Synchronized鎖升級原理與過程深入剖析
Synchronized鎖升級原理與過程深入剖析
前言
在上篇文章深入學習Synchronized各種使用方法當中我們仔細介紹了在各種情況下該如何使用synchronized關鍵字。因為在我們寫的程序當中可能會經常使用到synchronized關鍵字,因此JVM對synchronized做出了很多優化,而在本篇文章當中我們將仔細介紹JVM對synchronized的各種優化的細節。
工具準備
在正式談synchronized的原理之前我們先談一下自旋鎖,因為在synchronized的優化當中自旋鎖發揮了很大的作用。而需要了解自旋鎖,我們首先需要了解什麼是原子性。
所謂原子性簡單說來就是一個一個操作要麼不做要麼全做,全做的意思就是在操作的過程當中不能夠被中斷,比如說對變量data進行加一操作,有以下三個步驟:
- 將
data從內存加載到寄存器。 - 將
data這個值加一。 - 將得到的結果寫回內存。
原子性就表示一個線程在進行加一操作的時候,不能夠被其他線程中斷,只有這個線程執行完這三個過程的時候其他線程才能夠操作數據data。
我們現在用代碼體驗一下,在Java當中我們可以使用AtomicInteger進行對整型數據的原子操作:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicDemo {
public static void main(String[] args) throws InterruptedException {
AtomicInteger data = new AtomicInteger();
data.set(0); // 將數據初始化位0
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1); // 對數據 data 進行原子加1操作
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1);// 對數據 data 進行原子加1操作
}
});
// 啟動兩個線程
t1.start();
t2.start();
// 等待兩個線程執行完成
t1.join();
t2.join();
// 打印最終的結果
System.out.println(data); // 200000
}
}
從上面的代碼分析可以知道,如果是一般的整型變量如果兩個線程同時進行操作的時候,最終的結果是會小於200000。
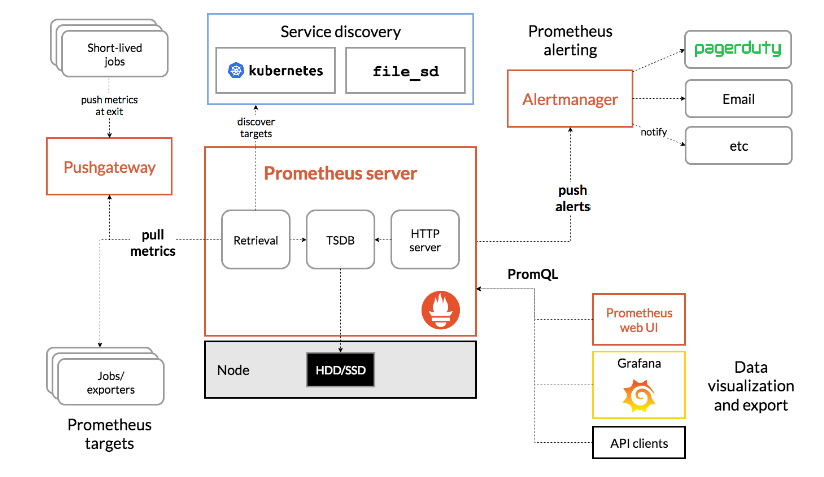
我們現在來模擬一下一般的整型變量出現問題的過程:
-
主內存
data的初始值等於0,兩個線程得到的data初始值都等於0。
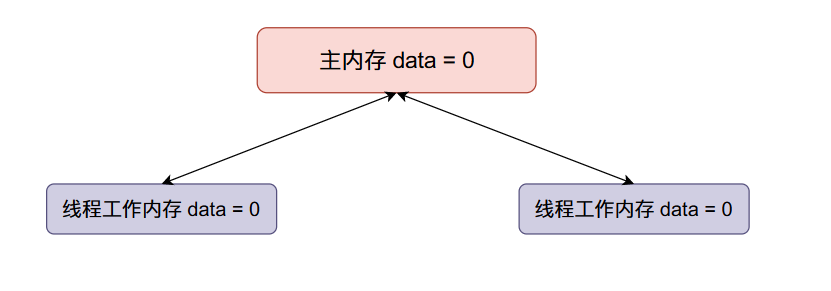
-
現在線程一將
data加一,然後線程一將data的值同步回主內存,整個內存的數據變化如下:
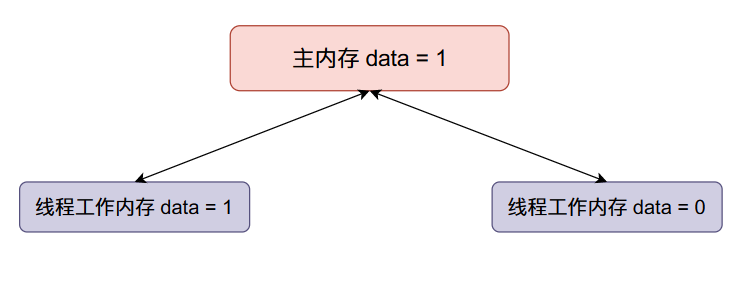
-
現在線程二
data加一,然後將data的值同步回主內存(將原來主內存的值覆蓋掉了):



我們本來希望data的值在經過上面的變化之後變成2,但是線程二覆蓋了我們的值,因此在多線程情況下,會使得我們最終的結果變小。
但是在上面的程序當中我們最終的輸出結果是等於20000的,這是因為給data進行+1的操作是原子的不可分的,在操作的過程當中其他線程是不能對data進行操作的。這就是原子性帶來的優勢。
事實上上面的+1原子操作就是通過自旋鎖實現的,我們可以看一下AtomicInteger的源代碼:
public final int addAndGet(int delta) {
// 在 AtomicInteger 內部有一個整型數據 value 用於存儲具體的數值的
// 這個 valueOffset 表示這個數據 value 在對象 this (也就是 AtomicInteger一個具體的對象)
// 當中的內存偏移地址
// delta 就是我們需要往 value 上加的值 在這裡我們加上的是 1
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
上面的代碼最終是調用UnSafe類的方法進行實現的,我們再看一下他的源代碼:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset); // 從對象 o 偏移地址為 offset 的位置取出數據 value ,也就是前面提到的存儲整型數據的變量
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
上面的代碼主要流程是不斷的從內存當中取對象內偏移地址為offset的數據,然後執行語句!compareAndSwapInt(o, offset, v, v + delta)
這條語句的主要作用是:比較對象o內存偏移地址為offset的數據是否等於v,如果等於v則將偏移地址為offset的數據設置為v + delta,如果這條語句執行成功返回 true否則返回false,這就是我們常說的Java當中的CAS。
看到這裡你應該就發現了當上面的那條語句執行不成功的話就會一直進行while循環操作,直到操作成功之後才退出while循環,假如沒有操作成功就會一直「旋」在這裡,像這種操作就是自旋,通過這種自旋方式所構成的鎖🔒就叫做自旋鎖。
對象的內存布局
在JVM當中,一個Java對象的內存主要有三塊:
- 對象頭,對象頭包含兩部分數據,分別是Mark word和類型指針(Kclass pointer)。
- 實例數據,就是我們在類當中定義的各種數據。
- 對齊填充,JVM在實現的時候要求每一個對象所佔有的內存大小都需要是8位元組的整數倍,如果一個對象的數據所佔有的內存大小不夠8位元組的整數倍,那就需要進行填充,補齊到8位元組,比如說如果一個對象站60位元組,那麼最終會填充到64位元組。
而與我們要談到的synchronized鎖升級原理密切相關的是Mark word,這個字段主要是存儲對象運行時的數據,比如說對象的Hashcode、GC的分代年齡、持有鎖的線程等等。而Kclass pointer主要是用於指向對象的類,主要是表示這個對象是屬於哪一個類,主要是尋找類的元數據。
在32位Java虛擬機當中Mark word有4個位元組一共32個比特位,其內容如下:

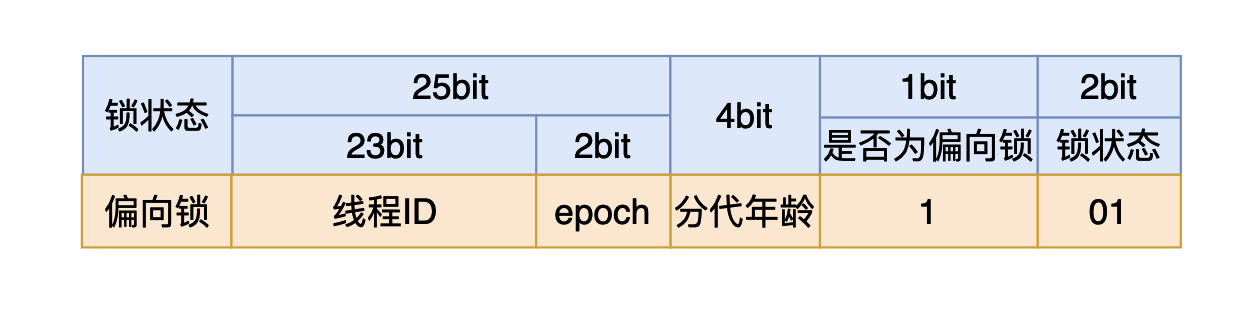
我們在使用synchronized時,如果我們是將synchronized用在同步代碼塊,我們需要一個鎖對象。對於這個鎖對象來說一開始還沒有線程執行到同步代碼塊時,這個4個位元組的內容如上圖所示,其中有25個比特用來存儲哈希值,4個比特用來存儲垃圾回收的分代年齡(如果不了解可以跳過),剩下三個比特其中第一個用來表示當前的鎖狀態是否為偏向鎖,最後的兩個比特表示當前的鎖是哪一種狀態:
- 如果最後三個比特是:001,則說明鎖狀態是沒有鎖。
- 如果最後三個比特是:101,則說明鎖狀態是偏向鎖。
- 如果最後兩個比特是:00, 則說明鎖狀態是輕量級鎖。
- 如果最後兩個比特是:10, 則說明鎖狀態是重量級鎖。
而synchronized鎖升級的順序是:無🔒->偏向🔒->輕量級🔒->重量級🔒。
在Java當中有一個JVM參數用於設置在JVM啟動多少秒之後開啟偏向鎖(JDK6之後默認開啟偏向鎖,JVM默認啟動4秒之後開啟對象偏向鎖,這個延遲時間叫做偏向延遲,你可以通過下面的參數進行控制):
//設置偏向延遲時間 只有經過這個時間只有對象鎖才會有偏向鎖這個狀態
-XX:BiasedLockingStartupDelay=4
//禁止偏向鎖
-XX:-UseBiasedLocking
//開啟偏向鎖
-XX:+UseBiasedLocking
我們可以用代碼驗證一下在無鎖狀態下,MarkWord的內容是什麼:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord {
public Object o = new Object();
public synchronized void demo() {
synchronized (o) {
System.out.println("synchronized代碼塊內");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
public static void main(String[] args) throws InterruptedException {
System.out.println("等待4s前");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
TimeUnit.SECONDS.sleep(4);
MarkWord markWord = new MarkWord();
System.out.println("等待4s後");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
}
}
上面代碼輸出結果,下面的紅框框住的表示是否是偏向鎖和鎖標誌位(可能你會有疑問為什麼是這個位置,不應該是最後3個比特位表示鎖相關的狀態嗎,這個其實是數據表示的大小端問題,大家感興趣可以去查一下,在這你只需知道紅框三個比特就是用於表示是否為偏向鎖和鎖的標誌位):
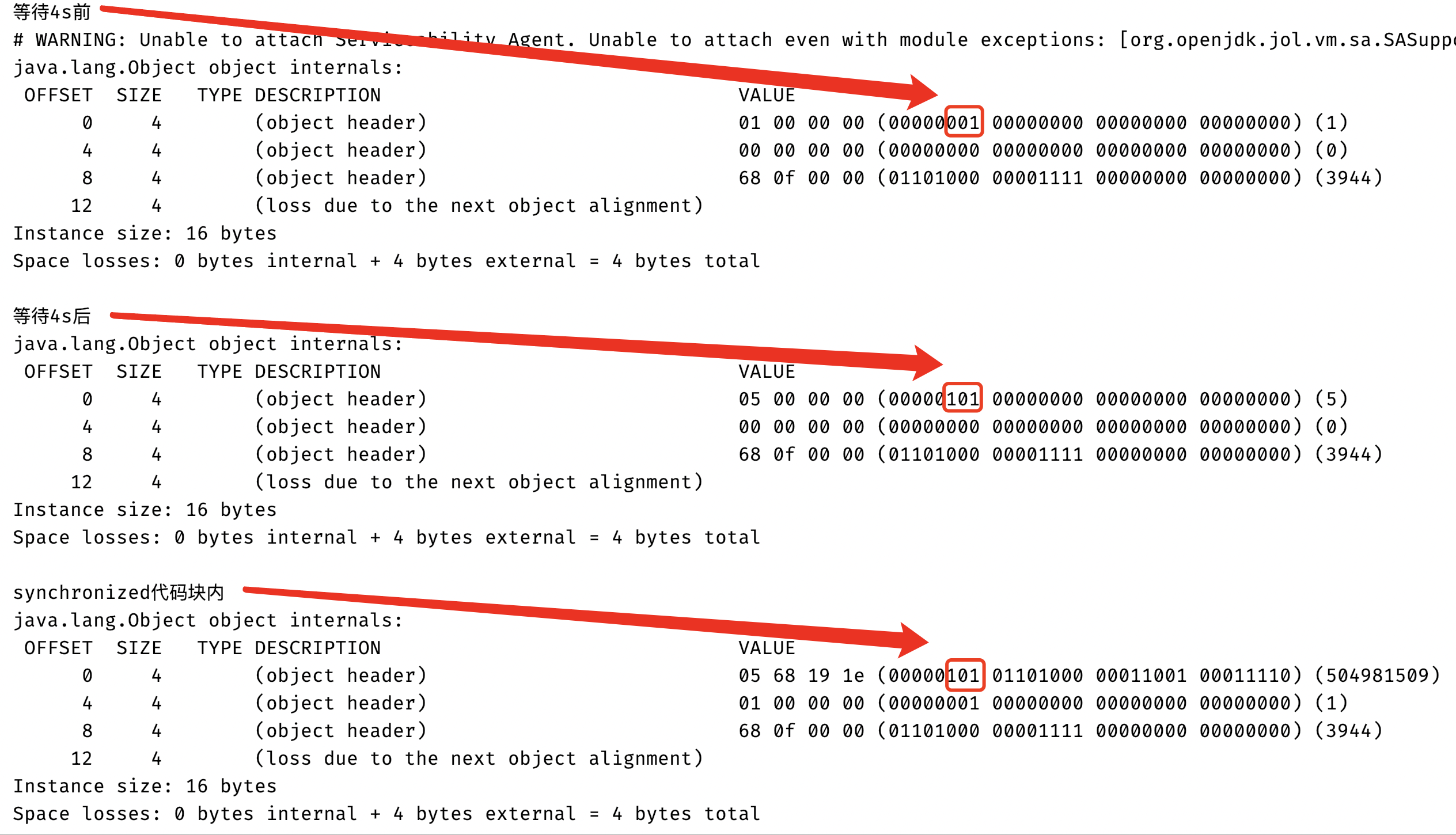
從上面的圖當中我們可以分析得知在偏向延遲的時間之前,對象鎖的狀態還不會有偏向鎖,因此對象頭中的Markword當中鎖狀態是01,同時偏向鎖狀態是0,表示這個時候是無鎖狀態,但是在4秒之後偏向鎖的狀態已經變成1了,因此當前的鎖狀態是偏向鎖,但是還沒有線程佔有他,這種狀態也被稱作匿名偏向,因為在上面的代碼當中只有一個線程進入了synchronized同步代碼塊,因此可以使用偏向鎖,因此在synchronized代碼塊當中打印的對象的鎖狀態也是偏向鎖。
上面的代碼當中使用到了jol包,你需要在你的pom文件當中引入對應的包:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
上圖當中我們顯示的結果是在64位機器下面顯示的結果,在64位機器當中在Java對象頭當中的MarkWord和Klcass Pointer內存布局如下:

其中MarkWord佔8個位元組,Kclass Pointer佔4個位元組。JVM在64位和32位機器上的MarkWord內容基本一致,64位機器上和32位機器上的MarkWord內容和表示意義是一樣的,因此最後三位的意義你可以參考32位JVM的MarkWord。
鎖升級過程
偏向鎖
假如你寫的synchronized代碼塊沒有多個線程執行,而只有一個線程執行的時候這種鎖對程序性能的提高還是非常大的。他的具體做法是JVM會將對象頭當中的第三個用於表示是否為偏向鎖的比特位設置為1,同時會使用CAS操作將線程的ID記錄到Mark Word當中,如果操作成功就相當於獲得🔒了,那麼下次這個線程想進入臨界區就只需要比較一下線程ID是否相同了,而不需要進行CAS或者加鎖這樣花費比較大的操作了,只需要進行一個簡單的比較即可,這種情況下加鎖的開銷非常小。
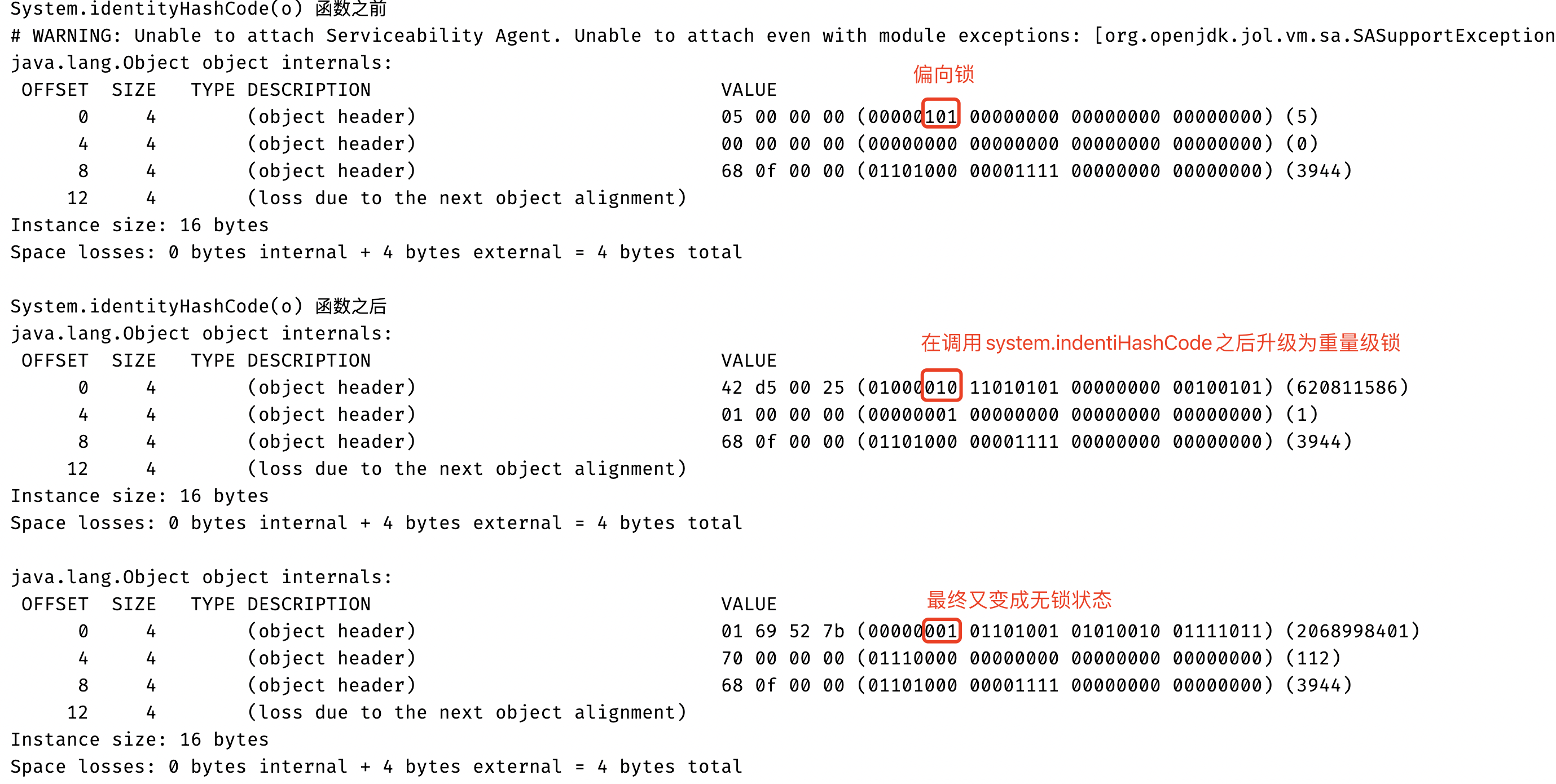
可能你會有一個疑問在無鎖的狀態下Mark Word存儲的是哈希值,而在偏向鎖的狀態下存儲的是線程的ID,那麼之前存儲的Hash Code不就沒有了嘛!你可能會想沒有就沒有吧,再算一遍不就行了!事實上不是這樣,如果我們計算過哈希值之後我們需要盡量保持哈希值不變(但是這個在Java當中並沒有強制,因為在Java當中可以重寫hashCode方法),因此在Java當中為了能夠保持哈希值的不變性就會在第一次計算一致性哈希值(Mark Word裏面存儲的是一致性哈希值,並不是指重寫的hashCode返回值,在Java當中可以通過 Object.hashCode()或者System.identityHashCode(Object)方法計算一致性哈希值)的時候就將計算出來的一致性哈希值存儲到Mark Word當中,下一次再有一致性哈希值的請求的時候就將存儲下來的一致性哈希值返回,這樣就可以保證每次計算的一致性哈希值相同。但是在變成偏向鎖的時候會使用線程ID覆蓋哈希值,因此當一個對象計算過一致性哈希值之後,他就再也不能進行偏向鎖狀態,而且當一個對象正處於偏向鎖狀態的時候,收到了一致性哈希值的請求的時候,也就是調用上面提到的兩個方法,偏向鎖就會立馬膨脹為重量級鎖,然後將Mark Word 儲在重量級鎖里。
下面的代碼就是驗證當在偏向鎖的狀態調用System.identityHashCode函數鎖的狀態就會升級為重量級鎖:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord {
public Object o = new Object();
public synchronized void demo() {
System.out.println("System.identityHashCode(o) 函數之前");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o) {
System.identityHashCode(o);
System.out.println("System.identityHashCode(o) 函數之後");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
public static void main(String[] args) throws InterruptedException {
TimeUnit.SECONDS.sleep(5);
MarkWord markWord = new MarkWord();
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
TimeUnit.SECONDS.sleep(2);
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
}
}
輕量級鎖
輕量級鎖也是在JDK1.6加入的,當一個線程獲取偏向鎖的時候,有另外的線程加入鎖的競爭時,這個時候就會從偏向鎖升級為輕量級鎖。
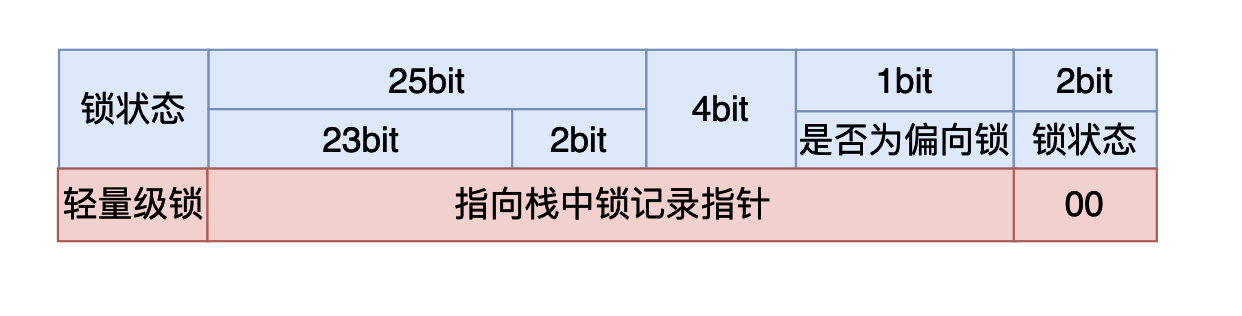
在輕量級鎖的狀態時,虛擬機首先會在當前線程的棧幀當中建立一個鎖記錄(Lock Record),用於存儲對象MarkWord的拷貝,官方稱這個為Displaced Mark Word。然後虛擬機會使用CAS操作嘗試將對象的MarkWord指向棧中的Lock Record,如果操作成功說明這個線程獲取到了鎖,能夠進入同步代碼塊執行,否則說明這個鎖對象已經被其他線程佔用了,線程就需要使用CAS不斷的進行獲取鎖的操作,當然你可能會有疑問,難道就讓線程一直死循環了嗎?這對CPU的花費那不是太大了嗎,確實是這樣的因此在CAS滿足一定條件的時候輕量級鎖就會升級為重量級鎖,具體過程在重量級鎖章節中分析。
當線程需要從同步代碼塊出來的時候,線程同樣的需要使用CAS將Displaced Mark Word替換回對象的MarkWord,如果替換成功,那麼同步過程就完成了,如果替換失敗就說明有其他線程嘗試獲取該鎖,而且鎖已經升級為重量級鎖,此前競爭鎖的線程已經被掛起,因此線程在釋放鎖的同時還需要將掛起的線程喚醒。
重量級鎖
所謂重量級鎖就是一種開銷最大的鎖機制,在這種情況下需要操作系統將沒有進入同步代碼塊的線程掛起,JVM(Linux操作系統下)底層是使用pthread_mutex_lock、pthread_mutex_unlock、pthread_cond_wait、pthread_cond_signal和pthread_cond_broadcast這幾個庫函數實現的,而這些函數依賴於futex系統調用,因此在使用重量級鎖的時候因為進行了系統調用,進程需要從用戶態轉為內核態將線程掛起,然後從內核態轉為用戶態,當解鎖的時候又需要從用戶態轉為內核態將線程喚醒,這一來二去的花費就比較大了(和CAS自旋鎖相比)。
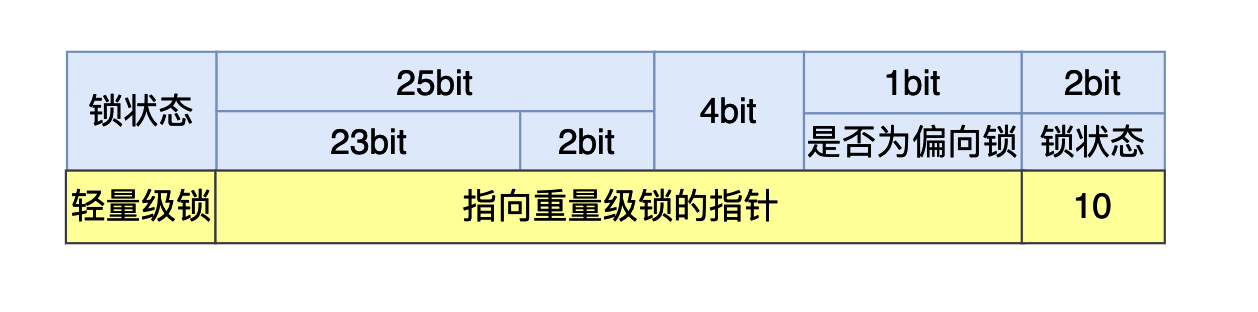
在有兩個以上的線程競爭同一個輕量級鎖的情況下,輕量級鎖不再有效(輕量級鎖升級的一個條件),這個時候鎖為膨脹成重量級鎖,鎖的標誌狀態變成10,MarkWord當中存儲的就是指向重量級鎖的指針,後面等待鎖的線程就會被掛起。
因為這個時候MarkWord當中存儲的已經是指向重量級鎖的指針,因此在輕量級鎖的情況下進入到同步代碼塊在出同步代碼塊的時候使用CAS將Displaced Mark Word替換回對象的MarkWord的時候就會替換失敗,在前文已經提到,在失敗的情況下,線程在釋放鎖的同時還需要將被掛起的線程喚醒。
總結
在本篇文章當中我們主要介紹了synchronized內部鎖升級的原理,具體的鎖升級的過程是:無🔒->偏向🔒->輕量級🔒->重量級🔒。
- 無鎖:這是沒有開啟偏向鎖的時候的狀態,在JDK1.6之後偏向鎖的默認開啟的,但是有一個偏向延遲,需要在JVM啟動之後的多少秒之後才能開啟,這個可以通過JVM參數進行設置,同時是否開啟偏向鎖也可以通過JVM參數設置。
- 偏向鎖:這個是在偏向鎖開啟之後的鎖的狀態,如果還沒有一個線程拿到這個鎖的話,這個狀態叫做匿名偏向,當一個線程拿到偏向鎖的時候,下次想要競爭鎖只需要拿線程ID跟MarkWord當中存儲的線程ID進行比較,如果線程ID相同則直接獲取鎖(相當於鎖偏向於這個線程),不需要進行CAS操作和將線程掛起的操作。
- 輕量級鎖:在這個狀態下線程主要是通過CAS操作實現的。將對象的MarkWord存儲到線程的虛擬機棧上,然後通過CAS將對象的MarkWord的內容設置為指向Displaced Mark Word的指針,如果設置成功則獲取鎖。在線程出臨界區的時候,也需要使用CAS,如果使用CAS替換成功則同步成功,如果失敗表示有其他線程在獲取鎖,那麼就需要在釋放鎖之後將被掛起的線程喚醒。
- 重量級鎖:當有兩個以上的線程獲取鎖的時候輕量級鎖就會升級為重量級鎖,因為CAS如果沒有成功的話始終都在自旋,進行while循環操作,這是非常消耗CPU的,但是在升級為重量級鎖之後,線程會被操作系統調度然後掛起,這可以節約CPU資源。
以上就是本篇文章的所有內容了,我是LeHung,我們下期再見!!!更多精彩內容合集可訪問項目://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,了解更多計算機(Java、Python、計算機系統基礎、算法與數據結構)知識。