【爬蟲+情感判定+Top10高頻詞+詞雲圖】”王心凌”熱門彈幕python輿情分析
- 2022 年 6 月 6 日
- 筆記
- python可視化, python情感分析, Python數據分析, python文本挖掘, python輿情分析, 文本分析, 文本挖掘
一、背景介紹
最近一段時間,王心凌在浪姐3的表現格外突出,喚醒了一大批沉睡中的老粉,紛紛直呼’爺青回’!
針對此熱門事件,我用Python的爬蟲和情感分析技術,針對小破站的彈幕數據,分析了眾多網友彈幕的輿論導向,下面我們來看一下,是如何實現的分析過程。
二、代碼講解-爬虫部分
2.1 分析彈幕接口
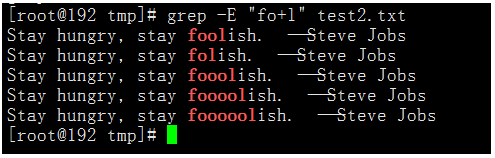
首先分析B站彈幕接口。
經過分析,得到的彈幕地址有兩種:
第一種://comment.bilibili.com/{cid}.xml
第二種://api.bilibili.com/x/v1/dm/list.so?oid={cid}
這兩種返回的結果一致!但都不全,都是只有部分彈幕!
以B站視頻 //www.bilibili.com/video/BV1qY4y157dz 為例,查看網頁源代碼,可以找到對應的cid為727777486,所以該視頻對應的彈幕接口地址是://comment.bilibili.com/727777486.xml
既然這樣,就好辦了,開始擼代碼!
2.2 講解爬蟲代碼
首先,導入需要用到的庫:
import re # 正則表達式提取文本
import requests # 爬蟲發送請求
from bs4 import BeautifulSoup as BS # 爬蟲解析頁面
import time
import pandas as pd # 存入csv文件
import os
然後,向視頻地址發送請求,解析出cid號:
r1 = requests.get(url=v_url, headers=headers)
html1 = r1.text
cid = re.findall('cid=(.*?)&aid=', html1)[0] # 獲取視頻對應的cid號
print('該視頻的cid是:', cid)
根據cid號,拼出xml接口地址,並再次發送請求:
danmu_url = '//comment.bilibili.com/{}.xml'.format(cid) # 彈幕地址
print('彈幕地址是:', danmu_url)
r2 = requests.get(danmu_url)
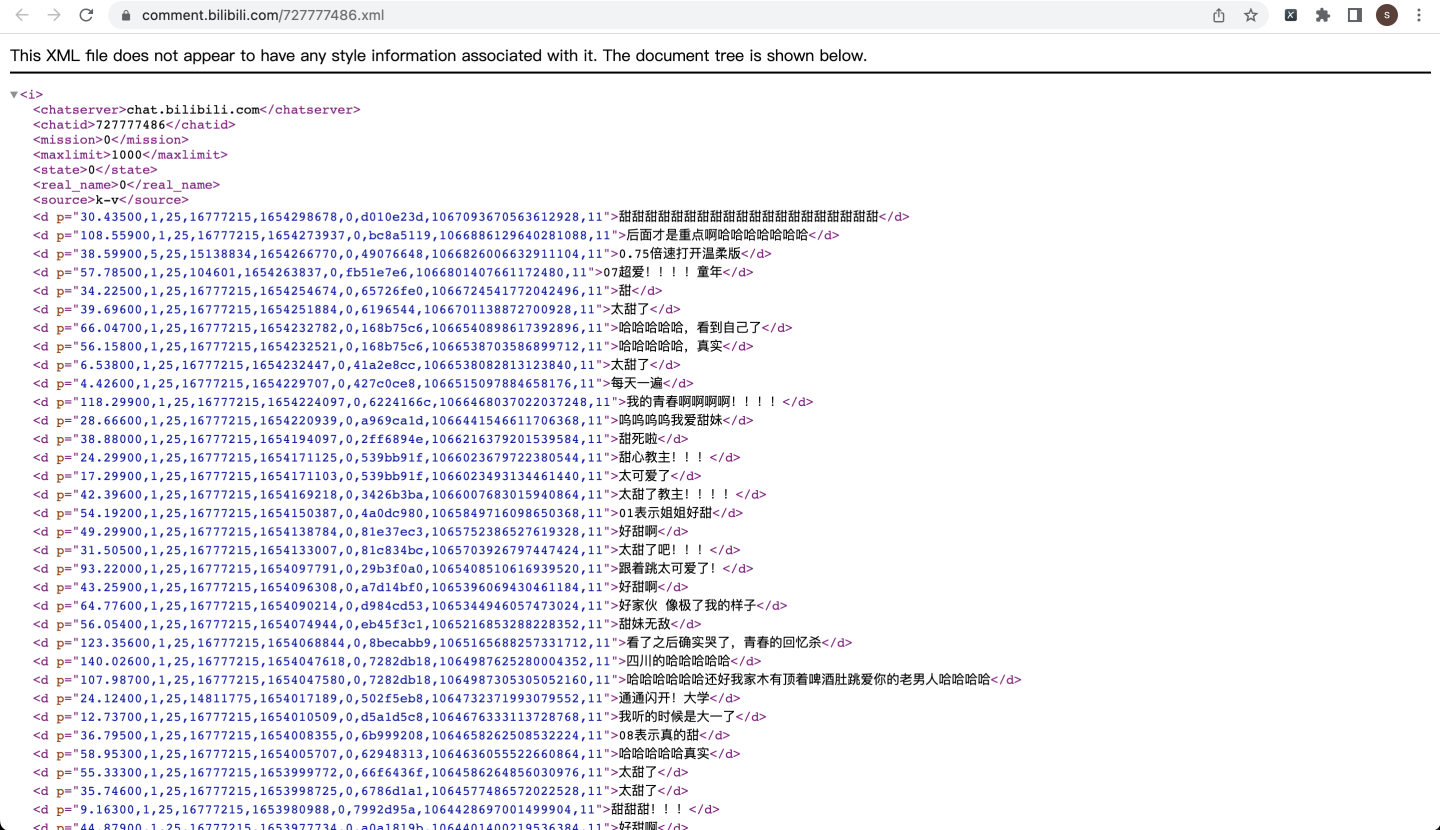
解析xml頁面:
soup = BS(html2, 'xml')
danmu_list = soup.find_all('d')
print('共爬取到{}條彈幕'.format(len(danmu_list)))
video_url_list = [] # 視頻地址
danmu_url_list = [] # 彈幕地址
time_list = [] # 彈幕時間
text_list = [] # 彈幕內容
for d in danmu_list:
data_split = d['p'].split(',') # 按逗號分隔
temp_time = time.localtime(int(data_split[4])) # 轉換時間格式
danmu_time = time.strftime("%Y-%m-%d %H:%M:%S", temp_time)
video_url_list.append(v_url)
danmu_url_list.append(danmu_url)
time_list.append(danmu_time)
text_list.append(d.text)
print('{}:{}'.format(danmu_time, d.text))
保存時應注意,為了避免多次寫入csv標題頭,像這樣:
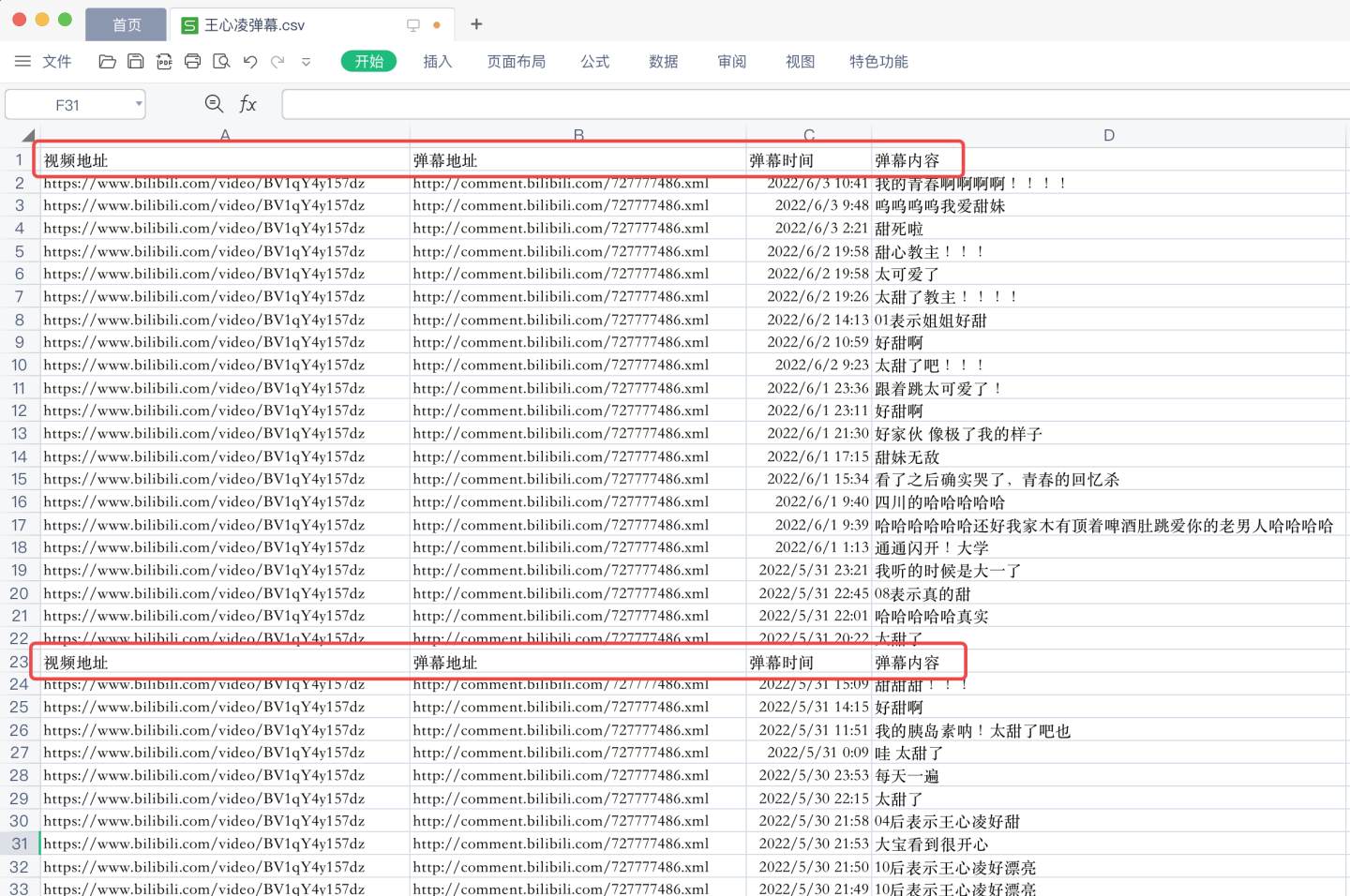
這裡,我寫了一個處理邏輯,大家看注釋,應該能明白:
if os.path.exists(v_result_file): # 如果文件存在,不需寫入字段標題
header = None
else: # 如果文件不存在,說明是第一次新建文件,需寫入字段標題
header = ['視頻地址', '彈幕地址', '彈幕時間', '彈幕內容']
df.to_csv(v_result_file, encoding='utf_8_sig', mode='a+', index=False, header=header) # 數據保存到csv文件
需要注意的是,encoding參數賦值為utf_8_sig,不然csv內容可能會產生亂碼,避免踩坑!
三、代碼講解-情感分析部分
3.1 整體思路
針對情感分析需求,我主要做了三個步驟的分析工作:
- 用SnowNLP給彈幕內容打標:積極、消極,並統計佔比情況
- 用jieba.analyse分詞,並統計top10高頻詞
- 用WordCloud繪製詞雲圖
首先,導入csv數據,並做數據清洗工作,不再贅述。
下面,正式進入情感分析代碼部分:
3.2 情感分析打標
情感分析計算得分值、分類打標,並畫出餅圖。
# 情感判定
for comment in v_cmt_list:
tag = ''
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.5:
tag = '消極'
neg_count += 1
elif sentiments_score > 0.5:
tag = '積極'
pos_count += 1
else:
tag = '中性'
mid_count += 1
score_list.append(sentiments_score) # 得分值
tag_list.append(tag) # 判定結果
df['情感得分'] = score_list
df['分析結果'] = tag_list
這裡,我設定情感得分值小於0.5為消極,大於0.5為積極,等於0.5為中性。(這個分界線,沒有統一標準,根據數據分佈情況和分析經驗自己設定分界線即可)
情感判定結果:
畫出佔比餅圖的代碼:
grp = df['分析結果'].value_counts()
print('正負面評論統計:')
print(grp)
grp.plot.pie(y='分析結果', autopct='%.2f%%') # 畫餅圖
plt.title('王心凌彈幕_情感分佈佔比圖')
plt.savefig('王心凌彈幕_情感分佈佔比圖.png') # 保存圖片
餅圖結果:
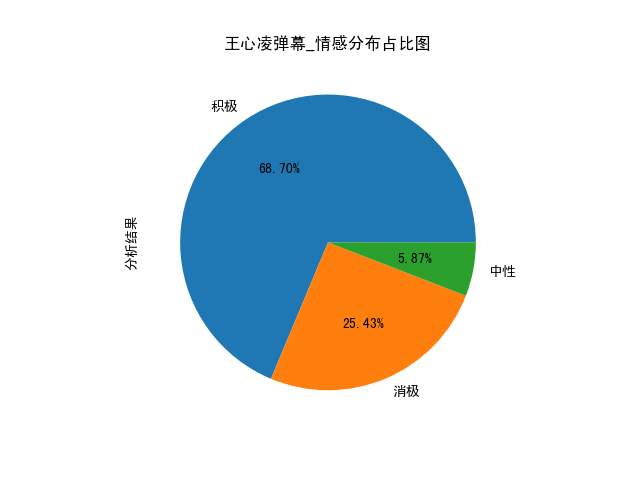
從佔比結果來看,大部分網友還是很認可王心凌的。
3.3 統計top10高頻詞
代碼如下:
# 2、用jieba統計彈幕中的top10高頻詞
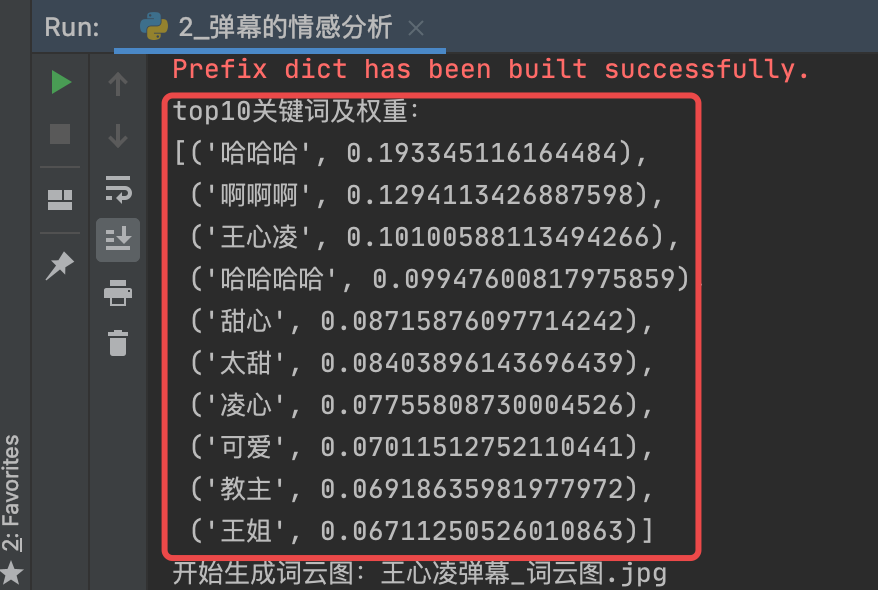
keywords_top10 = jieba.analyse.extract_tags(v_cmt_str, withWeight=True, topK=10)
print('top10關鍵詞及權重:')
pprint(keywords_top10)
這裡需要注意,在調用jieba.analyse.extract_tags函數時,要導入的是import jieba.analyse 而不是 import jieba
統計結果為:
3.4 繪製詞雲圖
注意別踩坑:
想要通過原始圖片的形狀生成詞雲圖,原始圖片一定要白色背景(實在沒有的話,PS修圖修一個吧),否則生成的是滿屏詞雲!!
try:
stopwords = v_stopwords # 停用詞
backgroud_Image = np.array(Image.open('王心凌_背景圖.png')) # 讀取背景圖片
wc = WordCloud(
background_color="white", # 背景顏色
width=1500, # 圖寬
height=1200, # 圖高
max_words=1000, # 最多字數
font_path='/System/Library/Fonts/SimHei.ttf', # 字體文件路徑,根據實際情況(Mac)替換
# font_path="C:\Windows\Fonts\simhei.ttf", # 字體文件路徑,根據實際情況(Windows)替換
stopwords=stopwords, # 停用詞
mask=backgroud_Image, # 背景圖片
)
jieba_text = " ".join(jieba.lcut(v_str)) # jieba分詞
wc.generate_from_text(jieba_text) # 生成詞雲圖
wc.to_file(v_outfile) # 保存圖片文件
print('詞雲文件保存成功:{}'.format(v_outfile))
except Exception as e:
print('make_wordcloud except: {}'.format(str(e)))
得到的詞雲圖,如下:

和原始圖片對比:

3.5 情感分析結論
- 打標結果中,積極和中性評價占約74%,遠遠大於消極評價!
- top10關鍵詞統計結果中,”哈哈哈”、”啊啊啊”、”王心凌”、”甜心”、”可愛”等好評詞彙佔據多數!
- 詞雲圖中,”好甜”、”愛”、”甜”、”青春”等好評詞看上去更大(詞頻高)!
綜上所述,經分析”王心凌”相關彈幕,得出結論:
眾多網友對王心凌的評價都很高,畢竟誰能不愛甜妹呢,”甜心教主”的名號真不是蓋的!
四、同步演示視頻
演示代碼執行過程:
//www.zhihu.com/zvideo/1516442497433235456
by 馬哥python說