redis持久化之RDB (七)
一:什麼是redis的持久化
Redis 持久化
Redis 提供了不同級別的持久化方式:
- RDB持久化方式能夠在指定的時間間隔能對你的數據進行快照存儲.
- AOF持久化方式記錄每次對服務器寫的操作,當服務器重啟的時候會重新執行這些命令來恢復原始的數據,AOF命令以redis協議追加保存每次寫的操作到文件末尾.Redis還能對AOF文件進行後台重寫,使得AOF文件的體積不至於過大.
- 如果你只希望你的數據在服務器運行的時候存在,你也可以不使用任何持久化方式.
- 你也可以同時開啟兩種持久化方式, 在這種情況下, 當redis重啟的時候會優先載入AOF文件來恢復原始的數據,因為在通常情況下AOF文件保存的數據集要比RDB文件保存的數據集要完整.
- 最重要的事情是了解RDB和AOF持久化方式的不同,讓我們以RDB持久化方式開始:
RDB的優點
- RDB是一個非常緊湊的文件,它保存了某個時間點得數據集,非常適用於數據集的備份,比如你可以在每個小時報保存一下過去24小時內的數據,同時每天保存過去30天的數據,這樣即使出了問題你也可以根據需求恢復到不同版本的數據集.
- RDB是一個緊湊的單一文件,很方便傳送到另一個遠端數據中心或者亞馬遜的S3(可能加密),非常適用於災難恢復.
- RDB在保存RDB文件時父進程唯一需要做的就是fork出一個子進程,接下來的工作全部由子進程來做,父進程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 與AOF相比,在恢復大的數據集的時候,RDB方式會更快一些.
-
RDB的缺點
- 如果你希望在redis意外停止工作(例如電源中斷)的情況下丟失的數據最少的話,那麼RDB不適合你.雖然你可以配置不同的save時間點(例如每隔5分鐘並且對數據集有100個寫的操作),是Redis要完整的保存整個數據集是一個比較繁重的工作,你通常會每隔5分鐘或者更久做一次完整的保存,萬一在Redis意外宕機,你可能會丟失幾分鐘的數據.
- RDB 需要經常fork子進程來保存數據集到硬盤上,當數據集比較大的時候,fork的過程是非常耗時的,可能會導致Redis在一些毫秒級內不能響應客戶端的請求.如果數據集巨大並且CPU性能不是很好的情況下,這種情況會持續1秒,AOF也需要fork,但是你可以調節重寫日誌文件的頻率來提高數據集的耐久度.
二:Redis的RDB是什麼?
在指定的時間間隔內將內存中的數據集快照寫入磁盤,也就是行話講的Snapshot快照,它恢復時是將快照文件直接讀到內存里,Redis會單獨創建(fork)一個子進程來進行持久化,會先將數據寫入到。
一個臨時文件中,待持久化過程都結束了,再用這個臨時文件替換上次持久化好的文件。整個過程中,主進程是不進行任何IO操作的,這就確保了極高的性能。如果需要進行大規模數據的恢復,且對於數據恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺點是最後一次持久化後的數據可能丟失。
三:Redis配置文件redis.conf中關於RDB的相關配置
################################ SNAPSHOTTING ################################ # # Save the DB on disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving completely by commenting out all "save" lines. # # It is also possible to remove all the previously configured save # points by adding a save directive with a single empty string argument # like in the following example: # # save "" # 存 DB 到磁盤: # # 格式:save <間隔時間(秒)> <寫入次數> # # 根據給定的時間間隔和寫入次數將數據保存到磁盤 # # 下面的例子的意思是: # 900 秒內如果至少有 1 個 key 的值變化,則保存 # 300 秒內如果至少有 10 個 key 的值變化,則保存 # 60 秒內如果至少有 10000 個 key 的值變化,則保存 # # 注意:你可以注釋掉所有的 save 行來停用保存功能。 # 也可以直接一個空字符串來實現停用: # save "" save 900 1 save 300 10 save 60 10000 # By default Redis will stop accepting writes if RDB snapshots are enabled # (at least one save point) and the latest background save failed. # This will make the user aware (in a hard way) that data is not persisting # on disk properly, otherwise chances are that no one will notice and some # disaster will happen. # # If the background saving process will start working again Redis will # automatically allow writes again. # # However if you have setup your proper monitoring of the Redis server # and persistence, you may want to disable this feature so that Redis will # continue to work as usual even if there are problems with disk, # permissions, and so forth. # 默認情況下,如果 redis 最後一次的後台保存失敗,redis 將停止接受寫操作, # 這樣以一種強硬的方式讓用戶知道數據不能正確的持久化到磁盤, # 否則就會沒人注意到災難的發生。 # # 如果後台保存進程重新啟動工作了,redis 也將自動的允許寫操作。 # # 然而你要是安裝了靠譜的監控,你可能不希望 redis 這樣做,那你就改成 no 好了。<br># 如果配置成no 那麼表示你不在乎數據的一致性,或者你又其他手段發現合控制。 stop-writes-on-bgsave-error yes # Compress string objects using LZF when dump .rdb databases? # For default that's set to 'yes' as it's almost always a win. # If you want to save some CPU in the saving child set it to 'no' but # the dataset will likely be bigger if you have compressible values or keys. # 是否在 dump .rdb 數據庫的時候使用 LZF 壓縮字符串 # 默認都設為 yes # 如果你希望保存子進程節省點 cpu ,你就設置它為 no , # 不過這個數據集可能就會比較大 rdbcompression yes # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. # This makes the format more resistant to corruption but there is a performance # hit to pay (around 10%) when saving and loading RDB files, so you can disable it # for maximum performances. # # RDB files created with checksum disabled have a checksum of zero that will # tell the loading code to skip the check. # 是否校驗rdb文件 但是CRC64算法會增大大約10%的性能消耗 rdbchecksum yes # The filename where to dump the DB # 設置 dump 文件的默認文件文件名<br>dbfilename dump.rdb # The working directory. # # The DB will be written inside this directory, with the filename specified # above using the 'dbfilename' configuration directive. # # The Append Only File will also be created inside this directory. # # Note that you must specify a directory here, not a file name. # 工作目錄 # 例如上面的 dbfilename 只指定了文件名, # 但是它會寫入到這個目錄下。這個配置項一定是個目錄,而不能是文件名。 dir ./
注意,當執行類似 flushall 這樣的提交命令的時候也會產生新的RDB文件,所以備份的時候執行的RDB文件也是空的。該命令會清除redis在內存中的所有數據。執行該命令後,只要redis中配置的快照規則不 為空, 也就是save 的規則存在。redis就會執行一次快照操作。不管規則是什麼樣的都會執行。如果沒有定義 快照規則,就不會執行快照操作。
恢復時只要把RDB文件移動到redis安裝目錄下並啟動服務,就能自動恢復
用戶執行SAVE或者GBSAVE命令:
除了讓Redis自動進行快照以外,當我們對服務進行重啟或者服務器遷移我們需要人工去干預備份。 redis提供了兩條命令來完成這個任務
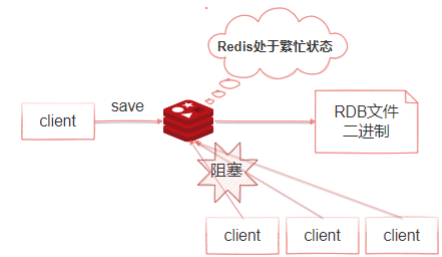
save命令 如下圖所示,當執行save命令時,Redis同步做快照操作,在快照執行過程中會阻塞所有來自客 戶端的請求。當redis內存中的數據較多時,通過該命令將導致Redis較長時間的不響應。所以不建 議在生產環境上使用這個命令,而是推薦使用bgsave命令
bgsave命令 如下圖所示,bgsave命令可以在後台異步地進行快照操作,快照的同時服務器還可以繼續響應 來自客戶端的請求。執行BGSAVE後,Redis會立即返回ok表示開始執行快照操作,在redis-cli終 端,通過 LASTSAVE 這個命令可以獲取最近一次成功執行快照的時間(以 UNIX 時間戳格式表示)。
- redis使用fork函數複製一份當前進程的副本(子進程)
- 父進程繼續接收並處理客戶端發來的命令,而子進程開始將內存中的數據寫入硬盤中的臨時文件
- 當子進程寫入完所有數據後會用該臨時文件替換舊的RDB文件,至此,一次快照操作完成。
redis在進行快照的過程中不會修改RDB文件,只有快照結束後才會將舊的文件替換成新 的,也就是說任何時候RDB文件都是完整的。 這就使得我們可以通過定時備份RDB文件來實現 redis數據庫的備份, RDB文件是經過壓縮的二進制文件,佔用的空間會小於內存中的數據,更加利於傳輸。
bgsave是異步執行快照的,bgsave寫入的數據就是for進程時redis的數據狀態,一旦完成 fork,後續執行的新的客戶端命令對數據產生的變更都不會反應到本次快照。
Redis啟動後會讀取RDB快照文件,並將數據從硬盤載入到內存。根據數據量大小以及服務器性能不 同,這個載入的時間也不同。

RDB 文件 的優勢和劣勢:
一、優勢
RDB 是一個非常緊湊(compact)的文件,它保存了 redis 在某個時間點上的數據集。這種文件非常適合用於進行備份和災難恢復。
生成 RDB 文件的時候,redis 主進程會 fork()一個子進程來處理所有保存工作,主進程不需要進行任何磁盤 IO 操作。
RDB 在恢復大數據集時的速度比 AOF 的恢復速度要快。
二、劣勢
RDB 方式數據沒辦法做到實時持久化/秒級持久化。因為 bgsave 每次運行都要執行 fork 操作創建子進程,頻繁執行成本過高。
在一定間隔時間做一次備份,所以如果 redis 意外 down 掉的話,就會丟失最後一次快照之後的所有修改(數據有丟失)。如果數據相對來說比較重要,希望將損失降到最小,則可以使用 AOF 方式進行持久化。


