Google搜索為什麼不能無限分頁?
- 2022 年 6 月 9 日
- 筆記
- elasticsearch, 深度分頁

這是一個很有意思卻很少有人注意的問題。
當我用Google搜索MySQL這個關鍵詞的時候,Google只提供了13頁的搜索結果,我通過修改url的分頁參數試圖搜索第14頁數據,結果出現了以下的錯誤提示:
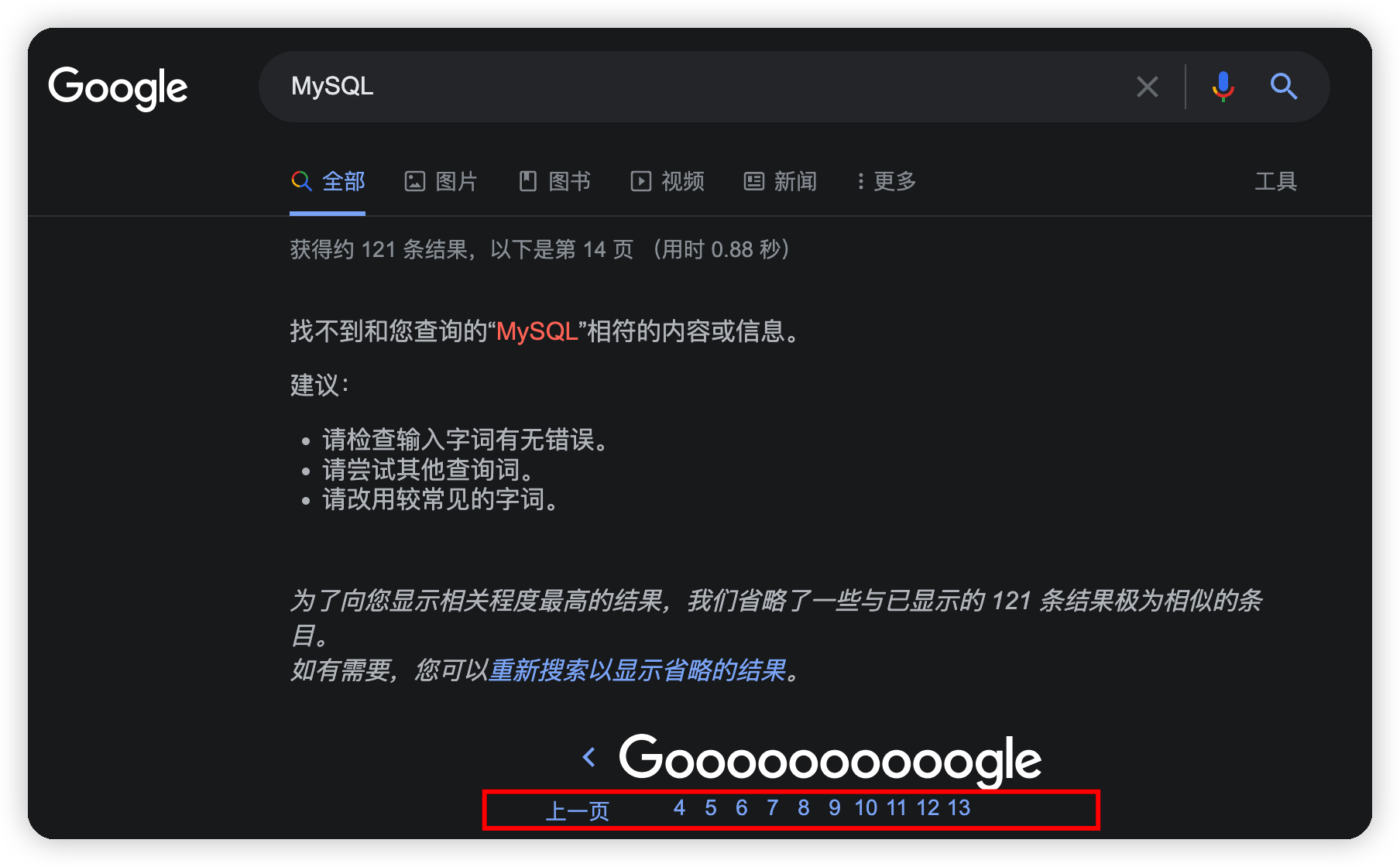
百度搜索同樣不提供無限分頁,對於MySQL關鍵詞,百度搜索提供了76頁的搜索結果。
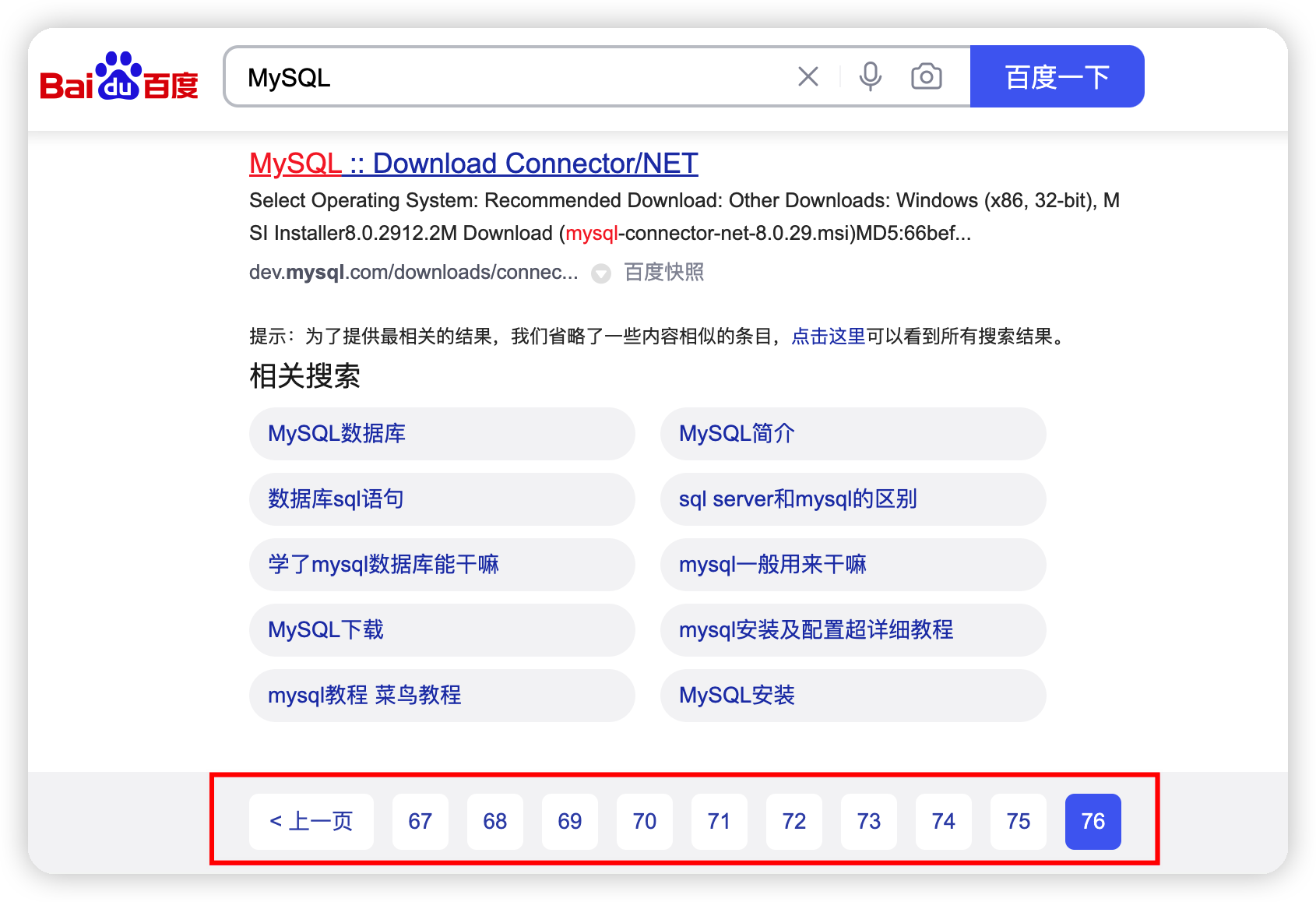
為什麼不支持無限分頁
強如Google搜索,為什麼不支持無限分頁?無非有兩種可能:
- 做不到
- 沒必要
「做不到」是不可能的,唯一的理由就是「沒必要」。
首先,當第1頁的搜索結果沒有我們需要的內容的時候,我們通常會立即更換關鍵詞,而不是翻第2頁,更不用說翻到10頁往後了。這是沒必要的第一個理由——用戶需求不強烈。
其次,無限分頁的功能對於搜索引擎而言是非常消耗性能的。你可能感覺很奇怪,翻到第2頁和翻到第1000頁不都是搜索嘛,能有什麼區別?
實際上,搜索引擎高可用和高伸縮性的設計帶來的一個副作用就是無法高效實現無限分頁功能,無法高效意味着能實現,但是代價比較大,這是所有搜索引擎都會面臨的一個問題,專業上叫做「深度分頁」。這也是沒必要的第二個理由——實現成本高。
我自然不知道Google的搜索具體是怎麼做的,因此接下來我用ES(Elasticsearch)為例來解釋一下為什麼深度分頁對搜索引擎來說是一個頭疼的問題。
為什麼拿ES舉例子
Elasticsearch(下文簡稱ES)實現的功能和Google以及百度搜索提供的功能是相同的,而且在實現高可用和高伸縮性的方法上也大同小異,深度分頁的問題都是由這些大同小異的優化方法導致的。
什麼是ES
ES是一個全文搜索引擎。
全文搜索引擎又是個什麼鬼?
試想一個場景,你偶然聽到了一首旋律特別優美的歌曲,回家之後依然感覺餘音繞梁,可是無奈你只記得一句歌詞中的幾個字:「傘的邊緣」。這時候搜索引擎就發揮作用了。
使用搜索引擎你可以獲取到帶有「傘的邊緣」關鍵詞的所有結果,這些結果有一個術語,叫做文檔。並且搜索結果是按照文檔與關鍵詞的相關性進行排序之後返回的。我們得到了全文搜索引擎的定義:
全文搜索引擎是根據文檔內容查找相關文檔,並按照相關性順序返回搜索結果的一種工具
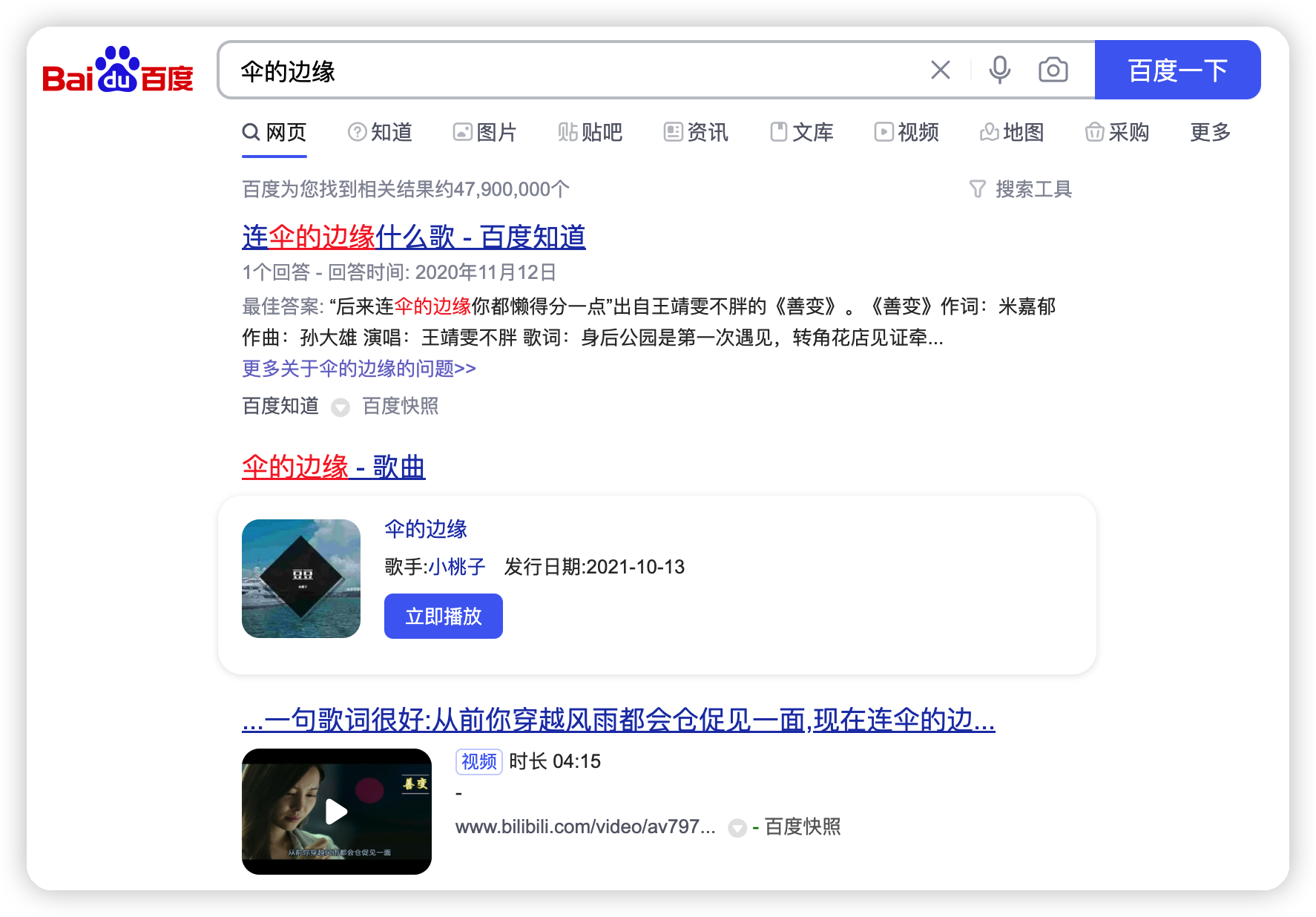
網上衝浪太久,我們會漸漸地把計算機的能力誤以為是自己本身具備的能力,比如我們可能誤以為我們大腦本身就很擅長這種搜索。恰恰相反,全文檢索的功能是我們非常不擅長的。
舉個例子,如果我對你說:靜夜思。你可能脫口而出:床前明月光,疑是地上霜。舉頭望明月,低頭思故鄉。但是如果我讓你說出帶有「月」的古詩,想必你會費上一番功夫。
包括我們平時看的書也是一樣,目錄本身就是一種符合我們人腦檢索特點的一種搜索結構,讓我們可以通過文檔ID或者文檔標題這種總領性的標識來找到某一篇文檔,這種結構叫做正排索引。

而全文搜索引擎恰好相反,是通過文檔中的內容來找尋文檔,詩詞大會中的飛花令就是人腦版的全文搜索引擎。

全文搜索引擎依賴的數據結構就是大名鼎鼎的倒排索引(「倒排」這個詞就說明這種數據結構和我們正常的思維方式恰好相反),它是單詞和文檔之間包含關係的一種具體實現形式。
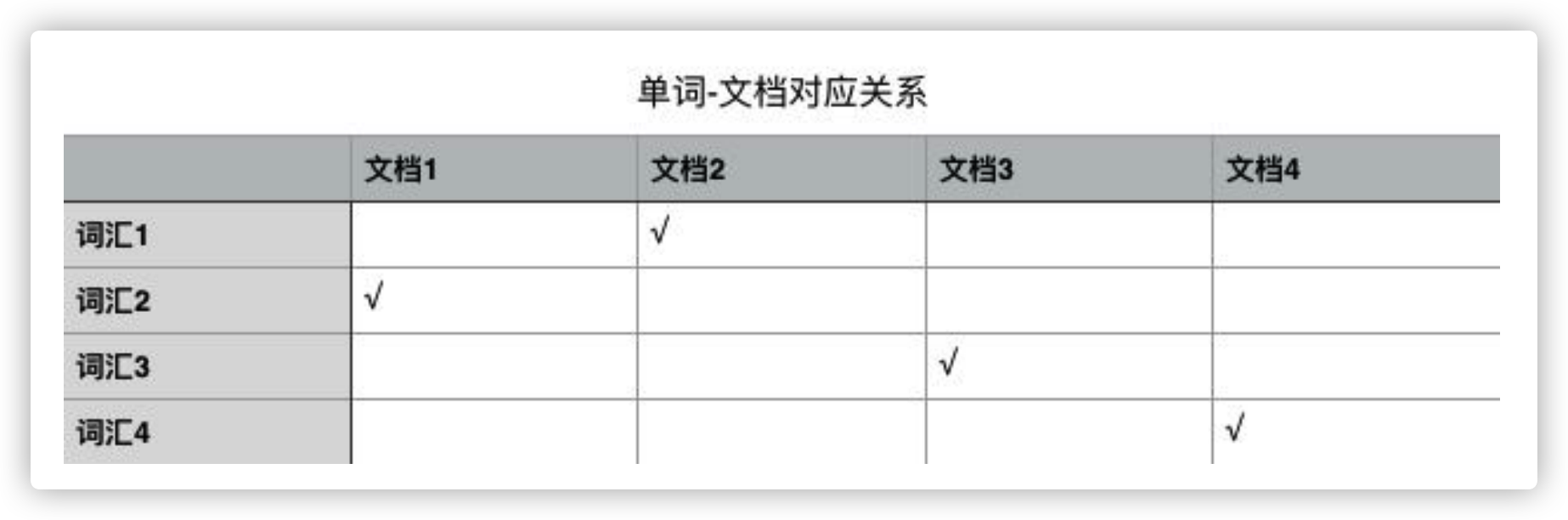
打住!不能繼續展開了話題了,趕緊一句話介紹完ES吧!
ES是一款使用倒排索引數據結構、能夠根據文檔內容查找相關文檔,並按照相關性順序返回搜索結果的全文搜索引擎
高可用的秘密——副本(Replication)
高可用是企業級服務必須考慮的一個指標,高可用必然涉及到集群和分佈式,好在ES天然支持集群模式,可以非常簡單地搭建一個分佈式系統。
ES服務高可用要求其中一個節點如果掛掉了,不能影響正常的搜索服務。這就意味着掛掉的節點上存儲的數據,必須在其他節點上留有完整的備份。這就是副本的概念。

如上圖所示,Node1作為主節點,Node2和Node3作為副本節點保存了和主節點完全相同的數據,這樣任何一個節點掛掉都不會影響業務的搜索。滿足服務的高可用要求。
但是有一個致命的問題,無法實現系統擴容!即使添加另外的節點,對整個系統的容量擴充也起不到任何幫助。因為每一個節點都完整保存了所有的文檔數據。
因此,ES引入了分片(Shard)的概念。
PB級數量的基石——分片(Shard)
ES將每個索引(ES中一系列文檔的集合,相當於MySQL中的表)分成若干個分片,分片將儘可能平均地分配到不同的節點上。比如現在一個集群中有3台節點,索引被分成了5個分片,分配方式大致(因為具體如何平均分配取決於ES)如下圖所示。
這樣一來,集群的橫向擴容就非常簡單了,現在我們向集群中再添加2個節點,則ES會自動將分片均衡到各個節點之上:
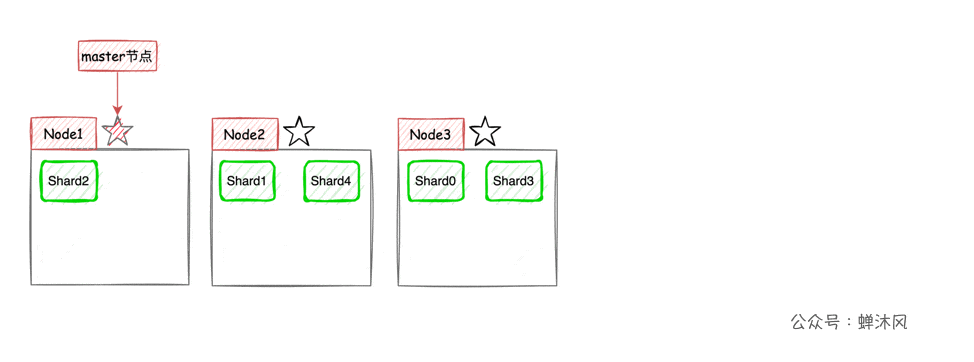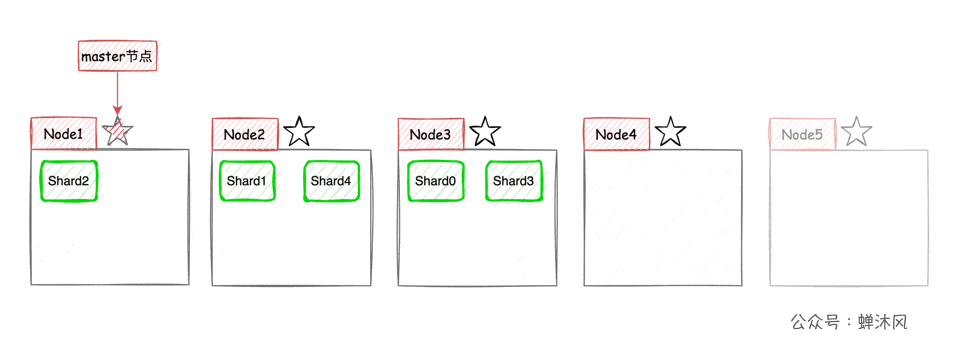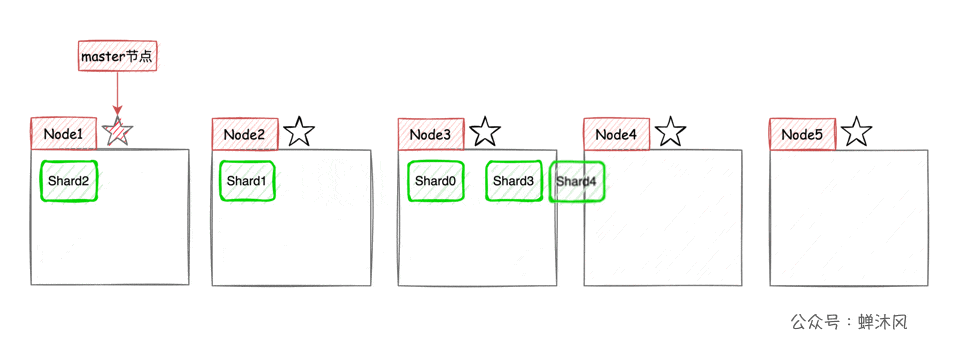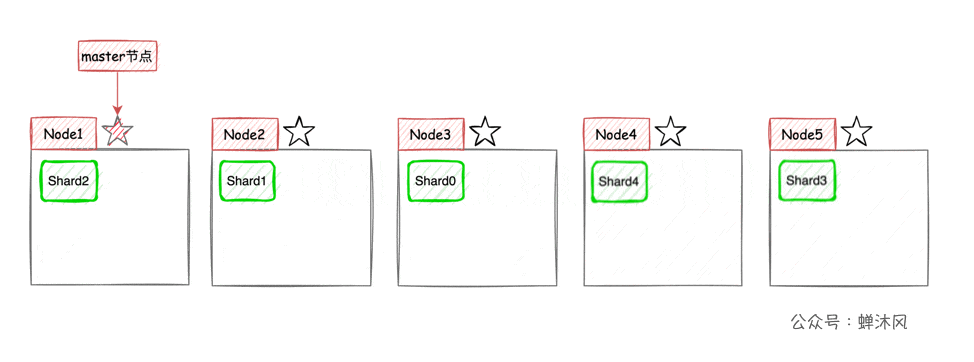
高可用 + 彈性擴容
副本和分片功能通力協作造就了ES如今高可用和支持PB級數據量的兩大優勢。
現在我們以3個節點為例,展示一下分片數量為5,副本數量為1的情況下,ES在不同節點上的分片排布情況:
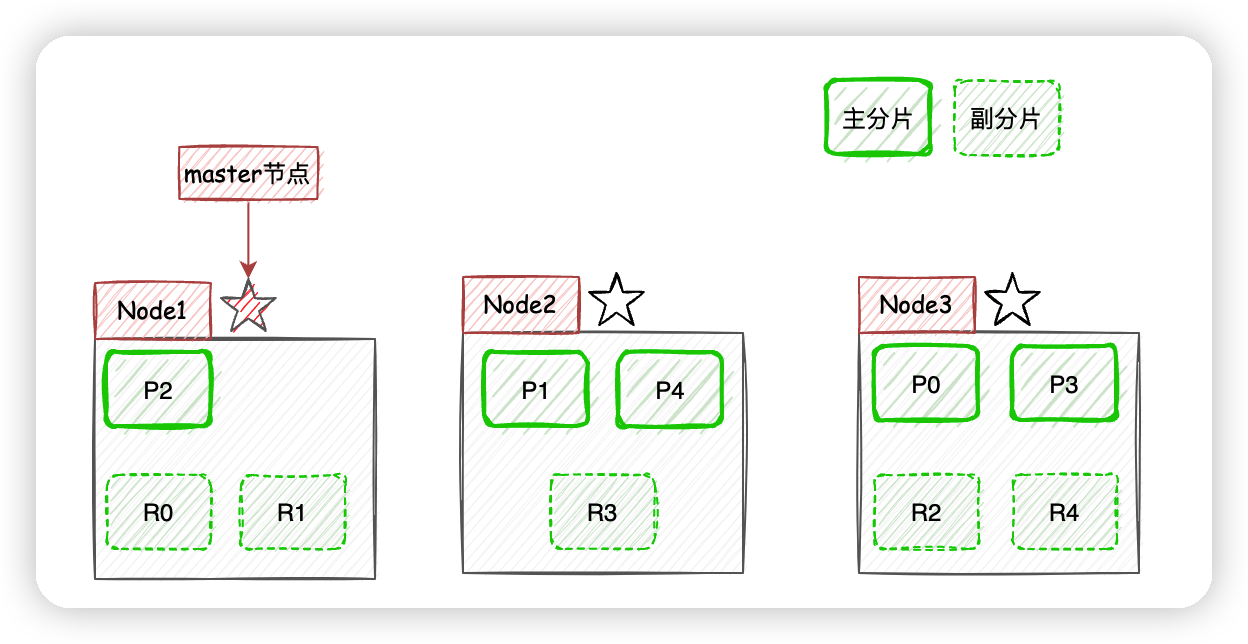
有一點需要注意,上圖示例中主分片和對應的副本分片不會出現在同一個節點上,至於為什麼,大家可以自己思考一下。
文檔的分佈式存儲
ES是怎麼確定某個文檔應該存儲到哪一個分片上呢?

通過上面的映射算法,ES將文檔數據均勻地分散在各個分片中,其中routing默認是文檔id。
此外,副本分片的內容依賴主分片進行同步,副本分片存在意義就是負載均衡、頂上隨時可能掛掉的主分片位置,成為新的主分片。
現在基礎知識講完了,終於可以進行搜索了。
ES的搜索機制
一圖勝千言:
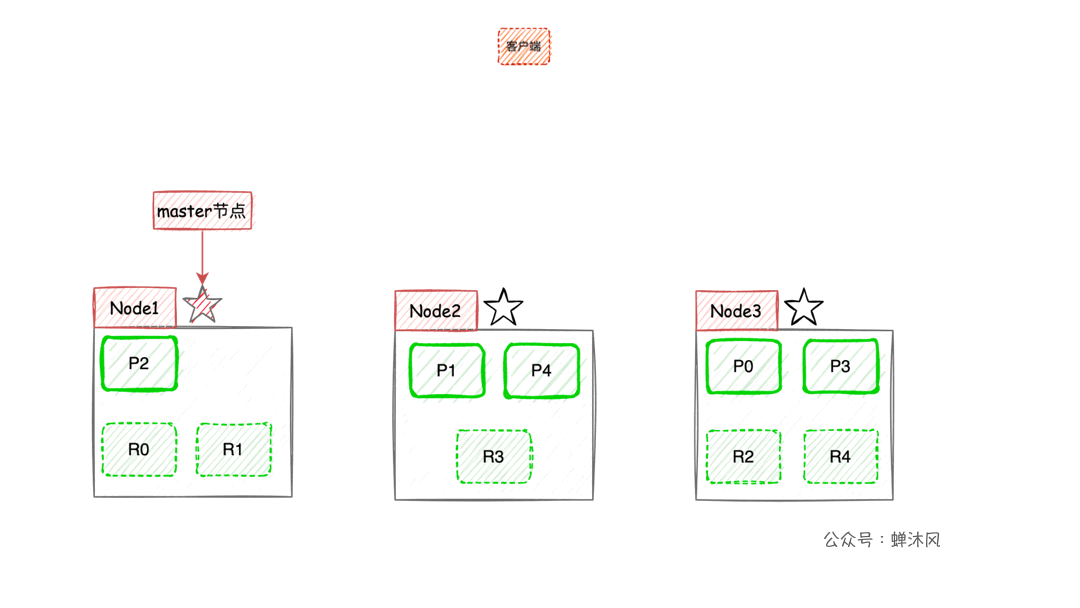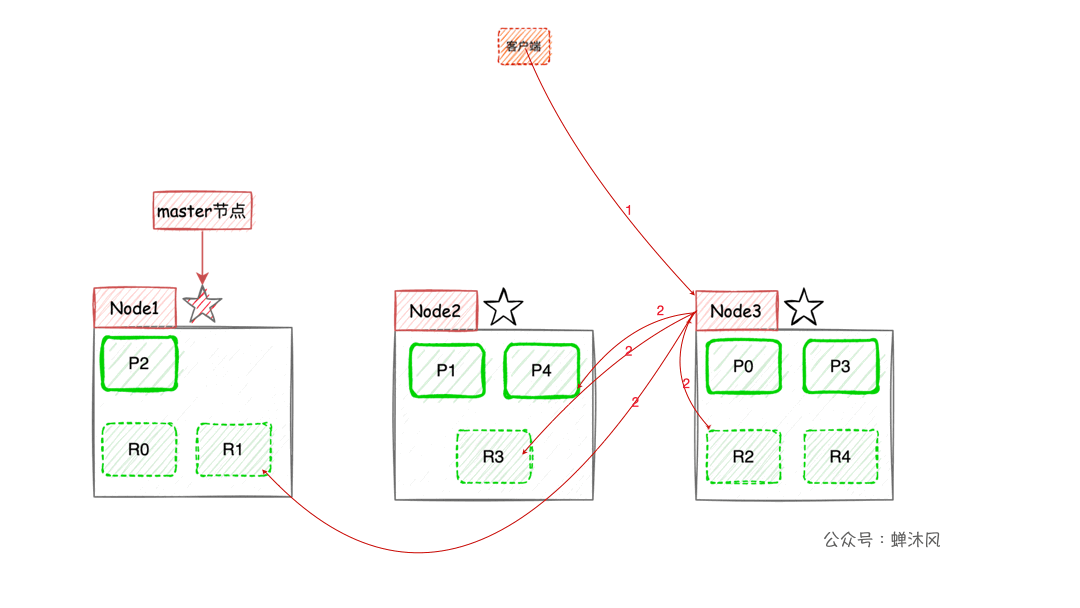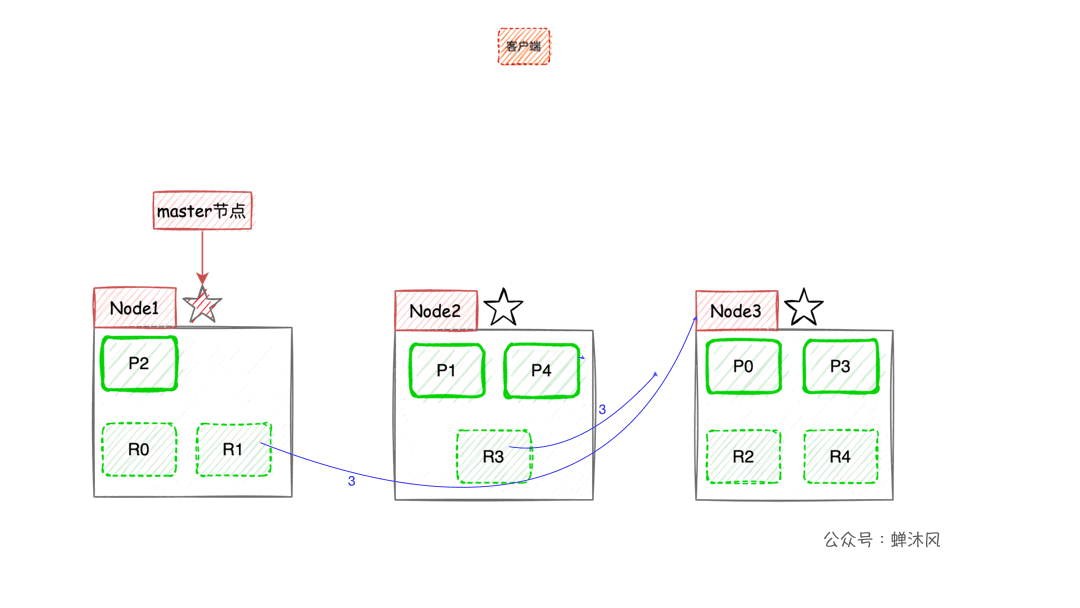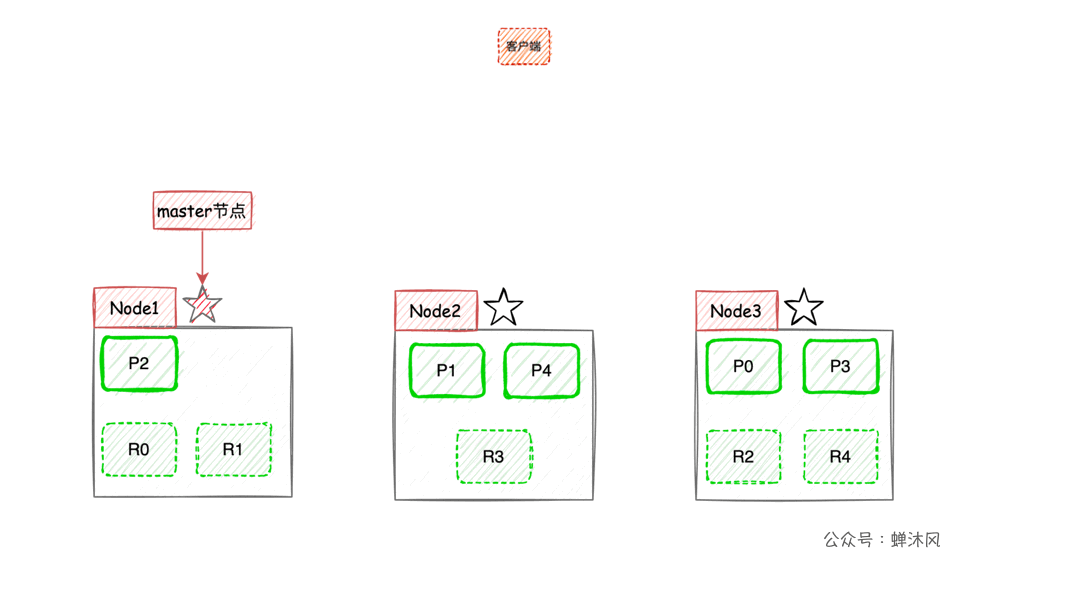
- 客戶端進行關鍵詞搜索時,
ES會使用負載均衡策略選擇一個節點作為協調節點(Coordinating Node)接受請求,這裡假設選擇的是Node3節點; Node3節點會在10個主副分片中隨機選擇5個分片(所有分片必須能包含所有內容,且不能重複),發送search request;- 被選中的5個分片分別執行查詢並進行排序之後返回結果給
Node3節點; Node3節點整合5個分片返回的結果,再次排序之後取到對應分頁的結果集返回給客戶端。
註:實際上
ES的搜索分為Query階段和Fetch階段兩個步驟,在Query階段各個分片返迴文檔Id和排序值,Fetch階段根據文檔Id去對應分片獲取文檔詳情,上面的圖片和文字說明對此進行了簡化,請悉知。
現在考慮客戶端獲取990~1000的文檔時,ES在分片存儲的情況下如何給出正確的搜索結果。
獲取990~1000的文檔時,ES在每個分片下都需要獲取1000個文檔,然後由Coordinating Node聚合所有分片的結果,然後進行相關性排序,最後選出相關性順序在990~1000的10條文檔。
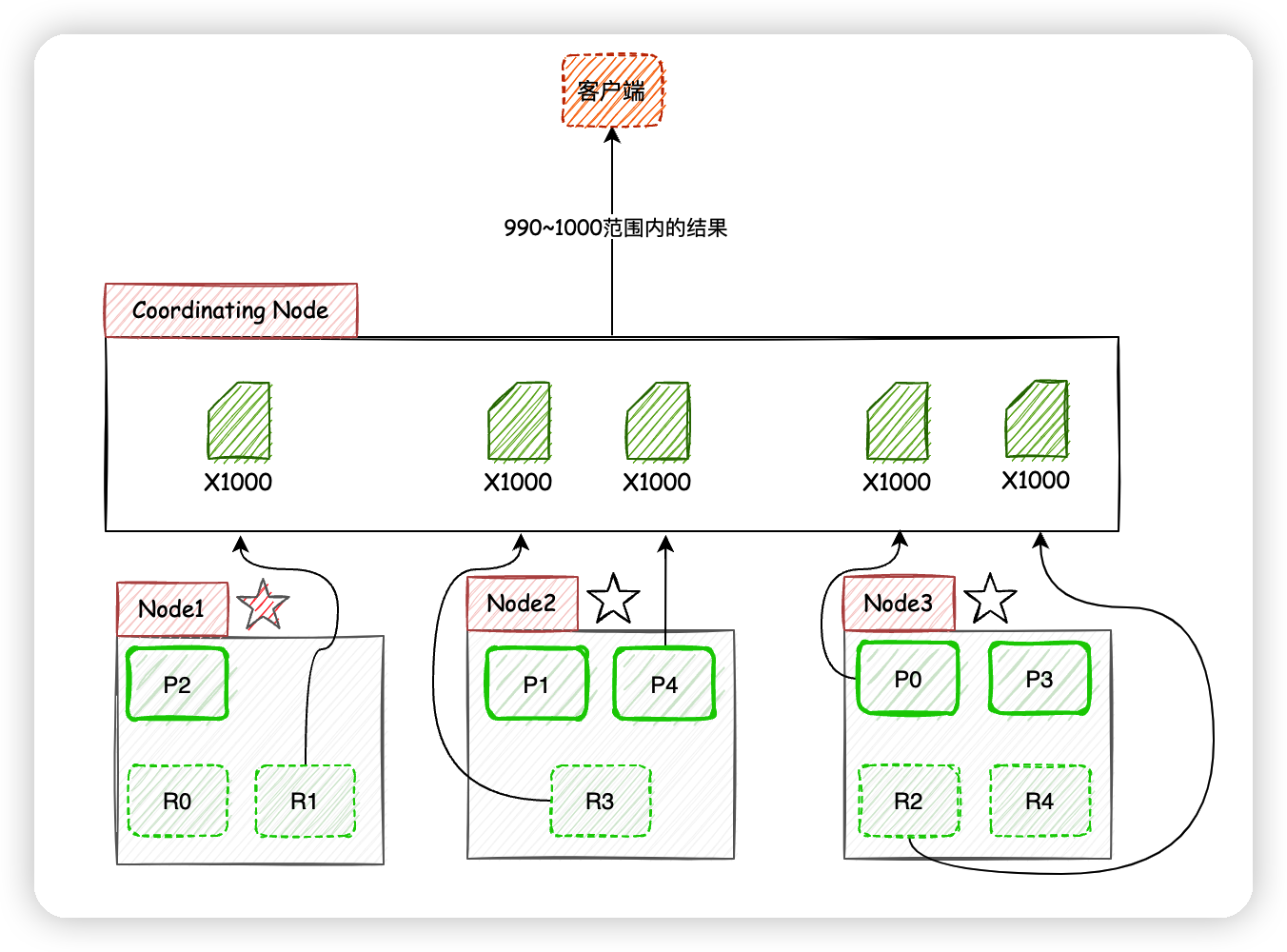
頁數越深,每個節點處理的文檔也就越多,佔用的內存也就越多,耗時也就越長,這也就是為什麼搜索引擎廠商通常不提供深度分頁的原因了,他們沒必要在客戶需求不強烈的功能上浪費性能。
公眾號「蟬沐風」,關注我,邂逅更多精彩文章
完。


