【論文翻譯】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模細粒度關係的知識圖增強預訓練語言模型
(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
- 摘要
知識圖譜(KG)中實體之間的交互作用為語言表徵學習提供了豐富的知識。然而,現有的知識增強型預訓練語言模型(PLMS)只關注實體信息,而忽略了實體之間的細粒度關係。在這項工作中,我們建議將KG(包括實體和關係)納入語言學習過程中,以獲得KG增強的預訓練語言模型,即KLMo。具體來說,設計了一種新的知識聚合器來顯式建模文本中的實體片段(entity span)和上下文KG中的所有實體和關係之間的交互。利用一個關係預測目標,通過遠程監督來合併關係信息。進一步利用鏈接目標的實體來將文本中的實體跨鏈接到KG中的實體。這樣,結構化的知識就可以有效地集成到語言表示形式中。實驗結果表明,與最先進的知識增強型PLMs相比,KLMo在實體類型和關係分類等知識驅動任務上取得了很大的進步。
- 01引言
帶有實體和關係的知識圖(KG)為語言學習提供了豐富的知識(Wang et al.,2017,2014)。最近,研究人員探索了將KG信息納入PLMs中來增強語言表徵,比如ERNIE-THU (Zhang et al., 2019), WKLM (Xiong et al.,2019) , KEPLER (Wang et al., 2019), KnowBERT (Peters et al., 2019), BERT-MK (He et al., 2019) and KALM (Rosset et al., 2020), .但是,它們只利用實體信息,而忽略了實體之間的細粒度關係。實體間關係的細粒度語義信息對語言表示學習也是至關重要的。
2001年,郎朗參加了BBC的畢業舞會,但他在中國直到2012年在《幸福三重奏》中亮相才很受歡迎。
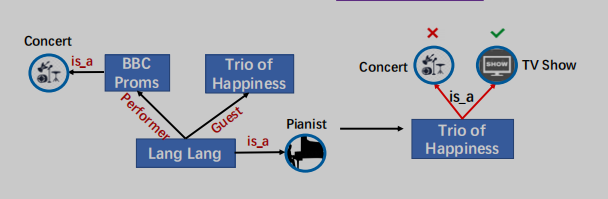
圖1:將知識合併到PLMs中的一個示例。KG中的關係對於正確預測Trio of Happiness的類型至關重要。
以圖1為例,實體類型,沒有明確地知道細粒度Lang Lang和Trio of Happiness的關係是客人(Guest),這是不同於關係表演者(Performer)LangLang和BBC Proms,不可能正確預測Trio of Happiness作為電視節目的類型,因為輸入句子字面上意味着Trio of Happiness和BBC Proms屬於同一類型。KG中實體之間的細粒度關係為實體提供了特定的約束,從而在知識驅動任務的語言學習中發揮重要作用。為了明確地將KG中的實體和細粒度關係合併到PLMs中,我們面臨的一個主要挑戰是文本-知識對齊(TKA)問題:很難為文本和知識的融合進行token-關係和token-實體對齊。為了解決這個問題,我們提出了KG增強的預訓練語言模型(KLMo)來將KG(即實體和細粒度關係)集成到語言表示學習中。KLMo的主要組件是一個知識聚合器,它負責從兩個單獨的嵌入空間即token嵌入空間和KG嵌入空間,進行文本和知識信息的融合。知識聚合器通過實體片段級的交叉KG注意力機制,建模文本中實體片段和所有實體和關係之間的交互,使tokens注意KG中高度相關的實體和關係。基於KG增強的token表示,利用關係預測目標,基於KG的遠程監督,預測文本中每對實體的關係。關係預測和實體鏈接目標是將KG信息集成到文本表示中的關鍵。
我們在兩個中國知識驅動的自然語言處理任務上進行了實驗,即實體類型和關係分類。實驗結果表明,通過充分利用包含實體和細粒度關係的結構化KG,KLMo比BERT和現有的知識增強PLMs有了很大的改進。我們還將發佈一個中國的實體類型數據集,用於評估中國的PLMs。
- 02模型描述
如圖2所示,KLMo被設計為一個基於多層Transformer的(Vaswani et al.,2017)模型,該模型接受一個token序列及其上下文KG中的實體和關係作為輸入。文本(token)序列首先由一個基於多層Transformer的文本編碼器進行編碼。文本編碼器的輸出進一步被用作知識聚合器的輸入,該知識聚合器將實體和關係的知識融入到文本(token)序列中,以獲得KG增強的token表示。基於KG增強表示,將新的關係預測和實體鏈接目標聯合優化為預訓練目標,有助於將KG中的高度相關的實體和關係信息合併到文本表示中。
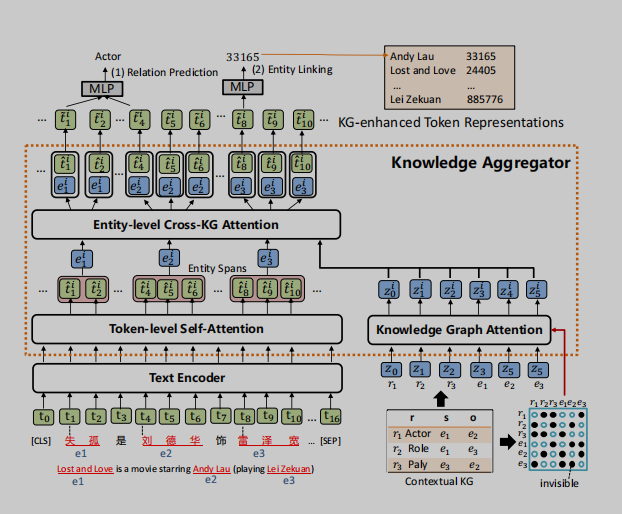
圖2:模型體系結構的概述。
2.1知識聚合器
如圖2所示,知識聚合器被設計為一個M層知識編碼器,將KG中的知識集成到語言表示學習中。它接受token序列的隱藏層和KG中實體和關係的知識嵌入作為輸入,並融合來自兩個單獨嵌入空間的文本和KG信息。它接受token序列的隱藏層和KG中實體和關係的知識嵌入作為輸入,並融合來自兩個單獨嵌入空間的文本和KG信息。知識聚合器包含兩個獨立的多頭注意力機制:token級自注意力和知識圖譜注意力(Veliˇckovi『cetal.,2017),它對輸入文本和KG進行獨立編碼。實體表示是通過彙集一個實體片段中的所有token來計算的。然後,聚合器通過實體級的交叉KG注意力,將文本中的實體片段與上下文KG中的所有實體和關係之間的交互進行建模,從而將知識融入到文本表示中。
Knowledge Graph Attention (知識圖譜注意力機制)
由於KG中的實體和關係組成了一個圖,因此在知識表示學習過程中考慮圖的結構是至關重要的。我們首先通過TransE(Bordes et al.,2013)表示上下文KG中的實體和關係,然後將它們轉化為一個實體和關係向量序列{z0,z1,…,zq},作為知識聚合器的輸入。然後,知識聚合器通過知識圖譜注意力對實體和關係序列進行編碼,知識圖譜注意力通過將可見矩陣M引入傳統的自注意機制來考慮其圖結構(Liu et al.,2020)。可見矩陣M只允許在表示學習過程中,KG中的相鄰實體和關係彼此可見,如圖2的右下角所示。
Entity-level Cross-KG Attention(實體級別交叉KG注意力機制)
為了計算KG增強實體表示,給定一個實體提及列表(entity mention list )Ce = {(e0,start0,end0),…,(em,start m,end m)},知識聚合器首先計算實體片段表示{eˆi0…,eˆim},通過在文本中實體範圍內的所有tokens上pooling計算得到文本中實體片段表示(Lee et al.,2017)。實體片段嵌入{eˆi0,…,eˆim}可以擴展到所有標記{eˆi0,…,eˆin},方法是為不屬於任何實體片段的token創建eˆij=tˆij,其中tˆij表示來自的第j個標記的表示token-level的自注意力。
為了對文本中的實體跨度與上下文KG中的所有實體和關係之間的交互進行建模,聚合器執行一個實體級的交叉KG注意力,讓token關注KG中高度相關的實體和關係,從而計算KG增強的實體表示。具體來說,第i個聚合器中的實體級交叉KG注意力是通過實體片段嵌入{eˆi0,…,eˆin}作為query和實體和關係嵌入{zi0,…,ziq}作為key和value之間的上下文多頭注意力機制來實現的。(將文本中的實體片段表示作為query,將KG中的實體和關係表示作為key和value,進行注意力計算,從而得到知識增強的實體表示)
KG-enhanced Token Representations (知識增強文本表示)
為了將KG增強的實體信息注入到文本表示中,知識聚合器的第i層通過採用{tˆi0,…,tˆin}和{ei0…,…,eni}之間的信息融合操作來計算KG增強的token表徵{ti0,…,tin}。對於第j個token,融合操作的定義如下:
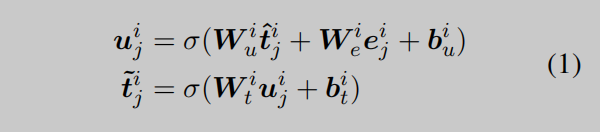
其中,uij表示集成來自token和實體信息的隱蔽態。Wi∗和bi∗分別是可學習的權重和偏差。KG增強的token表示{t˜i0,…,tin˜˜}作為輸入被輸入到下一層知識聚合器中。
2.2預訓練目標
為了將KG知識納入語言表徵學習中,KLMo採用了多任務損失函數作為訓練目標:
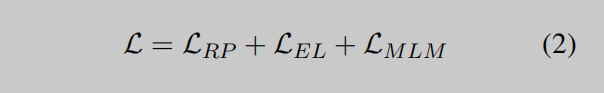
除了掩碼語言模型的損失LMLM (Devlin et al., 2018; Li et al., 2020),基於相應的KG增強文本表示{t˜M0,…,t˜Mn},整合關係預測損失LRP和實體鏈接損失LEL來預測KG中的實體。
對於每一對實體片段,我們利用它們在KG中對應實體之間的關係作為關係預測的遠距離監督。關係預測和實體鏈接目標是將KG中的關係和實體整合到文本中的關鍵。由於在實體鏈接目標中的Softmax操作在KG中的實體數量相當大,我們通過只預測同一批中的實體而不是KG中的所有實體來處理這個問題。為了防止KLMo在預測而不是依賴於文本上下文時完全記住實體的提到,我們在輸入文本中使用一個特殊的[MASK]token隨機屏蔽了10%的實體。
03實驗
本節詳細介紹KLMo預訓練及其對兩個特定知識驅動的NLP任務的微調:實體類型和關係分類。我們通過百度百科的中文語料庫和百度百科的知識圖譜的中文語料庫對KLMo進行預訓練。訓練前語料庫和實驗設置的細節見附錄A。
3.1Baselines
我們將KLMo與在同一百度百科語料庫上預訓練的最先進的PLMs進行了比較:(1)BERT-Base Chinese (Devlin et al., 2018),在百度百科語料庫進行一輪預訓練(2)ERNIE-THU (Zhang et al., 2019),這是該領域的開創性和典型工作,將實體知識納入PLM。(3)WKLM (Xiong et al., 2019),一個弱監督的知識增強PLM,使用實體替換預測來合併實體知識,它提供了幾個知識驅動任務的最先進的結果。
3.2實體類型
數據集 在這項工作中,我們創建了一個中文實體類型數據集,這是一個完全手動的數據集,包含23100個句子和28093個注釋實體,分佈在15個細粒度的媒體作品類別,如電影、節目和電視劇。我們將數據集分成一個有15000個句子的訓練集和一個有8100個句子的測試集。數據集的詳細統計數據和微調設置顯示在附錄B.1中。
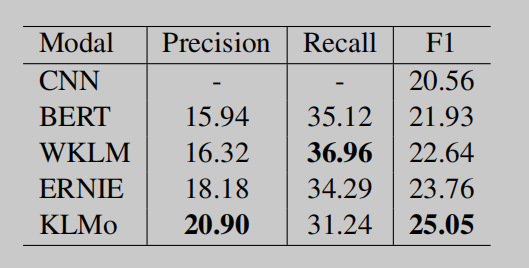
表2:關於關係分類的結果。

表3:實體類型的消融研究。
結果 我們在準確率、召回率、微f1和精度指標下評估了實體類型的各種預訓練模型。結果如表1所示。我們可以找到以下的觀察結果:(1)所有知識增強的PLMs在所有度量上的表現通常都比BERT baseline好得多,這表明實體知識在注釋資源有限的情況下有利於實體類型的預測。(2)與現有的知識增強PLMs相比,KLMo比WKLM和ERNIE極大地提高了召回率,對micro-F1分別提高了1.58和0.57。這表明,實體之間的細粒度關係有助於KLMo為更多的實體預測適當的類別。
3.3關係分類
數據集 The CCKS 2019 Task 3 Inter-Personal Relational Extraction (IPRE) dataset (Han et al., 2020) 用於關係分類的評估。訓練集通過遠程監督自動標記,測試集被手動標註。有35個關係(包括一個空關係類「NA」),其中「NA」在訓練集中占近86%,在測試集中佔97%。數據集的詳細統計數據和微調設置見附錄B.2。
結果 我們採用準確率、召回率和microF1作為評價措施。結果如表2所示。除了BERT baseline外,我們還將KLMo與官方的CNN baseline進行了比較,該baseline將CNN輸出作為句子嵌入,並將其輸入關係分類器。從表2中可以看出,CNN和BERT baseline模型都表現不佳,這表明數據集的難度很高。這是由於在由遠程監督自動產生的訓練集中有大量的噪聲標籤。
雖然數據集非常困難,但我們仍然可以觀察到:(1)所有知識增強的PLMs都大大提高了準確率和microF1分數,這表明實體信息和KG信息都可以增強語言表示,從而促進關係分類的性能。(2) KLMo對WKLM和ERNIE的準確率顯著提高,對micro-F1分別提高了2.41和1.29,說明KG中的細粒度關係有助於KLMo避免對噪聲標籤的擬合,並正確預測關係
3.4 KG信息的影響
大多數NLP任務只提供文本輸入,而實體鏈接本身是一項艱巨的任務。因此,我們研究了KG實體的影響和關係對實體類型的影響。w/o KG是指在不輸入KG實體和關係的情況下對KLMo進行微調。表3為消融實驗研究的結果。在沒有KG輸入進行微調的情況下,KLMo在準確率和召回率得分上仍大大優於BERT,從而在micro-F1上提高了1.74。與使用KG的KLMo微調相比,沒有KG的KLMo在microf1測量上略有下降了0.84。這表明KG信息在訓練前已經被集成到KLMo中。對於大多數特定的NLP任務,KLMo可以以類似於BERT的方式進行微調。
04結論
在本文中,我們提出了一種新的KG增強的預訓練語言模型KLMo,明確地將KG實體和細粒度關係集成到語言表徵學習中。因此,設計了一種新的知識聚合器來處理異構信息融合和文本知識對齊問題。進一步,聯合優化了關係預測和實體鏈接目標,以促進知識信息集成。實驗結果表明,KLMo的性能優於其他最先進的知識增強的PLMs,這驗證了KG中的細粒度關係可以增強語言表示學習,並有利於一些知識驅動的NLP任務。
A Pre-training Settings
A.1 Pretraining Corpus
Baike Knowledge Graph
百科知識庫是一個通用領域的中國知識庫,它包含226種概念類型、超過1億個實體和22億個三元組。百度知識庫中的每個實體都與各種來源的網頁對齊,如百度百科度、搜狗百科和雙重媒體。為了預訓練一個KG增強的中文模型,我們提取了該知識庫的一個子集,使用以下規則構建一個百科KG:1)刪除百度百科文章以外的實體;2)刪除低流行實體(小於200);3)僅保留兩個實體都是百度百科實體的事實三元組。最終的百科KG包含2466069個實體,390個關係和9859314個三倍。
中國訓練前語料庫 KLMo主要採用百度百科的網頁進行預訓練,其中包含用正式中文編寫的百科全書文章。文章中的實體可以通過錨定鏈接提取,並與百科 KG實體對齊。對語料庫進行預處理後,生成一個包含78B個標記、1.74億個句子、2100萬個實體和120萬個關係的大格式數據集,用於KLMo的預訓練。具有少於5個單詞或2個實體的句子將被丟棄。
A.2實施細節
在實驗中,我們首先使用OpenKE工具包(Han等人,2018),獲得了通過TransE(Bordes等人,2013)算法在百科KG三元組上訓練的知識表示。這些表示法用於初始化KLMo中的實體和關係嵌入。嵌入維數設置為100,輪數設置為5000。
對於KLMo的預訓練,由於預訓練代價昂貴,我們繼承BERT-Base中文參數來初始化token編碼,而實體和關係編碼模塊的參數都是隨機初始化的。文本編碼器層L和知識聚合器層M均為6個。token嵌入dt、知識嵌入dz和實體跨度嵌入de的隱藏大小分別設置為768、100和100。標記導向注意頭At、kg導向注意頭Az和實體跨級注意頭Ae的數量分別設置為12、4和12。KLMo的預訓練在4個NVIDIA TeslaV100(32GB)gpu上運行3個時代,批量大小為128,最大序列長度為512,學習速率為5e-5。

表4:中國實體分類數據集的統計數據。

表5:中國關係分類數據集的統計數據。
B微調設置
B.1實體類型化
為了評估KLMo的性能,本文執行了兩個知識驅動的任務,即實體類型和關係分類。給定一個提到實體的句子,實體輸入任務是用其細粒度的語義類型來標記提及。
數據集 實體類型並不是一個新的任務。然而,據我們所知,目前還沒有關於中文細粒度實體類型的公開基準數據集。因此,在這項工作中,我們創建了一個中文實體類型數據集,這是一個完全手動注釋的數據集,包含23100個句子和28093個注釋實體,分佈在15個細粒度的媒體作品類別,如電影、節目和電視劇。我們將數據集分成一個有15000個句子的訓練集和一個有8100個句子的測試集。數據集的詳細統計數據如表4所示。
微調
中文實體類型數據集缺乏KG實體注釋,因此我們首先使用帶有百科知識庫的實體鏈接工具來識別句子中提到的實體,並將其鏈接到相應的百科KG實體。鏈接的實體類型數據集的統計數據如表4所示。超過50%的句子在訓練集和測試集中都包含至少一個鏈接的KG實體。為了為實體類型的KLMo,我們使用每個實體跨度的第一個標記的表示來預測其實體類型。該模型在訓練集上細化了10輪,批處理大小為128,最大序列長度為256,學習速率為2e-5。


