實踐GoF的設計模式:迭代器模式
摘要:迭代器模式主要用在訪問對象集合的場景,能夠向客戶端隱藏集合的實現細節。
本文分享自華為雲社區《【Go實現】實踐GoF的23種設計模式:迭代器模式》,作者:元閏子。
簡介
有時會遇到這樣的需求,開發一個模塊,用於保存對象;不能用簡單的數組、列表,得是紅黑樹、跳錶等較為複雜的數據結構;有時為了提升存儲效率或持久化,還得將對象序列化;但必須給客戶端提供一個易用的 API,允許方便地、多種方式地遍歷對象,絲毫不察覺背後的數據結構有多複雜。
對這樣的 API,很適合使用 迭代器模式(Iterator Pattern)實現。
GoF 對 迭代器模式 的定義如下:
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
從描述可知,迭代器模式主要用在訪問對象集合的場景,能夠向客戶端隱藏集合的實現細節。
Java 的 Collection 家族、C++ 的 STL 標準庫,都是使用迭代器模式的典範,它們為客戶端提供了簡單易用的 API,並且能夠根據業務需要實現自己的迭代器,具備很好的可擴展性。
UML 結構
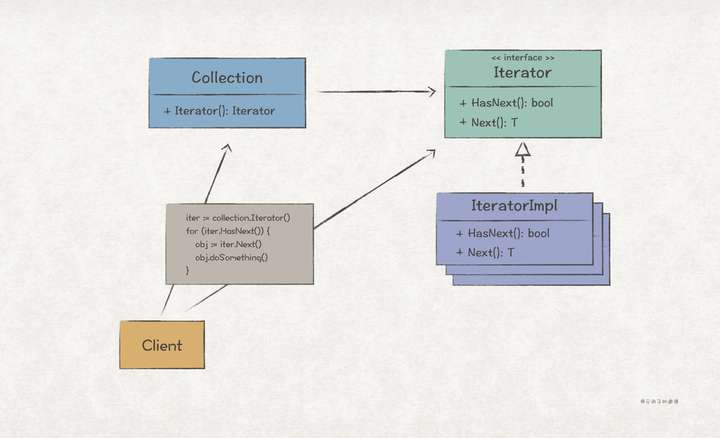
場景上下文
在簡單的分佈式應用系統(示例代碼工程)中,db 模塊用來存儲服務註冊和監控信息,它的主要接口如下:
// demo/db/db.go package db // Db 數據庫抽象接口 type Db interface { CreateTable(t *Table) error CreateTableIfNotExist(t *Table) error DeleteTable(tableName string) error Query(tableName string, primaryKey interface{}, result interface{}) error Insert(tableName string, primaryKey interface{}, record interface{}) error Update(tableName string, primaryKey interface{}, record interface{}) error Delete(tableName string, primaryKey interface{}) error ... }
從增刪查改接口可以看出,它是一個 key-value 數據庫,另外,為了提供類似關係型數據庫的按列查詢能力,我們又抽象出 Table 對象:
// demo/db/table.go package db // Table 數據表定義 type Table struct { name string recordType reflect.Type records map[interface{}]record }
其中,Table 底層用 map 存儲對象數據,但並沒有存儲對象本身,而是從對象轉換而成的 record 。record 的實現原理是利用反射機制,將對象的屬性名 field 和屬性值 value 分開存儲,以此支持按列查詢能力(一類對象可以類比為一張表):
// demo/db/record.go package db type record struct { primaryKey interface{} fields map[string]int // key為屬性名,value屬性值的索引 values []interface{} // 存儲屬性值 } // 從對象轉換成record func recordFrom(key interface{}, value interface{}) (r record, e error) { ... // 異常處理 vType := reflect.TypeOf(value) vVal := reflect.ValueOf(value) if vVal.Type().Kind() == reflect.Pointer { vType = vType.Elem() vVal = vVal.Elem() } record := record{ primaryKey: key, fields: make(map[string]int, vVal.NumField()), values: make([]interface{}, vVal.NumField()), } for i := 0; i < vVal.NumField(); i++ { fieldType := vType.Field(i) fieldVal := vVal.Field(i) name := strings.ToLower(fieldType.Name) record.fields[name] = i record.values[i] = fieldVal.Interface() } return record, nil }
當然,客戶端並不會察覺 db 模塊背後的複雜機制,它們直接使用的仍是對象:
type testRegion struct { Id int Name string } func client() { mdb := db.MemoryDbInstance() tableName := "testRegion" table := NewTable(tableName).WithType(reflect.TypeOf(new(testRegion))) mdb.CreateTable(table) mdb.Insert(tableName, "region1", &testRegion{Id: 0, Name: "region-1"}) result := new(testRegion) mdb.Query(tableName, "region1", result) }
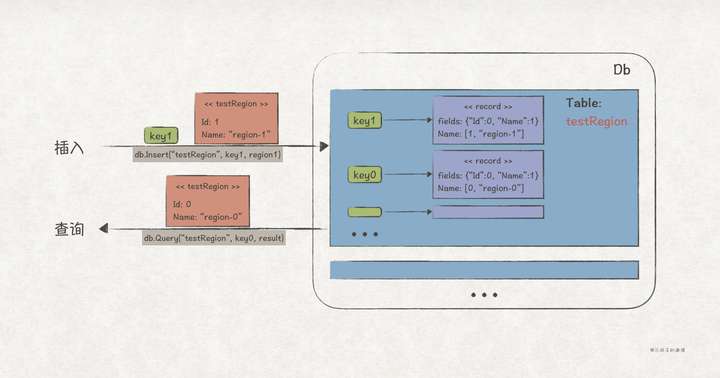
另外,除了上述按 Key 查詢接口,我們還想提供全表查詢接口,有隨機和有序 2 種表記錄遍歷方式,並且支持客戶端自己擴展遍歷方式。下面使用迭代器模式來實現該需求。
代碼實現
這裡並沒有按照標準的 UML 結構去實現,而是結合工廠方法模式來解決公共代碼的復用問題:
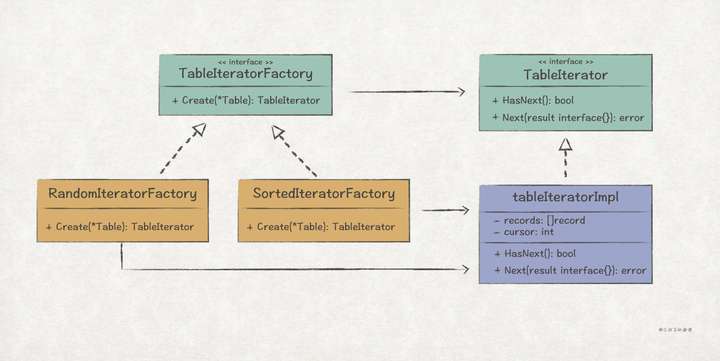
// demo/db/table_iterator.go package db // 關鍵點1: 定義迭代器抽象接口,允許後續客戶端擴展遍歷方式 // TableIterator 表迭代器接口 type TableIterator interface { HasNext() bool Next(next interface{}) error } // 關鍵點2: 定義迭代器接口的實現 // tableIteratorImpl 迭代器接口公共實現類 type tableIteratorImpl struct { // 關鍵點3: 定義一個集合存儲待遍歷的記錄,這裡的記錄已經排序好或者隨機打散 records []record // 關鍵點4: 定義一個cursor游標記錄當前遍歷的位置 cursor int } // 關鍵點5: 在HasNext函數中的判斷是否已經遍歷完所有記錄 func (r *tableIteratorImpl) HasNext() bool { return r.cursor < len(r.records) } // 關鍵點6: 在Next函數中取出下一個記錄,並轉換成客戶端期望的對象類型,記得增加cursor func (r *tableIteratorImpl) Next(next interface{}) error { record := r.records[r.cursor] r.cursor++ if err := record.convertByValue(next); err != nil { return err } return nil } // 關鍵點7: 通過工廠方法模式,完成不同類型的迭代器對象創建 // TableIteratorFactory 表迭代器工廠 type TableIteratorFactory interface { Create(table *Table) TableIterator } // 隨機迭代器 type randomTableIteratorFactory struct{} func (r *randomTableIteratorFactory) Create(table *Table) TableIterator { var records []record for _, r := range table.records { records = append(records, r) } rand.Seed(time.Now().UnixNano()) rand.Shuffle(len(records), func(i, j int) { records[i], records[j] = records[j], records[i] }) return &tableIteratorImpl{ records: records, cursor: 0, } } // 有序迭代器 // Comparator 如果i<j返回true,否則返回false type Comparator func(i, j interface{}) bool // sortedTableIteratorFactory 根據主鍵進行排序,排序邏輯由Comparator定義 type sortedTableIteratorFactory struct { comparator Comparator } func (s *sortedTableIteratorFactory) Create(table *Table) TableIterator { var records []record for _, r := range table.records { records = append(records, r) } sort.Sort(newRecords(records, s.comparator)) return &tableIteratorImpl{ records: records, cursor: 0, } }
最後,為 Table 對象引入 TableIterator:
// demo/db/table.go // Table 數據表定義 type Table struct { name string recordType reflect.Type records map[interface{}]record // 關鍵點8: 持有迭代器工廠方法接口 iteratorFactory TableIteratorFactory // 默認使用隨機迭代器 } // 關鍵點9: 定義Setter方法,提供迭代器工廠的依賴注入 func (t *Table) WithTableIteratorFactory(iteratorFactory TableIteratorFactory) *Table { t.iteratorFactory = iteratorFactory return t } // 關鍵點10: 定義創建迭代器的接口,其中調用迭代器工廠完成實例化 func (t *Table) Iterator() TableIterator { return t.iteratorFactory.Create(t) }
客戶端這樣使用:
func client() { table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))). WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator)) iter := table.Iterator() for iter.HashNext() { next := new(testRegion) err := iter.Next(next) ... } }
總結實現迭代器模式的幾個關鍵點:
- 定義迭代器抽象接口,目的是提供客戶端自擴展能力,通常包含 HashNext() 和 Next() 兩個方法,上述例子為 TableIterator。
- 定義迭代器接口的實現類,上述例子為 tableIteratorImpl,這裡主要起到了 Java/C++ 等帶繼承特性語言中,基類的作用,目的是復用代碼。
- 在實現類中持有待遍歷的記錄集合,通常是已經排序好或隨機打散後的,上述例子為 tableIteratorImpl.records。
- 在實現類中持有游標值,記錄當前遍歷的位置,上述例子為 tableIteratorImpl.cursor。
- 在 HashNext() 方法中判斷是否已經遍歷完所有記錄。
- 在 Next() 方法中取出下一個記錄,並轉換成客戶端期望的對象類型,取完後增加游標值。
- 通過工廠方法模式,完成不同類型的迭代器對象創建,上述例子為 TableIteratorFactory 接口,以及它的實現,randomTableIteratorFactory 和 sortedTableIteratorFactory。
- 在待遍歷的對象中,持有迭代器工廠方法接口,上述例子為 Table.iteratorFactory。
- 為對象定義 Setter 方法,提供迭代器工廠的依賴注入,上述例子為 Table.WithTableIteratorFactory() 方法。
- 為對象定義創建迭代器的接口,上述例子為 Table.Iterator() 方法。
其中,7~9 步是結合工廠方法模式實現時的特有步驟,如果你的迭代器實現中沒有用到工廠方法模式,可以省略這幾步。
擴展
Go 風格的實現
前面的實現,是典型的面向對象風格,下面以隨機迭代器為例,給出一個 Go 風格的實現:
// demo/db/table_iterator_closure.go package db // 關鍵點1: 定義HasNext和Next函數類型 type HasNext func() bool type Next func(interface{}) error // 關鍵點2: 定義創建迭代器的方法,返回HashNext和Next函數 func (t *Table) ClosureIterator() (HasNext, Next) { var records []record for _, r := range t.records { records = append(records, r) } rand.Seed(time.Now().UnixNano()) rand.Shuffle(len(records), func(i, j int) { records[i], records[j] = records[j], records[i] }) size := len(records) cursor := 0 // 關鍵點3: 在迭代器創建方法定義HasNext和Next的實現邏輯 hasNext := func() bool { return cursor < size } next := func(next interface{}) error { record := records[cursor] cursor++ if err := record.convertByValue(next); err != nil { return err } return nil } return hasNext, next }
客戶端這樣用:
func client() { table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))). WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator)) hasNext, next := table.ClosureIterator() for hasNext() { result := new(testRegion) err := next(result) ... } }
Go 風格的實現,利用了函數閉包的特點,把原本在迭代器實現的邏輯,放到了迭代器創建方法上。相比面向對象風格,省掉了迭代器抽象接口和實現對象的定義,看起來更加的簡潔。
總結幾個實現關鍵點:
- 聲明 HashNext 和 Next 的函數類型,等同於迭代器抽象接口的作用。
- 定義迭代器創建方法,返回類型為 HashNext 和 Next,上述例子為 ClosureIterator() 方法。
- 在迭代器創建方法內,定義 HasNext 和 Next 的具體實現,利用函數閉包來傳遞狀態(records 和 cursor)。
基於 channel 的實現
我們還能基於 Go 語言中的 channel 來實現迭代器模式,因為前文的 db 模塊應用場景並不適用,所以另舉一個簡單的例子:
type Record int func (r *Record) doSomething() { // ... } type ComplexCollection struct { records []Record } // 關鍵點1: 定義迭代器創建方法,返回只能接收的channel類型 func (c *ComplexCollection) Iterator() <-chan Record { // 關鍵點2: 創建一個無緩衝的channel ch := make(chan Record) // 關鍵點3: 另起一個goroutine往channel寫入記錄,如果接收端還沒開始接收,會阻塞住 go func() { for _, record := range c.records { ch <- record } // 關鍵點4: 寫完後,關閉channel close(ch) }() return ch }
客戶端這樣使用:
func client() { collection := NewComplexCollection() // 關鍵點5: 使用時,直接通過for-range來遍歷channel讀取記錄 for record := range collection.Iterator() { record.doSomething() } }
總結實現基於 channel 的迭代器模式的幾個關鍵點:
- 定義迭代器創建方法,返回一個只能接收的 channel。
- 在迭代器創建方法中,定義一個無緩衝的 channel。
- 另起一個 goroutine 往 channel 中寫入記錄。如果接收端沒有接收,會阻塞住。
- 寫完後,關閉 channel。
- 客戶端使用時,直接通過 for-range 遍歷 channel 讀取記錄即可。
帶有 callback 函數的實現
還可以在創建迭代器時,傳入一個 callback 函數,在迭代器返回記錄前,先調用 callback 函數對記錄進行一些操作。
比如,在基於 channel 的實現例子中,可以增加一個 callback 函數,將每個記錄打印出來:
// 關鍵點1: 聲明callback函數類型,以Record作為入參 type Callback func(record *Record) //關鍵點2: 定義具體的callback函數 func PrintRecord(record *Record) { fmt.Printf("%+v\n", record) } // 關鍵點3: 定義以callback函數作為入參的迭代器創建方法 func (c *ComplexCollection) Iterator(callback Callback) <-chan Record { ch := make(chan Record) go func() { for _, record := range c.records { // 關鍵點4: 遍歷記錄時,調用callback函數作用在每條記錄上 callback(&record) ch <- record } close(ch) }() return ch } func client() { collection := NewComplexCollection() // 關鍵點5: 創建迭代器時,傳入具體的callback函數 for record := range collection.Iterator(PrintRecord) { record.doSomething() } }
總結實現帶有 callback 的迭代器模式的幾個關鍵點:
- 聲明 callback 函數類型,以 Record 作為入參。
- 定義具體的 callback 函數,比如上述例子中打印記錄的 PrintRecord 函數。
- 定義迭代器創建方法,以 callback 函數作為入參。
- 迭代器內,遍歷記錄時,調用 callback 函數作用在每條記錄上。
- 客戶端創建迭代器時,傳入具體的 callback 函數。
典型應用場景
- 對象集合/存儲類模塊,並希望向客戶端隱藏模塊背後的複雜數據結構。
- 希望支持客戶端自擴展多種遍歷方式。
優缺點
優點
- 隱藏模塊背後複雜的實現機制,為客戶端提供一個簡單易用的接口。
- 支持擴展多種遍歷方式,具備較強的可擴展性,符合開閉原則。
- 遍歷算法和數據存儲分離,符合單一職責原則。
缺點
- 容易濫用,比如給簡單的集合類型實現迭代器接口,反而使代碼更複雜。
- 相比於直接遍歷集合,迭代器效率要更低一些,因為涉及到更多對象的創建,以及可能的對象拷貝。
- 需要時刻注意在迭代器遍歷過程中,由原始集合發生變更引發的並發問題。一種解決方法是,在創建迭代器時,拷貝一份原始數據(TableIterator 就這麼實現),但存在效率低、內存佔用大的問題。
與其他模式的關聯
迭代器模式通常會與工廠方法模 一起使用,如前文實現。
文章配圖
可以在用Keynote畫出手繪風格的配圖中找到文章的繪圖方法。
參考
[1] 【Go實現】實踐GoF的23種設計模式:SOLID原則, 元閏子
[2] 【Go實現】實踐GoF的23種設計模式:工廠方法模式, 元閏子
[3] Design Patterns, Chapter 5. Behavioral Patterns, GoF
[4] Iterators in Go, Ewen Cheslack-Postava
[5] 迭代器模式, refactoringguru.cn


