分佈式存儲系統之Ceph集群存儲池、PG 與 CRUSH
- 2022 年 10 月 5 日
- 筆記
- ceph, Ceph存儲池類型, Ceph客戶端IO的簡要工作流程, Ceph客戶端計算PG_ID的步驟, CRUSH, PG的常見狀態, PG計數, PG計算公式, 副本池IO, 糾刪碼池IO
前文我們了解了ceph集群狀態獲取常用命令以及通過ceph daemon、ceph tell動態配置ceph組件、ceph.conf配置文件相關格式的說明等,回顧請參考//www.cnblogs.com/qiuhom-1874/p/16727820.html;今天我們來聊一聊ceph的存儲池、PG以及CRUSH相關話題;
一、關於存儲池
我們知道ceph客戶端存儲對象數據到RADOS集群上,不是客戶端直接存儲到osd上;首先客戶端會根據ceph集群的配置,將客戶端存儲的對象數據切分多個固定大小的對象數據,然後再將這些固定大小的數據對象通過一致性hash算法將對象數據映射至存儲池裡的PG,然後由CRUSH算法計算以後,再將PG映射至對應osd,然後由mon返回osd的ID給客戶端,客戶端拿着mon給的osd相關信息主動聯繫對應osd所在節點osd進程,進行數據存儲操作;
什麼是存儲池呢?在ceph上,所謂存儲池是ceph以「存儲池(pool)」的方式,將RADOS存儲集群提供的存儲服務邏輯分割一個或多個存儲區域;我們可以理解為數據對象的名稱空間;實踐中,管理員可以為特定應用程序存儲不同類型數據的需求分別創建專用的存儲池,例如rbd存儲池、rgw存儲池等,也可以為某個項目或某個用戶創建專有的存儲池;當然,如果我們在一個存儲池裡存儲的數據過多,為了方便管理,存儲池還可以進一步細分為一至多個名稱空間(namespace);客戶端(包括rbd和rgw等)存取數據時,需要事先指定存儲池名稱、用戶名和密鑰等信息完成認證,而後將一直維持與其指定的存儲池的連接,於是也可以把存儲池看作是客戶端的IO接口;
Ceph存儲池類型
在ceph上,存儲池有兩種類型;默認情況下,我們不指定什麼類型的存儲池就是副本池(replicated pool);所謂副本池就是存儲在該存儲之上的對象數據,都會由RADOS集群將每個對象數據在集群中存儲為多個副本,其中存儲於主OSD的為主副本,副本數量在創建存儲池時 由管理員指定;默認情況下不指定副本數量,對應副本數量為3個,即1主2從;從上面的描述可以看到,當我們存儲一份對象數據時,為了冗餘備份,我們需要將數據存儲3分,即有兩份冗餘;這也意味着,我們磁盤利用率也只有1/3;於是,為了提高磁盤的利用率的同時,又能保證冗餘,ceph還支持糾刪碼池(erasure code);糾刪碼池就是把個對象存儲為 N=K+M 個塊,其中,K為數據塊數量,M為編碼塊數量,因此存儲池的尺寸為 K+M ;糾刪碼是一種前向糾錯(FEC)代碼通過將K塊的數據轉換為N塊,假設N=K+M,則其中的M代表糾刪碼算法添加的額外或冗餘的塊數量以提供冗餘機制(即編碼塊),而N則表示在糾刪碼編碼之後要創建的塊的總數,其可以故障的總塊數為M(即N-K)個;類似RAID5;糾刪碼池減少了確保數據持久性所需的磁盤空間量,但計算量上卻比副本存儲池要更貴一些;但我們在使用糾刪碼池的時候需要注意不是所有的應用都支持糾刪碼池,比如,RGW可以使用糾刪碼存儲池,但RBD就不支持糾刪碼池,它只支持副本池;
副本池IO
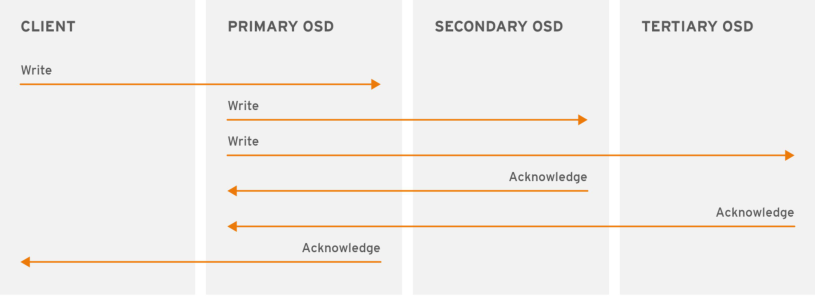
提示:在ceph上,副本池會將一個數據對象存儲為多個副本;為此,在寫入操作時,ceph客戶端使用crush算法來計算對象的PG ID和Primary OSD,然後客戶端將數據寫入主OSD,主OSD根據設定的副本數、對象的名稱、存儲池名稱和集群運行圖(Cluster Map)計算出PG的各輔助OSD,而後由主OSD將數據同步給這些輔助OSD,只有在其他輔助osd和主osd都將對應數據存儲好以後,主osd收到對應輔助osd的確認以後,才會給客戶端確認;
糾刪碼池IO
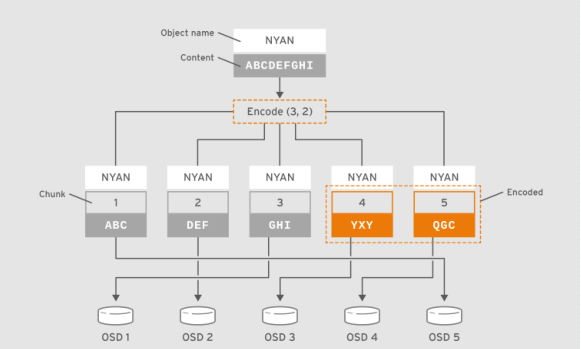
提示:如上圖所示客戶端把包含數據「ABCDEFGHI」的對象NYAN保存到存儲池中時,假設糾刪碼算法會將內容分割為三個數據塊:第一個包含ABC,第二個為DEF,最後一個為GHI,並為這三個數據塊額外創建兩個編碼塊:第四個YXY和第五個QGC;在有着兩個編碼塊配置的存儲池中,它容許至多兩個OSD不可用而不影響數據的可用性。假設,在某個時刻OSD 1和OSD 3因故無法正常響應客戶端請求,這意味着客戶端僅能讀取到ABC、DEF和QGC,此時糾刪編碼算法會通過計算重那家出GHI和YXY;
二、關於PG
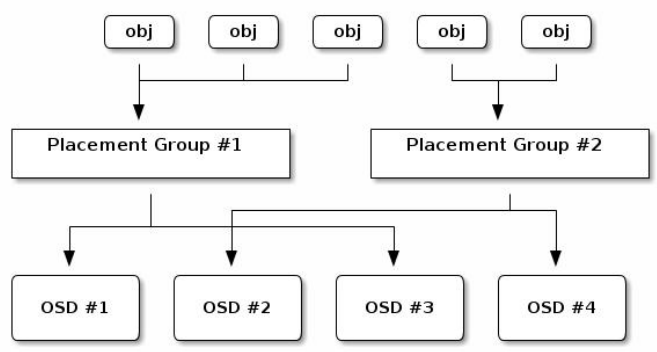
提示:PG是用於跨OSD將數據存儲在某個存儲池中的內部數據結構;相對於存儲池來說,PG是一個虛擬組件,它是對象映射到OSD時使用的虛擬層;出於規模伸縮及性能方面的考慮,Ceph將存儲池細分為歸置組,把每個單獨的對象映射到歸置組,並將歸置組分配給一個主OSD;存儲池由一系列的歸置組組成,而CRUSH算法則根據集群運行圖和集群狀態,將各PG均勻、偽隨機地分佈到集群中的OSD之上;所謂偽隨機是指,在osd都健康數量沒有變化的情況下,同一PG始終映射相同的OSD;若某OSD失敗或需要對集群進行重新平衡,Ceph則移動或複製整個歸置組而無需單獨尋址每個對象;歸置組在OSD守護進程和Ceph客戶端之間生成了一個中間層,CRUSH算法負責將每個對象動態映射到一個歸置組,然後再將每個歸置組動態映射到一個或多個OSD守護進程,從而能夠支持在新的OSD設備上線時動態進行數據重新平衡;
PG計數
PG數量由管理員在創建存儲池時指定,而後由CRUSH負責創建和使用,通常,PG的數量應該是數據的合理顆粒度的子集,例如,一個包含256個PG的存儲池意味着每個PG包含大約1/256的存儲池數據;當需要將PG從一個OSD移動到另一個OSD時,PG的數量會對性能產生影響;PG數量過少,Ceph將不得不同時移動相當數量的數據,其產生的網絡負載將對集群的正常性能輸出產生負面影響;即PG過少,那麼對應一個PG存儲的數據就越多,則移動PG會佔用過多的網絡帶寬,從而影響正常客戶端的使用;而在過多的PG數量場景中在移動極少量的數據時,Ceph將會佔用過多的CPU和RAM,從而對集群的計算資源產生負面影響。即PG過多,對應每個PG維護的數據較少,但是集群需要花費很多CPU和內存來維護和追蹤PG的信息;從而造成集群的計算資源和內存資源造成影響,從而進一步影響客戶端使用;所以在ceph上pg的數量不宜過多和過少;
PG數量在群集分發數據和重新平衡時扮演着重要作用,在所有OSD之間進行數據持久存儲及完成數據分佈會需要較多的歸置組,但是它們的數量應該減少到最大性能所需的最小數量值,以節省CPU和內存資源;一般說來,對於有着超過50個OSD的RADOS集群,建議每個OSD大約有50-100個PG以平衡資源使用,取得更好的數據持久性和數據分佈,更大規模的集群中,每個OSD大約可持有100-200個PG至於應該使用多少個PG,可通過下面的公式計算後,將其值以類似於四捨五入到最近的2的N次冪;
PG計算公式:(Total OSDs * PGPerOSD)/Replication factor => Total PGs;即一個ceph集群總PG數量=每個OSD上的pg數量×OSD的數量,然後除以副本數量;一個RADOS集群上可能會存在多個存儲池,因此管理員還需要考慮所有存儲池上的PG分佈後每個OSD需要映射的PG數量;即總pg數量/存儲池個數,就是平均一個存儲的PG數量;簡單講就是所有存儲池的PG數量之和應該等於通過上述公式算出來的值四捨五入到最近的2的N次冪;
PG狀態
依據PG當前的工作特性或工作進程所處的階段,它總是處於某個或某些個「狀態」中,最為常見的狀態應該為「active+clean」;
PG的常見狀態
1、Active:所謂Active狀態是指主OSD和各輔助OSD均處於就緒狀態,可正常服務於客戶端的IO請求所處於的狀態;一般,Peering操作過程完成後即會轉入Active狀態;
2、Clean:是指主OSD和各輔助OSD均處於就緒狀態,所有對象的副本數量均符合期望,並且PG的活動集和上行集是為同一組OSD;
活動集(Acting Set):由PG當前的主OSD和所有的處於活動狀態的輔助OSD組成,這組OSD負責執行此PG上數據對象的存取操作I/O;
上行集(Up Set):根據CRUSH的工作方式,集群拓撲架構的變動將可能導致PG相應的OSD變動或擴展至其它的OSD之上,這個新的OSD集也稱為PG的」上行集(Up Set)「,其映射到的新OSD集可能部分地與原有OSD集重合,也可能會完全不相干; 上行集OSD需要從當前的活動集OSD上複製數據對象,在所有對象同步完成後,上行集便成為新的活動集,而PG也將轉為「活動(active)」狀態;
3、Peering:一個PG中的所有OSD必須就它們持有的數據對象狀態達成一致,而「對等(Peering)」即為讓其OSD從不一致轉為一致的過程;
4、Degraded:在某OSD標記為「down」時,所有映射到此OSD的PG即轉入「降級(degraded)」狀態;此OSD重新啟動並完成Peering操作後,PG將重新轉回clean;一旦OSD標記為down的時間超過5分鐘,它將被標記出集群,而後Ceph將對降級狀態的PG啟動恢復操作,直到所有因此而降級的PG重回clean狀態;在其內部OSD上某對象不可用或悄然崩潰時,PG也會被標記為降級狀態,直至對象從某個權威副本上正確恢復;
5、Stale:每個OSD都要周期性地向RADOS集群中的監視器報告其作為主OSD所持有的所有PG的最新統計數據,因任何原因導致某個主OSD無法正常向監視器發送此類報告,或者由其它OSD報告某個OSD已經down掉,則所有以此OSD為主OSD的PG將立即被標記為stale狀態;
6、Undersized: PG中的副本數少於其存儲池定義的個數時即轉入undersized狀態,恢復和回填操作在隨後會啟動以修復其副本數為期望值;
7、Scrubbing:各OSD還需要周期性地檢查其所持有的數據對象的完整性,以確保所有對等OSD上的數據一致;處於此類檢查過程中的PG便會被標記為scrubbing狀態,這也通常被稱作light scrubs、shallowscrubs或者simply scrubs;另外,PG還偶爾需要進行deep scrubs檢查以確保同一對象在相關的各OSD上能按位匹配,此時PG將處於scrubbing+deep狀態;
8、Recovering:添加一個新的OSD至存儲集群中或某OSD宕掉時,PG則有可能會被CRUSH重新映射進而將持有與此不同的OSD集,而這些處於內部數據同步過程中的PG則被標記為recovering狀態;
9、Backfilling:新OSD加入存儲集群後,Ceph則會進入數據重新均衡的狀態,即一些數據對象會在進程後台從現有OSD移到新的OSD之上,此操作過程即為backfill;
三、關於CRUSH
CRUSH是Controlled Replication Under Scalable Hashing的縮寫,它是一種數據分佈式算法,類似於一致性哈希算法,用於為RADOS存儲集群控制數據分佈;在ceph上如果我們把對象直接映射到OSD上會導致二者的耦合度過於緊密;這意味着如果一個OSD的變動,可能導致整個集群的數據的變動;所以,Ceph將一個對象映射進RADOS集群的過程分為兩步;首先是以一致性哈希算法將對象名稱映射到PG,而後而後是將PG ID基於CRUSH算法映射到OSD;此兩個過程都以「實時計算」的方式完成,而非傳統的查表方式,從而有效規避了任何組件被「中心化」的可能性,使得集群規模擴展不再受限;
Ceph客戶端IO的簡要工作流程
在ceph上,客戶端存取對象時,客戶端從Ceph監視器檢索出集群運行圖,綁定到指定的存儲池,並對存儲池上PG內的對象執行IO操作;存儲池的CRUSH規則集和PG的數量是決定Ceph如何放置數據的關鍵性因素,基於最新版本的集群運行圖,客戶端能夠了解到集群中的所有監視器和OSD以及它們各自的當前狀態;這對於客戶端來說,對象存儲在那個位置是一無所知的;執行對象的存取操作時,客戶端需要輸入的是對象標識和存儲池名稱;客戶端需要在存儲池中存儲命名對象時,它將對象名稱、對象名稱的哈希碼、存儲池中的PG數量和存儲池名稱作為輸入,而後由CRUSH計算出PG的ID及此PG的主OSD;通過將對象標識進行一致性哈希運算得到的哈希值與PG位圖掩碼進行」與「運算得到目標PG,從而得出目標PG的ID(pg_id),完成由Object至PG的映射; 而後,CRUSH算法便將以此pg_id、CRUSH運行圖和歸置規則(Placement Rules)為輸入參數再次進行計算,並輸出一個確定且有序的目標存儲向量列表(OSD列表),從而完成從PG至OSD的映射;
Ceph客戶端計算PG_ID的步驟
1、首先客戶端輸入存儲池名稱及對象名稱,例如,pool = pool1以及object-id = obj1;
2、獲取對象名稱並通過一致性哈希算法對其進行哈希運算,即hash(o),其中o為對象名稱;
3、將計算出的對象標識哈希碼與PG位圖掩碼進行「與」運算獲得目標PG的標識符,即PG_ID,如1701;計算公式為pgid=func(hash(o)&m,r),其中,變量o是對象標識符,變量m是當前存儲池中PG的位圖掩碼,變量r是指複製因子,用於確定目標PG中OSD數量;
4、CRUSH根據集群運行圖計算出與目標PG對應的有序的OSD集合,並確定出其主OSD;
5、客戶端獲取到存儲池名稱對應的數字標識,例如,存儲池「pool1」的數字標識11;
6、客戶端將存儲池的ID添加到PG ID,例如,11.1701;
7、客戶端通過直接與PG映射到的主OSD通信來執行諸如寫入、讀取或刪除之類的對象操作;
簡單來講,ceph客戶端存取對象數據的過程就是,先提取用戶要存入的對象數據的名稱和存儲到那個存儲池之上;然後通過一致性哈希算法計算出對象名稱的hash值,然後把這個hash值和在對應存儲池PG位圖掩碼做「與」運算得到目標PG的標識符,即PG ID;有了PG_ID,再根據CRUSH算法結合集群運行圖和PG對應的OSD集合,最終把PG對應的主OSD確認,然後將對應osd的信息返回給客戶端,然後客戶端拿着這些信息主動聯繫osd所在主機進行數據的存取;這一過程中,沒有傳統的查表,查數據庫之類的操作;全程都是通過計算來確定對應數據存儲路徑;這也就規避了傳統查表或查數據庫的方式給集群帶來的性能瓶頸的問題;


