爬蟲(14) – Scrapy-Redis分佈式爬蟲(1) | 詳解
- 2022 年 7 月 6 日
- 筆記
- scrapy-redis, 測試開發 - python, 測試高級進階 - 爬蟲, 爬蟲
1.什麼是Scrapy-Redis
- Scrapy-Redis是scrapy框架基於redis的分佈式組件,是scrapy的擴展;分佈式爬蟲將多台主機組合起來,共同完成一個爬取任務,快速高效地提高爬取效率。
- 原先scrapy的請求是放在內存中,從內存中獲取。scrapy-redisr將請求統一放在redis裏面,各個主機查看請求是否爬取過,沒有爬取過,排隊入隊列,主機取出來爬取。爬過了就看下一條請求。
- 各主機的spiders將最後解析的數據通過管道統一寫入到redis中
- 優點:加快項目的運行速度;單個節點的不穩定性不影響整個系統的穩定性;支持端點爬取
- 缺點:需要投入大量的硬件資源,硬件、網絡帶寬等
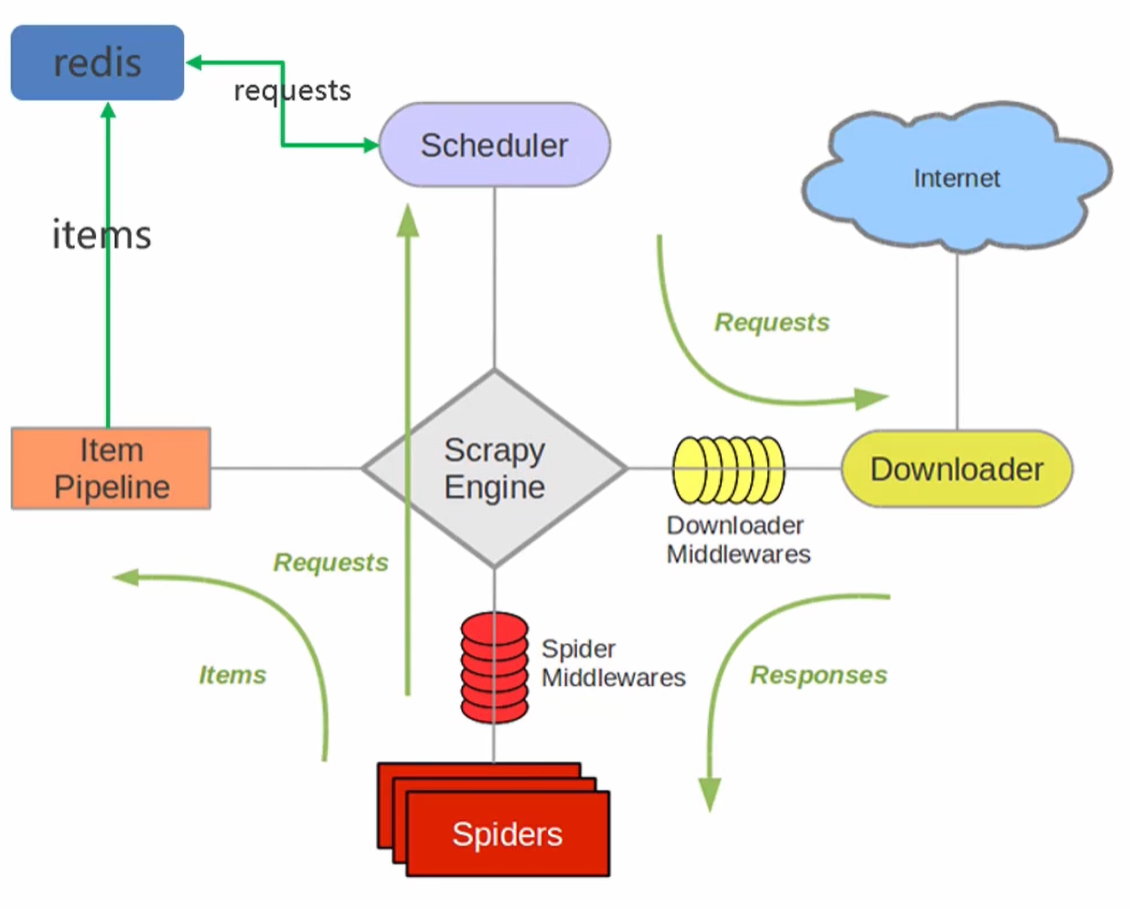
- 在scrapy框架流程的基礎上,把存儲request對象放到了redis的有序集合中,利用該有序集合實現了請求隊列
- 並對request對象生成指紋對象,也存儲到同一redis的集合中,利用request指紋避免發送重複的請求
2.Scrapy-Redis分佈式策略
假設有三台電腦:Windows 10、Ubuntu 16.04、Windows 10,任意一台電腦都可以作為 Master端 或 Slaver端,比如:
- Master端(核心服務器) :使用 Windows 10,搭建一個Redis數據庫,不負責爬取,只負責url指紋判重、Request的分配,以及數據的存儲。
- Slaver端(爬蟲程序執行端) :使用 Ubuntu 16.04、Windows 10,負責執行爬蟲程序,運行過程中提交新的Request給Master。
首先Slaver端從Master端拿任務(Request、url)進行數據抓取,Slaver抓取數據的同時,產生新任務的Request便提交給 Master 處理
Master端只有一個Redis數據庫,負責將未處理的Request去重和任務分配,將處理後的Request加入待爬隊列,並且存儲爬取的數據。
Scrapy-Redis默認使用的就是這種策略,我們實現起來很簡單,因為任務調度等工作Scrapy-Redis都已經幫我們做好了,我們只需要繼承RedisSpider、指定redis_key就行了。
缺點是,Scrapy-Redis調度的任務是Request對象,裏面信息量比較大(不僅包含url,還有callback函數、headers等信息),可能導致的結果就是會降低爬蟲速度、而且會佔用Redis大量的存儲空間,所以如果要保證效率,那麼就需要一定硬件水平。
3.Scrapy-Redis的安裝和項目創建
3.1.安裝scrapy-redis
pip install scrapy-redis
3.2.項目創建前置準備
- win 10
- Redis安裝:redis相關配置參照這個//www.cnblogs.com/gltou/p/16226721.html;如果跟着筆記學到這的,前面鏈接那個redis版本3.0太老了,需要重新安裝新版本,新版本下載鏈接://pan.baidu.com/s/1UwhJA1QxDDIi2wZFFIZwow?pwd=thak,提取碼:thak;
- Another Redis Desktop Manager:這個軟件是用於查看redis中存儲的數據,安裝也很簡單,一直下一步即可;下載鏈接://pan.baidu.com/s/18CC2N6XtPn_2NEl7gCgViA?pwd=ju81 提取碼:ju81
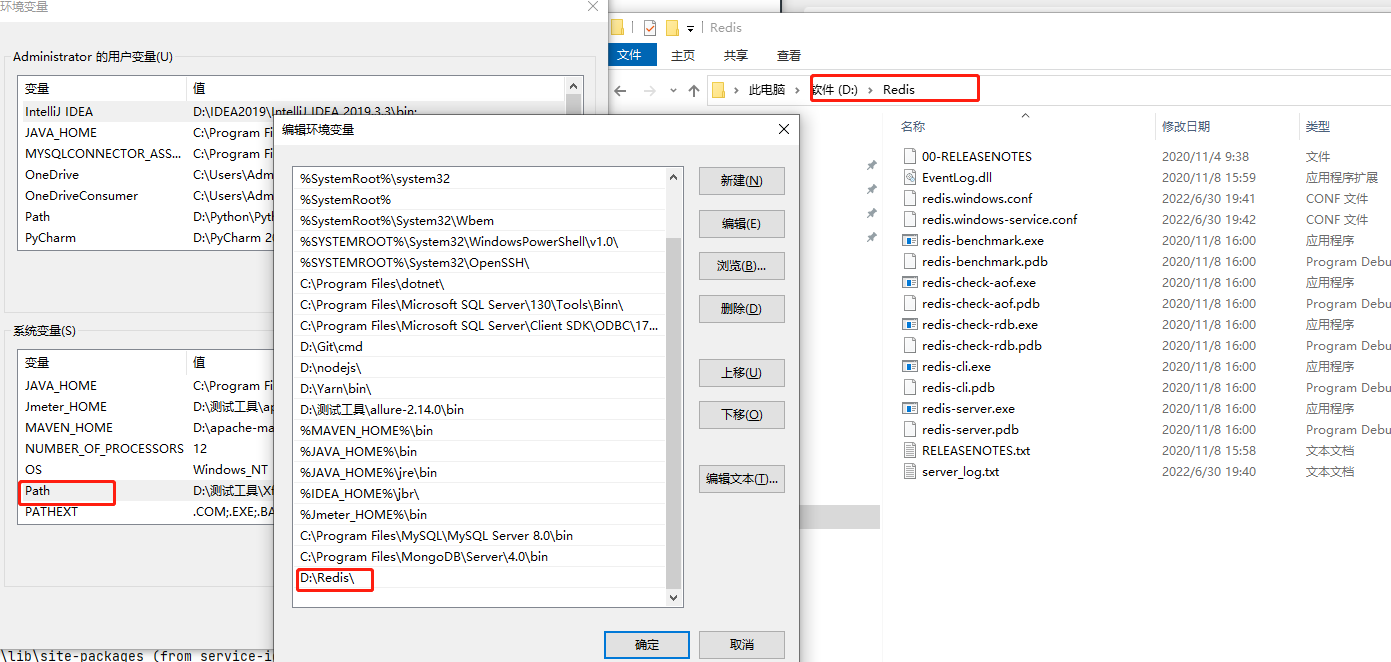
Redia安裝簡單講解:安裝包下載下來後,點擊下一步一直安裝就行,把安裝路徑記錄好;注意安裝好後需要將redis的安裝目錄添加到環境變量中;每當你修改了配置文件,需要重啟redis時,要記得將服務重啟下
Another Redis Desktop Manager簡單講解:點擊【New Connection】添加redis連接,連接內容如下(地址、端口等),密碼Auth和昵稱Name不是必填。

可以看到redis安裝的環境、當前redis的版本、內存、連接數等信息。後面我們的筆記會講解通過該軟件查看待抓取的URL以及URL的指紋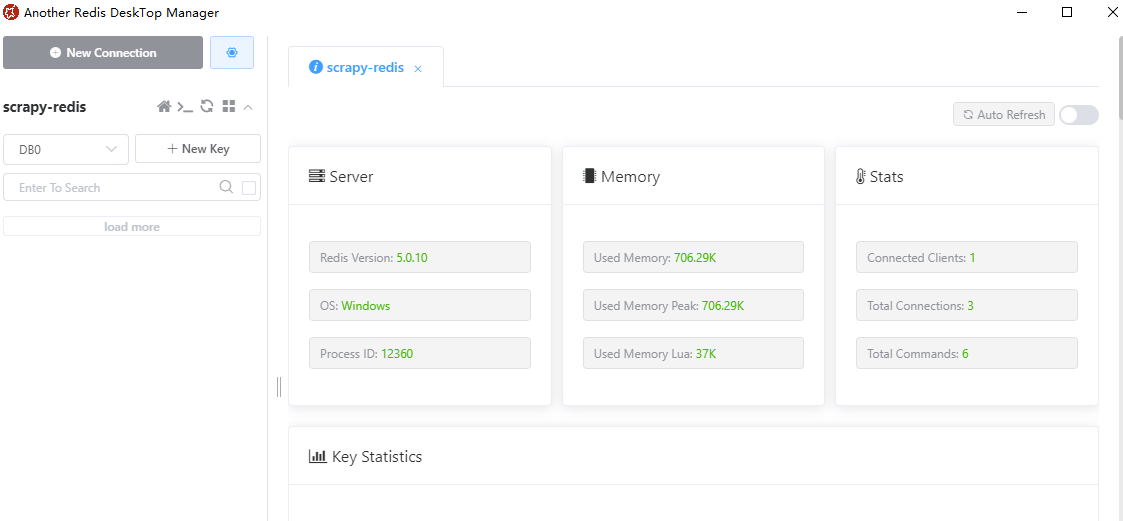
3.3.項目創建
創建普通scrapy爬蟲項目,在普通的項目上改造成scrapy-redis項目;普通爬蟲分為四個階段:創建項目、明確目標、創建爬蟲、保存內容;
scrapy爬蟲項目創建好後,進行改造,具體改造點如下:
- 導入scrapy-redis中的分佈式爬蟲類
- 繼承類
- 注釋start_url & allowed_domains
- 設置redis_key獲取start_urls
- 編輯settings文件
3.3.1.創建scrapy爬蟲
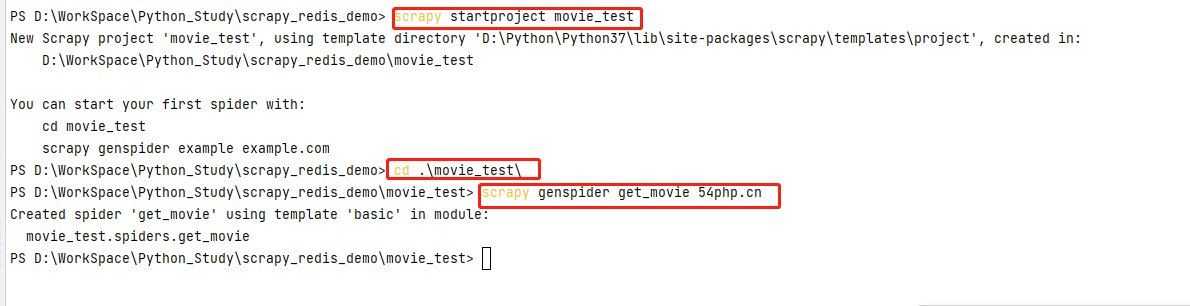
step-1:創建項目
創建scrapy_redis_demo目錄,在該目錄下輸入命令 scrapy startproject movie_test ,生成scrapy項目👉cd到movie_test項目下 cd .\movie_test\ 👉輸入命令 scrapy genspider get_movie 54php.cn 生成spiders模板文件;這個過程不清楚的,轉到//www.cnblogs.com/gltou/p/16400449.html學習下
step-2:明確目標
在items.py文件中,明確我們此次需要爬取目標網站哪些數據。
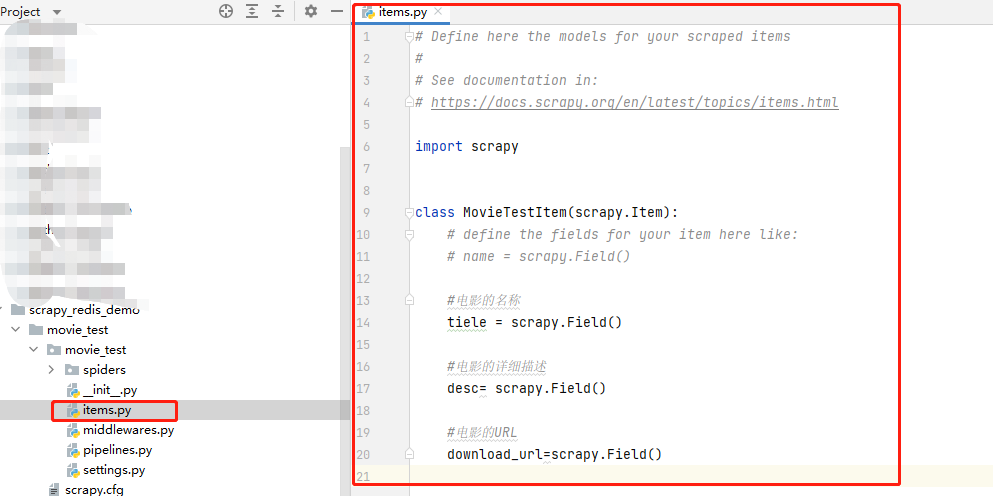
1 # Define here the models for your scraped items 2 # 3 # See documentation in: 4 # //docs.scrapy.org/en/latest/topics/items.html 5 6 import scrapy 7 8 9 class MovieTestItem(scrapy.Item): 10 # define the fields for your item here like: 11 # name = scrapy.Field() 12 13 #電影的名稱 14 tiele = scrapy.Field() 15 16 #電影的詳細描述 17 desc= scrapy.Field() 18 19 #電影的URL 20 download_url=scrapy.Field()
step-3:創建爬蟲
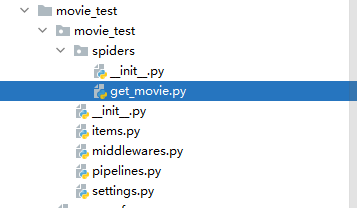
導入items.py的類,在get_movie.py文件中編寫我們的爬蟲文件,下面為get_movie.py的code代碼
import scrapy from ..items import MovieTestItem class GetMovieSpider(scrapy.Spider): name = 'get_movie' allowed_domains = ['54php.cn'] start_urls = ['//movie.54php.cn/movie/'] def parse(self, response): movie_item=response.xpath("//div[2][@class='row']/div") for i in movie_item: #詳情頁url detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first() yield scrapy.Request(url=detail_url,callback=self.parse_detail) next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first() if next_page: next_page_url='//movie.54php.cn{}'.format(next_page) yield scrapy.Request(url=next_page_url,callback=self.parse) def parse_detail(self,response): """解析詳情頁""" movie_info=MovieTestItem() movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first() movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first() movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first() yield movie_info
在settings.py文件中啟用 USER_AGENT 並將網站的value放進去;將 ROBOTSTXT_OBEY 協議改為False

step-4:保存內容
此處暫時不寫,先忽略,後面改成scrapy-redis寫入redis時,再編寫相關代碼
step-5:運行爬蟲,查看結果
輸入命令 scrapy crawl get_movie 運行爬蟲,查看結果; finish_reason 為finished運行結束、 item_scraped_count 共爬取1060條數據、 log_count/DEBUG 日誌文件中DEBUG記錄共2192條等結果信息。
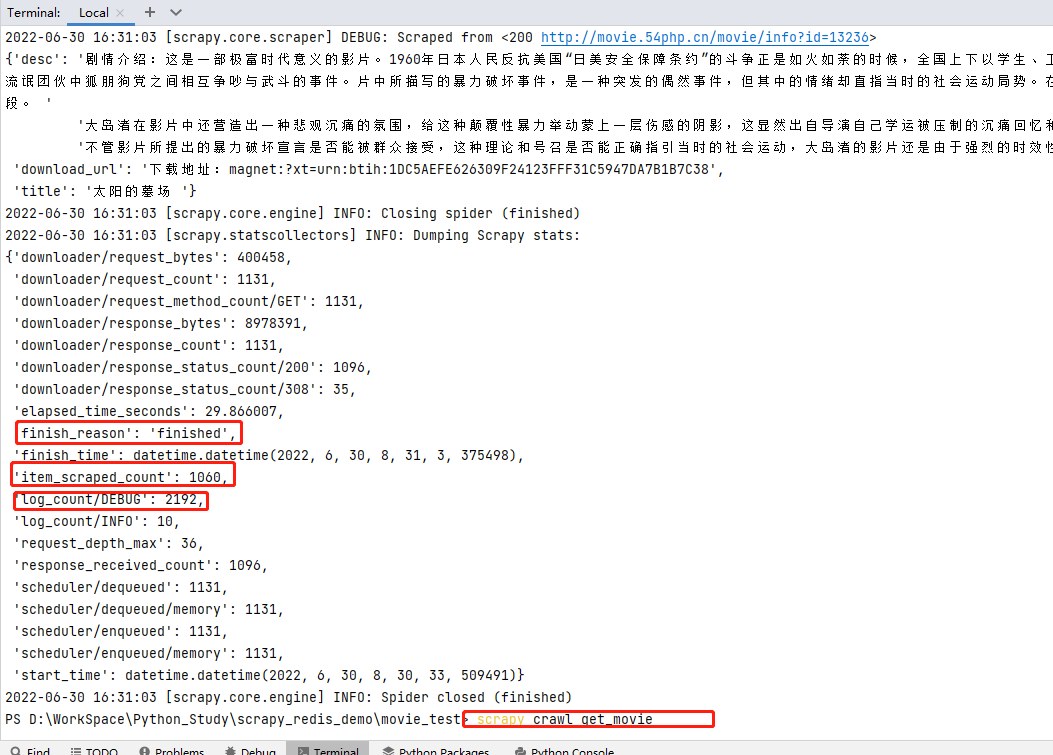
scrapy項目創建且運行成功,下面將進行scrapy-redis改造
3.3.2.改為scrapy-redis爬蟲
step-1:修改爬蟲文件
get_movie.py爬蟲文件引入 scrapy_redis 的 RedisSpider 類,並繼承他;將 allowed_domains 和 start_urls 注釋掉;新增 redis_key ,值value 是一個鍵值對,key就是name值即爬蟲名字,value就是start_urls這個變量名
1 import scrapy 2 from ..items import MovieTestItem 3 from scrapy_redis.spiders import RedisSpider 4 5 class GetMovieSpider(RedisSpider): 6 name = 'get_movie' 7 # allowed_domains = ['54php.cn'] 8 # start_urls = ['//movie.54php.cn/movie/'] 9 redis_key = "get_movie:start_urls" 10 11 def parse(self, response): 12 movie_item=response.xpath("//div[2][@class='row']/div") 13 for i in movie_item: 14 #詳情頁url 15 detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first() 16 yield scrapy.Request(url=detail_url,callback=self.parse_detail) 17 18 next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first() 19 if next_page: 20 next_page_url='//movie.54php.cn{}'.format(next_page) 21 yield scrapy.Request(url=next_page_url,callback=self.parse) 22 23 def parse_detail(self,response): 24 """解析詳情頁""" 25 movie_info=MovieTestItem() 26 movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first() 27 movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first() 28 movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first() 29 yield movie_info 30 31
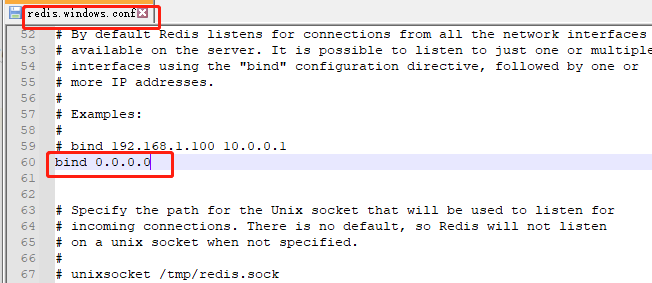
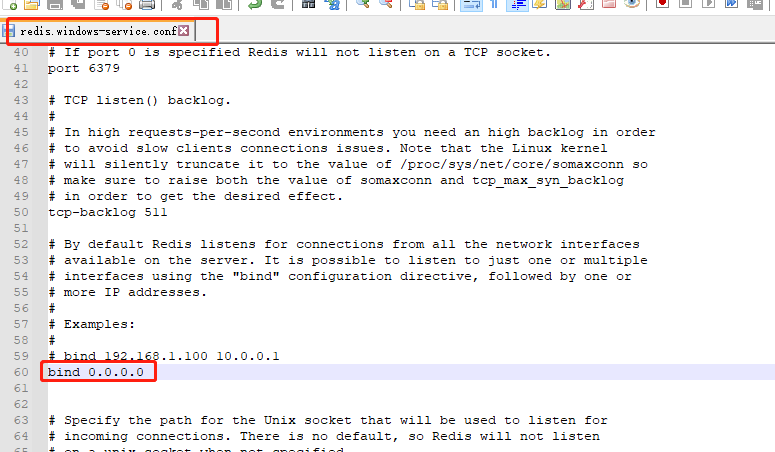
step-2:修改redis配置文件
將redis.windows.conf和redis.windows-service.conf文件中 bind 設置成 0.0.0.0 ,重啟redis服務
step-3:redis存入種子url
cmd輸入 redis-cli 進入redis命令行,如果有密碼,追加命令 auth 密碼 如圖

將爬蟲get_movie.py文件中設置的 redis_key (是一個鍵值對,key就是 name 值即爬蟲名字,value就是 start_urls 這個變量名),在redis中lpush一下;redis命令行輸入lpush後會將命令格式帶出來,不用管他,在lpush後面輸入key和value值
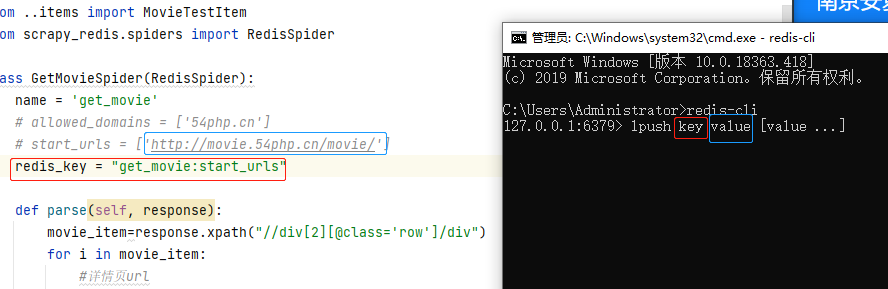
lpush的key值就是代碼中的 redis_key 的值,value是 start_urls 的值,輸入好後,按下Enter鍵

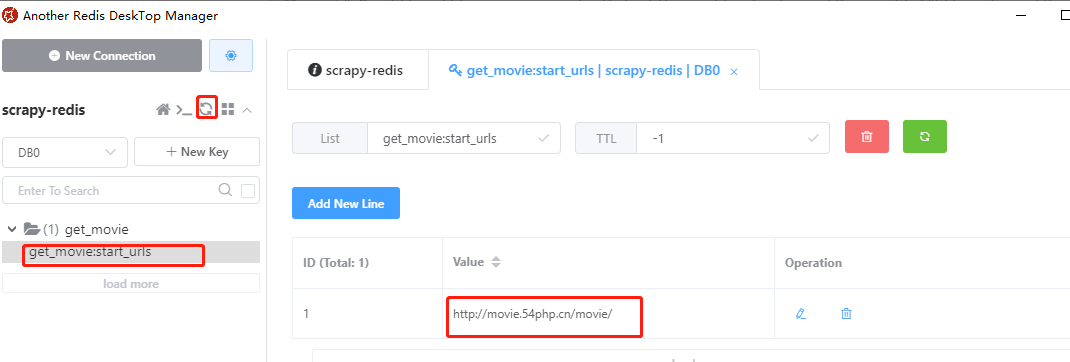
在Another Redis Desktop Manager軟件中檢查是否添加成功,發現添加成功
step-4:配置文件添加組件及redis參數
settings.py文件中添加設置去重組件和調度組件,添加redis連接信息;
1 # 設置去重組件 2 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" 3 # 調度組件 4 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 5 6 #redis 連接信息 7 REDIS_HOST = "127.0.0.1" 8 REDIS_PORT = 6379 9 REDIS_ENCODING = 'utf-8' 10 #REDIS_PARAMS = {"password":"123456"}
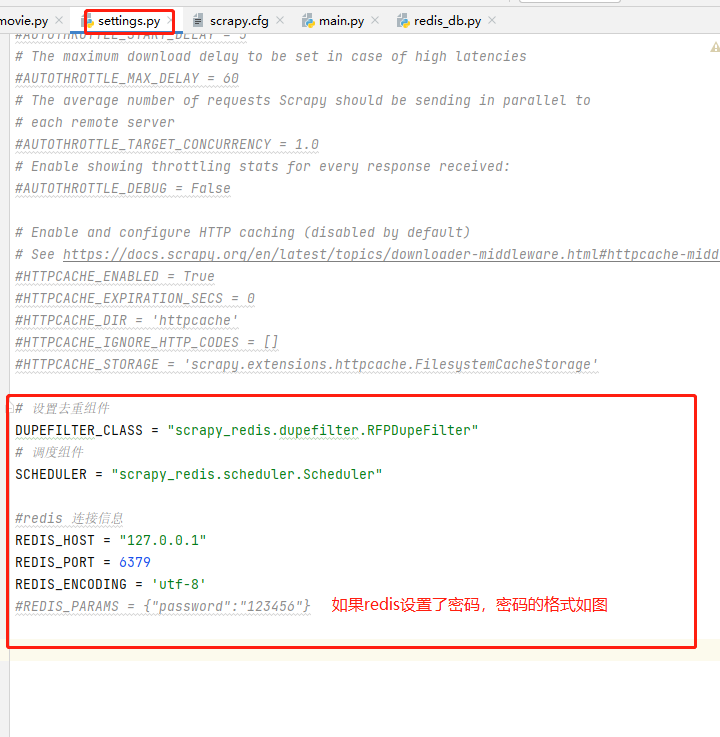
疑問:有人肯定會問,我在settings.py文件中添加了redis的信息,scrapy框架是怎麼拿到的呢?
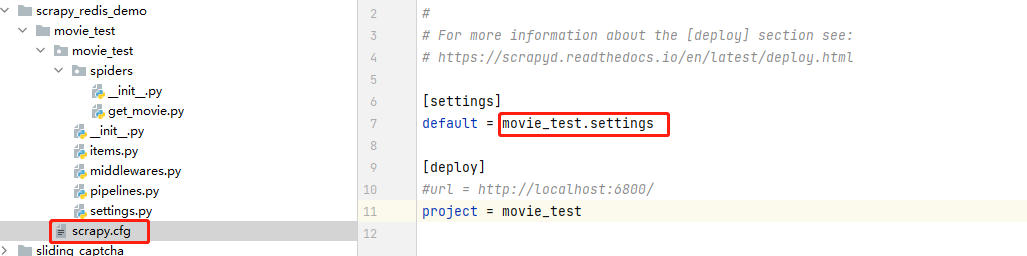
答案:其實在//www.cnblogs.com/gltou/p/16400449.html這篇的筆記中已經講到了,scrapy框架的scrapy.cfg文件裏面會告訴框架配置文件在哪邊,如圖,即在movie_test目錄下的settings文件中
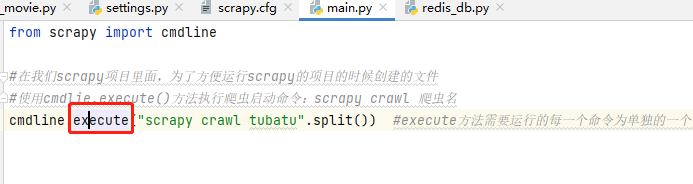
然後scrapy運行怕從文件是通過cmdline的execute方法運行的 ,這個方法其中執行的get_project_settings( )方法,就是導入全局配置文件scrapy.cfg,進而導入項目的settings .py
通過get_project_settings( )這個方法的project.py文件,我們在from部分看到導入了Settings,感興趣的可以自己研究下源碼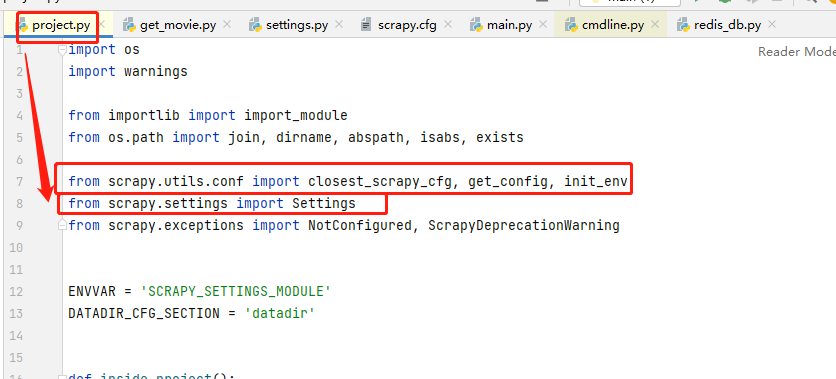
step-5:運行爬蟲文件
pycharm輸入命令 scrapy crawl get_movie 運行爬蟲文件
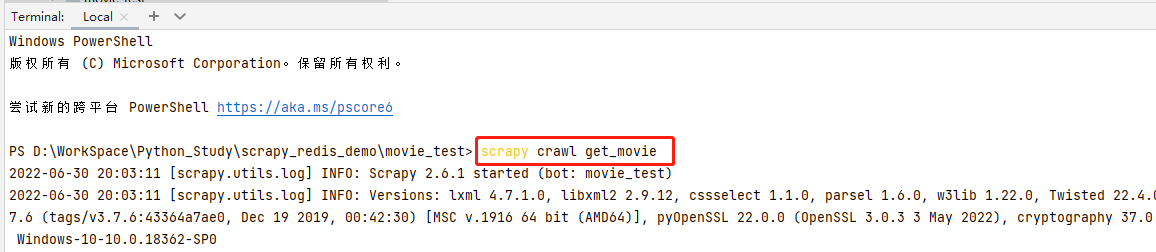
常見報錯:

報錯分析: 這個是因為我們安裝scrapy版本問題導致的,安裝Scrapy==2.5.1 版本即可
解決方案:
pip install -U Scrapy==2.5.1 -i //pypi.tuna.tsinghua.edu.cn/simple/

注意:在pycharm中重新安裝後,啟動爬蟲文件如果還報錯。在cmd窗口再執行一下pip命令,問題就解決了
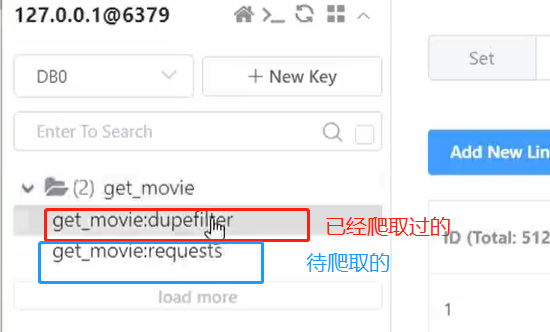
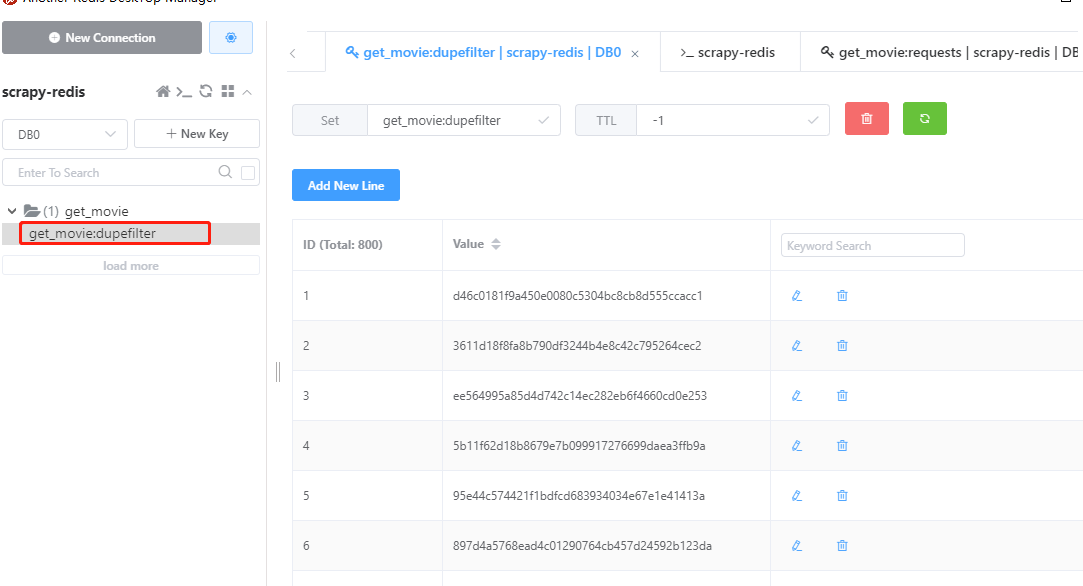
運行爬蟲腳本,爬取過程中,發現redis有兩張表(易於理解的描述), get_movie:dupefilter 代表已經爬取過的URL, get_movie:requests 代表待爬取的url
爬蟲腳本執行成功,查看redis,發現value裏面有好多數據,這些數據都是hash值,已經爬取過的url就會以hash的方式存儲到value裏面,這樣就不會重複爬取同一個url。爬取結束後,pycharm中按ctrl+c停止腳本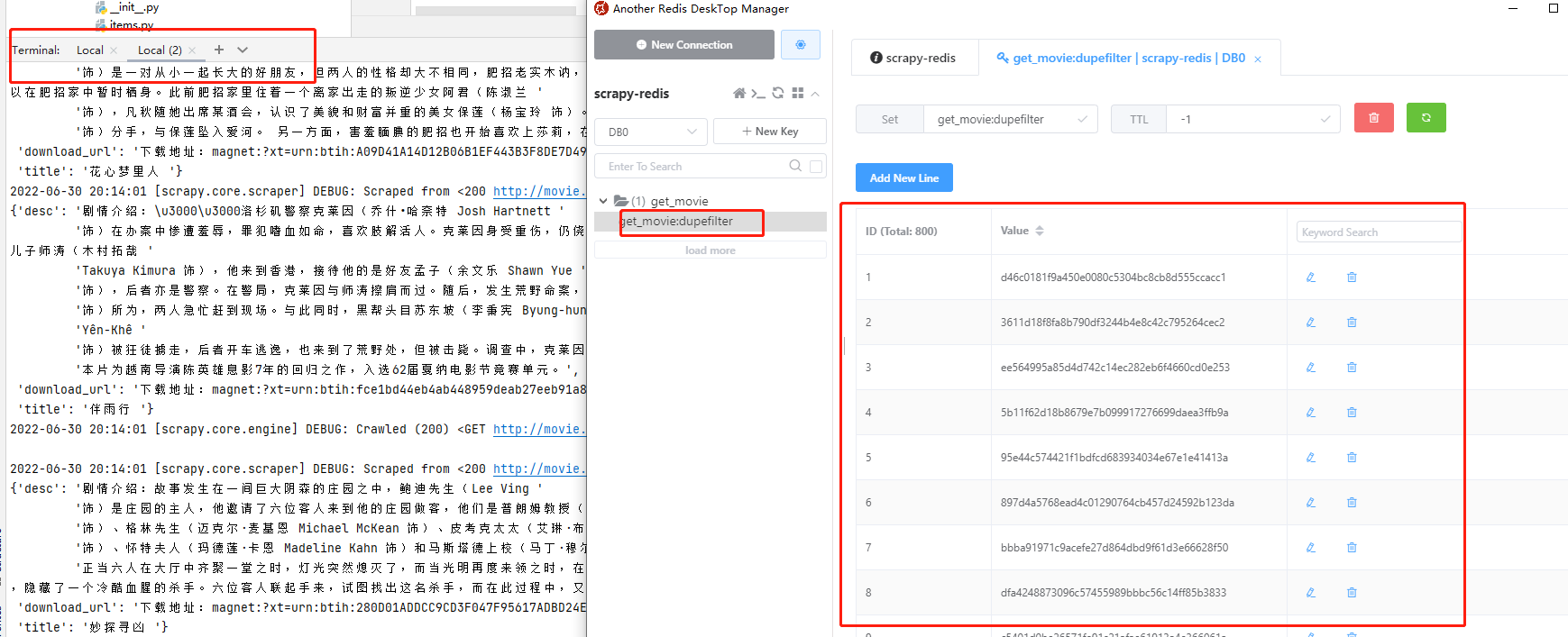
step-6:再次爬取
爬蟲腳本執行結束後,redis裏面種子url沒有了。想要再次執行爬蟲腳本,需要將種子再下發給redis,即再執行一次lpush命令,就又可以執行爬蟲腳本了。

再次下發種子

執行腳本再次爬取

3.3.3.斷點續爬
當爬蟲爬取一半中斷時,設置了斷點續爬後,爬蟲會接着爬取,而不會再次重新爬取數據。如何實現斷點續爬,很簡單,再settings.py文件中開啟斷點續爬即可
1 #斷點續爬 2 SCHEDULER_PERSIST = True
示例
場景:爬蟲到一半我們CTRL+C停止爬蟲腳本👉再次啟動爬蟲腳本👉爬取結束後,沒有種子url的情況下再次執行爬蟲腳本
步驟:
step-1:redis放入種子url執行爬蟲,強制停止爬蟲腳本
LPUSH get_movie:start_urls //movie.54php.cn/movie/
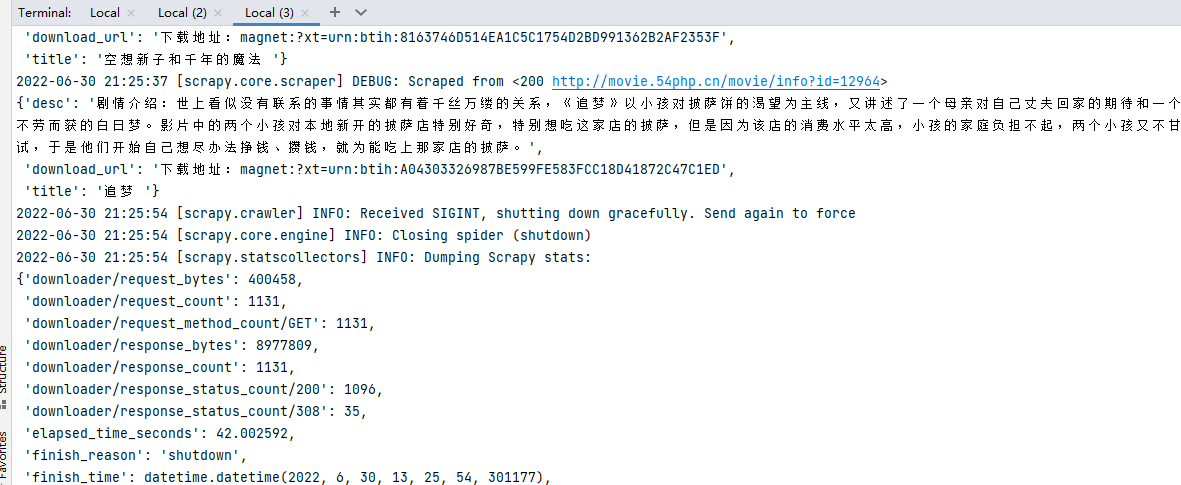

結果:爬取到一半,我們強制停止爬蟲腳本,發現redis裏面requests的數據還在,沒有消失
step-2:再次啟動爬蟲文件


結果:最後腳本結束統計的爬取數量是第二次爬取的數量,而不是總的數量
step-3:當爬取結束後,我們再次啟動爬蟲文件
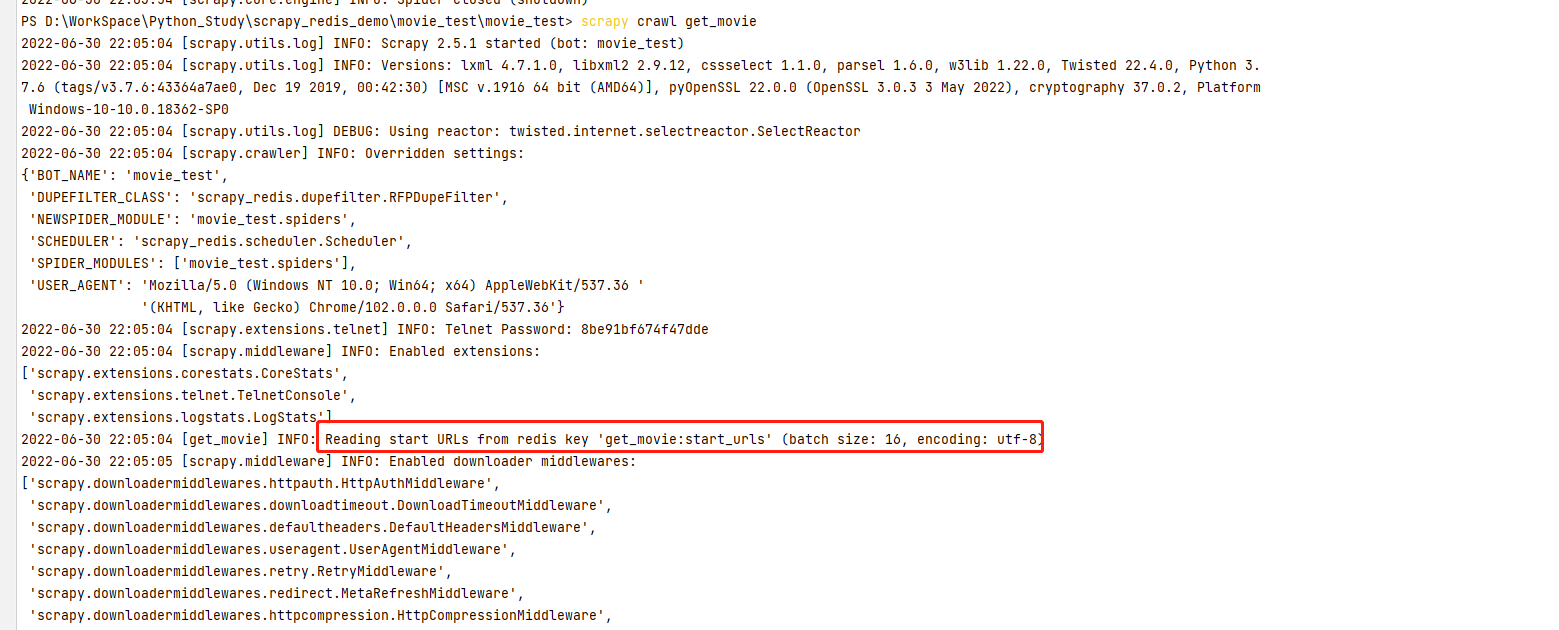
結果:控制台告訴我們 start_urls 已經抓取過了,你要抓取的url在 get_movie:dupefilter 裏面都有了,不要要再爬取了
————————————————————————————————————————————
思考:在不重新給種子url的情況下,我就是想多次爬取怎麼辦?
解決方案:在爬蟲文件parse方法裏面yield回調的時候,加上參數 dont_filter=True 即可再次爬取;dont_filter是scrapy過濾重複請求的,默認為False可以過濾dupefilter中已經抓取過去的請求,避免重複抓取,改為True後即為不過濾,可以再次請求爬取,scrapy提供了這個參數就是讓自己去決定這個數據是應該過濾掉還是可以重複抓取
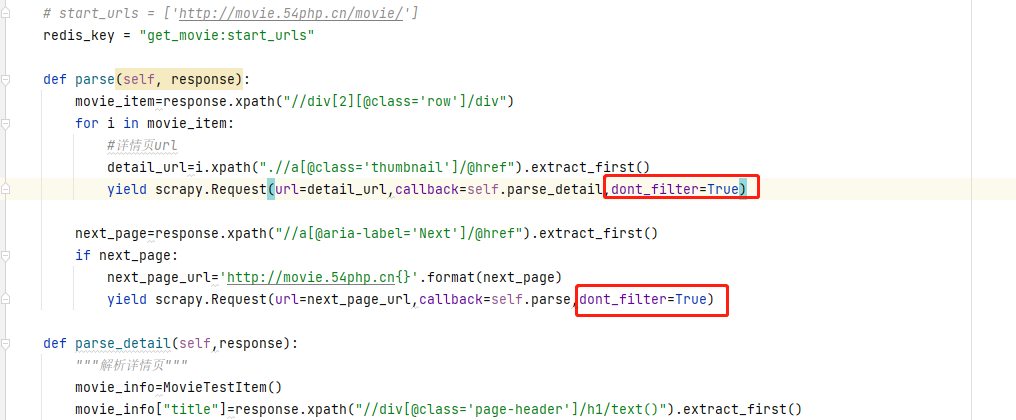
示例
step-1:下發種子url,執行爬蟲,等待爬蟲結束



step-2:爬取結束,按下CTRL+C停止腳本,按照圖示點擊Flush DB清空DB,再次執行爬蟲腳本;沒有傳入種子URL的情況下,爬蟲可以照常爬取

3.4.實現分佈式爬蟲
通過實例項目來講解分佈式爬蟲的實現;
內容較多,在新的隨筆裏面://www.cnblogs.com/gltou/p/16433539.html


