aws上傳文件、刪除文件、圖像識別
目錄
aws的上傳、刪除s3文件以及圖像識別文字功能
準備工作
安裝aws cli
根據自己的操作系統,下載相應的安裝包安裝。安裝過程很簡單,在此不再贅述。
在安裝完成之後,運行以下兩個命令來驗證AWS CLI是否安裝成功。參考以下示例,在MacOS上打開Terminal程序。如果是Windows系統,打開cmd。
- where aws / which aws 查看AWS CLI安裝路徑
- aws –version 查看AWS CLI版本
zonghan@MacBook-Pro ~ % aws --version
aws-cli/2.0.30 Python/3.7.4 Darwin/21.6.0 botocore/2.0.0dev34
zonghan@MacBook-Pro ~ % which aws
/usr/local/bin/aws
初始化配置AWS CLI
在使用AWS CLI前,可使用aws configure命令,完成初始化配置。
zonghan@MacBook-Pro ~ % aws configure
AWS Access Key ID [None]: AKIA3GRZL6WIQEXAMPLE
AWS Secret Access Key [None]: k+ci5r+hAcM3x61w1example
Default region name [None]: ap-east-1
Default output format [None]: json
-
AWS Access Key ID 及AWS Secret Access Key可在AWS管理控制台獲取,AWS CLI將會使用此信息作為用戶名、密碼連接AWS服務。
點擊AWS管理控制台右上角的用戶名 –> 選擇Security Credentials
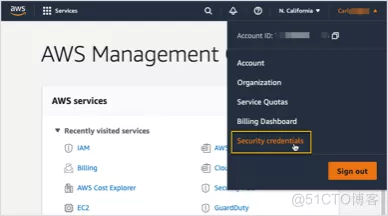
- 點擊Create New Access Key以創建一對Access Key ID 及Secret Access Key,並保存(且僅能在創建時保存)
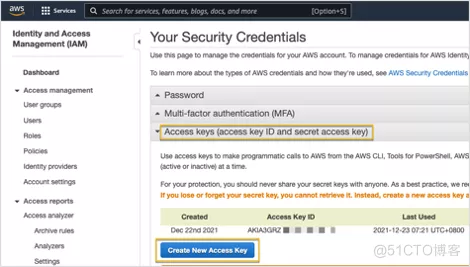
- Default region name,用以指定要連接的AWS 區域代碼。每個AWS區域對應的代碼可通過 此鏈接查找。
- Default output format,用以指定命令行輸出內容的格式,默認使用JSON作為所有輸出的格式。也可以使用以下任一格式:
JSON(JavaScript Object Notation)
YAML: 僅在 AWS CLI v2 版本中可用
Text
Table
更多詳細的配置請看該文章
s3存儲桶開通
該電腦配置的認證用戶在aws的s3上有權限訪問一個s3的存儲桶,這個一般都是管理員給你開通
圖像識別文字功能開通
該電腦配置的認證用戶在aws的Amazon Textract的權限,這個一般都是管理員給你開通
aws的sdk
import boto3
from botocore.exceptions import ClientError, BotoCoreError
安裝上述boto3的模塊,一般會同時安裝botocore模塊
上傳文件
方法一
使用upload_file方法來上傳文件
import logging
import boto3
from botocore.exceptions import ClientError
import os
def upload_file(file_path, bucket, file_name=None):
"""Upload a file to an S3 bucket
:param file_name: File to upload
:param bucket: Bucket to upload to
:param object_name: S3 object name. If not specified then file_name is used
:return: True if file was uploaded, else False
"""
# If S3 object_name was not specified, use file_name
if object_name is None:
object_name = os.path.basename(file_name)
# Upload the file
s3_client = boto3.client('s3')
# s3 = boto3.resource('s3')
try:
response = s3_client.upload_file(file_path, bucket, file_name)
# response = s3.Bucket(bucket).upload_file(file_name, object_name)
except ClientError as e:
logging.error(e)
return False
return True
方法二
使用PutObject來上傳文件
import logging
import os
import boto3
from botocore.exceptions import ClientError, BotoCoreError
from django.conf import settings
from celery import shared_task
logger = logging.getLogger(__name__)
def upload_file_to_aws(file_path, bucket, file_name=None):
"""Upload a file to an S3 bucket
:param file_path: File to upload
:param file_name: S3 object name. If not specified then file_path is used
:return: True if file was uploaded, else False
"""
# If S3 object_name was not specified, use file_name
if file_name is None:
file_name = os.path.basename(file_path)
# Upload the file
s3 = boto3.resource('s3')
try:
with open(file_path, 'rb') as f:
data = f.read()
obj = s3.Object(bucket, file_name)
obj.put(
Body=data
)
except BotoCoreError as e:
logger.info(e)
return False
return True
刪除文件
def delete_aws_file(file_name, bucket):
try:
s3_client = boto3.client("s3")
s3_client.delete_object(Bucket=bucket, Key=file_name)
except Exception as e:
logger.info(e)
圖像識別文字
識別發票、賬單這種key,value的形式
def get_labels_and_values(result, field):
if "LabelDetection" in field:
key = field.get("LabelDetection")["Text"]
value = field.get("ValueDetection")["Text"]
if key and value:
if key.endswith(":"):
key = key[:-1]
result.append({key: value})
def process_text_detection(bucket, document):
try:
client = boto3.client("textract", region_name="ap-south-1")
response = client.analyze_expense(
Document={"S3Object": {"Bucket": bucket, "Name": document}}
)
except Exception as e:
logger.info(e)
raise "An unknown error occurred on the aws service"
result = {}
for expense_doc in response["ExpenseDocuments"]:
for line_item_group in expense_doc["LineItemGroups"]:
for line_items in line_item_group["LineItems"]:
for expense_fields in line_items["LineItemExpenseFields"]:
get_labels_and_values(result, expense_fields)
for summary_field in expense_doc["SummaryFields"]:
get_labels_and_values(result, summary_field)
return result
def get_extract_info(bucket, document):
return process_text_detection(bucket, document)
單純的識別文字
#Analyzes text in a document stored in an S3 bucket. Display polygon box around text and angled text
import boto3
import io
from io import BytesIO
import sys
import math
from PIL import Image, ImageDraw, ImageFont
def ShowBoundingBox(draw,box,width,height,boxColor):
left = width * box['Left']
top = height * box['Top']
draw.rectangle([left,top, left + (width * box['Width']), top +(height * box['Height'])],outline=boxColor)
def ShowSelectedElement(draw,box,width,height,boxColor):
left = width * box['Left']
top = height * box['Top']
draw.rectangle([left,top, left + (width * box['Width']), top +(height * box['Height'])],fill=boxColor)
# Displays information about a block returned by text detection and text analysis
def DisplayBlockInformation(block):
print('Id: {}'.format(block['Id']))
if 'Text' in block:
print(' Detected: ' + block['Text'])
print(' Type: ' + block['BlockType'])
if 'Confidence' in block:
print(' Confidence: ' + "{:.2f}".format(block['Confidence']) + "%")
if block['BlockType'] == 'CELL':
print(" Cell information")
print(" Column:" + str(block['ColumnIndex']))
print(" Row:" + str(block['RowIndex']))
print(" Column Span:" + str(block['ColumnSpan']))
print(" RowSpan:" + str(block['ColumnSpan']))
if 'Relationships' in block:
print(' Relationships: {}'.format(block['Relationships']))
print(' Geometry: ')
print(' Bounding Box: {}'.format(block['Geometry']['BoundingBox']))
print(' Polygon: {}'.format(block['Geometry']['Polygon']))
if block['BlockType'] == "KEY_VALUE_SET":
print (' Entity Type: ' + block['EntityTypes'][0])
if block['BlockType'] == 'SELECTION_ELEMENT':
print(' Selection element detected: ', end='')
if block['SelectionStatus'] =='SELECTED':
print('Selected')
else:
print('Not selected')
if 'Page' in block:
print('Page: ' + block['Page'])
print()
def process_text_analysis(bucket, document):
#Get the document from S3
s3_connection = boto3.resource('s3')
s3_object = s3_connection.Object(bucket,document)
s3_response = s3_object.get()
stream = io.BytesIO(s3_response['Body'].read())
image=Image.open(stream)
# Analyze the document
client = boto3.client('textract')
image_binary = stream.getvalue()
response = client.analyze_document(Document={'Bytes': image_binary},
FeatureTypes=["TABLES", "FORMS"])
### Alternatively, process using S3 object ###
#response = client.analyze_document(
# Document={'S3Object': {'Bucket': bucket, 'Name': document}},
# FeatureTypes=["TABLES", "FORMS"])
### To use a local file ###
# with open("pathToFile", 'rb') as img_file:
### To display image using PIL ###
# image = Image.open()
### Read bytes ###
# img_bytes = img_file.read()
# response = client.analyze_document(Document={'Bytes': img_bytes}, FeatureTypes=["TABLES", "FORMS"])
#Get the text blocks
blocks=response['Blocks']
width, height =image.size
draw = ImageDraw.Draw(image)
print ('Detected Document Text')
# Create image showing bounding box/polygon the detected lines/text
for block in blocks:
DisplayBlockInformation(block)
draw=ImageDraw.Draw(image)
if block['BlockType'] == "KEY_VALUE_SET":
if block['EntityTypes'][0] == "KEY":
ShowBoundingBox(draw, block['Geometry']['BoundingBox'],width,height,'red')
else:
ShowBoundingBox(draw, block['Geometry']['BoundingBox'],width,height,'green')
if block['BlockType'] == 'TABLE':
ShowBoundingBox(draw, block['Geometry']['BoundingBox'],width,height, 'blue')
if block['BlockType'] == 'CELL':
ShowBoundingBox(draw, block['Geometry']['BoundingBox'],width,height, 'yellow')
if block['BlockType'] == 'SELECTION_ELEMENT':
if block['SelectionStatus'] =='SELECTED':
ShowSelectedElement(draw, block['Geometry']['BoundingBox'],width,height, 'blue')
#uncomment to draw polygon for all Blocks
#points=[]
#for polygon in block['Geometry']['Polygon']:
# points.append((width * polygon['X'], height * polygon['Y']))
#draw.polygon((points), outline='blue')
# Display the image
image.show()
return len(blocks)
def main():
bucket = ''
document = ''
block_count=process_text_analysis(bucket,document)
print("Blocks detected: " + str(block_count))
if __name__ == "__main__":
main()

