《深入了解java虛擬機》高效並發讀書筆記——Java內存模型,線程,線程安全 與鎖優化
《深入了解java虛擬機》高效並發讀書筆記——Java內存模型,線程,線程安全 與鎖優化
本文主要參考《深入了解java虛擬機》高效並發章節
關於鎖升級,偏向鎖,輕量級鎖參考《Java並發編程的藝術》
關於線程安全和線程安全的程度參考了《Java並發編程實戰》
圖片參考//www.processon.com/u/5dee0443e4b093b9f775065c#pc
一丶Java內存模型
1.概述
多任務處理已經是操作系統的必備技能,計算機被要求同時做好幾件事情,不僅是由於計算機計算能力強大了,還因為cpu的計算能力和存儲以及通信子系統的速度差異太大了(指cpu工作的時候大部分時間花費在網絡io,磁盤io上)所以人們開始讓處理器同時進行多個任務而不是浪費時間等待io操作的完成,從而提高TPS(每秒事務處理數)
2.硬件的效率和緩存一致性
-
解決cpu和內存運算能力差距巨大的問題
為了解決CPU和存儲子系統的存在幾個數量級的問題,現代計算機系統引入了多層的高速緩衝作為內存和處理器之間的緩衝(有點類似於使用redis提高系統的訪問速度,當我們系統的TPS受限於數據的io時,常常把熱點數據放在基於內存的redis從而提高TPS)把運算需要數據複製到緩存,提高運算速度,當運算結束後再從緩存同步到內存,從而使處理器不必等待緩慢的內存讀寫了
-
高速緩存引入的新問題
高速緩存的引入確實很好的解決了處理器和內存速度的問題,但是同時也引入了新的問題——緩存一致性:多處理器系統中,每個處理器擁有自己的高速緩存且共享主內存,當多個處理器的運算涉及到同一主內存的時候,可能存在緩存不一致的問題(ABC三個處理器,最開始緩存數據為1,後續各自分別自加1,2,3,最後需要寫回主內存,這時候出現緩存不一致的問題)
-
指令重排
為了使處理器內部運算單元可以被充分利用,處理器可能會對輸入的代碼進行亂序執行的優化,處理器在計算之後把亂序執行結果重組,保證結果和程序員定義的代碼順序執行結果相同,但是並不保證程序中每一個語句的計算先後順序與輸入代碼中順序一致。所以如果存在一個計算任務依賴另一個任務的中間結果的時候將無法依靠代碼的順序來進行保證,Java虛擬機的即時編譯器也存在這樣的指令重排技術
3.Java內存模型
屏蔽了操作系統的差異,保證java代碼在不同的操作系統上並發完全正常,Java內存模型簡稱為JMM
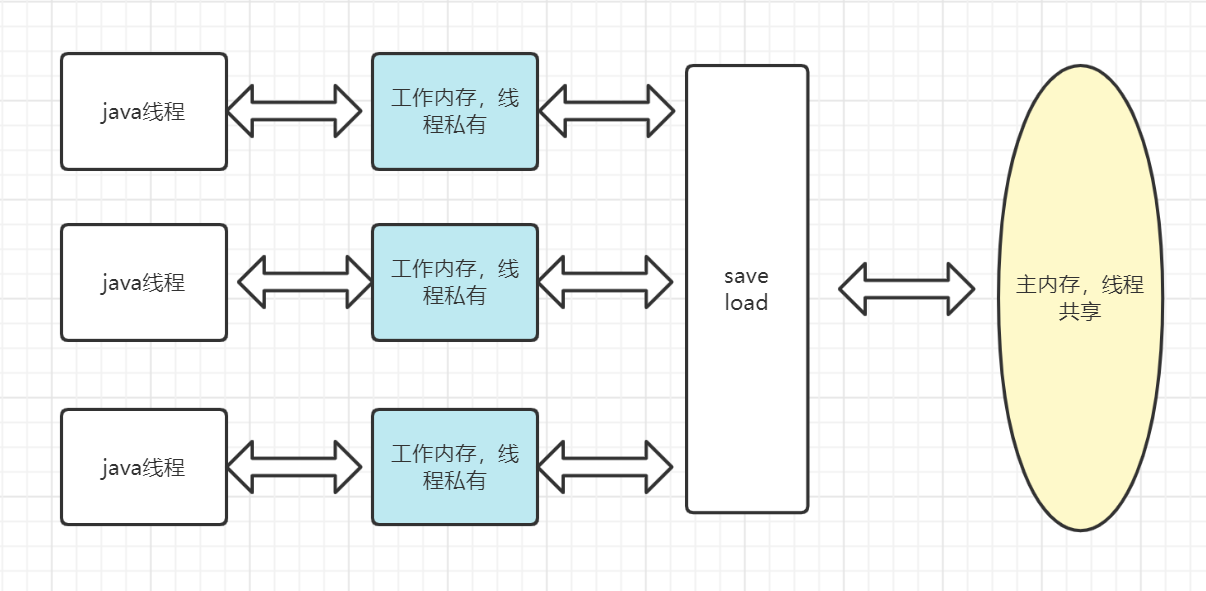
3.1主內存和工作內存
JMM定義了程序中共享變量的訪問規則,關注於虛擬機把共享變量存儲到內存和從內存取值的底層細節。(共享變量指的是線程共享的字段,常包括實例字段,靜態字段,構成數對象的元素,但是不包括局部變量和方法參數,這裡的局部變量是reference類型,雖然它指向的對象在堆中是線程共享的但是reference本身是在棧的局部變量中,是線程私有的)。 JMM規定了:
- 所以變量存儲在主內存,每條線程還由自己的工作內存(類別高速緩存)工作內存保存該線程使用變量的主內存的副本(不一定是複製整個對象,也許是這個對象被使用的某些字段,即使是volatile變量也存在線程工作內存的副本),
- 線程對變量的操作必須在工作內存中進行,而不能直接操作主內存
- 不同線程不能直接訪問對方工作內存中的變量,線程中的變量傳遞必須通過主內存來完成
3.2內存間交互操作
3.2.1 八種內存交互的操作
JMM規定了一個變量如何從主內存拷貝到工作內存,如何從工作內存同步到主內存的實現細節,並且定義了8中類似的操作,Java虛擬機保證以下操作都是原子的不可再分的(這裡64位的double類型,long類型在某寫平台可能load,store,read,write並不保證原子性,也就意味着可能存在半讀半寫的情況,但是無需過於關注這一點)
- lock:作用於主內存的變量,把變量標識位線程獨佔的狀態
- unlock: 作用於主內存變量,表示把處於鎖定狀態的變量釋放出來,釋放後的變量才可以被其他線程lock
- read: 從主內存讀取變量傳輸到線程工作內存,以便後續load操作
- load: 作用於工作內存變量,把read讀取到主內存的變量放入工作內存的變量副本中
- use:作用於工作內存變量,表示把工作內存中的變量傳遞給執行引擎
- assign: 作用於工作內存的變量,表示從執行引擎接收到的值
賦值給工作內存中的變量 - store:作用於工作內存中的變量,表示把工作內存中的變量傳送到主內存中,以便後續write操作
- write: 作用主內存的變量,把store操作從工作內存中得到的值放入到主內存的變量
JMM要求一個變量從主內存拷貝工作內存,必須順序的執行read load
要把變量從工作內存同步到主內存,也要順序執行store write
但是兩個命令之間可以插入其他命令
到這裡我們可以簡單分析下為什麼i++這種操作線程不安全
首先i一開始位於主內存,被多個線程使用read 和load 從主內存複製到工作內存,
然後每一個線程使用use進行自增操作,
然後assign 賦值給線程私有的工作內存,
然後每一個線程使用store把工作內存中值傳送到主內存,
然後使用write操作寫到主內存
雖然這每一步都是原子性的,但是合在一起就不是原子性的,
也就是說線程A write到主內存的時候,線程B也進行了write 造成都寫入了2,
線程C也沒有在線程A寫回主內存後再拉去i的值進行自增,
依舊使用的是工作內存中的i
3.2.2 八種基本操作必須滿足的規則
- read和 load,store 和write 不可單獨操作,也就是是從主內存讀取變量到工作內存後續筆記存在load操作讓工作保存變量的副本,同樣從工作內存傳送到主內存後續也必須存在write操作讓主內存寫入工作內存中的值到主內存。
- 不允許線程丟棄最近的assign操作,也就是說工作內存中改變了變量,必須要同步回主內存
- 不允許一個線程無任何原因(沒有發生assign操作)把數據從工作內存同步回主內存
- 一個變量只可以從主內存中誕生,不允許在工作內存中直接使用一個未被初始化的(load 或者assign)的變量,也就是對一個變量use 和store操作之前必須先執行assign操作和load操作
- 一個變量在同一個時刻只允許一個線程對其進行lock操作,但是lock操作可以被一個線程執行多次,但是lock多少次也需要unlock多少次
- 如果對一個變量指向了lock操作,那麼會清空工作內存中的此變量值,執行引擎使用這個變量之前,必須重新執行load 或assign來初始化變量的值
- 如果一個變量沒有被lock 那麼也不能被unlock,A線程不能unlock B線程lock的變量
- 對一個變量指向unlock之前,必須把這個變量同步會主內存中(store然後write)
3.1 volatile
3.1.1 volatile 的特性
volatile是java提供的輕量級同步機制,當一個變量被定義成volatile後,它會具備以下兩個特性
- 對所有線程的可見性,即任何一個線程修改了volatile修飾的變量,對於其他線程都是可以立即得知(普通變量一個線程修改之後必須同步會主內存,然後另外一個線程從主內存重新讀取才可以得知變化)
- 禁止指令重排序優化,普通的變量只能保證該方法執行的時候所有依賴賦值結果的地方都能正確的結果,表現為”線程內表現為串行的語義”
3.1.2 線程可見性和禁止指令重排是如何實現的
-
線程可見性
volatile修飾的變量,在賦值後會多執行一個
lock add$0xx,(%esp)的操作,lock前綴的指令會導致將當前工作內存此變量寫回到主內存,寫回內存的操作會是其他CPU中的緩存了此變量的數據無效,每個處理通過嗅探總線上傳播的數據來判斷自己的緩存數據是否過期,如果過期當處理器需要對數據進行修改的時候將從主內存中獲取最新的數據 -
禁止指令重排序
lock add$0xx,(%esp)把修改同步到主內存意味着前面指令的操作以及執行完成,也就是說lock之前的指令不可在lock指令之後,從而實現重排序無法越過內存屏障的效果這裡我們說下為什麼雙重if+synchronizated為什麼要把引用使用volatile修飾 創建一個對象實例,可以分為三步: 1.分配對象內存。 2.調用構造器方法,執行初始化。 3.將對象引用賦值給變量。 如果不適應volatile 可能出現被重排為 1.分配對象內存。 2.將對象引用賦值給變量。 3.調用構造器方法,執行初始化。 假設這個線程A正在執行new Instance()下執行倒2, 已經改變了instance的指向 這個時候線程B也調用getInstance 將導致線程B獲得還沒有執行初始化的對象實例 volatile在雙重if+synchronizated的單例實際是起到了禁止指令重排的作用 插入`lock add$0xx,(%esp)`保證了1,2,3都完成執行完,1,2,3可以進行重排,但是1,2,3必須都在`lock add$0xx,(%esp)`的前面執行
4 先行發生原則
4.1先行發生原則是什麼:
先行發生原子是我們判斷數據是否存在競爭,線程是否安全的有用手段。先行發生是java內存模型中定義兩項操作之前的偏序關係,並不意味着時間上的先後,而是說先行發生的操作對後續操作是可見的,比如我們說A先行發生於B,那麼意味着A操作造成的影響對B是可見的
4.2 Java內存模型下的先行發生原則
- 程序次序規則:指一個線程內,按照控制六順序,書寫在前面的操作必然是對書寫在後面的操作可見的
- 管程鎖定規則:unlock操作先行發生於後面對同一個鎖的lock操作(後面是時間上的先後)
- volatile 變量規則:同一個volatile變量的寫先行發生於後面對此變量的讀(後面是時間上的先後)
- 線程啟動規則:Thread的start方法先行發生於此線程的任何動作
- 線程終止規則:線程中所有操作都先行發生於對此線程的終止檢測,所以Thread::isAlive 可以檢查當前線程是否終止
- 對象終結規則: 一個線程的初始化完成先行發生於finalize方法的開始
- 傳遞性:A先行發生於B,B先行發生於C那麼A先行發生於C
4.3先行發生原則的使用
private int value;
public void setValue(int value){
this.value=value;
}
public int getValue(){
return value;
}
如果線程A在10:20:01 調用了setValue(1),線程B在10:20:02調用了getValue()那麼線程B得到的是什麼昵,顯然是無法確定的也許是0,也許是1,因為無法確定線程A刷新工作內存到主內存和線程B重新獲取主內存中值的先後順序。
-
使用volatile修飾value
套用volatile 變量規則:同一個volatile變量的寫先行發生於後面對此變量的讀,所以線程A寫入是先於線程B的讀取,所以B可以正確拿到值
-
使用synchronized修飾方法
套用管程鎖定規則:unlock操作先行發生於後面對同一個鎖的lock操作(後面是時間上的先後),A釋放鎖在B拿到鎖之前,B也可以成功拿到值
同樣我們還可以使用基於AQS實現的ReentrantLock(見我的筆記《JUC源碼學習筆記1——AQS獨佔模式和ReentrantLock》),我的理解是ReentrantLock套用的是volatile 變量規則,加鎖解鎖其實是修改state這個volatile變量,然後volatile可以防止指令重排,對value的設置肯定是位於鎖獲取和釋放之間的
二丶Java與線程
1.java線程的實現
線程是比進程更輕量級的調度執行單位,線程的引入,可以把一個進程的資源分配和執行調度分開,各個線程可以共享進程資源(內存地址,文件io)又可以獨立調度。對於hotspot虛擬機來說,Java線程都是映射到一個操作系統原生線程來實現,而且中間沒有額外的間接結構,所以hotspot不會幹預線程調度的(只能通過線程優先級給操作系統調度的建議),何時凍結線程,給線程分配多少處理器執行時間,線程安排給哪個處理器核心執行都是由操作系統完成的且全權決定的。
2.java線程的調度
線程的調度是指系統為線程分配處理器使用權的過程,調度方式主要有兩種:協同式調度(使用多少時間由線程本身控制)搶佔式——每個線程由系統來分配執行時間,線程的切換不由線程本身決定,但是線程可以主動讓出執行時間比如Thread::yield()方法,但是想主動獲取處理器執行時間,線程本身無法做到,搶佔式調度避免了協同式調度線程處理器執行時間不可控制的問題
三丶線程安全
1.線程安全的概念
當多個線程同時訪問一個對象時,如果不用考慮這些多線程在運行時環境下的調度和交替執行,也不需要進行額外的同步,或者調用方不需要進行任何其他的協調工作,調用這個對象的行為都可以獲取正確的結構,那麼我們稱這個對象時線程安全的
線程安全的對象封裝了必要的正確性保障手段,調用方無須過多擔心多線程問題
2.線程安全程度
2.1.不可變
不可變對象一定時線程安全的,無論時方法的實現或者還是方法的調用者,都不需要過多的關注線程安全問題,比如說String(拋開反射修改char數組的奇葩行為)大部分方法都是生產一個新的String對象,以及Integer等。在java中,如果一個多線程共享的數據是一個final修飾的基本類型,那麼必定不會再這個基本類型上存在線程安全問題,但是如果是一個引用類型那麼需要我們自己自行保證線程安全。
2.2 絕對線程安全
不管運行時環境如何,調用者都不需要額外的同步措施的多線是絕對線程安全的對象。這個絕對是比較難以理解的,比如Vector使用synchronized修飾方法,那麼就是線程絕對安全的么?不是我們只能保證單獨的操作是線程安全的,但是比如先contain查看是否包含然後add這種複合操作任然需要我們自己加鎖保證。這裡的絕對是說無論我如何使用當前這個類那麼都是線程安全的
2.3相對線程安全
這種就是我們常常說的線程安全,只需要保證這種對象單次的操作是線程安全的,不需要任何額外手段保證線程安全,但是一些連續的符合方法調用任然需要自行保證線程安全
2.4 線程兼容
線程兼容是對象本身不是線程安全的,但是可以通過在調用端使用一些手段保證線程安全,那麼就可以保證這個對象在並發中是安全的。這就是我們常說的線程不安全
2.5 線程對立
不論調用端是否採取同步措施,都無法保證線程安全的對象。比如Thread的suspend(),resume,如果兩個線程分別調用另外一個線程的這兩個方法,都存在死鎖的風險。
當線程A使用鎖L,如果線程A處於suspend狀態,而另一個線程B,需要L這把鎖才能resume線程A,因為線程A處理suspend狀態,是不會釋放L鎖,所以線程B線獲取不到這個鎖,而一直處於爭奪L鎖的狀態,最終導致死鎖。
3.如何實現線程安全
1.互斥同步
最常見的線程安全手段,同步的意思時多個線程並發訪問共享數據時,保證共享數據同一個時刻只能被一個或一些線程訪問到。互斥是實現同步的一種方式,臨界區,互斥量,信號量是常見的互斥方式。
臨界區:保證在某一時刻只有一個線程能訪問數據的簡便辦法。在任意時刻只允許一個線程對共享資源進行訪問。如果有多個線程試圖同時訪問臨界區,那麼 在有一個線程進入後其他所有試圖訪問此臨界區的線程將被掛起,並一直持續到進入臨界區的線程離開。
互斥量:互斥量跟臨界區很相似,只有擁有互斥對象的線程才具有訪問資源的權限,由於互斥對象只有一個,因此就決定了任何情況下此共享資源都不會同時被多個線程所訪問
常見是使用synchronized和互斥鎖ReentrantLock,前者編譯後生成monitorenter 和monitorexit指令,如果當前線程重複進行monitorenter那麼計數加1,多少次monitorenter那麼就是需要多少次monitorexit。計數為0表示放棄鎖,如果獲取鎖前被另外一個線程執行了monitorenter 那麼當前線程將一致被阻塞等待知道鎖被釋放。後者可以看我關於AQS的筆記
2.非阻塞同步
互斥同步屬於一種悲觀的並發策略(無論共享數據有無競爭,先上鎖)都會導致用戶態到內核態的切換。基於衝突檢測的樂觀並發策略——CAS(也有其他方式,但是提得最多的就是CAS了)比較並交換,CAS需要三個參數,第一個是共享數據的地址,第二個是預期的舊值,第三個是準備設置的新值,只有當前地址對應的值等於舊值的時候才會設置地址對應的值為新值,如果發現舊值不等於地址的值那麼將操作失敗。CAS的原子性由操作系統指令(如cmpxchg)來保證。Java中Unsafe類和原子類提供了CAS方法,可以看我關於原子類的筆記。
3.可重入代碼
指在代碼執行的任何時候都可以中斷它,去執行另外一段代碼(包括調用自己)控制權回來的時候程序不會出現任何錯誤,對結果也不會有任何影響。(可重入代碼,一般都不依賴於全局變量,不依賴堆上的對象,狀態都從參數傳入,不調用其他不可重入的代碼)有點類似無狀態的servlet
4.ThreadLocal
把共享數據的可見限制在一個線程之內,那麼無需同步也可以實現安全。關於ThreadLocal可以看我的相關源碼學習
四丶鎖優化
1.自旋鎖 與自適應自旋
1.1自旋鎖是什麼,為什麼需要自旋鎖
互斥同步由於線程的掛起和回複線程的操作都需要從用戶態和內核態的切換,導致jvm並發性能的降低。但是共享數據的鎖定狀態有時候只會持續一小段時間,為了加鎖去掛起和恢複線程並不值得。自旋鎖應運而生,不讓線程立馬掛起而是讓線程執行自旋讓線程等待鎖的釋放。
1.2自旋鎖的缺點和自適應自旋
自旋是線程執行循環,雖然避免了線程的切換,但是自旋是需要佔用處理器時間的,所以如果鎖被佔用的時間很短那麼自旋鎖能夠有一個很好的效果,但是如果鎖被霸佔的時間比較長,那麼線程一致進行自旋消耗cpu資源,將導致性能的浪費。因此自旋等待的時間需要有一定的限度,如果自旋的次數超過了限定的次數但是還是沒有獲取到鎖,這時候需要掛起線程。在這個背景下,JDK6進行了自適應自旋,自適應自旋意味着自旋的時間不在固定了,而是由上一次在同一個鎖上的自旋時間以及鎖擁有者的狀態來決定的。如果在同一個鎖上面,自旋等待剛剛獲取到了鎖,並且持有鎖的線程正在運行中,那麼虛擬機會認為這次自旋也很有可能再次成功,進而允許自旋等待持續相對更長的時間。如果一個鎖,自旋很少成功獲得鎖,那麼在後續對這個鎖的爭奪的時候將可能直接忽略自旋過程,避免處理器資源的浪費。有了自適應自旋,隨着程序運行的時間以及性能監控的完善,虛擬機對鎖的預測將越來越精準。
2.鎖消除
指虛擬器即時編譯器運行過程中,對於一段需要同步的代碼,檢測其根本不存在共享數據的競爭,那麼將對競爭的鎖進行消除
public synchronized String concat(String a,String b){
return a+b;
}
//string的連接操作總是產生一個新的字符串
//上面代碼也許會被優化成棧中new一個 StringBuffer 進行append
//StringBuffer中的同步鎖,鎖的是StringBuffer對象,
//但是StringBuffer在棧中new出來的
//逃逸分析就發現動態作用域在concat內部那麼就不需要線程同步
虛擬機發現這段代碼中,在堆中的數據都不會逃逸出被其他線程訪問到,那麼就會視為棧上的數據對待,認為它們線程私有,那麼加鎖也就沒有了必要。
3.鎖粗化
隨讓我們通常推薦鎖的粒度儘可能小,從而提高性能,但是如果對一個對象重複的進行加鎖解鎖,甚至是在for循環中加鎖解鎖,那麼即使沒有線程競爭,頻繁進行互斥同步也是非常浪費性能,也許虛擬機會幫我們擴大鎖的範圍,比如擴大到for循環的外部,這樣只需要進行一次加鎖解鎖了
4.鎖升級
4.1Java對象頭
以下是Java對象的內存布局
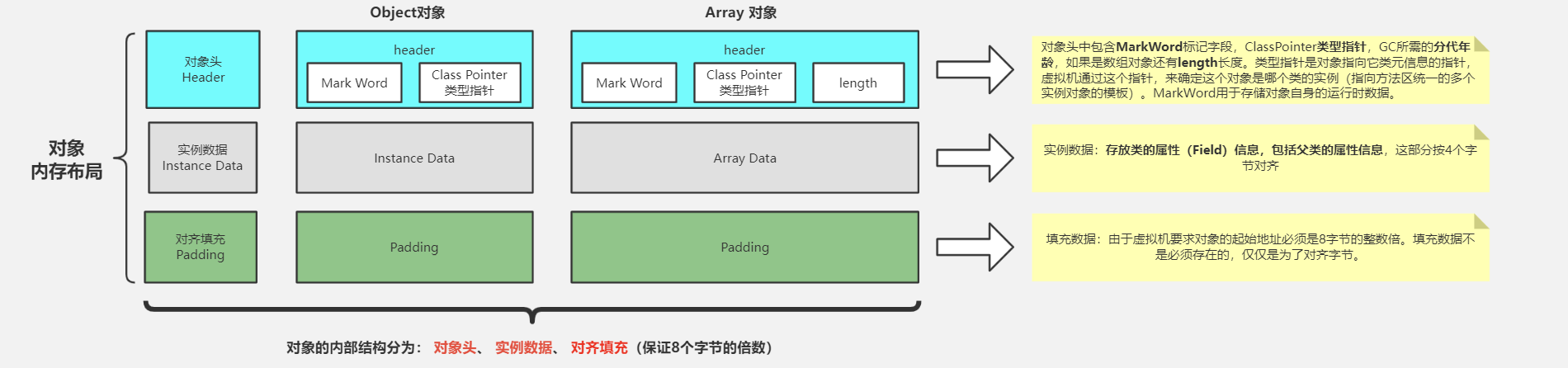
Java對象頭存儲的信息有:
- mark word存儲對象的hashCode,鎖信息,分代年齡等
- class pointer,存儲當前對象類型數據的指針
- array Lenth:如果是數組那麼還有這部分來存儲數組的長度
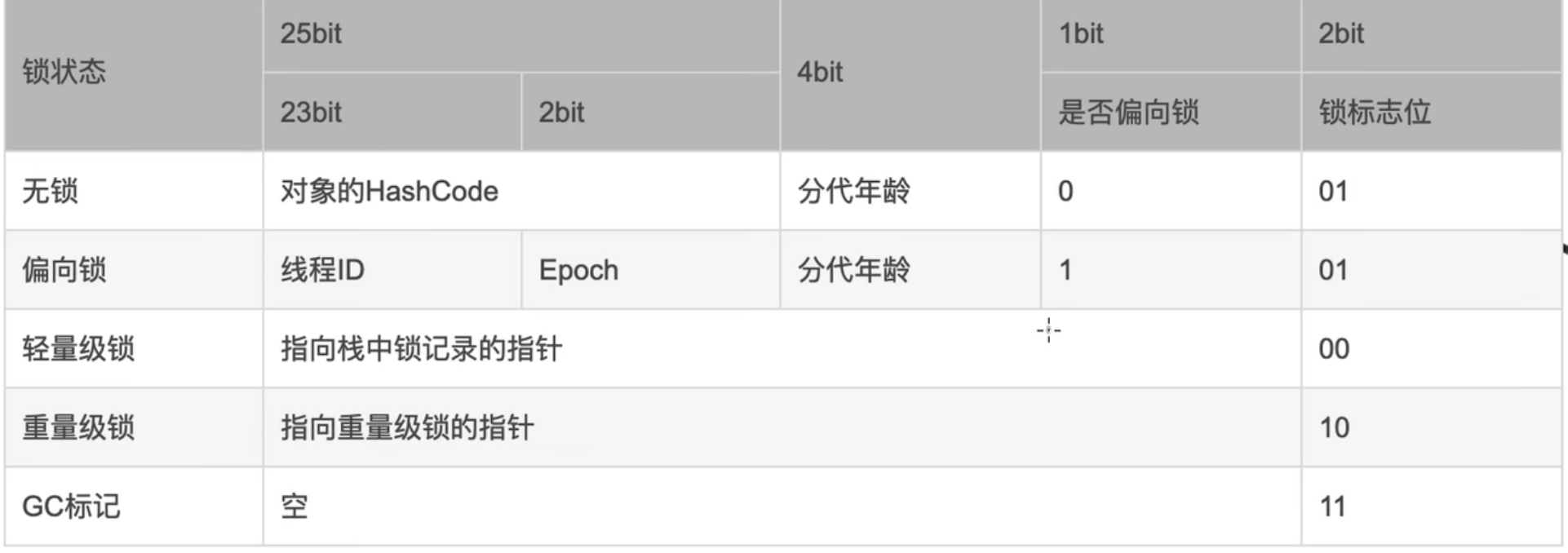
其中markword存儲了許多和對象運行狀態相關的數據,且這一部分涉及的非常的靈活,在不同的情況下可以表示不同的信息,下面是不同鎖狀態下32位虛擬機markword存儲信息的結構
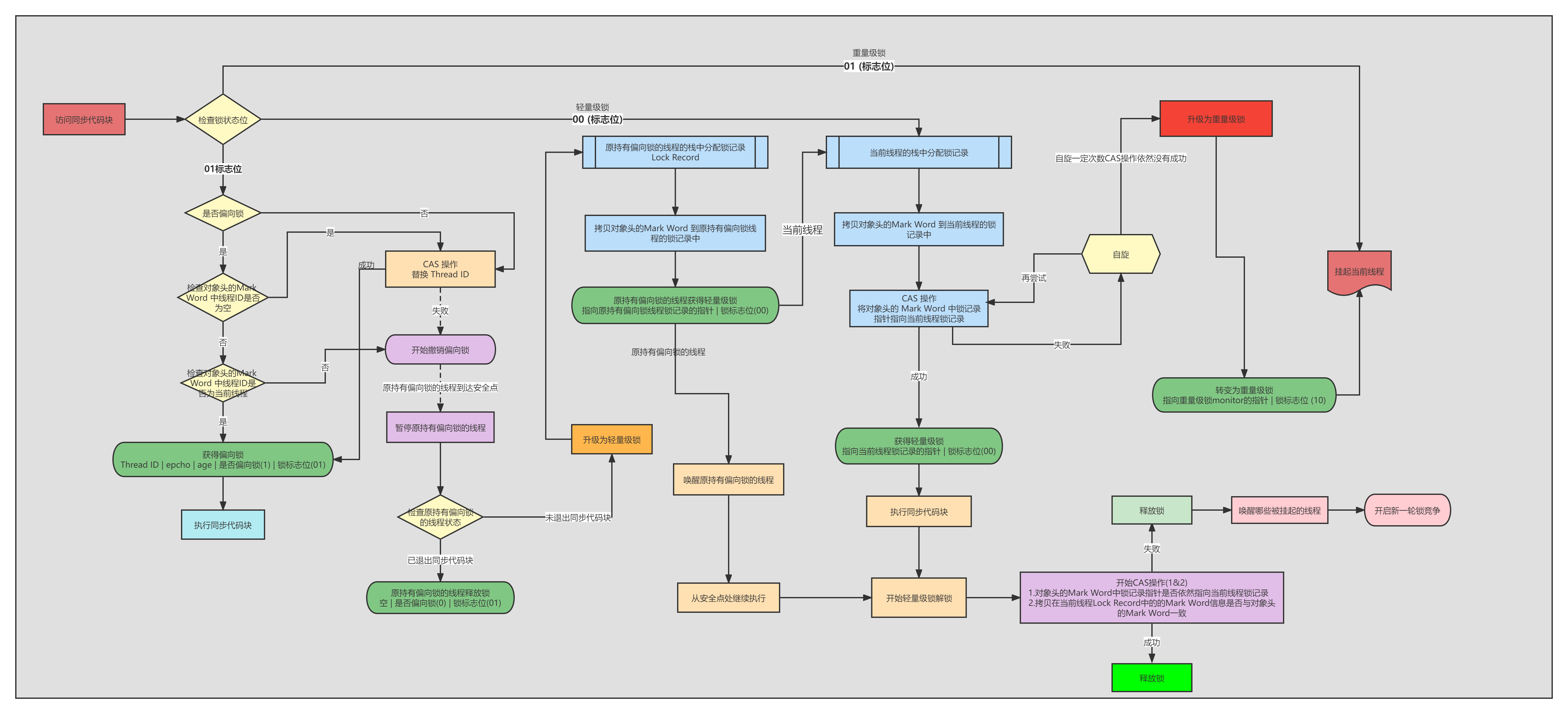
4.2 鎖升級的概念
JDK6為了解決獲取鎖釋放鎖的性能消耗,引入了偏向鎖和輕量級鎖。鎖的狀態從低到高依次是無鎖,偏向鎖,輕量級鎖,重量級鎖
4.3偏向鎖
hotspot的作者經過研究發現,大多數情況下,鎖不僅不存在多線程競爭,還常常是由同一個線程多次獲取,那麼能不能讓鎖記錄這個線程,下次這個線程來直接獲取鎖即可,從而降低獲得鎖的代價。當一個線程範圍同步塊並且獲取鎖時,會在對象頭和站在棧幀中記錄存儲鎖偏向的線程ID,以後進入和退出同步塊的時候都不需要進行CAS操作加鎖和解鎖。
4.3.1 偏向鎖的獲取
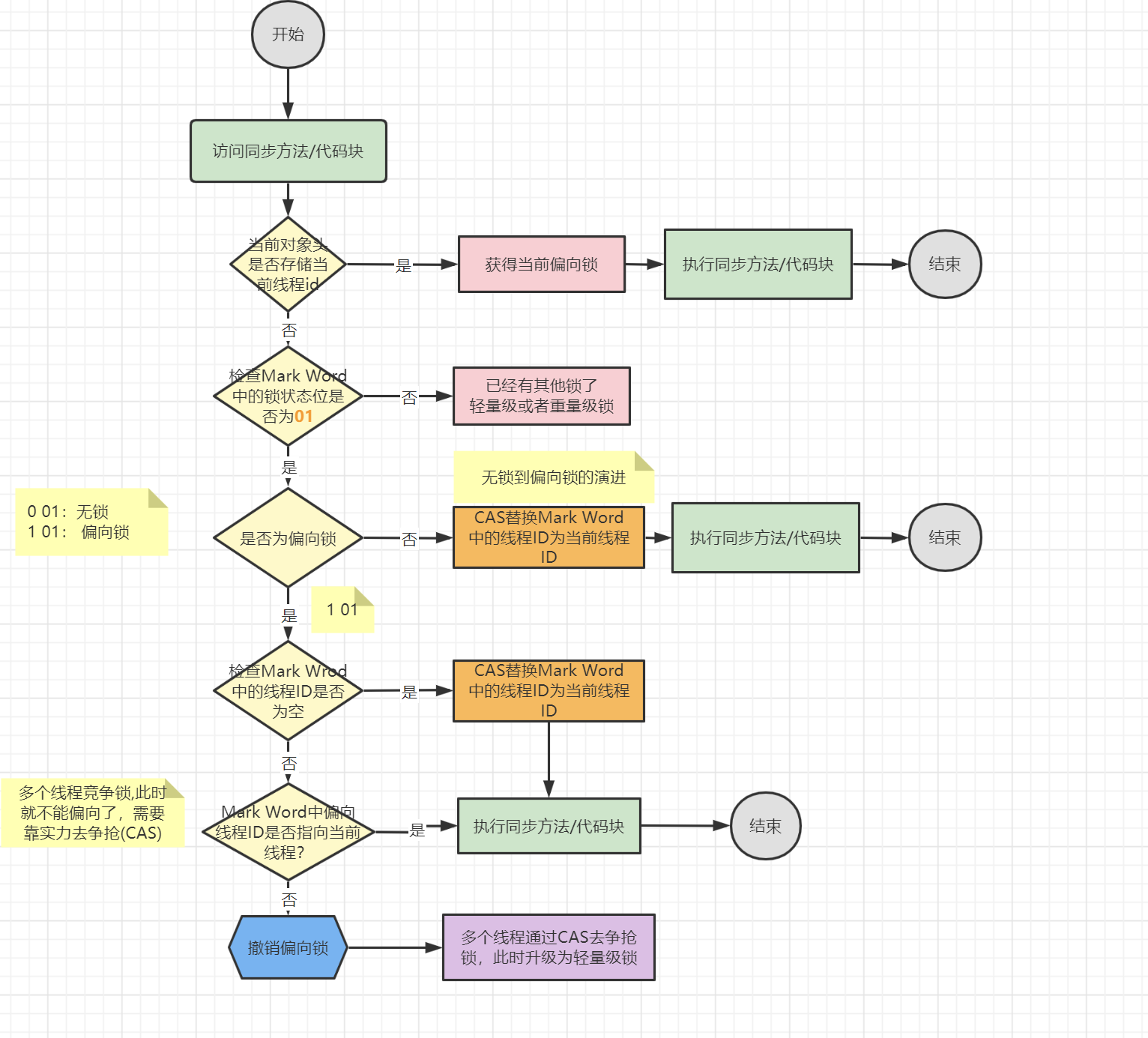
首先直接看對象頭中是否存儲了當前線程的id,如果存儲了那麼當前線程拿到鎖,這就是偏向的含義,如果失敗,那麼再看下當前鎖標誌位是否是01,01表示無鎖或者偏向鎖,繼續判斷是否是偏向鎖,如果是偏向鎖那麼需要查看是否存儲了當前線程id,如果沒有存儲任何線程id那就CAS設置線程id。如果當前時無鎖也是CAS設置線程Id
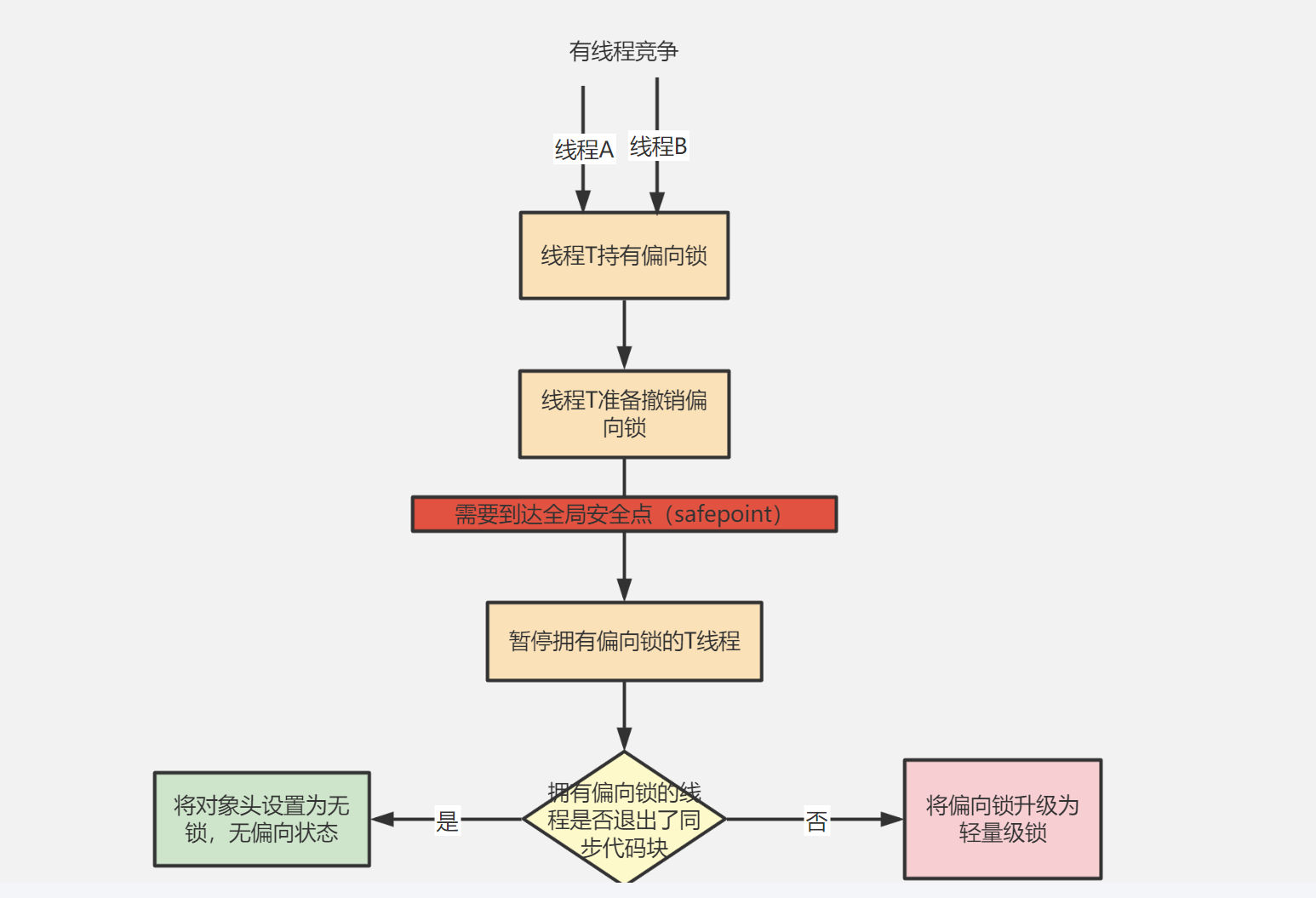
4.3.2 偏向鎖的撤銷
偏向鎖使用一種等待競爭出現的時候才釋放鎖的機制,當其他線程嘗試競爭偏向鎖時,持有偏向鎖的線程才會釋放鎖。偏向鎖的撤銷需要等待全局安全點(這個時間點沒有正在執行的位元組碼)首先需要暫停持有偏向鎖的線程,然後檢查持有偏向鎖的線程是否存活,如果持有的線程不處於活動狀態那麼設置為無鎖狀態,如果任然存活,那麼擁有偏向鎖的棧才會被執行,遍歷偏向對象的鎖記錄,棧中的鎖記錄和對象頭的markword要麼偏向其他線程,要麼恢復到無鎖,要麼標記對象不適合偏向鎖。後續被標記不適合偏向鎖那麼將使用輕量級鎖
4.4輕量級鎖
4.4.1 輕量級鎖的獲取
線程在執行同步塊之前,JVM會先在當前線程的棧幀中創建用於存儲鎖記錄的空間(lock record)並且將對象頭中的mark word 賦值到鎖記錄lock record中,這種操作叫做Displaced mark word。然後線程產品使用CAS把對象頭的mark word替換為指向鎖記錄的指針,如果成功那麼表示當前線程獲取到鎖,如果失敗,表示存在其他線程競爭鎖,當前線程將通過自旋的方式獲取鎖。輕量級鎖解決了競爭線程不多,並且鎖很快就釋放,這時候掛起喚醒線程不划算,通過自旋減少用戶態到內核態的切換。
4.4.2輕量級鎖解鎖
解鎖,使用CAS操作把Displaced Mark Word替換回到對象頭,如果成功表示沒有不存在競爭,如果失敗表示當前鎖存在競爭,那麼鎖會膨脹為重量級鎖
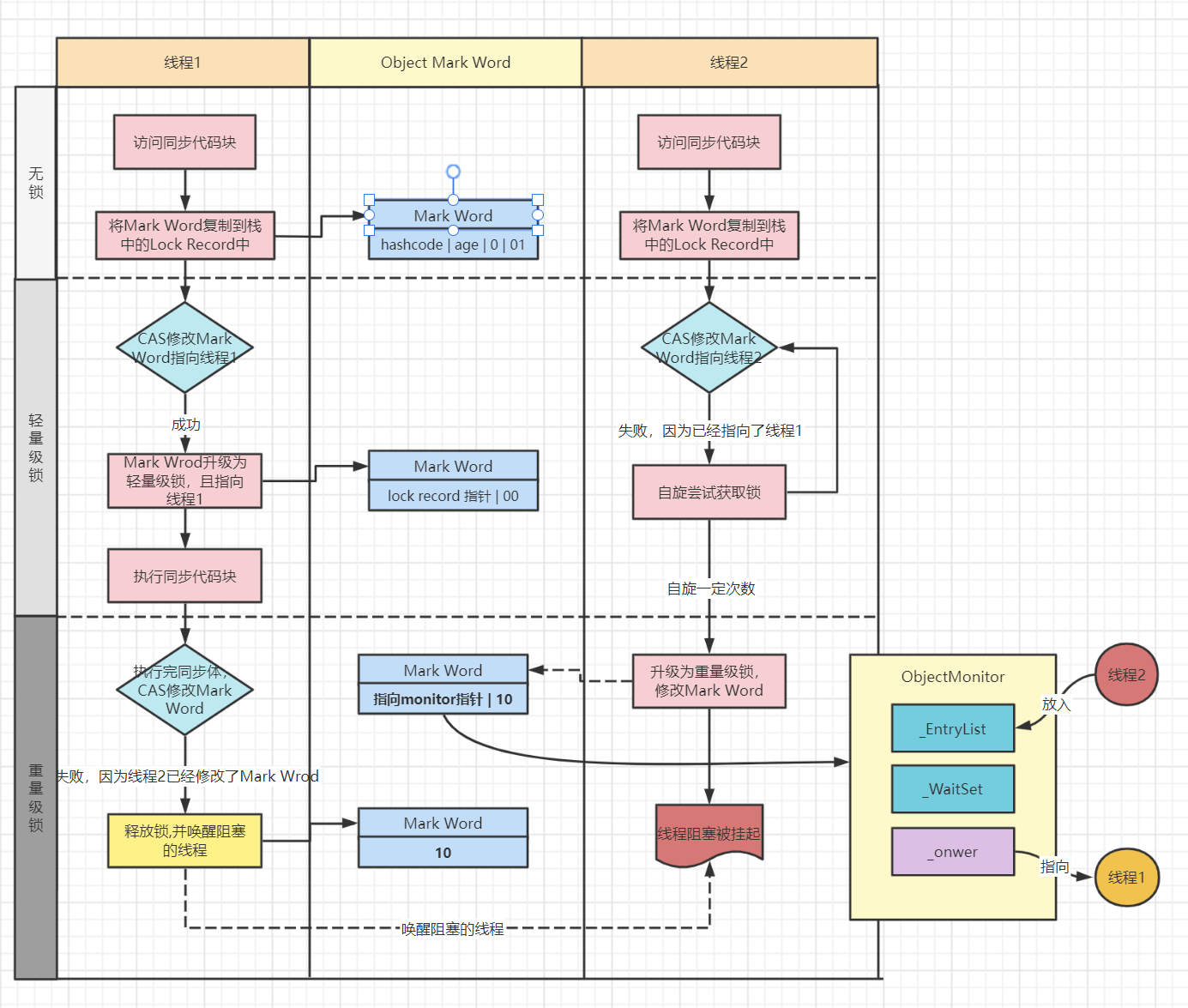
4.5鎖升級全流程