讀時加寫鎖,寫時加讀鎖,Eureka可真的會玩
- 2022 年 9 月 14 日
- 筆記
- SpringCloud
大家好,我是三友~~
在對於讀寫鎖的認識當中,我們都認為讀時加讀鎖,寫時加寫鎖來保證讀寫和寫寫互斥,從而達到讀寫安全的目的。但是就在我翻Eureka源碼的時候,發現Eureka在使用讀寫鎖時竟然是在讀時加寫鎖,寫時加讀鎖,這波操作屬實震驚到了我,於是我就花了點時間研究了一下Eureka的這波操作。
Eureka服務註冊實現類
眾所周知,Eureka作為一個服務註冊中心,肯定會涉及到服務實例的註冊和發現,從而肯定會有服務實例寫操作和讀操作,這是每個註冊中心最基本也是最核心的功能。
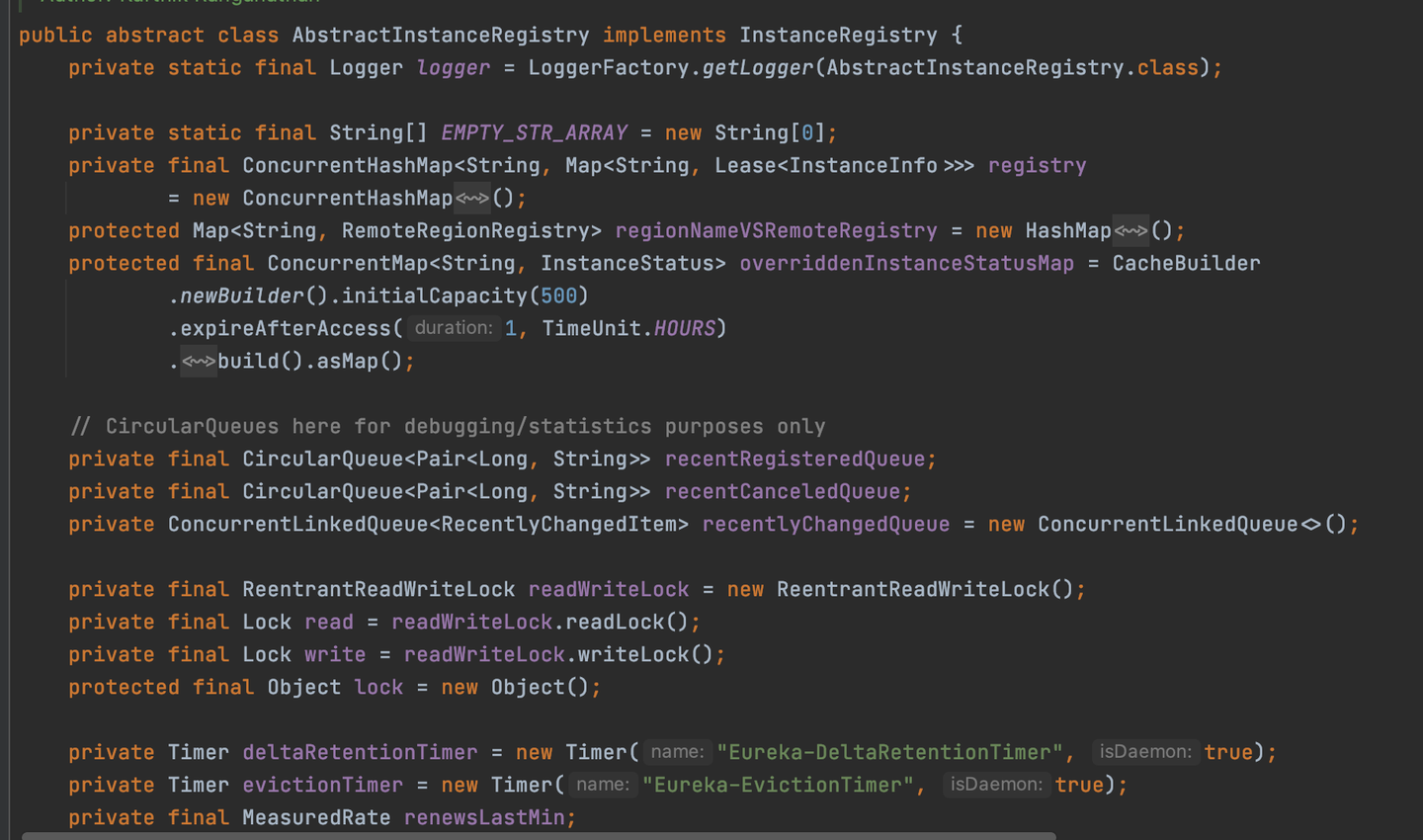 AbstractInstanceRegistry
AbstractInstanceRegistry
如上圖,AbstractInstanceRegistry是註冊中心的服務註冊核心實現類,這裏面保存了服務實例的數據,封裝了對於服務實例註冊、下線、讀取等核心方法。
這裡講解一下這個類比較重要的成員變量
服務註冊表
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
註冊表就是存儲的服務實例的信息。Eureka是使用ConcurrentHashMap來進行保存的。鍵值是服務的名稱,值為服務的每個具體的實例id和實例數據的映射,所以也是一個Map數據結構。InstanceInfo就是每個服務實例的數據的封裝對象。
服務的上線、下線、讀取其實就是從註冊表中讀寫數據。
最近變動的實例隊列
private ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue = new ConcurrentLinkedQueue<>();
recentlyChangedQueue保存了最近變動的服務實例的信息。如果有服務實例的變動發生,就會將這個服務實例封裝到RecentlyChangedItem中,存到recentlyChangedQueue中。
什麼叫服務實例發生了變動。舉個例子,比如說,有個服務實例來註冊了,這個新添加的實例就是變動的實例。
所以服務註冊這個操作就會有兩步操作,首先會往註冊表中添加這個實例的信息,其次會給這個實例標記為新添加的,然後封裝到RecentlyChangedItem中,存到recentlyChangedQueue中。
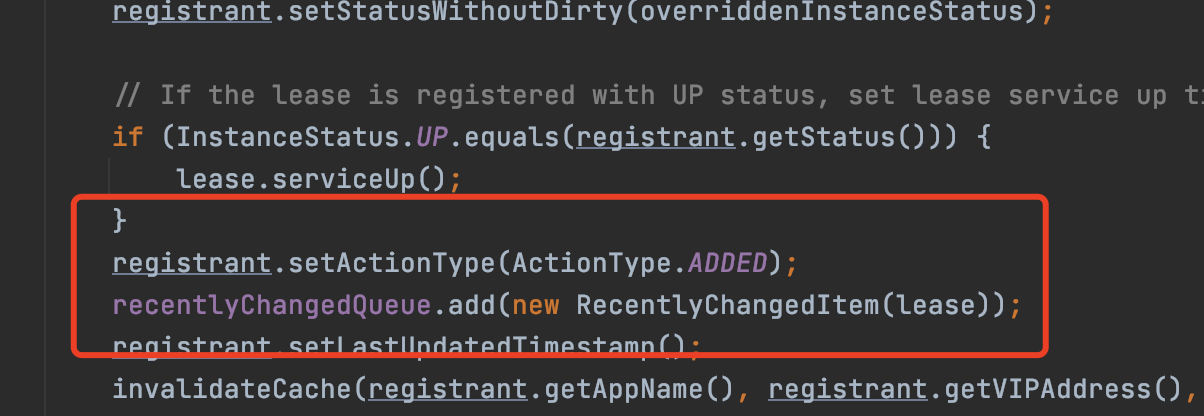 新增
新增
同樣的,服務實例狀態的修改、刪除(服務實例下線)不僅會操作註冊表,同樣也會進行標記,封裝成一個RecentlyChangedItem並添加到recentlyChangedQueue中。
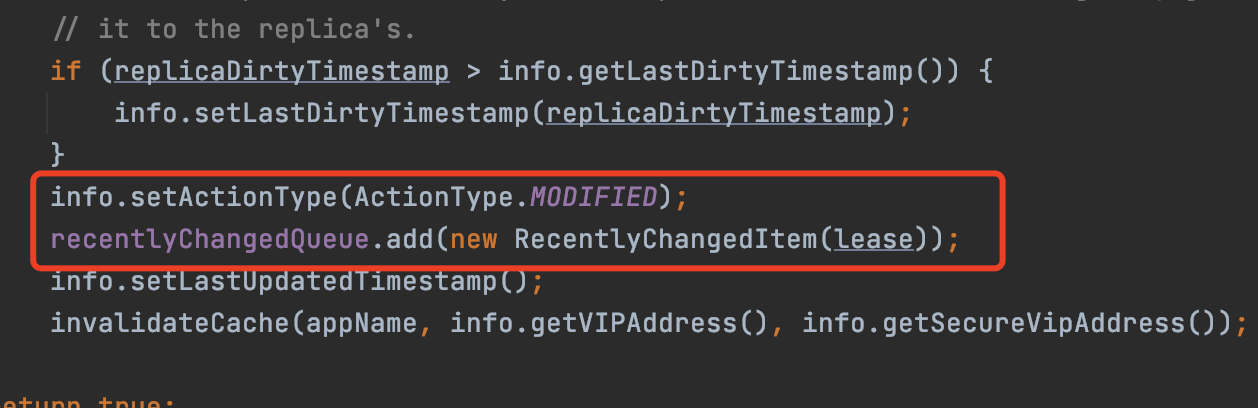 修改
修改 下線
下線
所以從這分析也可以看出,註冊表的寫操作同時也會往recentlyChangedQueue中寫一條數據,這句話很重要。
後面本文提到的註冊表的寫操作都包含對recentlyChangedQueue的寫操作。
讀寫鎖
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock(); private final Lock read = readWriteLock.readLock(); private final Lock write = readWriteLock.writeLock();
讀寫鎖就不用說了,JDK提供的實現。
讀寫鎖的加鎖場景
上面說完了AbstractInstanceRegistry比較重要的成員變量,其中就有一個讀寫鎖,也是本文的主題,所以接下來看看哪些操作加讀鎖,哪些操作加寫鎖。
加讀鎖的場景
1、服務註冊
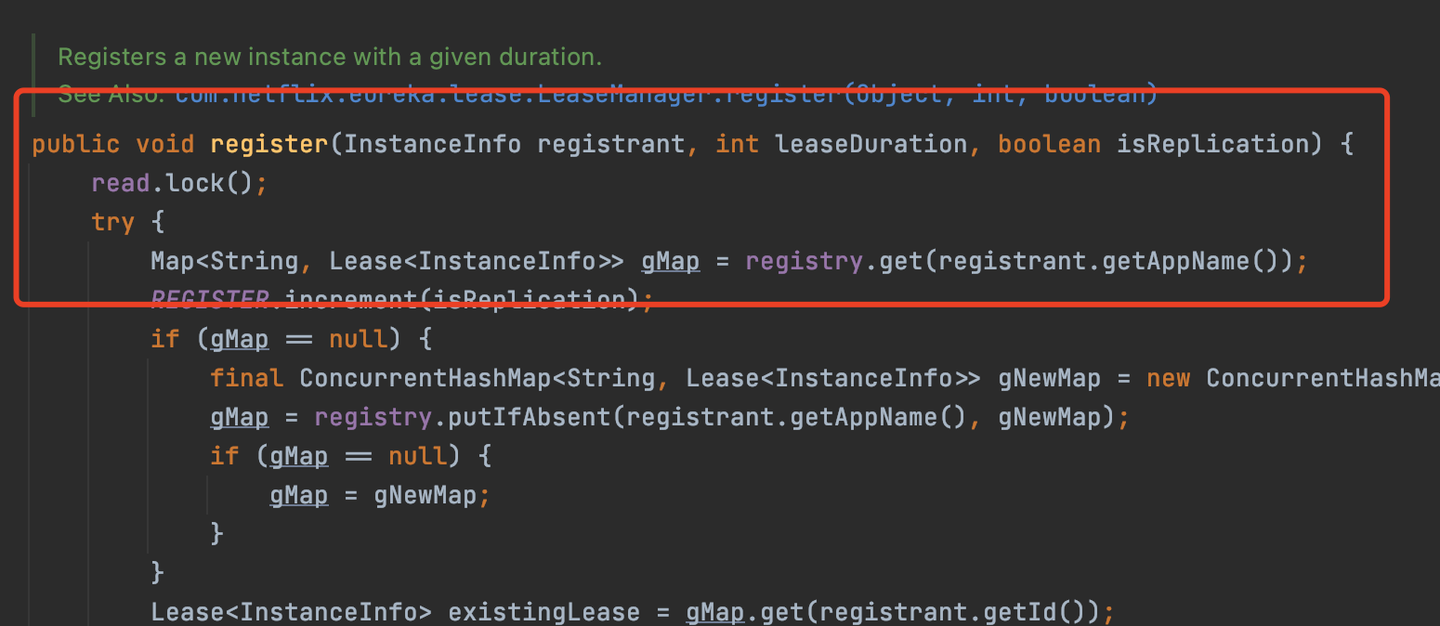 register
register
服務註冊就是在註冊表中添加一個服務實例的信息,加讀鎖。
2、服務下線
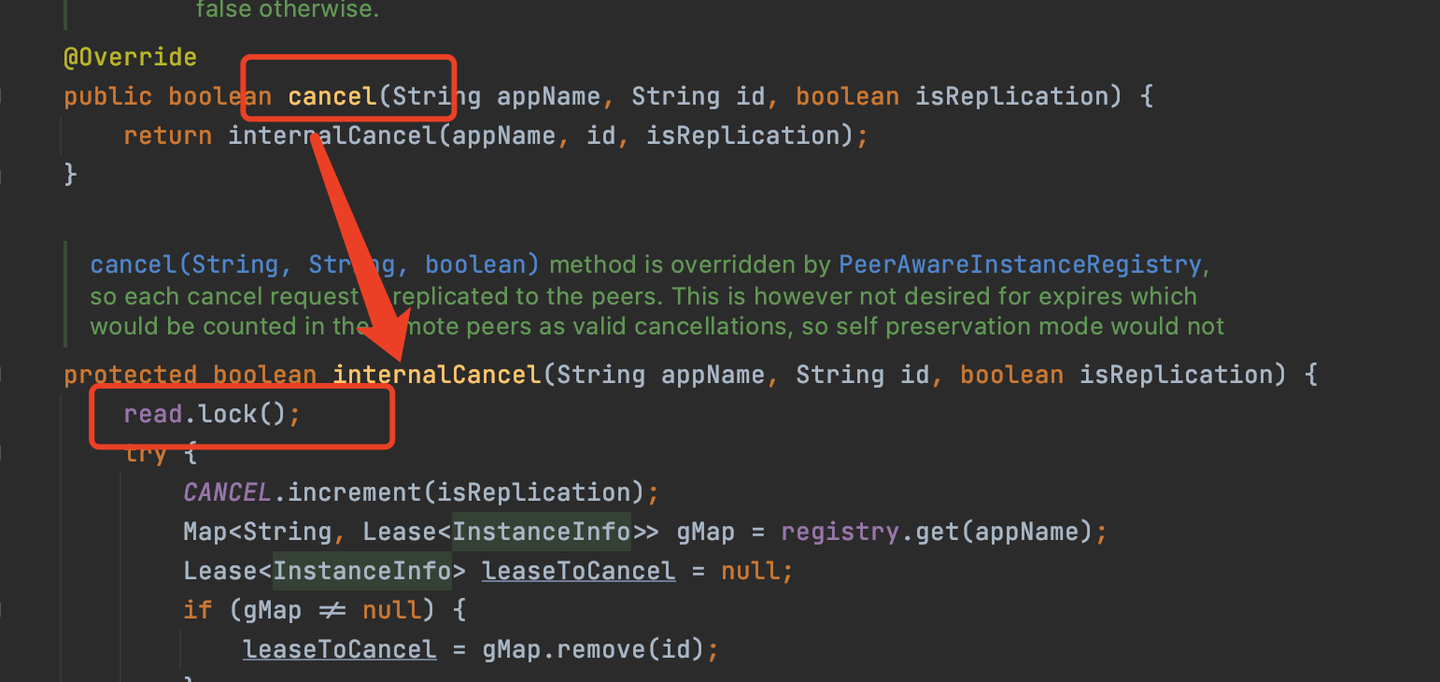 cancel和internalCancel
cancel和internalCancel
服務下線就是在註冊表刪除這個服務實例的信息,服務下線的方法最後是調用internalCancel實現的,而internalCancel是加的讀鎖,所以服務實例下線的時候加了讀鎖。
3、服務驅逐
什麼叫服務驅逐,很簡單,就是服務端會定時檢查每個服務實例是否有向服務端發送心跳,如果服務端超過一定時間沒有接收到服務實例的心跳信息,那麼就會認為這個服務實例不可用,就會自動將這個服務實例從註冊表刪除,這就是叫服務驅逐。
服務驅逐是通過evict方法實現的,這個方法最終也是調用服務下線internalCancel方法來實現驅逐的。
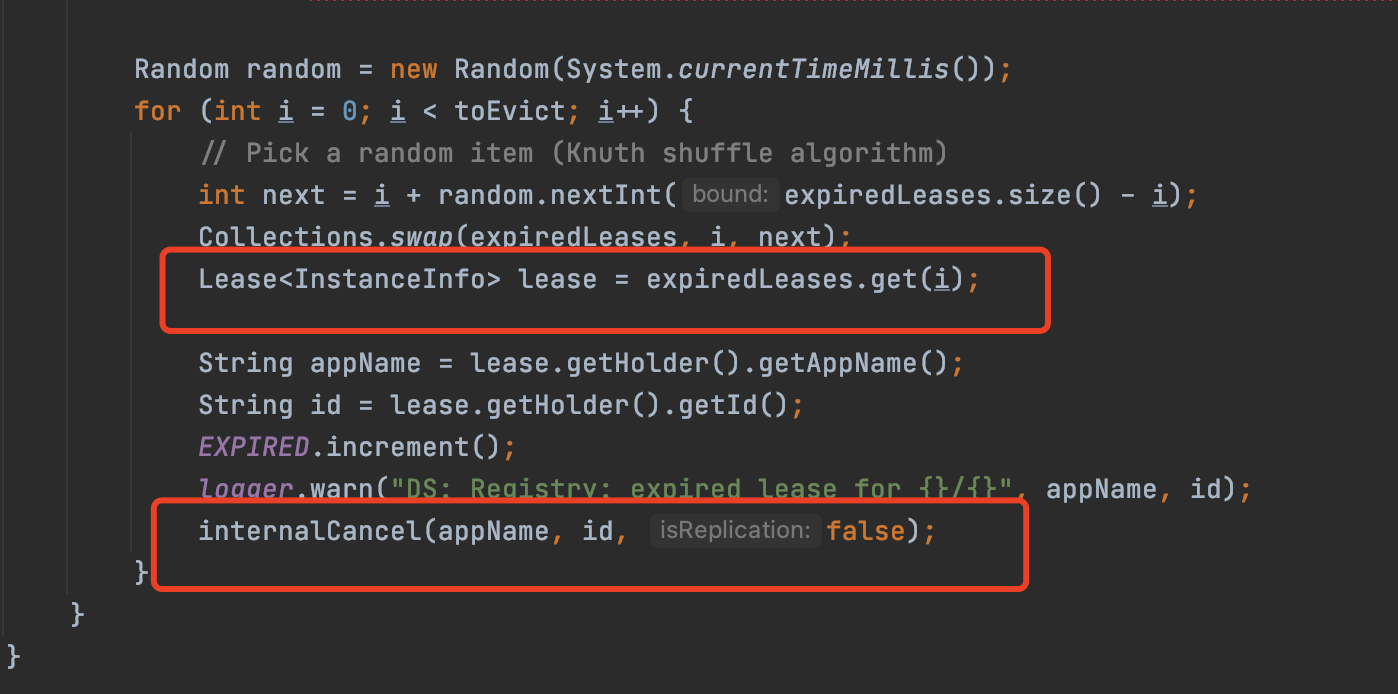
所以服務驅逐,其實也是加讀鎖的,因為最後是調用internalCancel方法來實現的,而internalCancel方法就是加的讀鎖。
4、更新服務狀態
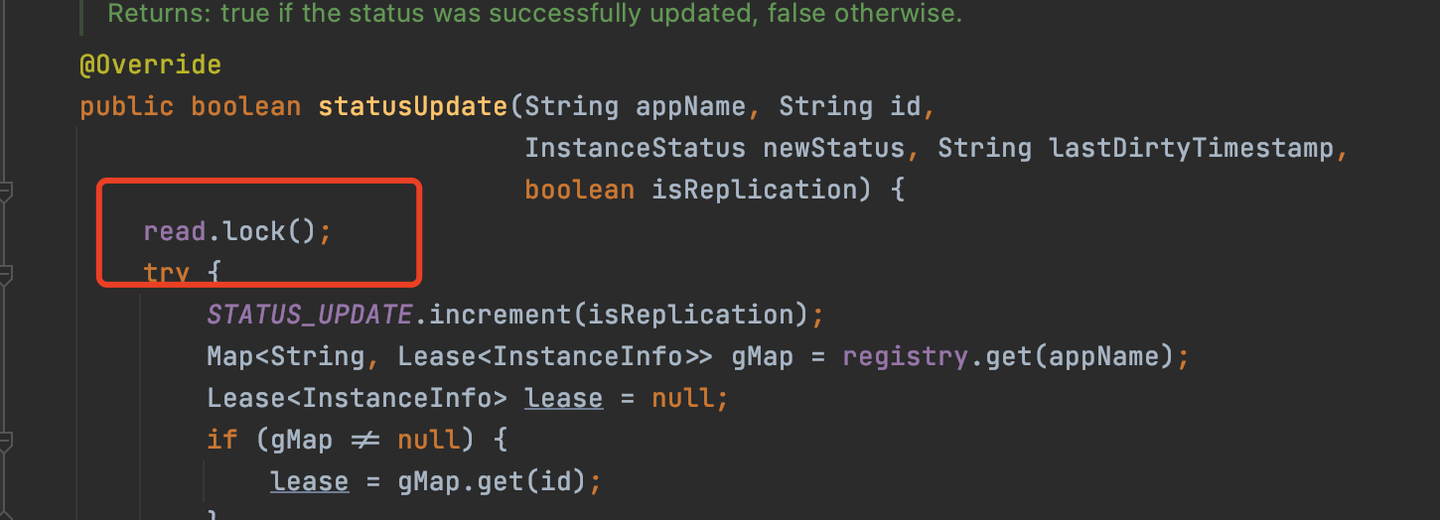
服務實例的狀態變動了,進行更新操作,也是加的讀鎖
5、刪除服務狀態
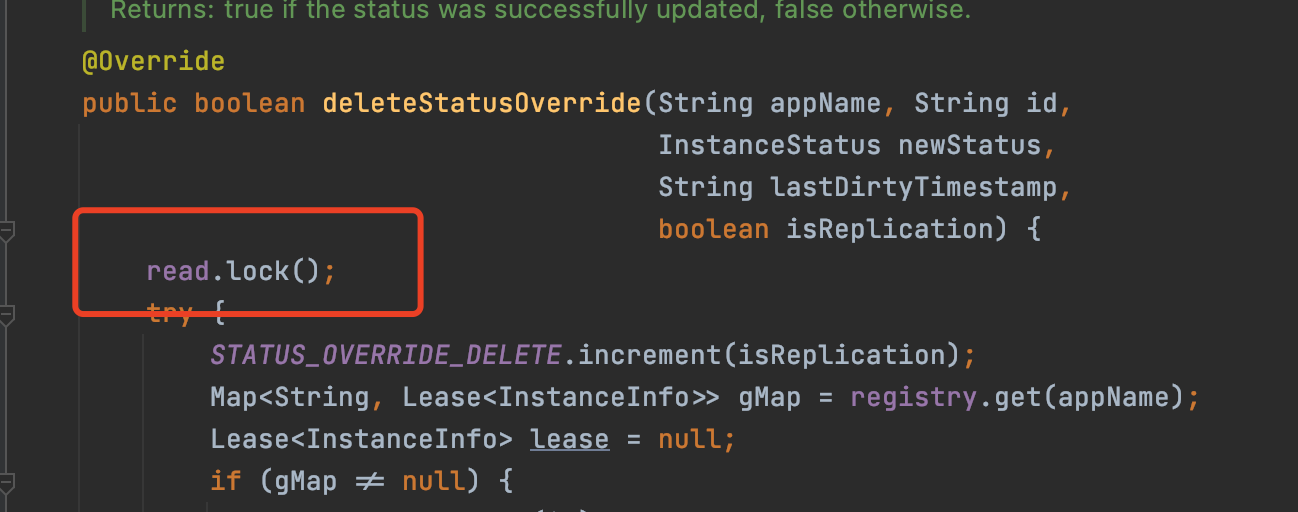
將服務的狀態刪了,也是加的讀鎖。
這裡都是對於註冊表的寫操作,所以進行這些操作的同時也會往recentlyChangedQueue中寫一條數據,只不過方法太長,代碼太多,這裡就沒有截出來。
加寫鎖的場景
獲取增量的服務實例的信息。
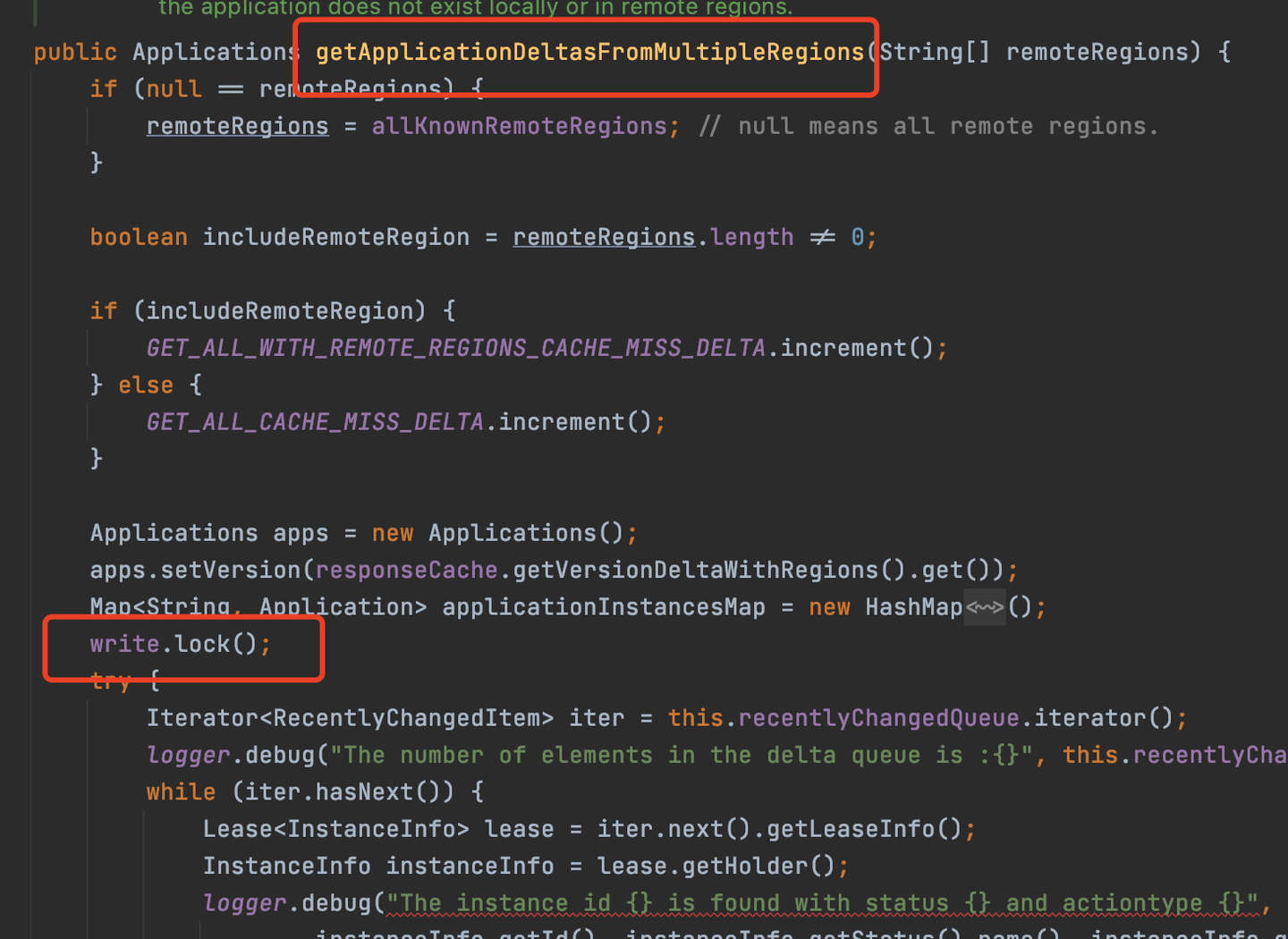 getApplicationDeltasFromMultipleRegions
getApplicationDeltasFromMultipleRegions
所謂的增量信息,就是返回最近有變動的服務實例,而recentlyChangedQueue剛剛好保存了最近的服務實例的信息,所以這個方法的實現就是遍歷recentlyChangedQueue,取出最近有變動的實例,返回。所以保存最近變動的實例,其實是為了增量拉取做準備的。
加鎖總結
這裡我總結一下讀鎖和寫鎖的加鎖場景:
- 加讀鎖: 服務註冊、服務下線、服務驅逐、服務狀態的更新和刪除
- 加寫鎖:獲取增量的服務實例的信息
讀寫鎖的加鎖疑問
上一節講了Eureka中加讀鎖和寫鎖的場景,有細心的小夥伴可能會有疑問,加讀鎖的場景主要涉及到服務註冊表的增刪操作,也就是寫操作;而加寫鎖的場景是一個讀的操作。
這不是很奇怪么,不按套路出牌啊,別人都是寫時加寫鎖,讀時加讀鎖,Eureka剛好反過來,屬實是真的會玩。

寫的時候加的讀鎖,那麼就說明可以同時寫,那會不會有線程安全問題呢?
答案是不會有安全問題。
我們以一個服務註冊為例。一個服務註冊,涉及到註冊表的寫操作和recentlyChangedQueue的寫操作。
註冊表本身就是一個ConcurrentHashMap,線程安全的map,註冊表的值的Map數據結構,其實也是一個ConcurrentHashMap,如圖。
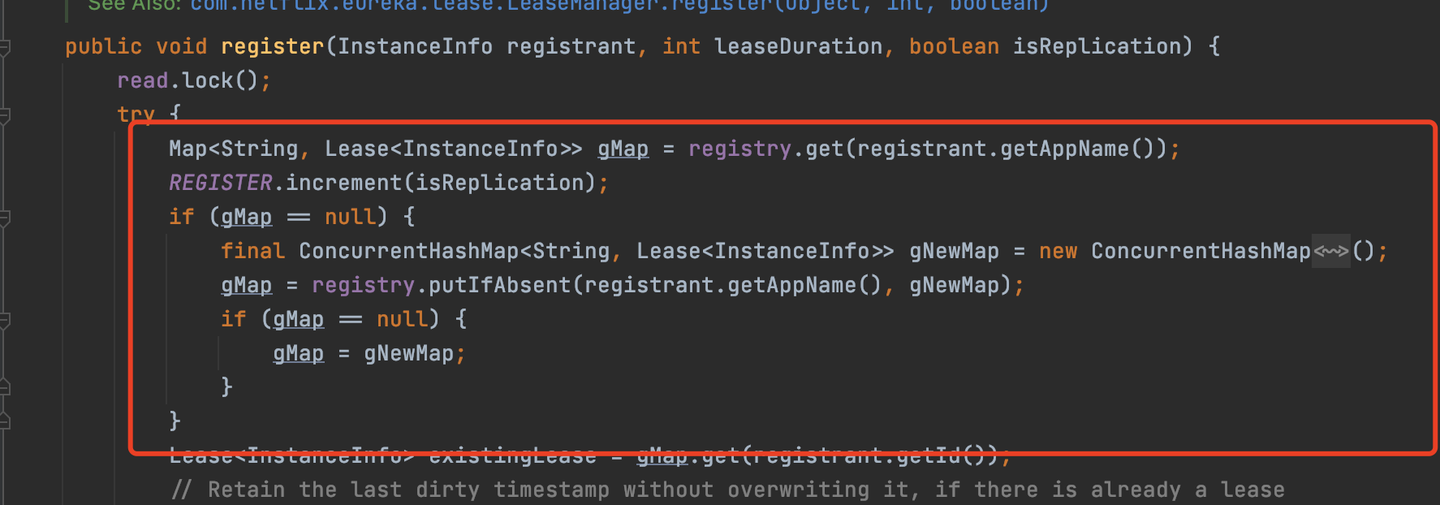
通過源碼可以發現,其實也是放入的值也是一個ConcurrentHashMap,所以註冊表本身就是線程安全的,所以對於註冊表的寫操作,本身就是安全的。
再來看一下對於recentlyChangedQueue,它本身就是一個ConcurrentLinkedQueue,並發安全的隊列,也是線程安全的。
所以單獨對註冊表和recentlyChangedQueue的操作,其實是線程安全的。
到這裡更加迷糊了,本身就是線程安全的,為什麼要加鎖呢,而且對於寫操作,還加的是讀鎖,這就導致可以有很多線程同時去寫,對於寫來說,相當加鎖加了個寂寞。
帶着疑惑,接着往下看。
Eureka服務實例的拉取方式和hash對比機制
拉取方式
Eureka作為一個註冊中心,客戶端肯定需要知道服務端道理存了哪些服務實例吧,所以就涉及到了服務的發現,從而涉及到了客戶端跟服務端數據的交互方式,pull還是push。如果有不清楚pull和push的機制,可以看一下RocketMQ的push消費方式實現的太聰明了這篇文章,裏面有交代什麼是pull還是push。
那麼Eureka到底是pull還是push模式呢?這裡我就不再賣關子了,其實是一種pull模式,也就是說客戶端會定期從服務端拉取服務實例的數據。並且Eureka提供了兩種拉取方式,全量和增量。
1、全量
全量其實很好理解,就是拉取註冊表所有的數據。
全量一般發生在客戶端啟動之後第一次獲取註冊表的信息的時候,就會全量拉取註冊表。還有一種場景也會全量拉取,後面會說。
2、增量
增量,前面在說加寫鎖的時候提到了,就是獲取最近發生變化的實例的信息,也就是recentlyChangedQueue裏面的數據。
增量相比於全量拉取的好處就是可以減少資源的浪費,假如全量拉取的時候數據壓根就沒有變動,那麼白白浪費網絡資源;但是如果是增量的話,數據沒有變動,那麼就沒有增量信息,就不會有資源的浪費。
在客戶端第一次啟動的全量拉取之後,定時任務每次拉取的就是增量數據。
增量拉取的hash對比機制
如果是增量拉取,客戶端在拉取到增量數據之後會多干兩件事:
- 會將增量信息跟本地緩存的服務實例進行合併
- 判斷合併後的服務的數據跟服務端的數據是不是一樣
那麼如何去判定客戶端的數據跟服務端的數據是不是一樣呢?
Eureka是通過一種hash對比的機制來實現的。
當服務端生成增量信息的時候,同時會生成一個代表這一刻全部服務實例的hash值,設置到返回值中,代碼如下
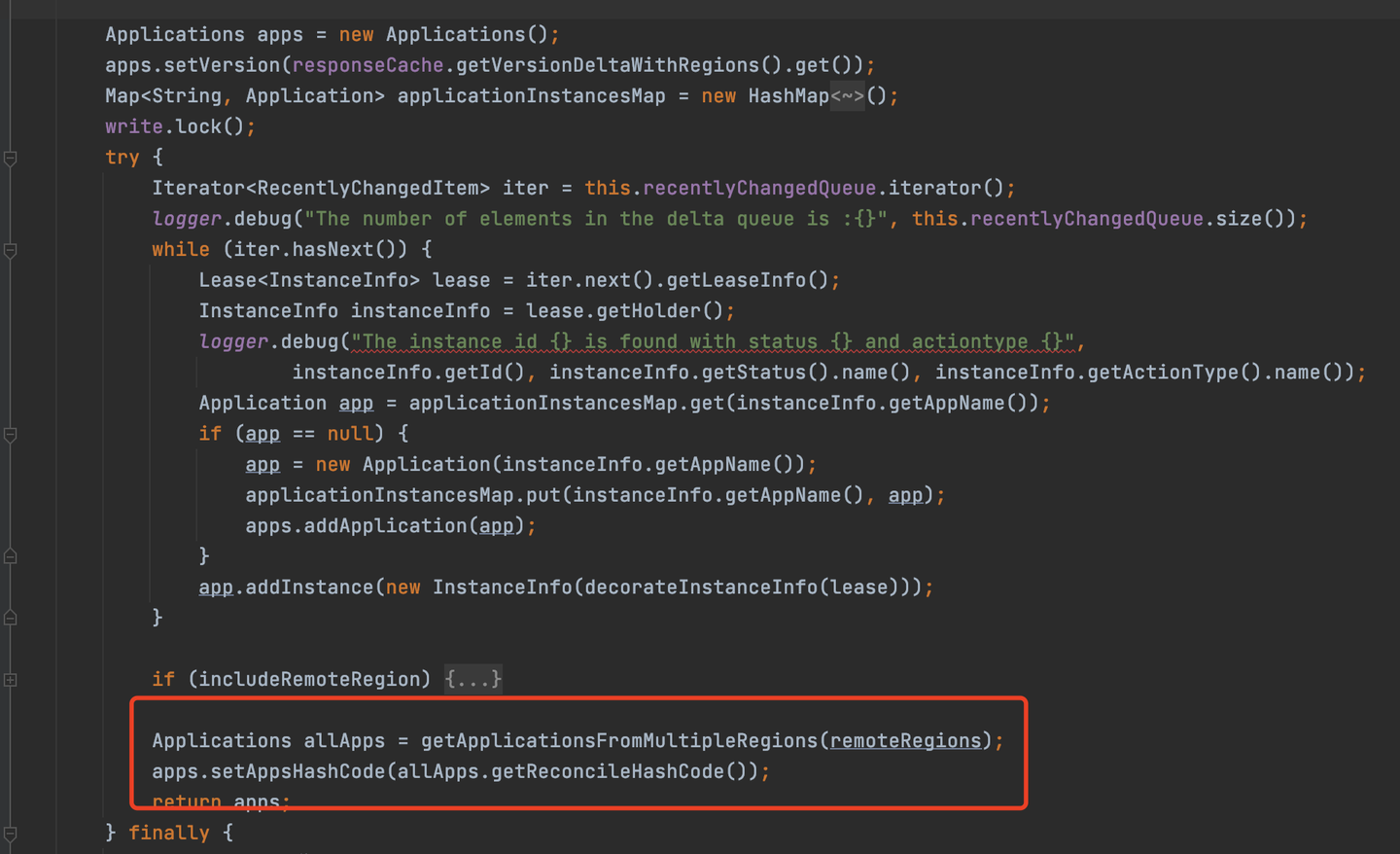
所以增量信息返回的數據有兩部分,一部分是變動的實例的信息,還有就是這一刻服務端所有的實例信息生成的hash值。
當客戶端拉取到增量信息並跟本地原有的老的服務實例合併完增量信息之後,客戶端會用相同的方式計算出合併後服務實例的hash值,然後會跟服務端返回的hash值進行對比,如果一樣,說明本次增量拉取之後,客戶端緩存的服務實例跟服務端一樣,如果不一樣,說明兩邊的服務實例的數據不一樣。
這就是hash對比機制,通過這個機制來判斷增量拉取的時候兩邊的服務實例數據是不是一樣。
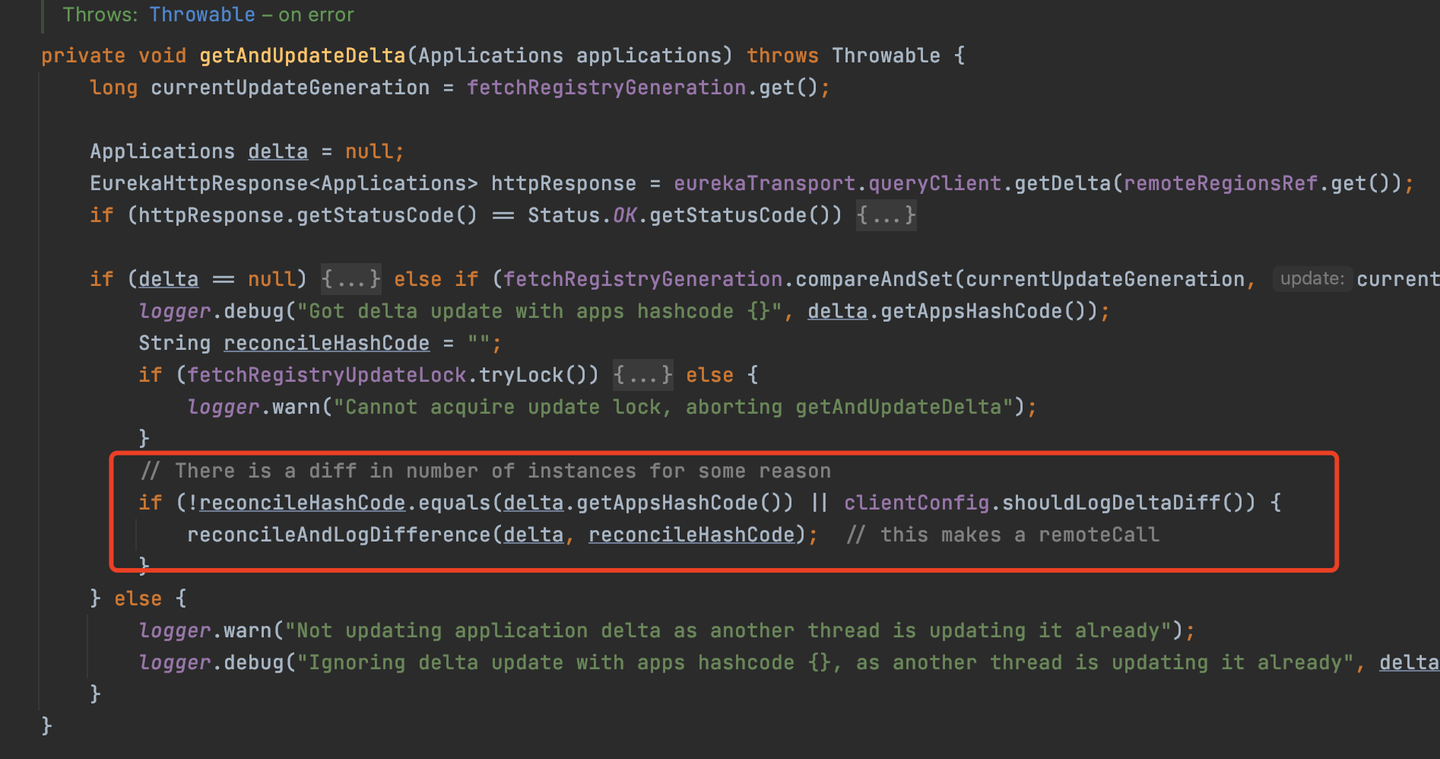 hash對比
hash對比
但是,如果發現了不一樣,那麼此時客戶端就會重新從服務端全量拉取一次服務數據,然後將該次全量拉取的數據設置到本地的緩存中,所以前面說的還有一種全量拉取的場景就在這裡,源碼如下
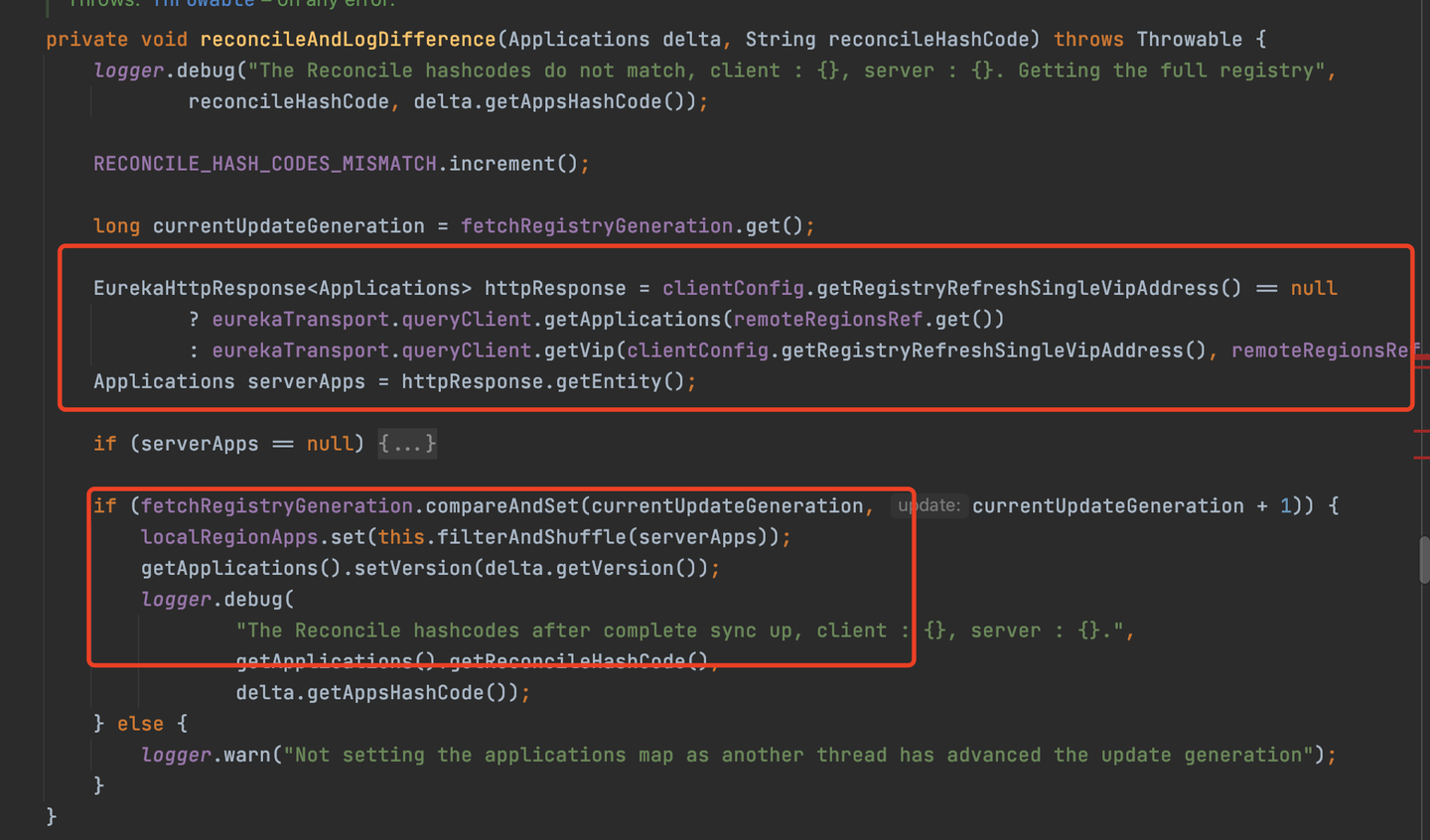 重新全量拉取
重新全量拉取
讀寫鎖的使用揭秘
前面說了增量拉取和hash對比機制,此時我們再回過頭仔細分析一下增量信息封裝的兩步操作:
- 第一步遍歷recentlyChangedQueue,封裝增量的實例信息
- 第二步生成所有服務實例數據對應的hash值,設置到增量信息返回值中
為什麼要加鎖
假設不加鎖,那麼對於註冊表和recentlyChangedQueue讀寫都可以同時進行,那麼會出現這麼一種情況
當獲取增量信息的時候,在第一步遍歷recentlyChangedQueue時有2個變動的實例,註冊表總共有5個實例
當recentlyChangedQueue遍歷完之後,還沒有進行第二步計算hash值時,此時有服務實例來註冊了,由於不加鎖,那麼可以同時操作註冊表和recentlyChangedQueue,於是註冊成功之後註冊表數據就變成了6個實例,recentlyChangedQueue也會添加一條數據
但是因為recentlyChangedQueue已經遍歷完了,此時不會在遍歷了,那麼剛註冊的這個實例在此次獲取增量數據時就獲取不到了,但是由於計算hash值是通過這一時刻所有的實例數據來計算,那麼就會把這個新的實例計算進去了。
這不完犢子了么,增量信息沒有,但是全部實例數據的hash值有,那麼就會導致客戶端在合併增量信息之後計算的hash值跟返回的hash值不一樣,就會導致再次全量拉取,白白浪費了本次增量拉取操作。
所以一定要加鎖,保證在獲取增量數據時,不能對註冊表進行改動。
為什麼加讀寫鎖而不是synchronized鎖
這個其實跟Eureka沒多大關係,主要是讀寫鎖和synchronized鎖特性決定的。synchronized會使得所有的操作都是串行化,雖然也能解決問題,但是也會導致並發性能降低。
為什麼寫時加讀鎖,讀時加寫鎖
現在我們轉過來,按照正常的操作,服務註冊等寫操作加寫鎖,獲取增量的時候加讀鎖,那麼可以不可呢?
其實也是可以的,因為這樣註冊表寫操作和獲取的增量信息讀操作還是互斥的,那麼獲取的增量信息還是對的。
那麼為什麼Eureka要反過來?
寫(鎖)寫(鎖)是互斥的。如果註冊表寫操作加了寫鎖,那麼所有的服務註冊、下線、狀態更新都會串行執行,並發性能就會降低,所以對於註冊表寫操作加了讀鎖,可以提高寫的性能。
但是,如果獲取的增量讀的操作加了寫鎖,那豈不是讀操作都串行化了,那麼讀的性能不是會變低么?而且註冊中心其實是一個讀多寫少的場景,為了提升寫的性能,浪費讀的性能不是得不償失么?
哈哈,其實對於這個讀操作性能低的問題,Eureka也進行了優化,那就是通過緩存來優化了這個讀的性能問題,讀的時候先讀緩存,緩存沒有才會真正調用獲取增量的方法來讀取增量的信息,所以最後真正走到獲取增量信息的方法,請求量很低。
 ResponseCacheImpl
ResponseCacheImpl
ResponseCacheImpl內部封裝了緩存的操作,因為不是本文的重點,這裡就不討論了。
總結
所以,通過上面的一步一步分析,終於知道了Eureka讀寫鎖的加鎖場景、為什麼要加讀寫鎖以及為什麼寫時加讀鎖,讀時加寫鎖。這裡我再總結一下:
為什麼加讀寫鎖
是為了保證獲取增量信息的讀操作和註冊表的寫操作互斥,避免由於並發問題導致獲取到的增量信息和實際註冊表的數據對不上,從而引發客戶端的多餘的一次全量拉取的操作。
為什麼寫時加讀鎖,讀時加寫鎖
其實是為了提升寫的性能,而讀由於有緩存的原因,真正走到獲取增量信息的請求很少,所以讀的時候就算加寫鎖,對於讀的性能也沒有多大的影響。
從Eureka對於讀寫鎖的使用也可以看出,一個技術什麼時候用,如何使用都是根據具體的場景來判斷的,不能要一概而論。
往期熱門文章推薦
掃碼或者搜索關注公眾號 三友的java日記 ,及時乾貨不錯過,公眾號致力於通過畫圖加上通俗易懂的語言講解技術,讓技術更加容易學習,回復 面試 即可獲得一套面試真題。


