CAP:多重注意力機制,有趣的細粒度分類方案 | AAAI 2021
論文提出細粒度分類解決方案CAP,通過上下文感知的注意力機制來幫助模型發現細微的特徵變化。除了像素級別的注意力機制,還有區域級別的注意力機制以及局部特徵編碼方法,與以往的視覺方案很不同,值得一看
來源:曉飛的算法工程筆記 公眾號
論文: Context-aware Attentional Pooling (CAP) for Fine-grained Visual Classification

Introduction
論文認為大多數優秀的細粒度圖像識別方法通過發掘目標的局部特徵來輔助識別,卻沒有對局部信息進行標註,而是採取弱監督或無監督的方式來定位局部特徵位置。而且大部分的方法採用預訓練的檢測器,無法很好地捕捉目標與局部特徵的關係。為了能夠更好地描述圖片內容,需要更細緻地考慮從像素到目標到場景的信息,不僅要定位局部特徵/目標的位置,還要從多個維度描述其豐富且互補的特徵,從而得出完整圖片/目標的內容。
論文從卷積網絡的角度考慮如何描述目標,提出了context-aware attentional pooling(CAP)模塊,能夠高效地編碼局部特徵的位置信息和外觀信息。該模塊將卷積網絡輸出的特徵作為輸入,學習調整特徵中不同區域的重要性,從而得出局部區域的豐富的外觀特徵及其空間特徵,進而進行準確的分類。
論文的主要貢獻如下:
- 提出在細粒度圖像識別領域的擴展模塊CAP,能夠簡單地應用到各種卷積網絡中,帶來可觀的細粒度分類性能提升。
- 為了捕捉目標/場景間的細微差別,提出由區域特徵引導的上下文相關的attention特徵。
- 提出可學習的池化操作,用於自動選擇循環網絡的隱藏狀態構成空間和外觀特徵。
- 將提出的算法在8個細粒度數據集上進行測試,獲得SOTA結果。
- 分析不同的基礎網絡,擴大CAP模塊的應用範圍。
Proposed Approach
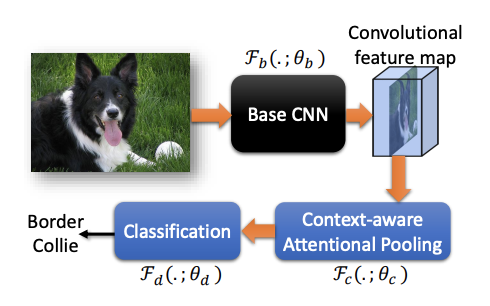
論文算法的整體流程如上圖所示,輸入圖片,輸出具體從屬類別,包含3個組件(3組參數):
- 基礎CNN網絡\mathcal{F}(.;\theta_b)
- CAP模塊\mathcal{F}(.;\theta_c)
- 分類模塊\mathcal{F}(.;\theta_d)
Context-aware attentional pooling (CAP)
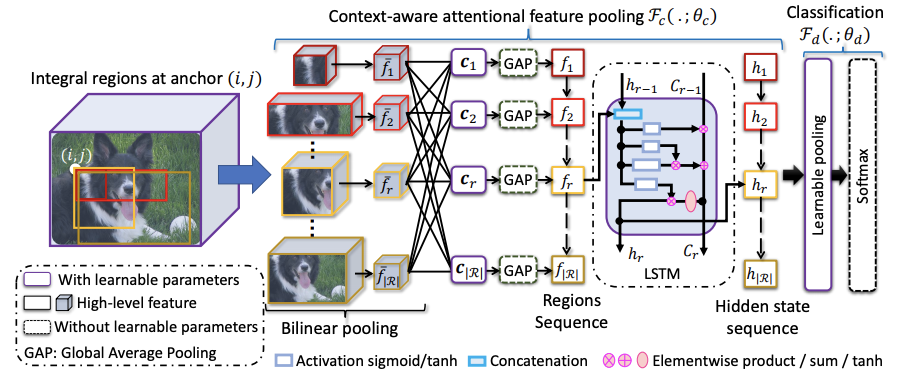
定義卷積網絡輸出的特徵為x=\mathcal{F}_b(I_n;\theta_b),CAP的模塊綜合考慮像素級特徵、小區域特徵、大區域特徵以及圖片級特徵的上下文信息進行分類。
-
pixel-level contextual information
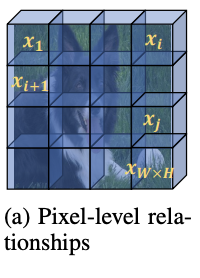
像素級特徵的上下文信息主要學習像素間的關聯度p(x_i|x_j;\theta_p),在計算j位置的輸出時根據關聯度綜合所有其他像素特徵,直接使用self-attention實現,特徵轉化使用$1\times 1$卷積。這一步直接對主幹網絡輸出的特徵進行操作,但沒在整體流程圖中體現。
-
Proposing integral regions
為了更高效地學習上下文信息,論文在特徵圖o上定義不同粒度級別的基本區域,粒度級別由區域的大小決定。假設(i,j)位置上的最小的區域為r(i,j\Delta_x,\Delta_y)為例,可通過放大寬高衍生出一系列區域R=\{r(i,j,m\Delta_x,n\Delta_y)\},i < i + m \Delta_x \le W,j < j + n \Delta_y \le H。在不同的位置產生相似的區域合集R,得到最終的區域合集\mathcal{R}=\{R\}。\mathcal{R}覆蓋了所有的位置的不同寬高比區域,可以提供全面的上下文信息,幫助在圖片的不同層級提供細微特徵。
-
Bilinear pooling
按照上一步,在特徵圖上得到|\mathcal{R}|個區域,大小從最小的\Delta_x\times\Delta_y\times C到最大的W\times H\times C,論文的目標是將不同大小的區域表示為固定大小的特徵,主要採用了雙線性插值。定義T_{\psi}(y)為坐標轉換函數,y=(i,j)\in \mathbb{R}^c為區域坐標,對應的特徵值為R(y)\in \mathbb{R}^C,則轉換後的圖片\tilde{R}的\tilde{y}坐標上的值為:
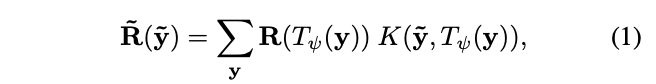
R(T_{\psi(y)})為採樣函數,K(\cdots)為核函數,這裡採用的是最原始的方法,將目標坐標映射回原圖,取最近的四個點,按距離進行輸出,最終得到池化後的固定特徵\bar{f}(w\times h\times C)。
-
Context-aware attention
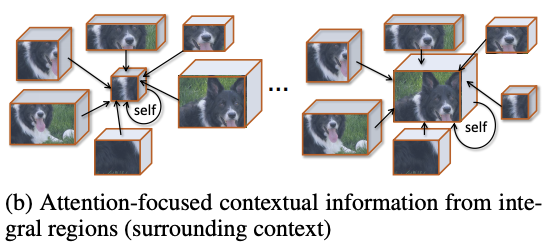
這裡,論文使用全新的注意力機制來獲取上下文信息,根據\bar{f}_r與其他特徵\bar{f}_{r^{‘}}(r, r^{‘}\in \mathcal{R})的相似性進行加權輸出,使得模型能夠選擇性地關注更相關的區域,從而產生更全面的上下文信息。以查詢項q(\bar{f}_r)和一組關鍵詞項k(\bar{f}_{r^{‘}}),輸出上下文向量c_r:
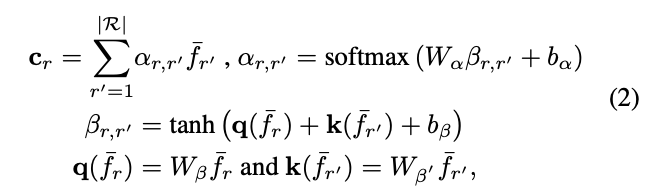
參數矩陣W_{\beta}和W_{\beta^{‘}}用來將輸入特徵轉換為查詢項核關鍵項,W_{\alpha}為非線性組合,b_{\alpha}和b_{\beta}為偏置項,整體的可學習參數為\{W_{\beta},W_{\beta^{‘}},W_{\alpha},b_{\alpha},b_{\beta}\}\in\theta_c,而注意力項\alpha_{r,r^{‘}}則代表兩個特徵之間的相似性。這樣,上下文向量c_r能夠代表區域\bar{f}_r蘊含的上下文信息,這些信息是根據其與其他區域的相關程度獲得的,整體的計算思想跟self-attention基本相似。
-
Spatial structure encoding
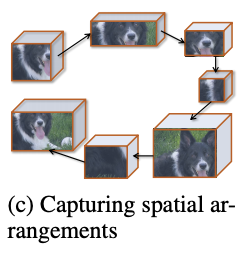
上下文向量c=\{c_r|r=1,\cdots|\mathcal{R}|\}描述了區域的關鍵程度和特點,為了進一步加入空間排列相關的結構信息,論文將區域的上下文向量c轉為區域序列(論文按上到下、左到右的順序),輸入到循環神經網絡中,使用循環神經網絡的隱藏單元h_r\in\mathbb{R}^n來表達結構特徵。
區域r的中間特徵可表示為h_r=\mathcal{F}_h(h_{r-1},f_r;\theta_h),\mathcal{F}_h採用LSTM,\theta_h\in\theta_c包含LSTM的相關參數。為了增加泛化能力和減少計算量,上下文特徵f_r\in\mathbb{R}^{1\times C}由c_r\in\mathbb{R}^{w\times h\times C}進行全局平均池化得到,最終輸出上下文特徵序列f=(f_1,f_2,\cdots,f_r,\cdots,f_{|\mathcal{R}|})對應的隱藏狀態序列h=(h_1,h_2,\cdots,h_r,\cdots,h_{|\mathcal{R}|}),後續用於分類模塊中。
Classification
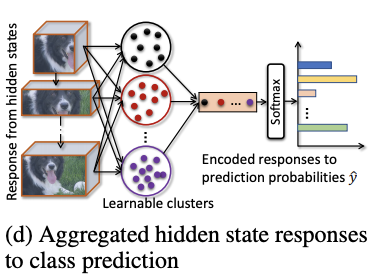
為了進一步引導模型分辨細微的變化,論文提出可學習的池化操作,能夠通過組合響應相似的隱藏層h_r來整合特徵信息。論文借鑒NetVLAD的思想,用可導的聚類方法來對隱藏層的響應值進行轉換,首先計算隱藏層響應對類簇k的相關性,再加權到類簇k的VLAD encoding中:
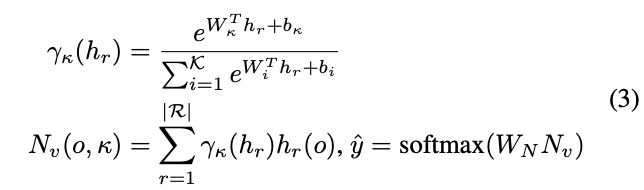
每個類簇都有其可學習的參數W_i和b_i,整體思想基於softmax,將隱藏層的響應值按softmax的權重分配到不同的類簇中。在得到所有類簇的encoding向量後,使用可學習的權值W_N和softmax進行歸一化。因此,分類模塊\mathcal{F}_d的可學習參數為\theta_d=\{W_i, b_i, W_N\}。
Experiments and Discussion
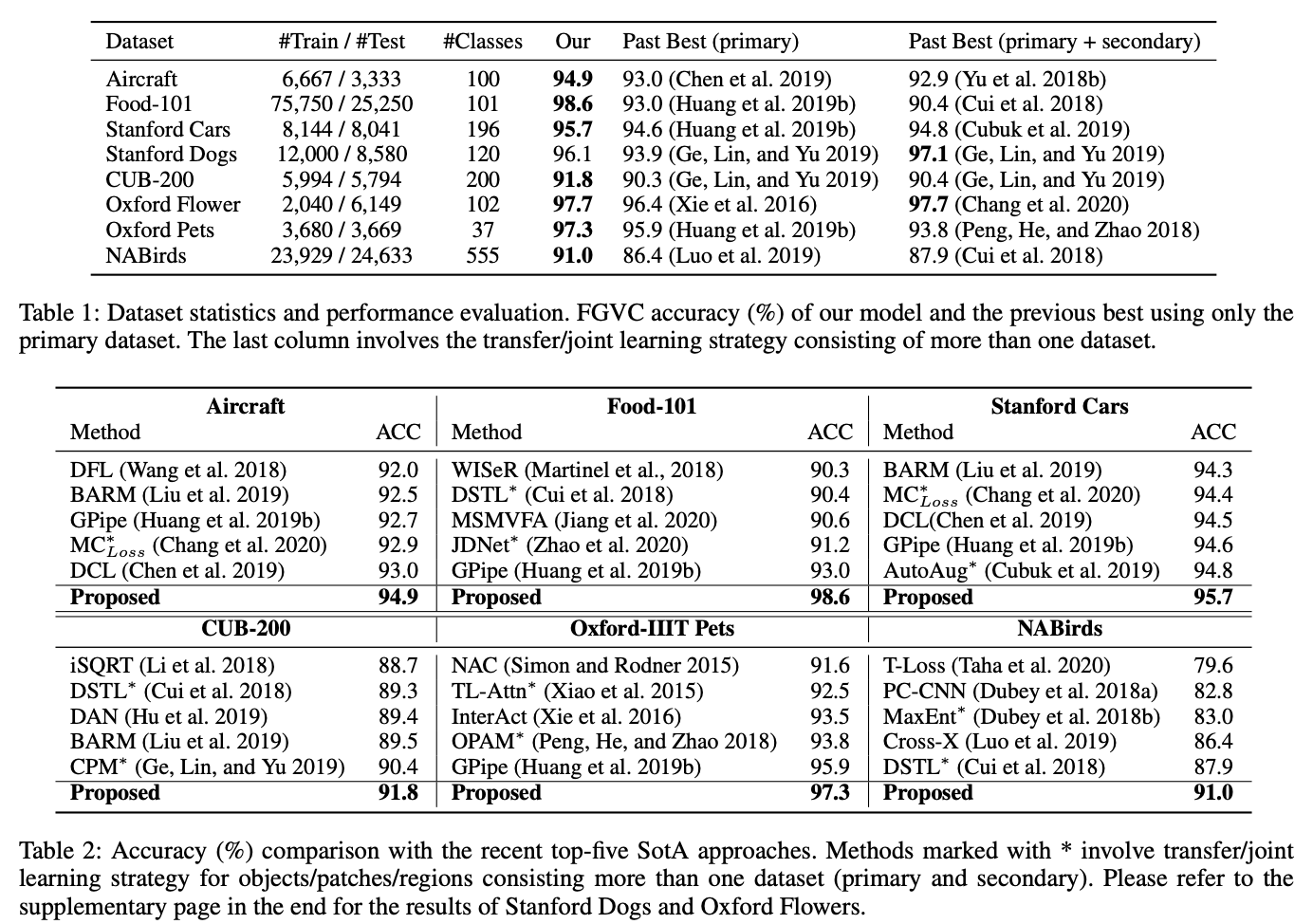
在不同的數據集上,對不同方法進行對比。
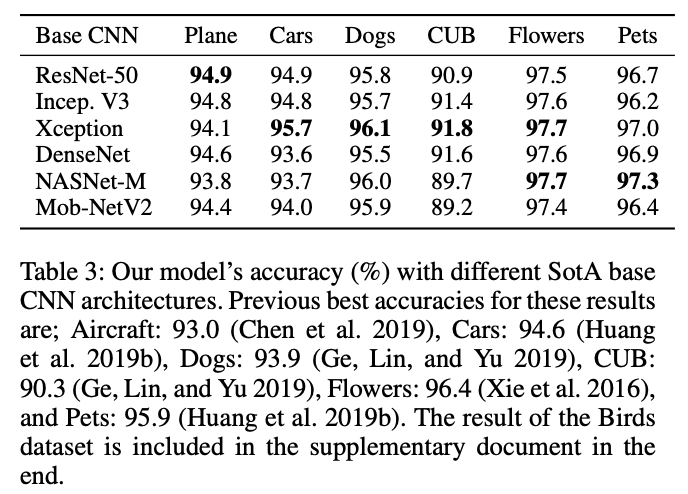
不同主幹網絡下的準確率對比。

不同模塊輸出特徵的可視化,圖b是加入CAP後,主幹網絡輸出的特徵。
Conclusion
論文提出細粒度分類解決方案CAP,通過上下文感知的注意力機制來幫助模型發現目標的細微特徵變化。除了像素級別的注意力機制,還有區域級別的注意力機制以及局部特徵編碼方法,與以往的視覺方案很不同,值得一看。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的算法工程筆記】



