斯坦福NLP課程 | 第15講 – NLP文本生成任務

- 作者:韓信子@ShowMeAI,路遙@ShowMeAI,奇異果@ShowMeAI
- 教程地址://www.showmeai.tech/tutorials/36
- 本文地址://www.showmeai.tech/article-detail/252
- 聲明:版權所有,轉載請聯繫平台與作者並註明出處
- 收藏ShowMeAI查看更多精彩內容

ShowMeAI為斯坦福CS224n《自然語言處理與深度學習(Natural Language Processing with Deep Learning)》課程的全部課件,做了中文翻譯和注釋,並製作成了GIF動圖!視頻和課件等資料的獲取方式見文末。
引言

概要

- Recap what we already know about NLG / NLG要點回顧
- More on decoding algorithms / 解碼算法
- NLG tasks and neural approaches to them / NLG任務及其神經網絡解法
- NLG evaluation: a tricky situation / NLG評估:一個棘手的情況
- Concluding thoughts on NLG research, current trends, and the future / NLG研究的一些想法,目前的趨勢,未來的可能方向
1.語言模型與解碼算法知識回顧

1.1 自然語言生成(NLG)

- 自然語言生成指的是我們生成 (即寫入) 新文本的任何任務
- NLG 包括以下內容:
- 機器翻譯
- 摘要
- 對話 (閑聊和基於任務)
- 創意寫作:講故事,詩歌創作
- 自由形式問答 (即生成答案,從文本或知識庫中提取)
- 圖像字幕
1.2 要點回顧

(語言模型相關內容也可以參考ShowMeAI對吳恩達老師課程的總結文章深度學習教程 | 序列模型與RNN網絡)
- 語言建模是給定之前的單詞,預測下一個單詞的任務:
\[P\left(y_{t} \mid y_{1}, \ldots, y_{t-1}\right)
\]
\]
- 一個產生這一概率分佈的系統叫做語言模型 (LM)
- 如果系統使用 RNN,則被稱為 RNN-LM

- 條件語言建模是給定之前的單詞以及一些其他 (限定條件) 輸入 \(x\),預測下一個單詞的任務:
\[P\left(y_{t} \mid y_{1}, \dots, y_{t-1}, x\right)
\]
\]
- 條件語言建模任務的例子:
- 機器翻譯 x = source sentence, y = target sentence
- 摘要 x = input text, y = summarized text
- 對話 x = dialogue history, y = next utterance
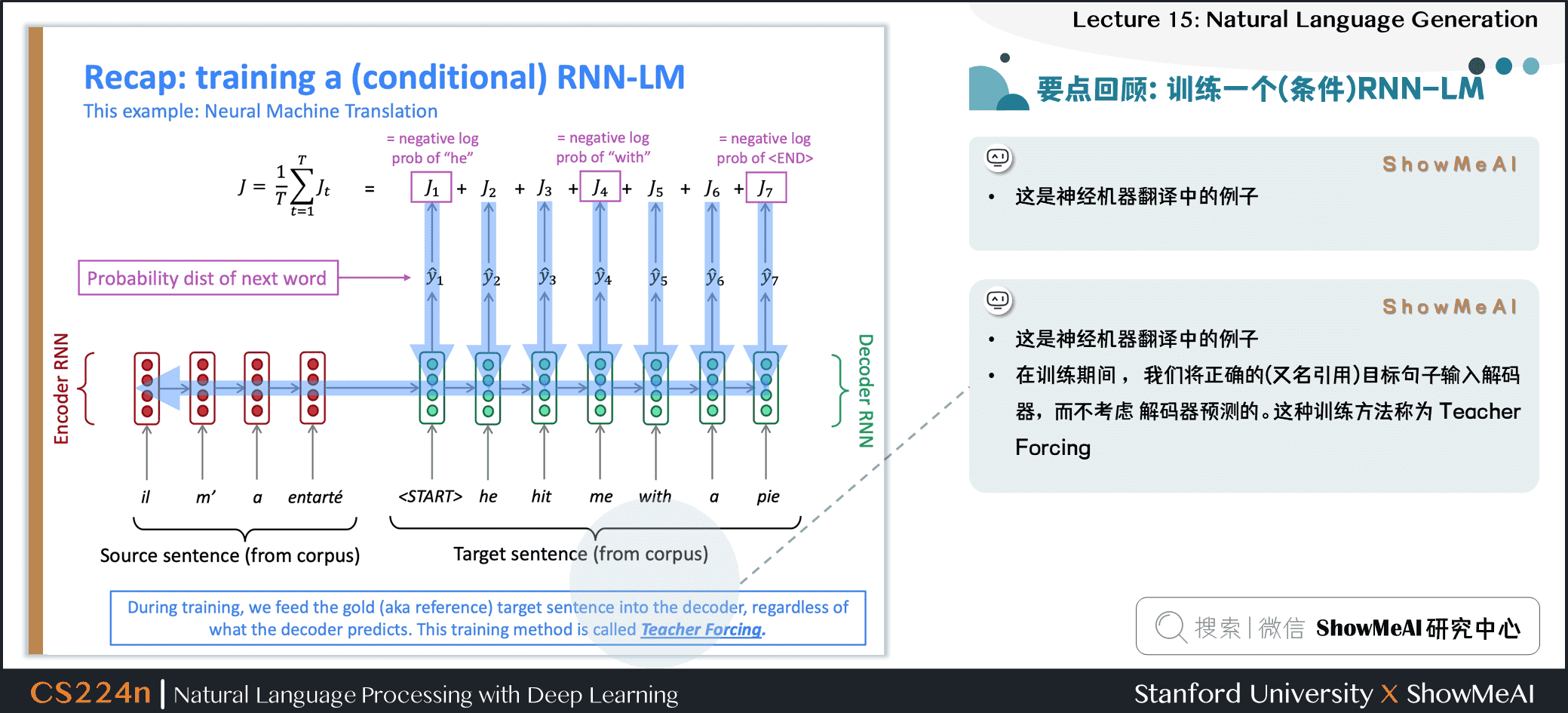
訓練一個(條件)RNN語言模型
- 這是神經機器翻譯中的例子
- 在訓練期間,我們將正確的 (又名引用) 目標句子輸入解碼器,而不考慮解碼器預測的。這種訓練方法稱為 Teacher Forcing

解碼算法
- 問題:訓練條件語言模型後,如何使用它生成文本?
- 答案:解碼算法是一種算法,用於從語言模型生成文本
- 我們了解了兩種解碼算法
- 貪婪解碼
- 集束搜索
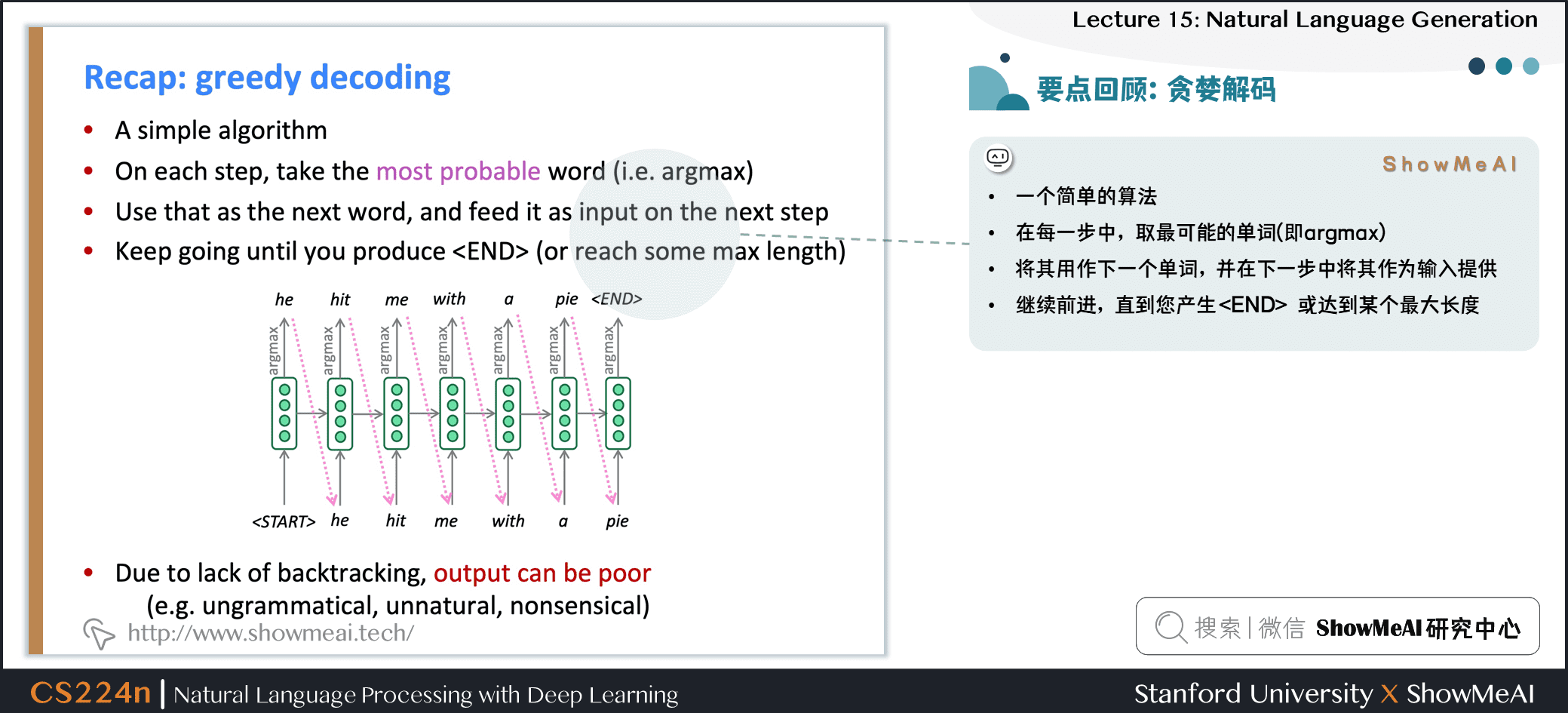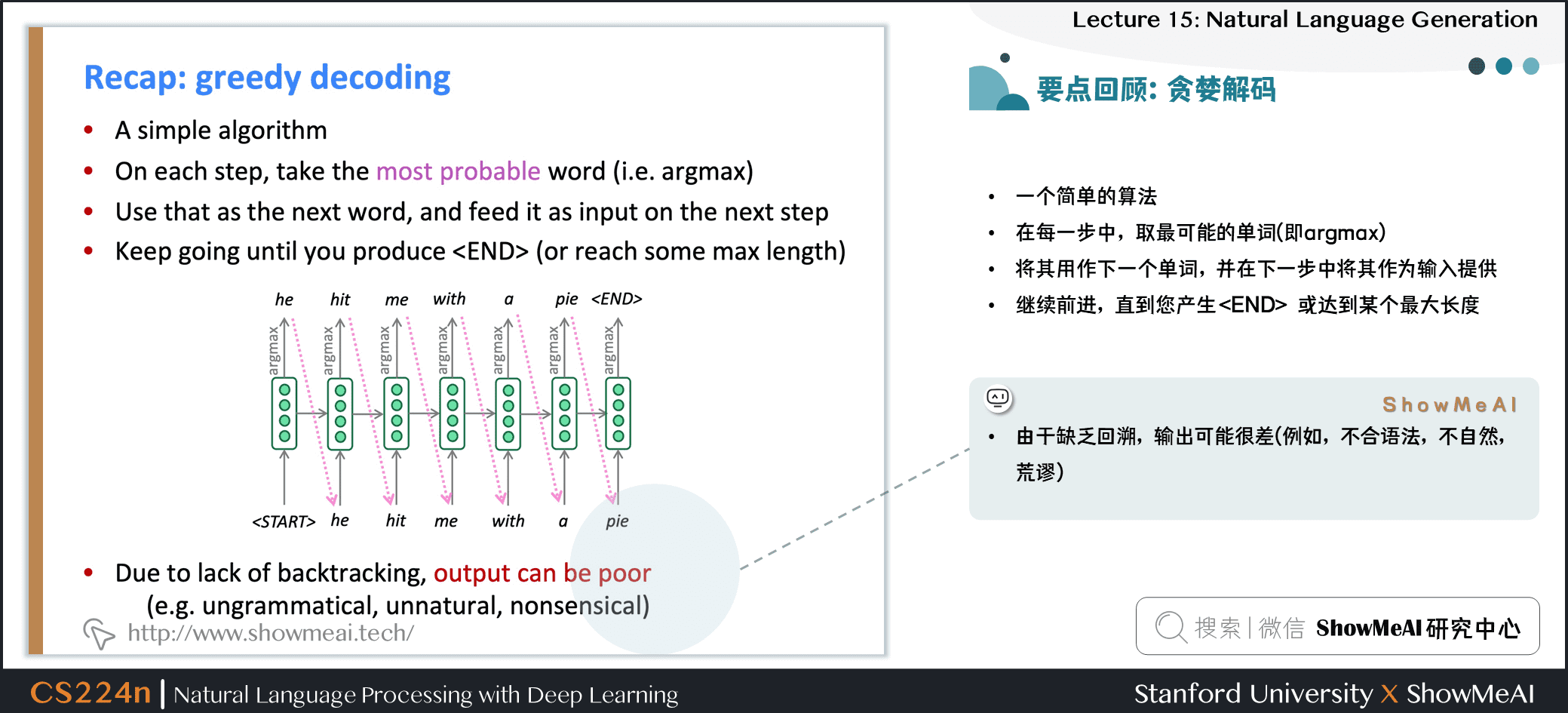
貪婪解碼
- 一個簡單的算法
- 在每一步中,取最可能的單詞 (即 argmax)
- 將其用作下一個單詞,並在下一步中將其作為輸入提供
- 繼續前進,直到產生 \(<\text{END}>\) 或達到某個最大長度
- 由於缺乏回溯,輸出可能很差 (例如,不合語法,不自然,荒謬)
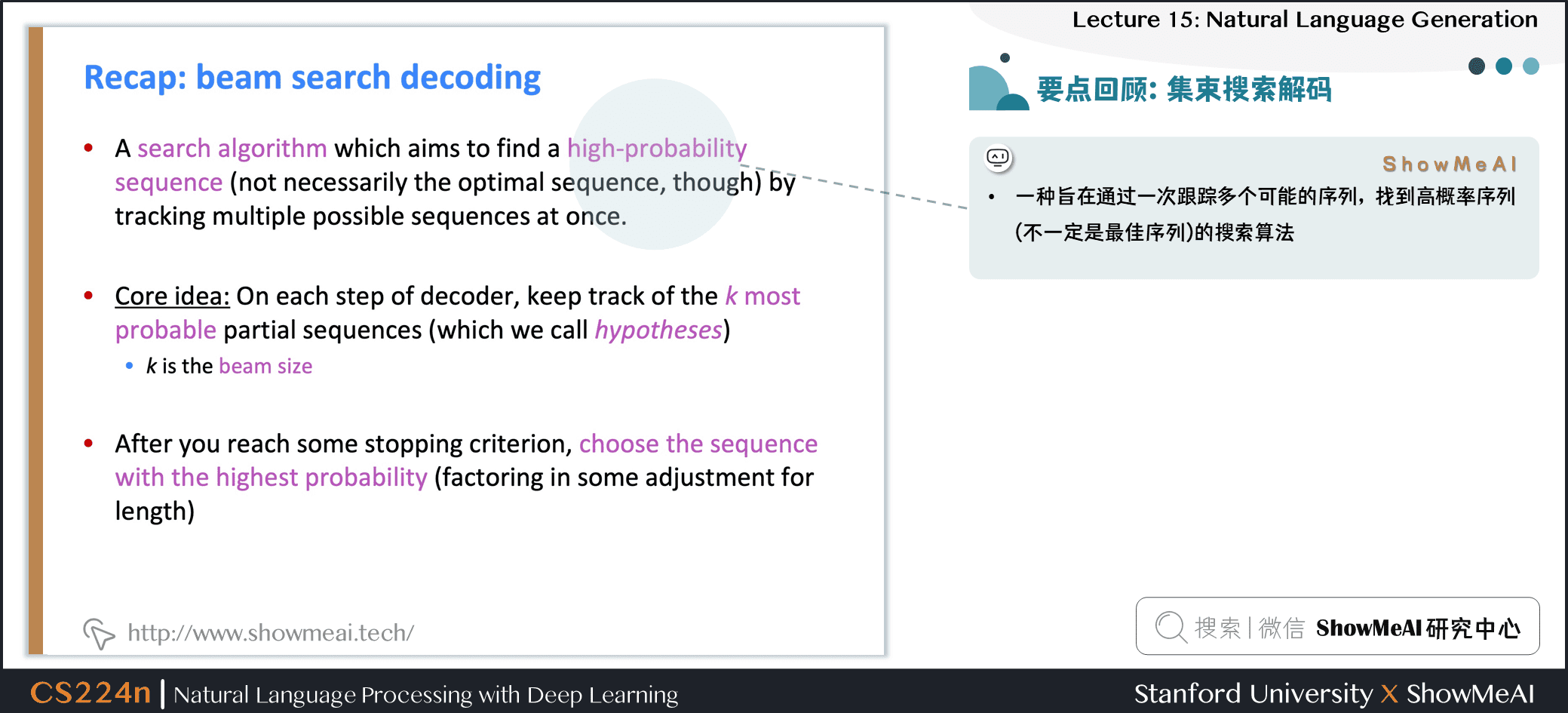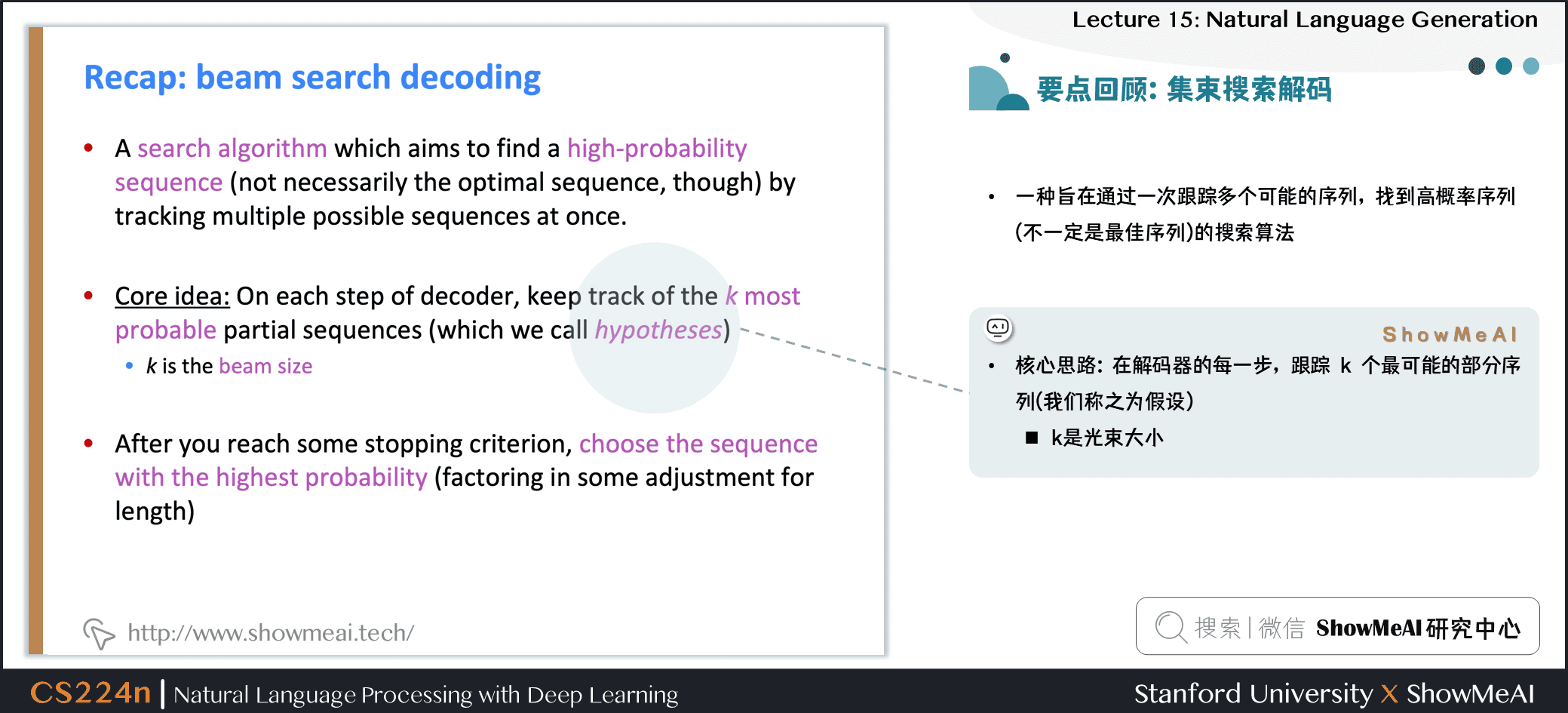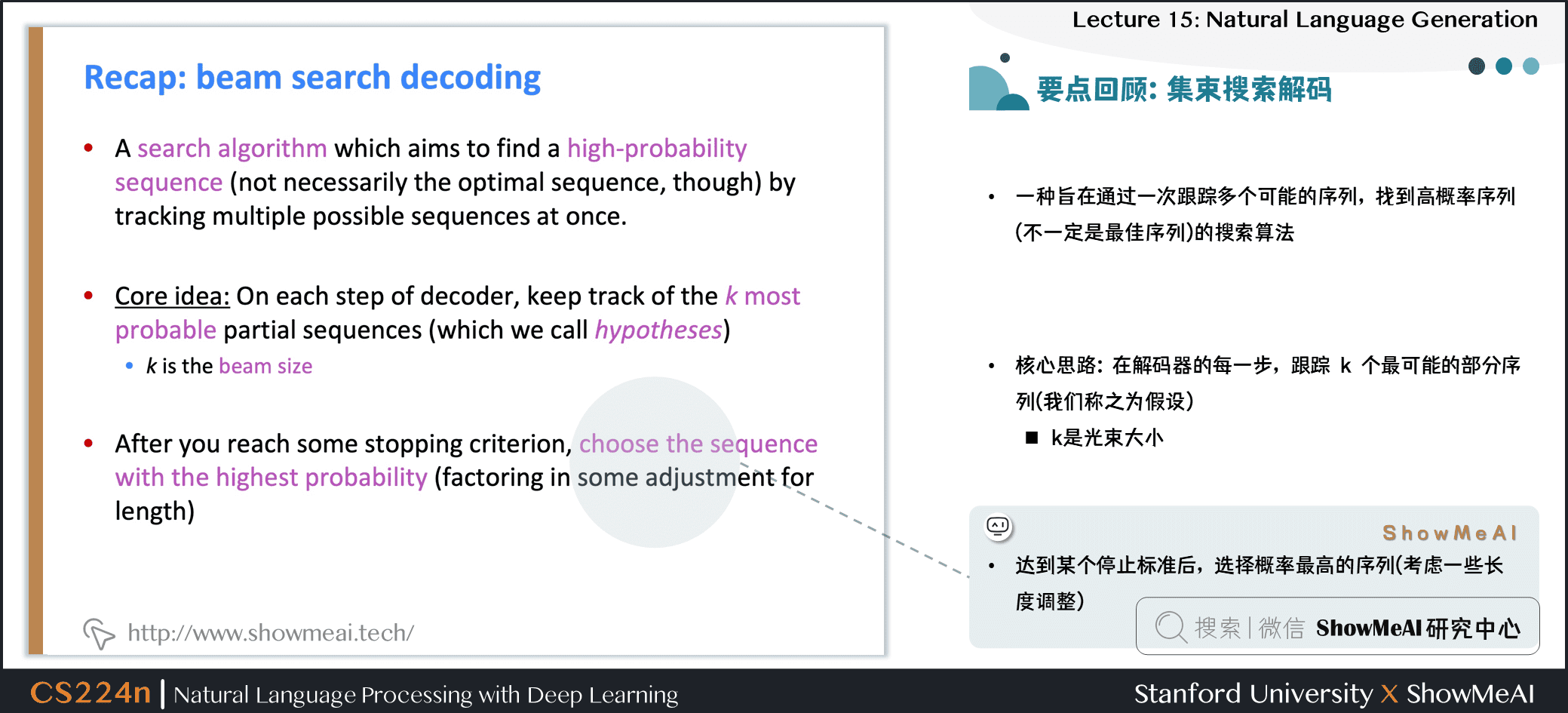
集束搜索解碼
- 一種旨在通過一次跟蹤多個可能的序列,找到高概率序列 (不一定是最佳序列) 的搜索算法
- 核心思路:在解碼器的每一步,跟蹤 \(k\) 個最可能的部分序列 (我們稱之為假設)
- \(k\) 是光束大小
- 達到某個停止標準後,選擇概率最高的序列 (考慮一些長度調整)
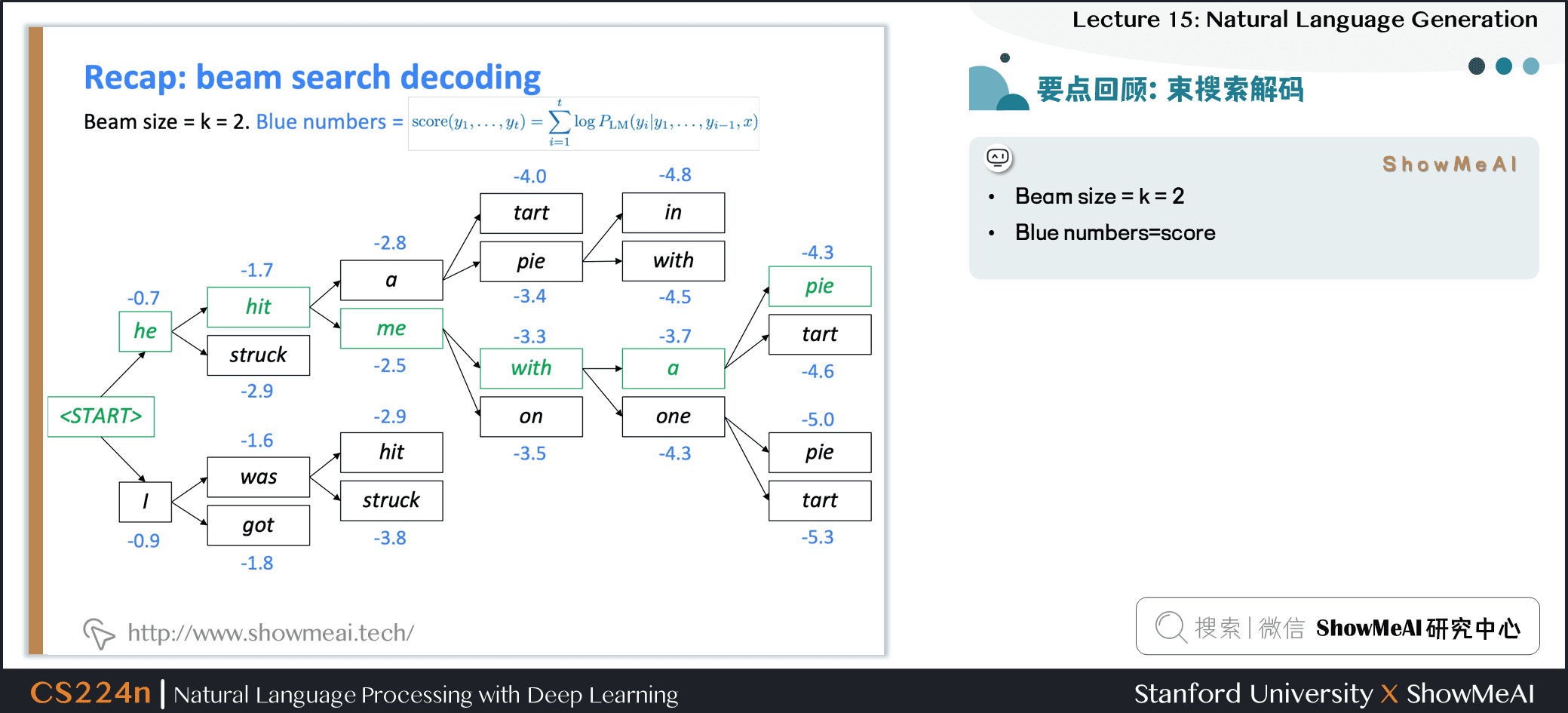
束搜索解碼
- Beam size = k = 2
- Blue numbers=score
1.3 旁白:《西部世界》使用的是集束搜索嗎?
1.4 改變beam size k有什麼影響?

- 小的 \(k\) 與貪心解碼有類似的問題 (\(k = 1\) 時就是貪心解碼)
- 不符合語法,不自然,荒謬,不正確
- 更大的 \(k\) 意味着考慮更多假設
- 增加 \(k\) 可以減少上述一些問題
- 更大的 \(k\) 在計算上更昂貴
- 但增加 \(k\) 可能會引入其他問題:
- 對於NMT,增加 \(k\) 太多會降低 BLEU 評分(Tu et al, Koehnet al),這主要是因為大 \(k\) 光束搜索產生太短的翻譯 (即使得分歸一化)
- 在閑聊話等開放式任務中,大的 \(k\) 會輸出非常通用的句子 (見下一張幻燈片)
1.5 光束大小對聊天對話的影響
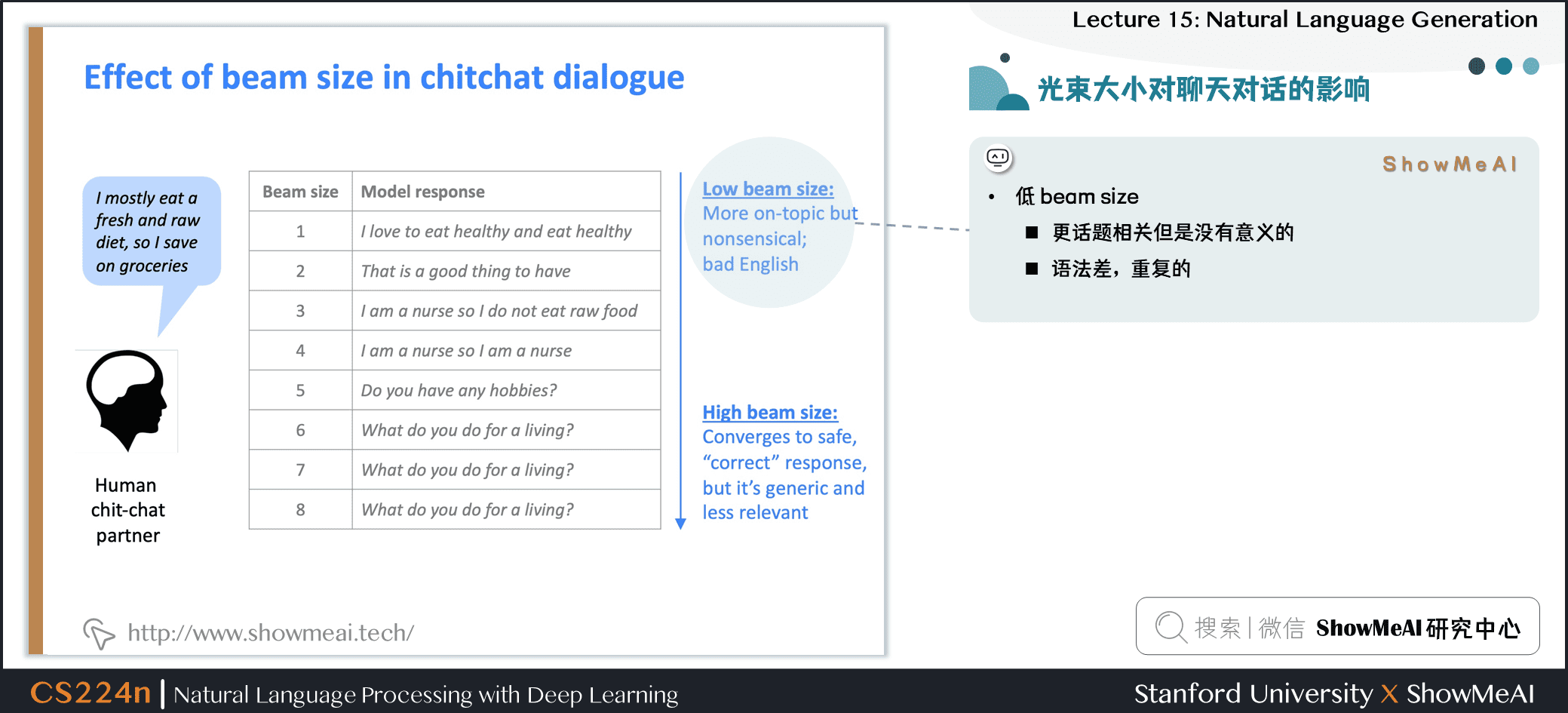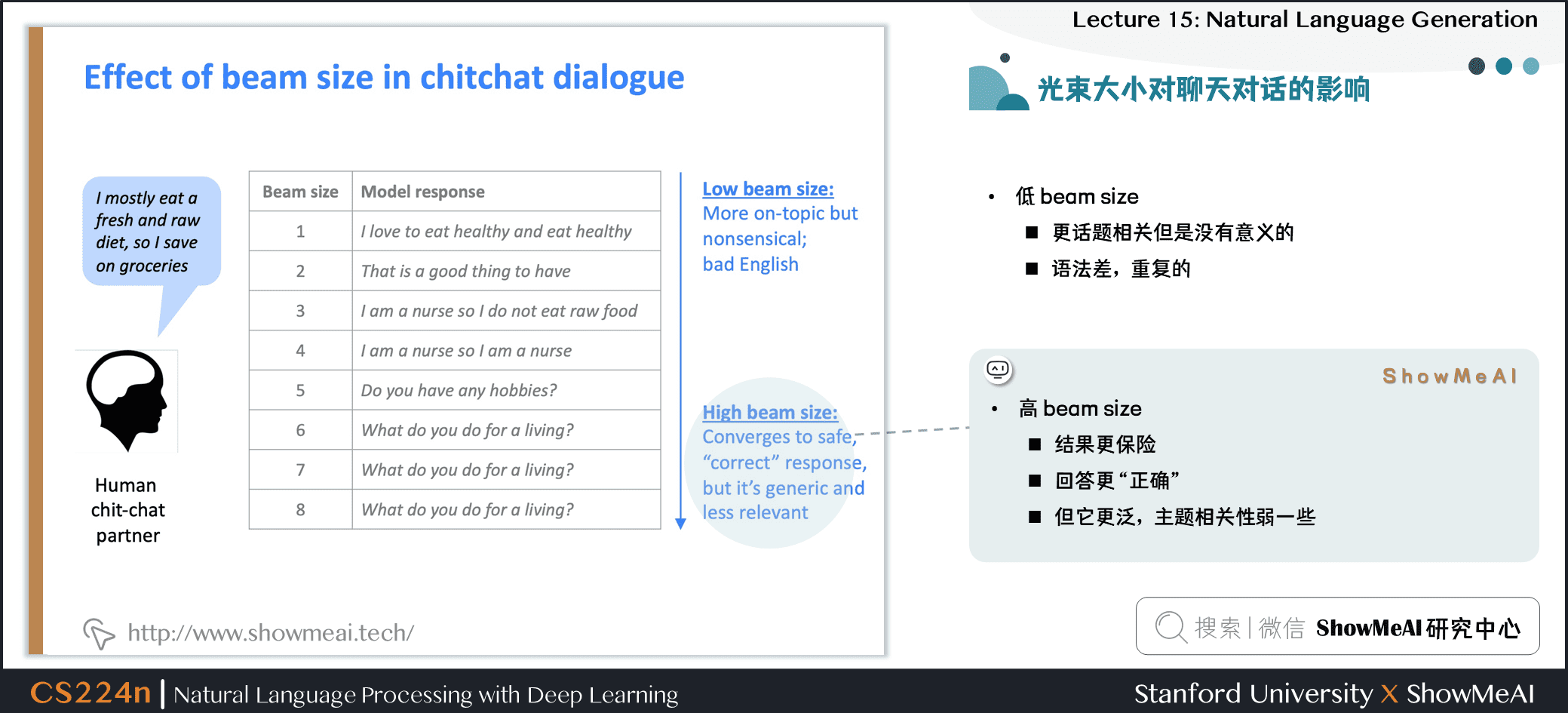
- 低 beam size
- 話題更相關但是沒有意義的
- 語法差,重複的
- 高 beam size
- 結果更保險
- 回答更
正確 - 但它更泛,主題相關性弱一些
1.6 基於採樣的解碼
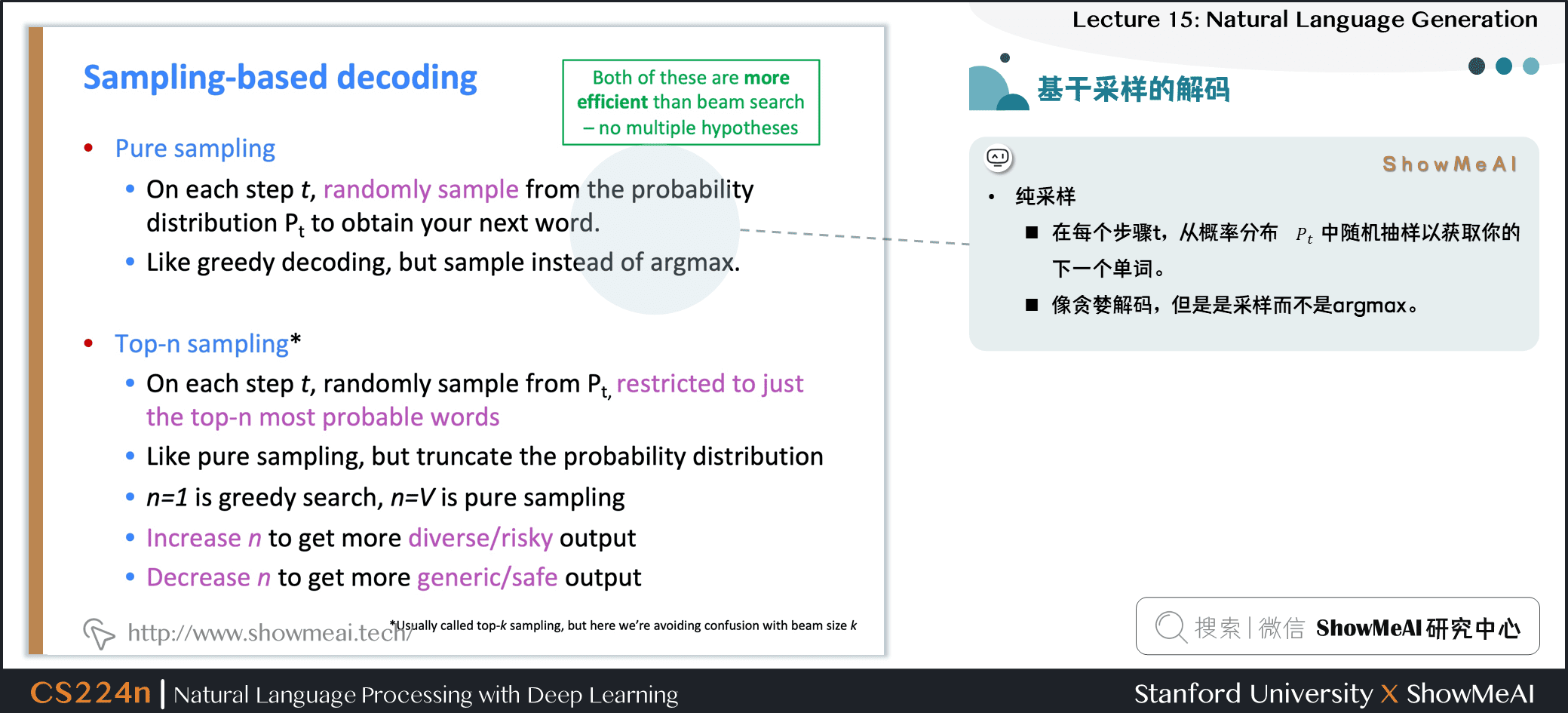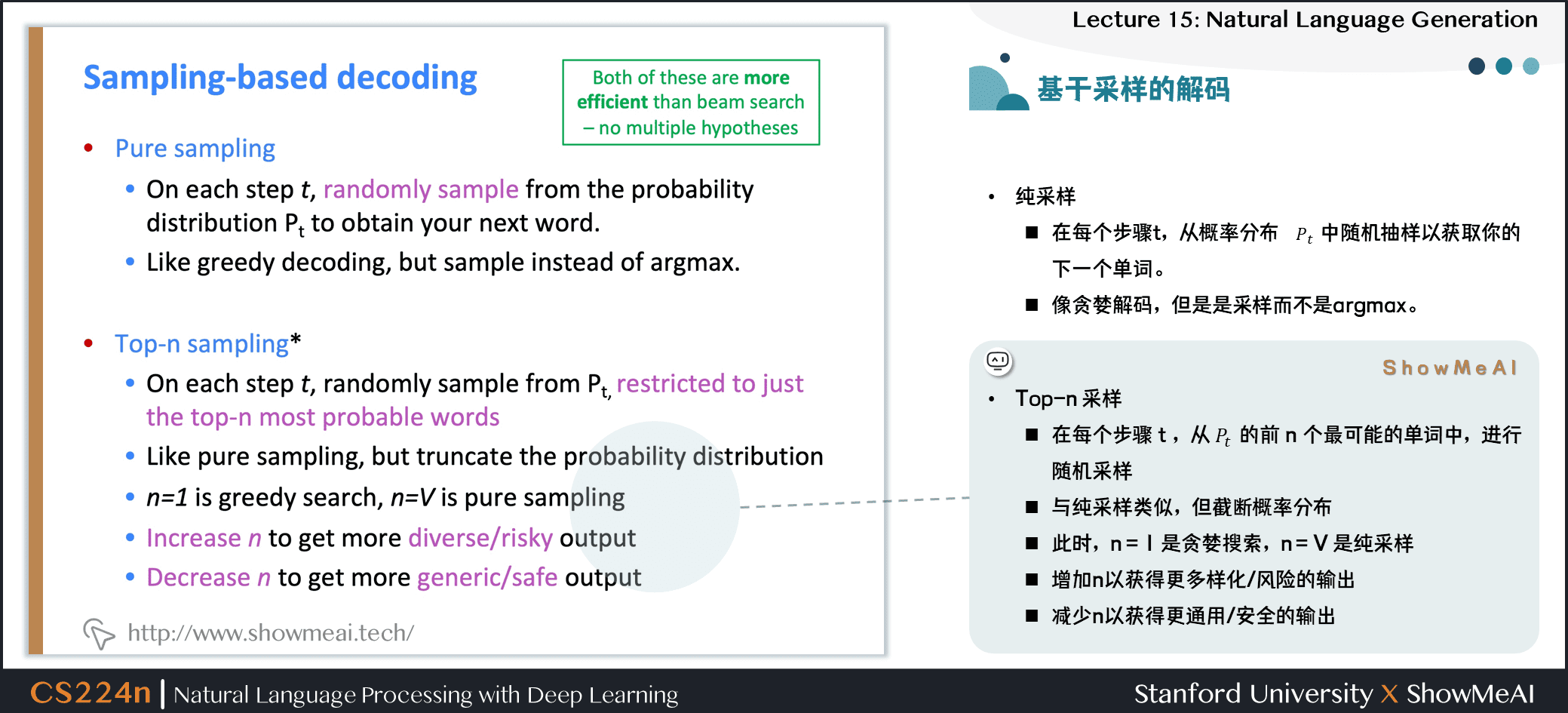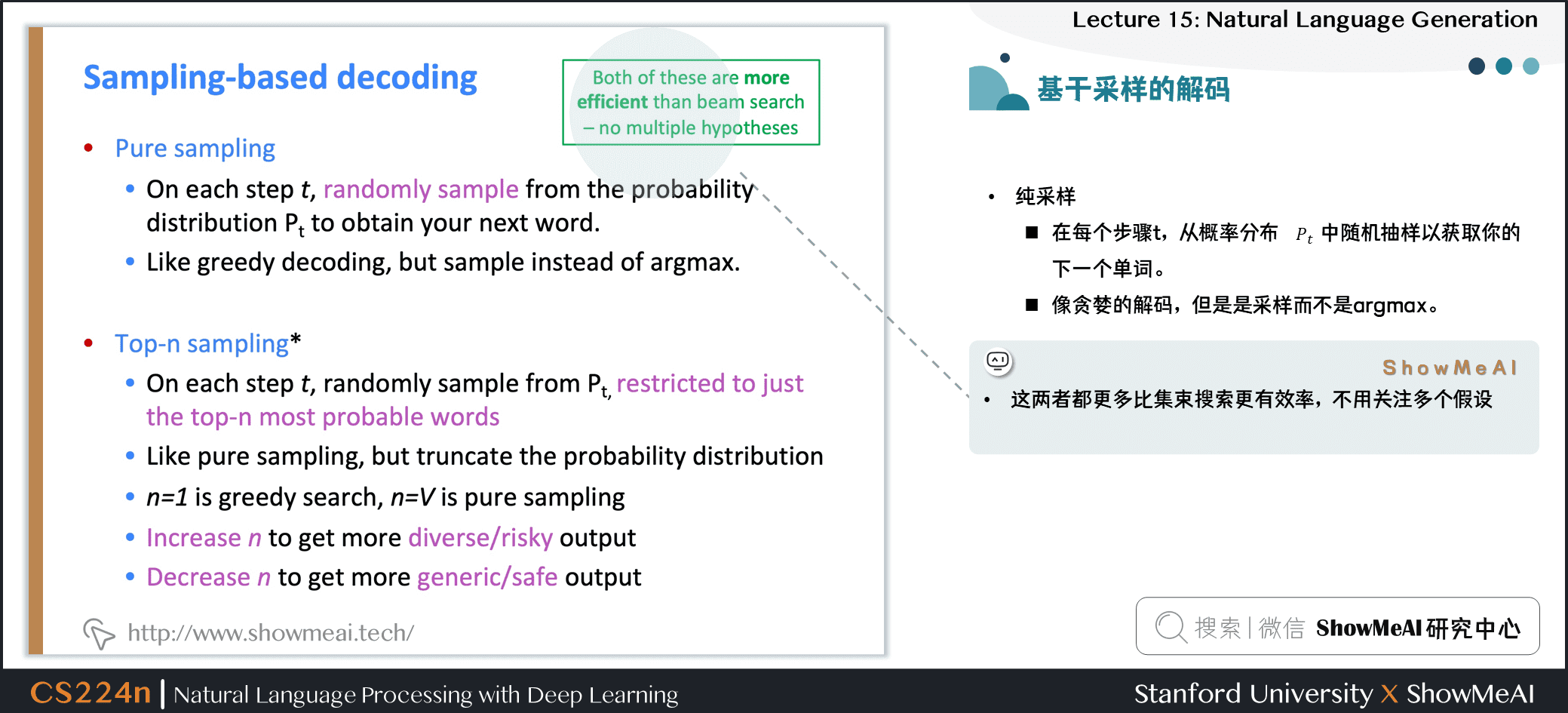
- 純採樣
- 在每個步驟 \(t\),從概率分佈 \(P_t\) 中隨機抽樣以獲取下一個單詞
- 像貪婪的解碼,但是,是採樣而不是 argmax
- Top-n 採樣
- 在每個步驟 \(t\),從 \(P_t\) 的前 \(n\) 個最可能的單詞中,進行隨機採樣
- 與純採樣類似,但截斷概率分佈
- 此時,\(n = 1\) 是貪婪搜索,\(n = V\) 是純採樣
- 增加 \(n\) 以獲得更多樣化 / 風險的輸出
- 減少 \(n\) 以獲得更通用 / 安全的輸出
- 這兩者都比光束搜索更有效率,不用關注多個假設
1.7 Softmax temperature

- 回顧:在時間步 \(t\),語言模型通過對分數向量 \(s \in \mathbb{R}^{|V|}\) 使用 softmax 函數計算出概率分佈 \(P_t\)
\[P_{t}(w)=\frac{\exp \left(s_{w}\right)}{\sum_{w^{\prime} \in V} \exp \left(s_{w^{\prime}}\right)}
\]
\]
- 可以對 softmax 函數時候用溫度超參數
\[P_{t}(w)=\frac{\exp \left(s_{w} / \tau\right)}{\sum_{w^{\prime} \in V} \exp \left(s_{w^{\prime}} / \tau\right)}
\]
\]
- 提高溫度 \(\tau\):\(P_t\) 變得更均勻
- 因此輸出更多樣化 (概率分佈在詞彙中)
- 降低溫度 \(\tau\):\(P_t\) 變得更尖銳
- 因此輸出的多樣性較少 (概率集中在頂層詞彙上)
1.8 解碼算法:總結

- 貪心解碼是一種簡單的譯碼方法;給低質量輸出
- Beam搜索(特別是高beam大小) 搜索高概率輸出
- 比貪婪提供更好的質量,但是如果 Beam 尺寸太大,可能會返回高概率但不合適的輸出(如通用的或是短的)
- 抽樣方法來獲得更多的多樣性和隨機性
- 適合開放式/創意代 (詩歌,故事)
- \(Top-n\) 個抽樣允許控制多樣性
- Softmax 溫度控制的另一種方式多樣性
- 它不是一個解碼算法!這種技術可以應用在任何解碼算法。
2.NLG任務和它們的神經網絡解法

2.1 摘要:任務定義

-
任務:給定輸入文本 \(x\),寫出更短的摘要 \(y\) 並包含 \(x\) 的主要信息
-
摘要可以是單文檔,也可以是多文檔
- 單文檔意味着我們寫一個文檔 \(x\) 的摘要 \(y\)
- 多文檔意味着我們寫一個多個文檔 \(x_{1}, \ldots, x_{n}\) 的摘要 \(y\)
- 通常 \(x_{1}, \ldots, x_{n}\) 有重疊的內容:如對同一事件的新聞文章

在單文檔摘要,數據集中的源文檔具有不同長度和風格
- Gigaword:新聞文章的前一兩句 → 標題 (即句子壓縮)
- LCSTS (中文微博):段落 → 句子摘要
- NYT, CNN / DailyMail:新聞文章 → (多個)句子摘要
- Wikihow (new!):完整的 how-to 文章 → 摘要句子
句子簡化是一個不同但相關的任務:將源文本改寫為更簡單 (有時是更短) 的版本
- Simple Wikipedia:標準維基百科句子 → 簡單版本
- Newsela:新聞文章 → 為兒童寫的版本
2.2 總結:兩大策略

-
抽取式摘要 Extractive summarization
- 選擇部分 (通常是句子) 的原始文本來形成摘要
- 更簡單
- 限定性的 (無需解釋)
- 選擇部分 (通常是句子) 的原始文本來形成摘要
-
生成式摘要 Abstractive summarization
- 使用自然語言生成技術生成新的文本
- 更困難
- 更多變 (更人性化)
- 使用自然語言生成技術生成新的文本
2.3 前神經網絡時代摘要抽取綜述
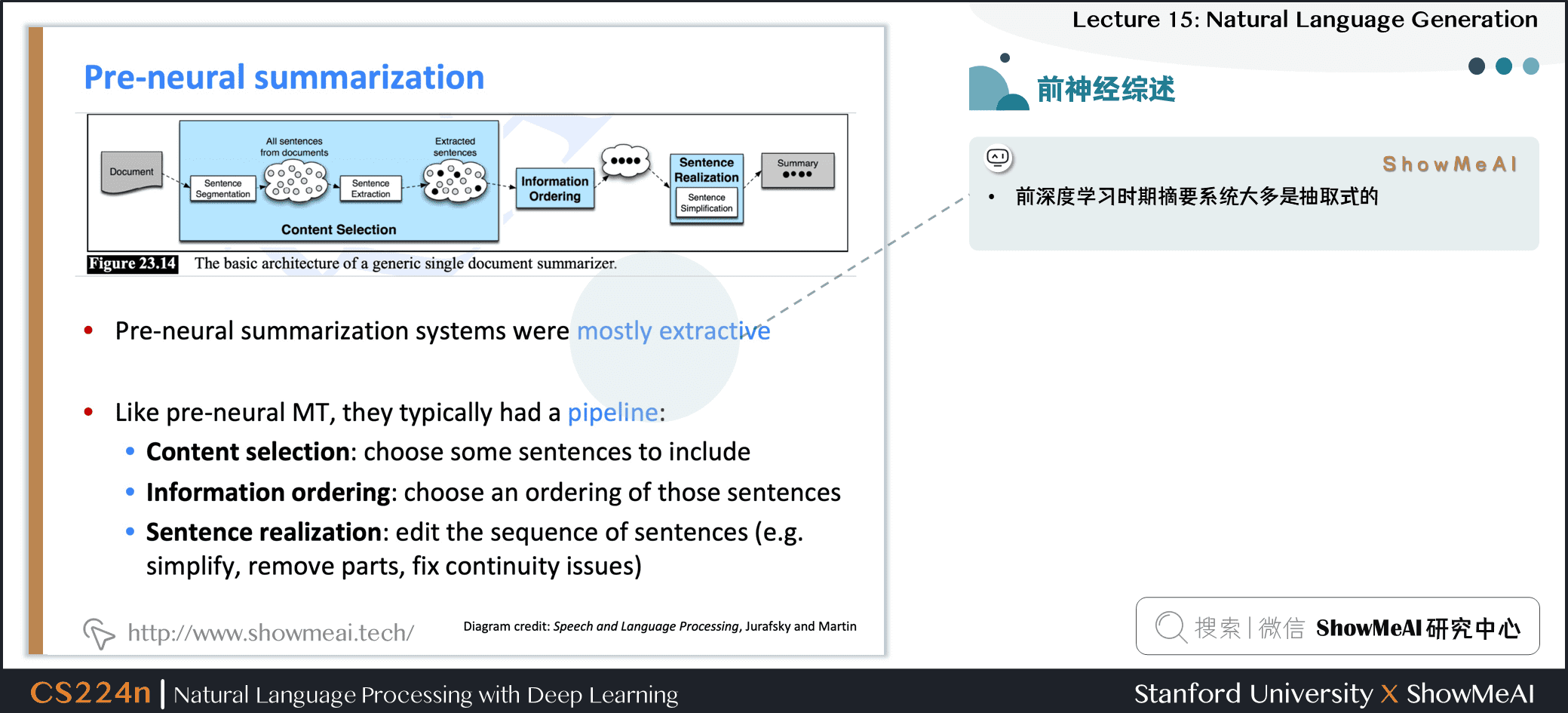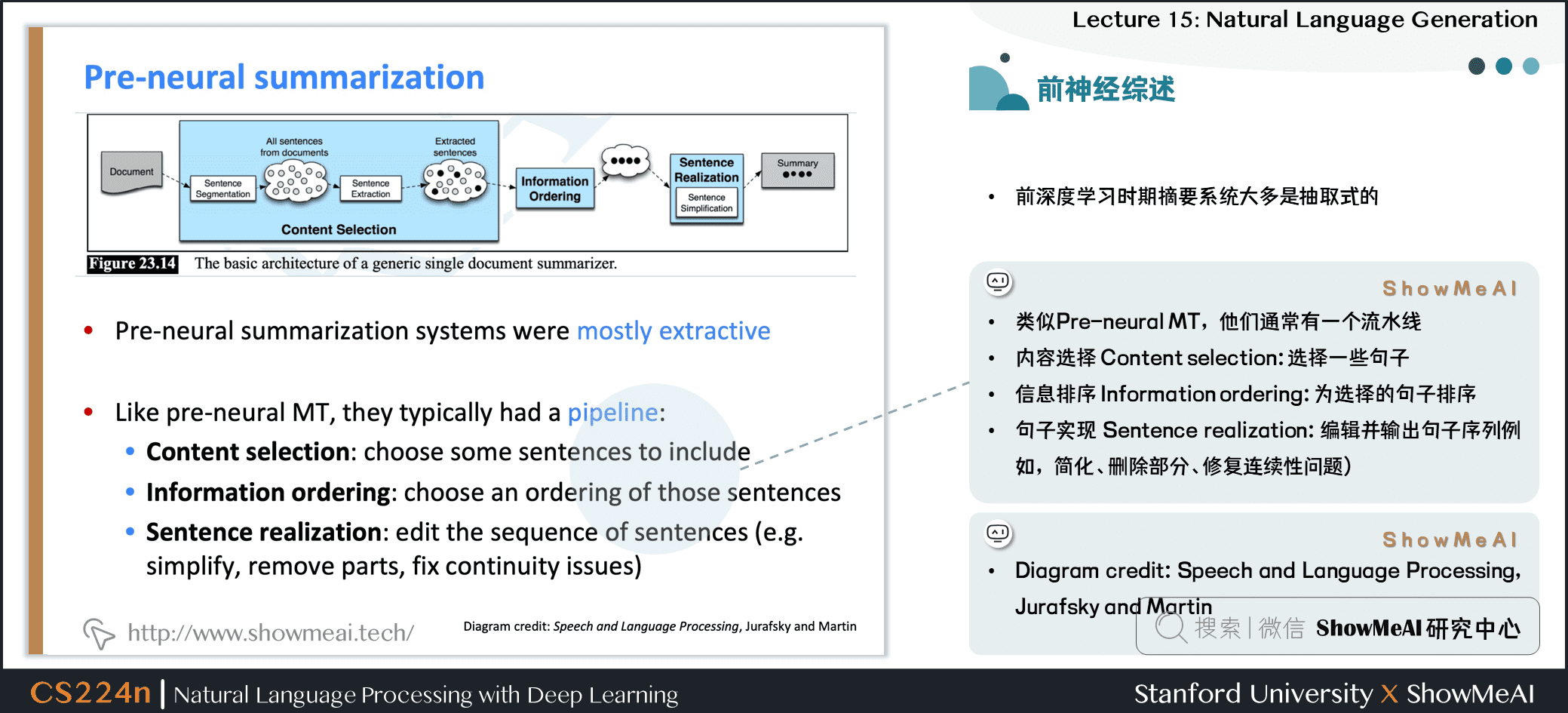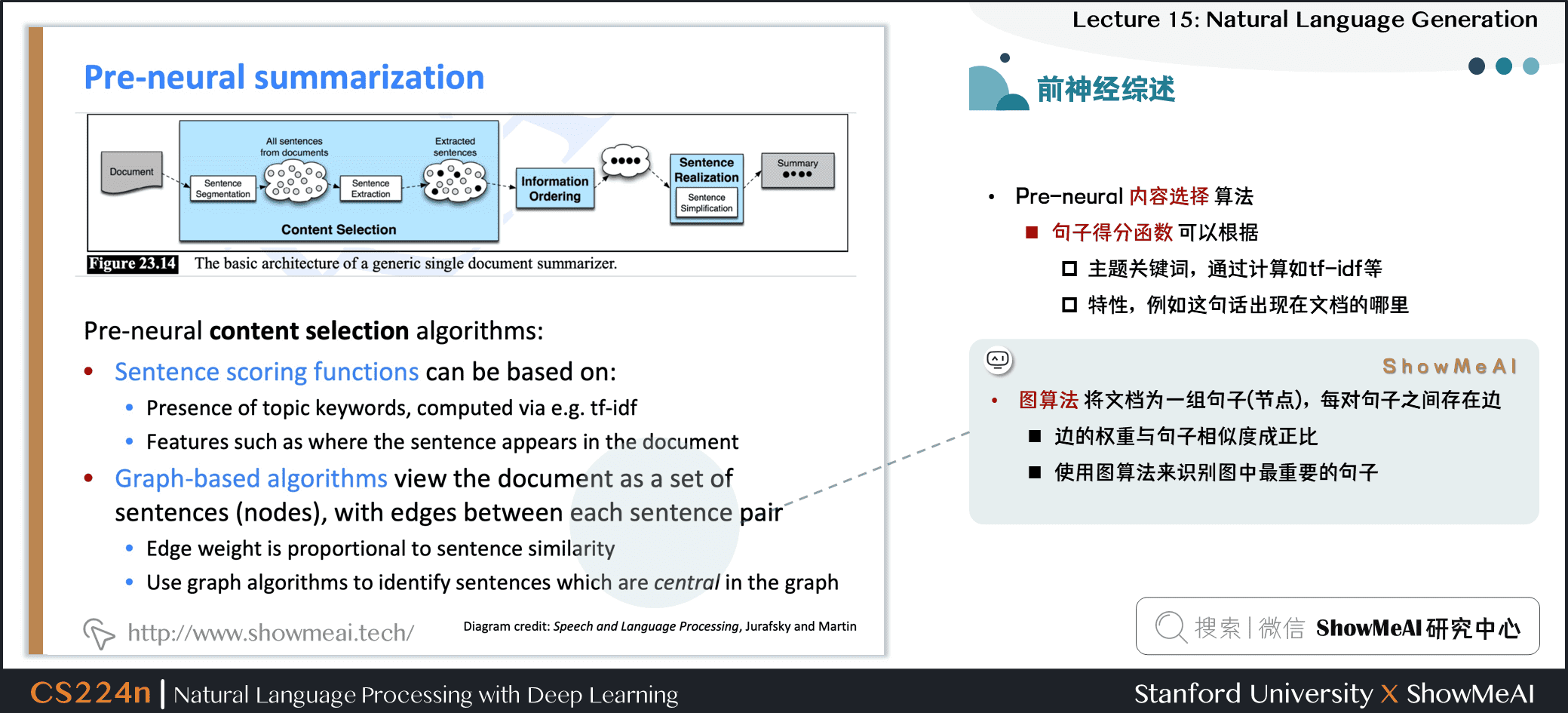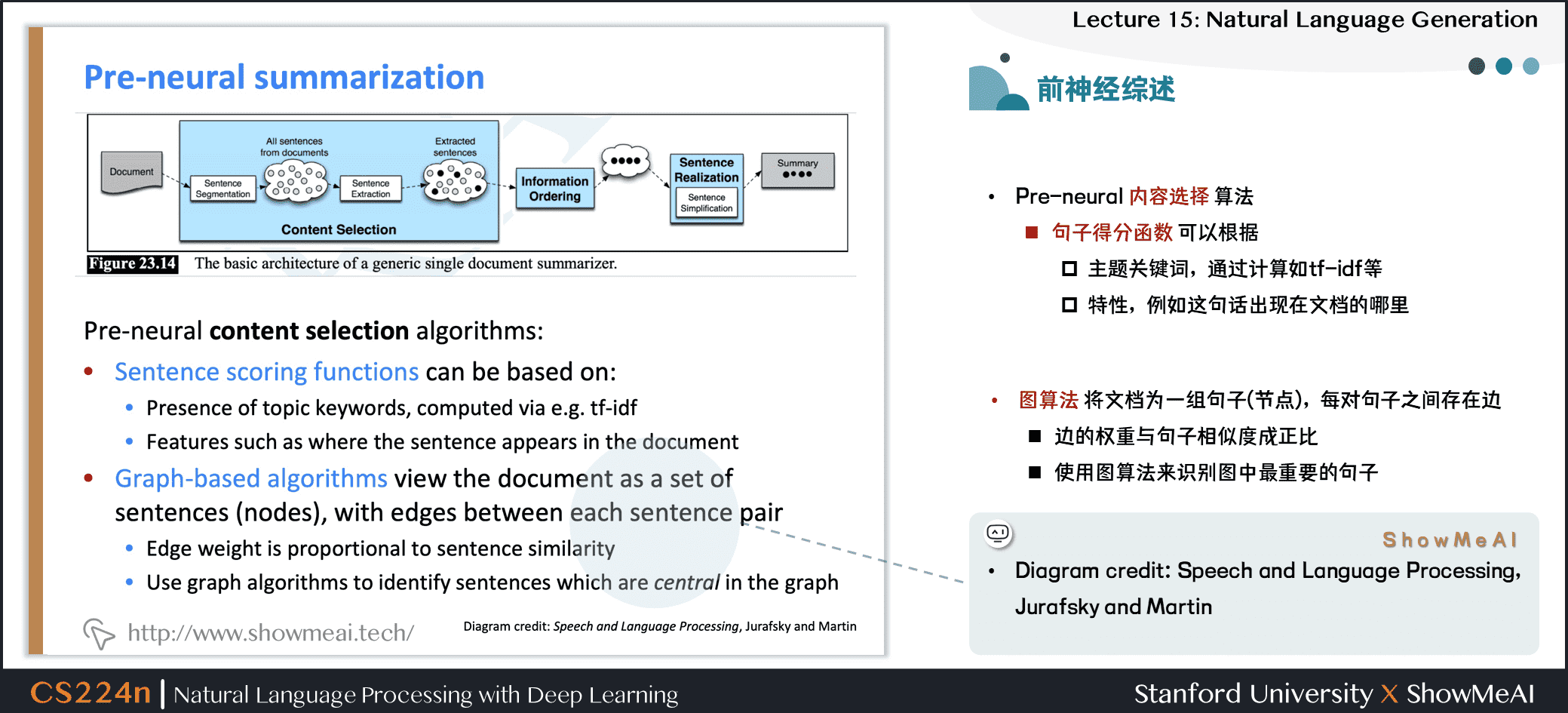
- 前深度學習時期摘要系統大多是抽取式的
- 類似統計機器翻譯系統,他們通常有一個流水線
- 內容選擇 Content selection:選擇一些句子
- 信息排序 Information ordering:為選擇的句子排序
- 句子實現 Sentence realization:編輯並輸出句子序列例如,簡化、刪除部分、修復連續性問題
- Diagram credit: Speech and Language Processing, Jurafsky and Martin
- 前神經網絡時代的內容選擇算法
- 句子得分函數可以根據
- 主題關鍵詞,通過計算如 tf-idf 等
- 特性,例如這句話出現在文檔的哪裡
- 句子得分函數可以根據
- 圖算法將文檔為一組句子(節點),每對句子之間存在邊
- 邊的權重與句子相似度成正比
- 使用圖算法來識別圖中最重要的句子
2.4 綜述生成評估:ROUGE
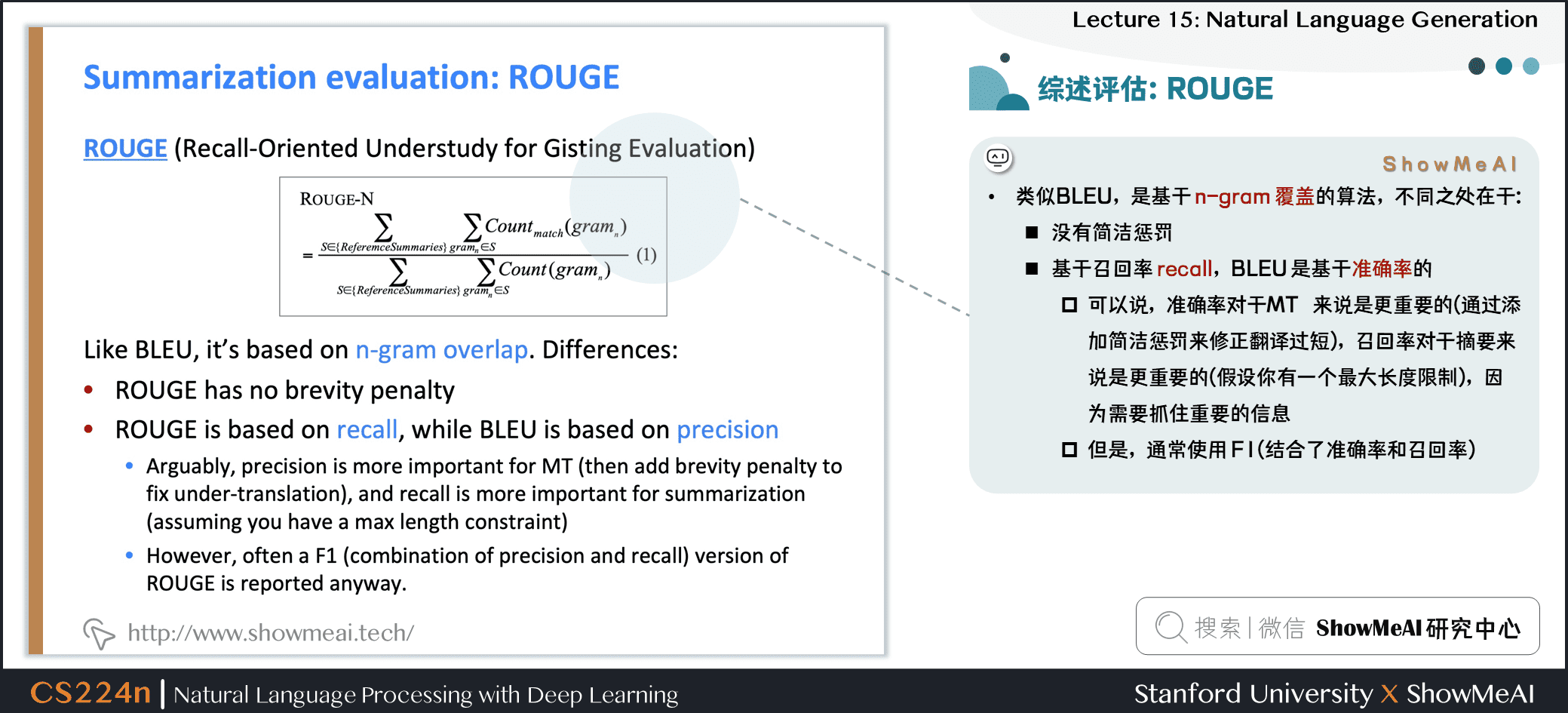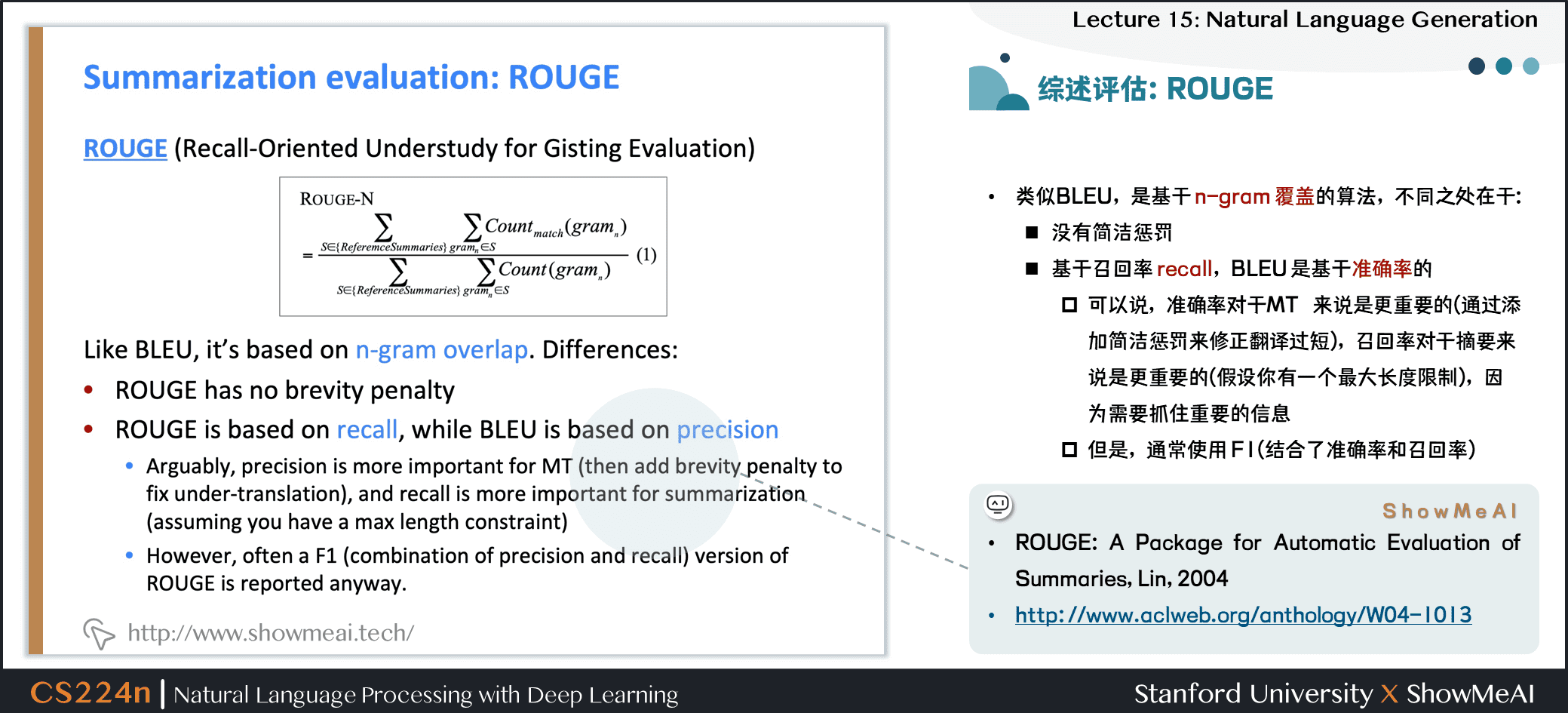
類似於 BLEU,是基於 n-gram 覆蓋的算法,不同之處在於:
- 沒有簡潔懲罰
- 基於召回率 recall,BLEU 是基於準確率的
- 可以說,準確率對於機器翻譯來說是更重要的 (通過添加簡潔懲罰來修正翻譯過短),召回率對於摘要來說是更重要的 (假設你有一個最大長度限制),因為需要抓住重要的信息
- 但是,通常使用 F1 (結合了準確率和召回率)
- ROUGE: A Package for Automatic Evaluation of Summaries, Lin, 2004
- //www.aclweb.org/anthology/W04-1013

- BLEU 是一個單一的數字,它是 \(n=1,2,3,4n-grams\) 的精度的組合
- 每 n-gram 的 ROUGE 得分分別報告
- 最常見的報告ROUGE得分是
- ROUGE-1:unigram單元匹配
- ROUGE紅-2:bigram二元分詞匹配
- ROUGE-L:最長公共子序列匹配
- 現在有了一個方便的 ROUGE 的 Python 實現
2.5 神經摘要生成 (2015年-至今)

- 2015:Rush et al. publish the first seq2seq summarization paper
- 單文檔摘要摘要是一項翻譯任務!
- 因此我們可以使用標準的 seq2seq + attention 神經機器翻譯方法
- A Neural Attention Model for Abstractive Sentence Summarization, Rush et al, 2015
- //arxiv.org/pdf/1509.00685.pdf

- 自2015年以來,有了更多的發展
- 使其更容易複製
- 也防止太多的複製
- 分層 / 多層次的注意力機制
- 更多的全局 / 高級的內容選擇
- 使用 RL 直接最大化 ROUGE 或者其他離散目標 (例如長度)
- 復興前深度學習時代的想法 (例如圖算法的內容選擇),把它們變成神經系統
- 使其更容易複製

- Seq2seq+attention systems 善於生成流暢的輸出,但是不擅長正確的複製細節 (如罕見字)
- 複製機制使用注意力機制,使seq2seq系統很容易從輸入複製單詞和短語到輸出
- 顯然這是非常有用的摘要
- 允許複製和創造給了一個混合了抽取 / 抽象式的方法

- 有幾篇論文提出了複製機制的變體:
- Language as a Latent Variable: Discrete Generative Models for Sentence Compression, Miao et al, 2016
- Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond, Nallapati et al, 2016
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu et al, 2016

- 在每一步上,計算生成下一個詞彙的概率 \(P_{gen}\),最後的分佈是生成 (詞彙表) 分佈和copying (注意力) 分佈的一個混合分佈
- Get To The Point: Summarization with Pointer-Generator Networks, See et al, 2017
- //arxiv.org/pdf/1704.04368.pdf

- 複製機制的大問題
- 他們複製太多!
- 主要是長短語,有時甚至整個句子
- 他們複製太多!
- 一個原本應該是抽象的摘要系統,會崩潰為一個主要是抽取的系統
- 另一個問題
- 他們不善於整體內容的選擇,特別是如果輸入文檔很長的情況下
- 沒有選擇內容的總體戰略

- 回憶:前深度學習時代摘要生成是不同階段的內容選擇和表面實現 (即文本生成)
- 標準 seq2seq + attention 的摘要系統,這兩個階段是混合在一起的
- 每一步的譯碼器(即表面實現),我們也能進行詞級別的內容選擇(注意力)
- 這是不好的:沒有全局內容選擇策略
- 一個解決辦法:自下而上的匯總
2.6 自下而上的摘要生成

- 內容選擇階段:使用一個神經序列標註模型來將單詞標註為
include/don』t-include - 自下而上的注意力階段:seq2seq + attention 系統不能處理
don』t-include的單詞 (使用 mask)
- 簡單但是非常有效!
- 更好的整體內容選擇策略
- 減少長序列的複製 (即更摘要的輸出)
- 因為長序列中包含了很多
don』t-include的單詞,所以模型必須學會跳過這些單詞並將那些include的單詞進行摘要與組合
- 因為長序列中包含了很多
2.7 基於強化學習的神經網絡摘要生成
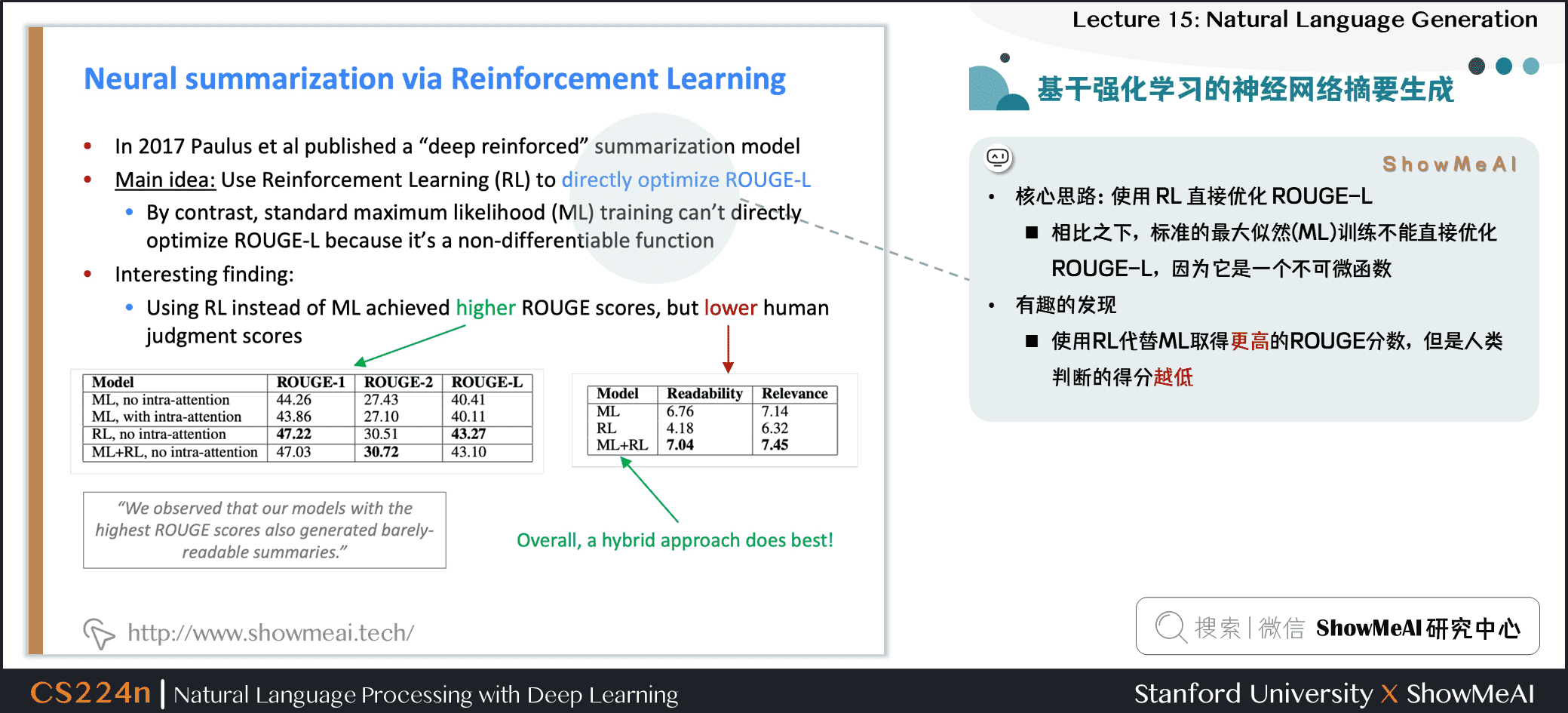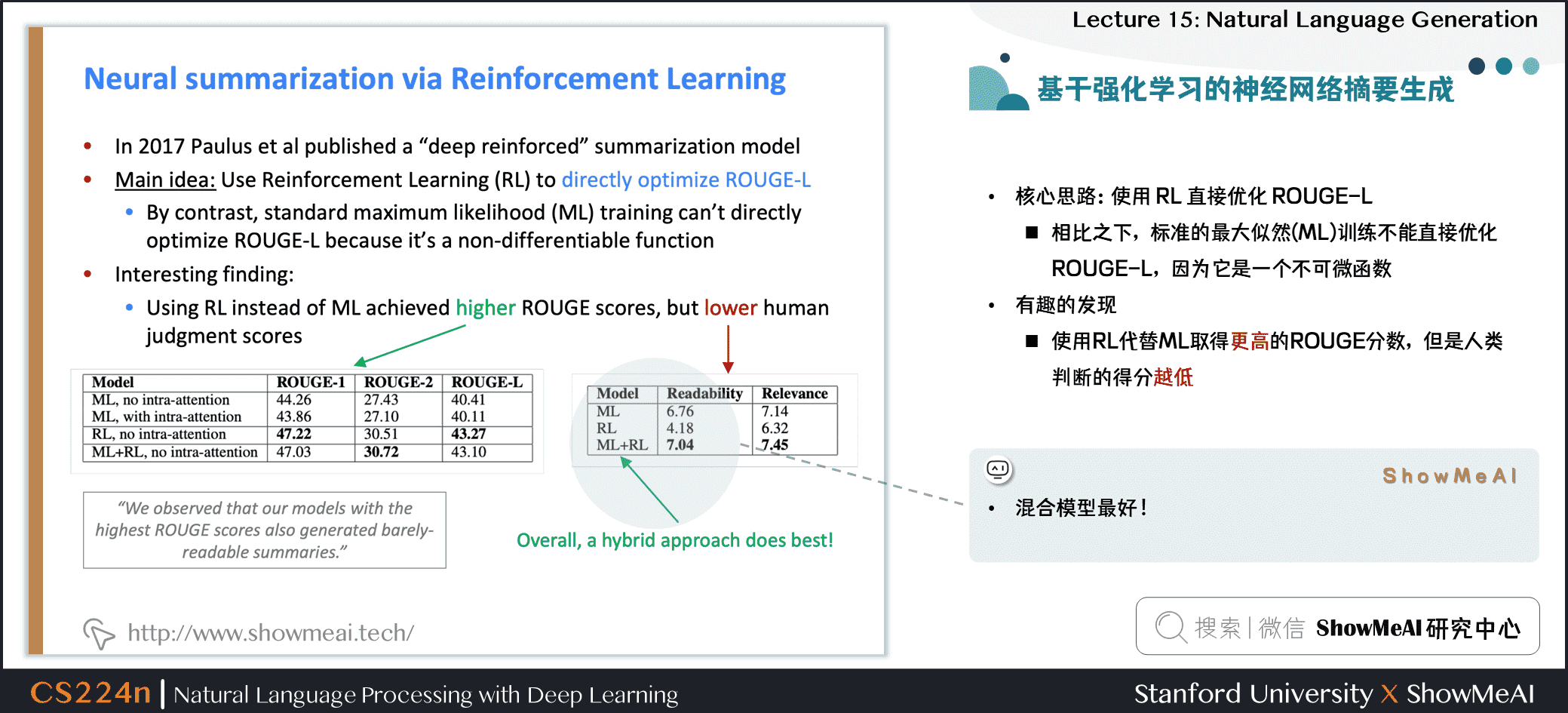
- 核心思路:使用 RL 直接優化 ROUGE-L
- 相比之下,標準的最大似然 (ML) 訓練不能直接優化 ROUGE-L,因為它是一個不可微函數
- 有趣的發現
- 使用RL代替ML取得更高的ROUGE分數,但是人類判斷的得分越低
- 混合模型最好!
2.8 對話系統

對話 包括各種各樣的設置
- 面向任務的對話
- 輔助 (如客戶服務、給予建議,回答問題,幫助用戶完成任務,如購買或預訂)
- 合作 (兩個代理通過對話在一起解決一個任務)
- 對抗 (兩個代理通過對話完成一個任務)
- 社會對話
- 閑聊 (為了好玩或公司)
- 治療 / 精神健康
2.9 前/後神經網絡時期對話系統

- 由於開放式自由 NLG 的難度,前深度學習時代的對話系統經常使用預定義的模板,或從語料庫中檢索一個適當的反應的反應
- 摘要過去的研究,自2015年以來有很多論文將seq2seq方法應用到對話,從而導致自由對話系統興趣重燃
- 一些早期 seq2seq 對話文章包括
- A Neural Conversational Model, Vinyals et al, 2015
- Neural Responding Machine for Short-Text Conversation, Shang et al, 2015
2.10 基於Seq2Seq的對話
(seq2seq相關內容也可以參考ShowMeAI的NLP教程NLP教程(6) – 神經機器翻譯、seq2seq與注意力機制,以及對吳恩達老師課程的總結文章深度學習教程 | Seq2Seq序列模型和注意力機制)
- 然而,很快就發現,標準 seq2seq +attention 的方法在對話 (閑聊) 任務中有嚴重的普遍缺陷
- 一般性/無聊的反應
- 無關的反應(與上下文不夠相關)
- 重複
- 缺乏上下文(不記得談話歷史)
- 缺乏一致的角色人格
2.11 無關回答問題

- 問題:seq2seq 經常產生與用戶無關的話語
- 要麼因為它是通用的 (例如
我不知道) - 或因為改變話題為無關的一些事情
- 要麼因為它是通用的 (例如
- 一個解決方案:不是去優化輸入 \(S\) 到回答 \(T\) 的映射來最大化給定 \(S\) 的 \(T\) 的條件概率,而是去優化輸入 \(S\) 和回復 \(T\) 之間的最大互信息Maximum Mutual Information (MMI),從而抑制模型去選擇那些本來就很大概率的通用句子
\[\log \frac{p(S, T)}{p(S) p(T)}
\]
\]
\[\hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\log p(T)\}
\]
\]
2.12 一般性/枯燥的回答問題
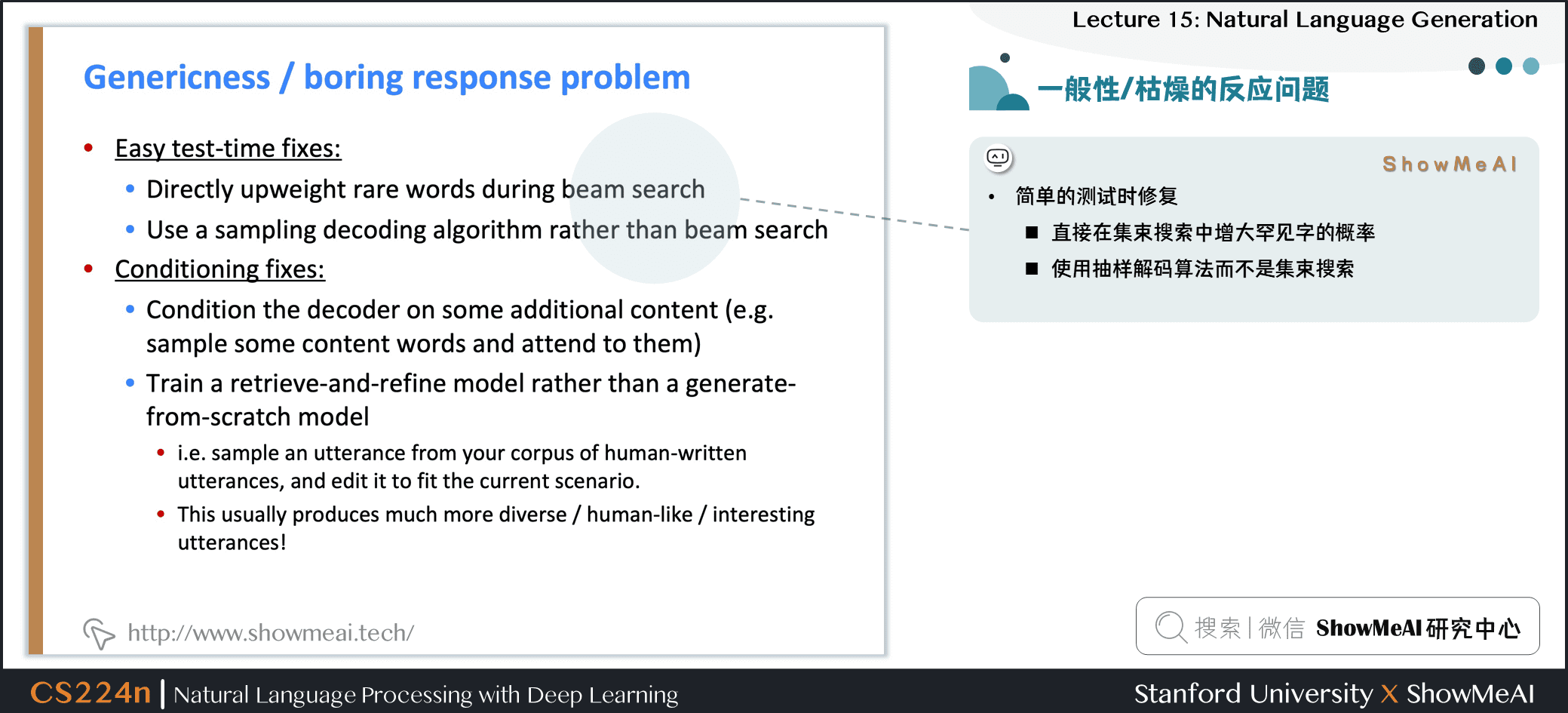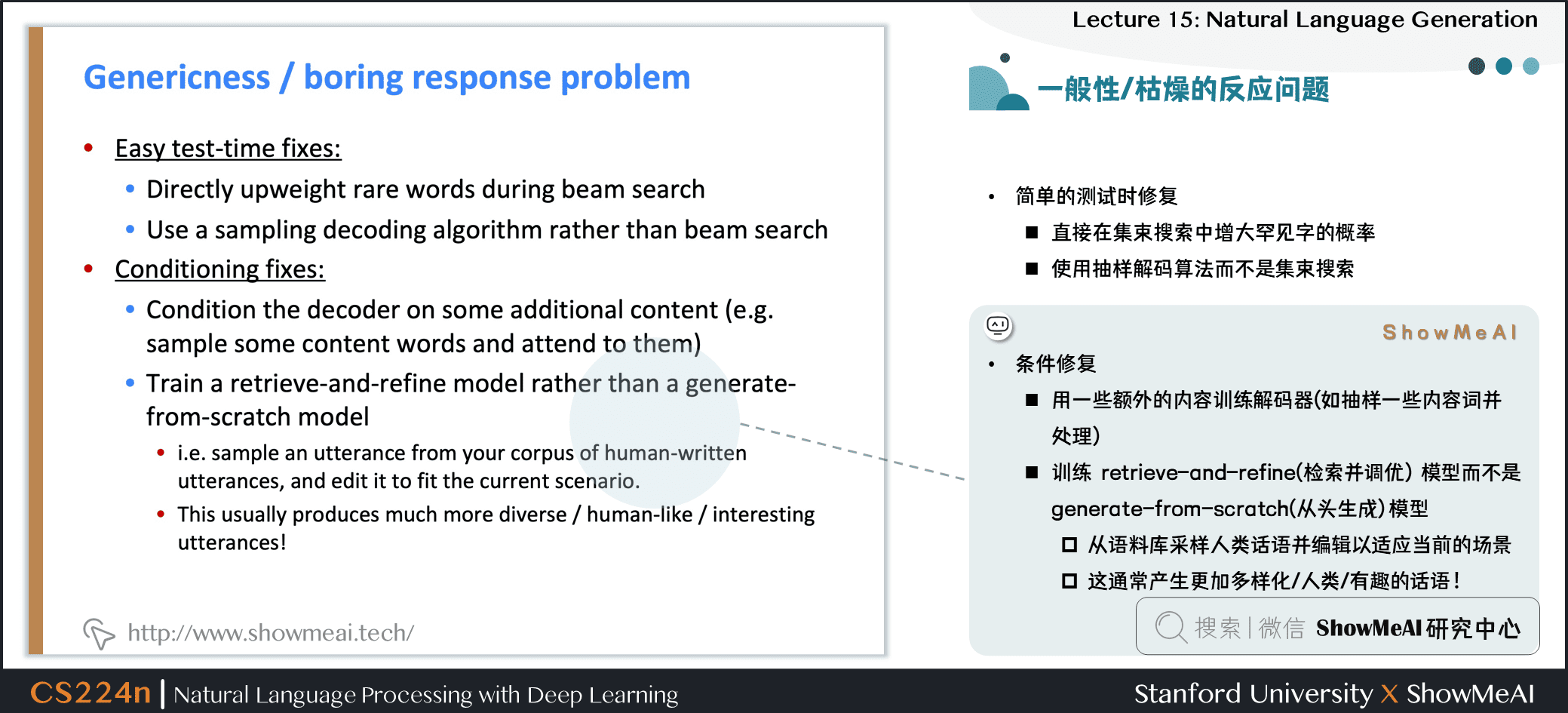
- 簡單的測試修復
- 直接在集束搜索中增大罕見字的概率
- 使用抽樣解碼算法而不是Beam搜索
- 條件修復
- 用一些額外的內容訓練解碼器 (如抽樣一些內容詞並處理)
- 訓練 retrieve-and-refine(檢索並調優) 模型而不是 generate-from-scratch(從頭生成) 模型
- 從語料庫採樣人類話語並編輯以適應當前的場景
- 這通常產生更加多樣化/人類/有趣的話語!
2.13 重複回答問題
- 簡單的解決方案
- 直接在集束搜索中禁止重複n-grams
- 通常非常有效
- 直接在集束搜索中禁止重複n-grams
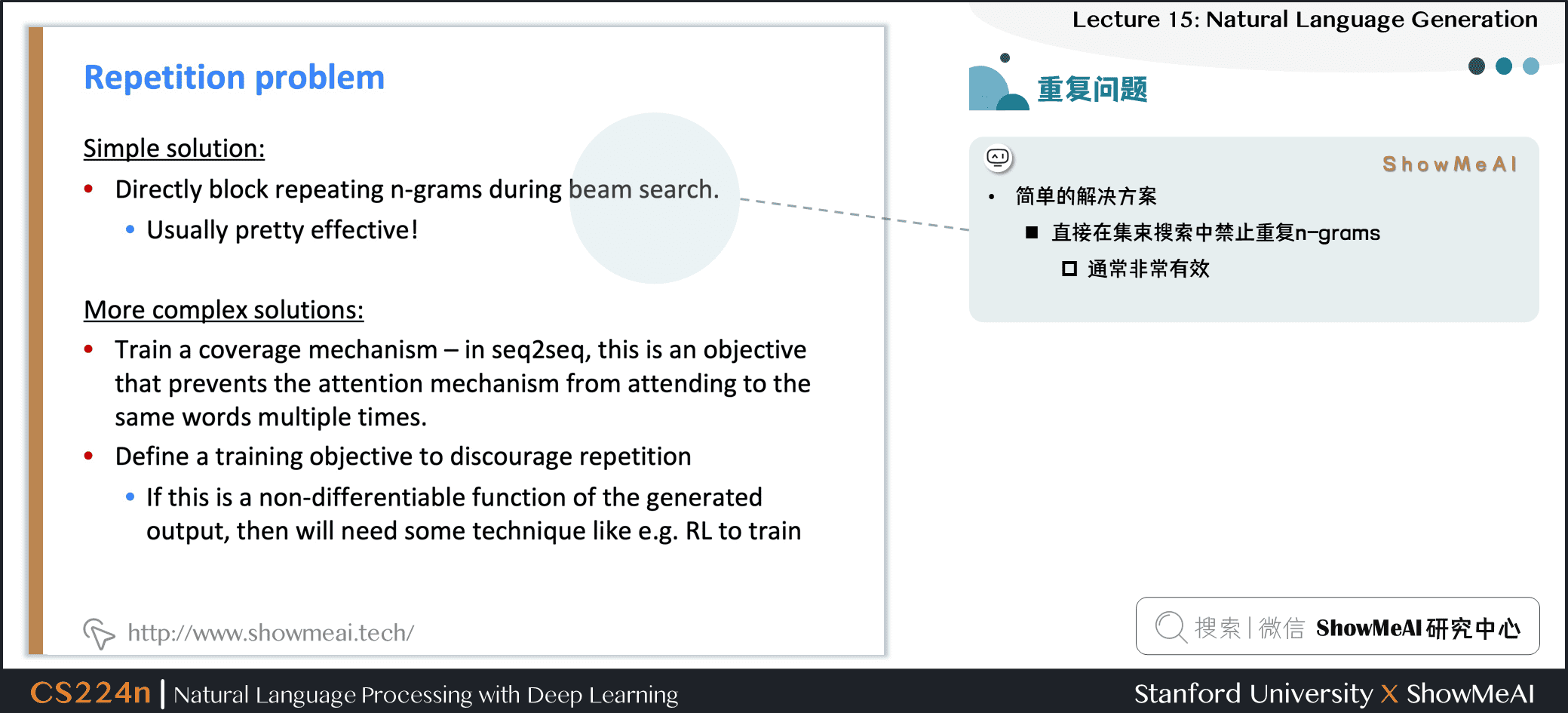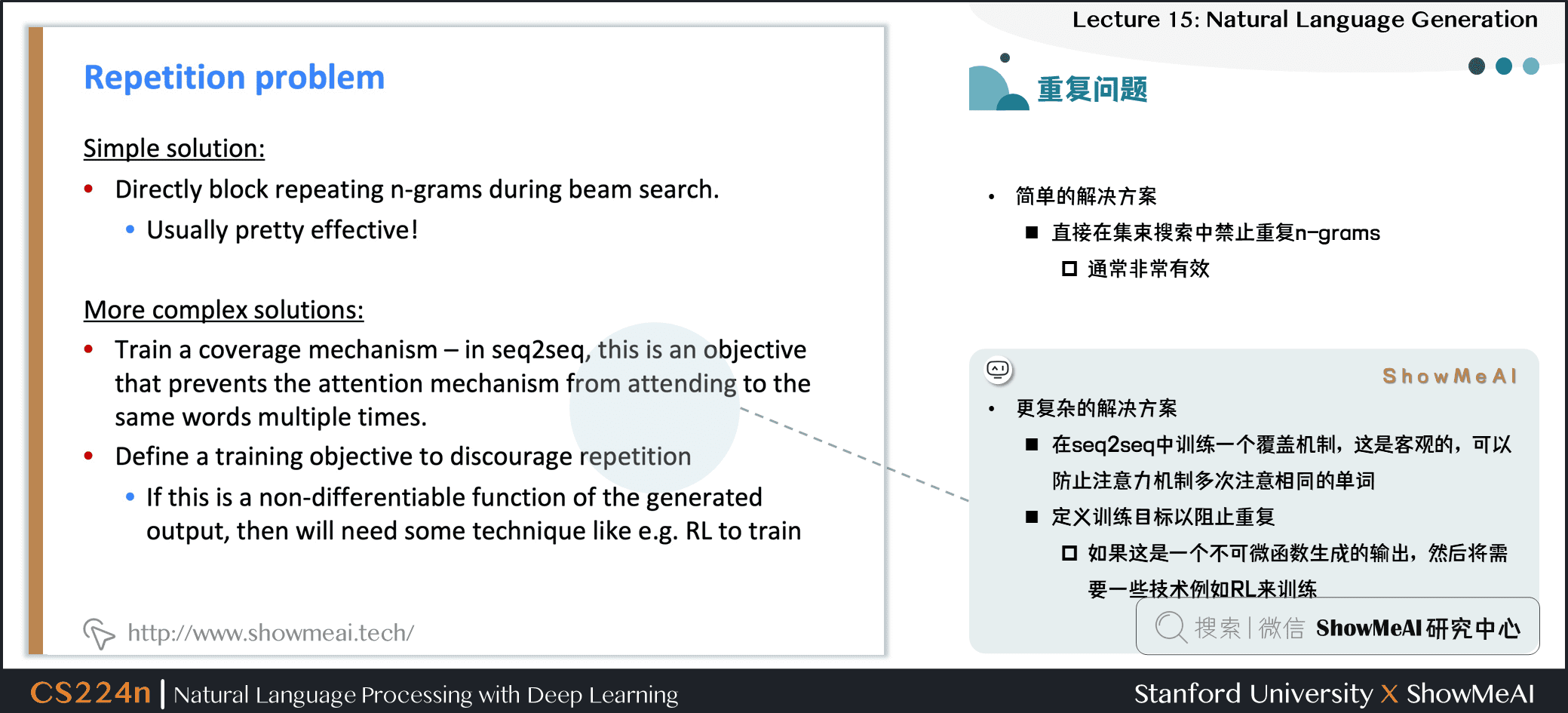
- 更複雜的解決方案
- 在seq2seq中訓練一個覆蓋機制,這是客觀的,可以防止注意力機制多次注意相同的單詞
- 定義訓練目標以阻止重複
- 如果這是一個不可微函數生成的輸出,然後將需要一些技術例如 RL 來訓練
2.14 缺少一致的人物角色問題

- 2016年,李等人提出了一個 seq2seq 對話模式,學會將兩個對話夥伴的角色編碼為嵌入
- 生成的話語是以嵌入為條件的

- 最近有一個閑聊的數據集稱為 PersonaChat,包括每一次會話的角色 (描述個人特質的5個句子的集合)
- 這提供了一種簡單的方式,讓研究人員構建 persona-conditional 對話代理
2.15 談判對話
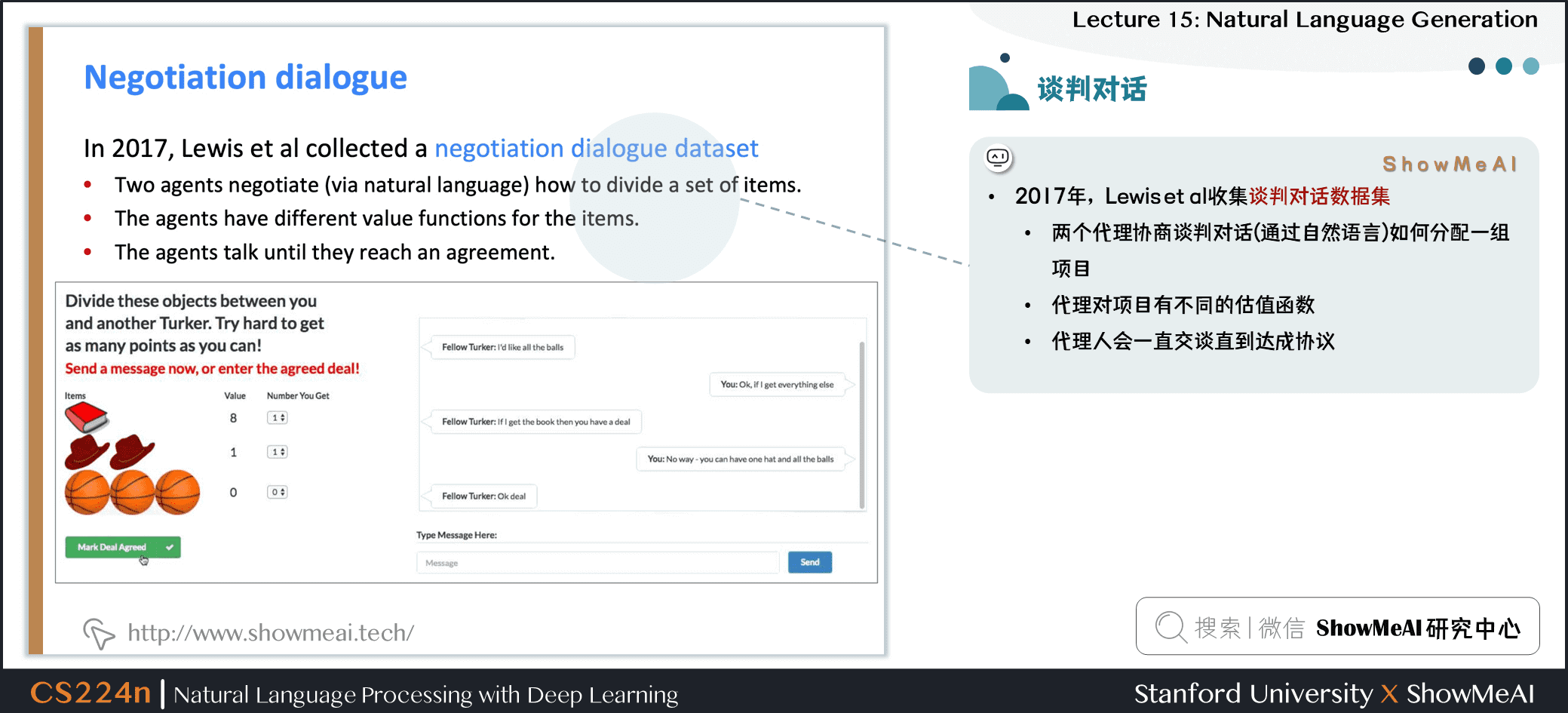
- 2017年,Lewis et al 收集談判對話數據集
- 兩個代理協商談判對話 (通過自然語言) 如何分配一組項目
- 代理對項目有不同的估值函數
- 代理人會一直交談直到達成協議

- 他們發現用標準的最大似然 (ML) 來訓練 seq2seq 系統的產生了流利但是缺乏策略的對話代理
- 和 Paulus 等的摘要論文一樣,他們使用強化學習來優化離散獎勵 (代理自己在訓練自己)
- RL 的基於目的的目標函數與 ML 目標函數相結合
- 潛在的陷阱:如果兩兩對話時,代理優化的只是RL目標,他們可能會偏離英語
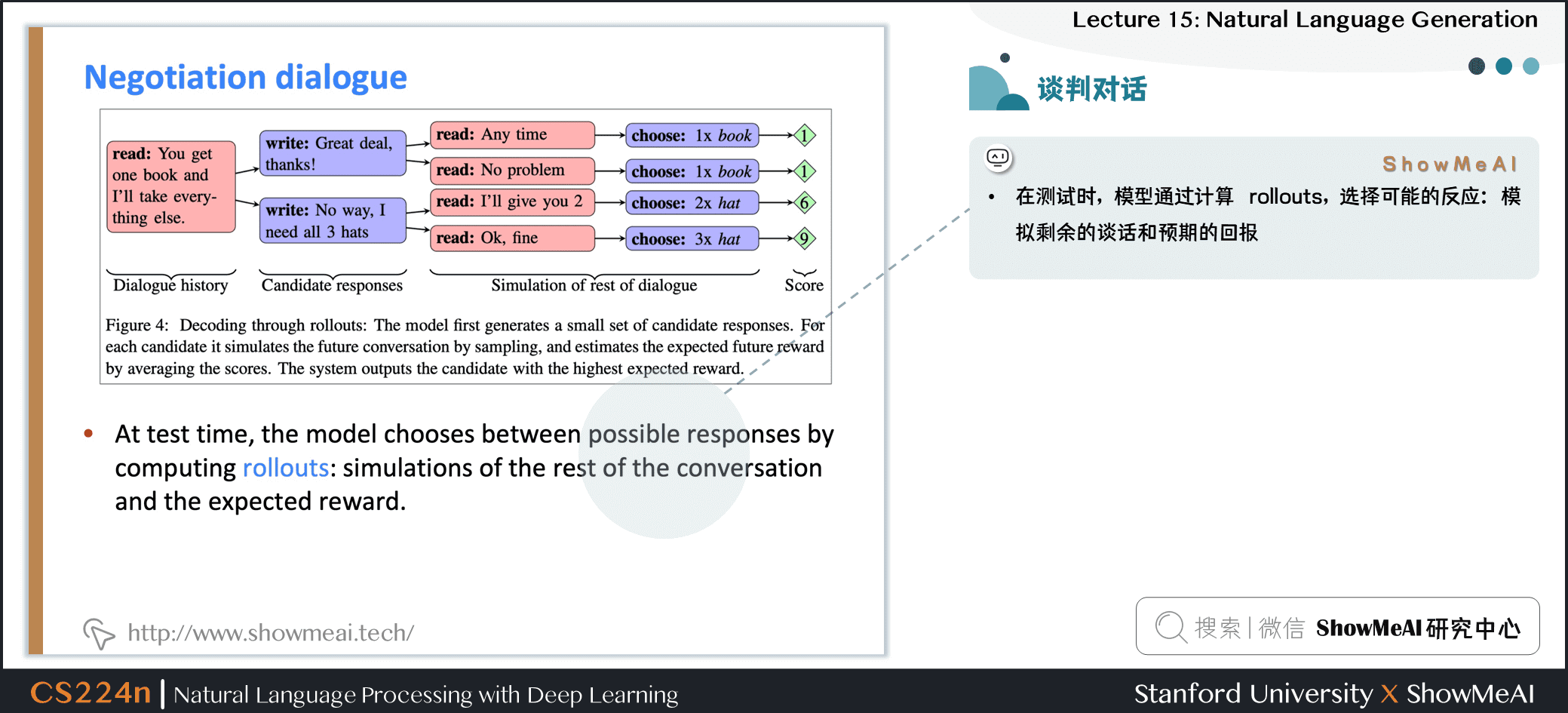
- 在測試時,模型通過計算 rollouts,選擇可能的反應:模擬剩餘的談話和預期的回報

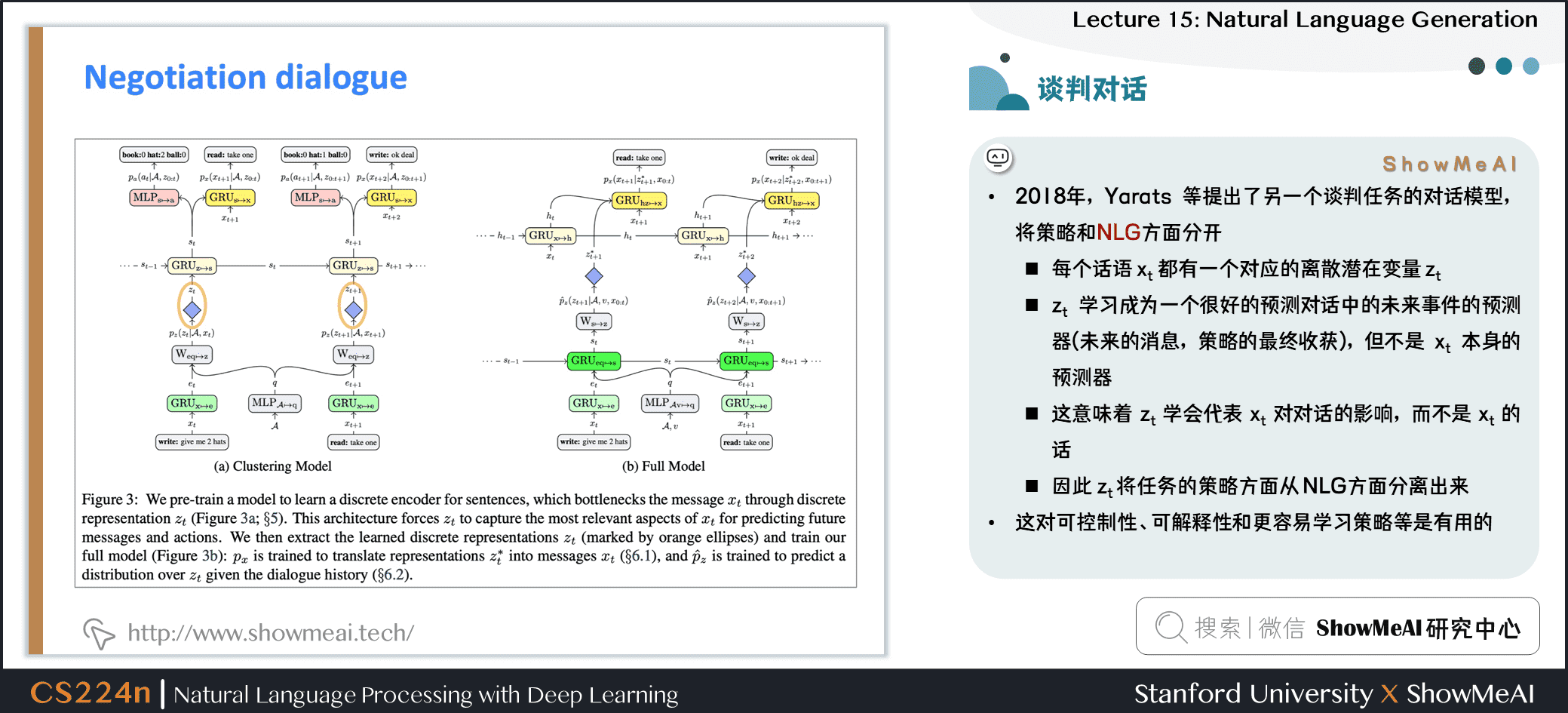
- 2018年,Yarats 等提出了另一個談判任務的對話模型,將策略和 NLG 方面分開
- 每個話語 \(x_t\) 都有一個對應的離散潛在變量 \(z_t\)
- \(z_t\) 學習成為一個很好的預測對話中的未來事件的預測器 (未來的消息,策略的最終收穫),但不是 \(x_t\) 本身的預測器
- 這意味着 \(z_t\) 學會代表 \(x_t\) 對對話的影響,而不是 \(x_t\) 的 words
- 因此 \(z_t\) 將任務的策略方面從 NLG方面分離出來
- 這對可控制性、可解釋性和更容易學習策略等是有用的
2.16 會話問答:CoQA

- 一個來自斯坦福 NLP 的新數據集
- 任務:回答關於以一段對話為上下文的文本的問題
- 答案必須寫摘要地(不是複製)
- QA / 閱讀理解任務,和對話任務
2.17 故事述說
- 神經網絡講故事的大部分工作使用某種提示
- 給定圖像生成的故事情節段落
- 給定一個簡短的寫作提示生成一個故事
- 給定迄今為止的故事,生成故事下個句子(故事續寫)
- 這和前兩個不同,因為我們不關心系統在幾個生成的句子上的性能
- 神經故事飛速發展
- 第一個故事研討會於 2018 年舉行
- 它舉行比賽 (使用五張圖片的序列生成一個故事)
2.18 從圖像生成故事

- 有趣的是,這並不是直接的監督圖像標題。沒有配對的數據可以學習。

- 問題:如何解決缺乏並行數據的問題
- 回答:使用一個通用的 sentence-encoding space
- Skip-thought 向量是一種通用的句子嵌入方法
- 想法類似於我們如何學通過預測周圍的文字來學習單詞的嵌入
- 使用 COCO (圖片標題數據集),學習從圖像到其標題的 Skip-thought 編碼的映射
- 使用目標樣式語料庫(Taylor Swift lyrics),訓練RNN-LM, 將Skip-thought向量解碼為原文
- 把兩個放在一起
2.19 從寫作提示生成故事

- 2018年,Fan 等發佈了一個新故事生成數據集 collected from Reddit』s WritingPrompts subreddit.
- 每個故事都有一個相關的簡短寫作提示
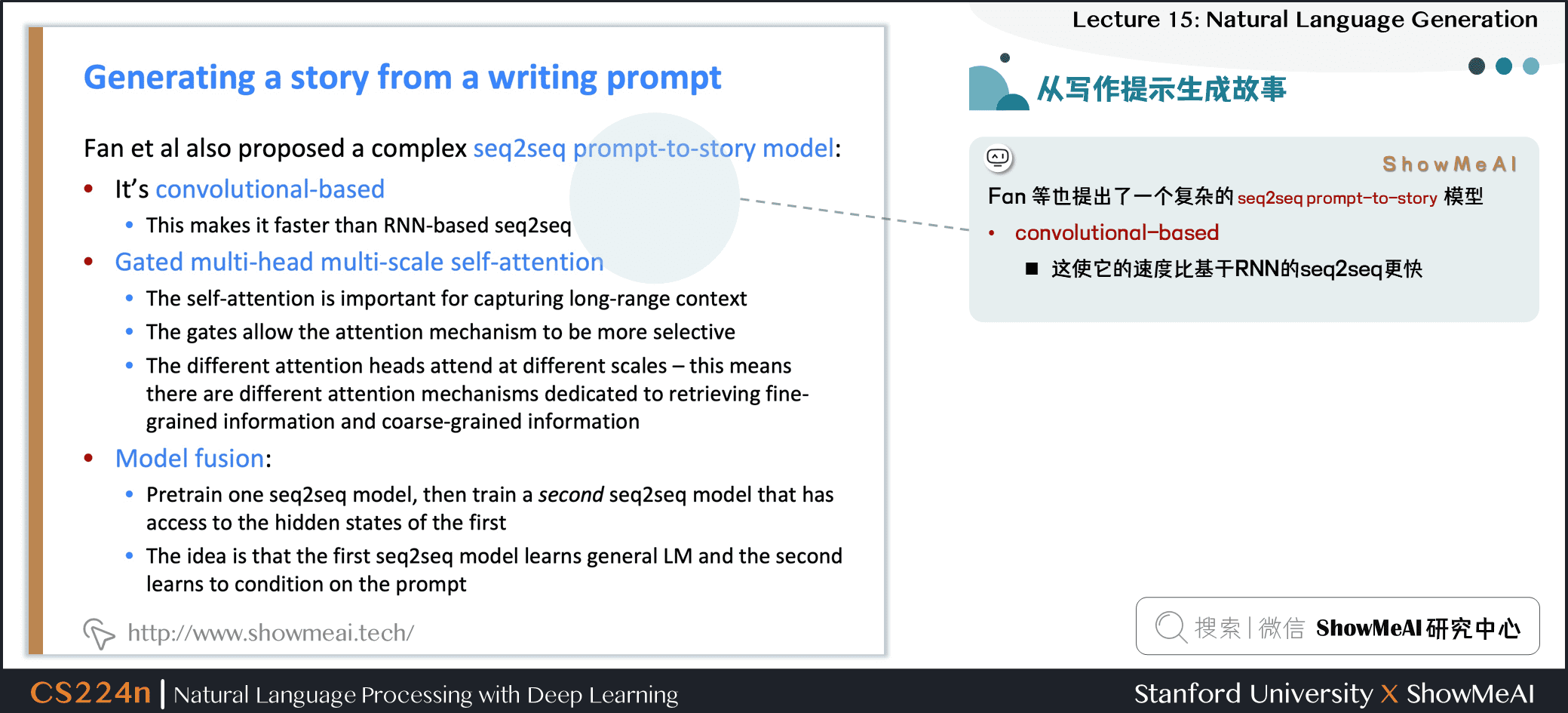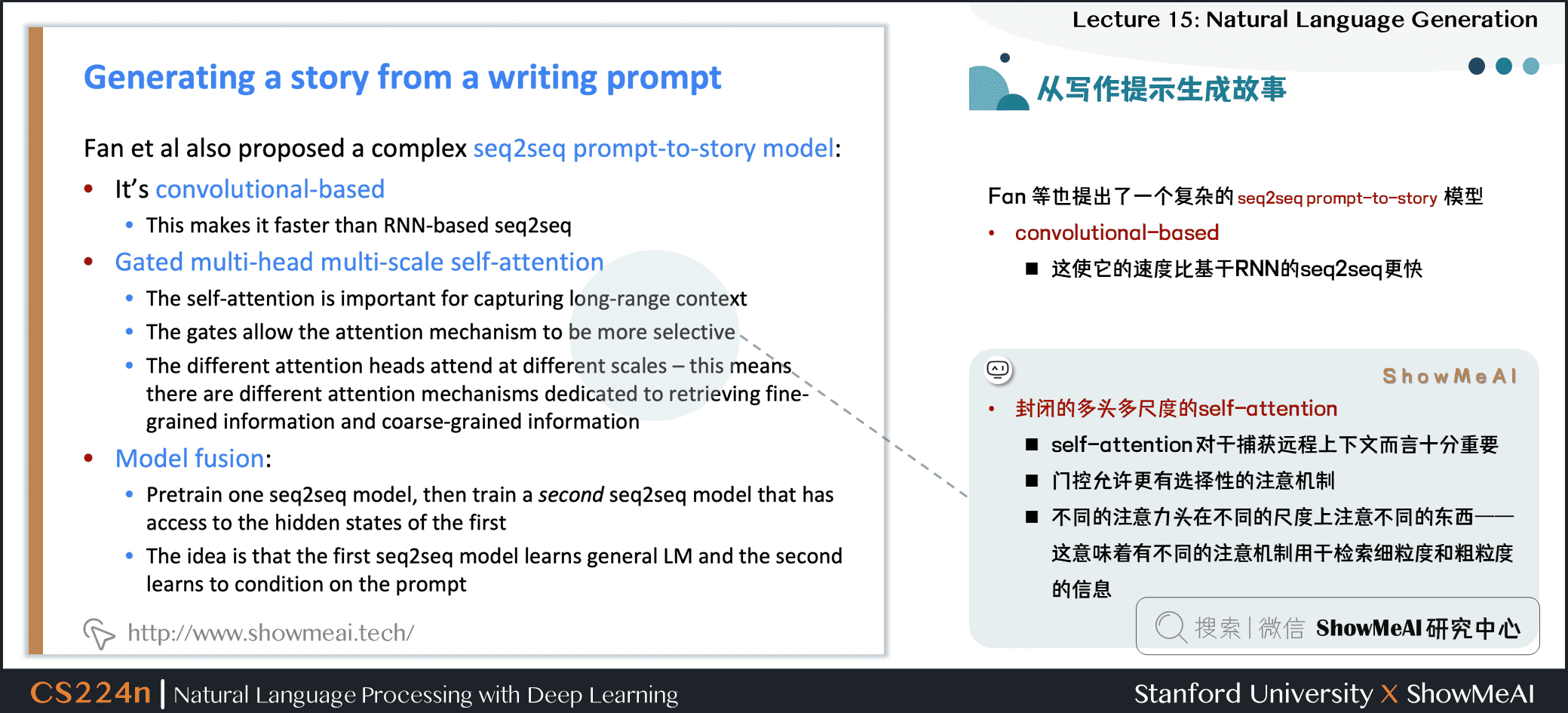
Fan 等也提出了一個複雜的 seq2seq prompt-to-story 模型
- 基於卷積的模型
- 這使它的速度比基於RNN的 seq2seq 更快
- 封閉的多頭多尺度的自注意力
- 自注意力對於捕獲遠程上下文而言十分重要
- 門控允許更有選擇性的注意機制
- 不同的注意力頭在不同的尺度上注意不同的東西——這意味着有不同的注意機制用於檢索細粒度和粗粒度的信息

- 模型融合
- 預訓練一個 seq2seq 模型,然後訓練第二個 seq2seq 模型訪問的第一個模型的隱狀態
- 想法是,第一個 seq2seq 模型學習通用語言模型,第二個模型學習基於提示的條件

- 結果令人印象深刻
- 與提示相關
- 多樣化,並不普通
- 在文體上戲劇性
- 但是
- 主要是氛圍 / 描述性 / 場景設定,很少是事件 / 情節
- 生成更長時,大多數停留在同樣的想法並沒有產生新的想法——一致性問題
2.20 講故事的挑戰

- 由神經語言模型生成的故事聽起來流暢…但是是曲折的,荒謬的,情節不連貫的
缺失的是什麼?
- 語言模型對單詞序列進行建模。故事是事件序列
- 為了講一個故事,我們需要理解和模擬
- 事件和它們之間的因果關係結構
- 人物,他們的個性、動機、歷史、和其他人物之間的關係
- 世界 (誰、是什麼和為什麼)
- 敘事結構(如說明 → 衝突 → 解決)
- 良好的敘事原則(不要引入一個故事元素然後從未使用它)
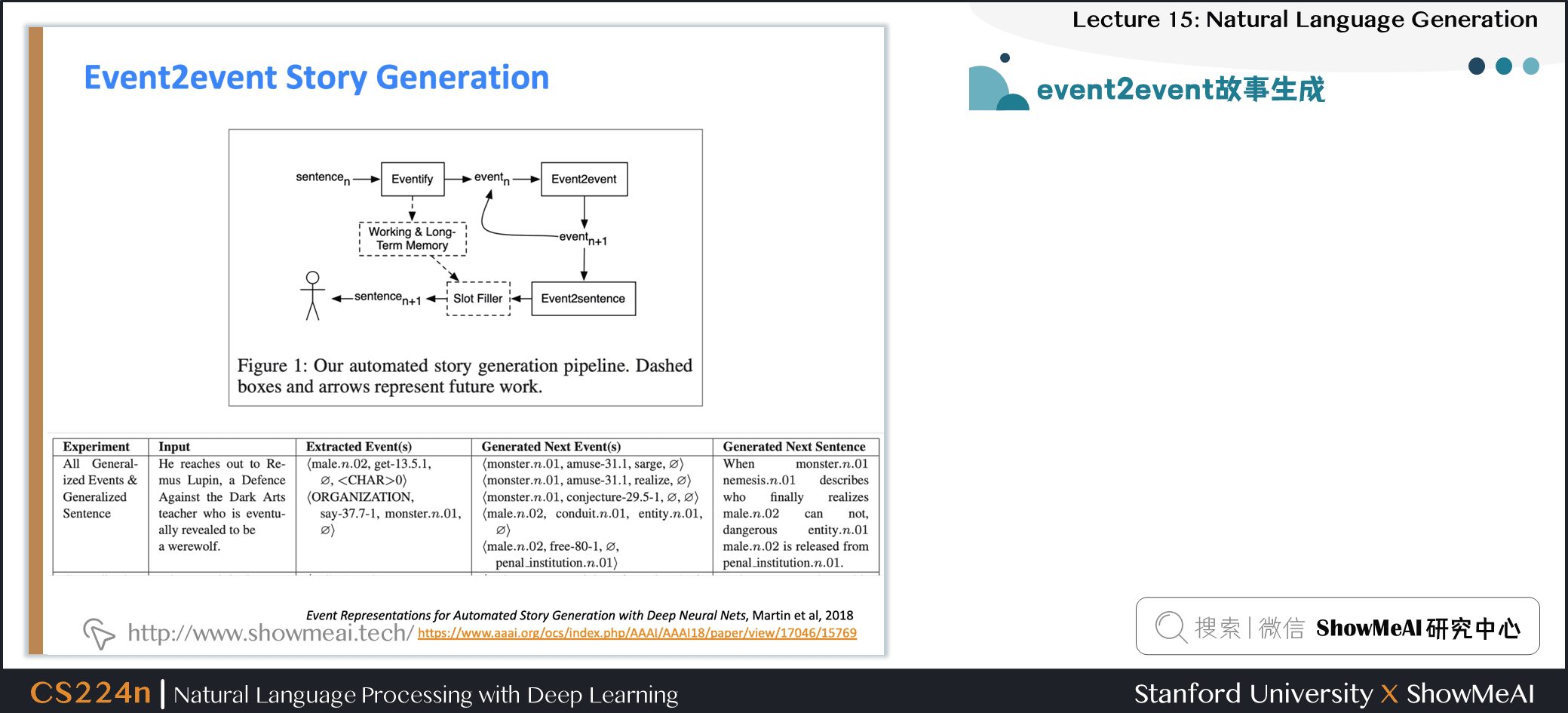
2.21 event2event故事生成
2.22 結構化故事生成

2.23 跟蹤事件、實體、狀態等
- 旁註:在神經 NLU (自然語言理解) 領域,已經有大量關於跟蹤事件 / 實體 / 狀態的工作
- 例如,Yejin Choi』s group 很多工作在這一領域
- 將這些方法應用到 NLG是更加困難的
- 如果縮小範圍,則更可控的
- 不採用自然語言生成開放域的故事,而是跟蹤狀態
- 生成一個配方 (考慮到因素),跟蹤因素的狀態
2.24 生成食譜時跟蹤狀態
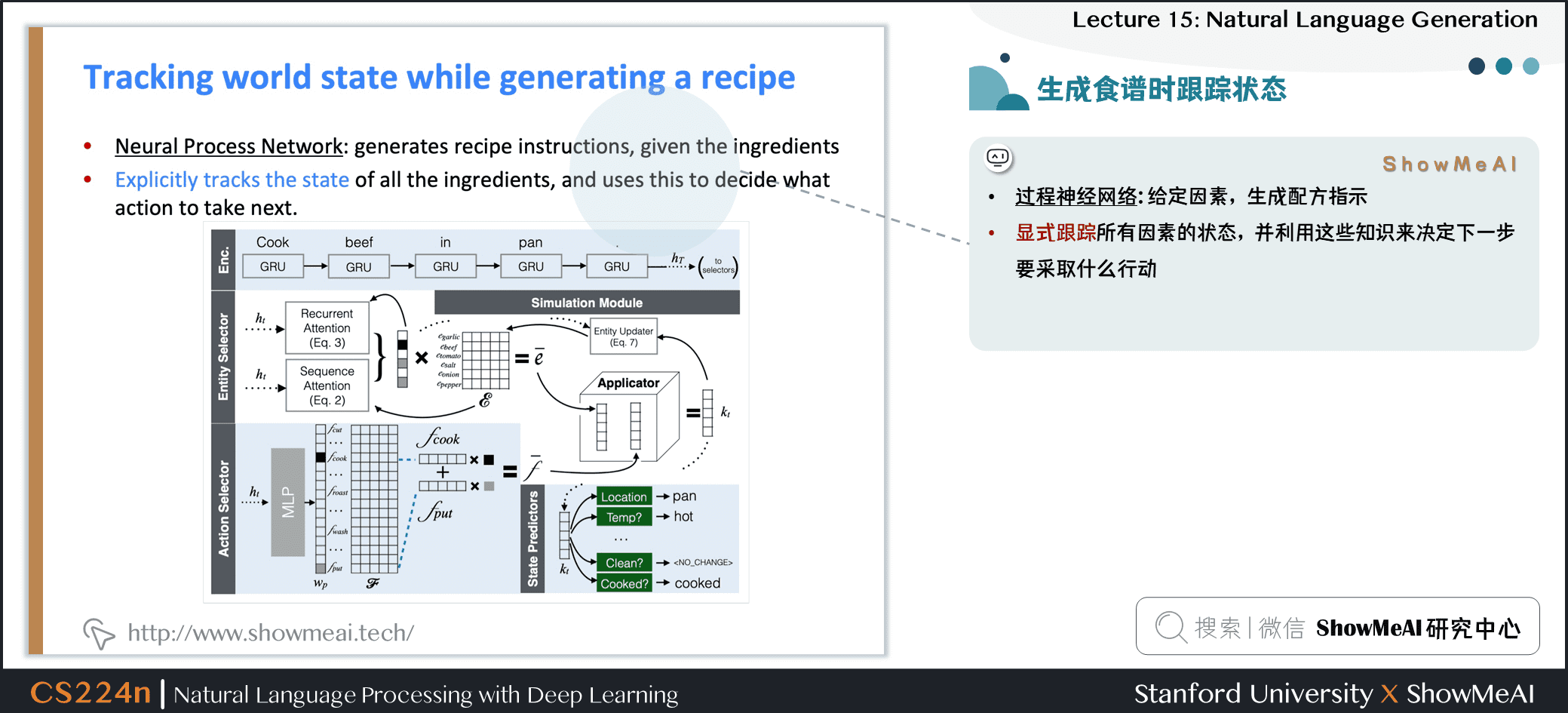
- 過程神經網絡:給定因素,生成配方指示
- 顯式跟蹤所有因素的狀態,並利用這些知識來決定下一步要採取什麼行動
2.25 詩歌生成:Hafez

- Hafez:Ghazvininejad et al 的詩歌系統
- 主要思路:使用一個有限狀態受體 (FSA) 來定義所有可能的序列,服從希望滿足的韻律 (節拍) 約束
- 然後使用 FSA 約束 RNN-LM 的輸出
- 例如
- 莎士比亞的十四行詩是 14 行的 iambic pentameter
- 所以莎士比亞的十四行詩的 FSA 是 \(((01)^5)^{14}\)
- 在Beam搜索解碼中,只有探索屬於 FSA 的假設
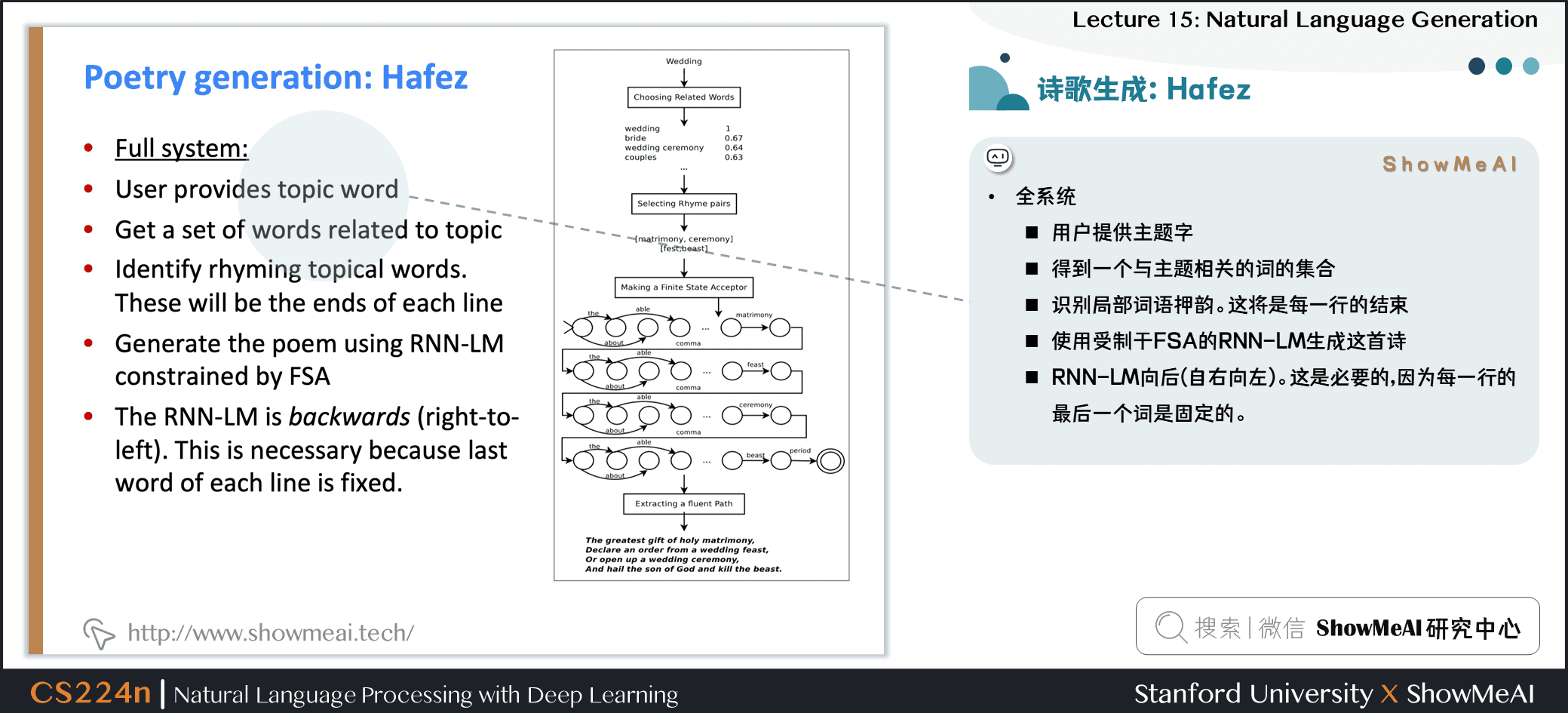
- 全系統
- 用戶提供主題字
- 得到一個與主題相關的詞的集合
- 識別局部詞語押韻,這將是每一行的結束
- 使用受制於 FSA 的 RNN語言模型生成這首詩
- RNN語言模型向後(自右向左)。這是必要的,因為每一行的最後一個詞是固定的
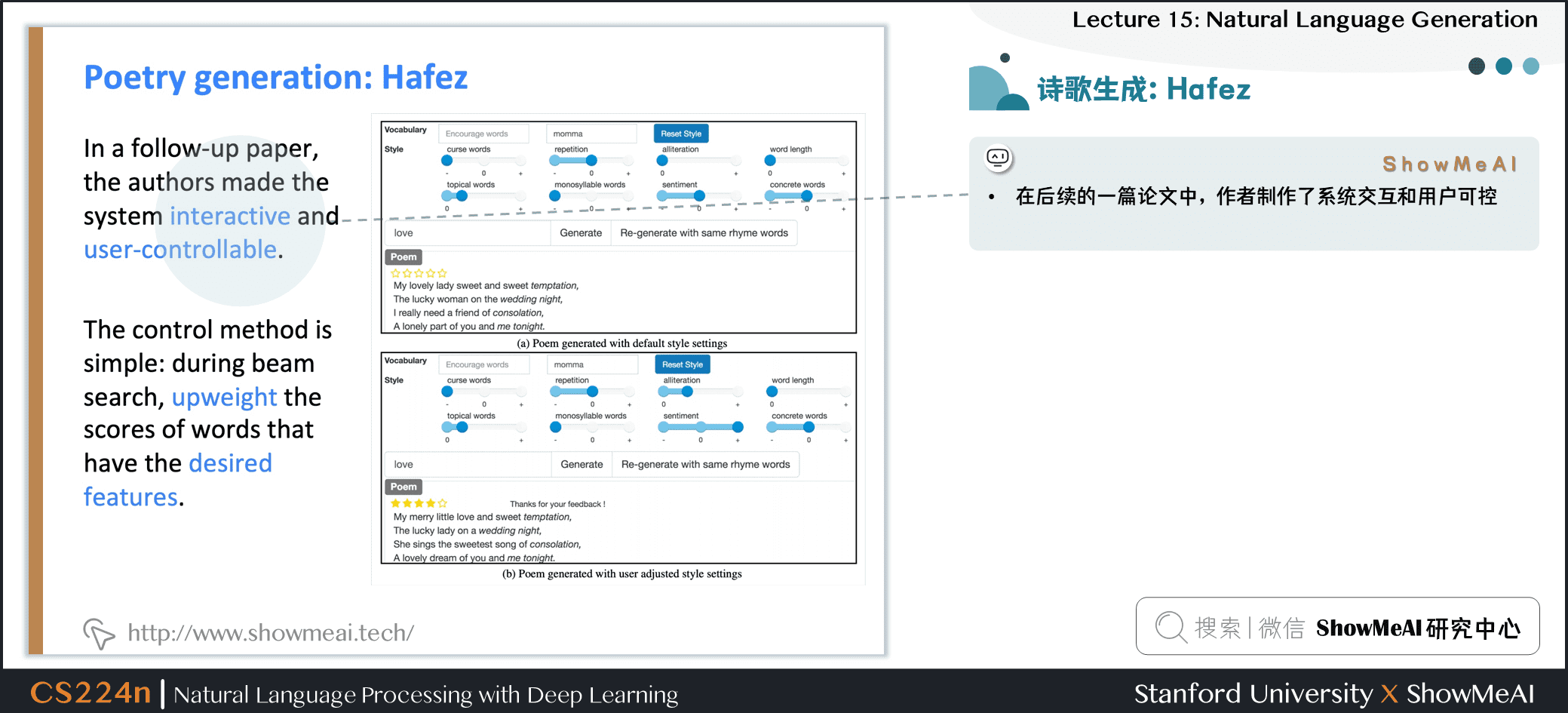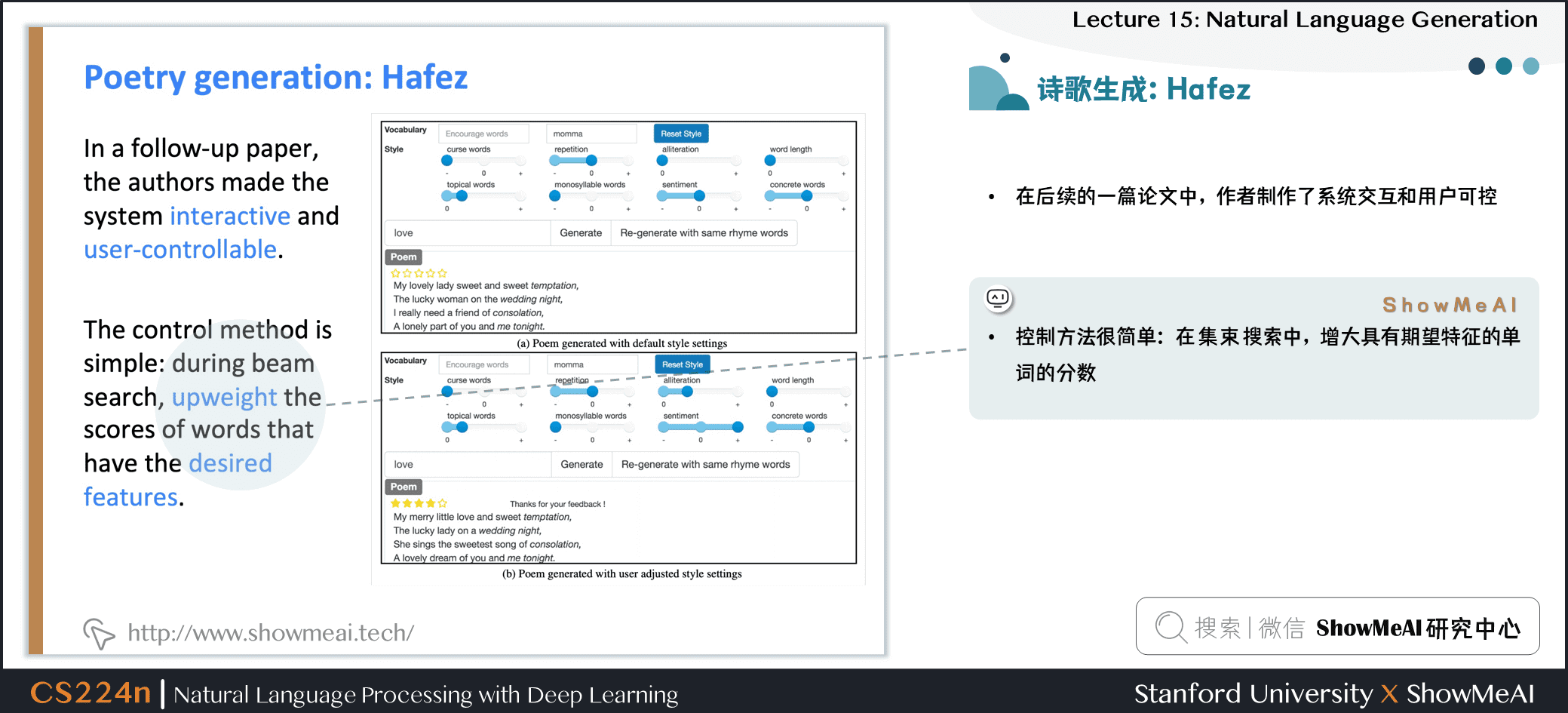
- 在後續的一篇論文中,作者製作了系統交互和用戶可控
- 控制方法很簡單:在集束搜索中,增大具有期望特徵的單詞的分數
2.26 詩歌生成:Deep-speare
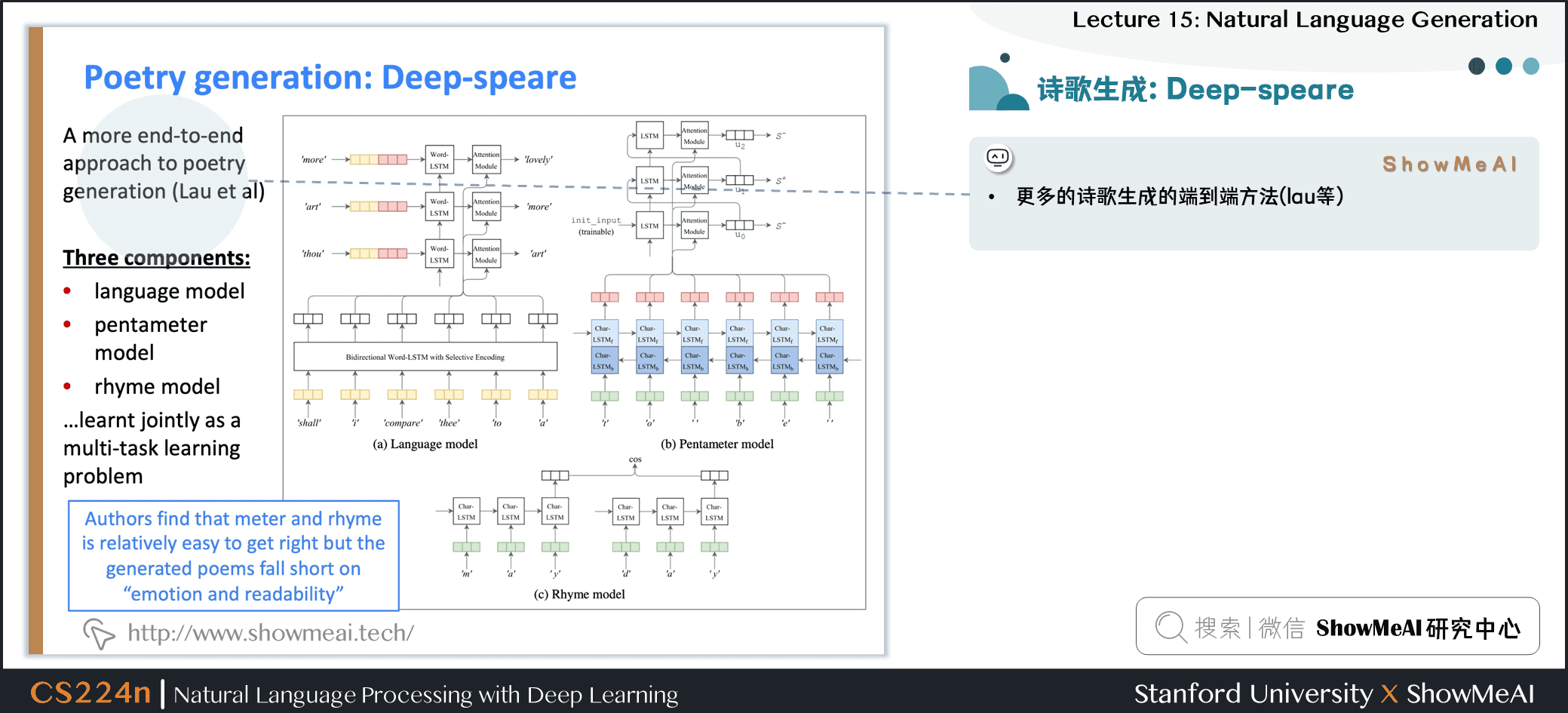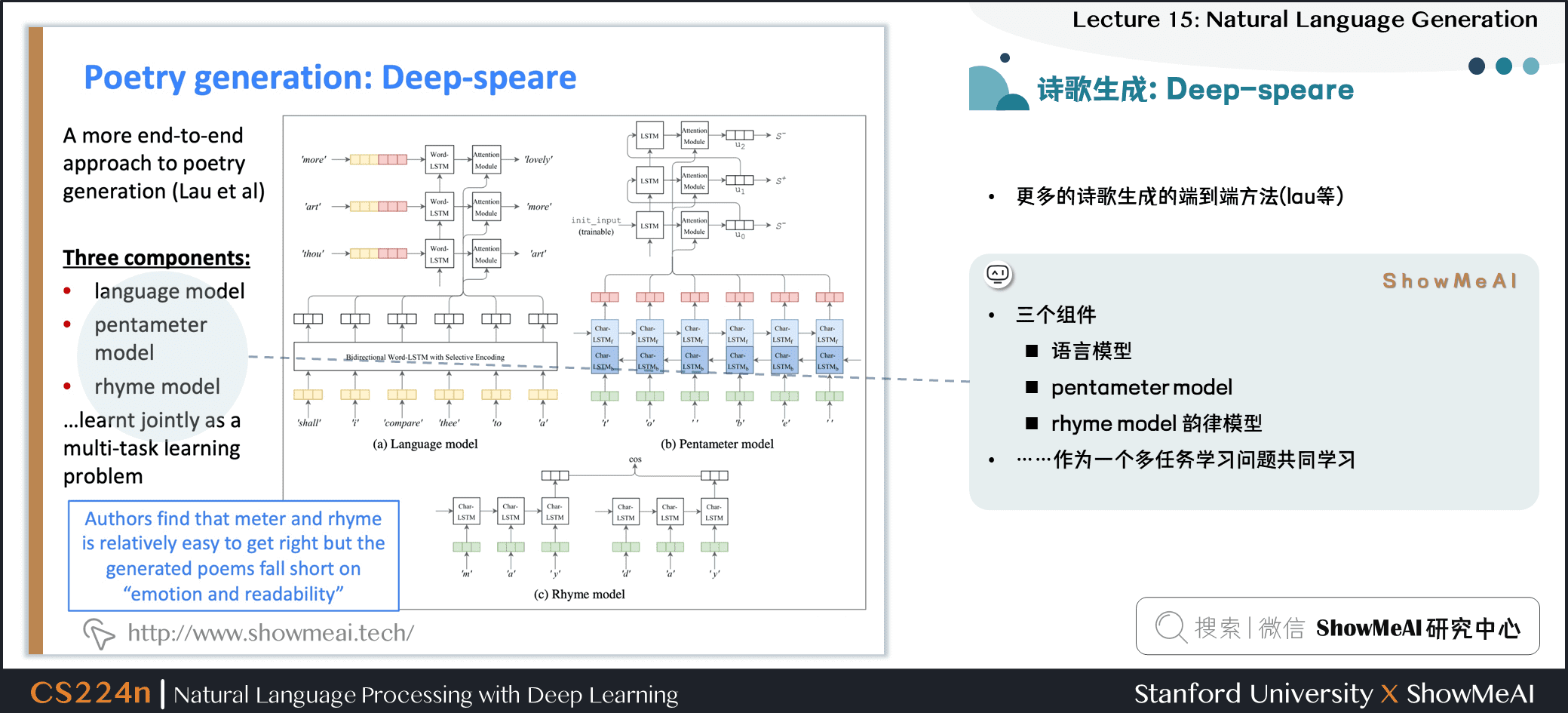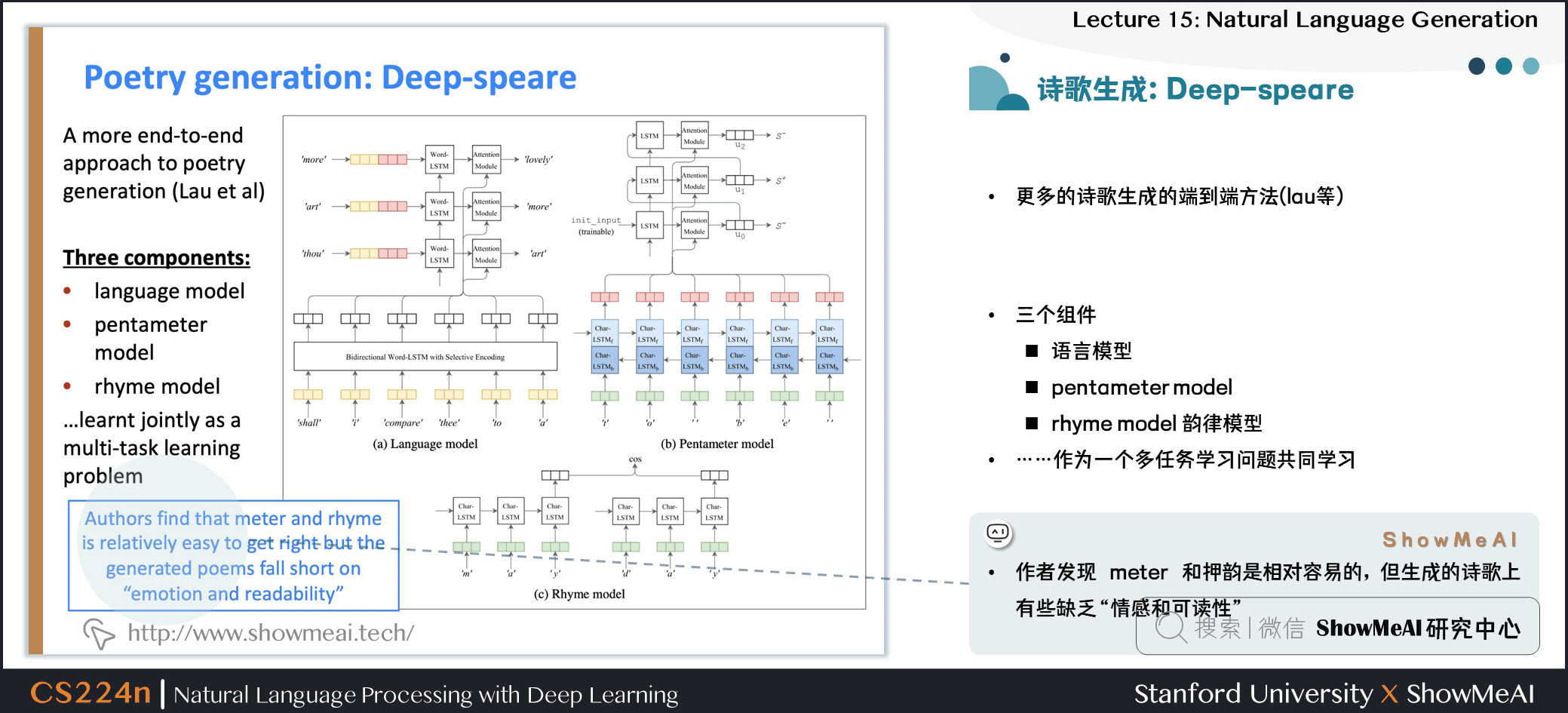
- 更多的詩歌生成的端到端方法 (lau等)
- 三個組件
- 語言模型
- pentameter model
- rhyme model 韻律模型……
- 作為一個多任務學習問題共同學習
- 作者發現 meter 和押韻是相對容易的,但生成的詩歌上有些缺乏
情感和可讀性
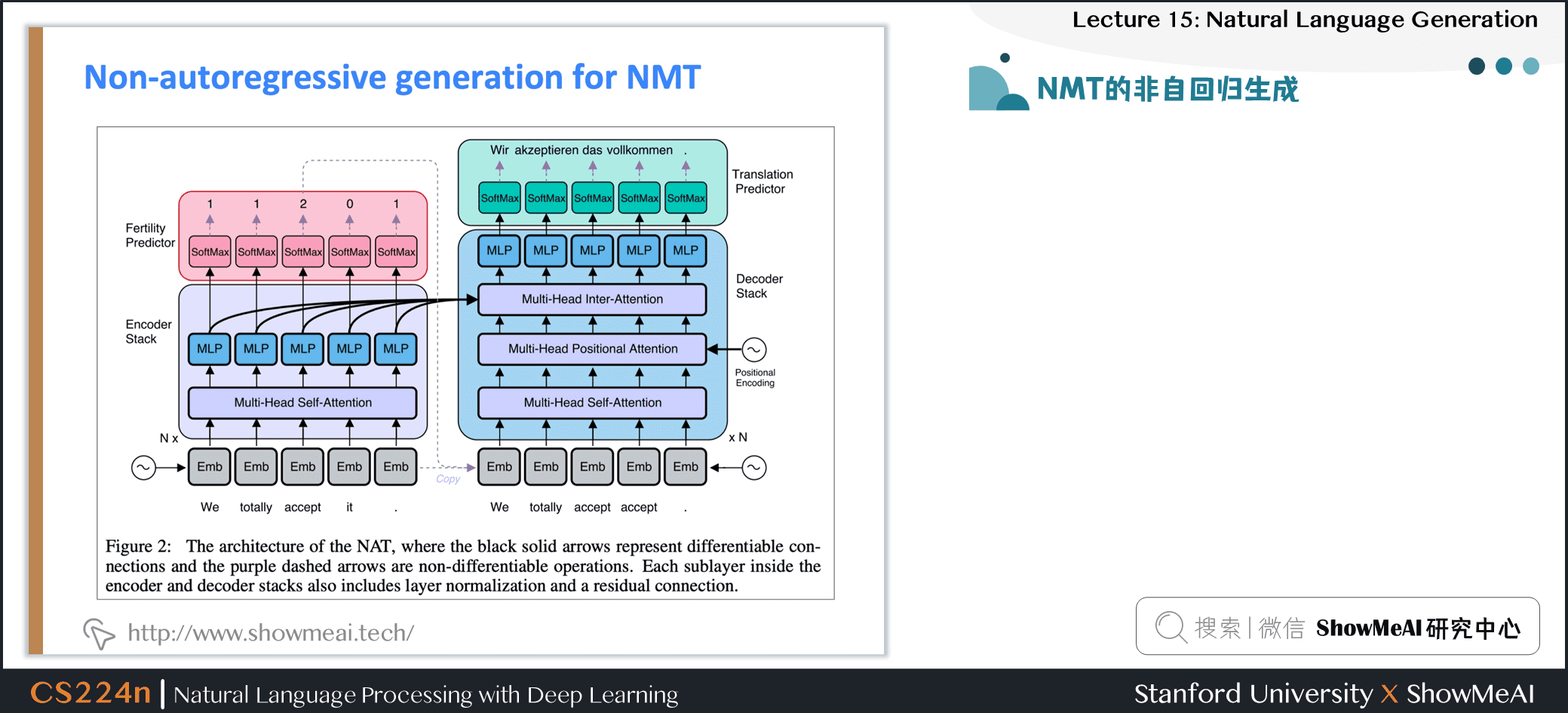
2.27 NMT的非自回歸生成

- 2018年,顧等發表了
Non-autoregressive 神經機器翻譯模型- 意義:它不是根據之前的每個單詞,從左到右產生翻譯
- 它並行生成翻譯
- 這具有明顯的效率優勢,但從文本生成的角度來看也很有趣
- 架構是基於Transformer 的;最大的區別是,解碼器可以運行在測試時並行
3.自然語言生成NLG評估

3.1 NLG的自動評價指標

基於詞重疊的指標 (BLEU,ROUGE,METROR,F1,等等)
- 他們不適合機器翻譯
- 對於摘要而言是更差的評價標準,因為摘要比機器翻譯更開放
- 不幸的是,與抽象摘要系統相比,提取摘要系統更受ROUGE青睞
- 對於對話甚至更糟,這比摘要更開放
- 類似的例子還有故事生成
3.2 單詞重疊指標不利於對話

- 上圖展示了 BLEU-2、Embedding average 和人類評價的相關性都不高

3.3 NLG的自動評價指標

- Perplexity / 困惑度?
- 捕捉 LM 有多強大,但是不會告訴關於生成的任何事情 (例如,如果困惑度是未改變的,解碼算法是不好的)
- 詞嵌入基礎指標?
- 主要思想:比較詞嵌入的相似度 (或詞嵌入的均值),而不僅僅是重疊的單詞。以更靈活的方式捕獲語義
- 不幸的是,仍然沒有與類似對話的開放式任務的人類判斷,產生很好的聯繫
3.4 單詞重疊指標不利於對話

3.5 NLG的自動評價指標

- 沒有自動指標充分捕捉整體質量 (即代表人類的質量判斷)
- 但可定義更多的集中自動度量來捕捉生成文本的特定方面
- 流利性 (使用訓練好的語言模型計算概率)
- 正確的風格 (使用目標語料庫上訓練好的語言模型的概率)
- 多樣性 (罕見的用詞,n-grams 的獨特性)
- 相關輸入 (語義相似性度量)
- 簡單的長度和重複
- 特定於任務的指標,如摘要的壓縮率
- 雖然這些不衡量整體質量,他們可以幫助我們跟蹤一些我們關心的重要品質
3.6 人工評價

- 人類的判斷被認為是黃金標準
- 當然,我們知道人類評價是緩慢而昂貴的
- 但這些問題?
- 假如獲得人類的評估:人類評估解決所有的問題嗎?
- 沒有!進行人類有效評估非常困難:
- 是不一致的
- 可能是不合邏輯的
- 失去注意力
- 誤解了問題
- 不能總是解釋為什麼他們會這樣做
3.7 可控聊天機械人的詳細人工評估
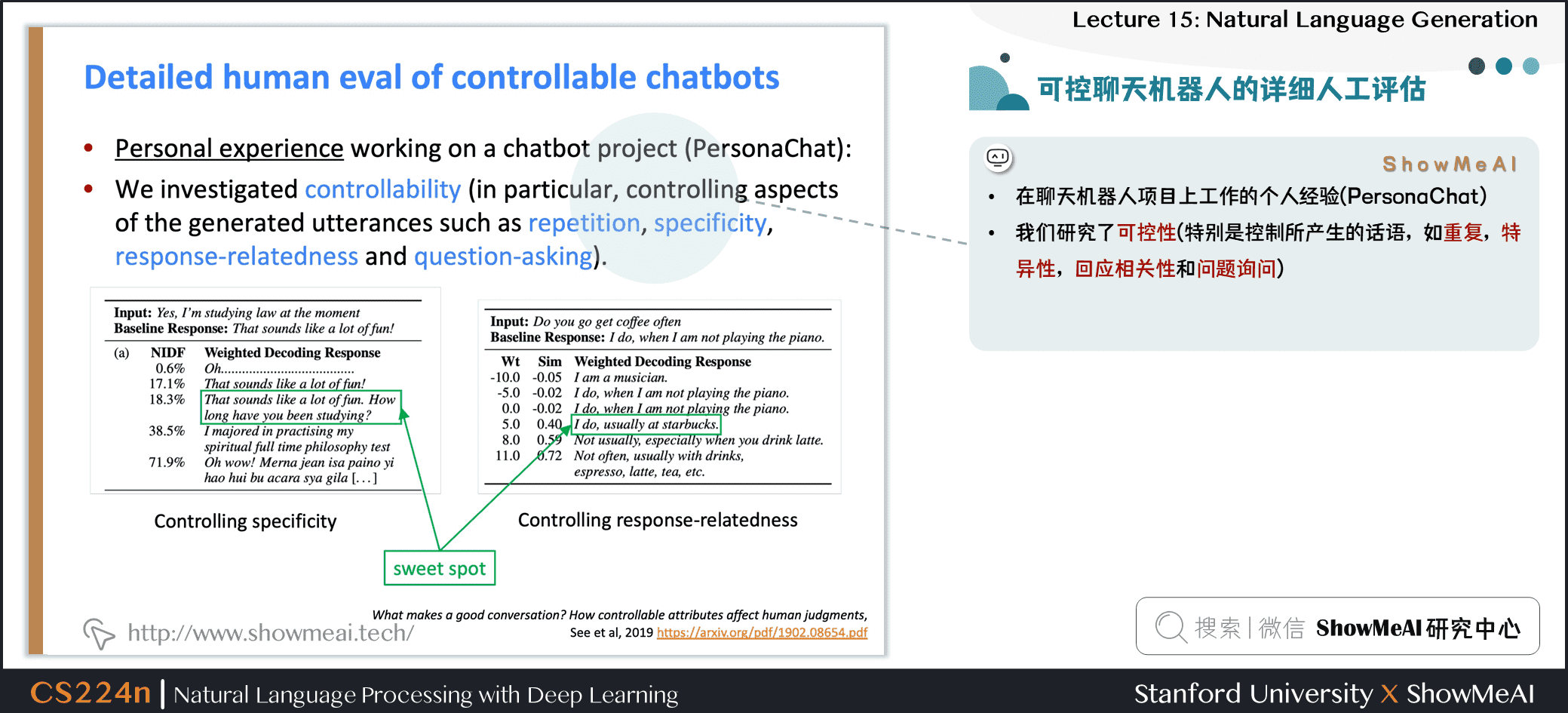
- 在聊天機械人項目上工作的個人經驗 (PersonaChat)
- 我們研究了可控性 (特別是控制所產生的話語,如重複,特異性,回應相關性 和 問題詢問)

- 如何要求人的質量判斷?
- 我們嘗試了簡單的整體質量 (多項選擇) 問題,例如:
- 這次對話有多好?
- 這個用戶有多吸引人?
- 這些用戶中哪一個給出了更好的響應?
- 想再次與該用戶交談嗎?
- 認為該用戶是人還是機械人?
- 主要問題:
- 必然非常主觀
- 回答者有不同的期望;這會影響他們的判斷
- 對問題的災難性誤解 (例如
聊天機械人非常吸引人,因為它總是回寫) - 總體質量取決於許多潛在因素;他們應該如何被稱重 和/或 比較?
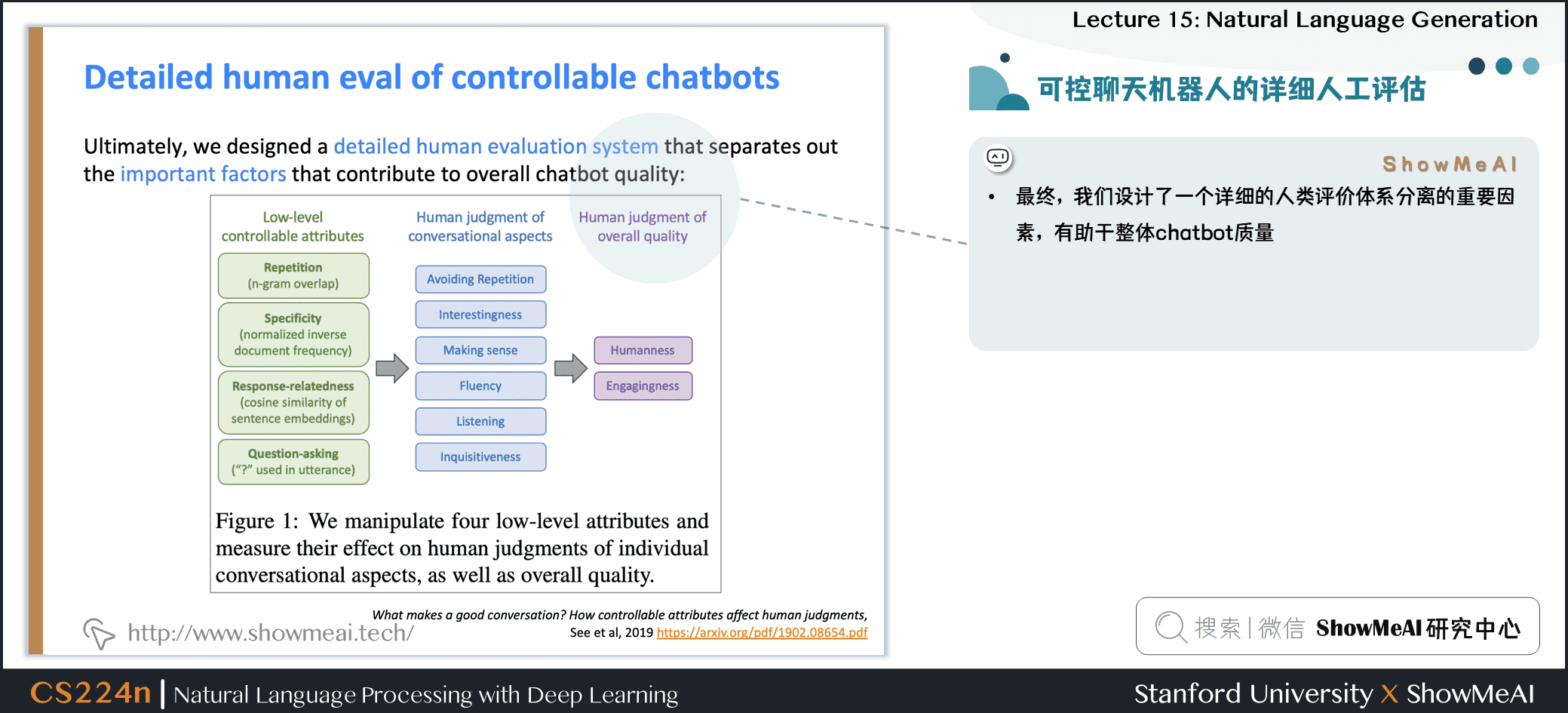
- 最終,我們設計了一個詳細的人類評價體系分離的重要因素,有助於整體 chatbot 質量

發現
- 控制重複對於所有人類判斷都非常重要
- 提出更多問題可以提高參與度
- 控制特異性 (較少的通用話語) 提高了聊天機械人的吸引力,趣味性和感知的聽力能力。
- 但是,人類評估人員對風險的容忍度較低 (例如無意義或非流利的輸出) 與較不通用的機械人相關聯
- 總體度量「吸引力」 (即享受) 很容易最大化 – 我們的機械人達到了近乎人性化的表現
- 整體度量「人性化」 (即圖靈測試) 根本不容易最大化 – 所有機械人遠遠低於人類表現
- 人性化與會話質量不一樣!
- 人類是次優的會話主義者:他們在有趣,流利,傾聽上得分很低,並且問的問題太少
3.8 NLG評估的可能新途徑?

- 語料庫級別的評價指標
- 度量應獨立應用於測試集的每個示例,或整個語料庫的函數
- 例如,如果對話模型對測試集中的每一個例子回答相同的通用答案,它應該被懲罰
- 評估衡量多樣性安全權衡的評估指標
- 免費的人類評估
- 遊戲化:使任務(例如與聊天機械人交談)有趣,這樣人類就可以為免費提供監督和隱式評估,作為評估指標
- 對抗性鑒別器作為評估指標
- 測試 NLG 系統是否能愚弄經過訓練能夠區分人類文本和 AI 生成的文本的識別器
4.NLG研究的一些想法,目前的趨勢,未來的可能方向

4.1 NLG中令人興奮的當前趨勢

- 將離散潛在變量納入 NLG
- 可以幫助在真正需要它的任務中建模結構,例如講故事,任務導向對話等
- 嚴格的從左到右生成的替代方案
- 並行生成,迭代細化,自上而下生成較長的文本
- 替代 teacher forcing 的最大可能性訓練
- 更全面的句子級別的目標函數 (而不是單詞級別)
4.2 NLG研究

4.3 神經NLG群體正在迅速成熟

- 在NLP+深度學習的早期,社區主要將成功的非機動車交通方法遷移到NLG任務中。
- 現在,越來越多的創新 NLG 技術出現,針對非 NMT 生成環境。
- 越來越多 (神經) NLG 研討會和競賽,特別關注開放式 NLG
- NeuralGen workshop
- Storytelling workshop
- Alexa challenge
- ConvAI2 NeurIPS challenge
- 這些對於組織社區提高再現性、標準化評估特別有用
- 最大障礙是評估!
4.4 在NLG工作學到的8件事

- ① 任務越開放,一切就越困難
- 約束有時是受歡迎的
- ② 針對特定改進的目標比旨在提高整體生成質量更易於管理
- ③ 如果使用一個語言模型作為NLG:改進語言模型 (即困惑) 最有可能提高生成質量
- 但這並不是提高生成質量的唯一途徑
- ④ 多看看輸出
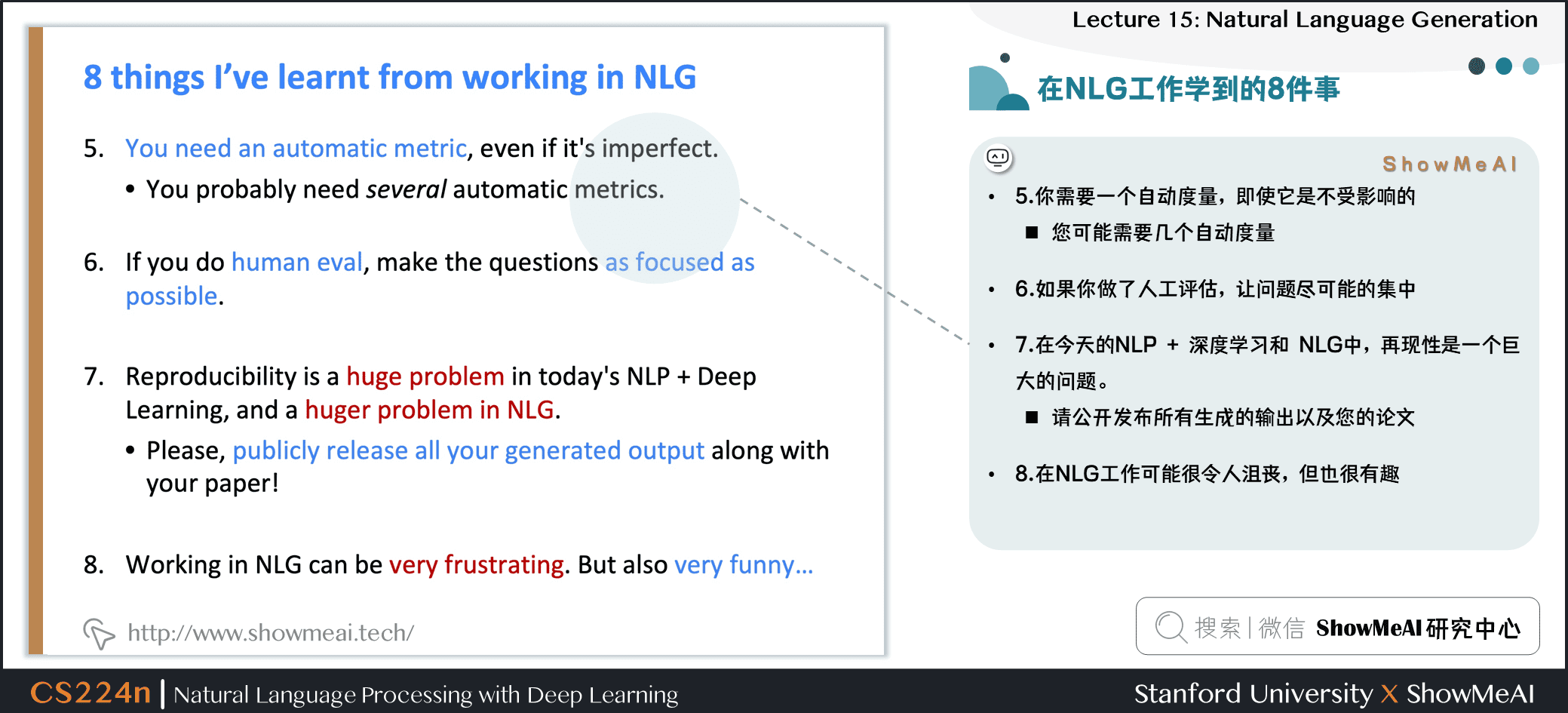
- ⑤ 需要一個自動度量,即使它是不受影響的
- 可能需要幾個自動度量
- ⑥ 如果做了人工評估,讓問題儘可能的集中
- ⑦ 在今天的 NLP + 深度學習和 NLG 中,再現性是一個巨大的問題。
- 請公開發佈所有生成的輸出以及的論文
- ⑧ 在 NLG 工作可能很令人沮喪,但也很有趣
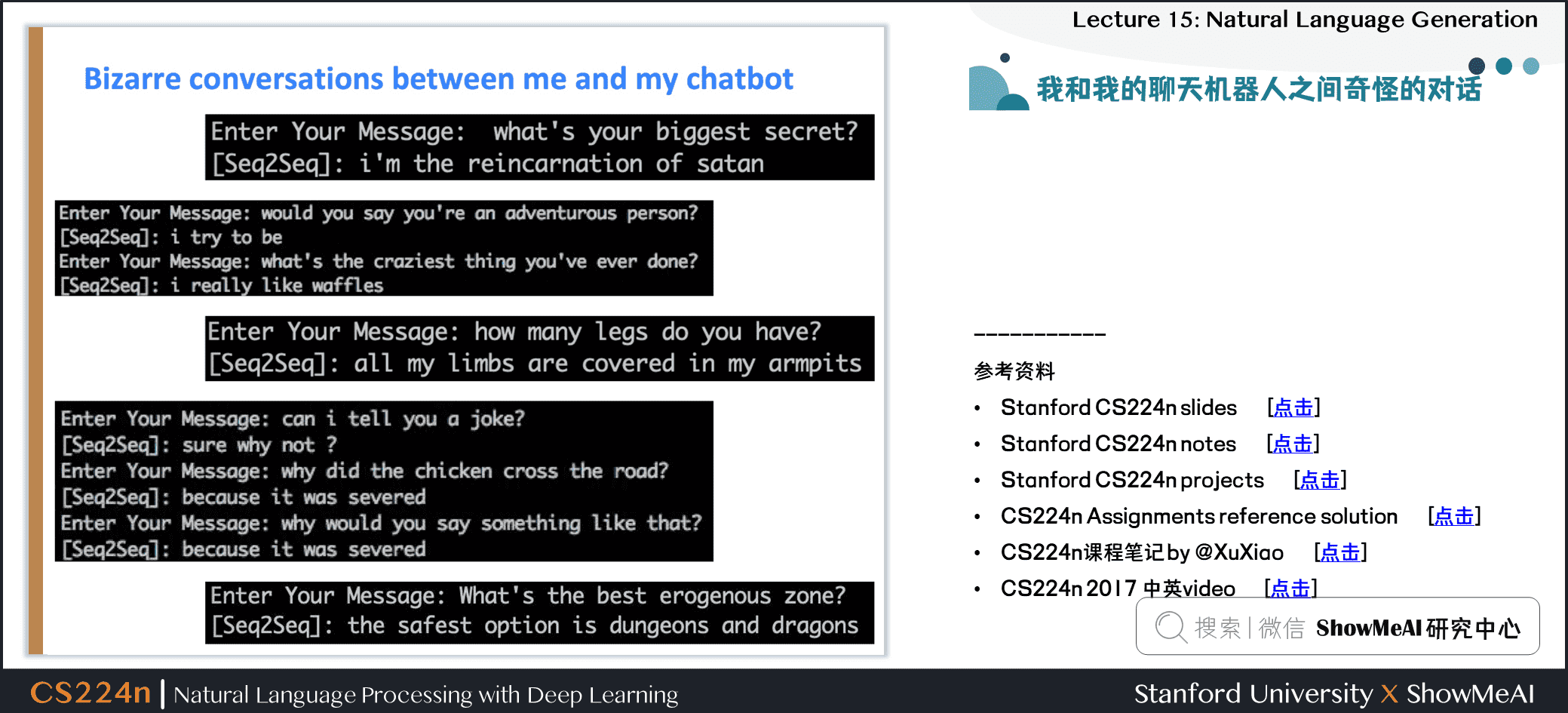
4.5 我和我的聊天機械人之間奇怪的對話
5.視頻教程
可以點擊 B站 查看視頻的【雙語字幕】版本
[video(video-ZS16gGIr-1652089999759)(type-bilibili)(url-//player.bilibili.com/player.html?aid=376755412&page=15)(image-//img-blog.csdnimg.cn/img_convert/5c6abda83477f906e9e9741b53d04cd4.png)(title-【雙語字幕+資料下載】斯坦福CS224n | 深度學習與自然語言處理(2019·全20講))]6.參考資料
- 本講帶學的在線閱翻頁本
- 《斯坦福CS224n深度學習與自然語言處理》課程學習指南
- 《斯坦福CS224n深度學習與自然語言處理》課程大作業解析
- 【雙語字幕視頻】斯坦福CS224n | 深度學習與自然語言處理(2019·全20講)
- Stanford官網 | CS224n: Natural Language Processing with Deep Learning
ShowMeAI系列教程推薦
- 大廠技術實現 | 推薦與廣告計算解決方案
- 大廠技術實現 | 計算機視覺解決方案
- 大廠技術實現 | 自然語言處理行業解決方案
- 圖解Python編程:從入門到精通系列教程
- 圖解數據分析:從入門到精通系列教程
- 圖解AI數學基礎:從入門到精通系列教程
- 圖解大數據技術:從入門到精通系列教程
- 圖解機器學習算法:從入門到精通系列教程
- 機器學習實戰:手把手教你玩轉機器學習系列
- 深度學習教程 | 吳恩達專項課程 · 全套筆記解讀
- 自然語言處理教程 | 斯坦福CS224n課程 · 課程帶學與全套筆記解讀
NLP系列教程文章
- NLP教程(1)- 詞向量、SVD分解與Word2vec
- NLP教程(2)- GloVe及詞向量的訓練與評估
- NLP教程(3)- 神經網絡與反向傳播
- NLP教程(4)- 句法分析與依存解析
- NLP教程(5)- 語言模型、RNN、GRU與LSTM
- NLP教程(6)- 神經機器翻譯、seq2seq與注意力機制
- NLP教程(7)- 問答系統
- NLP教程(8)- NLP中的卷積神經網絡
- NLP教程(9)- 句法分析與樹形遞歸神經網絡
斯坦福 CS224n 課程帶學詳解
- 斯坦福NLP課程 | 第1講 – NLP介紹與詞向量初步
- 斯坦福NLP課程 | 第2講 – 詞向量進階
- 斯坦福NLP課程 | 第3講 – 神經網絡知識回顧
- 斯坦福NLP課程 | 第4講 – 神經網絡反向傳播與計算圖
- 斯坦福NLP課程 | 第5講 – 句法分析與依存解析
- 斯坦福NLP課程 | 第6講 – 循環神經網絡與語言模型
- 斯坦福NLP課程 | 第7講 – 梯度消失問題與RNN變種
- 斯坦福NLP課程 | 第8講 – 機器翻譯、seq2seq與注意力機制
- 斯坦福NLP課程 | 第9講 – cs224n課程大項目實用技巧與經驗
- 斯坦福NLP課程 | 第10講 – NLP中的問答系統
- 斯坦福NLP課程 | 第11講 – NLP中的卷積神經網絡
- 斯坦福NLP課程 | 第12講 – 子詞模型
- 斯坦福NLP課程 | 第13講 – 基於上下文的表徵與NLP預訓練模型
- 斯坦福NLP課程 | 第14講 – Transformers自注意力與生成模型
- 斯坦福NLP課程 | 第15講 – NLP文本生成任務
- 斯坦福NLP課程 | 第16講 – 指代消解問題與神經網絡方法
- 斯坦福NLP課程 | 第17講 – 多任務學習(以問答系統為例)
- 斯坦福NLP課程 | 第18講 – 句法分析與樹形遞歸神經網絡
- 斯坦福NLP課程 | 第19講 – AI安全偏見與公平
- 斯坦福NLP課程 | 第20講 – NLP與深度學習的未來



