Hudi 數據湖的插入,更新,查詢,分析操作示例
Hudi 數據湖的插入,更新,查詢,分析操作示例
作者:Grey
原文地址:
前置工作
首先,需要先完成
本文基於上述四個環境已經搭建完成的基礎上進行 Hudi 數據湖的插入,更新,查詢操作。
開發環境
Scala 2.11.8
JDK 1.8
需要熟悉 Maven 構建項目和 Scala 一些基礎語法。
操作步驟
master 節點首先啟動集群,執行:
stop-dfs.sh && start-dfs.sh
啟動 yarn,執行:
stop-yarn.sh && start-yarn.sh
然後準備一個 Mave 項目,在 src/main/resources 目錄下,將 Hadoop 的一些配置文件拷貝進來,分別是
$HADOOP_HOME/etc/hadoop/core-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
注意,需要在你訪問集群的機器上配置 host 文件,這樣才可以識別 master 節點。
$HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
$HADOOP_HOME/etc/hadoop/yarn-site.xml 文件,目前還沒有任何配置
<?xml version="1.0"?>
<configuration>
</configuration>
然後,設計實體的數據結構,
package git.snippet.entity
case class MyEntity(uid: Int,
uname: String,
dt: String
)
插入數據代碼如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataInsertion {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
insertData(sparkSession)
}
def insertData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交時間
val df = sparkSession.read.text("/mydata/data1")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 時間戳列
.withColumn("uuid", col("uid"))
.withColumn("hudipart", col("dt")) //增加hudi分區列
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交時間列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一標示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分區列
.mode(SaveMode.Overwrite)
.save("/snippet/data/hudi")
}
}
然後,在 master 節點先準備好數據
vi data1
輸入如下數據
{'uid':1,'uname':'grey','dt':'2022/09'}
{'uid':2,'uname':'tony','dt':'2022/10'}
然後創建文件目錄,
hdfs dfs -mkdir /mydata/
把 data1 放入目錄下
hdfs dfs -put data1 /mydata/
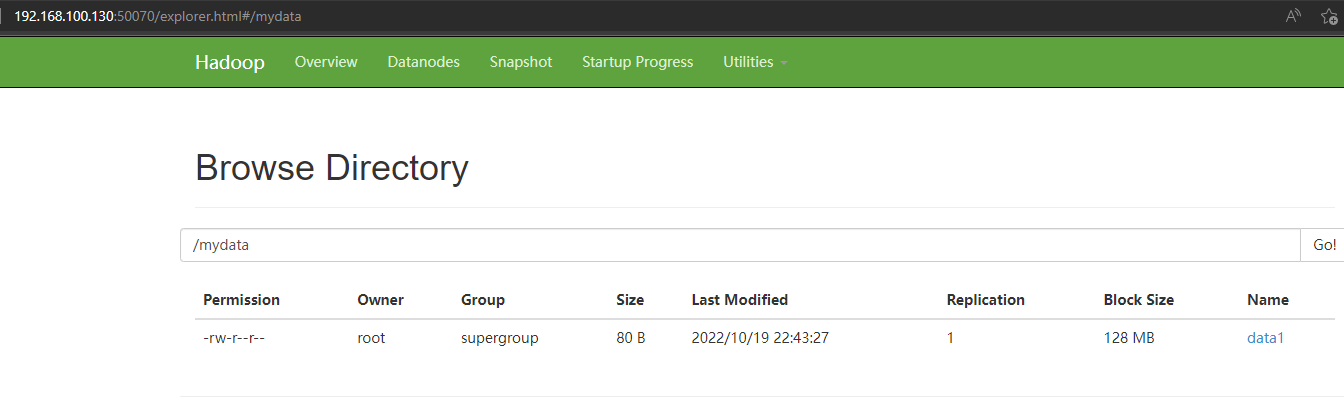
訪問://192.168.100.130:50070/explorer.html#/mydata
可以查到這個數據
接下來執行插入數據的 scala 代碼,執行完畢後,驗證一下
訪問://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到插入的數據

準備一個 data2 文件
cp data1 data2 && vi data2
data2 的數據更新為
{'uid':1,'uname':'grey1','dt':'2022/11'}
{'uid':2,'uname':'tony1','dt':'2022/12'}
然後執行
hdfs dfs -put data2 /mydata/
更新數據的代碼,我們可以做如下調整,完整代碼如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataUpdate {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
updateData(sparkSession)
}
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交時間
val df = sparkSession.read.text("/mydata/data2")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 時間戳列
.withColumn("uuid", col("uid")) //添加uuid 列
.withColumn("hudipart", col("dt")) //增加hudi分區列
result.write.format("org.apache.hudi")
// .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交時間列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一標示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分區列
.mode(SaveMode.Append)
.save("/snippet/data/hudi")
}
}
執行更新數據的代碼。
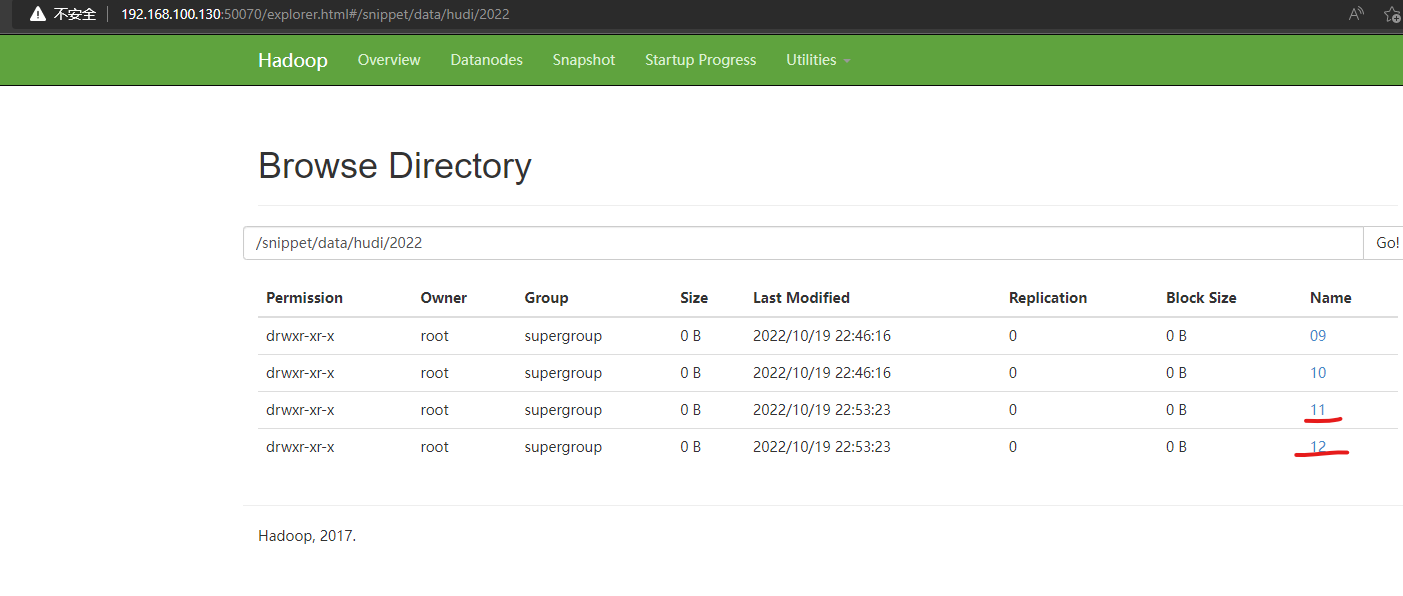
驗證一下,訪問://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到更新的數據情況
數據查詢的代碼也很簡單,完整代碼如下
package git.snippet.test
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DataQuery {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
queryData(sparkSession)
}
def queryData(sparkSession: SparkSession) = {
val df = sparkSession.read.format("org.apache.hudi")
.load("/snippet/data/hudi/*/*")
df.show()
println(df.count())
}
}
執行,輸出以下信息,驗證成功。

數據查詢也支持很多查詢條件,比如增量查詢,按時間段查詢等。
接下來是 flink 實時數據分析的服務,首先需要在 master 上啟動 kafka,並創建 一個名字為 mytopic 的 topic,詳見Linux 下搭建 Kafka 環境
相關命令如下
創建topic
kafka-topics.sh --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --create --topic mytopic
生產者啟動配置
kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic mytopic
消費者啟動配置
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic mytopic
然後運行如下代碼
package git.snippet.analyzer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class DataAnalyzer {
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
properties.setProperty("group.id", "snippet");
//構建FlinkKafkaConsumer
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>("mytopic", new SimpleStringSchema(), properties);
//指定偏移量
myConsumer.setStartFromLatest();
final DataStream<String> stream = env.addSource(myConsumer);
env.enableCheckpointing(5000);
stream.print();
try {
env.execute("DataAnalyzer");
} catch (Exception e) {
e.printStackTrace();
}
}
}
其中
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
根據自己的配置調整,然後通過 kakfa 的生產者客戶端輸入一些數據,這邊可以收到這個數據,驗證完畢。
完整代碼見


