論文解讀(RvNN)《Rumor Detection on Twitter with Tree-structured Recursive Neural Networks》
論文信息
論文標題:Rumor Detection on Twitter with Tree-structured Recursive Neural Networks
論文作者:Jing Ma, Wei Gao, Kam-Fai Wong
論文來源:ACL,2018
論文地址:download
論文代碼:download
Abstract
本文提出了兩種基於自下向上和自上而下的樹狀結構神經網絡的遞歸神經模型用於謠言表示學習和分類,自然符合推文的傳播布局。
1 Introduction
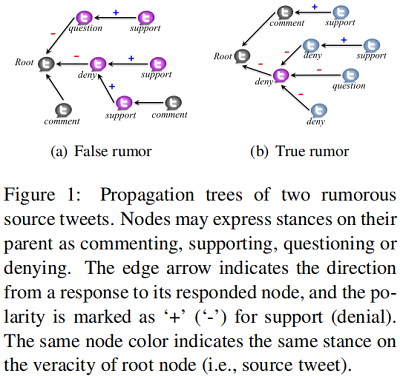
Figure 1 舉例說明了兩個謠言傳播樹,一個是假,一個是真。對於結構不敏感的方法,帖子回復通常有支持或者否定的回答,這種方法基本上依賴於文本中不同態度的比例。同時存在一些推文不是直接回復源推文,而是直接對其祖先進行回應,表明交互作用具有明顯的局部特徵。
本文貢獻:
-
- 這是第一個基於樹狀結構遞歸神經網絡的結構和內容語義,用於檢測微博帖子的謠言;
- 提出了兩種基於自下而上和自上而下的樹狀結構的 RvNN 模型的變體,通過捕獲結構和紋理屬性來為一個聲明生成更好的集成表示;
- 基於真實世界的Twitter數據集的實驗在謠言分類和早期檢測任務上都取得了比最先進的基線更好的改進;
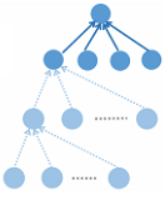
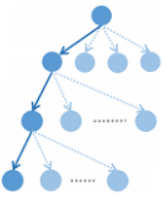
2 RvNN-based Rumor Detection
方法的核心思想是通過對樹中不同分支上的傳播結構的遞歸來加強樹節點的高級表示。例如,確認或支持一個節點的響應節點(例如,「我同意」,「正確」等)可以進一步加強該節點的立場,而拒絕或質疑回答(例如,「不同意」,真的嗎?!)否則就會削弱它的立場。
2.1 Standard Recursive Neural Networks
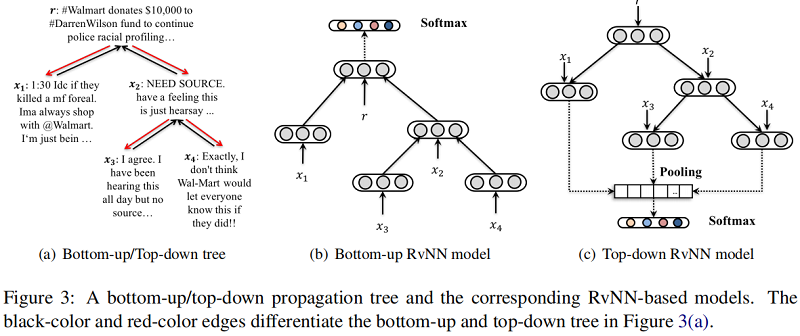
RvNN 是一種樹狀結構的神經網絡。RvNN 的原始版本使用了二值化的句子解析樹,其中與解析樹的每個節點相關聯的表示是從其直接子節點計算出來的。標準 RvNN 的整體結構如 Figure 2 的右側所示,對應於左側的輸入解析樹。
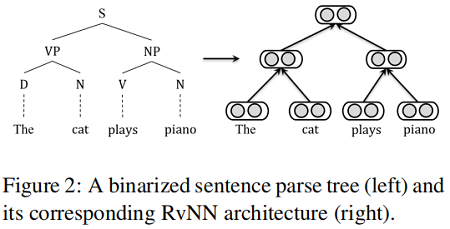
葉節點是一個輸入句子中的單詞,每個單詞都由一個低維的單詞嵌入來表示。非葉節點是句子的組成部分,通過基於子節點的表示進行遞歸計算。假設 $p$ 是用有兩個子節點 $c_{1}$ 和 $c_{2}$ 的父節點 特徵向量,且可以通過子節點特徵向量計算 $p=f\left(W \cdot\left[c_{1} ; c_{2}\right]+b\right)$,其中 $f(\cdot) $ 代表着激活函數。
這個計算是在所有樹節點上遞歸完成的;學習到的節點的隱藏向量可以用於各種分類任務。
2.2 Bottom-up RvNN
自底向上模型的核心思想是通過遞歸地訪問從底部的葉子到頂部的根節點的每個節點,為每個子樹生成一個特徵向量。通過這種方式,具有類似上下文的子樹,例如那些具有拒絕父樹和一組支持性子樹的子樹,將被投影到表示空間中的鄰近區域。因此,這些局部謠言指示特徵沿着不同的分支聚集成整個樹的一些全局表示。
在本文中,選擇擴展 GRU 作為隱藏單元來建模樹節點上的長距離交互作用,因為它由於參數更少,效率更高。設 $S (j)$ 表示節點 $j$ 的直接子節點的集合。自底向上模型中節點 $j$ 的過渡方程公式如下:
-
- $x_{j}$ 是節點 $j$ 的原始輸入向量;
- $E$ 表示參數矩陣轉換後輸入;
- $\tilde{x}_{j}$ 是 $j$ 的轉換後表示;
- $\left[W_{*}, U_{*}\right]$ 是 GRU 內部的權重連接;
- $h_{j}$ 和 $h_{s}$ 分別指 $j$ 的隱藏狀態及 $s$ 的隱藏狀態;
- $h_{\mathcal{S}}$ 表示 $j$ 的所有孩子的隱藏狀態的和;
- 重置門 $r_{j}$ 決定如何將當前輸入 $\tilde{x}_{j}$ 與子節點組合;
- 更新門 $z_{j}$ 定義有多少子節點的級聯到當前節點;
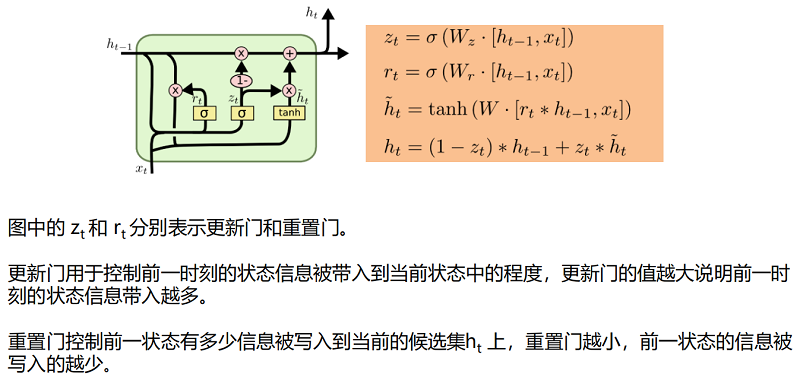
標準 GRU 回顧:
經過自下到上的遞歸聚合後,根節點的狀態(即源推文)可以看作是用於監督分類的整個樹的表示。因此,一個輸出層連接到根節點,使用 softmax 函數來預測樹的類:
$\hat{y}=\operatorname{Softmax}\left(V h_{0}+b\right) \quad\quad\quad(2)$
其中,$h_{0}$ 為學習到的根節點隱藏向量;
2.3 Top-down RvNN
這種自上而下的方法的想法是為每個帖子的傳播路徑生成一個增強的特徵向量,其中指示謠言的特徵沿着路徑上的傳播歷史聚合。言下之意就是當前節點的父節點支持、否定源帖的行為有很大的參考價值。話是這麼說,但是公式沒有體現出來,只是單純的聚合消息。
假設節點 $j$ 的隱藏狀態為 $h_{j}$,然後,通過將其父節點 $j$ 的隱藏狀態 $h_{\mathcal{P}(j)}$ 與其自己的輸入向量 $x_{j}$ 相結合,可以計算出節點j的隱藏狀態 $h_{j}$ 。因此,節點 $j$ 的轉移方程可以表示為一個標準的 GRU:
$\begin{aligned}\tilde{x}_{j} &=x_{j} E \\r_{j} &=\sigma\left(W_{r} \tilde{x}_{j}+U_{r} h_{\mathcal{P}(j)}\right) \\z_{j} &=\sigma\left(W_{z} \tilde{x}_{j}+U_{z} h_{\mathcal{P}(j)}\right) \\\tilde{h}_{j} &=\tanh \left(W_{h} \tilde{x}_{j}+U_{h}\left(h_{\mathcal{P}(j)} \odot r_{j}\right)\right) \\h_{j} &=\left(1-z_{j}\right) \odot h_{\mathcal{P}(j)}+z_{j} \odot \tilde{h}_{j}\end{aligned} \quad\quad\quad(3)$
因此,我們添加了一個最大池化層,以取所有葉節點上向量的每個維度的最大值。這還可以幫助從所有傳播路徑中捕獲最吸引人的指示性特性。
基於池化的結果,我們最終在輸出層中使用一個 softmax 函數來預測樹的標籤:
2.4 Model Training
$L(y, \hat{y})=\sum\limits_{n=1}^{N} \sum\limits _{c=1}^{C}\left(y_{c}-\hat{y}_{c}\right)^{2}+\lambda\|\theta\|_{2}^{2}\quad\quad\quad$
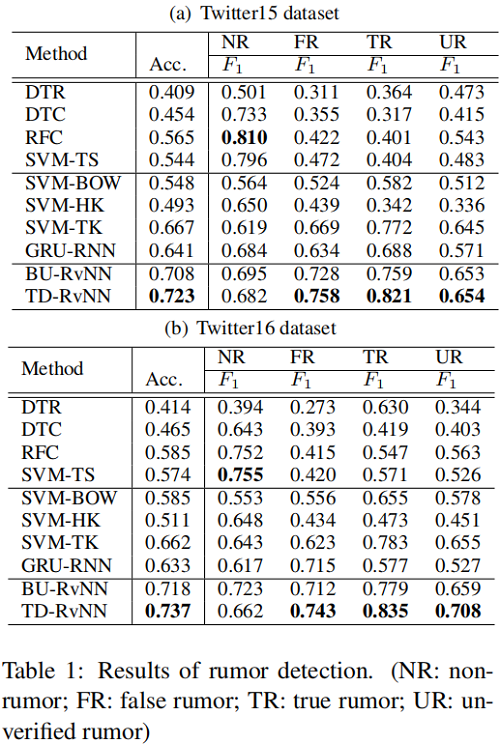
3 Experiments
4 Conclusions
我們提出了一種基於遞歸神經網絡的自下而上和自頂向下的樹結構模型,用於推特謠言檢測。遞歸模型的固有特性允許它們使用傳播樹來指導從推文內容中學習表示,例如嵌入隱藏在結構中的各種指示性信號,以便更好地識別謠言。在兩個公開的推特數據集上的結果表明,與最先進的基線相比,我們的方法在非常大的利潤範圍內提高了謠言檢測性能。
在我們未來的工作中,我們計劃將其他類型的信息,如用戶屬性,集成到結構化的神經模型中,以進一步增強表示學習,同時檢測謠言散布者。我們還計劃通過利用結構信息來使用無監督模型。


