一場pandas與SQL的巔峰大戰(六)
- 2020 年 2 月 20 日
- 筆記
本文目錄:
數據準備 日活計算 SQL計算日活 pandas計算日活 留存率計算 SQL計算 次日留存計算 多日留存計算 pandas方式 小結
在之前的五篇系列文章中,我們對比了pandas和SQL在數據方面的多項操作。
具體來講,第一篇文章一場pandas與SQL的巔峰大戰涉及到數據查看,去重計數,條件選擇,合併連接,分組排序等操作。
第二篇文章一場pandas與SQL的巔峰大戰(二)涉及字符串處理,窗口函數,行列轉換,類型轉換等操作。
第三篇文章一場pandas與SQL的巔峰大戰(三)圍繞日期操作展開,主要討論了日期獲取,日期轉換,日期計算等內容。
第四篇文章一場pandas與SQL的巔峰大戰(四)學習了在MySQL,Hive SQL和pandas中用多種方式計算日環比,周同比的方法。
第五篇文章一場pandas與SQL的巔峰大戰(五)我們用多種方案實現了分組和不分組情況下累計百分比的計算。
本篇文章主要來總結學習SQL和pandas中計算日活和多日留存的方法。
數據準備
先來看一下日活和留存的定義,對任何一款App而言,這兩個指標都是很重要的。
日活(Daily Active User,即DAU)顧名思義即每天的活躍用戶,至於如何定義就有多種口徑了。一方面要約定何為「活躍」,可以是啟動一次App,可以是到達某一個頁面,可以是進入App後產生某一個行為等等。
另一方面要約定計量的口徑,可以是計算用戶id的去重數,也可以是設備id的去重數。這兩種口徑統計結果會有差異,原因在於未登錄的用戶可能存在設備id,不存在用戶id;並且設備id與用戶id可能存在多對多的情況。因此對於運營來講,確定合理有效的口徑是很重要的。
留存是一個動態的概念,指的是某段時間使用了產品的用戶,在一段時間之後仍然在使用產品的用戶,二者相比可以求出留存率。常見的留存率有次日留存率,7日留存率,30日留存率等。次日留存是指今天活躍的用戶,在明天還剩下多少仍然活躍的用戶。留存率越高,說明產品的粘性越好。
我們的數據是一份用戶登錄數據,數據來源為:
https://www.kaggle.com/nikhil04/login-time-for-users 。
數據格式比較簡單:id:自增id,uid:用戶唯一id。ts:用戶登錄的時間(精確到秒),數據樣例如下圖,在公眾號後台回復「對比六」可以獲得本文全部的數據和代碼,方便進行實操。

本次我們只用到MySQL和pandas。MySQL可以直接運行我提供的login.sql文件加載數據,具體過程可以參考前面的文章。pandas中直接使用read_csv的方式讀取即可,可以參考後面的代碼。
日活計算
這裡我們約定日活是指每天登錄的user_id去重數,從我們的數據來看,計算方式非常簡單。

SQL計算日活
早在系列第一篇中我們就學習過group by聚合操作。只需要按天分組,將uid去重計數,即可得到答案。代碼如下:
select substr(ts, 1, 10) as dt, count(distinct uid) as dau from t_login group by substr(ts, 1, 10)

pandas計算日活
pandas計算日活也不難,同樣是使用groupby ,對uid進行去重計數。代碼如下:
import pandas as pd login_data = pd.read_csv('login_data.txt', sep='t', parse_dates=['ts']) login_data.head() login_data['day'] = login_data['ts'].map(lambda x: x.strftime('%Y-%m-%d')) uid_count = login_data.groupby('day').aggregate({'uid': lambda x: x.nunique()}) uid_count.reset_index(inplace=True) uid_count
我們增加了一列精確到天的日期數據,便於後續分組。在聚合時,使用了nunique進行去重。(在這裡也糾正一下系列第一篇文章中第6部分中的寫法,np.size 是不去重的,相當於count,但又不能直接寫np.nunique,所以我們採用了lambda函數的形式。感謝熱心讀者的指出~)最終uid_count的輸出結果如下圖所示,uid列就是我們要求的dau,結果和SQL算出來一樣。可以再用rename對列進行重命名,此處略:

留存計算
如前文所示,這裡我們定義,留存率是指一段時間後仍然登錄的用戶占第一天登錄用戶的比例,由於2017-01-07登錄的用戶太少,我們選擇2017-01-12作為第一天。分別計算次日留存率,7日,14日留存率。
SQL方式
次日留存計算
同前面計算日環比周同比一樣,我們可以採用自連接的方式,但連接的條件除了日期外,還需要加上uid,這是一個更加嚴格的限制。左表計數求出初始活躍用戶,右表計數求出留存用戶,之後就可以求出留存率。代碼如下,注意連接條件:
SELECT substr(a.ts, 1, 10) as dt, count(distinct a.uid), count(distinct b.uid), concat(round((count(distinct b.uid) / count(distinct a.uid)) * 100, 2) ,'%') as 1_day_remain from t_login a left join t_login b on a.uid = b.uid and date_add(substr(a.ts, 1, 10), INTERVAL 1 day) = substr(b.ts, 1, 10) group by substr(a.ts, 1, 10)
得到的結果如下:

多日留存計算
上面自連接的方法固然可行,但是如果要同時計算次日,7日,14日留存,還需要在此基礎上進行關聯兩次,關聯條件分別為日期差為6和13。讀者可以試試寫一下代碼。
當數據量比較大時,多次關聯在執行效率上會有瓶頸。因此我們可以考慮新的思路。在確定要求固定日留存時,我們使用了日期關聯,那麼如果不確定求第幾日留存的情況下,是不是可以不寫日期關聯的條件呢,答案是肯定的。來看代碼:
select substr(a.ts, 1, 10) as dt, count(distinct a.uid), count(distinct if(datediff(substr(b.ts, 1, 10), substr(a.ts, 1, 10))=1, b.uid, null)) as 1_day_remain_uid, count(distinct if(datediff(substr(b.ts, 1, 10), substr(a.ts, 1, 10))=6, b.uid, null)) as 7_day_remain_uid, count(distinct if(datediff(substr(b.ts, 1, 10), substr(a.ts, 1, 10))=13, b.uid, null)) as 14_day_remain_uid from t_login a left join t_login b on a.uid = b.uid group by substr(a.ts, 1, 10)
如代碼所示,在關聯時先不限制日期,最外層查詢時根據自己的目標限定日期差,可以算出相應的留存用戶數,第一天的活躍用戶也可以看作是日期差為0時的情況。這樣就可以一次性計算多日留存了。結果如下,如果要計算留存率,只需轉換為對應的百分比即可,參考前面的代碼,此處略。

pandas方式
次日留存計算
pandas計算留存也是緊緊圍繞我們的目標進行:同時求出第一日和次日的活躍用戶數,然後求比值。同樣也可以採用自連接的方式。代碼如下(這裡的步驟比較多):
1.導入數據並添加兩列日期,分別是字符串格式和datetime64格式,便於後續日期計算
import pandas as pd from datetime import timedelta login_data = pd.read_csv('login_data.txt', sep='t', parse_dates=['ts']) login_data['day'] = login_data['ts'].map(lambda x: x.strftime('%Y-%m-%d')) login_data['dt_ts'] = pd.to_datetime(login_data['day'], format='%Y-%m-%d') login_data.head()

2.構造新的dataframe,計算日期,之後與原數據進行連接。
data_1 = login_data.copy() data_1['dt_ts_1'] = data_1['dt_ts'] + timedelta(-1) data_1.head()

3.合併前面的兩個數據,使用uid和dt_ts 關聯,dt_ts_1是當前日期減一天,左邊是第一天活躍的用戶,右邊是第二天活躍的用戶
merge_1 = pd.merge(login_data, data_1, left_on=['uid', 'dt_ts'], right_on=['uid', 'dt_ts_1'], how='left') merge_1.head(10)

4.計算第一天活躍的用戶數
init_user = merge_1.groupby('day_x').aggregate({'uid': lambda x: x.nunique()}) init_user.reset_index(inplace=True) init_user.head()

5.計算次日活躍的用戶數
one_day_remain_user = merge_1[merge_1['day_y'].notnull()].groupby('day_x').aggregate({'uid': lambda x: x.nunique()}) one_day_remain_user.reset_index(inplace=True) one_day_remain_user.head()

6.合併前面兩步的結果,計算最終留存
merge_one_day = pd.merge(init_user, one_day_remain_user, on=['day_x']) merge_one_day['one_remain_rate'] = merge_one_day['uid_y'] / merge_one_day['uid_x'] merge_one_day['one_remain_rate'] = merge_one_day['one_remain_rate'].apply(lambda x: format(x, '.2%')) merge_one_day.head(20)

多日留存計算
方法一:
多日留存的計算可以沿用SQL中的思路,關聯時先不用帶日期條件
1.計算日期差,為後續做準備
merge_all = pd.merge(login_data, login_data, on=['uid'], how='left') merge_all['diff'] = (merge_all['dt_ts_y'] - merge_all['dt_ts_x']).map(lambda x: x.days)#使用map取得具體數字 merge_all.head()
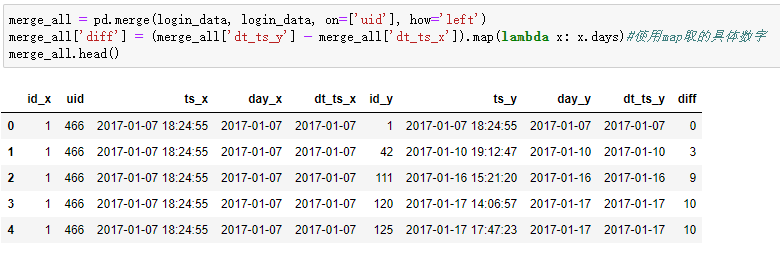
2.計算第n天的留存人數,n=0,1,6,13。需要先進行篩選再進行計數,仍然使用nunique
diff_0 = merge_all[merge_all['diff'] == 0].groupby('day_x')['uid'].nunique() diff_1 = merge_all[merge_all['diff'] == 1].groupby('day_x')['uid'].nunique() diff_6 = merge_all[merge_all['diff'] == 6].groupby('day_x')['uid'].nunique() diff_13 = merge_all[merge_all['diff'] == 13].groupby('day_x')['uid'].nunique() diff_0 = diff_0.reset_index()#groupby計數後得到的是series格式,reset得到dataframe diff_1 = diff_1.reset_index() diff_6 = diff_6.reset_index() diff_13 = diff_13.reset_index()
3.對多個dataframe進行一次合併
liucun = pd.merge(pd.merge(pd.merge(diff_0, diff_1, on=['day_x'], how='left'), diff_6, on=['day_x'], how='left'), diff_13, on=['day_x'], how='left') liucun.head()

4.對結果重命名,並用0填充na值
liucun.columns=['day', 'init', 'one_day_remain', 'seven_day_remain', 'fifteen_day_remain']#後來發現英文寫錯了,將就看,懶得改了 liucun.fillna(0, inplace=True) liucun.head(20)

得到的結果和SQL計算的一致,同樣省略了百分比轉換的代碼。
方法二:
這種方法是從網上看到的,也放在這裡供大家學習,文末有鏈接。它沒有用自關聯,而是對日期進行循環,計算當日的活躍用戶數和n天后的活躍用戶數。把n作為參數傳入封裝好的函數中。參考下面代碼:
def cal_n_day_remain(df, n): dates = pd.Series(login_data.dt_ts.unique()).sort_values()[:-n]#取截止到n天的日期,保證有n日留存 users = [] #定義列表存放初始用戶數 remains = []#定義列表存放留存用戶數 for d in dates: user = login_data[login_data['dt_ts'] == d]['uid'].unique()#當日活躍用戶 user_n_day = login_data[login_data['dt_ts']==d+timedelta(n)]['uid'].unique()#n日後活躍用戶 remain = [x for x in user_n_day if x in user]#取交集 users.append(len(user)) remains.append(len(remain)) #一次循環計算一天的n日留存 #循環結束後構造dataframe並返回 remain_df = pd.DataFrame({'days': dates, 'user': users, 'remain': remains}) return remain_df
代碼的邏輯整體比較簡單,必要的部分我做了注釋。但需要一次一次調用,最後再merge起來。最後結果如下所示,從左到右依次是次日,7日,14日留存,和前面結果一樣(可以再重命名一下)。
one_day_remain = cal_n_day_remain(login_data, 1) seven_day_remain = cal_n_day_remain(login_data, 6) fifteen_day_remain = cal_n_day_remain(login_data, 13) liucun2 = pd.merge(pd.merge(one_day_remain, seven_day_remain[['days', 'remain']], on=['days'], how='left'), fifteen_day_remain[['days', 'remain']], on=['days'], how='left') liucun2.head(20)

至此,我們完成了SQL和pandas對日活和留存率的計算。
小結
本篇文章我們研究了非常重要的兩個概念,日活和留存。探討了如何用SQL和pandas進行計算。日活計算比較簡單。留存計算可以有多種思路。
推薦閱讀:


