Java面試題(六)–Redis
1 Redis基礎篇
1、簡單介紹一下Redis優點和缺點?
優點:
1、本質上是一個 Key-Value 類型的內存數據庫,很像memcached
2、整個數據庫統統加載在內存當中進行操作,定期通過異步操作把數據庫數據 flush 到硬盤上進行保存
3、因為是純內存操作,Redis 的性能非常出色,每秒可以處理超過 10 萬次讀寫操作,是已知性能最快的Key-Value DB
4、Redis最大的魅力是支持保存多種數據結構(string,list,set,hash,sortedset),此外單個 value 的最大限制是 1GB,不像memcached只能保存 1MB 的數據
5、Redis也可以對存入的 Key-Value 設置 expire 時間,因此也可以被當作一個功能加強版的memcached 來用
缺點:
1、Redis 的主要缺點是數據庫容量受到物理內存的限制,不能用作海量數據的高性能讀寫,因此 Redis 適合的場景主要局限在較小數據量的高性能操作和運算上。
2、沒有豐富的搜索功能
2、系統中為什麼要使用緩存?
主要從「高性能」和「高並發」這兩點來看待這個問題。
高性能:
假如用戶第一次訪問數據庫中的某些數據。這個過程會比較慢,因為是從硬盤上讀取的。將該用戶訪問的數據存在數緩存中,這樣下一次再訪問這些數據的時候就可以直接從緩存中獲取了。操作緩存就是直接操作內存,所以速度相當快。如果數據庫中的對應數據改變的之後,同步改變緩存中相應的數據即可!
高並發:
直接操作緩存能夠承受的請求是遠遠大於直接訪問數據庫的,所以我們可以考慮把數據庫中的部分數據轉移到緩存中去,這樣用戶的一部分請求會直接到緩存這裡而不用經過數據庫。
3、常見的緩存同步方案都有哪些?(高頻)
同步方案:更改代碼業務代碼,加入同步操作緩存邏輯的代碼(數據庫操作完畢以後,同步操作緩存)
異步方案:
1、使用消息隊列進行緩存同步:更改代碼加入異步操作緩存的邏輯代碼(數據庫操作完畢以後,將要同步的數據發送到MQ中,MQ的消費者從MQ中獲取數據,然後更新緩存)
2、使用阿里巴巴旗下的canal組件實現數據同步:不需要更改業務代碼,部署一個canal服務。canal服務把自己偽裝成mysql的一個從節點,當mysql數據更新以後,canal會讀取binlog數據,然後在通過canal的客戶端獲取到數據,更新緩存即可。
4、Redis常見數據結構以及使用場景有哪些?(高頻)
1、 string
常見命令:set、get、decr、incr、mget等。
基本特點:string數據結構是簡單的key-value類型,value其實不僅可以是String,也可以是數字。
應用場景:常規計數:微博數,粉絲數等。
2、hash
常用命令: hget、hset、hgetall等。
基本特點:hash 是一個 string 類型的 field 和 value 的映射表,hash 特別適合用於存儲對象,後續操作的時候,你可以直接僅僅修改這個對象中的某個字段的值。
應用場景:存儲用戶信息,商品信息等。
3、list
常用命令: lpush、rpush、lpop、rpop、lrange等。
基本特點:類似於Java中的list可以存儲多個數據,並且數據可以重複,而且數據是有序的。
應用場景:存儲微博的關注列表,粉絲列表等。
4、set
常用命令: sadd、spop、smembers、sunion 等
基本特點:類似於Java中的set集合可以存儲多個數據,數據不可以重複,使用set集合不可以保證數據的有序性。
應用場景:可以利用Redis的集合計算功能,實現微博系統中的共同粉絲、公告關注的用戶列表計算。
5、sorted set
常用命令: zadd、zrange、zrem、zcard 等。
基本特點:和set相比,sorted set增加了一個權重參數score,使得集合中的元素能夠按score進行有序排列。
應用場景:在直播系統中,實時排行信息包含直播間在線用戶列表,各種禮物排行榜等。
5、Redis有哪些數據刪除策略?(高頻)
數據刪除策略:Redis中可以對數據設置數據的有效時間,數據的有效時間到了以後,就需要將數據從內存中刪除掉。而刪除的時候就需要按照指定的規則進行刪除,這種刪除規則就被稱之為數據的刪除策略。
Redis中數據的刪除策略:
① 定時刪除
-
概述:在設置某個key 的過期時間同時,我們創建一個定時器,讓定時器在該過期時間到來時,立即執行對其進行刪除的操作。
-
優點:定時刪除對內存是最友好的,能夠保存內存的key一旦過期就能立即從內存中刪除。
-
缺點:對CPU最不友好,在過期鍵比較多的時候,刪除過期鍵會佔用一部分CPU時間,對服務器的響應時間和吞吐量造成影響。
② 惰性刪除
-
概述:設置該key過期時間後,我們不去管它,當需要該key時,我們在檢查其是否過期,如果過期,我們就刪掉它,反之返回該key。
-
優點:對CPU友好,我們只會在使用該鍵時才會進行過期檢查,對於很多用不到的key不用浪費時間進行過期檢查。
-
缺點:對內存不友好,如果一個鍵已經過期,但是一直沒有使用,那麼該鍵就會一直存在內存中,如果數據庫中有很多這種使用不到的過期鍵,這些鍵便永遠不會被刪除,內存永遠不會釋放。
③ 定期刪除
-
概述:每隔一段時間,我們就對一些key進行檢查,刪除裏面過期的key(從一定數量的數據庫中取出一定數量的隨機鍵進行檢查,並刪除其中的過期鍵)。
-
優點:可以通過限制刪除操作執行的時長和頻率來減少刪除操作對 CPU 的影響。另外定期刪除,也能有效釋放過期鍵佔用的內存。
-
缺點:難以確定刪除操作執行的時長和頻率。
如果執行的太頻繁,定期刪除策略變得和定時刪除策略一樣,對CPU不友好。如果執行的太少,那又和惰性刪除一樣了,過期鍵佔用的內存不會及時得到釋放。
另外最重要的是,在獲取某個鍵時,如果某個鍵的過期時間已經到了,但是還沒執行定期刪除,那麼就會返回這個鍵的值,這是業務不能忍受的錯誤。
Redis的過期刪除策略:惰性刪除 + 定期刪除兩種策略進行配合使用定期刪除函數的運行頻率,在Redis2.6版本中,規定每秒運行10次,大概100ms運行一次。在Redis2.8版本後,可以通過修改配置文件redis.conf 的 hz 選項來調整這個次數。
6、Redis中有哪些數據淘汰策略?(高頻)
數據的淘汰策略:當Redis中的內存不夠用時,此時在向Redis中添加新的key,那麼Redis就會按照某一種規則將內存中的數據刪除掉,這種數據的刪除規則被稱之為內存的淘汰策略。
常見的數據淘汰策略:
noeviction # 不刪除任何數據,內存不足直接報錯(默認策略)
volatile-lru # 挑選最近最久使用的數據淘汰(舉例:key1是在3s之前訪問的, key2是在9s之前訪問的,刪除的就是key2)
volatile-lfu # 挑選最近最少使用數據淘汰 (舉例:key1最近5s訪問了4次, key2最近5s訪問了9次, 刪除的就是key1)
volatile-ttl # 挑選將要過期的數據淘汰
volatile-random # 任意選擇數據淘汰
allkeys-lru # 挑選最近最少使用的數據淘汰
allkeys-lfu # 挑選最近使用次數最少的數據淘汰
allkeys-random # 任意選擇數據淘汰,相當於隨機
注意:
1、不帶allkeys字樣的淘汰策略是隨機從Redis中選擇指定的數量的key然後按照對應的淘汰策略進行刪除,帶allkeys是對所有的key按照對應的淘汰策略進行刪除。
2、緩存淘汰策略常見配置項
maxmemory-policy noeviction # 配置淘汰策略
maxmemory ?mb # 最大可使用內存,即佔用物理內存的比例,默認值為0,表示不限制。生產環境中根據需求設定,通常設置在50%以上。
maxmemory-samples count # 設置redis需要檢查key的個數
7、Redis中數據庫默認是多少個db即作用?
Redis默認支持16個數據庫,可以通過配置databases來修改這一數字。客戶端與Redis建立連接後會自動選擇0號數據庫,不過可以隨時使用select命令更換數據庫。
Redis支持多個數據庫,並且每個數據庫是隔離的不能共享,並且基於單機才有,如果是集群就沒有數據庫的概念。
8、緩存穿透、緩存擊穿、緩存雪崩解決方案?(高頻)
加入緩存以後的數據查詢流程:
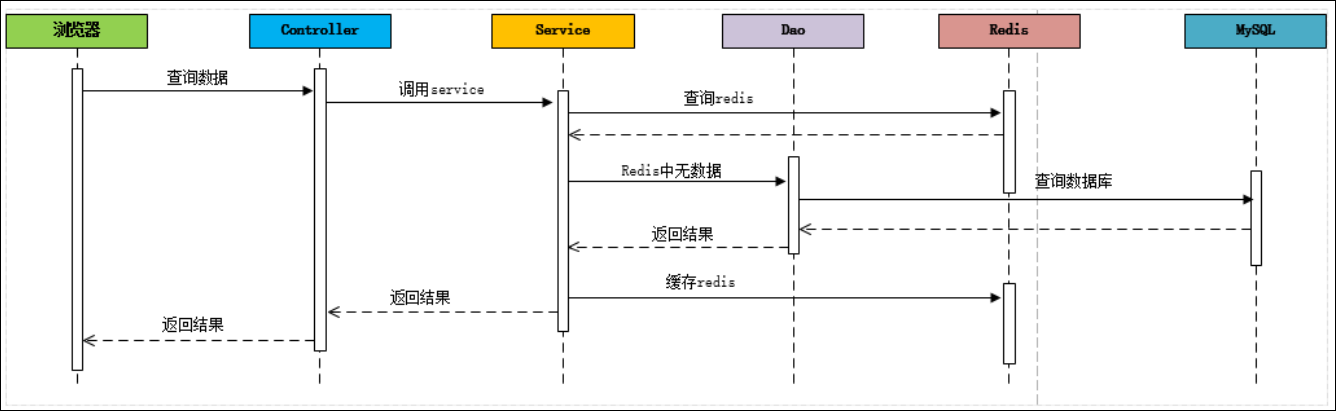
緩存穿透:
概述:指查詢一個一定不存在的數據,如果從存儲層查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到 DB 去查詢,可能導致 DB 掛掉。
解決方案:
1、查詢返回的數據為空,仍把這個空結果進行緩存,但過期時間會比較短
2、布隆過濾器:將所有可能存在的數據哈希到一個足夠大的 bitmap 中,一個一定不存在的數據會被這個 bitmap 攔截掉,從而避免了對DB的查詢
緩存擊穿:
概述:對於設置了過期時間的key,緩存在某個時間點過期的時候,恰好這時間點對這個Key有大量的並發請求過來,這些請求發現緩存過期一般都會從後端 DB 加載數據並回設到緩存,這個時候大並發的請求可能會瞬間把 DB 壓垮。
解決方案:
1、使用互斥鎖:當緩存失效時,不立即去load db,先使用如 Redis 的 setnx 去設置一個互斥鎖,當操作成功返回時再進行 load db的操作並回設緩存,否則重試get緩存的方法
2、永遠不過期:不要對這個key設置過期時間
緩存雪崩:
概述:設置緩存時採用了相同的過期時間,導致緩存在某一時刻同時失效,請求全部轉發到DB,DB 瞬時壓力過重雪崩。與緩存擊穿的區別:雪崩是很多key,擊穿是某一個key緩存。
解決方案:
將緩存失效時間分散開,比如可以在原有的失效時間基礎上增加一個隨機值,比如1-5分鐘隨機,這樣每一個緩存的過期時間的重複率就會降低,就很難引發集體失效的事件。
9、什麼是布隆過濾器?(高頻)
概述:布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上由一個很長的二進制向量(二進制數組)和一系列隨機映射函數(hash函數)。

作用:布隆過濾器可以用於檢索一個元素是否在一個集合中。
添加元素:將商品的id(id1)存儲到布隆過濾器
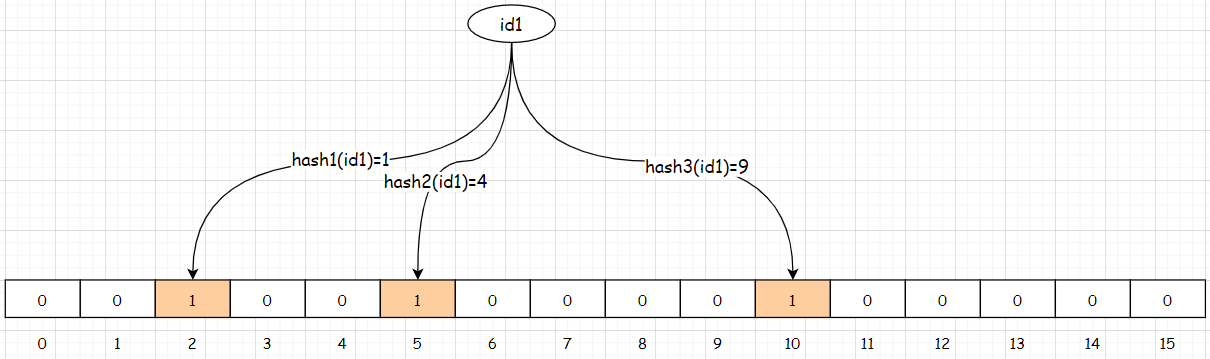
假設當前的布隆過濾器中提供了三個hash函數,此時就使用三個hash函數對id1進行哈希運算,運算結果分別為:1、4、9那麼就會數組中對應的位置數據更改為1。
判斷數據是否存在:使用相同的hash函數對數據進行哈希運算,得到哈希值。然後判斷該哈希值所對應的數組位置是否都為1,如果不都是則說明該數據
肯定不存在。如果是說明該數據可能存在,因為哈希運算可能就會存在重複的情況。如下圖所示:
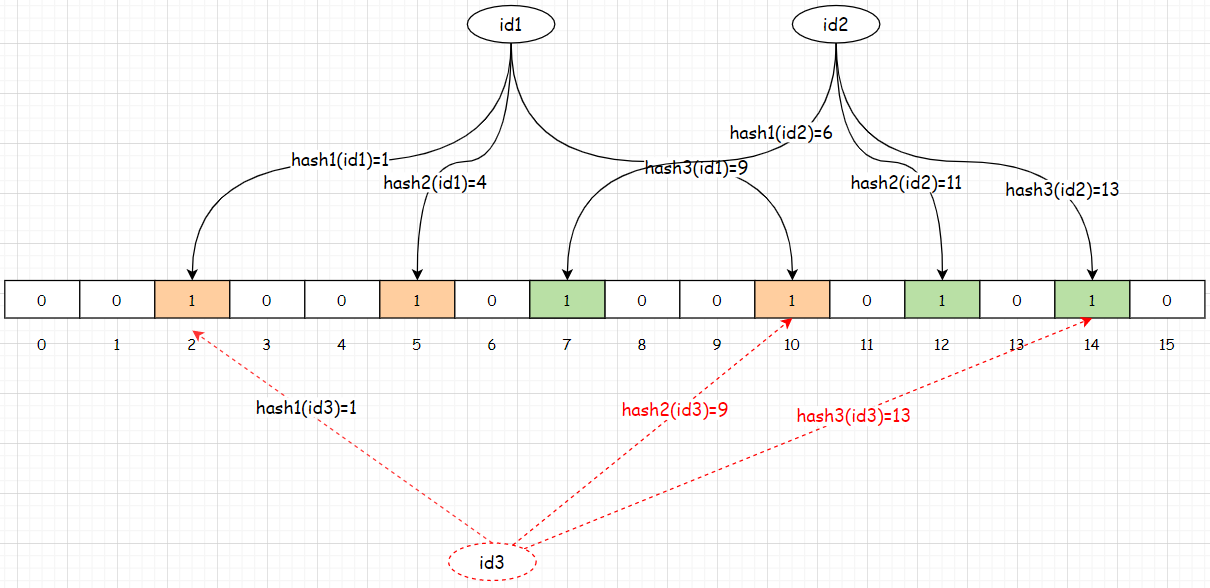
假設添加完id1和id2數據以後,布隆過濾器中數據的存儲方式如上圖所示,那麼此時要判斷id3對應的數據在布隆過濾器中是否存在,按照上述的判斷規則應該是存在,但是id3這個數據在布隆過濾器中壓根就不存在,這種情況就屬於誤判。
誤判率:數組越小誤判率就越大,數組越大誤判率就越小,但是同時帶來了更多的內存消耗。
刪除元素:布隆布隆器不支持數據的刪除操作,因為如果支持刪除那麼此時就會影響判斷不存在的結果。
使用布隆過濾器:在谷歌的guava緩存工具中提供了布隆過濾器的實現,使用方式如下所示:
pom.xml文件
測試代碼:
// 創建一個BloomFilter對象
// 第一個參數:布隆過濾器判斷的元素的類型
// 第二個參數:布隆過濾器存儲的元素個數
// 第三個參數:誤判率,默認值為0.03
int size = 100_000 ;
BloomFilter
for(int x = 0 ; x < size ; x++) {
bloomFilter.put(“add” + x) ;
}
// 在向其中添加100000個數據測試誤判率
int count = 0 ; // 記錄誤判的數據條數
for(int x = size ; x < size * 2 ; x++) {
if(bloomFilter.mightContain(“add” + x)) {
count++ ;
System.out.println(count + “誤判了”);
}
}
// 輸出
System.out.println(“總的誤判條數為:” + count);
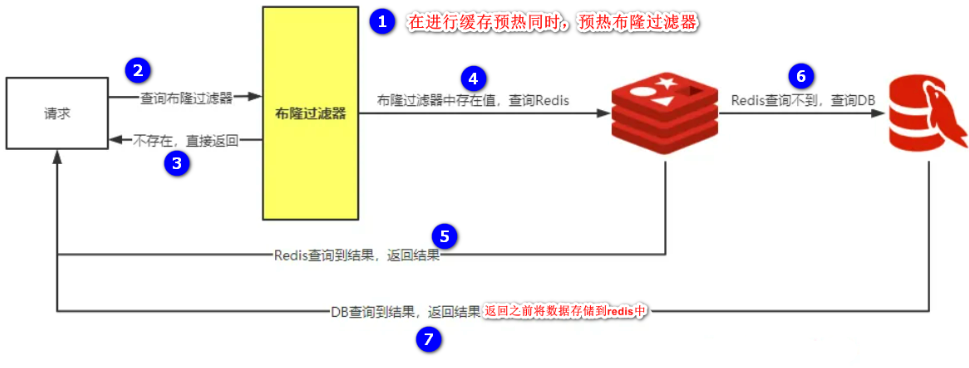
Redis中使用布隆過濾器防止緩存穿透流程圖如下所示:
10、Redis數據持久化有哪些方式?各自有什麼優缺點?(高頻)
在Redis中提供了兩種數據持久化的方式:1、RDB 2、AOF
RDB:定期更新,定期將Redis中的數據生成的快照同步到磁盤等介質上,磁盤上保存的就是Redis的內存快照
優點:數據文件的大小相比於aof較小,使用rdb進行數據恢復速度較快
缺點:比較耗時,存在丟失數據的風險
AOF:將Redis所執行過的所有指令都記錄下來,在下次Redis重啟時,只需要執行指令就可以了
優點:數據丟失的風險大大降低了
缺點:數據文件的大小相比於rdb較大,使用aof文件進行數據恢復的時候速度較慢
11、Redis都存在哪些集群方案?
在Redis中提供的集群方案總共有三種:
1、主從複製
-
保證高可用性
-
實現故障轉移需要手動實現
-
無法實現海量數據存儲
2、哨兵模式
-
保證高可用性
-
可以實現自動化的故障轉移
-
無法實現海量數據存儲
-
監控
-
故障轉移
-
通知客戶端
3、Redis分片集群
-
保證高可用性
-
可以實現自動化的故障轉移
-
可以實現海量數據存儲
12、說說Redis哈希槽的概念?
Redis 集群沒有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 個哈希槽,每個 key通過 CRC16 校驗後對 16384 取模來決定放置哪個槽,集群的每個節點負責一部分 hash 槽。
13、Redis中的管道有什麼用?
一次請求/響應服務器能實現處理新的請求即使舊的請求還未被響應,這樣就可以將多個命令發送到服務 器,而不用等待回復,最後在一個步驟中讀取該答覆。
14、談談你對Redis中事務的理解?(高頻)
事務是一個原子操作:事務中的命令要麼全部被執行,要麼全部都不執行。
Redis中的事務:Redis事務的本質是一組命令的集合。事務支持一次執行多個命令,一個事務中所有命令都會被序列化。在事務執行過程,會按照順序串行化執行隊列中的命令,其他客戶端提交的命令請求不會插入到事務執行命令序列中。
總結說:Redis事務就是一次性、順序性、排他性的執行一個隊列中的一系列命令。
15、Redis事務相關的命令有哪幾個?(高頻)
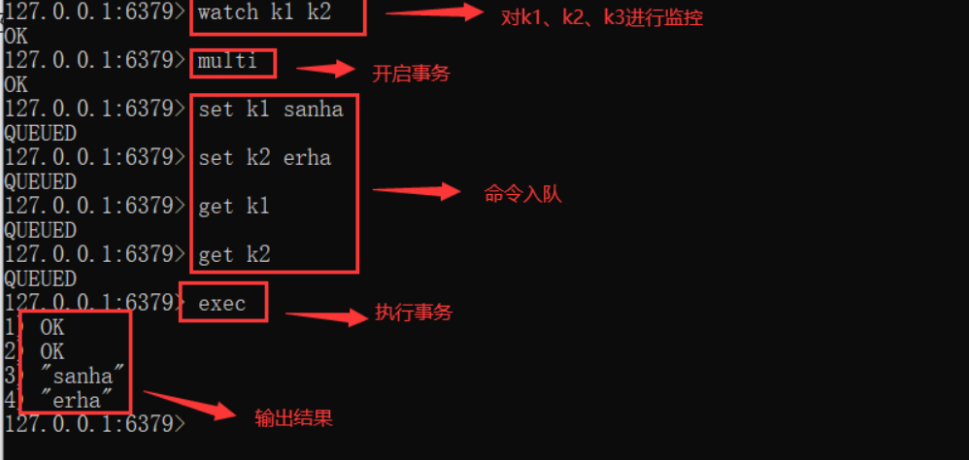
事務相關的命令:
1、MULTI:用來組裝一個事務
2、EXEC:執行一個事務
3、DISCARD:取消一個事務
4、WATCH:用來監視一些key,一旦這些key在事務執行之前被改變,則取消事務的執行
5、UNWATCH:取消 WATCH 命令對所有key的監視
如下所示:
16、Redis如何做內存優化?
儘可能使用散列表(hash),散列表(是說散列表裏面存儲的數少)使用的內存非常小,所以你應該儘可能的將你的數據模型抽象到一個散列表裏面。
比如你的 web 系統中有一個用戶對象,不要為這個用戶的名稱,姓氏,郵箱,密碼設置單獨的key,而是應該把這個用戶的所有信息存儲到一張散列表裏面。
17、Redis是單線的,但是為什麼還那麼快?(高頻)
Redis總體快的原因:
1、完全基於內存的
2、採用單線程,避免不必要的上下文切換可競爭條件
3、使用多路I/O復用模型,非阻塞IO
2 分佈式鎖篇
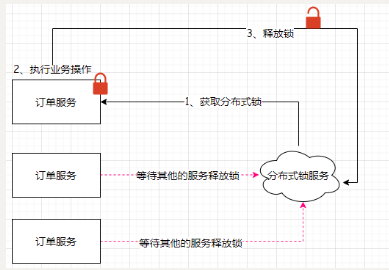
18、什麼是分佈式鎖?
概述:在分佈式系統中,多個線程訪問共享數據就會出現數據安全性的問題。而由於jdk中的鎖要求多個線程在同一個jvm中,因此在分佈式系統中無法使用jdk中的鎖保證數據的安全性,那麼此時就需要使用分佈式鎖。
作用:可以保證在分佈式系統中多個線程訪問共享數據時數據的安全性
舉例:
在電商系統中,用戶在進行下單操作的時候需要扣減庫存。為了提高下單操作的執行效率,此時需要將庫存的數據存儲到Redis中。訂單服務每一次生成訂單之前需要查詢一下庫存數據,如果存在則生成訂單同時扣減庫存。在高並發場景下會存在多個訂單服務操作Redis,此時就會出現線程安全問題。
分佈式鎖的工作原理:
分佈式鎖應該具備哪些條件:
1、在分佈式系統環境下,一個方法在同一時間只能被一個機器的一個線程執行
2、高可用的獲取鎖與釋放鎖
3、高性能的獲取鎖與釋放鎖
4、具備可重入特性
5、具備鎖失效機制,防止死鎖
可重入特性:獲取到鎖的線程再次調用需要鎖的方法的時候,不需要再次獲取鎖對象。
使用場景:遍歷樹形菜單的時候的遞歸調用。
注意:鎖具備可重入性的主要目的是為了防止死鎖。
19、分佈式鎖的實現方案都有哪些?(高頻)
分佈式鎖的實現方案:
1、數據庫
2、zookeeper
3、redis
20、Redis怎麼實現分佈式鎖思路?(高頻)
Redis實現分佈式鎖主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,則 SET)的簡寫。
127.0.0.1:6379> setnx lock value1 #在鍵lock不存在的情況下,將鍵key的值設置為value1
(integer) 1
127.0.0.1:6379> setnx lock value2 #試圖覆蓋lock的值,返回0表示失敗
(integer) 0
127.0.0.1:6379> get lock #獲取lock的值,驗證沒有被覆蓋
“value1”
127.0.0.1:6379> del lock #刪除lock的值,刪除成功
(integer) 1
127.0.0.1:6379> setnx lock value2 #再使用setnx命令設置,返回0表示成功
(integer) 1
127.0.0.1:6379> get lock #獲取lock的值,驗證設置成功
“value2”
上面這幾個命令就是最基本的用來完成分佈式鎖的命令。
加鎖:使用setnx key value命令,如果key不存在,設置value(加鎖成功)。如果已經存在lock(也就是有客戶端持有鎖了),則設置失敗(加鎖失敗)。
解鎖:使用del命令,通過刪除鍵值釋放鎖。釋放鎖之後,其他客戶端可以通過setnx命令進行加鎖。
21、Redis實現分佈式鎖如何防止死鎖現象?(高頻)
產生死鎖的原因:如果一個客戶端持有鎖的期間突然崩潰了,就會導致無法解鎖,最後導致出現死鎖的現象。
所以要有個超時的機制,在設置key的值時,需要加上有效時間,如果有效時間過期了,就會自動失效,就不會出現死鎖。然後加鎖的代碼就會變成這樣。
22、Redis實現分佈式鎖如何合理的控制鎖的有效時長?(高頻)
有效時間設置多長,假如我的業務操作比有效時間長?我的業務代碼還沒執行完就自動給我解鎖了,不就完蛋了嗎。
解決方案:
1、第一種:程序員自己去把握,預估一下業務代碼需要執行的時間,然後設置有效期時間比執行時間長一些,保證不會因為自動解鎖影響到客戶端業務代碼的執行。
2、第二種:給鎖續期。
鎖續期實現思路:當加鎖成功後,同時開啟守護線程,默認有效期是用戶所設置的,然後每隔10秒就會給鎖續期到用戶所設置的有效期,只要持有鎖的客戶端沒有宕機,就能保證一直持有鎖,直到業務代碼執行完畢由客戶端自己解鎖,如果宕機了自然就在有效期失效後自動解鎖。
上述的第二種解決方案可以使用redis官方所提供的Redisson進行實現。
Redisson是Redis官方推薦的Java版的Redis客戶端。它提供的功能非常多,也非常強大分佈式服務,使用Redisson可以輕鬆的實現分佈式鎖。Redisson中進行鎖續期的這種機制被稱為”看門狗“機制。
redission支持4種連接redis方式,分別為單機、主從、Sentinel、Cluster 集群。
23、Redis實現分佈式鎖如何保證鎖服務的高可用?(高頻)
解決方案:
1、使用Redis的哨兵模式構建一個主從架構的Redis集群
2、使用Redis Cluster集群
24、當同步鎖數據到從節點之前,主節點宕機了導致鎖失效,那麼此時其他線程就可以再次獲取到鎖,這個問題怎麼解決?(高頻)
使用Redission框架中的RedLock進行處理。
RedLock的方案基於2個前提:
1、不再需要部署從庫和哨兵實例,只部署主庫
2、但主庫要部署多個,官方推薦至少5個實例
也就是說,想使用RedLock,你至少要部署5個Redis實例,而且都是主庫,它們之間沒有任何關係,都是一個個孤立的實例。
工作流程如下所示:
1、客戶端先獲取【當前時間戳T1】
2、客戶端依次向這個5個Redis實例發起加鎖請求,且每個請求會設置超時時間(毫秒級,要遠小於鎖的有效時間),如果某一個實例加鎖失敗(包括網絡超時,鎖被其他的人持有等各種異常情況),就立即向下一個Redis實例申請加鎖
3、如果客戶端從 >=3 個(大多數)以上Redis實例加鎖成功,則再次獲取【當前時間戳T2】, 如果 T2 – T1 < 鎖的過期時間,此時,認為客戶端加鎖成功,否則加鎖失敗
4、加鎖成功,去操作共享資源
5、加鎖失敗,向【全部節點】發起釋放鎖請求
總結4個重點:
1、客戶端在多個Redis實例上申請加鎖
2、必須保證大多數節點加鎖成功
3、大多數節點加鎖的總耗時,要小於鎖設置的過期時間
4、鎖釋放,要向全部節點發起釋放鎖請求
24.1 為什麼要在多個實例上加鎖?
本質上是為了【容錯】, 部分實例異常宕機,剩餘的實例加鎖成功,整個鎖服務依舊可用。
24.2 為什麼步驟3加鎖成功後,還要計算加鎖的累計耗時?
因為操作的是多個節點,所以耗時肯定會比操作單個實例耗時更久,而且,因為是網絡請求,網絡情況是複雜的,有可能存在延遲、丟包、超時等情況發生,網絡請求越多,異常發生的概率就越大。所以,即使大多數節點加鎖成功,如果加鎖的累計耗時已經超過了鎖的過期時間,那此時有些實例上的鎖可能已經失效了,這個鎖就沒有意義了。
代碼大致如下所示:
Config config1 = new Config();
config1.useSingleServer().setAddress(“redis://192.168.0.1:5378”).setPassword(“a123456”).setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);
Config config2 = new Config();
config2.useSingleServer().setAddress(“redis://192.168.0.1:5379”).setPassword(“a123456”).setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);
Config config3 = new Config();
config3.useSingleServer().setAddress(“redis://192.168.0.1:5380”).setPassword(“a123456”).setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);
String resourceName = “REDLOCK_KEY”;
RLock lock1 = redissonClient1.getLock(resourceName);
RLock lock2 = redissonClient2.getLock(resourceName);
RLock lock3 = redissonClient3.getLock(resourceName);
// 向3個redis實例嘗試加鎖
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
boolean isLock;
try {
// isLock = redLock.tryLock();
// 500ms拿不到鎖, 就認為獲取鎖失敗。10000ms即10s是鎖失效時間。
isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
System.out.println(“isLock = “+isLock);
if (isLock) {
//TODO if get lock success, do something;
}
} catch (Exception e) {
} finally {
// 無論如何, 最後都要解鎖
redLock.unlock();
}


