6.28 學習內容
- 2022 年 6 月 29 日
- 筆記
昨日內容回顧
- 列表的內置方法
1.類型轉換
2.索引取值的操作
3.統計列表的數據個數
(len)關鍵字
4.增加數據值
(append)尾部增加數據值
(sinert)索引插入數據值
(extend)擴展列表 底層原理 for+append
(+) 也可以使用 + 號
5.修改數據值
通過索引修改想要修改的數據 list[] = 新的數值
6.刪除數據值
(del) 索引刪除
(pop) 默認刪除尾部 也可以通過索引刪除
(remove) 明確刪除數據值
7.排序
(sort)
8.翻轉
remevse
9.比較運算
- 可變類型與不可變類型
1.可變的類型
調用方法是修改自己的本身
2.不可變的類型
調用方式是產生新的數值 需要重新綁定變量名的數據值
- 元組的內置方法
1.類型轉換 支持 for循環的都可以轉成元組,元組在空括號時轉換的是元組
需要注意的是當元組只有一個數據值是什麼類型就是什麼類型 所以要在數據值後加上逗號
2.索引取值
3.統計元組內數據的個數 len
4.查與改
元組支持查 不支持修改
- 字典的內置方法
1.字典內的K V鍵值對無序的 不支持索引取值
2.取值操作 get
3.統計字典內的鍵值對個數 len
4.查找 通過索引K進行查找 或get方法
4.修改與增加
通過索引K 來修改
在沒有K 的時候是增加
5.刪除
del、pop、popitem
6.快速生成字典
formkeys
7.快速獲取 K V 鍵值對 (key、vluses、items)
- 集合的內置方法
1.類型轉換
支持 for循環的類型 並且必須是數據類型不可變的
2.定義空集合 set()
3.自帶去重功能
4.關係運算
& | ^ > <
今日內容概要
- 垃圾回收機制
- 字符編碼簡介
- 字符編碼的發展史
- 字符編碼實操
- 文件操作簡介
今日內容詳細
垃圾回收機制
1.什麼是垃圾回收機制
在python中編輯會產生很多的數據值 當沒有綁定變量的數據值則會被當成垃圾回收
”’python會自動申請內存和釋放空間”’
2.引用計數
當數據值身上計數不為0時表示還有用 不會被回收
當數據值身上計數為0時 則會被垃圾機制當成垃圾回收
eg:
name = 'jason' # jason身上引用計數為1
name1 = name # 此時jason身上引用計數為2
del name # jason 身上引用計數減1
當一個數據值身上有一個引用計數則不會被垃圾機制回收
3.標記清除
專門用於解決循環引用的問題 將內存中程序所產生的所有數據全部檢查一遍 是否存在循環打上標記之後一次性清除
eg:
l1 = ['jason']
l2 = ['lisa']
l1.append(l2) # 引用計數2
l2.append(l1) # 引用計數2
del l1 # 解除變量名與l1列表的綁定列表引用計數減一
del l2 # 解除變量名與l2列表的綁定列表引用計數減一
當我們把l1和l2的數據解除了 l1和l2的數據還是相互調用 計數存在是一,所以不能被垃圾機制回收
4.分帶回收
標記清除每隔一段時間就要把所以的數據查一遍 資源消耗過大
為了減輕垃圾機制的資源損耗 所以開發了三代管理 越往下檢測的頻率就越低

字符的編碼簡介
1.只有文本文件才有字符編碼的概念
2.計算機內部存取得數據本質 (二進制)
計算機其實只認識0和1
3.為什麼我們在使用計算機的時候能隨意敲出各國的文字
因為計算機不認識我們人類的語言,所以我們人類定義一種數字的轉換關係
4.轉換關係不能隨便改變 應該有統一的標準
字符編碼表 記錄了人類的字符與數字的對應關係
字符的編碼發展史
1.一家獨大
計算機是美國人發明的 美國人需要讓計算機識別英文字符
ps:英文所有的字符加起來不超過127個(2的七次方) 但是美國人考慮到後續可能出現新的字符所以加了以為以備不時之需(2的八次方)
ASCII:內部值記錄了英文字符與數據的對應關係 1bytes來存儲字符
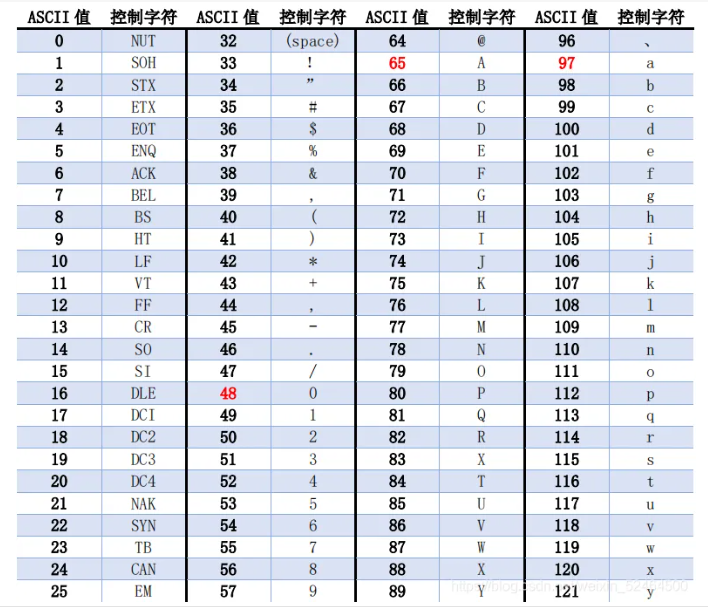
2.群雄割據
因為ASCII表只能表示英文不能表示中文
後面我們中國開發了一套可以識別中文的編碼表
GBK碼錶:內部記錄了中文字符、英文字符與數字對應的關係
2bybes起步儲存中文 (遇到生僻字需要使用跟多的位元組)
1bybes存儲英文
韓國對應的編碼表 EUS_kr碼
記錄了韓文字符與英文字符、數字的對應關係
日本對應的編碼表 shift_JIS碼錶
記錄了日文與英文字符、數字的對應關係
注意:此時的各國計算機文件文本無法直接交互 會出現亂碼的情況
3.天下統一
萬國碼(unicde):兼容萬國字符
所有的字符可以全部使用2bytes起步存儲
utf家族(針對unicde的優化版本):utf8
英文還是採用1bytes
其他統一採用3bybes
註:內存使用unicode 硬盤使用utf8
字符的編碼實操
1.只有字符串可以參與編碼解碼 其他數據類型需要先轉換成字符串才可以
2.如何解決亂碼
當初使用什麼編碼存的就使用什麼代碼解
3.編碼與解碼
把人類的字符按照指定的編碼轉換成計算機識別的數字
編碼:人類的字符>>>計算機的字符
使用encode 能將人類的認識的字符轉成計算機讀懂的字符
a = 'lisa:說皇天不負有心人'
res = a.encode('utf8')
print(res) # b'lisa\xef\xbc\x9a\xe8\xaf\xb4\xe7\x9a\x87\xe5\xa4\xa9\xe4\xb8\x8d\xe8\xb4\x9f\xe6\x9c\x89\xe5\xbf\x83\xe4\xba\xba'
'''在python中bytes類型的數據可以看成是二進制數'''
解碼:計算機的字符>>>人類的字符
b = a.decode(gbk)
print(a)
3.解釋器層面
python2默認的編碼是ASCII碼
3.1文件頭 # coding:utf8
3.2定義字符串 (需要在字符串的前面加u)
為什麼要這麼做 因為沒有辦法 只能做補救措施
python3默認的編碼是utf8
文件操作簡介
1.文件操作?
通過編寫代碼自動來操作文件讀寫
2.什麼是文件?
雙擊文件圖標是從硬件加載數據到內存
寫文件之後保存其實就是將內存的數據刷到硬盤
文件其實就是操作系統暴露給用戶操作計算機硬盤的快捷方式之一
3.如何代碼操作文件
open('文件路徑',讀寫模式,字符編碼')
方法1:
f = open()
f.close()
方法2:
with open() as 變量名
子代碼在運行之後自動調用close()方法
4.針對文件路徑可能有特殊含義字母與撬棍的組合
在字符串的前面加字母r取消特殊含義

