圖文詳解MapReduce工作機制
job提交階段
1、準備好待處理文本。
2、客戶端submit()前,獲取待處理數據的信息,然後根據參數配置,形成一個任務分配的規劃。
3、客戶端向Yarn請求創建MrAppMaster並提交切片等相關信息:job.split、wc.jar、job.xml。Yarn調用ResourceManager來創建MrAppMaster,而MrAppMaster則會根據切片的個數來創建MapTask。
其中切片規劃: InputFormat(默認為TextInputFormat)通過getSplits 方法對輸入目錄中的文件進行邏輯切片,並序列化成job.split文件。默認情況下,HDFS上的一個block對應一個InputSplit,一個InputSplit對應開啟一個MapTask。
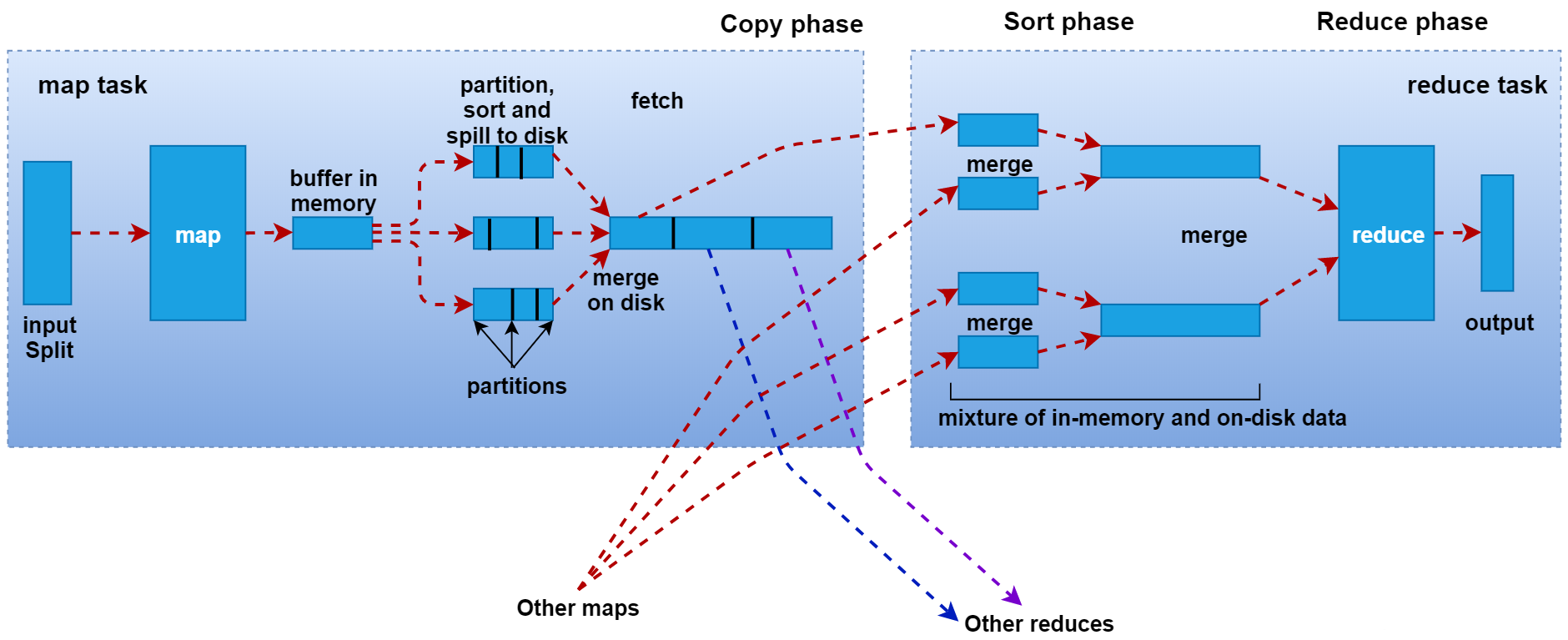
MapTask階段
1、Read階段:由RecordReader對象(默認是LineRecordReader)進行讀取,以換行符 (\n) 作為分隔符,每讀取一行數據,就返回一對<Key,Value>供Mapper使用。Key表示該行的起始位元組偏移量,Reduce表示這一行的內容。
2、Map階段: 將解析出的<Key,Value>交給用戶重寫的map()函數處理,每一行數據會調用一次map()函數。
3、Collect階段:map()函數中將數據處理完成後,一般會調用OutputCollector.collect()輸出結果。在該函數內部,它會將生成的key/value進行分區處理(調用Partitioner,默認為HashPartitioner),並寫入一個環形內存緩衝區中。
4、Spill階段(溢寫):當環形緩衝區的數據達到溢寫比例時(80%),會將數據溢寫到本地磁盤上,生成一個臨時文件。溢寫之前,還會對數據進行排序,必要時進行合併、壓縮操作。
5、Merge階段:當Mapper輸出全部文件後,產生多個臨時文件。MapTask將所有臨時文件以分區為單位,進行歸併排序,最終得到一個大文件,等待Reduce端的拉取。
ReduceTask階段
1、Copy階段:每個ReduceTask從各個MapTask上拉取對應分區的數據。拉取數據後先存儲到內存中,內存不夠時,再刷寫到磁盤。
2、Merge階段:在遠程拷貝數據的同時,ReduceTask啟動了兩個後台線程對內存和磁盤上的文件進行合併,以防止內存使用過多或磁盤上文件過多。
3、Sort階段:用戶編寫的reduce()函數的輸入數據是按Key進行聚集的一組數據。為了將相同Key的數據聚在一起,Hadoop採用了基於排序的策略。由於各個MapTask已經對自己的處理結果進行了分區內局部排序,因此,ReduceTask只需對所有數據進行一次歸併排序即可。
4、Reduce階段:相同Key的一組鍵值對調用一次Reduce方法,進行聚合處理。之後通過context.write,默認以TextOutputFormat格式經RecordWriter寫入到HDFS文件中。
溢寫階段詳情
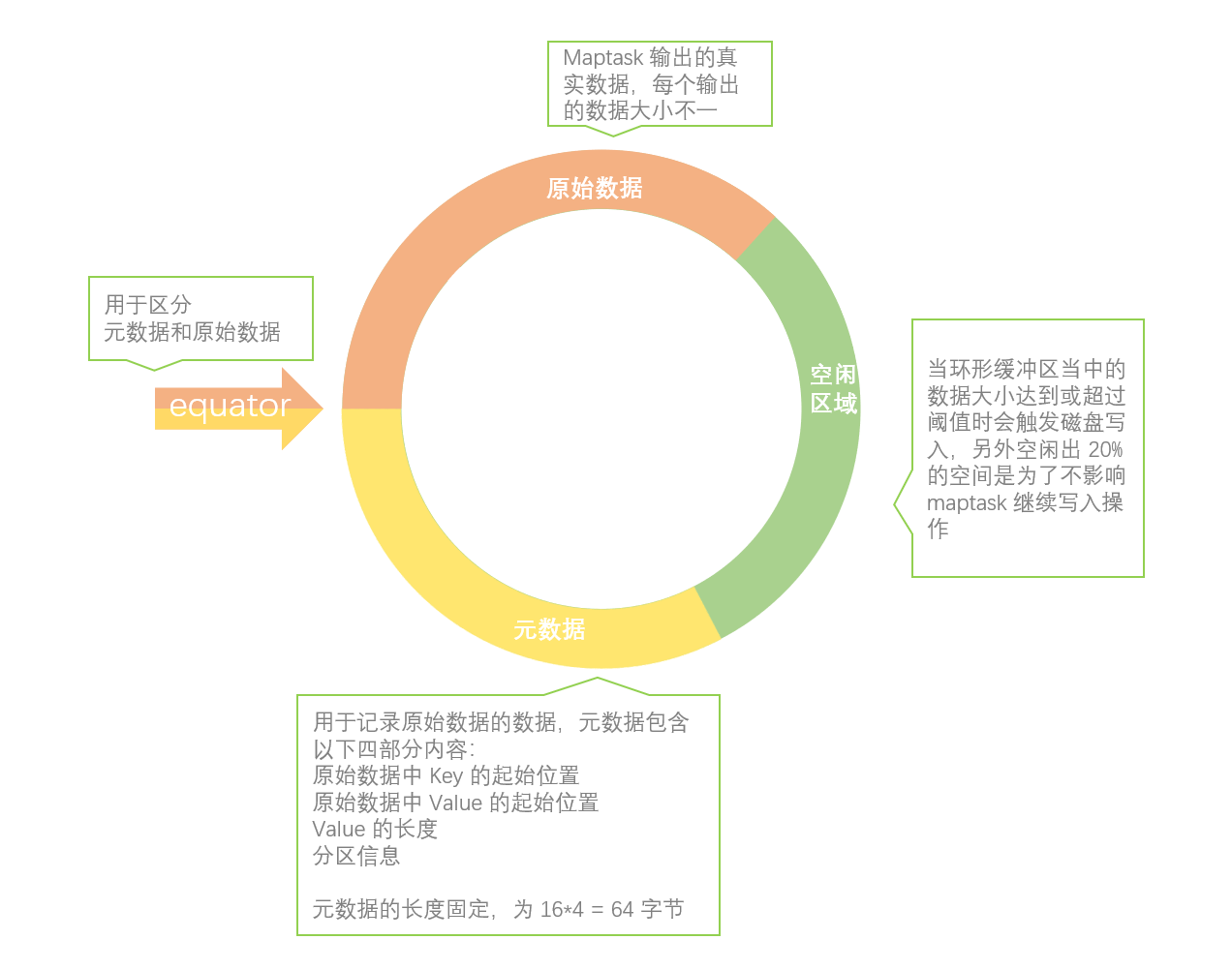
1、每個 MapTask都有一個環形內存緩衝區(默認大小為100M)用於批量收集Mapper結果,以減少磁盤IO的開銷。當緩衝區的數據達到溢寫比例時(默認為80%),溢寫線程啟動。此時MapTask仍繼續將結果寫入緩衝區,如果緩衝區被寫滿,MapTask就會阻塞直到溢出線程結束。如果數據量很小,達不到80M溢寫的話,就等所有文件都讀完後完成一次溢寫。
2、在溢寫之前,會採取快速排序算法對緩衝區內的數據按照Key進行字典順序排序:先把數據劃分到相應的分區(Partition),然後按照key進行排序。經過排序後,相同分區的數據聚集在一起,同一分區內的數據按照key有序。
3、如果設置了Combiner 函數,則在排序後,溢寫前對每個分區中的數據進行局部聚合操作,以減輕 Shuffle 過程中網絡傳輸壓力。
4、開始溢寫:按照分區編號由小到大依次將每個分區中的數據寫入任務工作目錄下的臨時文件output/spillN.out(N表示當前溢寫次數)中。每次內存緩衝區達到溢出閾值,就會新建一個溢出文件(spill file),當Mapper輸出全部文件時,會產生多個溢寫文件,最終會被合併成一個已分區且已排序的輸出文件。


