帶你了解CANN的目標檢測與識別一站式方案
摘要: 了解通用目標檢測與識別一站式方案的功能與特性,還有實現流程,以及可定製點。
本文分享自華為雲社區《玩轉CANN目標檢測與識別一站式方案》,作者: Tianyi_Li。
背景介紹
目標檢測與識別是計算機視覺領域中的關鍵技術,隨着深度學習技術的發展,目標檢測與識別的應用場景也越來越廣泛。當前, 主要有以下幾個應用場景:
安全領域:指紋識別、物體識別等。
交通領域:車牌號識別、無人駕駛、交通標誌識別等。
醫療領域:心電圖、B超、健康管理、營養學等。
生活領域:智能家居、智能購物、智能測膚等。
但當前人工智能應用開發面臨著開發周期長、AI軟件棧理解成本高、算法模型與業務結合難度高、對開發人員技能要求高等門檻。為了降低AI應用開發的門檻,昇騰CANN開源了高性能的通用目標檢測與識別一站式方案,通過其強大的可定製、可擴展性,旨在為AI開發者們提供更好的編程選擇。
特別提示,如果您具有以下知識儲備,將有助於學習:
- 具有C&C++編程經驗。
- 了解異構計算架構CANN在昇騰AI全棧中的位置和作用。
- 了解應用編程框架AscendCL的關鍵特性,並能夠基於AscendCL接口開發簡單的AI應用。
目標
- 了解通用目標檢測與識別一站式方案的功能與特性
- 了解ACLlite的背景及接口使用方法
- 深入了解通用目標檢測與識別一站式方案的實現流程
- 能夠基於此方案定製自己的AI應用
目標檢測與識別一站式方案介紹
方案特性
點此detect_and_classify,可查看方案源代碼。
方案整體特性概括如下:

1.支持多格式輸入和輸出
通用目標檢測和識別一站式方案支持圖片、離線視頻、RTSP視頻流等多輸入格式,開發者可基於此方案實現對圖片和視頻等不同格式的目標進行識別。另外在結果展示方面,支持圖片、離線視頻、Web前端等多形式展現,開發者可根據業務場景靈活呈現識別結果。
2.支持輕鬆替換和串接模型
該方案當前選用的是YoloV3圖片檢測模型與CNN顏色分類模型的串接,可實現基本的車輛檢測和車輛顏色識別,開發者可輕鬆修改程序代碼,自行替換/增加/刪除AI模型,實現更多AI功能。
3.支持高效數據預處理
圖片、視頻等各類數據是進行目標檢測和識別的原料,在把數據投入AI算法或模型前,我們需要對數據進行預加工,才能達到更加高效和準確的計算。該樣例採用獨立數據預處理模塊,支持開發者按需定製,高效實現解碼、摳圖、縮放、色域轉換等各種常見數據處理功能。
4.支持圖片數、分辨率可變場景定製
在目標檢測和識別領域,開發者們除了需要應對輸入數據格式等方面差異,還會經常遇到圖片數量、分辨率不確定的場景,這也是格外頭疼的問題之一。比如,在目標檢測和識別過程中,由於檢測出的目標個數不固定,導致程序要等到圖片攢到固定數量再進行AI計算,浪費了大量寶貴的AI計算資源。該樣例開放了便捷的定製入口,支持設置多種數據量Batch檔位、多種分辨率檔位,在推理時根據實際輸入情況靈活匹配,不僅擴寬了業務場景,更有效節省計算資源,大大提升AI計算效率。
5.支持多路多線程高性能編程
為了進一步提高編程的靈活性,滿足開發者實現高性能AI應用,該樣例支持通過極為友好和便捷的方式調整線程數和設備路數,極大降低學習成本,提升設備資源利用率。
6.高效後處理計算
除此之外,該樣例後續還會將原本需要在CPU上進行處理的功能推送到昇騰AI處理器上執行,利用昇騰AI處理器強大的算力實現後處理的加速,進一步提升整個AI應用的計算效率。
實現流程
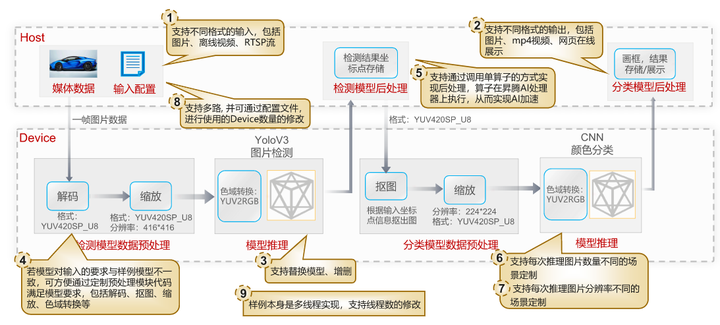
該樣例使用了圖片檢測模型與顏色分類模型,基於CANN AI應用編程接口,對數據預處理、模型推理、模型後處理等AI核心計算邏輯進行模塊化組裝,實現了車輛檢測和車身顏色識別基礎功能,以輸入圖片是JPEG壓縮圖片為例,該樣例功能流程如下所示:
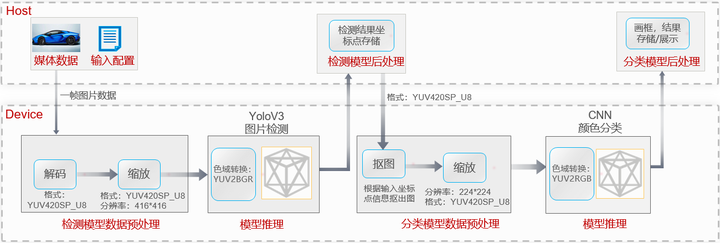
- 首先輸入圖片送入Device的DVPP進行數據預處理,因為模型的輸入要求是非壓縮的、指定編碼格式的圖片,所以首先使用DVPP進行圖片的解碼操作,解碼後格式為YUV420SP_U8。
- 由於圖片的大小與模型要求的大小不一致,解碼後我們使用DVPP的VPC功能進行大小的調整。
- 經過前面的一系列處理後,輸入到模型的編碼格式YUV420SP_U8仍與模型要求不一致,此時我們可以在模型轉換時通過AIPP的色域轉換功能實現格式轉換,將YUV420SP_U8格式轉換為模型要求的BGR格式,這裡的色域轉換功能其實就相當於在模型中添加了一個色域轉換算子,直接在模型推理前實現了編碼格式的轉換,而無需代碼層面的修改。
- 檢測模型推理後的結果就可以送入模型後處理模塊,後處理模塊根據業務流程需要,進行檢測坐標點的存儲。
- 下一步,就是將檢測坐標點以及前面預處理後的YUV圖片,一起送入分類模型的預處理模塊,首先根據檢測結果的坐標點信息對輸入的圖片進行摳圖,然後再將其縮放為分類模型要求的大小。
- 由於顏色分類模型要求的圖片編碼格式是RGB,同前面的檢測模型一樣,需要使用AIPP的色域轉換功能,在模型推理前將YUV轉換為RGB。
- 最後對分類模型推理後的結果進行處理,在圖片上進行畫框,標註結果,並根據用戶的輸出要求進行存儲或者在線展示。
快速體驗
下面介紹讓樣例快速跑起來,了解通用目標檢測與識別一站式方案的總體編譯運行流程,主要是:
- 輸入/輸出數據都為圖片,其中輸入數據請選擇jpeg格式的圖片
- 使用1個Device運行
準備環境
這裡不做過多介紹,使用的是ECS + 官方推送的鏡像,很簡單就能搞定了,需要注意的是環境準備好後,請以HwHiAiUser用戶體驗如下任務。HwHiAiUser用戶下已經配置好了環境變量,安裝好了應用所需基本依賴。
編譯運行樣例
因為鏡像已經做好了配置,可以直接下載樣例,模型與數據,直接編譯運行即可。詳細步驟如下:
步驟 1 :下載samples源碼倉。
此處已將samples倉下載到$HOME路徑下為例, 可以使用以下兩種方式下載,請選擇其中一種即可
【命令行下載】
cd ${HOME} git clone https://gitee.com/ascend/samples.git
【壓縮包下載】
a. 在samples倉右上角選擇【克隆/下載】下拉框,並選擇【下載ZIP】。
b. 將ZIP包以HwHiAiUser用戶上傳到開發環境的普通用戶家目錄中。
例如:${HOME}/ascend-samples-master.zip
c. 執行以下命令,解壓縮zip包。
cd ${HOME}
unzip ascend-samples-master.zip
步驟 2 : 準備模型及數據。
請參見README中的模型及數據準備章節。
步驟 3 : 樣例編譯運行。
請參見README中的樣例編譯運行章節。
【說明】
- 輸入/輸出數據都要求為圖片,其中輸入數據請選擇jpeg格式的圖片
- 使用1個Device運行
結果輸出
如下圖所示,左圖為運行的打印輸出,右圖為輸出的推理結果圖片:

此外,還支持多種輸入輸出模式:
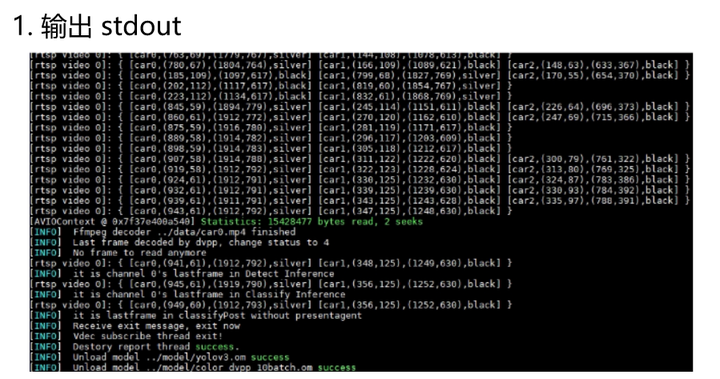
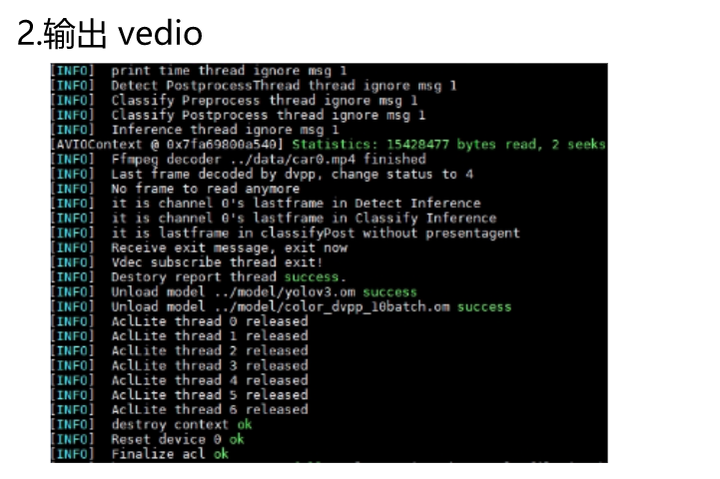
根據官方的測試,單device最多支持22路,在輸入分辨率1280 * 720的視頻下,單幀圖像處理耗時20ms,每秒最大處理幀數為50幀。
結語
本次的CANN目標檢測與識別一站式方案總體流程圖如下圖所示,
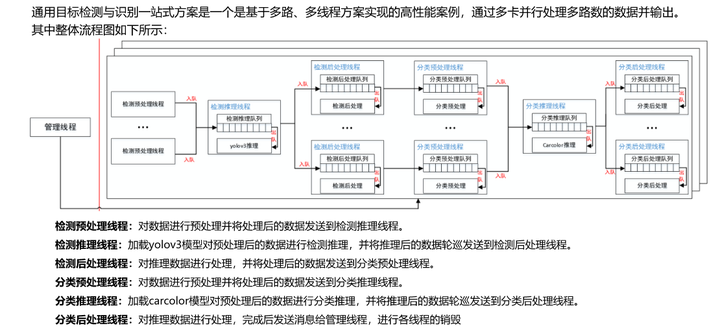
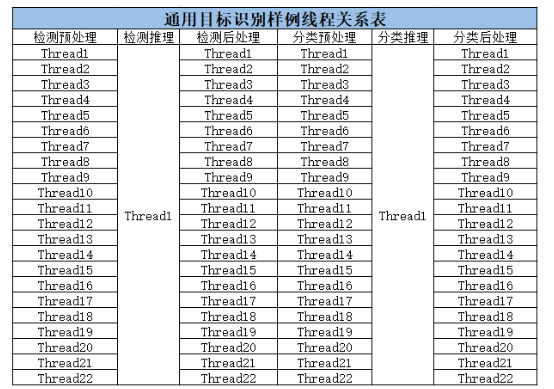
方案中大量使用了線程,多路線程分別進行數據流轉和協同合作,以單device為例,線程關係如下圖所示:
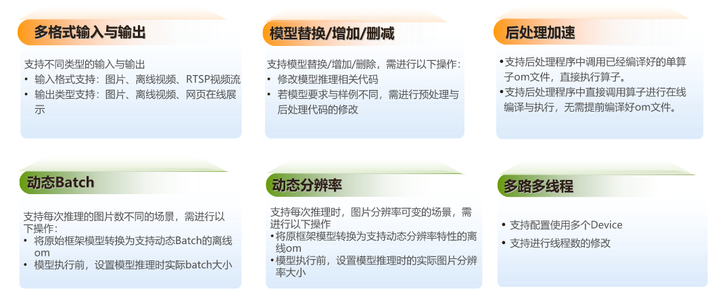
此外,還支持定製開發,開發者可根據需要,自行添加包括但不限於如下功能:
詳細的操作位置如下圖所示,具體可參考本方案代碼庫的README:
好了,最後奉上本方案代碼庫的獲取方式,如下圖所示,當然,也可以點擊在前文中咱們提供的鏈接。