跟我讀論文丨Multi-Model Text Recognition Network
摘要:語言模型往往被用於文字識別的後處理階段,本文將語言模型的先驗信息和文字的視覺特徵進行交互和增強,從而進一步提升文字識別的性能。
本文分享自華為雲社區《Multi-Model Text Recognition Network》,作者:穀雨潤一麥 。

語言模型經常被用於文字識別的後處理階段,用來優化識別結果。但該先驗信息是獨立作用於識別器的輸出,所以之前的方法並沒有充分利用該信息。本文提出MATRN,對語義特徵和視覺特徵之間進行跨模態的特徵增強,從而提高識別性能。
方法
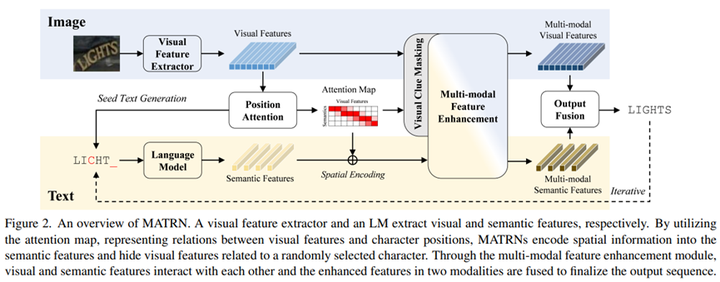
方法的流程圖如上圖所示,首先圖片通過視覺提取器和位置注意力模塊得到初步的文字識別結果。然後將該識別結果通過一個預訓練好的語言模型,得到文字的語義特徵。
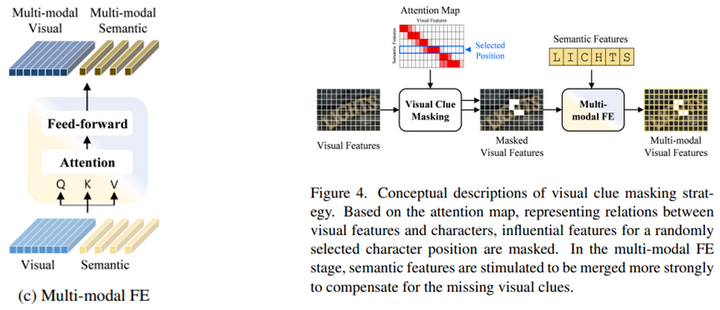
接着通過上圖左所示的模塊,利用transformer進行視覺特徵和語義特徵的特徵增強。最後利用如下公式,將視覺特徵和語義特徵進行特徵融合,並進行最終的分類。
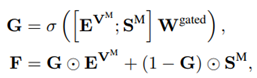
值得注意的是,有感於自監督的方法,本文也提出了一種在視覺特徵圖上加掩碼的方法。具體來說,利用位置注意力模塊中的注意力相應圖,隨機選擇某個時刻的注意力權重作為掩碼,mask掉一部分視覺特徵。
實驗結果
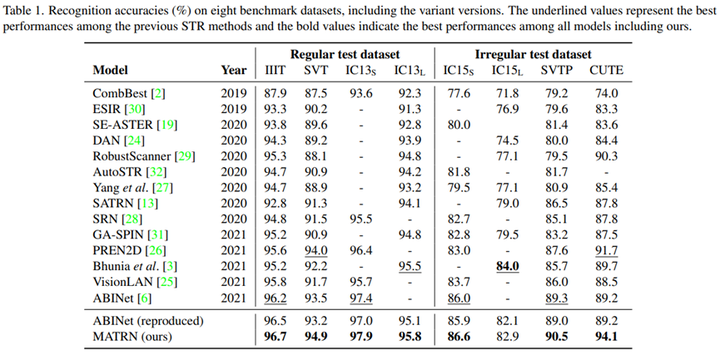
從實驗結果可以看出來,該方法在比較困難的不規則圖像中有較大提升。這說明當模型很難從視覺上進行識別的時候,文字之間的語義特徵有助於識別。


