大數據技術之HBase原理與實戰歸納分享-上
@
概述
定義
HBase 官網地址 //hbase.apache.org/
HBase 官網文檔 //hbase.apache.org/book.html
HBase GitHub源碼地址 //github.com/apache/hbase
Apache HBase™是以HDFS為數據存儲分佈式的、可伸縮的Hadoop NoSQL數據庫。最新版本為2.5.0
HBase支持對大數據進行隨機、實時的讀寫訪問,可以在商用硬件集群上託管非常大的表——數十億行X數百萬列。Apache HBase是一個開源的、分佈式的、版本化的、非關係數據庫,模仿了谷歌開發的Bigtable結構化數據的分佈式存儲系統,與Bigtable利用了谷歌文件系統提供的分佈式數據存儲一樣,Apache HBase在Hadoop和HDFS的基礎上提供了類似Bigtable的功能。
特點
- 可擴展性。
- 讀寫嚴格一致。
- 自動和可配置的表分片。
- regionserver之間的自動故障轉移支持。
- 使用Apache HBase表支持Hadoop MapReduce作業。
- 易於使用Java API進行客戶端訪問。
- 塊緩存和Bloom過濾器用於實時查詢。
- 通過服務器端過濾器下推查詢謂詞。
- Thrift網關和一個支持XML、Protobuf和二進制數據編碼選項的rest Web服務。
- 可擴展的基於jruby (JIRB)的shell。
- 支持通過Hadoop指標子模塊導出指標。
數據模型
概述
- HBase的設計理念依據Coogle 的BigTable論文,論文中說到Bigtable 是一個稀疏的,分佈式的,持久的多維排序map。
- 映射由行鍵,列鍵和時間戳索引;映射中的每一個值都是一個未解釋的位元組數組。
- HBase數據模型和BigTable的對應關係如下
- HBase 使用於 BigTable非常相似的數據模型,用戶將數據行存儲在帶標籤的表中,數據行具有可排序的鍵和任意數量的列。
- 該表存儲稀疏,因此如果用戶喜歡,同一表中的行可以具有瘋狂變化的列
HBase 數據模型的關鍵在於稀疏、分佈式、多維、排序的映射。其中映射 map 指代非關係型數據庫的 key-Value 結構。
邏輯結構
HBase 可以用於存儲多種結構的數據,以 JSON 為例:
{
"row_key1":{
"personal_info":{
"name":"zhangsan",
"city":"北京",
"phone":"131********"
},
"office_info":{
"tel":"010-1111111",
"address":"atguigu"
}
},
"row_key11":{
"personal_info":{
"city":"上海",
"phone":"132********"
},
"office_info":{
"tel":"010-1111111"
}
},
"row_key2":{
......
}
邏輯結構存儲數據稀疏,數據存儲多維,不同的行具有不同的列。數據存儲整體有序,按照RowKey的字典序排列,RowKey為Byte數組,示例如下:
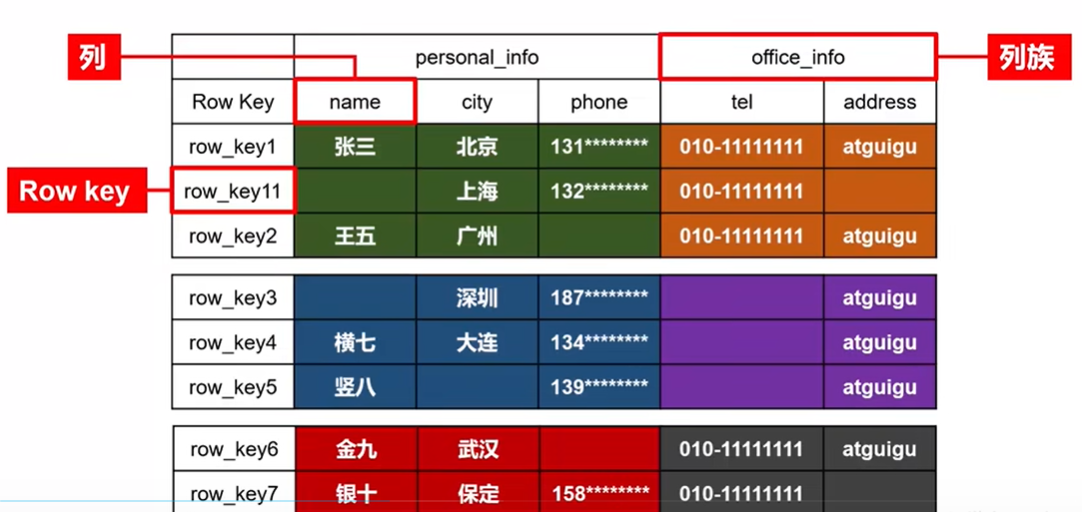
物理存儲結構
物理存儲結構即為數據映射關係,而在概念視圖的空單元格,底層實際根本不儲存。
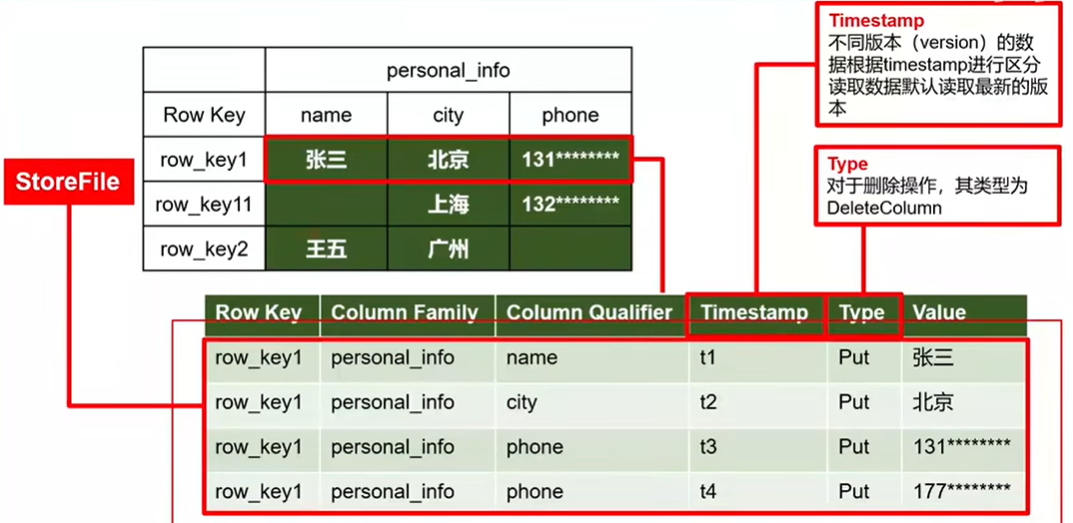
數據模型
- Name Space:命名空間,類似於關係型數據庫的 database 概念,每個命名空間下有多個表。HBase 兩個自帶的命名空間,分別是 hbase 和default,hbase 中存放的是 HBase 內置的表,default表是用戶默認使用的命名空間。
- Table:類似於關係型數據庫的表概念。不同的是,HBase 定義表時只需要聲明列族即可,不需要聲明具體的列。因為數據存儲時稀疏的,所有往 HBase 寫入數據時,字段可以動態、按需指定。因此和關係型數據庫相比,HBase 能夠輕鬆應對字段變更的場景。
- Row:HBase 表中的每行數據都由一個 RowKey 和多個 Column(列)組成,數據是按照 RowKey 的字典順序存儲的,並且查詢數據時只能根據 RowKey 進行檢索,所以 RowKey 的設計十分重要。
- Column:HBase 中的每個列都由 Column Family(列族)和 Column Qualifier(列限定符)進行限定,例如 info:name,info:age。建表時,只需指明列族,而列限定符無需預先定義。
- Time Stamp:用於標識數據的不同版本(version),每條數據寫入時,系統會自動為其加上該字段, 其值為寫入 HBase 的時間。
- Cell:由{rowkey, column Family:column Qualifier, timestamp} 唯一確定的單元。cell 中的數據全部是位元組碼形式存儲。
應用場景
- 對象存儲:比如一些app的海量的圖片、網頁、新聞等對象,可以存儲在HBase中,有些病毒公司的病毒庫也可以存儲在HBase中。
- 時空數據:主要是軌跡、氣象網格之類
- 比如滴滴打車的軌跡數據主要存在HBase之中。
- 另外大數據量的車聯網企業,數據也都是存在HBase中。
- 比如互聯網出行,智慧物流與外賣遞送,傳感網與實時GIS等場景。
- 時序數據:時序數據就是分佈在時間上的一系列數值。
- HBase之上有OpenTSDB模塊,可以滿足時序類場景的需求。
- 比如我們有很多的設備、傳感器,產生很多數據,如果規模不是特別大的廠家有幾千個風機,每個風機有幾百個指標,那麼就會有一百萬左右的時序數據,如果用採樣每一秒會產生一百萬個時間點,如果用傳統數據庫,那麼每一秒會產生一百萬次,持續地往MQ做一百萬次,它會崩裂。並且查詢也是個大問題,除了多維查詢以外,我們還會額外地增加時間緯度,查看一段時間的數據。這時候HBase很好了滿足了時序類場景的需求。
- 推薦畫像:特別是用戶的畫像,是一個比較大的稀疏矩陣,螞蟻的風控就是構建在HBase上。用戶畫像有用戶數據量大,用戶標籤多,標籤統計維度不確定等特點,適合HBase特性的發揮。
- 消息/訂單:在電信領域、銀行領域,不少的訂單查詢底層的存儲,另外不少通信、消息同步的應用構建在HBase之上。
- Feed流:是RSS中用來接收該信息來源更新的接口,簡單的說就是持續更新並呈現給用戶的內容。比如微信朋友圈中看到的好友的一條條狀態,微博看到的你關注的人更新的內容,App收到的一篇篇新文章的推送,都算是feed流。
- NewSQL:HBase上有Phoenix的插件,可以滿足二級索引、SQL的需求,對接傳統數據需要SQL非事務的需求。從NoSQL到NewSQL,Phoenix或許是新的趨勢。
基礎架構
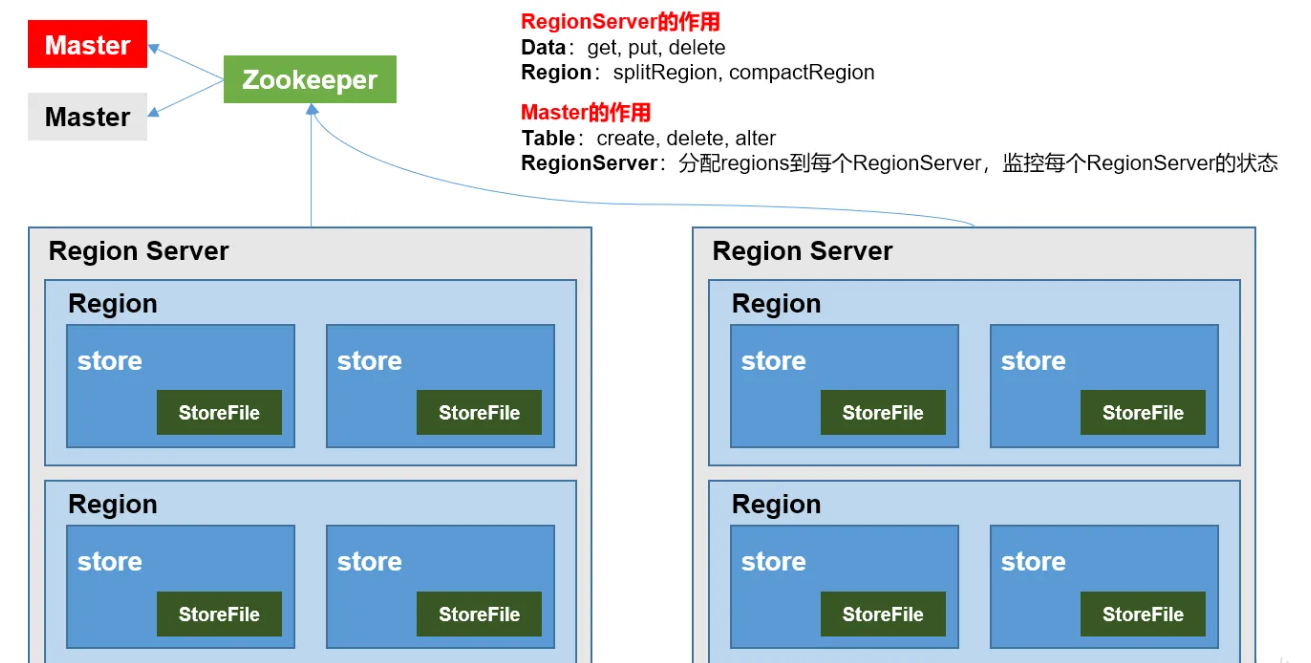
組成角色包含如下幾個部分:
- Master:實現類為 HMaster,負責監控集群中所有的 RegionServer 實例。
- 主要作用如下:
- 管理元數據表格 hbase:meta,接收用戶對表格創建修改刪除的命令並執行
- 監控 region 是否需要進行負載均衡,故障轉移和 region 的拆分。
- 管理元數據表格 hbase:meta,接收用戶對表格創建修改刪除的命令並執行。
- 監控 region 是否需要進行負載均衡,故障轉移和 region 的拆分。
- 通過啟動多個後台線程監控實現上述功能:
- LoadBalancer 負載均衡器:周期性監控 region 分佈在 regionServer 上面是否均衡,由參數 hbase.balancer.period 控 制周期時間,默認 5 分鐘。
- CatalogJanitor 元數據管理器:定期檢查和清理 hbase:meta 中的數據。meta 表內容在進階介紹。
- MasterProcWAL master 預寫日誌處理器:把 master 需要執行的任務記錄到預寫日誌 WAL 中,如果 master 宕機,讓 backupMaster 讀取日誌繼續干。
- 主要作用如下:
- Region Server:Region Server 實現類為 HRegionServer,主要作用如下:
- 負責數據 cell 的處理,例如寫入數據 put,查詢數據 get 等。
- 拆分合併 region 的實際執行者,有 master 監控,有 regionServer 執行。
- Zookeeper:HBase 通過 Zookeeper 來做 master 的高可用、記錄 RegionServer 的部署信息、並且存儲 有 meta 表的位置信息。 HBase 對於數據的讀寫操作時直接訪問 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客戶端可以直接訪問 master。使用此功能,會加大對 master 的壓力,減輕對 Zookeeper 的壓力。
- HDFS:HDFS 為 Hbase 提供最終的底層數據存儲服務,同時為 HBase 提供高容錯的支持。
安裝
前置條件
- Zookeeper(使用前面文章已部署集群)
- HDFS(使用前面文章已部署集群)
部署
# 下載最新版本HBase
wget --no-check-certificate //dlcdn.apache.org/hbase/2.5.0/hbase-2.5.0-bin.tar.gz
# 解壓
tar -xvf hbase-2.5.0-bin.tar.gz
# 進入目錄
cd hbase-2.5.0
# 配置環境變量
vim /etc/profile
export HBASE_HOME=/home/commons/hbase-2.5.0
export PATH=$HBASE_HOME/bin:$PATH
# 將配置文件分發到另外兩台節點上
scp /etc/profile hadoop2:/etc/
scp /etc/profile hadoop3:/etc/
# 在三台上執行環境變量生成命令
source /etc/profile
# 修改conf目錄下配置文件hbase-env.sh,
vim conf/hbase-env.sh
# false 取消 不需要自己管理實例 用zookeeper
export HBASE_MANAGES_ZK=false
# 聲明JAVA_HOME
export JAVA_HOME=/home/commons/jdk8
# HBase的jar包和Hadoop的jar包有衝突,導致服務沒有起來,報錯如object is not an instance of declaring class可以配置這個
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
- 修改conf目錄下配置文件vim conf/hbase-site.xml
##修改,
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
##去掉
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
##增加
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 記得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到臨時文件夾-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop2:9000/hbase</value>
<!--8020這個端口號,要跟hadoop的NameNode一樣-->
<description>The directory shared by RegionServers.
</description>
</property>
- 修改regionservers配置vim conf/regionservers
hadoop1
hadoop2
hadoop3
- 將Hadoop的配置文件core-site.xml和hdfs-site.xml拷貝到HBase的conf目錄下
cp /home/commons/hadoop/etc/hadoop/core-site.xml conf/
cp /home/commons/hadoop/etc/hadoop/hdfs-site.xml conf/
- 分發HBase目錄到其他兩個節點上
scp -r /home/commons/hbase-2.5.0 hadoop2:/home/commons
scp -r /home/commons/hbase-2.5.0 hadoop3:/home/commons
啟動服務
# 單點啟動
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
# 群啟
bin/start-hbase.sh
# 停止服務
bin/stop-hbase.sh
群啟後查看服務進程
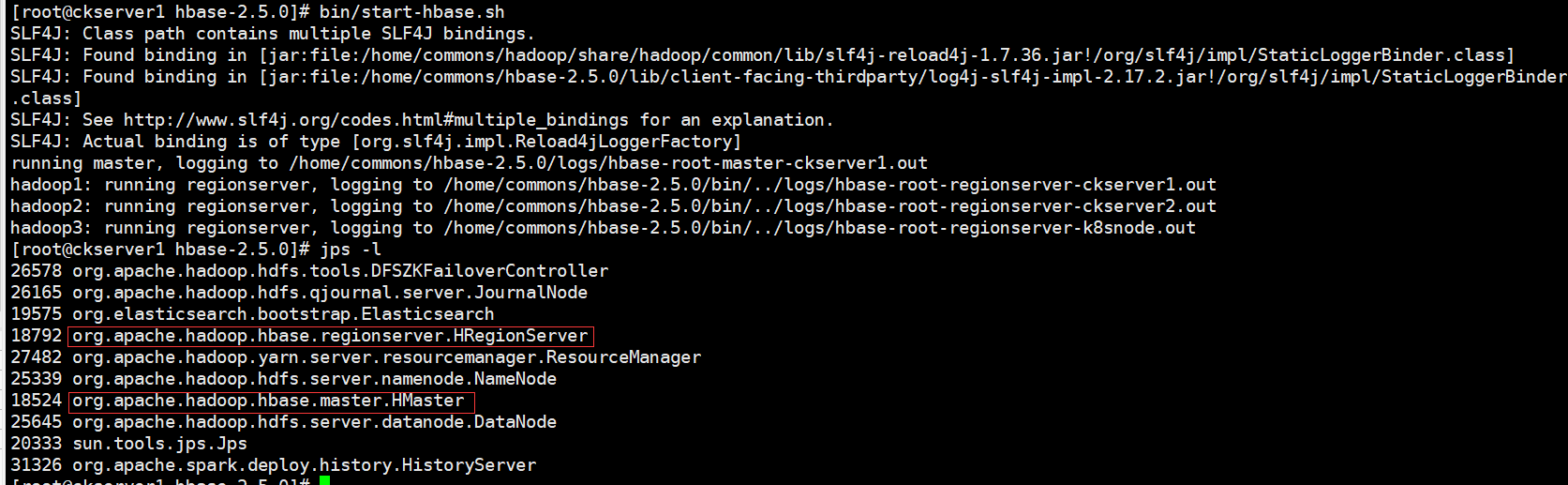
啟動成功後,可以通過「host:port」的方式來訪問 HBase 管理頁面, //hadoop1:16010
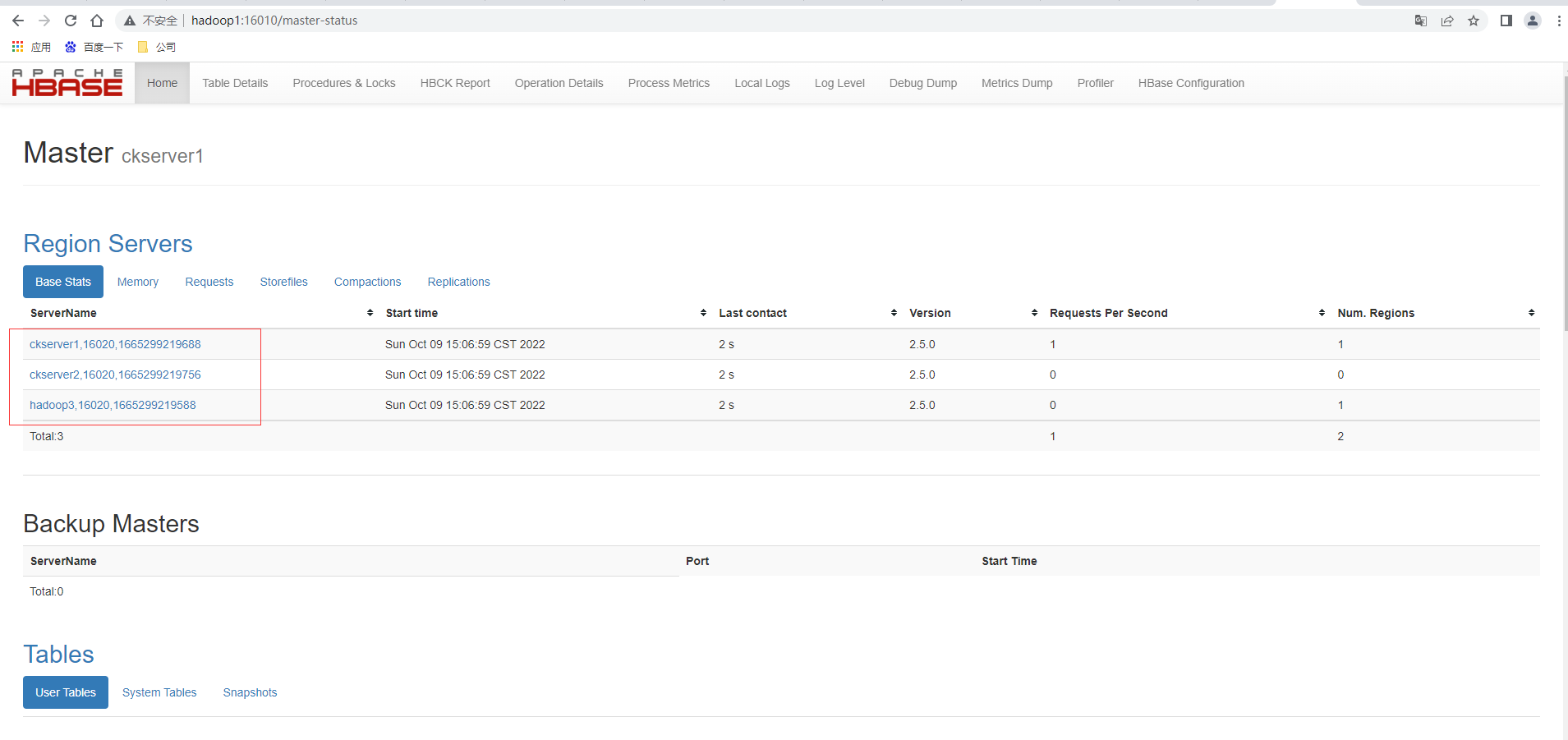
高可用
在 HBase 中 HMaster 負責監控 HRegionServer 的生命周期,均衡 RegionServer 的負載, 如果 HMaster 掛掉了,那麼整個 HBase 集群將陷入不健康的狀態,並且此時的工作狀態並不 會維持太久。所以 HBase 支持對 HMaster 的高可用配置。
# 先關閉上面啟動的HBase集群
bin/stop-hbase.sh
# 在 conf 目錄下創建 backup-masters 文件
touch conf/backup-masters
# 在 backup-masters 文件中配置高可用 HMaster 節點
echo hadoop2 > conf/backup-masters
# 將conf/backup-masters scp 到其他節點
scp /home/commons/hbase-2.5.0/conf/backup-masters hadoop2:/home/commons/hbase-2.5.0/conf
scp /home/commons/hbase-2.5.0/conf/backup-masters hadoop3:/home/commons/hbase-2.5.0/conf
# 重啟 hbase
bin/start-hbase.sh
群啟後查看服務進程,發現多了一個master進程
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-EteyEUXe-1665312413397)(image-20221009125044450.png)]
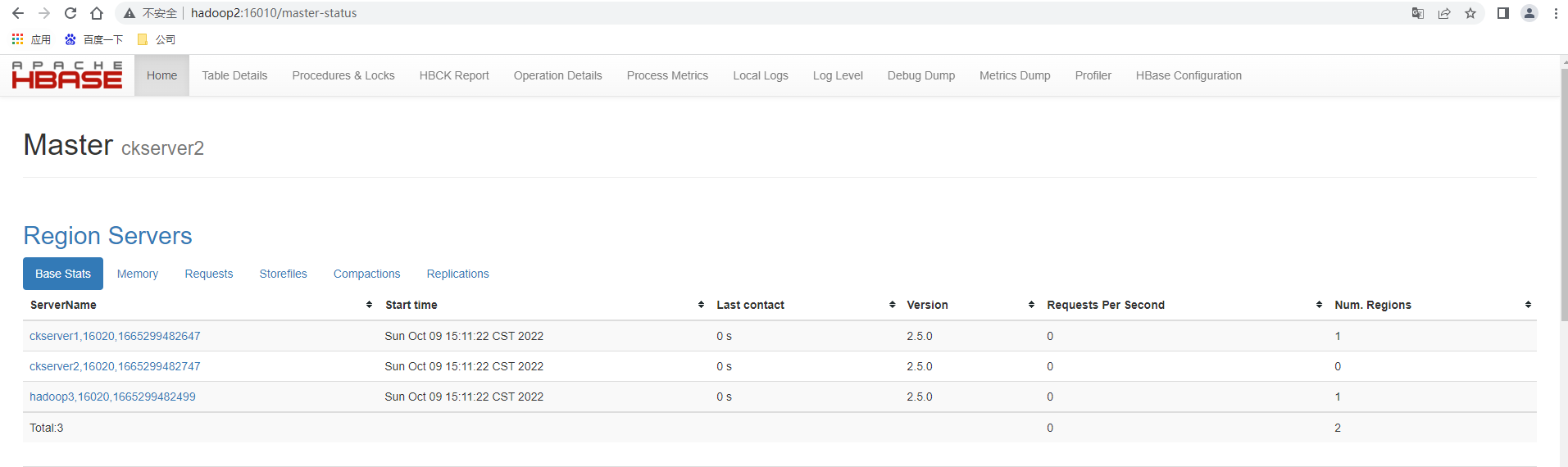
打開頁面測試另一台master顯示其為備用的Master,主master還是ckserver1也即是hadoop1,查看//hadoop2:16010
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-IePncDF4-1665312413398)(image-20221009125144397.png)]
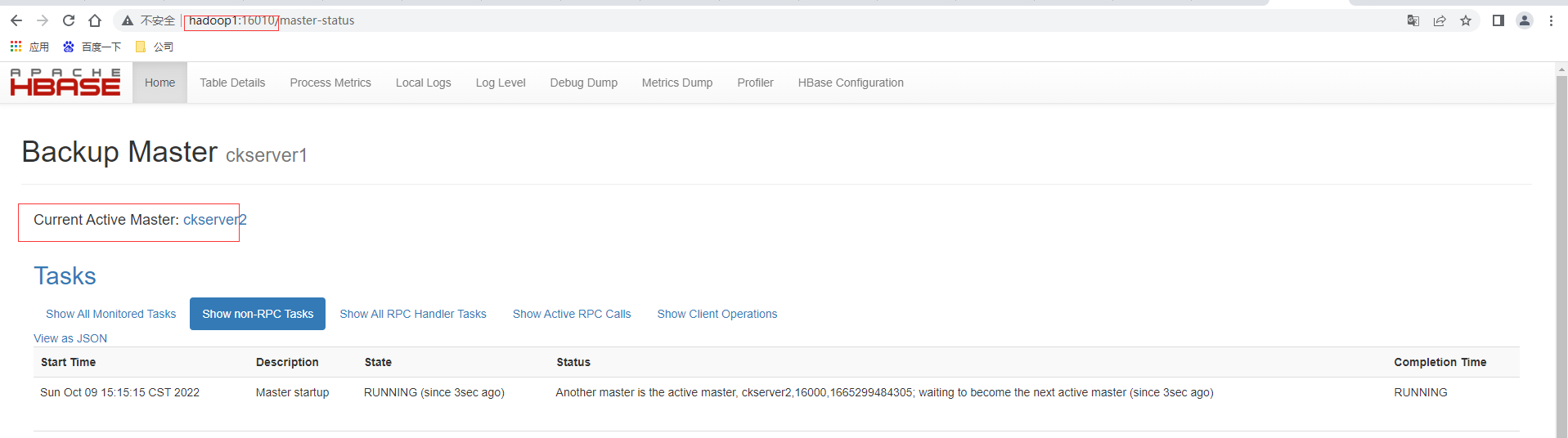
手動kill -9 殺死ckserver1也即是hadoop1上的HMaster進程,再次查看//hadoop2:16010,發現主master已經成功的切換為ckserver2也即是hadoop2
然後再單獨啟動ckserver1也即是hadoop1上的HMaster,執行bin/hbase-daemon.sh start master,這時訪問//hadoop1:16010,發現hadoop1為備用master。
Shell操作
基礎操作
# 進入 HBase 客戶端命令行hbase shell# 查看幫助命令夠展示 HBase 中所有能使用的命令,主要使用的命令有 namespace 命令空間相關, DDL 創建修改表格,DML 寫入讀取數據。help
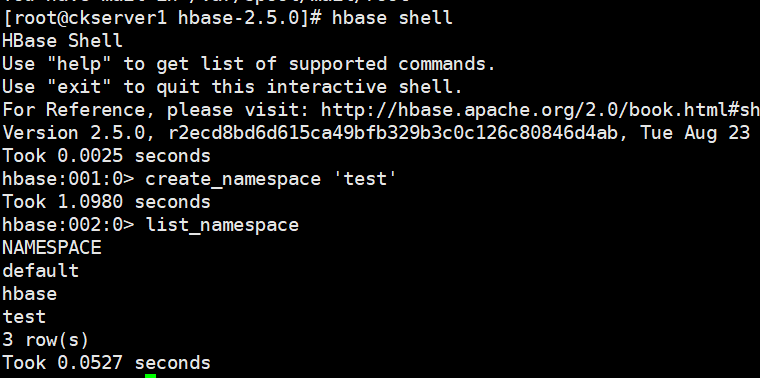
命令空間
# 使用特定的 help 語法能夠查看命令如何使用。help 'create_namespace'# 創建命名空間 testcreate_namespace 'test'# 查看所有的命名空間list_namespace
DDL
# 創建表,在test命名空間中創建表格 student,兩個列族。info 列族數據維護的版本數為 5 個, 如果不寫默認版本數為 1。create 'test:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}# 如果創建表格只有一個列族,沒有列族屬性,可以簡寫。如果不寫命名空間,使用默認的命名空間 default。create 'student1','info'# 查看錶查看錶有兩個命令:list 和 describe,list:查看所有的表名,describe:查看一個表的詳情listdescribe 'student1'
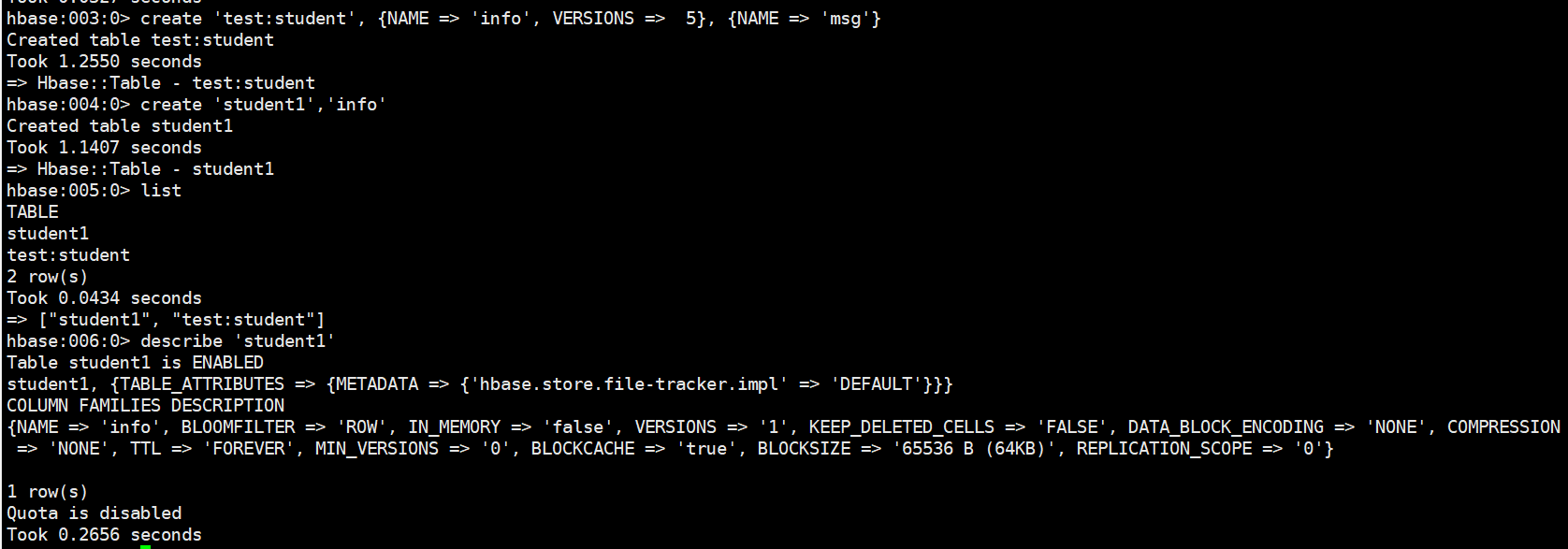
# 修改表表名創建時寫的所有和列族相關的信息,都可以後續通過 alter 修改,包括增加刪除列族。增加列族和修改信息都使用覆蓋的方法alter 'student1', {NAME => 'f1', VERSIONS => 3} # 刪除信息使用特殊的語法alter 'student1', NAME => 'f1', METHOD => 'delete' hbase:016:0> alter 'student1', 'delete' => 'f1'# shell 中刪除表格,需要先將表格狀態設置為不可用。disable 'student1' drop 'student1'
DML
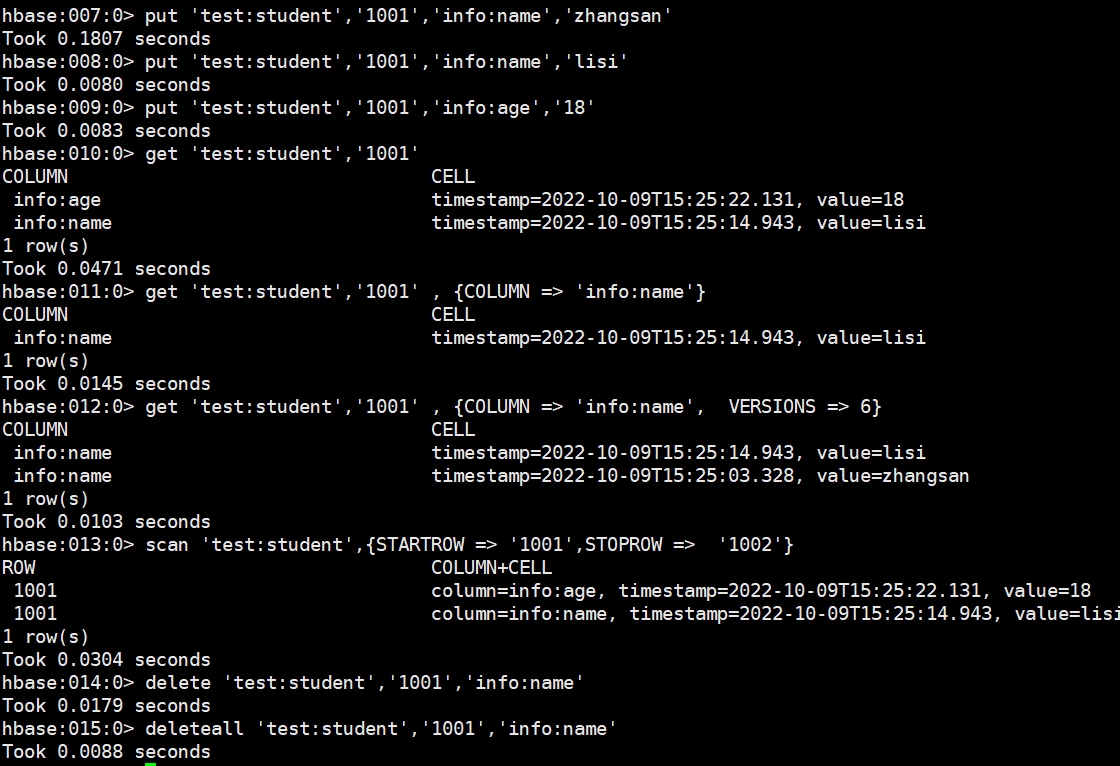
# 寫入數據在 HBase 中如果想要寫入數據,只能添加結構中最底層的 cell。可以手動寫入時間戳指 定 cell 的版本,推薦不寫默認使用當前的系統時間,如果重複寫入相同 rowKey,相同列的數據,會寫入多個版本進行覆蓋。put 'test:student','1001','info:name','zhangsan' put 'test:student','1001','info:name','lisi' put 'test:student','1001','info:age','18' #讀取數據,讀取數據的方法有兩個:get 和 scan。get最大範圍是一行數據,也可以進行列的過濾,讀取數據的結果為多行 cell。get 'test:student','1001' get 'test:student','1001' , {COLUMN => 'info:name'} # 也可以修改讀取 cell 的版本數,默認讀取一個。最多能夠讀取當前列族設置的維護版本數。get 'test:student','1001' , {COLUMN => 'info:name', VERSIONS => 6} # scan 是掃描數據,能夠讀取多行數據,不建議掃描過多的數據,推薦使用 startRow 和 stopRow 來控制讀取的數據,默認範圍左閉右開。scan 'test:student',{STARTROW => '1001',STOPROW => '1002'} # 刪除數據,刪除數據的方法有兩個:delete 和 deleteall;delete 表示刪除一個版本的數據,即為 1 個 cell,不填寫版本默認刪除最新的一個版本。delete 'test:student','1001','info:name'deleteall 'test:student','1001','info:name'
**本人博客網站 **IT小神 www.itxiaoshen.com


