回歸與分類
回歸與分類
機器學習的主要任務便是聚焦於兩個問題:回歸與分類
回歸與分類
回歸的定義
- 機器學習的過程就是尋找函數的過程,通過訓練獲得一個函數映射,給定函數的輸入,函數會給出相應的一個輸出,若輸出結果是一個數值scalar時,即稱這一類機器學習問題為回歸問題
- 就如李宏毅老師所說:Regression就是找到一個函數function,通過輸入特徵x,輸出一個數值scalar
- 例如:房價數據,根據位置、周邊、配套等等這些維度,給出一個房價的預測
分類與回歸的區別
- 分類是基於數據集,作出分類選擇
- 分類與回歸區別在一輸出變量的類型
- 輸出是離散的就可以做分類問題,即通常多個輸出,輸出i是預測為第i類的置信度
- 輸出是連續的就可以做回歸問題 ,即單連續值輸出,跟真實值區別作為損失
模型步驟
- step1:模型假設,選擇模型框架(線性模型)
- step2:模型評估,如何判斷眾多模型的好壞(損失函數)
- step3:模型優化,如何篩選最優的模型(梯度下降)
一、線性模型
step1 模型假設
- 給定n維輸入 x = [x1,x2,….,xn]^T
- 線性模型有一個n維權重和一個標量偏差 即w與b
- 輸出是輸入的加權和 y = w1x1 + w2x2 + … +wnxn +b
- 向量版本 y = <w,x> + b
假設1:影響房價的關鍵因素是卧室個數,衛生間個數,和居住面積,記為x1,x2,x3
假設2:成交價是關鍵因素的加權和 則 y = w1x1 + w2x2 +w3x3 + b,
權重和偏置的實際值在後面決定
step2 模型評估(衡量預估質量)
- 收集和訓練數據
- 如何判斷眾多模型的好壞(根據損失函數判斷)
1.平方損失 y為真實值,y1為估計值(預測值)
$$
p(y,y1) = 1/2(y-y1)^2
$$
2.訓練損失
$$
p(X,y,w,b) = ∑(y[i] – (b + <w,x[i]>))^2
$$
step3 選取最優模型(梯度下降)
- 為了獲得最優模型故要使L(w,b)損失函數值最小化,而對於L(w,b)實質上就是w,b的函數,因此可以通過求偏微分來尋找其最小化損失點
最小化損失學習參數
$$
w* , b* = arg min(X,y,w,b)
$$
-
而對於梯度下降來講
-
1.首先要挑選一個初始值 w0,同時引入學習率(步長的超參數) η
-
2.重複迭代參數 t =1,2,3
-
3.沿梯度方向將增加損失函數值
$$
w[t] = w[t-1] -η*(∂L/∂w[t-1])
$$
註:上式中減號意思為沿着梯度反方向
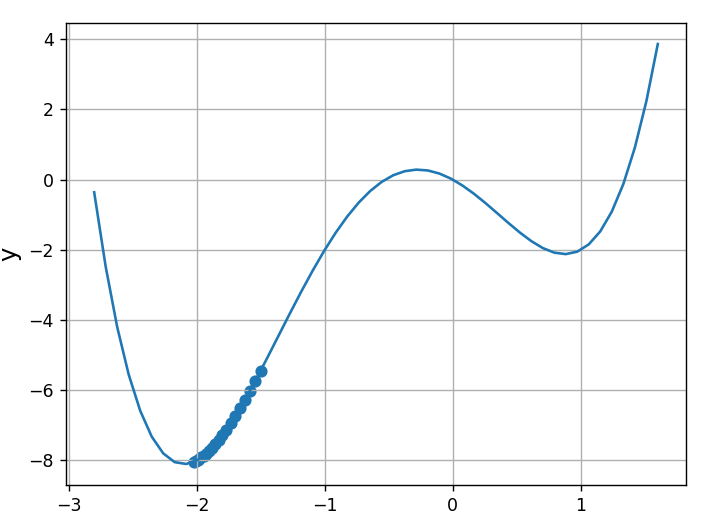
import numpy as np
import matplotlib.pyplot as plt
def my_func(x): #定義原函數
return x**4 + 2*x**3 - 3*x**2 -2*x
def grad_func(x): #定義導數
return 4*x**3 + 6*x**2 -6*x -2
eta = 0.09 #學習係數
x = -1.5 #定義自變量x起始值
record_x = [] #記錄x值
record_y = [] #記錄y值
for i in range(20): #將x循環20次
y = my_func(x)
record_x.append(x) #將記錄添加
record_y.append(y)
x -= eta*grad_func(x) #梯度下降法公式 學習係數*導數值
x_f = np.linspace(-2.8,1.6)
y_f = my_func(x_f)
plt.plot(x_f,y_f)
plt.scatter(record_x,record_y)
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.grid()
plt.show()
二、廣義線性模型(generalized linear model)
$$
y=g^-1 (w^Tx+b)
$$
上面式子即為廣義線性模型的一種表達,其中g(.)被稱為聯繫函數,同時要求單調可微。使用廣義線性模型可以實現強大的非線性函數映射功能(比如對數線性回歸,令g(.) = ln(.),此時模型預測值對應的是真實值標記在指數尺度上的變化)
那麼線性模型的輸出是一個實值,而分類任務的標記是離散值,怎麼把二者聯繫起來呢?
- 廣義線性模型已經給了我們答案,我們要做的是找到一個單調可微的聯繫函數,把二者聯繫起來
- 對於一個二分類任務,比較理想的函數是階躍函數(激活函數)
對數線性回歸(log-linear regression)
由於單位階躍函數不連續,所以不能直接用作聯繫函數。故思路轉換為如何在一定程度上近似單位階躍函數呢? 對數幾率函數正是我們所需常用的替代函數:sigmoid函數
- 對於分類任務,由於是離散的數據,可以通過廣義線性模型的非線性函數映射進行,簡單來說將其離散數據映射在相似函數之上,也就是激活函數
總結
那麼對於一整個回歸過程來說 首要要假設模型去進行預選,接着要進行模型的評估計算損失函數,最後一步則是對損失函數進行優化即梯度下降算法
將一整個回歸過程放在神經網絡中時 在正向傳播中,首先進行將數據值x進行輸入,其次通過權值和的計算以及激活函數得到輸出值,傳輸至第二層,層層往下,最後輸出值 根據輸出值與真實值之間的distance即為loss函數


