深入理解 volatile 關鍵字

volatile 關鍵字是 Java 語言的高級特性,但要弄清楚其工作原理,需要先弄懂 Java 內存模型。如果你之前沒了解過 Java 內存模型,那可以先看看之前我寫過的一篇「深入理解 Java 內存模型」一文。
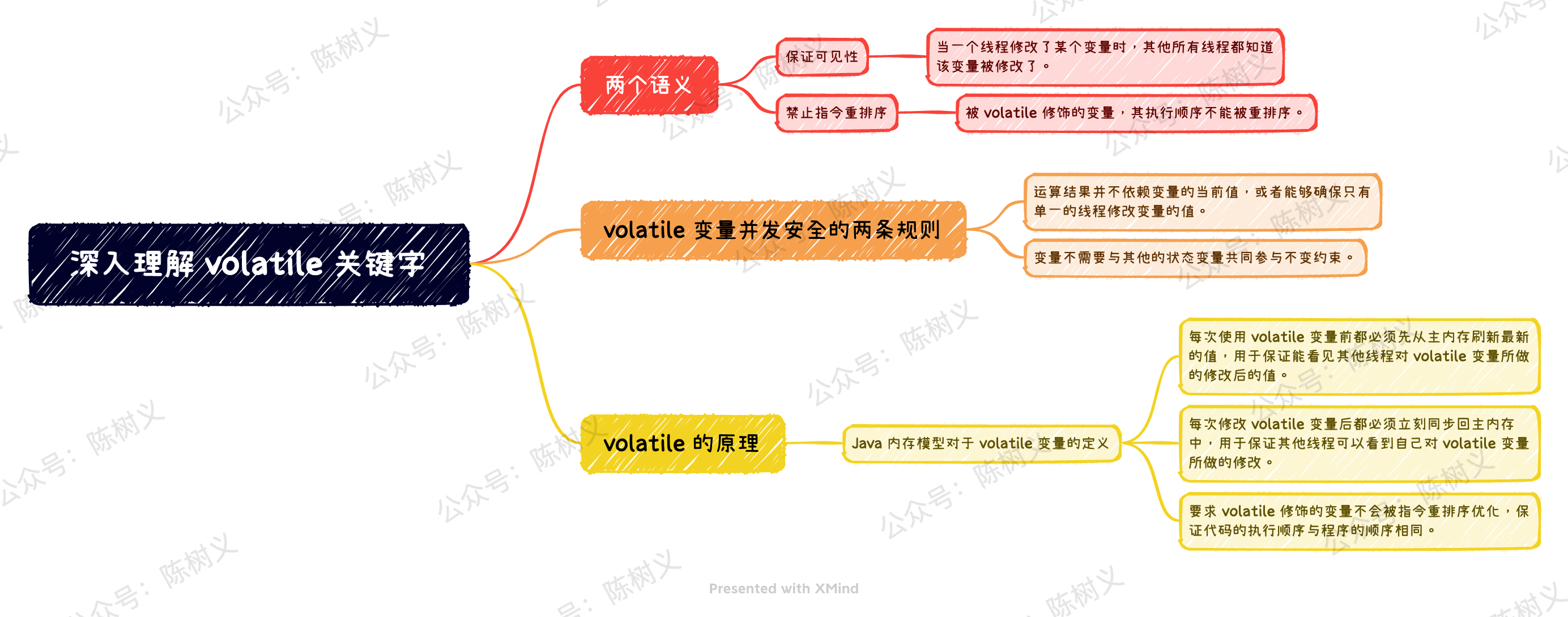
初學 volatile 關鍵字,我們需要弄清楚它到底意味着什麼。總的來說,它有兩個含義,分別是:
- 保證可見性
- 禁止指令重排序
保證可見性
保證可見性指的是:當一個線程修改了某個變量時,其他所有線程都知道該變量被修改了。 由於 volatile 可以保證可見性,因此 Java 能夠保證現在在讀取 volatile 變量時,線程讀取到的值是準確的。但是這並不意味着對 volatile 變量的操作是線程安全的,因為有可能在讀取到變量之後,又有其他線程對變量進行修改了。
為了說明這個問題,我們可以舉個簡單地例子。下面代碼發起了 20 個線程,每個線程對 race 變量進行 1 萬次自增操作。如果這段代碼能夠正確並發執行,那麼最後輸出的結果應該是 20 萬。但實際上,每次輸出的結果都不一樣,都是一個小於 20 萬的數字,為什麼呢?
這是因為當線程在獲取到 race 變量的值,然後對其進行自增這中間,有可能其他線程對 race 變量做了自增操作,然後寫回了主內存。而當前線程再將數據寫回主內存時,就發生了數據覆蓋。因此,就發生了數據不一致的問題。
要使得 volatile 變量不發生並發安全問題,只需要遵守如下兩條規則即可:
- 運算結果並不依賴變量的當前值,或者能夠確保只有單一的線程修改變量的值。
- 變量不需要與其他的狀態變量共同參與不變約束。
第一條規則比較好理解,例如上面例子的 race 變量,其運算結果就依賴於變量的當前值,所以其並不符合第一條規則,因此就會有線程安全問題。但如果 race++ 變成了 race=1; 這樣的情況,那麼 race 的值就不依賴變量當前值,因此就不會有線程安全問題。
第二條規則有點晦澀難懂。其意思是說,變量不能和其他變量一起參與判斷,無論其他變量是否是 volatile 類型的變量。例如 if(a && b) 這個判斷就無法滿足 volatile 的第二條規則,會發生線程安全問題,即使這兩個變量都是 volatile 類型的變量。
關於第二條規則的描述,為啥與其他變量一起,就沒法保證線程安全呢?
要解答這個問題,我們不妨假設一下各種可能的場景。
我們假設變量 a b 的初始值都是 true,並且兩者都是 volatile 類型變量。
場景一:線程 A 執行 if(a && b) 判斷,先判斷變量 a,發現是 true,於是繼續判斷變量 b。發現變量 b 也是 true,於是整個表達式為 true。
場景二:線程 A 執行 if(a && b) 判斷,先判斷變量 a,發現是 true。此時線程 B 修改了變量 b 的值為 false。接着線程 A 繼續判斷變量 b 的值,發現變量 b 的值為 false。於是整體表達式的值為 false。
通過上面的例子,我們發現同樣的表達式在不同的並發場景下會有不同的結果,這很明顯就是線程不安全的。因為線程安全的代碼,在單線程和多線程下,其結果應該是一樣的。
禁止指令重排序
指令重排序,指的是硬件層面為了加快執行速度,可能會調整指令的執行順序,從而會出現並不按代碼順序的執行情況出現。例如下面的代碼里,我們初始化了 flag 變量為 false,然後再將 flag 變量置為 true。但這樣的代碼在並發執行的時候,有可能先將 flag 職位 true,再將 flag 變為 false,從而發生線程安全問題。
boolean flag = false;
flag = true;
我們說 volatile 變量禁止指令重排序,其實就是指被 volatile 修飾的變量,其執行順序不能被重排序。 禁止重排序的實現,是使用了一個叫「內存屏障」的東西。簡單地說,內存屏障的作用就是指令重排序時,不能把後面的指令重排序到內存屏障之前的位置。
可見性的來源
我們前面說過:volatile 修飾的變量,當其被修改之後,其他變量就能立即獲取到其變化。但這個可見性的來源是哪裡呢?為什麼其能夠實現這樣的可見性呢?其實 volatile 的這些功能來源於 Java 內存模型中對 volatile 變量定義的特殊規則。
假定 T 表示一個線程,V 和 W 分別表示兩個 volatile 型變量。在 Java 內存模型中規定在進行 read、load、use、assign、store 和 write 操作時需要滿足如下規則:
- 只有當線程 T 對變量 V 執行的前一個動作是 load 的時候,線程 T 才能對變量 V 執行 use 動作。並且,只有當線程 T 對變量 V 執行的後一個動作是 use 的時候,線程 T 才能對變量 V 執行 load 動作。
- 只有當線程 T 對變量 V 執行的前一個動作是 assign 的時候,線程 T 才能對變量 V 執行 store 動作;並且,只有當線程 T 對變量V執行的後一個動作是 store 的時候,線程 T 才能對變量 V 執行 assign 動作。
- 假定動作 A 是線程 T 對變量 V 實施的 use 或 assign 動作,假定動作 F 是和動作 A 相關聯的 load 或 store 動作,假定動作 P 是和動作 F 相應的對變量 V 的 read 或 write 動作。類似的,假定動作 B 是線程 T 對變量 W 實施的 use 或 assign 動作,假定動作 G 是和動作 B 相關聯的 load 或 store 動作,假定動作 Q 是和動作 G 相應的對變量 W 的 read 或 write 動作。如果 A 先於 B,那麼 P 先於 Q。
上面三條規則有點複雜,我們來一條條講解下。
首先,我們來看看第一條規則。
只有當線程 T 對變量 V 執行的前一個動作是 load 的時候,線程 T 才能對變量 V 執行 use 動作。
load 動作,指的是把從主內存得到的變量值,放入到工作內存的變量副本。use 動作,指的是將工作內存的一個變量值,傳遞給執行引擎。那麼這句話合起來的意思可以理解為:要使用變量 V 之前,必須去主內存讀取變量 V。
並且,只有當線程 T 對變量 V 執行的後一個動作是 use 的時候,線程 T 才能對變量 V 執行 load 動作。
這句的意思可以理解為:要去讀取主內存的變量值放入工作內存的變量副本,那就必須使用它。
總的來說,這條規則的意思是:線程對變量 V 的 use 動作,必須與 read、load 動作連在一起,即 read -> load -> use 必須一起出現。這條規則要求在工作內存中,每次使用 V 前都必須先從主內存刷新最新的值,用於保證能看見其他線程對變量V所做的修改後的值。
我們繼續看第二條規則。
只有當線程 T 對變量 V 執行的前一個動作是 assign 的時候,線程 T 才能對變量 V 執行 store 動作。
assign 動作,指的是將執行引擎的值賦值給工作內存的變量。store 動作,指的是將工作內存的一個變量傳送到主內存,方便後續寫回主內存。那麼這句話合起來的意思可以理解為:要講工作內存的變量寫回主內存,那麼必須是工作內存的變量收到執行引擎的賦值。
並且,只有當線程 T 對變量 V 執行的後一個動作是 store 的時候,線程 T 才能對變量 V 執行 assign 動作。
這句話的意思可以理解為:要將執行引擎接收到的值賦給工作內存的變量,就必須把工作內存變量的值寫回主內存。
總的來說,這條規則的意思是:線程對變量 V 的 assign 動作,必須與 store、write 連在一起,即:assign -> store -> write 必須一起出現。這條規則要求在工作內存中,每次修改 V 後都必須立刻同步回主內存中,用於保證其他線程可以看到自己對變量 V 所做的修改。
我們繼續看第三條規則。
假定動作 A 是線程 T 對變量 V 實施的 use 或 assign 動作,假定動作 F 是和動作 A 相關聯的 load 或 store 動作,假定動作 P 是和動作 F 相應的對變量 V 的 read 或 write 動作。
這句話意思比較簡單,use 和 assign 動作分別是從工作內存傳遞變量給執行引擎,以及從執行引擎傳遞變量給工作內存。load 和 store 動作分別是從主內存載入數據到工作內存,以及從工作內存寫數據到主內存。read 和 write 動作分別是將數據讀取到工作內存,以及將數據寫回主內存。
我們假設是一個寫入到主內存動作,如果這幾個組合起來,那麼就是:A -> F -> P(assign -> store -> write)。
類似的,假定動作 B 是線程 T 對變量 W 實施的 use 或 assign 動作,假定動作 G 是和動作 B 相關聯的 load 或 store 動作,假定動作 Q 是和動作 G 相應的對變量 W 的 read 或 write 動作。
與上面類似,如果是一個寫入到主內存動作,如果這幾個組合起來,那麼就是:B -> G -> Q(assign -> store -> write)。
如果 A 先於 B,那麼 P 先於 Q。
這個的意思是,如果 A 動作早於 B 動作發生,那麼 A 動作對應的 P 動作(write 動作)就要早於 Q 動作(write 動作)。
這條規則要求 volatile 修飾的變量不會被指令重排序優化,保證代碼的執行順序與程序的順序相同。
所以說 volatile 變量的可見性以及禁止重排序的語義,其實都來源於 Java 內存模型里對於 volatile 變量的定義。
總結
這篇文章,我們介紹了 volatile 的兩個語義:
- 可見性
- 禁止重排序
可見性指的是 volatile 類型的變量,其變量值一旦被修改,其他線程就能夠立刻感知到。而禁止重排序指的是被 volatile 修飾的變量,其執行順序不能被重排序。我們在日常使用中,如果要使 volatile 變量不發生線程安全問題,只需要遵守下面兩個規則即可。
- 運算結果並不依賴變量的當前值,或者能夠確保只有單一的線程修改變量的值。
- 變量不需要與其他的狀態變量共同參與不變約束。
最後,我們進一步探究了 volatile 可見性以及禁止重排序的來源,其實就是 Java 內存模型里對於 volatile 變量的定義。
參考資料
- 《深入理解 Java 虛擬機》
- 如何理解 「變量不需要與其他的狀態變量共同參與不變約束」 一話? – 知乎


