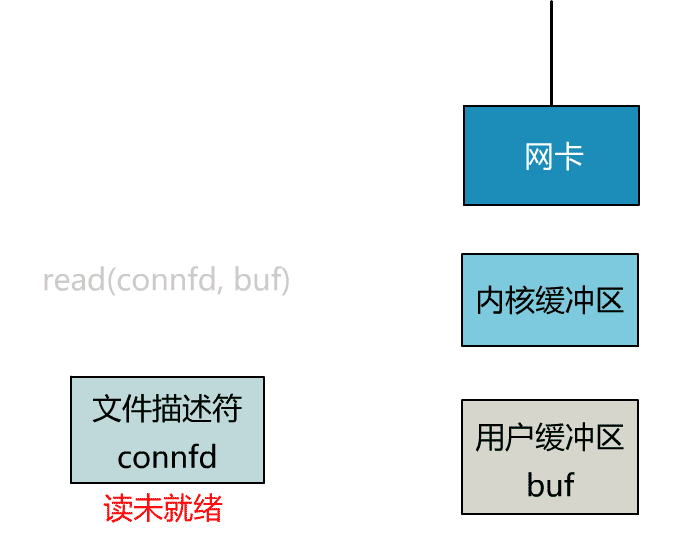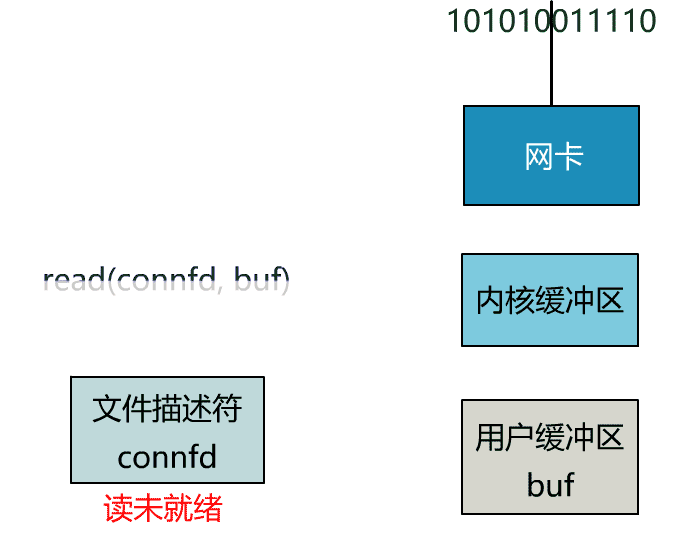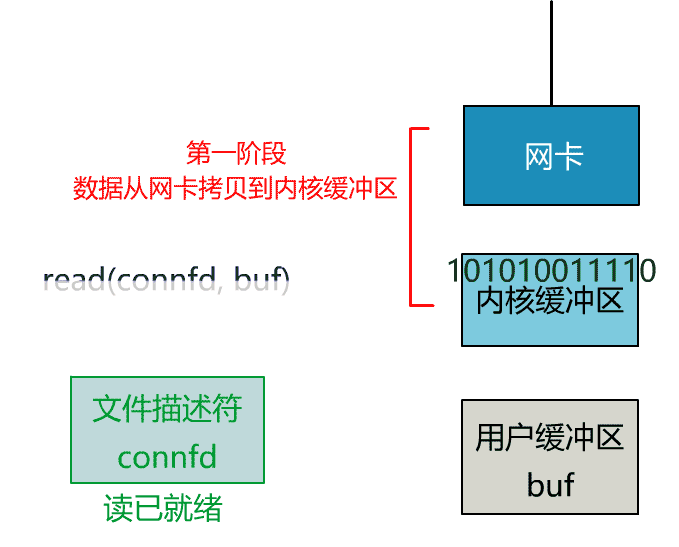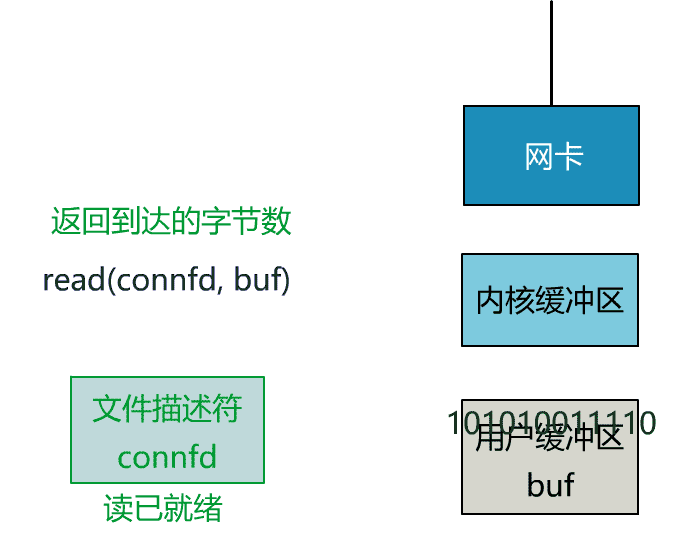
這就是傳統的阻塞 IO。
整體流程如下圖。

所以,如果這個連接的客戶端一直不發數據,那麼服務端線程將會一直阻塞在 read 函數上不返回,也無法接受其他客戶端連接。
這肯定是不行的。
非阻塞 IO
為了解決上面的問題,其關鍵在於改造這個 read 函數。
有一種聰明的辦法是,每次都創建一個新的進程或線程,去調用 read 函數,並做業務處理。
- while(1) {
- connfd = accept(listenfd); // 阻塞建立連接
- pthread_create(doWork); // 創建一個新的線程
- }
- void doWork() {
- int n = read(connfd, buf); // 阻塞讀數據
- doSomeThing(buf); // 利用讀到的數據做些什麼
- close(connfd); // 關閉連接,循環等待下一個連接
- }
這樣,當給一個客戶端建立好連接後,就可以立刻等待新的客戶端連接,而不用阻塞在原客戶端的 read 請求上。

不過,這不叫非阻塞 IO,只不過用了多線程的手段使得主線程沒有卡在 read 函數上不往下走罷了。操作系統為我們提供的 read 函數仍然是阻塞的。
所以真正的非阻塞 IO,不能是通過我們用戶層的小把戲,而是要懇請操作系統為我們提供一個非阻塞的 read 函數。
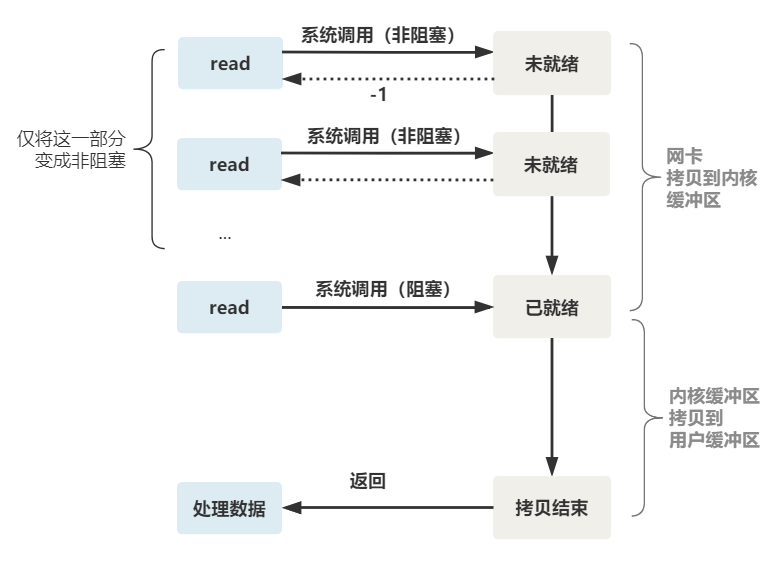
這個 read 函數的效果是,如果沒有數據到達時(到達網卡並拷貝到了內核緩衝區),立刻返回一個錯誤值(-1),而不是阻塞地等待。
操作系統提供了這樣的功能,只需要在調用 read 前,將文件描述符設置為非阻塞即可。
- fcntl(connfd, F_SETFL, O_NONBLOCK);
- int n = read(connfd, buffer) != SUCCESS);
這樣,就需要用戶線程循環調用 read,直到返回值不為 -1,再開始處理業務。
這裡我們注意到一個細節。
非阻塞的 read,指的是在數據到達前,即數據還未到達網卡,或者到達網卡但還沒有拷貝到內核緩衝區之前,這個階段是非阻塞的。
當數據已到達內核緩衝區,此時調用 read 函數仍然是阻塞的,需要等待數據從內核緩衝區拷貝到用戶緩衝區,才能返回。
整體流程如下圖
也就是說這不是真正意義上的非阻塞IO。
IO 多路復用
為每個客戶端創建一個線程,服務器端的線程資源很容易被耗光。
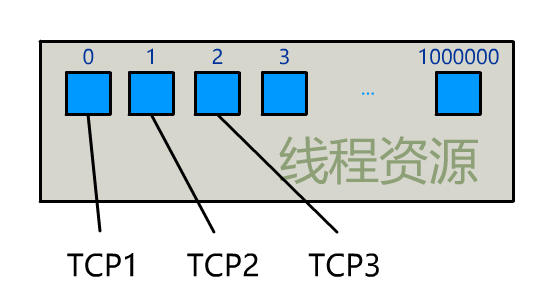
當然還有個聰明的辦法,我們可以每 accept 一個客戶端連接後,將這個文件描述符(connfd)放到一個數組裡。
fdlist.add(connfd);然後弄一個新的線程去不斷遍歷這個數組,調用每一個元素的非阻塞 read 方法。
- while(1) {
- for(fd <-- fdlist) {
- if(read(fd) != -1) {
- doSomeThing();
- }
- }
- }
這樣,我們就成功用一個線程處理了多個客戶端連接。
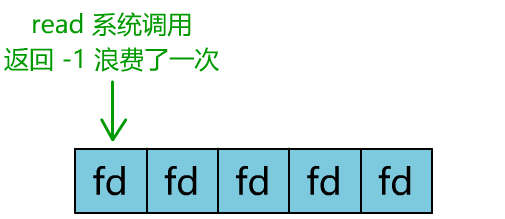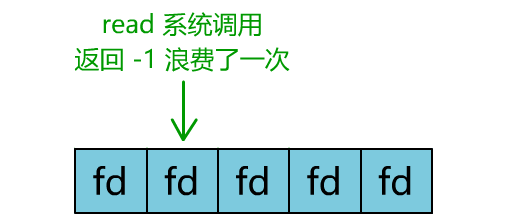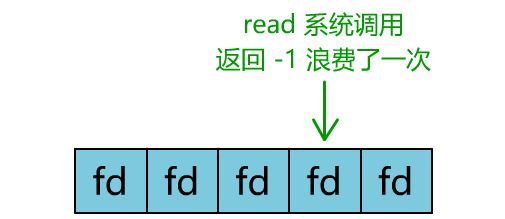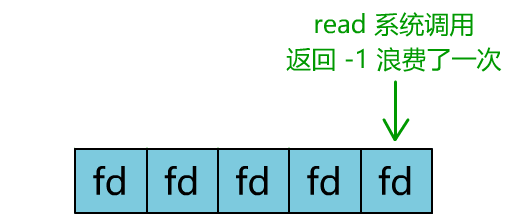
你是不是覺得這有些多路復用的意思?
但這和我們用多線程去將阻塞 IO 改造成看起來是非阻塞 IO 一樣,這種遍歷方式也只是我們用戶自己想出的小把戲,每次遍歷遇到 read 返回 -1 時仍然是一次浪費資源的系統調用。
所以,還是得懇請操作系統老大,提供給我們一個有這樣效果的函數,我們將一批文件描述符通過一次系統調用傳給內核,由內核層去遍歷(而不是在用戶態調用,再陷入到內核態中去遍歷),才能真正解決這個問題。
select
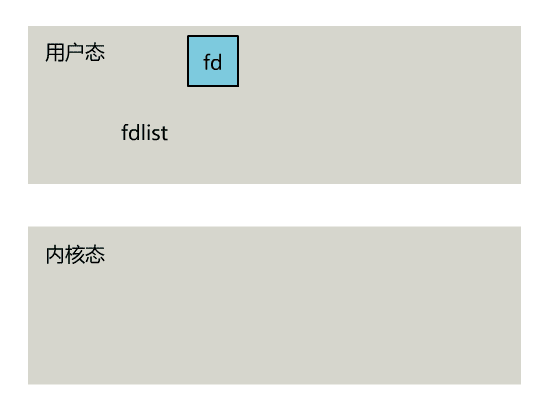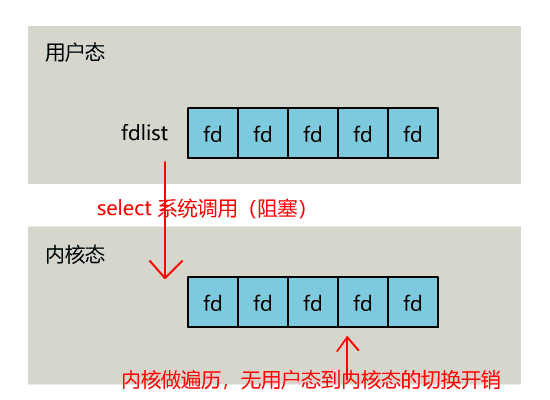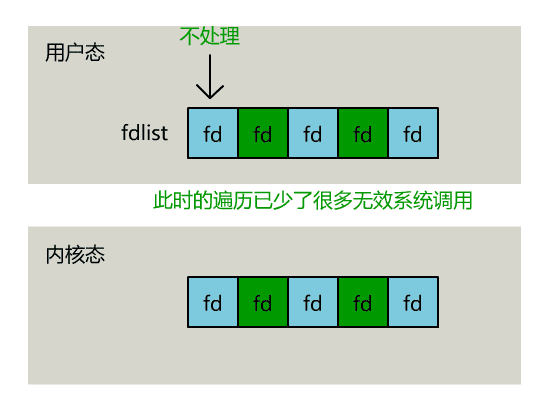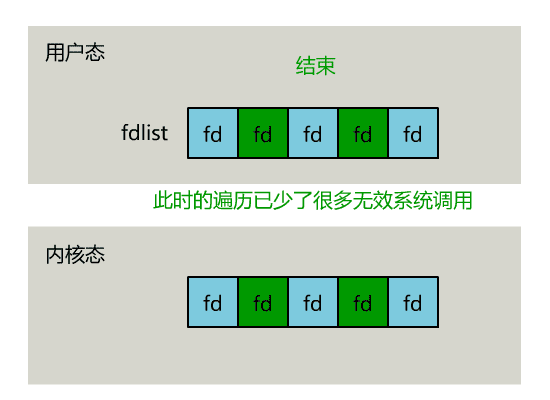
select 是操作系統提供的系統調用函數,通過它,我們可以把一個文件描述符的數組發給操作系統, 讓操作系統去遍歷,確定哪個文件描述符可以讀寫, 然後告訴我們去處理:
select系統調用的函數定義如下。
- int select(
- int nfds,
- fd_set *readfds,
- fd_set *writefds,
- fd_set *exceptfds,
- struct timeval *timeout);
- // nfds:監控的文件描述符集里最大文件描述符加1
- // readfds:監控有讀數據到達文件描述符集合,傳入傳出參數
- // writefds:監控寫數據到達文件描述符集合,傳入傳出參數
- // exceptfds:監控異常發生達文件描述符集合, 傳入傳出參數
- // timeout:定時阻塞監控時間,3種情況
- // 1.NULL,永遠等下去
- // 2.設置timeval,等待固定時間
- // 3.設置timeval里時間均為0,檢查描述字後立即返回,輪詢
服務端代碼,這樣來寫。
首先一個線程不斷接受客戶端連接,並把 socket 文件描述符放到一個 list 里。
- while(1) {
- connfd = accept(listenfd);
- fcntl(connfd, F_SETFL, O_NONBLOCK);
- fdlist.add(connfd);
- }
然後,另一個線程不再自己遍歷,而是調用 select,將這批文件描述符 list 交給操作系統去遍歷。
- while(1) {
- // 把一堆文件描述符 list 傳給 select 函數
- // 有已就緒的文件描述符就返回,nready 表示有多少個就緒的
- nready = select(list);
- ...
- }
不過,當 select 函數返回後,用戶依然需要遍歷剛剛提交給操作系統的 list。
只不過,操作系統會將準備就緒的文件描述符做上標識,用戶層將不會再有無意義的系統調用開銷。
- while(1) {
- nready = select(list);
- // 用戶層依然要遍歷,只不過少了很多無效的系統調用
- for(fd <-- fdlist) {
- if(fd != -1) {
- // 只讀已就緒的文件描述符
- read(fd, buf);
- // 總共只有 nready 個已就緒描述符,不用過多遍歷
- if(--nready == 0) break;
- }
- }
- }
可以看出幾個細節:
- select 調用需要傳入 fd 數組,需要拷貝一份到內核,高並發場景下這樣的拷貝消耗的資源是驚人的。(可優化為不複製)
- select 在內核層仍然是通過遍歷的方式檢查文件描述符的就緒狀態,是個同步過程,只不過無系統調用切換上下文的開銷。(內核層可優化為異步事件通知)
- select 僅僅返回可讀文件描述符的個數,具體哪個可讀還是要用戶自己遍歷。(可優化為只返回給用戶就緒的文件描述符,無需用戶做無效的遍歷)
整個 select 的流程圖如下。
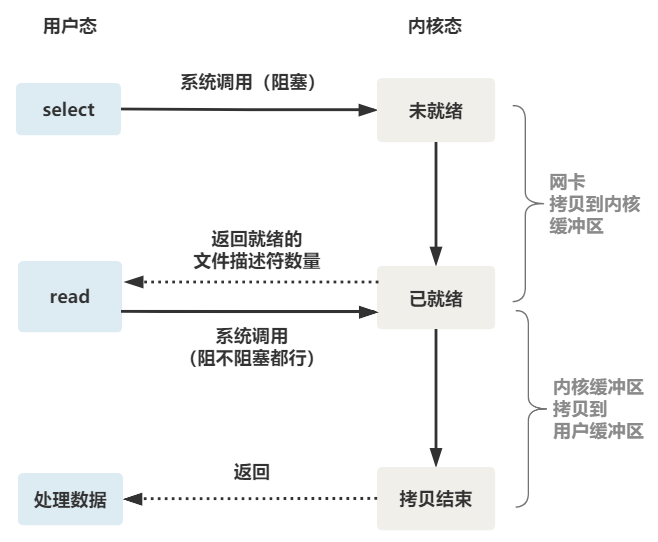
可以看到,這種方式,既做到了一個線程處理多個客戶端連接(文件描述符),又減少了系統調用的開銷(多個文件描述符只有一次 select 的系統調用 + n 次就緒狀態的文件描述符的 read 系統調用)。
epoll
epoll 是最終的大 boss,它解決了 select 和 poll 的一些問題。
還記得上面說的 select 的三個細節么?epoll 主要就是針對這三點進行了改進。
- 內核中保存一份文件描述符集合,無需用戶每次都重新傳入,只需告訴內核修改的部分即可。
- 內核不再通過輪詢的方式找到就緒的文件描述符,而是通過異步 IO 事件喚醒。
- 內核僅會將有 IO 事件的文件描述符返回給用戶,用戶也無需遍歷整個文件描述符集合。
使用起來,其內部原理就像如下一般絲滑。

總結一下。
一切的開始,都起源於這個 read 函數是操作系統提供的,而且是阻塞的,我們叫它 阻塞 IO。
為了破這個局,程序員在用戶態通過多線程來防止主線程卡死。
後來操作系統發現這個需求比較大,於是在操作系統層面提供了非阻塞的 read 函數,這樣程序員就可以在一個線程內完成多個文件描述符的讀取,這就是 非阻塞 IO。
但多個文件描述符的讀取就需要遍歷,當高並發場景越來越多時,用戶態遍歷的文件描述符也越來越多,相當於在 while 循環里進行了越來越多的系統調用。
後來操作系統又發現這個場景需求量較大,於是又在操作系統層面提供了這樣的遍歷文件描述符的機制,這就是 IO 多路復用。
多路復用有三個函數,最開始是 select,然後又發明了 poll 解決了 select 文件描述符的限制,然後又發明了 epoll 解決 select 的三個不足。
所以,IO 模型的演進,其實就是時代的變化,倒逼着操作系統將更多的功能加到自己的內核而已。
如果你建立了這樣的思維,很容易發現網上的一些錯誤。
比如好多文章說,多路復用之所以效率高,是因為用一個線程就可以監控多個文件描述符。
這顯然是知其然而不知其所以然,多路復用產生的效果,完全可以由用戶態去遍歷文件描述符並調用其非阻塞的 read 函數實現。而多路復用快的原因在於,操作系統提供了這樣的系統調用,使得原來的 while 循環里多次系統調用,變成了一次系統調用 + 內核層遍歷這些文件描述符。
就好比我們平時寫業務代碼,把原來 while 循環里調 http 接口進行批量,改成了讓對方提供一個批量添加的 http 接口,然後我們一次 rpc 請求就完成了批量添加。