Apache DolphinScheduler 簡單任務定義及複雜的跨節點傳參
- 2022 年 8 月 30 日
- 筆記
- Apache DolphinScheduler, ApacheDolphinScheduler, workflowascode, 任務調度, 大數據, 大數據調度, 工作流調度, 開源
點亮  Star · 照亮開源之路
Star · 照亮開源之路
GitHub://github.com/apache/dolphinscheduler

Apache DolphinScheduler是一款非常不錯的調度工具,可單機可集群可容 器,可調度sql、存儲過程、http、大數據等,也可使用shell、python、java、flink等語言及工具,功能強大類型豐富,適合各類調度型任務,社區及項目也十分活躍,現在Github中已有8.5k的star
準備工作
閱讀本文前建議您先閱讀下官方的文檔
文檔鏈接://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html
在這裡,先準備下sql表資源,以下為postgresql的sql腳本:
表結構
CREATE TABLE dolphinscheduler.tmp (
id int4 NOT NULL,
"name" varchar(50) NULL,
"label" varchar(50) NULL,
update_time timestamp NULL,
score int4 NULL,
CONSTRAINT tmp_pkey PRIMARY KEY (id) );

![]()
表數據
INSERT INTO tmp (id,"name","label",update_time,score) VALUES
(3,'二狗子','','2022-07-06 21:49:26.872',NULL),
(2,'馬云云','',NULL,NULL),
(1,'李思','','2022-07-05 19:54:31.880',85);
![]()
我這裡使用的 postgresql 的數據庫,如果您是 mysql 或者其他數據的用戶,請自行更改以上表和數據並添加到庫中即可~
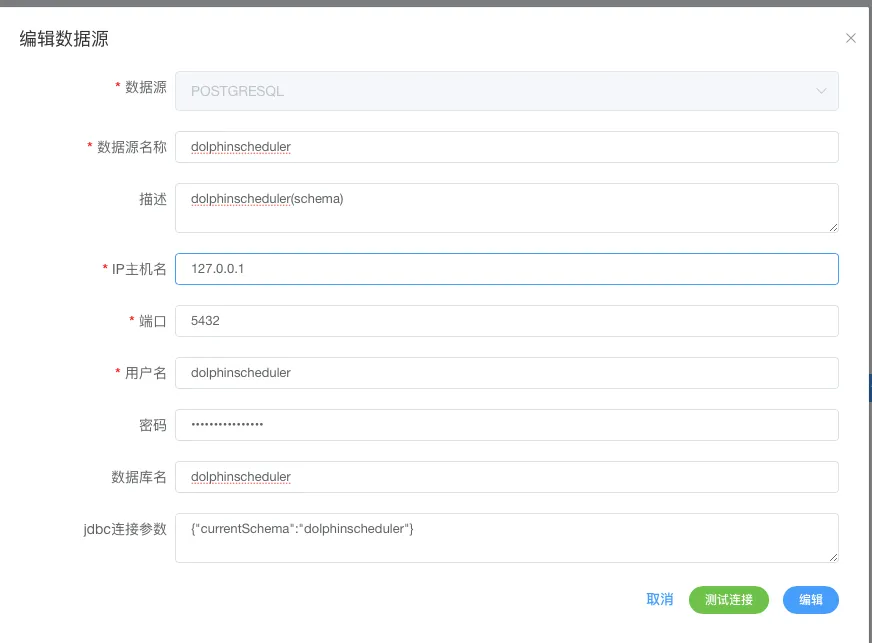
表及數據入庫,請將tmp所屬的庫配置到 DS後台->數據源中心->創建數據源 ,以下是我的配置,記住,這裏面的所有數據庫配置均遵守所屬數據庫類型的jdbc 的 driver 的配置參數,配置完成也會在DS的數據庫生成一條 jdbc 的連接地址,這點要明白~
簡單的項目創建及說明
因為DolphinScheduler的任務是配置在項目下面,所以第一步得新建一個項目,這樣:DS後台->項目管理->創建項目,這是我創建的請看下圖:
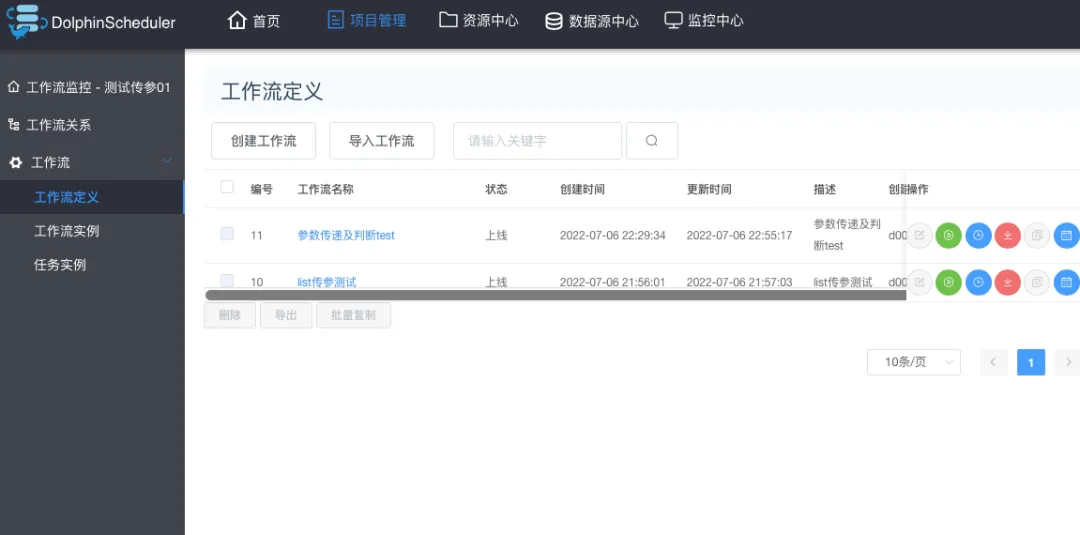
準備完項目之後,鼠標點進去,並進入到工作流定義菜單 頁面,如下圖:
簡單解釋下DS的基本結構
首先,DS一般部署在 linux 服務器下,創建任務的用戶需要在 admin賬戶 下創建,重要的是創建的每個工作賬戶需要與操作系統用戶一一對應.
比如你創建了一個 test 的DS賬戶,那所在的服務器也必須有一個test的賬戶才可行,這是DS的規則。
每個用戶下(除了admin外)所能創建的調度任務均在各自創建的項目下,每個項目又分為多個任務(工作流定義),一個任務下又可分為多個任務節點。
下圖為任務定義
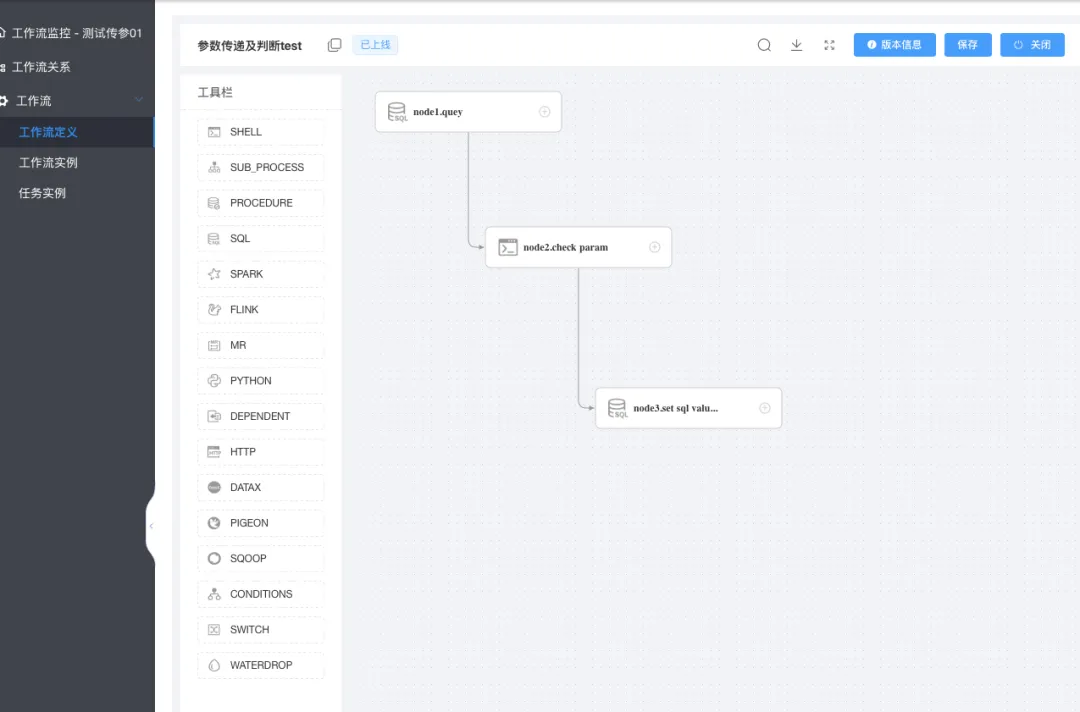
ok,如果已經準備好以上步驟,下面開始繼續定義一個簡單的調度任務~
簡單的參數傳遞
先看錶:
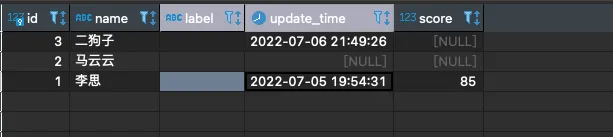
如圖我們先做個簡單的:
如果二狗子的本名叫李思,需要取** id=1 的 name 放到id=3 **的 label 中,並且更新 update_time
01
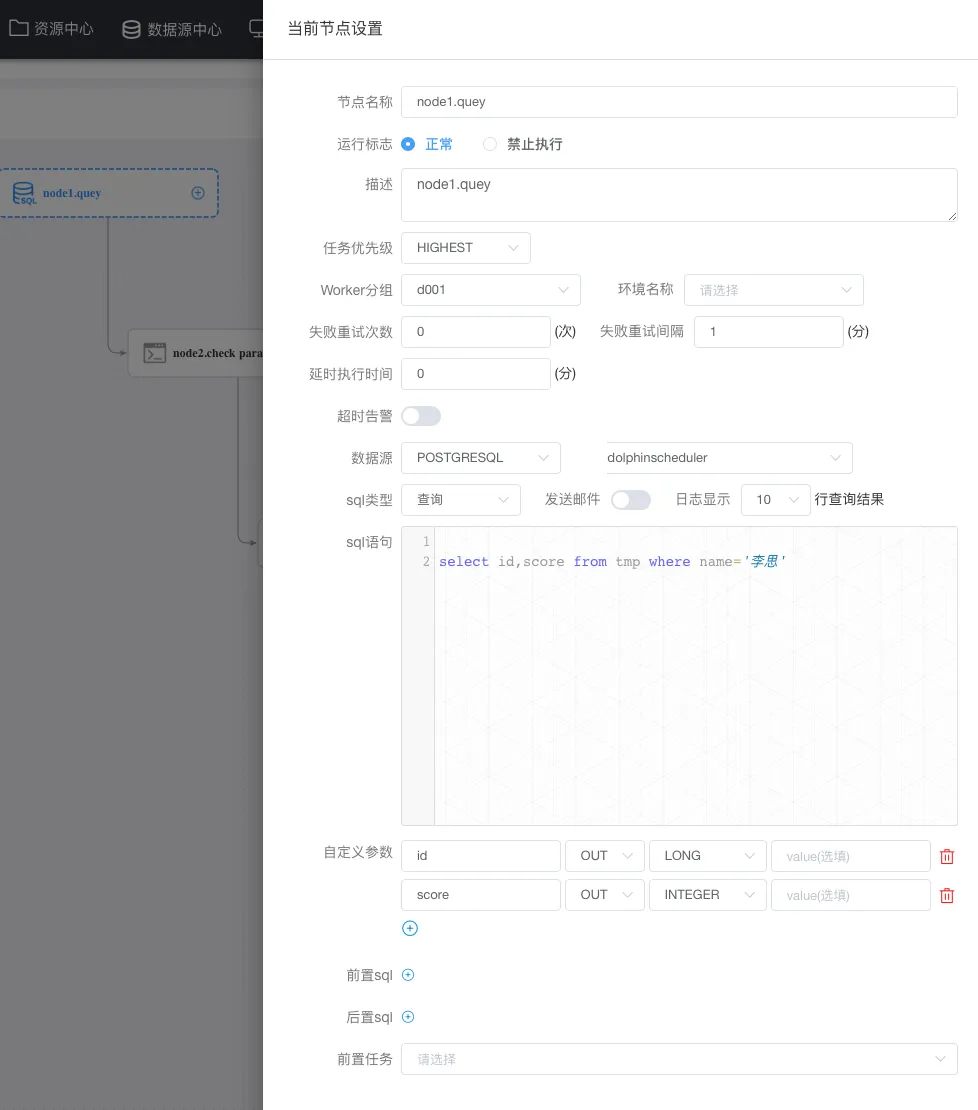
在工作流定義列表,點擊 創建工作流 就進入一個具體的任務(工作流)的定義,同時我們使用的是sql任務,需要從左側拖動一個sql任務到畫布中(右側空白處):
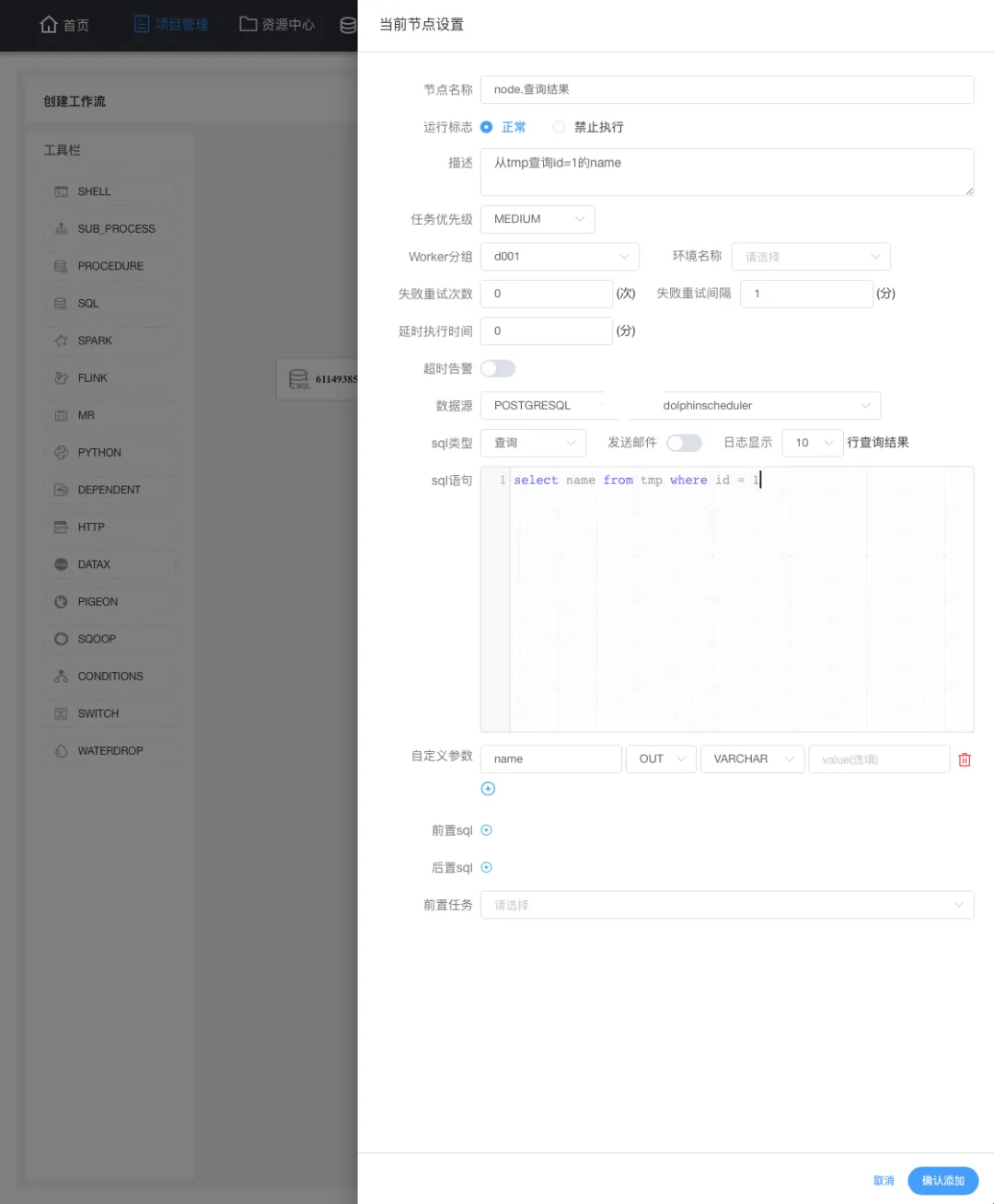
拖動 sql任務 到畫布會自動彈出節點定義,上圖為當前節點的一個定義,重點是:數據源、sql類型、sql語句,如官方所說,如果將 name 傳遞到下游,則需要在自定義參數重定義這個 name 為 out方向 類型為varchar。
02
因為傳遞到參數需要寫入到表,這裡我們再定義一個節點,這個節點負責接收上游傳遞到name,執行update 時使用這個 name ,以下是我的定義:
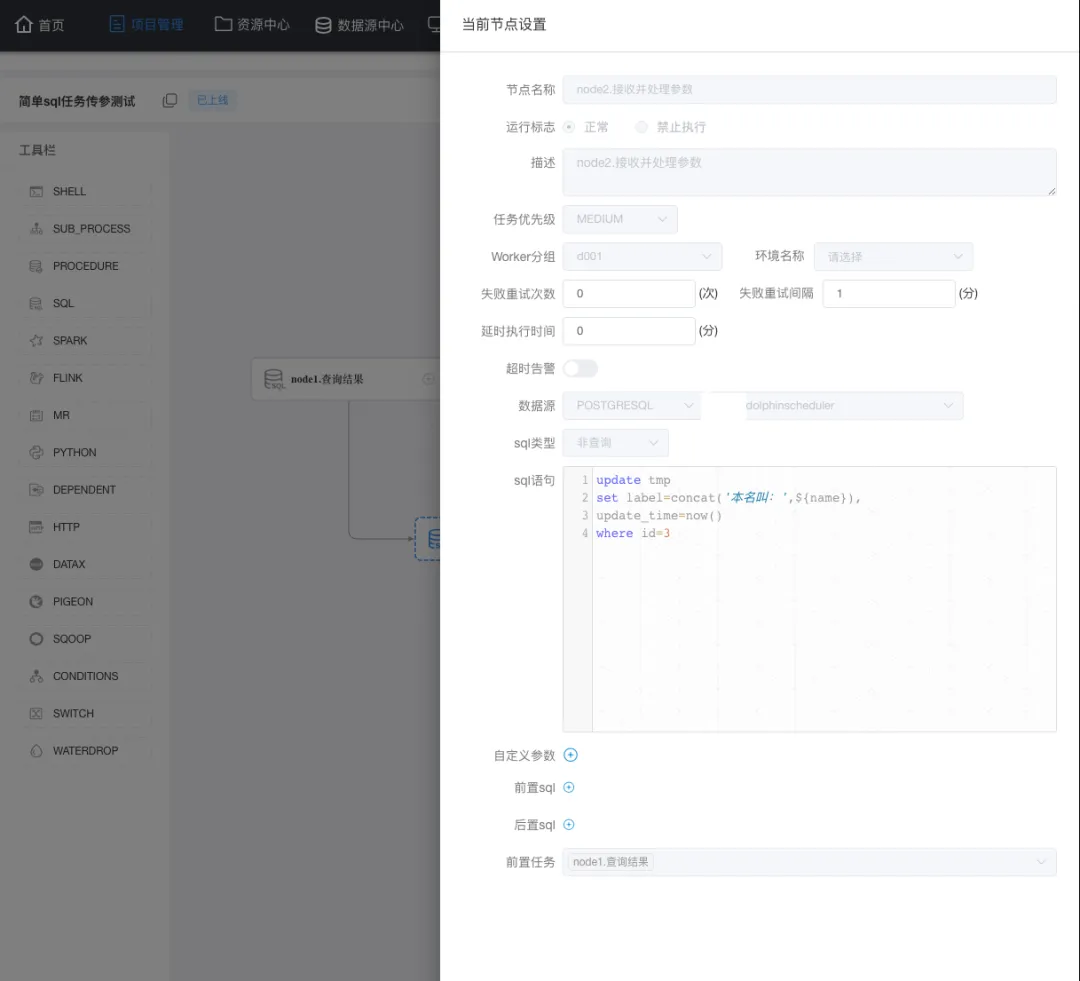
這裡不僅僅要注意 sql類型 (sql類型與sql語句是一一對應的,類型不能錯) ,還有就是前置任務一定要選中(上面定義的) node1節點。另外,需要注意的是當前任務是上下游傳參,所以在node2 中是直接使用 node1中定義的 name 這個參數。
03
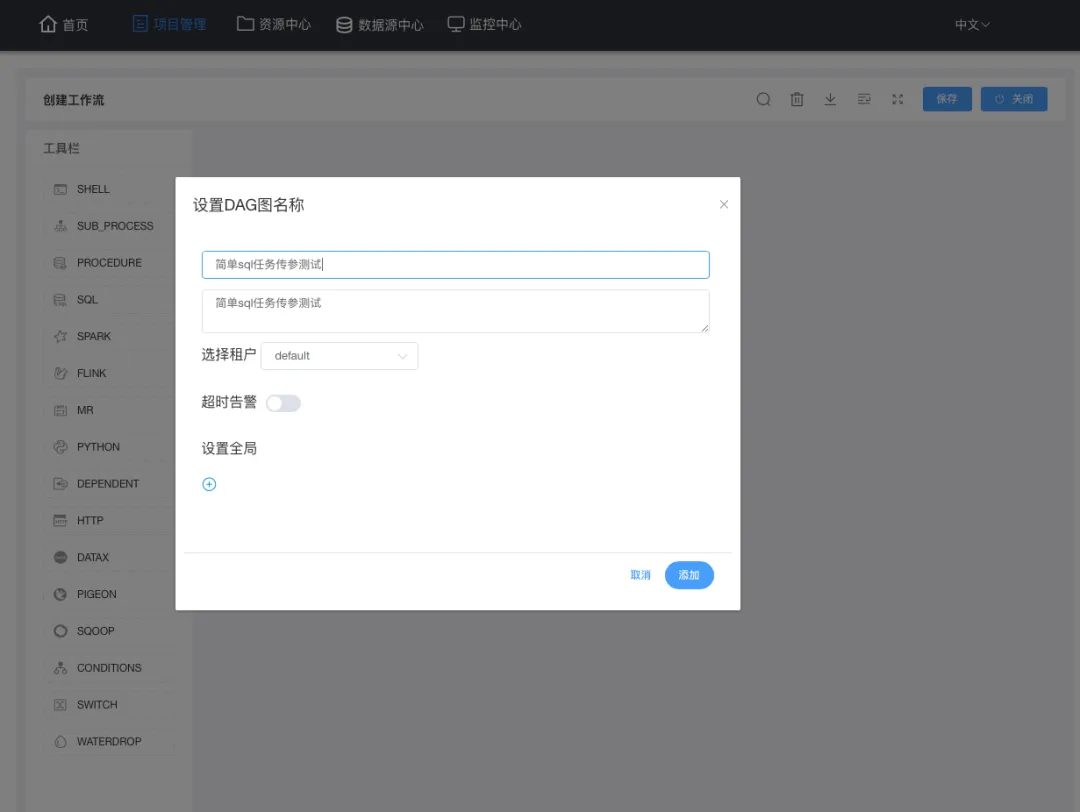
定義完成當前任務需要保存:點右上角保存,填寫並保存後點關閉以退出定義;
04
定義的任務需要上線了才可執行,所以在工作流定義列表先點該任務的黃色按鈕(任務上線),然後才是點綠色按鈕(執行任務):
05
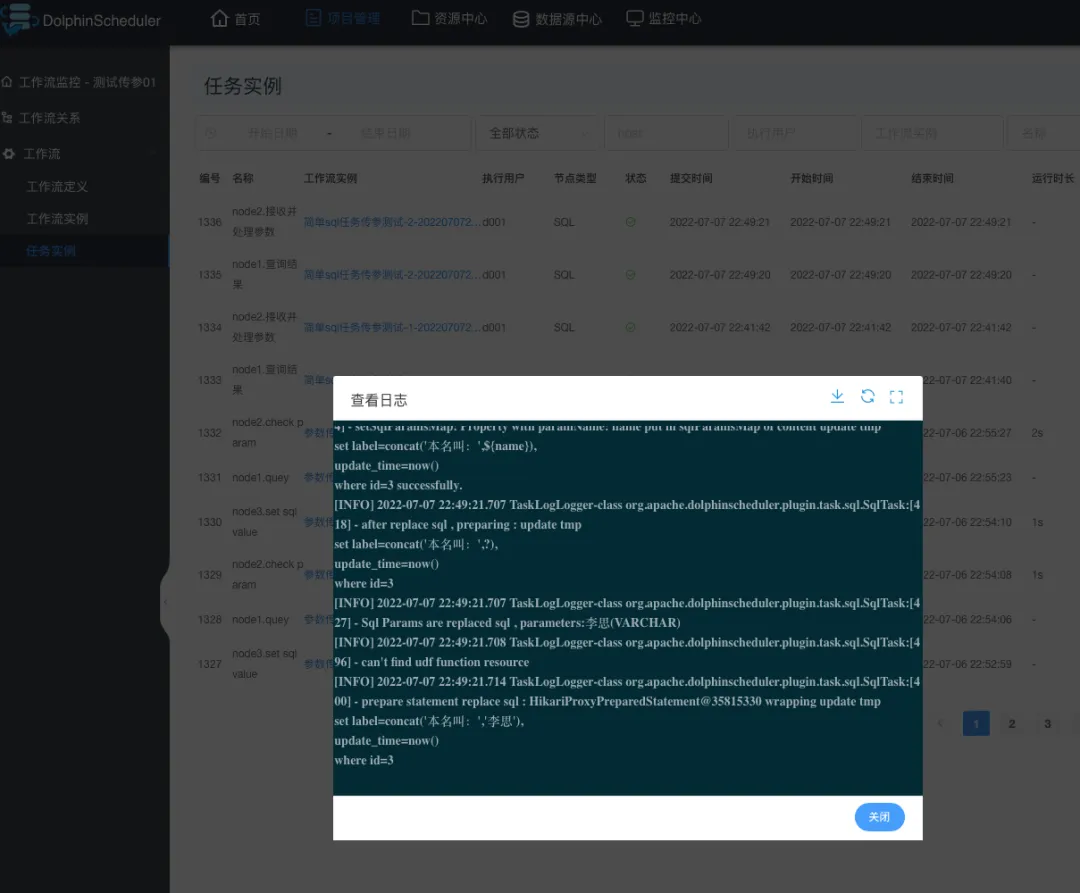
任務執行成功與否,具體得看任務實例,這是執行 node2節點 的日誌:
順帶再看看數據庫表是否真實成功:
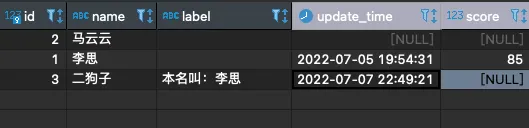
完美
複雜的跨節點傳參
首先看錶:
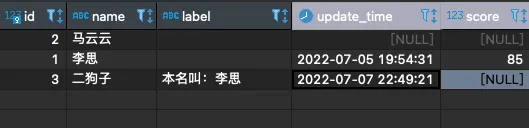
思考一個問題:可以看到李思的score是85,根據score應該被評為 B(>=90的為A)並寫入到 label字段,該怎麼辦呢?如果這個分數是90分又該怎麼辦呢?如果根本沒有score(分值) 這個任務是不是就不需要更新李思的label(評分)呢?
對於上面問題可以有一些偏門的解決方法,比如在sql中塞一個異常值,這樣看似不錯,不過作為調度工具建議還是在condition節點或者switch節點處理是最好的,目前我用的2.0.5版本對於這兩類任務節點是沒法接收參數的,這是一個遺憾;
個人覺得較好的方式是在寫入節點之前增加一個判斷節點,將錯誤拋出(沒有score的)最好~,對於此,我使用了一個shell的中間節點。
下面是我定義的三個節點:
node1節點定義:
node2節點定義:
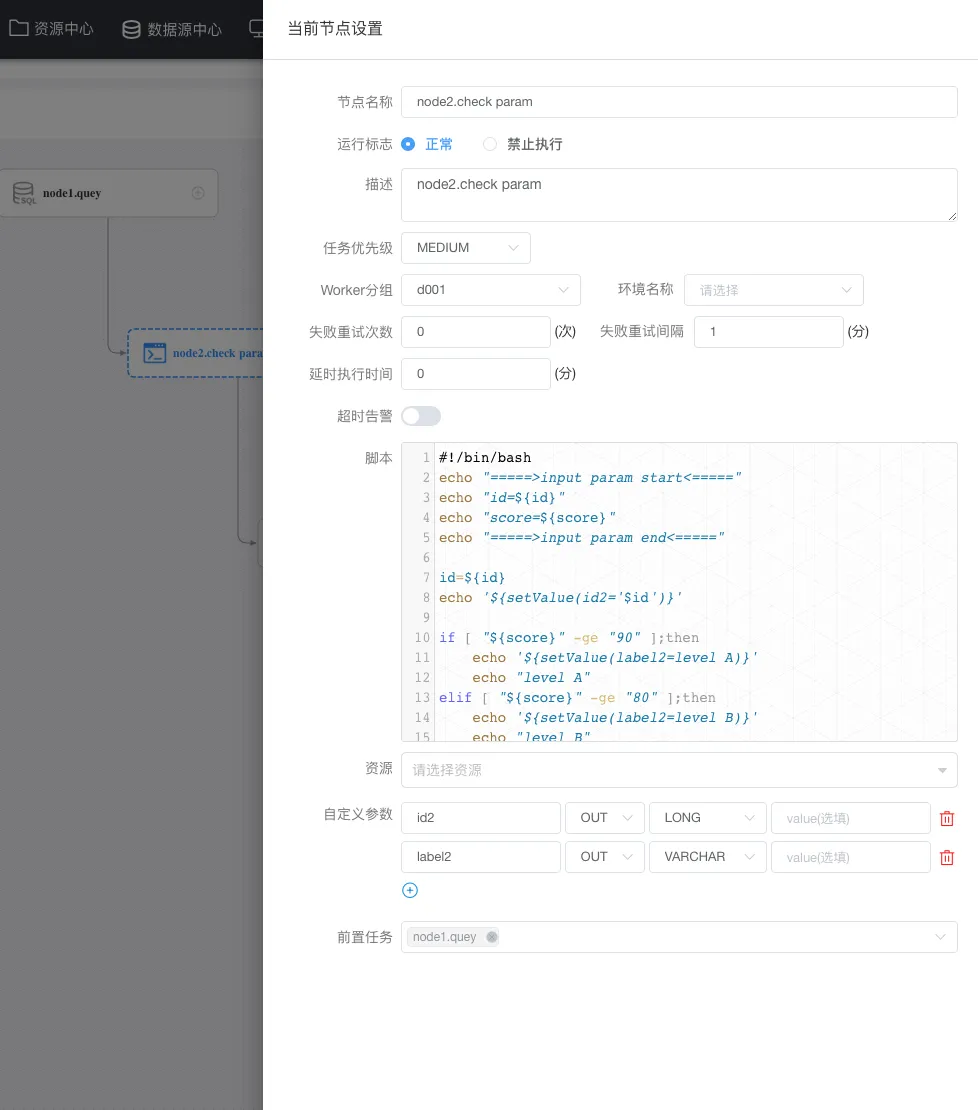
腳本內容
#!/bin/bash echo "=====>input param start<=====" echo "id=${id}" echo "score=${score}" echo "=====>input param end<=====" id=${id} echo '${setValue(id2='$id')}' if [ "${score}" -ge "90" ];then echo '${setValue(label2=level A)}' echo "level A" elif [ "${score}" -ge "80" ];then echo '${setValue(label2=level B)}' echo "level B" elif [ "${score}" -ge "60" ];then echo '${setValue(label2=level C)}' echo "level C" elif [ "${score}" -ge "0" ];then echo '${setValue(label2=F!)}' echo "F!" else echo "NO score ,please check!" exit 1 fi
node3節點定義:
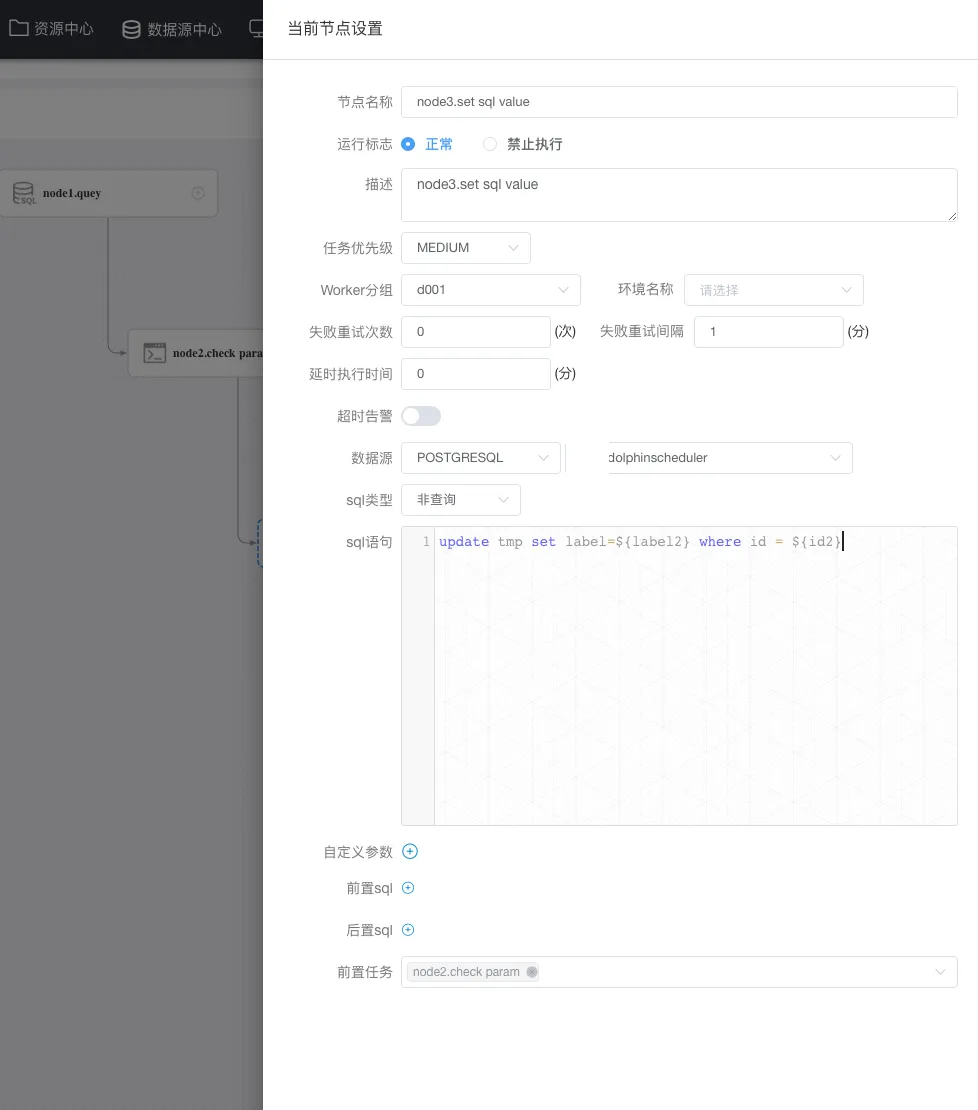
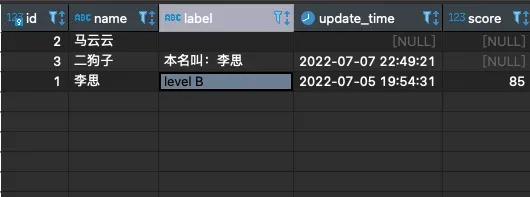
看一眼結果 :
:
小結
1、對於shell腳本不熟悉的,判斷節點其實還是有一些難度的,這是很重要的一點;
2、**node2(判斷節點)不能有重複的參數,不管局部的還是node1(上一級)**傳遞過來的,均不能重複;
3、因為在node2(判斷節點)需要將 id 以及 label 繼續往下傳(to node3),這時候就需要給 id 以及 label定義一個映射的out變量(id2、label2);
3、node2中重新設置參數麻煩,**需要在 shell 中重新定義變量(id2、label2),**同時需要在shell任務內使用拼接的方式賦值(如:echo ‘${setValue(id2=’$id’)}’);
4、sql類型以及不同節點下不同參數時常搞錯,不是任何節點都可以接收上級節點參數,以及局部變量與傳遞變量以及全局變量優先級區別及可能造成衝突;
5、DS列表傳參(2.0是不可以的)很雞肋,對於列表傳參又不能在下一級節點做循環賦值,這點對於DS是有改進的空間的;
DolphinScheduler還有很多可擴展的地方(因為實際需要),我還做了一些二次開發 ,後面會聊…大家期待喲
,後面會聊…大家期待喲
參與貢獻
隨着國內開源的迅猛崛起,Apache DolphinScheduler 社區迎來蓬勃發展,為了做更好用、易用的調度,真誠歡迎熱愛開源的夥伴加入到開源社區中來,為中國開源崛起獻上一份自己的力量,讓本土開源走向全球。
歡迎關注
參與 DolphinScheduler 社區有非常多的參與貢獻的方式,包括:
貢獻第一個PR(文檔、代碼) 我們也希望是簡單的,第一個PR用於熟悉提交的流程和社區協作以及感受社區的友好度。
社區匯總了以下適合新手的問題列表://github.com/apache/dolphinscheduler/issues/5689
非新手問題列表://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A”volunteer+wanted”
如何參與貢獻鏈接://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
來吧,DolphinScheduler開源社區需要您的參與,為中國開源崛起添磚加瓦吧,哪怕只是小小的一塊瓦,匯聚起來的力量也是巨大的。
參與開源可以近距離與各路高手切磋,迅速提升自己的技能,如果您想參與貢獻,我們有個貢獻者種子孵化群,可以添加社區Leonard-ds ,手把手教會您( 貢獻者不分水平高低,有問必答,關鍵是有一顆願意貢獻的心 )。
添加小助手時請說明想參與貢獻。
來吧,開源社區非常期待您的參與。
<  >
>
點亮 Star · 照亮開源之路
GitHub:[//github.com/apache/dolphinscheduler](//github.com/apache/dolphinscheduler)

Apache DolphinScheduler是一款非常不錯的調度工具,可單機可集群可容 器,可調度sql、存儲過程、http、大數據等,也可使用shell、python、java、flink等語言及工具,功能強大類型豐富,適合各類調度型任務,社區及項目也十分活躍,現在Github中已有8.5k的star
# 準備工作
閱讀本文前建議您先閱讀下官方的文檔
文檔鏈接:[//dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html](//dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html)
在這裡,先準備下sql表資源,以下為`postgresql`的`sql`腳本:
## 表結構
“`CREATE TABLE dolphinscheduler.tmp (
id int4 NOT NULL,
“name” varchar(50) NULL,
“label” varchar(50) NULL,
update_time timestamp NULL,
score int4 NULL,
CONSTRAINT tmp_pkey PRIMARY KEY (id) );
“`
## 表數據
“`INSERT INTO tmp (id,”name”,”label”,update_time,score) VALUES
(3,’二狗子’,”,’2022-07-06 21:49:26.872′,NULL),
(2,’馬云云’,”,NULL,NULL),
(1,’李思’,”,’2022-07-05 19:54:31.880′,85);
“`
我這裡使用的 postgresql 的數據庫,如果您是 mysql 或者其他數據的用戶,請自行更改以上表和數據並添加到庫中即可~
表及數據入庫,請將tmp所屬的庫配置到 DS後台->數據源中心->創建數據源 ,以下是我的配置,記住,這裏面的所有數據庫配置均遵守所屬數據庫類型的jdbc 的 driver 的配置參數,配置完成也會在DS的數據庫生成一條 jdbc 的連接地址,這點要明白~
# 簡單的項目創建及說明
因為DolphinScheduler的任務是配置在項目下面,所以第一步得新建一個項目,這樣:`DS後台`->`項目管理`->`創建項目`,這是我創建的請看下圖:

準備完項目之後,鼠標點進去,並進入到工作流定義菜單 頁面,如下圖:

## 簡單解釋下DS的基本結構
首先,DS一般部署在 linux 服務器下,創建任務的用戶需要在 admin賬戶 下創建,重要的是創建的每個工作賬戶需要與操作系統用戶一一對應.
比如你創建了一個 test 的DS賬戶,那所在的服務器也必須有一個test的賬戶才可行,這是DS的規則。
每個用戶下(除了admin外)所能創建的調度任務均在各自創建的項目下,每個項目又分為多個任務(工作流定義),一個任務下又可分為多個任務節點。
下圖為任務定義

ok,如果已經準備好以上步驟,下面開始繼續定義一個簡單的調度任務~
# 簡單的參數傳遞
先看錶:

如圖我們先做個簡單的:
如果二狗子的本名叫李思,需要取** id=1 **的 name 放到**id=3 **的 label 中,並且更新 update_time
### 01
在工作流定義列表,點擊 創建工作流 就進入一個具體的任務(工作流)的定義,同時我們使用的是sql任務,需要從左側拖動一個sql任務到畫布中(右側空白處):

拖動 sql任務 到畫布會自動彈出節點定義,上圖為當前節點的一個定義,重點是:數據源、sql類型、sql語句,如官方所說,如果將 name 傳遞到下游,則需要在自定義參數重定義這個 name 為 out方向 類型為varchar。
### 02
因為傳遞到參數需要寫入到表,這裡我們再定義一個節點,這個節點負責接收上游傳遞到name,執行update 時使用這個 name ,以下是我的定義:

這裡不僅僅要注意 sql類型 (sql類型與sql語句是一一對應的,類型不能錯) ,還有就是前置任務一定要選中(上面定義的) node1節點。另外,需要注意的是當前任務是上下游傳參,所以在node2 中是直接使用 node1中定義的 name 這個參數。
### 03
定義完成當前任務需要保存:點右上角保存,填寫並保存後點關閉以退出定義;

### 04
定義的任務需要上線了才可執行,所以在工作流定義列表先點該任務的黃色按鈕(任務上線),然後才是點綠色按鈕(執行任務):
### 05
任務執行成功與否,具體得看任務實例,這是執行 node2節點 的日誌:

順帶再看看數據庫表是否真實成功:

完美
# 複雜的跨節點傳參
首先看錶:

思考一個問題:可以看到李思的score是85,根據score應該被評為 B(>=90的為A)並寫入到 label字段,該怎麼辦呢?如果這個分數是90分又該怎麼辦呢?如果根本沒有score(分值) 這個任務是不是就不需要更新李思的label(評分)呢?
對於上面問題可以有一些偏門的解決方法,比如在sql中塞一個異常值,這樣看似不錯,不過作為調度工具建議還是在condition節點或者switch節點處理是最好的,目前我用的2.0.5版本對於這兩類任務節點是沒法接收參數的,這是一個遺憾;
個人覺得較好的方式是在寫入節點之前增加一個判斷節點,將錯誤拋出(沒有score的)最好~,對於此,我使用了一個shell的中間節點。
下面是我定義的三個節點:
node1節點定義:

node2節點定義:

**腳本內容**
“`#!/bin/bash echo “=====>input param start<=====” echo “id=${id}” echo “score=${score}” echo “=====>input param end<=====” id=${id} echo ‘${setValue(id2=’$id’)}’ if [ “${score}” -ge “90” ];then echo ‘${setValue(label2=level A)}’ echo “level A” elif [ “${score}” -ge “80” ];then echo ‘${setValue(label2=level B)}’ echo “level B” elif [ “${score}” -ge “60” ];then echo ‘${setValue(label2=level C)}’ echo “level C” elif [ “${score}” -ge “0” ];then echo ‘${setValue(label2=F!)}’ echo “F!” else echo “NO score ,please check!” exit 1 fi“`
node3節點定義:

看一眼結果:

# 小結
1、對於**shell腳本**不熟悉的,判斷節點其實還是有一些難度的,這是很重要的一點;
2、**node2(判斷節點)**不能有重複的參數,不管局部的還是**node1(上一級)**傳遞過來的,均不能重複;
3、因為在**node2(判斷節點)**需要將 id 以及 label 繼續往下傳**(to node3),**這時候就需要給 id 以及 label定義一個映射的**out變量(id2、label2);**
3、node2中重新設置參數麻煩,**需要在 shell 中重新定義變量(id2、label2),**同時需要在shell任務內使用拼接的方式賦值(如:echo ‘${setValue(id2=’$id’)}’);
4、**sql類型**以及不同節點下不同參數時常搞錯,不是任何節點都可以接收上級節點參數,以及局部變量與傳遞變量以及全局變量優先級區別及可能造成衝突;
5、DS列表傳參(2.0是不可以的)很雞肋,對於列表傳參又不能在下一級節點做循環賦值,這點對於DS是有改進的空間的;
DolphinScheduler還有很多可擴展的地方(因為實際需要),我還做了一些二次開發,後面會聊…大家期待喲
# 參與貢獻
隨着國內開源的迅猛崛起,Apache DolphinScheduler 社區迎來蓬勃發展,為了做更好用、易用的調度,真誠歡迎熱愛開源的夥伴加入到開源社區中來,為中國開源崛起獻上一份自己的力量,讓本土開源走向全球。
## 歡迎關注
參與 DolphinScheduler 社區有非常多的參與貢獻的方式,包括:
貢獻第一個PR(文檔、代碼) 我們也希望是簡單的,第一個PR用於熟悉提交的流程和社區協作以及感受社區的友好度。
社區匯總了以下適合新手的問題列表:[//github.com/apache/dolphinscheduler/issues/5689](//github.com/apache/dolphinscheduler/issues/5689)
非新手問題列表:[//github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A”volunteer+wanted”](//github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22)
如何參與貢獻鏈接:[//dolphinscheduler.apache.org/zh-cn/community/development/contribute.html](//dolphinscheduler.apache.org/zh-cn/community/development/contribute.html)
來吧,DolphinScheduler開源社區需要您的參與,為中國開源崛起添磚加瓦吧,哪怕只是小小的一塊瓦,匯聚起來的力量也是巨大的。
參與開源可以近距離與各路高手切磋,迅速提升自己的技能,如果您想參與貢獻,我們有個貢獻者種子孵化群,可以添加社區Leonard-ds ,手把手教會您( 貢獻者不分水平高低,有問必答,關鍵是有一顆願意貢獻的心 )。
添加小助手時請說明想參與貢獻。
**來吧,開源社區非常期待您的參與。**
< >