Http實戰之Wireshark抓包分析
Http實戰之Wireshark抓包分析
Http相關的文章網上一搜一大把,所以筆者這一系列的文章不會只陳述一些概念,更多的是通過實戰(抓包+代碼實現)的方式來跟大家討論Http協議中的各種細節,幫助大家理解那些反反覆復記不住的的概念!
搭建測試項目
我們選用netty搭建一個服務端,使用httpclient來實現http客戶端。
對netty或者httpclient不熟悉的同學不用擔心,涉及到的代碼都非常簡單。
服務端我之所以選用這兩個框架是因為相對來說,它們對http協議的封裝較淺,在後面的文章中我可以帶大家看看代碼層次上http協議是如何封裝的,這樣可以將http協議理解的更加透徹,在本文中大家將注意力放到抓包的分析過程即可!
代碼如下:
pom文件引入依賴:
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.65.Final</version>
</dependency>
<!-- //mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
服務端代碼:
public class HttpServer {
public static void main(String[] args) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.option(ChannelOption.SO_BACKLOG, 1024);
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new HttpHelloWorldServerInitializer());
Channel ch = b.bind(8080).sync().channel();
ch.closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
public class HttpHelloWorldServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
// 我們搭建的是一個http服務器,要使用http編解碼器
p.addLast(new HttpServerCodec());
// http請求處理核心類
p.addLast(new HttpHelloWorldServerHandler());
}
}
/**
* 這個類是處理http請求的核心類,這裡我們簡單處理
* 不論收到什麼信息我們都返回Hello World
*/
public class HttpHelloWorldServerHandler extends SimpleChannelInboundHandler<HttpObject> {
private static final byte[] CONTENT = { 'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd' };
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
ctx.flush();
}
@Override
public void channelRead0(ChannelHandlerContext ctx, HttpObject msg) {
if (msg instanceof HttpRequest) {
HttpRequest req = (HttpRequest) msg;
FullHttpResponse response = new DefaultFullHttpResponse(req.protocolVersion(), OK,Unpooled.wrappedBuffer(CONTENT));
response.headers()
.set(CONTENT_TYPE, TEXT_PLAIN)
.setInt(CONTENT_LENGTH, response.content().readableBytes());
ctx.write(response);
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
客戶端代碼如下:
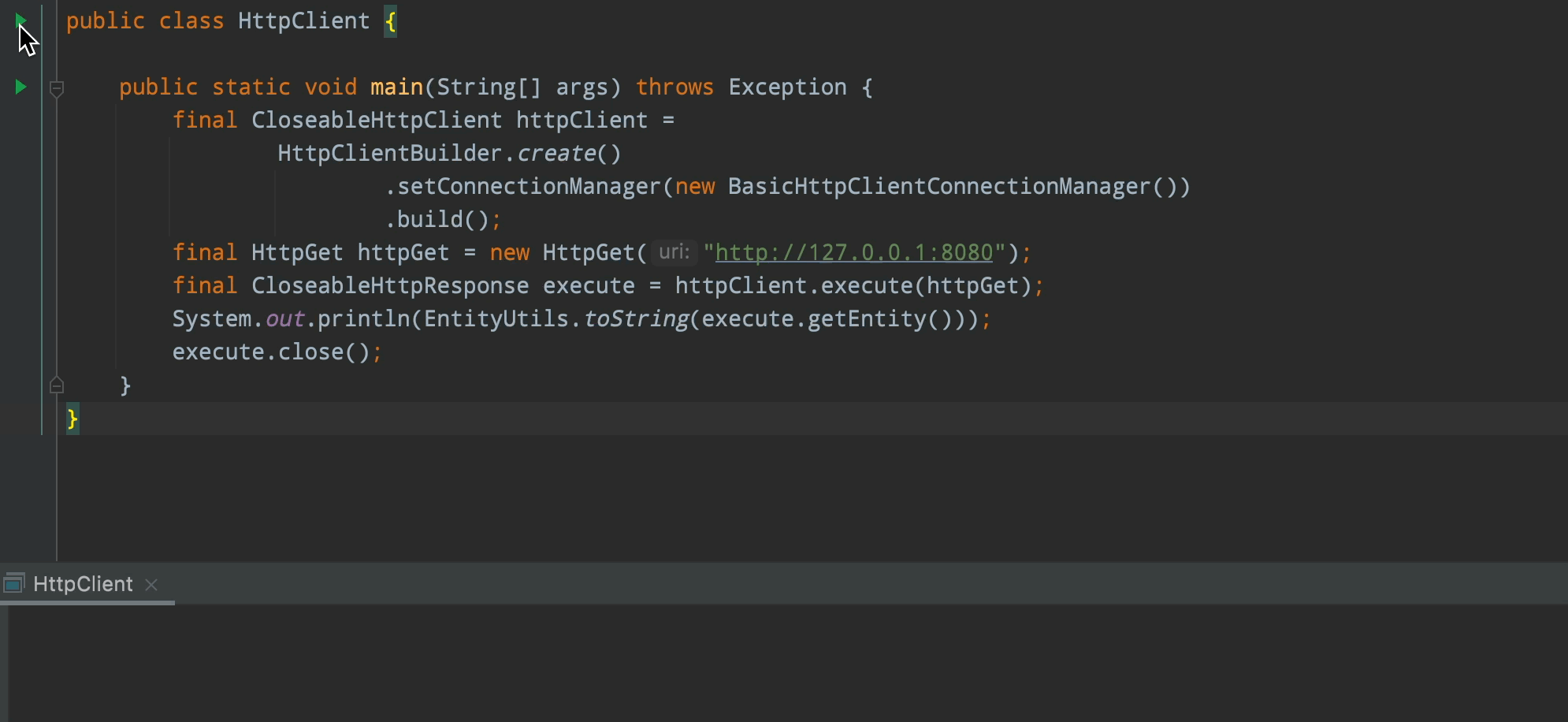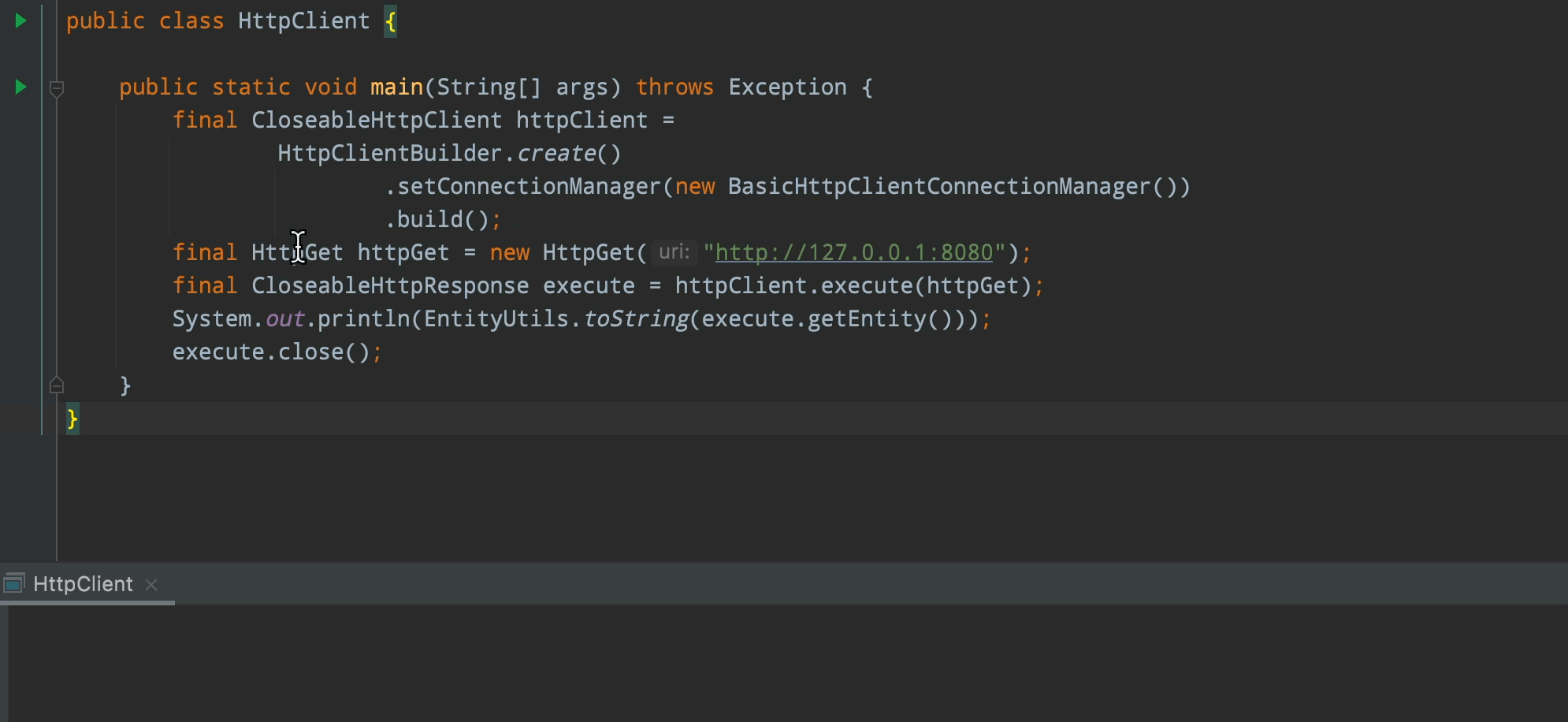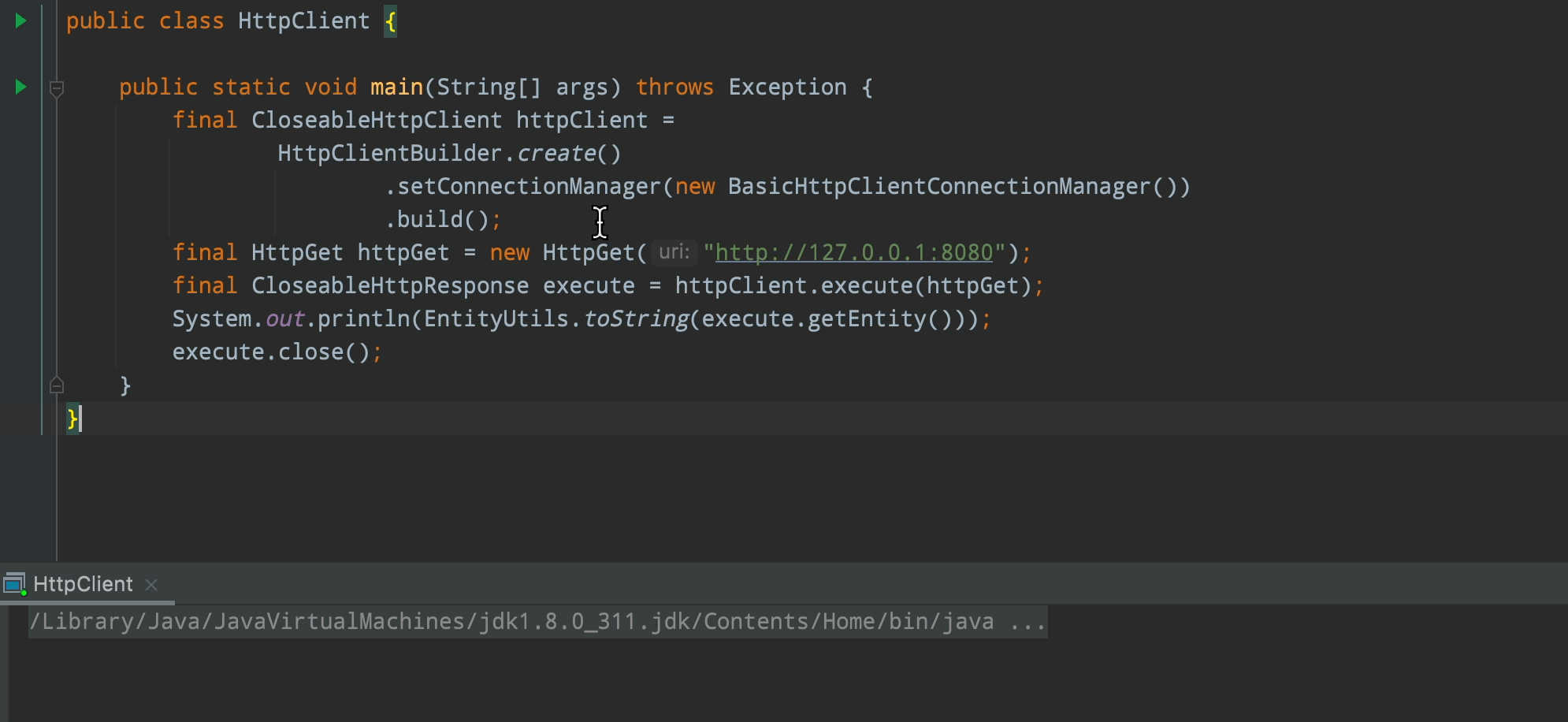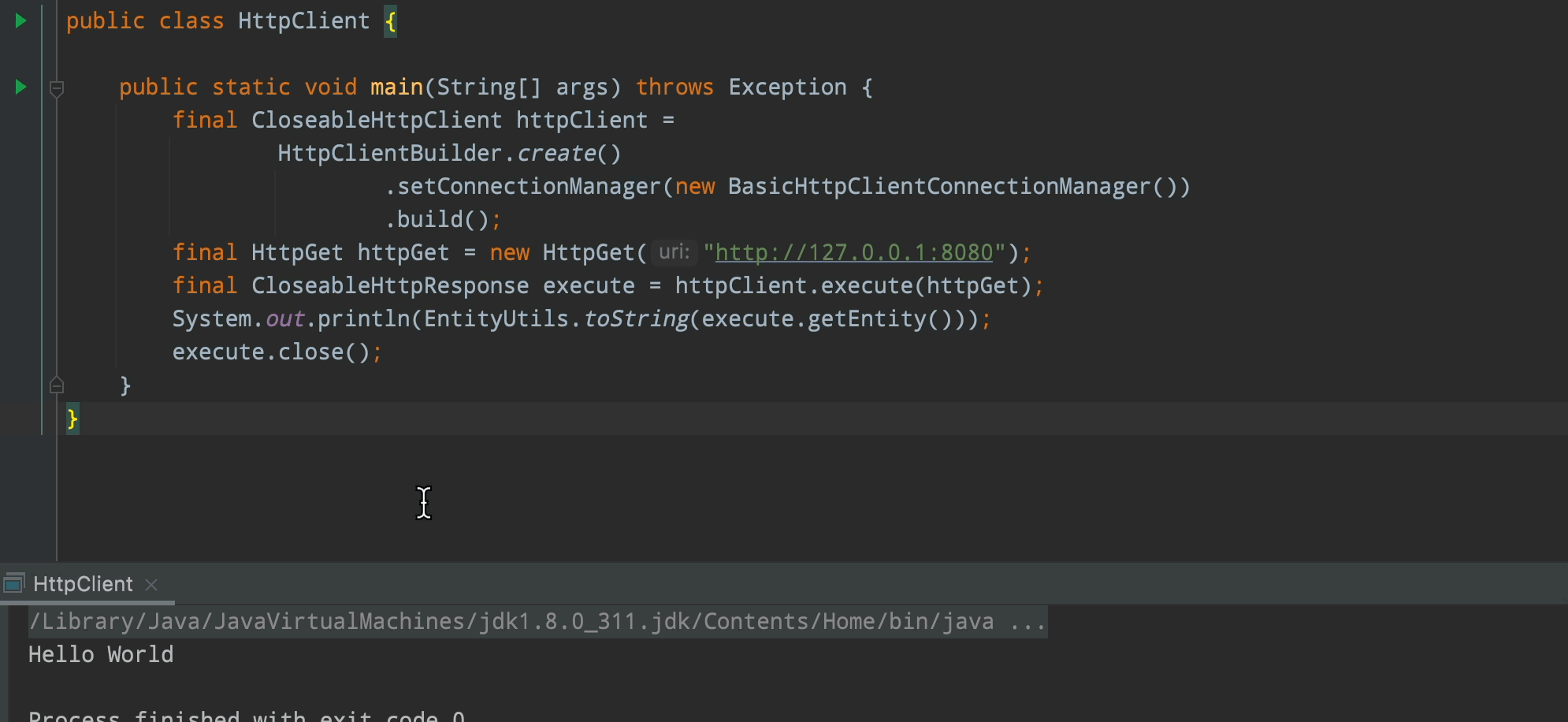
public class HttpClient {
public static void main(String[] args) throws Exception {
final CloseableHttpClient httpClient =
HttpClientBuilder.create()
.setConnectionManager(new BasicHttpClientConnectionManager())
.build();
final HttpGet httpGet = new HttpGet("//127.0.0.1:8080");
final CloseableHttpResponse execute = httpClient.execute(httpGet);
System.out.println(EntityUtils.toString(execute.getEntity()));
// 這裡代碼並不規範哈,正常應該try catch finally,不過這不是本文重點
execute.close();
}
}
我們將服務端啟動後,運行客戶端正常輸出「Hello World」說明項目搭建成功
Wireshark簡單介紹
Wireshark(前身 Ethereal)是一個網絡包分析工具。該工具主要是用來捕獲網絡數據包,並自動解析數據包,為用戶顯示數據包的詳細信息,供用戶對數據包進行分析。
下載成功後,我們打開主界面如下:

這裡我們看到的這個列表是我們本機的網卡列表,我們在抓包之前要確認具體的網卡,常用的網卡就是我在圖中框選的兩個
lo0:迴環網卡,對應localhost/127.0.0.1等本地服務
舉個例子,如果我要請求//localhost:12345/xxx這個服務,對應的網卡就選擇lo0。127.0.0.1的服務同理。en0:外網請求,比如,我要在瀏覽器訪問 www.baidu.com/ 這個服務,對應的網卡一般選en0。
那麼如何確定我們要抓取的數據包對應的網卡是哪個呢?
現在要確定當我們訪問www.baidu.com使用的是哪個網卡,我們可以執行如下操作:
- 監聽
www.baidu.com數據:sudo tcpdump host www.baidu.com -xnt -v -A | grep -C3 www.baidu.com - 訪問百度:
curl www.baidu.com。
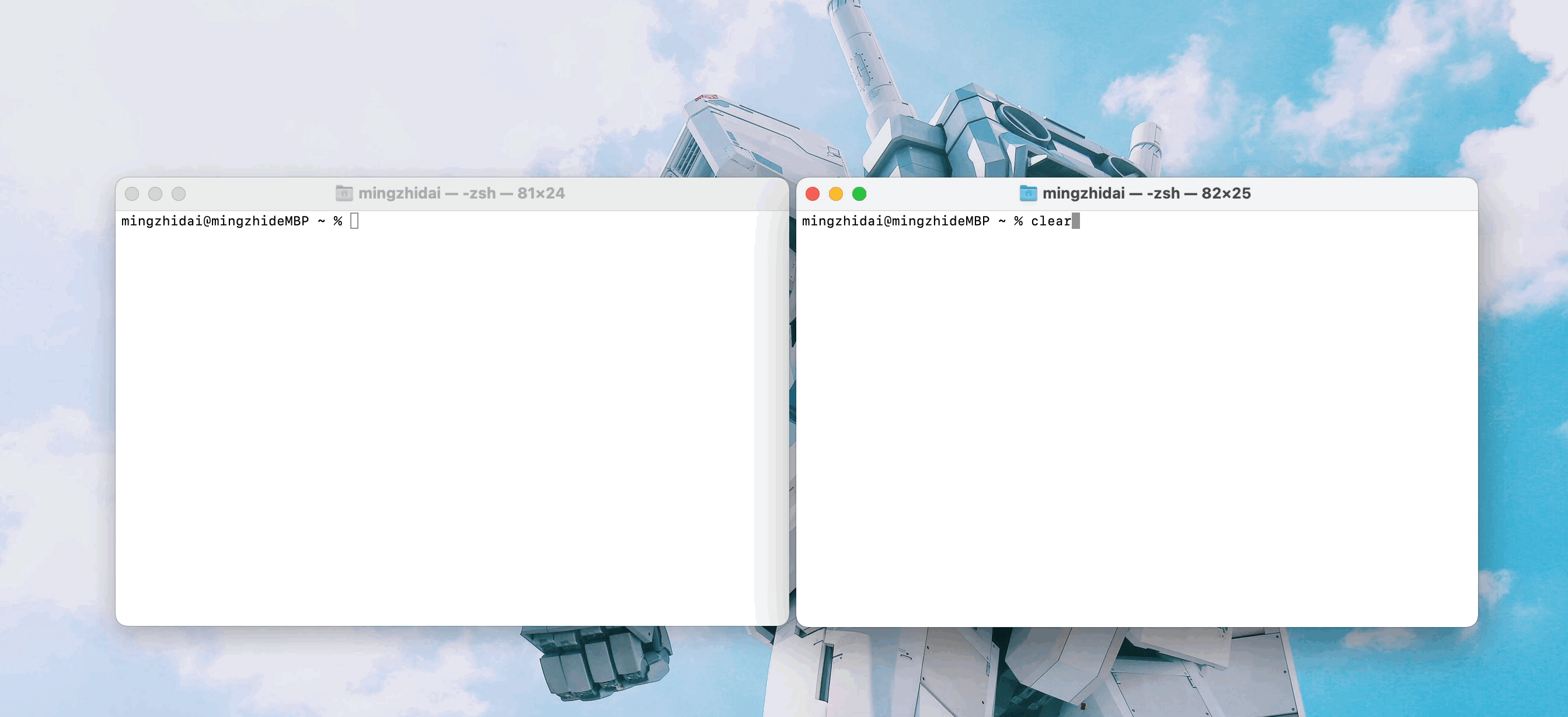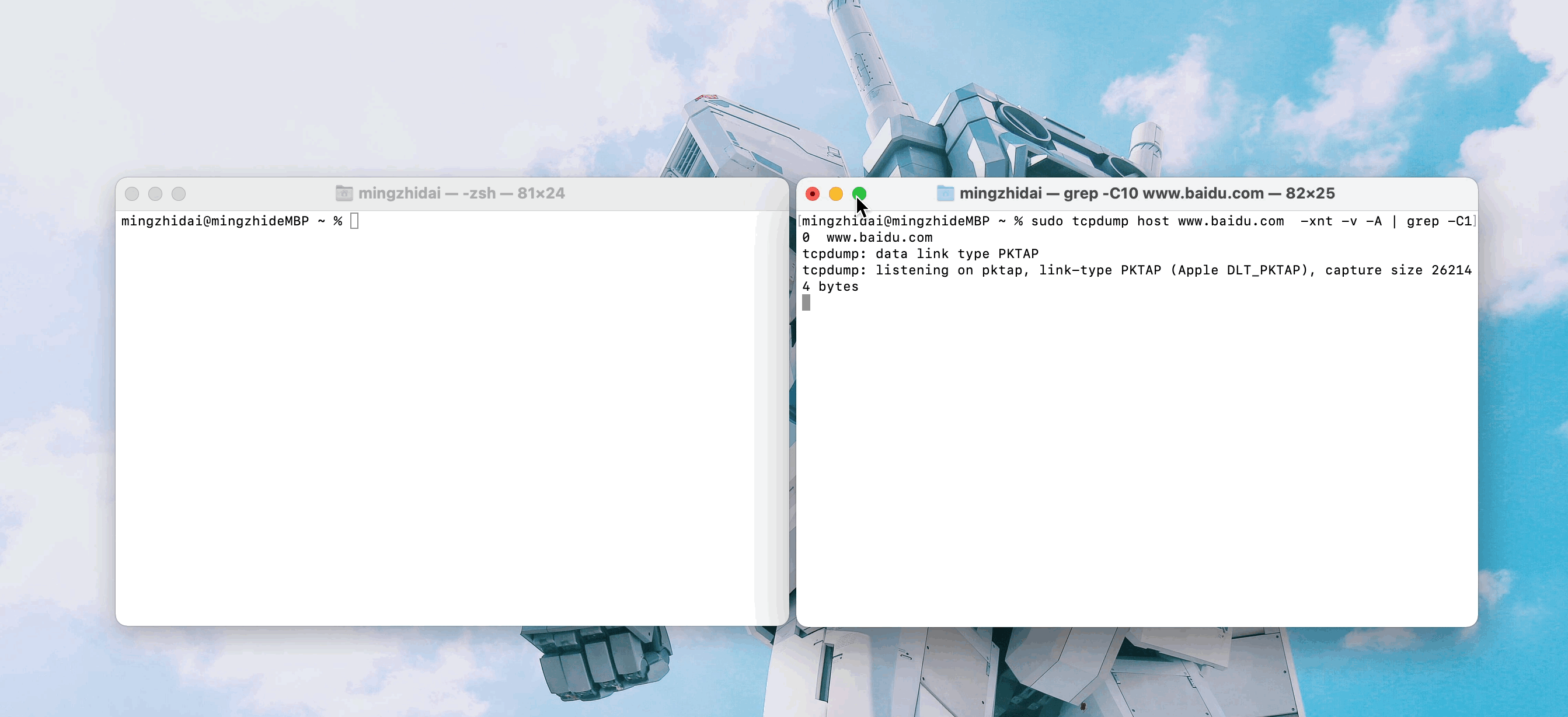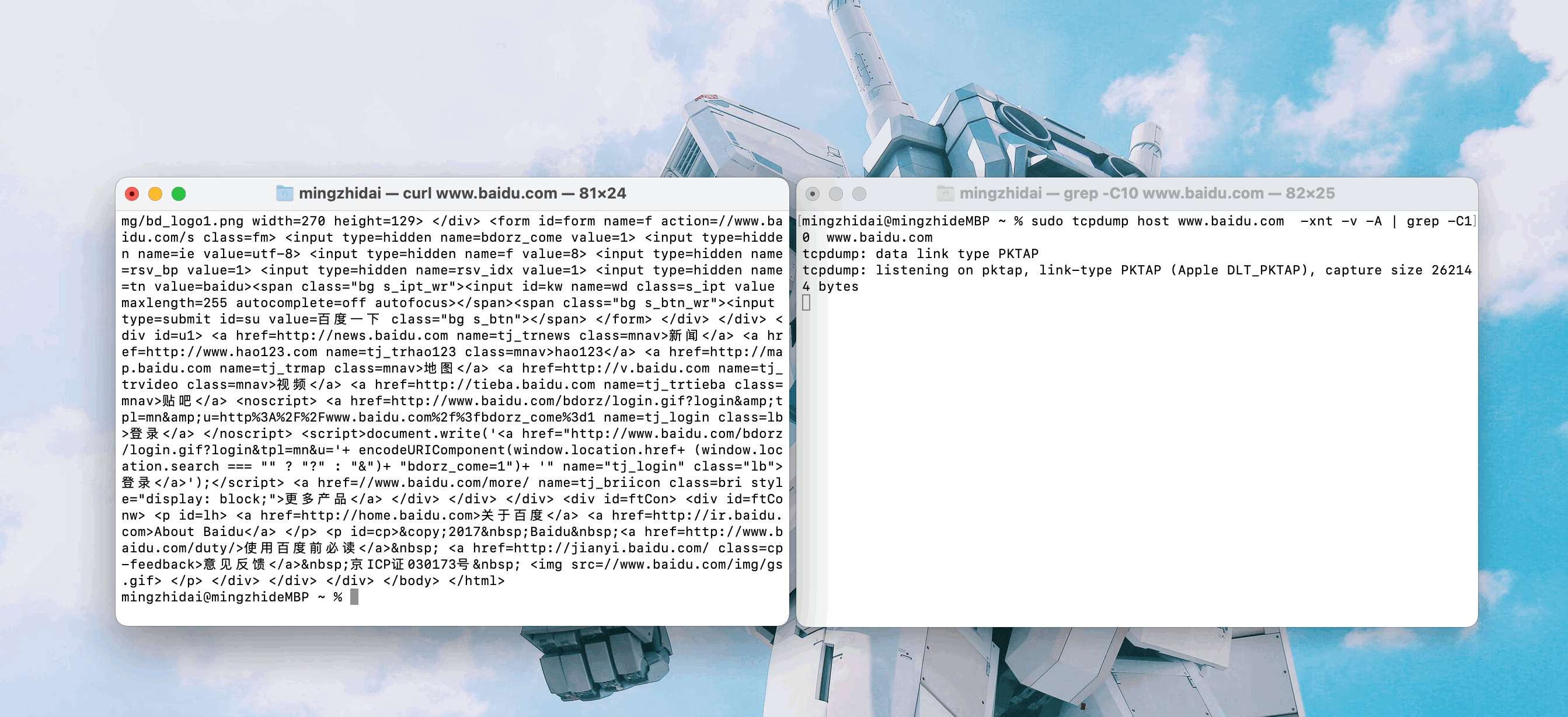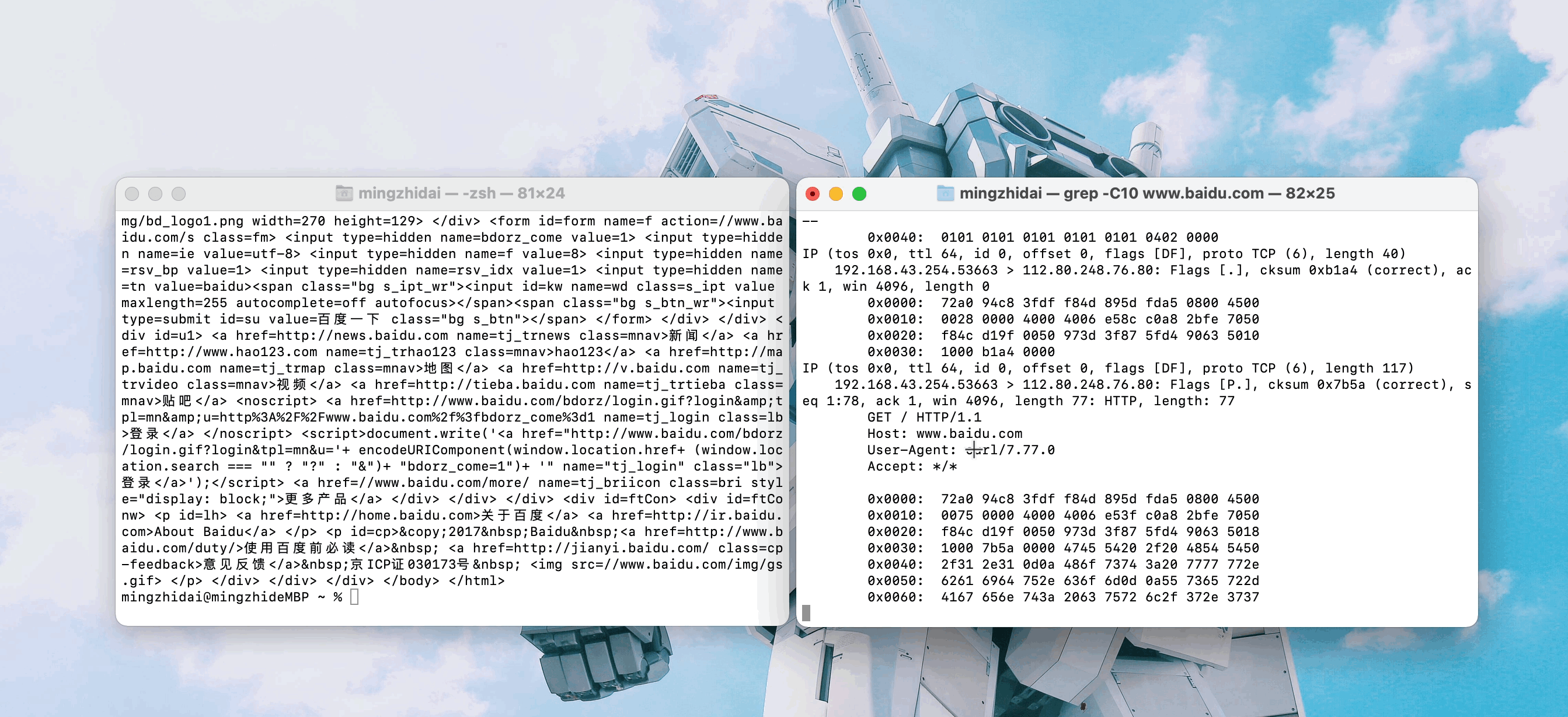
從這裡可以看到我們訪問百度時使用的ip地址(圖中馬塞克部分)
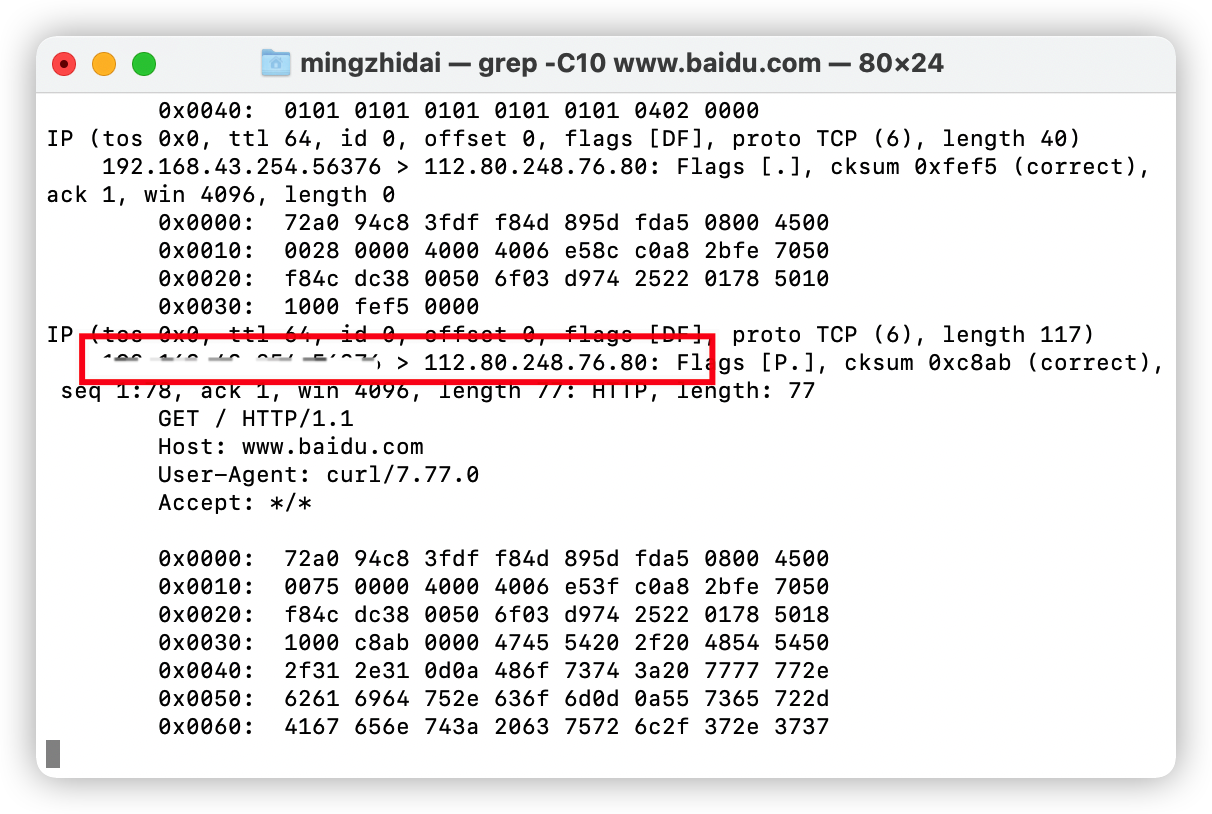
之後,通過執行ifconfig命令,就能查詢到這個ip對應的網卡
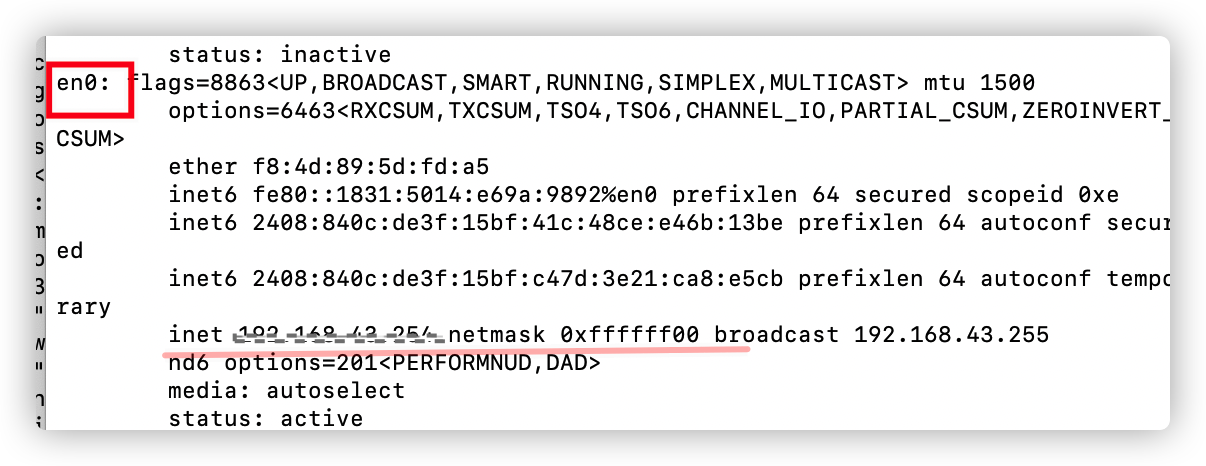
在我本機對應的就是en0這張網卡。確認了具體網卡後,我們在主界面選定此網卡,雙擊即可,此時可能會出現如下報錯:
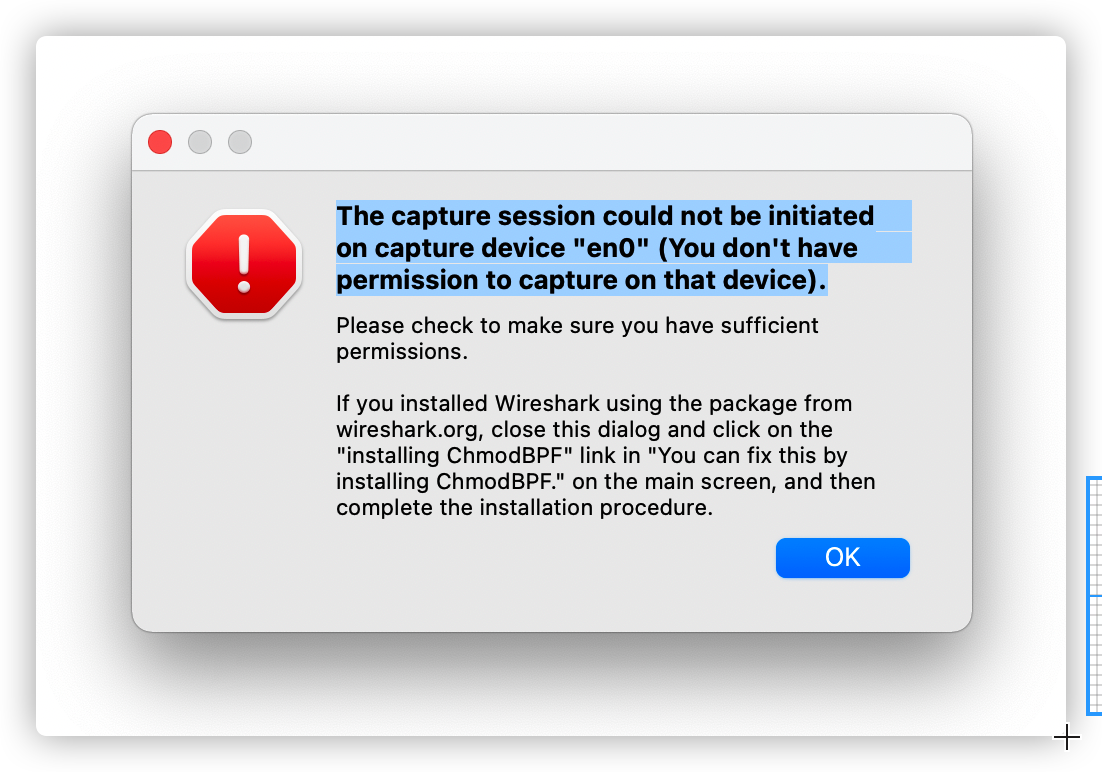
這是因為網卡權限問題,我們只需要在終端中輸入如下命令即可:sudo chmod 777 /dev/bpf*。執行完後記得要重啟WireShark。
重啟完成後,選定網卡雙擊會進入如下界面:
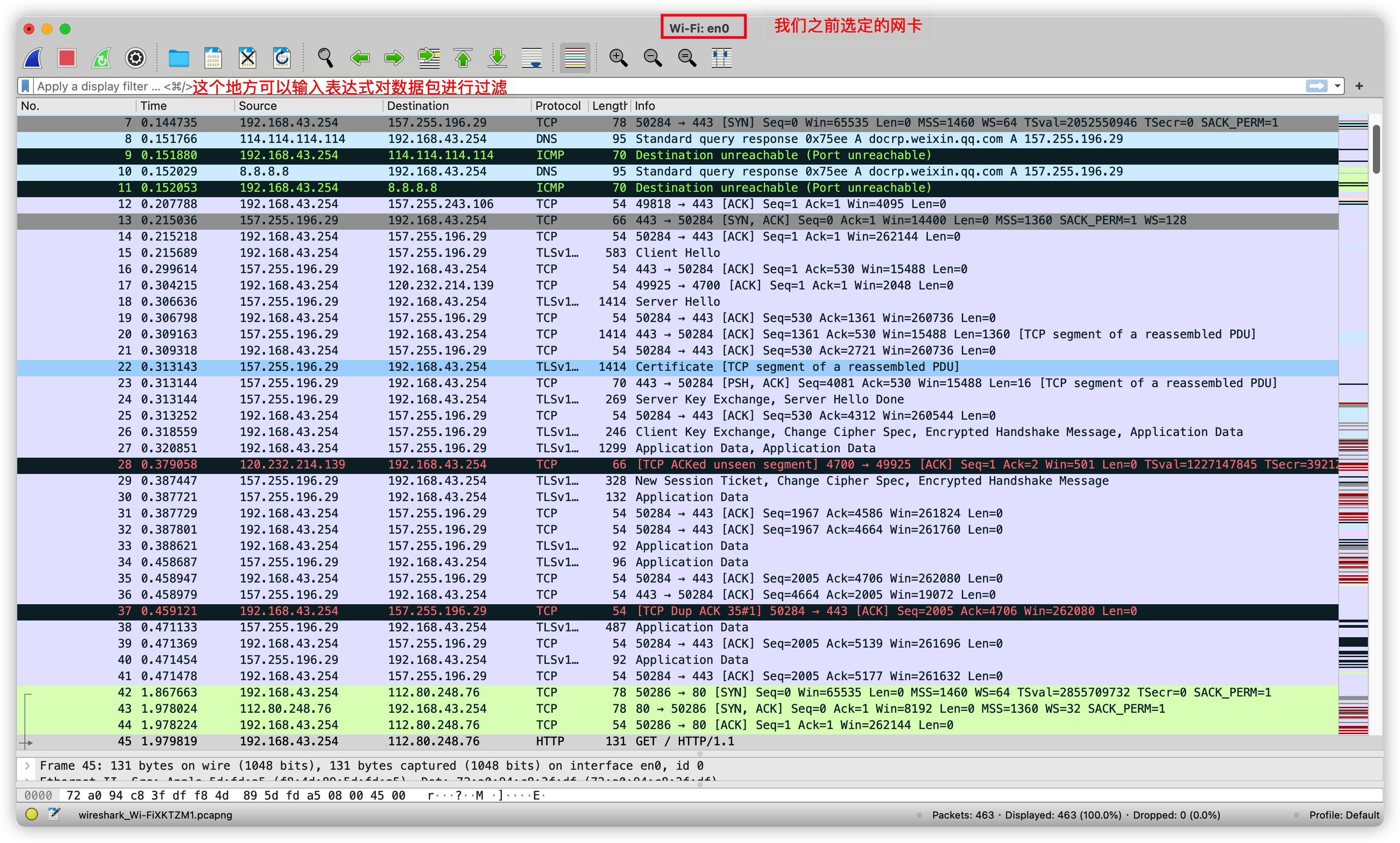
一進這個界面可能會有點懵,因為我們沒有輸入任何過濾表達式,所以此時整個界面上展示的是en0這個網卡上所有的數據包。關於WireShark的表達式不是本文重點,筆者也不打算過多介紹,本文用到的表達式都非常簡單,每個表達式我會做簡單解釋。
此時我們想要抓取訪問百度時的數據包,我們只需要輸入如下表達式:
http and ip.addr==112.80.248.76
表達式中的第一個http代表,我們要抓取的是http協議相關的數據包,同理,你可以輸入tcp,icmp等協議名稱過濾出對應協議相關的數據包。這個表達式的意思是,我要抓取http協議的數據包,同時通信的某一方的ip地址為112.80.248.76,這個ip地址可以通過ping www.baidu.com得到。
根據上述表達式我們可以抓到如下數據包:
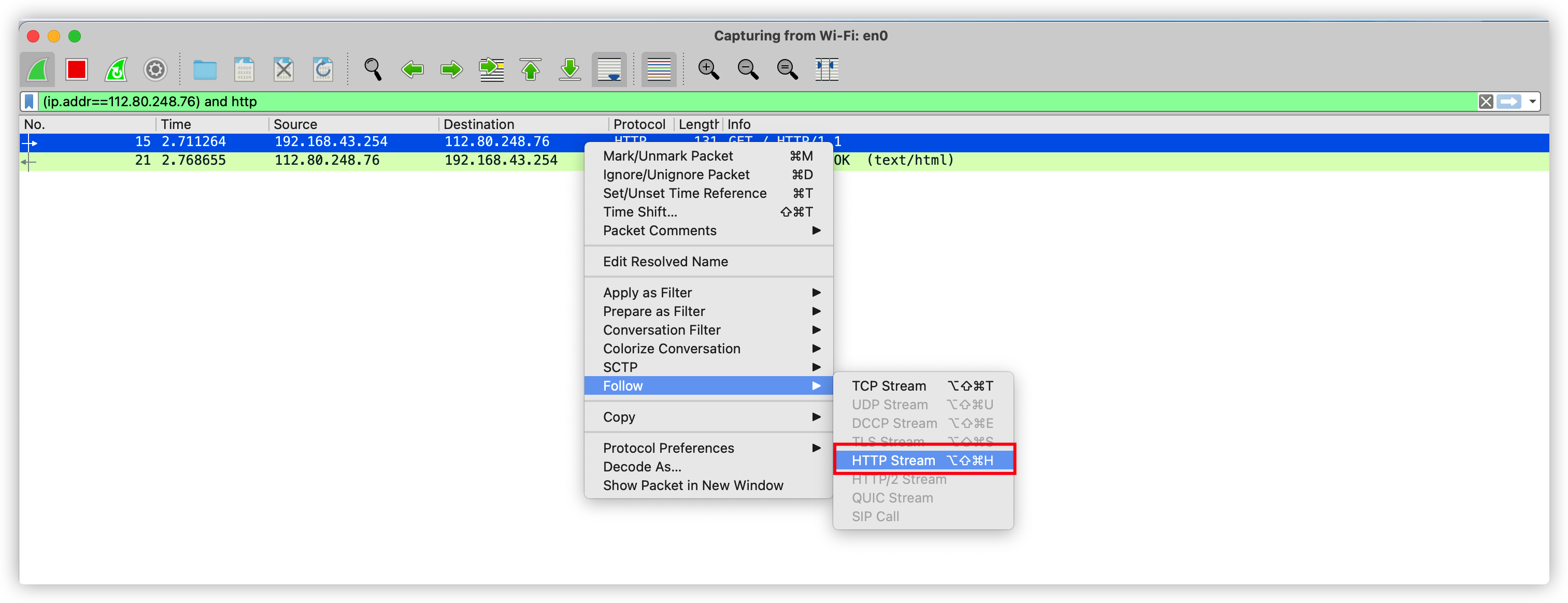
我們選中對應的報文,右鍵跟蹤http流,即可得到具體的http報文信息

那麼接下來我們正式開始抓包實驗,確保你的測試項目及Wireshark都是ok的哦~
Http抓包分析
-
wireShark要抓取的網卡是迴環網卡(測試項目中客戶端發起請求的URL是127.0.0.1:8080)
-
我們server在搭建時綁定的端口是8080,所以wireShark可以配置如下表達式:
http and tcp.port==8080,代表我們要抓取8080端口上所有http協議的包(因為是抓取迴環網卡網卡上的數據包,所以我們可以不指定IP)
接下來我們啟動sever端,然後運行client端發起一個http請求,在WireShark上可以抓取到如下數據:

按照前文所訴,我們追蹤下這個http流可以看到如下數據:
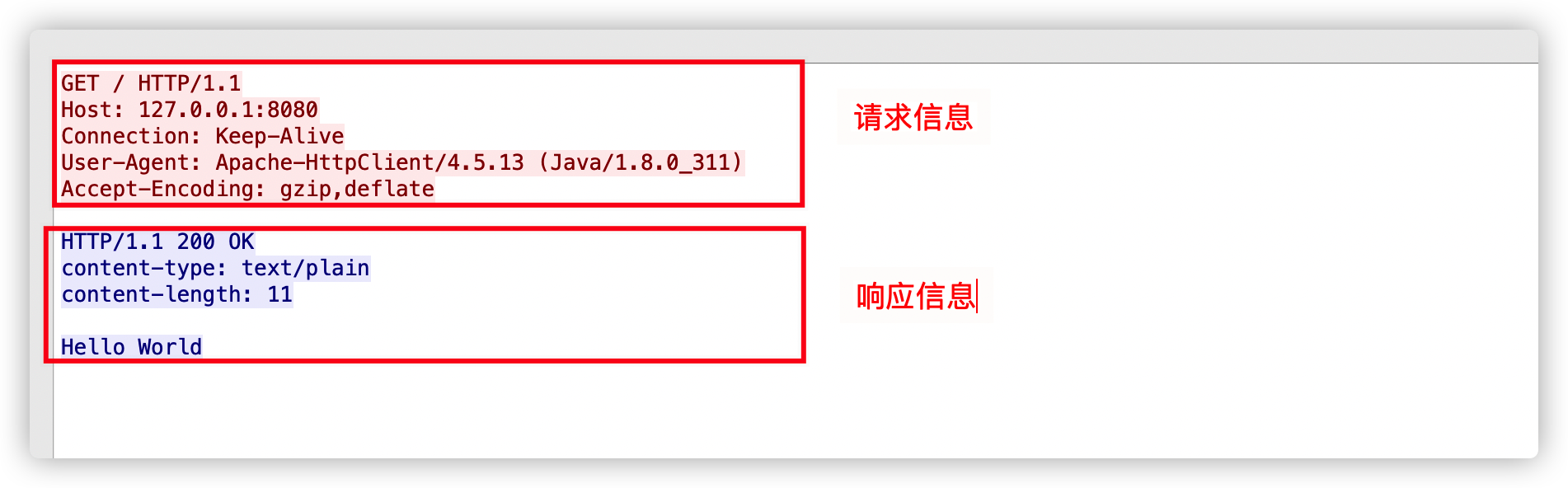
協議格式
HTTP 協議的請求報文和響應報文的結構基本相同,由三大部分組成:
起始行(start line):描述請求或響應的基本信息,在請求中我們稱之為請求行,響應中我們稱之為狀態行;
頭部字段集合(header):使用 key-value 形式更詳細地說明報文,在請求中我們稱之為請求頭,響應中我們稱之為響應頭。
消息正文(entity):實際傳輸的數據,它不一定是純文本,可以是圖片、視頻等二進制數據,也稱之為請求體或響應體
HTTP 協議規定報文必須有 header,但可以沒有 body,而且在 header 之後必須要有一個「空行」,也就是「CRLF」,十六進制的「0D0A」。
將抓包得到的報文用上述結構描述即如下圖所示:

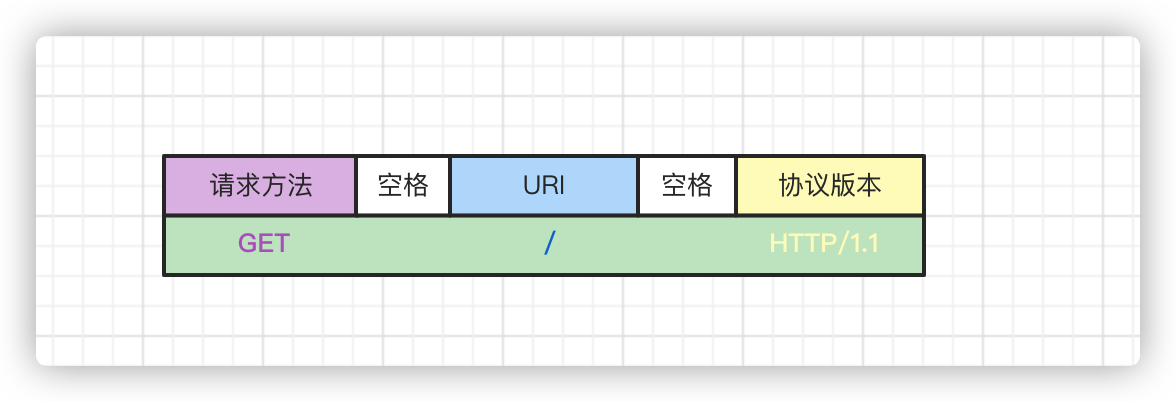
請求行
如下圖所示,請求行中主要包含三部分信息
- 請求方法
- 請求URI
- 本次發起http請求時使用的http協議版本
三部分之間使用空格進行分隔
常見的請求方法
| 請求方法 | 描述信息 | 補充 |
|---|---|---|
| GET | 請求從服務器獲取資源 | 這個資源既可以是靜態的文本、頁面、圖片、視頻,也可以是由 PHP、Java 動態生成的頁面或者其他格式的數據 |
| POST | 向服務器提交數據(例如提交表單或者上傳文件),數據包含在請求體中 | POST 表示的是「新建」「create」的含義 |
| PUT | PUT 的作用與 POST 類似,數據也包含在請求體中 | 通常 POST 表示的是「新建」「create」的含義,而 PUT 則是「修改」「update」的含義。 |
| DELETE | 指示服務器刪除資源 | 在RESTful架構使用較多下使用較多 |
| HEAD | 類似於 GET 請求,只不過返回的響應中沒有具體的內容,用於獲取報頭 | HEAD 方法可以看做是 GET 方法的一個「簡化版」或者「輕量版」。因為它的響應頭與 GET 完全相同,所以可以用在很多並不真正需要資源的場合,避免傳輸 body 數據的浪費。 |
| OPTIONS | 方法要求服務器列出可對資源實行的操作方法,在響應頭的 Allow 字段里返回。 | 它的功能很有限,用處也不大,有的服務器(例如 Nginx)乾脆就沒有實現對它的支持。 |
| TRACE | 用於對 HTTP 鏈路的測試或診斷,可以顯示出請求 – 響應的傳輸路徑。 | 它的本意是好的,但存在漏洞,會泄漏網站的信息,所以 Web 服務器通常也是禁止使用。 |
| CONNECT | 要求使用隧道協議連接代理 | 關於隧道大家可查看://www.zhihu.com/question/21955083,本文不在贅述 |
RESTful架構下,會使用四個表示操作方式的動詞:GET、POST、PUT、DELETE。它們分別對應四種基本操作:GET用來獲取資源,POST用來新建資源(也可以用於更新資源),PUT用來更新資源,DELETE用來刪除資源。
Get跟Post常見誤區
-
請求參數長度限制:GET請求長度最多1024kb,POST對請求數據沒有限制
答:GET 請求的參數位置一般是寫在 URL 中,URL 規定只能支持 ASCII,所以 GET 請求的參數只允許 ASCII 字符 ,而且瀏覽器會對 URL 的長度有限制(HTTP協議本身對 URL長度並沒有做任何規定)。
-
GET請求一定不能用request body傳輸數據
答:RFC 規範並沒有規定 GET 請求不能帶 body 的。理論上,任何請求都可以帶 body 的。只是因為 RFC 規範定義的 GET 請求是獲取資源,所以根據這個語義不需要用到 body。另外,URL 中的查詢參數也不是 GET 所獨有的,POST 請求的 URL 中也可以有參數的。我們在傳統的Spring環境下會發現下面兩種寫法都可以正常工作


狀態行
如下圖所示,請求行中主要包含三部分信息
- 使用的http協議版本
- 數字狀態碼
- 作為數字狀態碼補充,是更詳細的解釋文字,幫助人理解原因。
三部分之間使用空格進行分隔

狀態碼
RFC 標準把狀態碼分成了五類,用數字的第一位表示分類,這樣狀態碼的實際可用範圍就大大縮小了,由 000~999 變成了 100~599。
這五類的具體含義是:
1××:提示信息,表示目前是協議處理的中間狀態,還需要後續的操作;
2××:成功,報文已經收到並被正確處理;
3××:重定向,資源位置發生變動,需要客戶端重新發送請求;
4××:客戶端錯誤,請求報文有誤,服務器無法處理;
5××:服務器錯誤,服務器在處理請求時內部發生了錯誤。
實際上需要注意的是HTTP本身是一個協議,需要通信的雙方共同遵守,但這並不是必須的。
目前 RFC 標準里總共有 41 個狀態碼,但狀態碼的定義是開放的,允許自行擴展。所以 Apache、Nginx 等 Web 服務器都定義了一些專有的狀態碼。如果你自己開發 Web 應用,也完全可以在不衝突的前提下定義新的狀態碼。
1xx
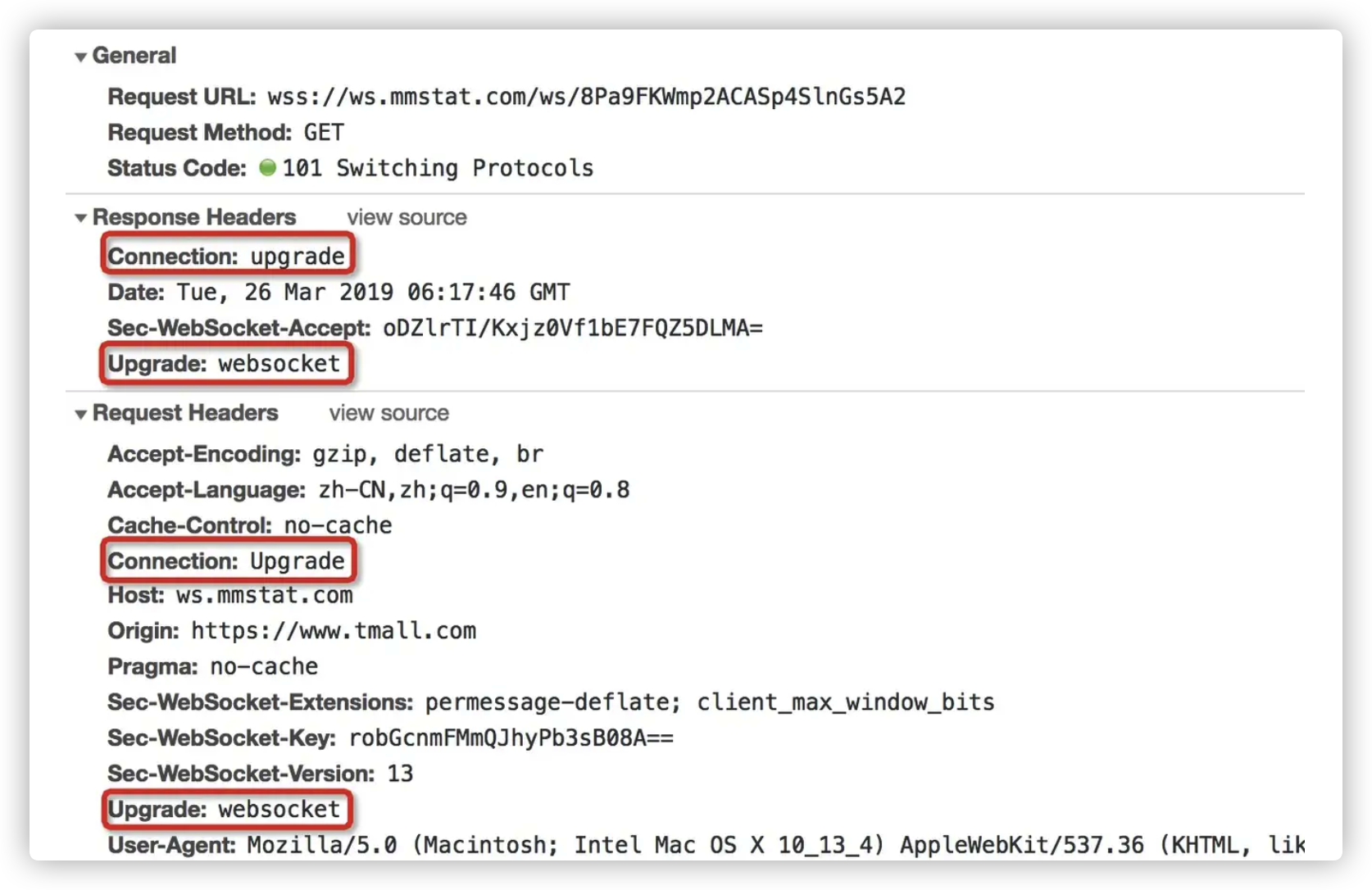
1xx 類狀態碼屬於提示信息,是協議處理中的一種中間狀態。例如在需要進行協議升級時,服務器會響應101。如下圖所示,使用websocket時,會進行一次協議升級:
2xx
2xx 類狀態碼錶示服務器成功處理了客戶端的請求,也是我們最願意看到的狀態。
- 「200 OK」是最常見的成功狀態碼,表示一切正常。如果是非
HEAD請求,服務器返回的響應頭都會有 body 數據。 - 「204 No Content」也是常見的成功狀態碼,與 200 OK 基本相同,但響應頭沒有 body 數據。
- 「206 Partial Content」是應用於 HTTP 分塊下載或斷點續傳,表示響應返回的 body 數據並不是資源的全部,而是其中的一部分,也是服務器處理成功的狀態。狀態碼 206 通常還會伴隨着頭字段「Content-Range」,表示響應報文里 body 數據的具體範圍,供客戶端確認,例如「Content-Range: bytes 0-99/2000」,意思是此次獲取的是總計 2000 個位元組的前 100 個位元組,這其實也就是http協議的分段請求功能,這部分內容我們之後會詳細介紹!
3xx
3xx 類狀態碼錶示客戶端請求的資源發生了變動,需要客戶端用新的 URL 重新發送請求獲取資源,也就是重定向。
- 「301 Moved Permanently」表示永久重定向,說明請求的資源已經不存在了,需改用新的 URL 再次訪問。
- 「302 Found」表示臨時重定向,說明請求的資源還在,但暫時需要用另一個 URL 來訪問。
301 和 302 都會在響應頭裡使用字段 Location,指明後續要跳轉的 URL,瀏覽器會自動重定向新的 URL。
- 「304 Not Modified」不具有跳轉的含義,表示資源未修改,重定向已存在的緩衝文件,也稱緩存重定向,也就是告訴客戶端可以繼續使用緩存資源,用於緩存控制。
4xx
4××類狀態碼錶示客戶端發送的請求報文有誤,服務器無法處理,它就是真正的「錯誤碼」含義了。
「400 Bad Request」是一個通用的錯誤碼,表示請求報文有錯誤,但具體是數據格式錯誤、缺少請求頭還是 URI 超長它沒有明確說,只是一個籠統的錯誤,客戶端看到 400 只會是「一頭霧水」「不知所措」。所以,在開發 Web 應用時應當盡量避免給客戶端返回 400,而是要用其他更有明確含義的狀態碼。
「403 Forbidden」實際上不是客戶端的請求出錯,而是表示服務器禁止訪問資源。原因可能多種多樣,例如信息敏感、法律禁止等,如果服務器友好一點,可以在 body 里詳細說明拒絕請求的原因,不過現實中通常都是直接給一個「閉門羹」。
「404 Not Found」可能是我們最常看見也是最不願意看到的一個狀態碼,它的原意是資源在本服務器上未找到,所以無法提供給客戶端。但現在已經被「用濫了」,只要服務器「不高興」就可以給出個 404,而我們也無從得知後面到底是真的未找到,還是有什麼別的原因,某種程度上它比 403 還要令人討厭。
4××里剩下的一些代碼較明確地說明了錯誤的原因,都很好理解,開發中常用的有:
- 405 Method Not Allowed:不允許使用某些方法操作資源,例如不允許 POST 只能 GET;
- 406 Not Acceptable:資源無法滿足客戶端請求的條件,例如請求中文但只有英文;
- 408 Request Timeout:請求超時,服務器等待了過長的時間;
- 409 Conflict:多個請求發生了衝突,可以理解為多線程並發時的競態;
- 413 Request Entity Too Large:請求報文里的 body 太大;
- 414 Request-URI Too Long:請求行里的 URI 太大;
- 429 Too Many Requests:客戶端發送了太多的請求,通常是由於服務器的限連策略;
- 431 Request Header Fields Too Large:請求頭某個字段或總體太大;
5xx
5xx 類狀態碼錶示客戶端請求報文正確,但是服務器處理時內部發生了錯誤,屬於服務器端的錯誤碼。
- 「500 Internal Server Error」與 400 類型,是個籠統通用的錯誤碼,服務器發生了什麼錯誤,我們並不知道。
- 「501 Not Implemented」表示客戶端請求的功能還不支持,類似「即將開業,敬請期待」的意思。
- 「502 Bad Gateway」通常是服務器作為網關或代理時返回的錯誤碼,表示服務器自身工作正常,訪問後端服務器發生了錯誤。
- 「503 Service Unavailable」表示服務器當前很忙,暫時無法響應客戶端,類似「網絡服務正忙,請稍後重試」的意思。
Header
ttp header 消息通常被分為4個部分:general header, request header, response header, entity header。但是這種分法就理解而言,感覺界限不太明確。根據維基百科對http header內容的組織形式,大體分為Request(請求頭)和Response(響應頭)兩部分。
Requests部分
| Header | 解釋 | 示例 |
|---|---|---|
| Accept | 指定客戶端能夠接收的內容類型 | Accept: text/plain, text/html |
| Accept-Charset | 客戶端可以接受的字符編碼集。 | Accept-Charset: iso-8859-5 |
| Accept-Encoding | 指定客戶端可以支持的web服務器返回內容壓縮編碼類型。 | Accept-Encoding: compress, gzip |
| Accept-Language | 客戶端可接受的語言 | Accept-Language: en,zh |
| Accept-Ranges | 可以請求網頁實體的一個或者多個子範圍字段 | Accept-Ranges: bytes |
| Authorization | HTTP授權的授權證書 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定請求和響應遵循的緩存機制 | Cache-Control: no-cache |
| Connection | 表示是否需要持久連接。(HTTP 1.1默認進行持久連接) | Connection: close |
| Cookie | HTTP請求發送時,會把保存在該請求域名下的所有cookie值一起發送給web服務器。 | Cookie: $Version=1; Skin=new; |
| Content-Length | 請求的內容長度 | Content-Length: 348 |
| Content-Type | 請求的與實體對應的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Date | 請求發送的日期和時間 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 請求的特定的服務器行為 | Expect: 100-continue |
| From | 發出請求的用戶的Email | From: [email protected] |
| Host | 指定請求的服務器的域名和端口號 | Host: www.zcmhi.com |
| If-Match | 只有請求內容與實體相匹配才有效 | If-Match: 「737060cd8c284d8af7ad3082f209582d」 |
| If-Modified-Since | 如果請求的部分在指定時間之後被修改則請求成功,未被修改則返回304代碼 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果內容未改變返回304代碼,參數為服務器先前發送的Etag,與服務器回應的Etag比較判斷是否改變 | If-None-Match: 「737060cd8c284d8af7ad3082f209582d」 |
| If-Range | 如果實體未改變,服務器發送客戶端丟失的部分,否則發送整個實體。參數也為Etag | If-Range: 「737060cd8c284d8af7ad3082f209582d」 |
| If-Unmodified-Since | 只在實體在指定時間之後未被修改才請求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通過代理和網關傳送的時間 | Max-Forwards: 10 |
| Pragma | 用來包含實現特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 連接到代理的授權證書 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只請求實體的一部分,指定範圍 | Range: bytes=500-999 |
| Referer | 先前網頁的地址,當前請求網頁緊隨其後,即來路 | Referer: //www.zcmhi.com/archives/71.html |
| TE | 客戶端願意接受的傳輸編碼,並通知服務器接受接受尾加頭信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 向服務器指定某種傳輸協議以便服務器進行轉換(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | User-Agent的內容包含發出請求的用戶信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中間網關或代理服務器地址,通信協議 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 關於消息實體的警告信息 | Warn: 199 Miscellaneous warning |
Responses 部分
| Header | 解釋 | 示例 |
|---|---|---|
| Accept-Ranges | 表明服務器是否支持指定範圍請求及哪種類型的分段請求 | Accept-Ranges: bytes |
| Age | 從原始服務器到代理緩存形成的估算時間(以秒計,非負) | Age: 12 |
| Allow | 對某網絡資源的有效的請求行為,不允許則返回405 | Allow: GET, HEAD |
| Cache-Control | 告訴所有的緩存機制是否可以緩存及哪種類型 | Cache-Control: no-cache |
| Content-Encoding | web服務器支持的返回內容壓縮編碼類型。 | Content-Encoding: gzip |
| Content-Language | 響應體的語言 | Content-Language: en,zh |
| Content-Length | 響應體的長度 | Content-Length: 348 |
| Content-Location | 請求資源可替代的備用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回資源的MD5校驗值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整個返回體中本部分的位元組位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回內容的MIME類型 | Content-Type: text/html; charset=utf-8 |
| Date | 原始服務器消息發出的時間 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | 請求變量的實體標籤的當前值 | ETag: 「737060cd8c284d8af7ad3082f209582d」 |
| Expires | 響應過期的日期和時間 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 請求資源的最後修改時間 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | 用來重定向接收方到非請求URL的位置來完成請求或標識新的資源 | Location: //www.zcmhi.com/archives/94.html |
| Pragma | 包括實現特定的指令,它可應用到響應鏈上的任何接收方 | Pragma: no-cache |
| Proxy-Authenticate | 它指出認證方案和可應用到代理的該URL上的參數 | Proxy-Authenticate: Basic |
| refresh | 應用於重定向或一個新的資源被創造,在5秒之後重定向(由網景提出,被大部分瀏覽器支持) | Refresh: 5; url=//www.zcmhi.com/archives/94.html |
| Retry-After | 如果實體暫時不可取,通知客戶端在指定時間之後再次嘗試 | Retry-After: 120 |
| Server | web服務器軟件名稱 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | 設置Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer | 指出頭域在分塊傳輸編碼的尾部存在 | Trailer: Max-Forwards |
| Transfer-Encoding | 文件傳輸編碼 | Transfer-Encoding:chunked |
| Vary | 告訴下游代理是使用緩存響應還是從原始服務器請求 | Vary: * |
| Via | 告知代理客戶端響應是通過哪裡發送的 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 警告實體可能存在的問題 | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | 表明客戶端請求實體應該使用的授權方案 | WWW-Authenticate: Basic |
總結
通過這篇文章我們搭建了測試項目,對wireShark有了一定了解,也知道了http協議的整體結構。僅僅是這樣我們很難對http有一個直觀深入的了解,所以下篇文章我會跟大家一起探討目前的主流框架是如何實現http協議的,例如:http的長連接在代碼層次是怎麼實現?服務器跟客戶端做了什麼去實現長連接呢?
下篇文章將從代碼實現的角度來分析http協議,跟着我捲起來~
參考:
-
《圖解Http》