流行於機器學習競賽的Boosting,這篇文章講的非常全了
- 2020 年 2 月 24 日
- 筆記

作者 | AISHWARYA SINGH
譯者 | 武明利,責編 | Carol
出品 | AI科技大本營(ID:rgznai100)
你能說出至少兩種機器學習中的 Boosting 嗎?
Boosting 已經存在了很多年,然而直到最近它們才成為機器學習社區的主流。那麼,為什麼這些 Boosting 如此流行呢?
Boosting 的流行的主要原因之一是機器學習競賽。Boosting 為機器學習模型賦予超能力來提高其預測準確性。快速瀏覽一下Kaggle競賽和DataHack黑客馬拉松就知道了—— Boosting 非常受歡迎!
簡而言之,Boosting 通常要比邏輯回歸和決策樹之類的簡單模型優越。實際上,DataHack平台上的大多數頂級產品都是使用一種 Boosting 或多種 Boosting 組合實現的。
在本文中,作者將介紹四種流行的 Boosting ,你可以在下一個機器學習黑客馬拉松或項目中使用它們。

Boosting快速入門(什麼是Boosting?)
想像一下這種場景:
你已經建立了線性回歸模型,該模型可以使驗證數據集的準確性達到77%。接下來,你決定通過在同一數據集上建立k近鄰算法(KNN)模型和決策樹模型來擴展你的數據集。這些模型在驗證集上的準確率分別為62%和89%。
顯然,這三個模型的工作方式完全不同。例如,線性回歸模型嘗試捕獲數據中的線性關係,而決策樹模型嘗試捕獲數據中的非線性。
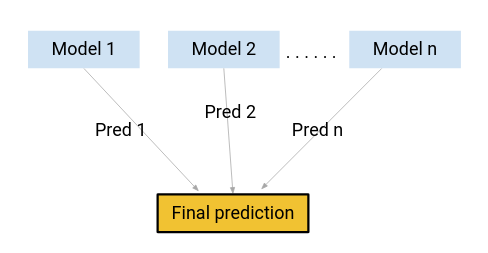
使用這些所有模型的組合而不是使用這些模型中的任何一個做出最終的預測怎麼樣?
我正在考慮這些模型的平均預測。這樣,我們將能從數據中捕獲更多信息。
這主要是集成學習背後的想法。 那麼 Boosting 出現在哪裡呢?
Boosting 是使用集成學習概念的技術之一。 Boosting 結合了多個簡單模型(也稱為弱學習者或基本估計量)來生成最終輸出。
我們將在本文中介紹一些重要的 Boosting 。

機器學習中的4種 Boosting
- 梯度提升機(GBM)
- 極端梯度提升機(XGBM)
- 輕量梯度提升機(LightGBM)
- 分類提升(CatBoost)
1、梯度提升機(GBM)
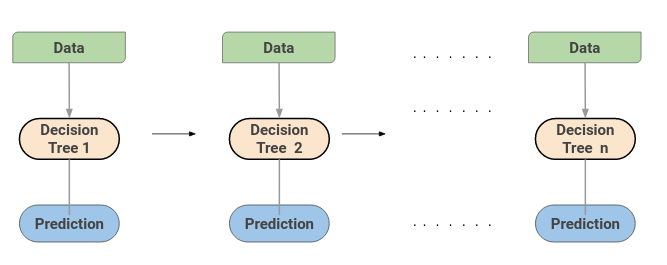
梯度提升機(GBM)結合了來自多個決策樹的預測來生成最終預測。注意,梯度提升機中的所有弱學習者都是決策樹。
但是,如果我們使用相同的算法,那麼使用一百個決策樹比使用單個決策樹好嗎?不同的決策樹如何從數據中捕獲不同的信號/信息呢?
這就是竅門––每個決策樹中的節點採用不同的功能子集來選擇最佳拆分。這意味着各個樹並不完全相同,因此它們能夠從數據中捕獲不同的信號。
另外,每棵新樹都考慮到先前樹所犯的錯誤。因此,每個連續的決策樹都是基於先前樹的錯誤。這就是按順序構建梯度 Boosting 中樹的方式。
2、極端梯度提升機(XGBM)
極端梯度提升機(XGBoost)是另一種流行的 Boosting 。實際上,XGBoost只是GBM算法的改進版!XGBoost的工作過程與GBM相同。XGBoost中的樹是按順序構建的嘗試用於更正先前樹的錯誤。
但是, XGBoost某些功能稍微優於GBM:
1)最重要的一點是XGBM實現了並行預處理(在節點級別),這使其比GBM更快。
2)XGBoost還包括各種正則化技術,可減少過度擬合併改善整體表現。你可以通過設置XGBoost算法的超參數來選擇正則化技術。
此外,如果使用的是XGBM算法,則不必擔心會在數據集中插入缺失值。XGBM模型可以自行處理缺失值。在訓練過程中,模型將學習缺失值是在右節點還是左節點中。
3、輕量梯度提升機(LightGBM)
由於其速度和效率,LightGBM Boosting 如今變得越來越流行。LightGBM能夠輕鬆處理大量數據。但是請注意,該算法在少數數據點上的性能不佳。
讓我們花點時間來了解為什麼會出現這種情況。
LightGBM中的樹具有葉向生長的,而不是水平生長的。在第一次分割之後,下一次分割僅在損失較大的葉節點上進行。
考慮下圖所示的示例:

第一次分割後,左側節點的損耗較高,因此被選擇用於下一個分割。現在,我們有三個葉節點,而中間葉節點的損耗最高。LightGBM算法的按葉分割使它能夠處理大型數據集。
為了加快訓練過程,LightGBM使用基於直方圖的方法來選擇最佳分割。對於任何連續變量而不是使用各個值,這些變量將被分成倉或桶。這樣訓練過程更快,並降低了內存開銷。
4、分類提升算法(CatBoost)
顧名思義,CatBoost是一種處理數據中的分類變量的 Boosting 。大多數機器學習算法無法處理數據中的字符串或類別。因此,將分類變量轉換為數值是一個重要的預處理步驟。
CatBoost可以在內部處理數據中的分類變量。使用有關特徵組合的各種統計信息,將這些變量轉換為數值變量。
如果你想了解如何將這些類別轉換為數字,請閱讀以下文章:
https://catboost.ai/docs/concepts/algorithm-main-stages_cat-to-numberic.html#algorithm-main-stages_cat-to-numberic)
CatBoost被廣泛使用的另一個原因是,它可以很好地處理默認的超參數集。因此,作為用戶,我們不必花費大量時間來調整超參數。

結論
在本文中,我們介紹了集成學習的基礎知識,並研究了4種 Boosting 。有興趣學習其他集成學習方法嗎?你應該查看以下文章:
綜合學習綜合指南(附Python代碼):
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/?utm_source=blog&utm_medium=4-boosting-algorithms-machine-learning
你還使用過其他哪些 Boosting ?你使用這些 Boosting 取得了成功嗎?歡迎在下面的評論中與我們分享你的想法和經驗。
原文:
4 Boosting Algorithms You Should Know – GBM, XGBoost, LightGBM & CatBoost
(*本文由AI科技大本營翻譯,轉載請微信聯繫1092722531)
【end】
◆


