大家都在用MySQL count(*)統計總數,到底有什麼問題?
在日常開發工作中,我經常會遇到需要統計總數的場景,比如:統計訂單總數、統計用戶總數等。一般我們會使用MySQL 的count函數進行統計,但是隨着數據量逐漸增大,統計耗時也越來越長,最後竟然出現慢查詢的情況,這究竟是什麼原因呢?本篇文章帶你一下學習一下。
1. MyISAM存儲引擎計數為什麼這麼快?
我們總有個錯覺,就是感覺MyISAM引擎的count計數要比InnoDB引擎更快,實際這不是錯覺。
MyISAM引擎把表的總行數單獨記錄在磁盤上,查詢的時候可以直接返回,不需要再累加統計。
但是當SQL查詢中有where條件的時候,就無法再使用表的總行數了,還是需要乖乖的進行累加統計,查詢性能也就跟InnoDB相差無幾了。
為什麼MyISAM引擎能夠記錄表的總行數,InnoDB引擎卻不行?
因為MyISAM引擎不支持事務,只有表鎖,所以記錄的總行數是準確的。
而InnoDB引擎支持事務和行鎖,存在並發修改的情況。又由於事務的隔離性,會出現不可重複讀和幻讀,記錄的總行數無法保證是準確的。
2. 能不能手動實現統計總行數
既然InnoDB引擎沒有幫我們記錄總行數,我們能不能手動記錄總行數,比如使用Redis。
其實也是不行的,使用Redis記錄總行數,至少有下面3個問題:
- 無法實現事務之間的隔離
- 更新丟失,因為i++不是原子操作,當然可以使用Lua腳本實現原子操作,更複雜。
- Redis是非關係型緩存數據庫,不能當作關係型持久化數據庫使用,一般需要設置過期時間。

由上圖中得知,雖然Redis計數加1操作放在了事務裏面,但是不受事務控制的,在事務沒有提交前,其他查詢依然讀到了最新的總行數,這就是臟讀的情況。
3. InnoDB引擎能否實現快速計數
有一種辦法,可以粗略估計表的總行數,就是使用MySQL命令:
show table status like 'user';

真實的總行數有100萬行,預估有99萬多行,誤差在可接受的範圍內。
部分場景適用,比如粗略估計網站的總用戶數。
4. 四種計數方式的性能差別
常見的統計總行數的方式有以下四種:
count(*) 、 count(常量) 、 count(id) 、 count(字段)
InnoDB引擎對count計數做了優化,會選用數據量較小的非聚簇索引進行統計。
比如用戶表中有三個索引,分別是主鍵索引、name索引和age索引,使用執行計劃查看計數的時候用到了哪個索引?
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`name` varchar(100) DEFAULT NULL COMMENT '姓名',
`age` tinyint NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB COMMENT='用戶表';
explain select count(*) from user;
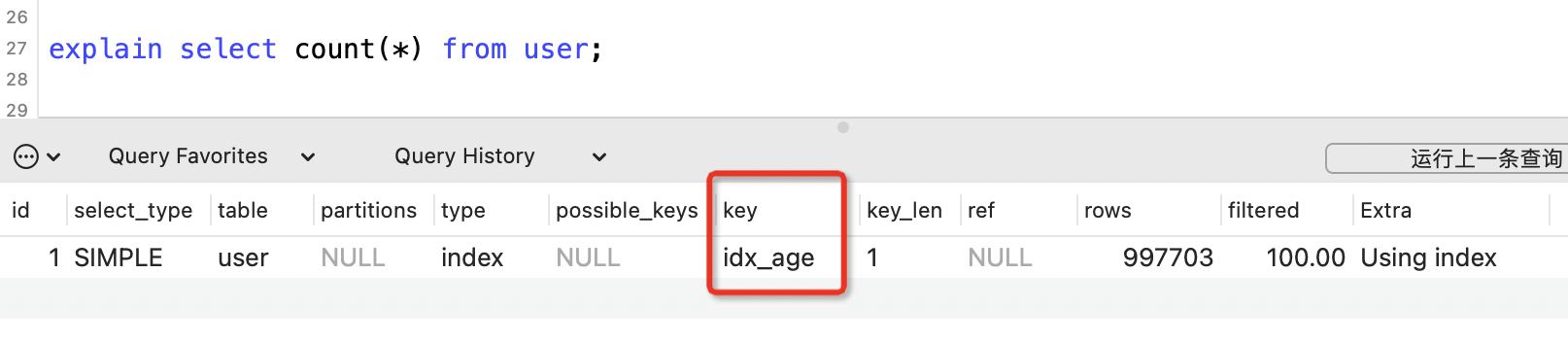
用到了數據量較小的age索引。
count(*) 、 count(常量) 是直接統計表中的總行數,效率較高。
而 count(id) 還需要把數據返回給MySQL Server端進行累加計數。
最後 count(字段)需要篩選不為null字段,效率最差。
四種計數的查詢性能從高到低,依次是:
count(*) ≈ count(常量) > count(id) > count(字段)
對於大多數情況,得到計數結果,還是老老實實使用count(*)
所以推薦使用select count(*),別跟**select *搞混了,不推薦使用select ***的。