MySQL性能優化 – 別再只會說加索引了
MySQL性能優化
MySQL性能優化我們可以從以下四個維度考慮:硬件升級、系統配置、表結構設計、SQL語句和索引。
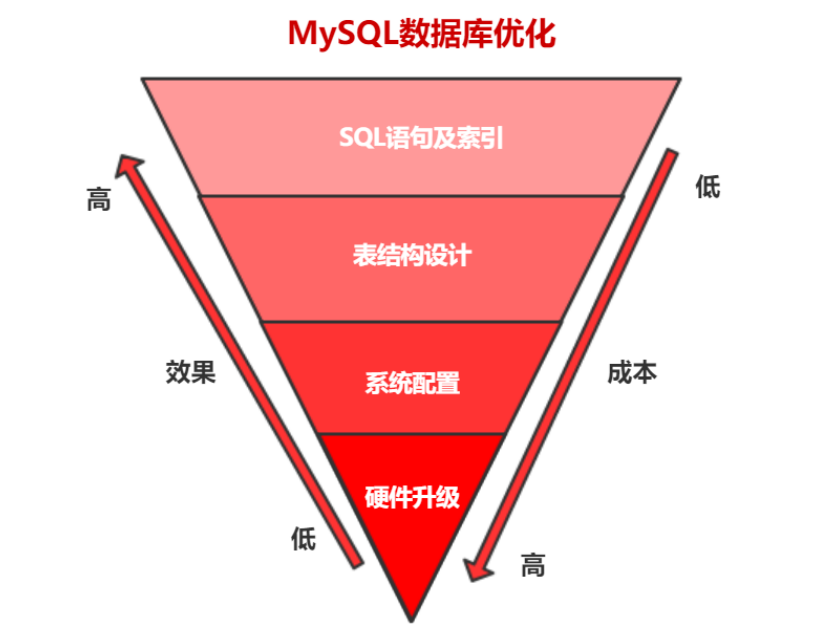
從成本上來說:硬件升級>系統配置>表結構設計>SQL語句及索引,然而效果卻是由低到高。所以我們在優化的時候還是盡量從SQL語句和索引開始入手。
硬件升級
硬件升級這裡不在過多贅述,升級更好配置的機器、機械硬盤更換為SSD等等。
系統配置優化
- 調整buffer_pool
通過調整buffer_pool使數據盡量從內存中讀取,最大限度的降低磁盤操作,這樣可以提升性能。查看buffer_pool數據的方法:
SHOW GLOBAL STATUS LIKE 'innodb_buffer_pool_page_%'
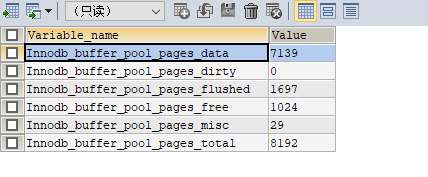
可以看出總頁數8192,空閑頁數1024。
//查看buffer_pool大小
SELECT @@innodb_buffer_pool_size/1024/1024
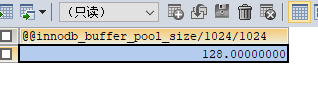
innodb_buffer_pool_size默認為128M,理論上可以擴大到內存的3/4或4/5。我們修改mysql配置文件my.cnf,增加如下配置:
innodb_buffer_pool_size = 750M
然後重啟MySQL。
2. 數據預熱
默認情況下,某條數據被讀取過一次才會被緩存在innodb_buffer_pool里。所以數據庫剛剛啟動,可以進行一次數據預熱,將磁盤上的數據緩存到內存中去。
預熱腳本:
SELECT DISTINCT
CONCAT('SELECT ',ndxcollist,' FROM ',db,'.',tb,
' ORDER BY ',ndxcollist,';') SelectQueryToLoadCache
FROM
(
SELECT
engine,table_schema db,table_name tb,
index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index)
ndxcollist
FROM
(
SELECT
B.engine,A.table_schema,A.table_name,
A.index_name,A.column_name,A.seq_in_index
FROM
information_schema.statistics A INNER JOIN
(
SELECT engine,table_schema,table_name
FROM information_schema.tables WHERE
engine='InnoDB'
) B USING (table_schema,table_name)
WHERE B.table_schema NOT IN ('information_schema','mysql')
ORDER BY table_schema,table_name,index_name,seq_in_index
) A
GROUP BY table_schema,table_name,index_name
) AA
ORDER BY db,tb;
將腳本保存為:loadtomem.sql
執行命令:
mysql -uroot -p -AN < /root/loadtomem.sql > /root/loadtomem.sql
在需要進行數據預熱時就執行下面的命令:
mysql -uroot < /root/loadtomem.sql > /dev/null 2>&1
- 降低日誌的磁盤落盤
- 增大redolog,減少落盤次數,innodb_log_file_size設置為0.25 * innodb_buffer_pool_size
- 通用查詢日誌、慢查詢日誌可以不開,bin-log要開,慢日誌查詢可以遇到性能問題再開
- 寫redolog策略 調整innodb_flush_log_at_trx_commit參數為0或2。當然涉及安全性非常高的系統(金融等)還是保持默認的就行。
在配置文件里加上 innodb_flush_log_at_trx_commit =2 即可。
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit'
表結構設計優化
- 設計中間表
設計中間表,一般針對於統計分析功能
2. 設計冗餘字段
為減少關聯查詢,創建合理的冗餘字段
3. 拆表
對於字段太多的大表,考慮拆表;對於表中經常不被使用的字段或存儲數據比較多的字段,考慮拆表
4. 主鍵優化
主鍵類型最好是int類型,建議自增主鍵(分佈式系統下用雪花算法)
5. 字段的設計
- 字段的寬度設得儘可能的小。
- 盡量把字段設置為NOT NULL
- 對於某些文本字段,如省份、性別等,我們可以把他們定義為enum類型。在mysql里enum類型被當作數值類型數據來處理,而數值型數據處理起來比文本類型快得多。
SQL語句及索引優化
- 學會用explain分析
- SQL語句中IN包含的值不應太多
MySQL對IN做了一些優化,將IN中的常量去不存在一個數組裡,而且會進行排序。如果數值較多,這些步驟消耗也是比較大的。
3. SELECT 語句務必指明字段名稱
SELECT * 增加了很多不必要的消耗(CPU、IO、內存、網絡帶寬)
4. 當只需要一條數據時,使用limit
5. 排序字段加索引
6. 如果查詢條件中其他字段沒有索引,少用or
or兩邊的字段中,如果有一個不是索引字段,則會造成該查詢都不會走索引的情況。
select * from tbiguser where nickname='zy1' or loginname='zhaoyun3';
如nickname是索引字段,loginname不是索引字段,則整體不會走索引。可以用union all代替
7. 盡量用union all代替union
union和union all的區別是,union需要將結果集合併再進行唯一性過濾操作,這就會涉及到排序,增加了大量的CPU運算。當然,使用union all的前提條件是兩個結果集沒有重複數據。
8. 區分in和exists、not in和not exists
- exists:以外表為驅動表,先被訪問。適合外表小而內表大的情況
- in:先執行子查詢。適合外表大而內表小的情況
關於not in和not exists,推薦使用not exists,不僅僅是效率問題,not in可能存在邏輯問題。如何高效的寫出一個替代not exists的SQL語句?
原語句:
select colname … from A表 where a.id not in (select b.id from B表)
優化後的語句:
select colname … from A表 Left join B表 on where a.id = b.id where b.id is null
- 不建議使用%前綴模糊查詢,不會走索引
- 避免在where子句中對字段進行表達式或函數操作
- 避免隱式類型轉換 如where age=’18’,如果確定是int類型,應寫為where age = 18;
- 對於聯合索引,要遵守最左前綴法則
舉例來說索引含有字段id、name、school,可以直接用id字段,也可以id、name這樣的順序,但是name;school都無法使用這個索引。所以在創建聯合索引的時候一定要注意索引字段順序,常用的查詢字段放在最前面。
13. 必要時可以使用force index來強制查詢使用某個索引
14. 注意範圍查詢語句
對於聯合索引來說,如果存在範圍查詢,比如between,>,<等條件時,會造成後面的索引字段失效
15. 使用JOIN優化
LEFT JOIN里左邊的表為驅動表,RIGHT JOIN里右邊的表為驅動表,而INNER JOIN MySQL會自動找出數據少的表為驅動表
注意:
- MySQL沒有full join,可以用以下方式解決
select * from A left join B on B.name = A.name where B.name is null union all
select * from B;
- 盡量用inner join,避免left join
- 合理利用索引字段作為on的限制字段
- 利用小表去驅動大表
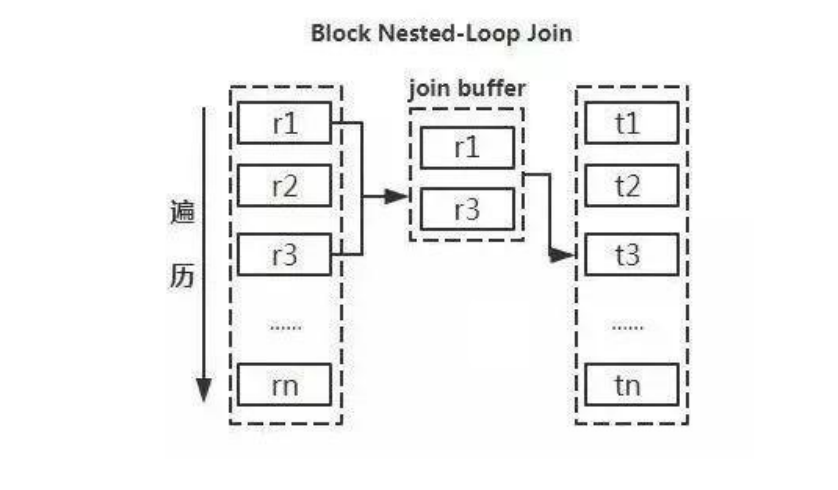
下圖是join查詢的原理圖,從圖中可以看出如果能夠減少驅動表的話,就能減少嵌套循環中的次數,以減少IO總量及CPU運算的次數。
SQL優化實戰案例
介紹:tbiguser表有10000000條記錄,表結構如下:
create table tbiguser(
id int primary key auto_increment,
nickname varchar(255),
loginname varchar(255),
age int ,
sex char(1),
status int,
address varchar(255)
);
創建存儲過程,並執行,插入一千萬條數據
CREATE PROCEDURE test_insert()
BEGIN DECLARE i INT DEFAULT 1;
WHILE i<=10000000
DO
insert into tbiguser
VALUES(null,concat('zy',i),concat('zhaoyun',i),23,'1',1,'beijing'); SET i=i+1;
END WHILE ;
commit;
END;
call test_insert
還有tuser1表和tuser2表,兩個表結構一致。
create table tuser1(
id int primary key auto_increment,
name varchar(255),
address varchar(255)
);
create table tuser2(
id int primary key auto_increment,
name varchar(255),
address varchar(255)
);

需求:tbiguser表按照地區分組統計求和,並且要求是在tuser1表和tuser2表中出現過的地區。
按照需求寫出SQL:
SELECT COUNT(*) num,address FROM tbiguser WHERE address IN (SELECT address FROM tuser1)
GROUP BY address
UNION
SELECT COUNT(*) num,address FROM tbiguser WHERE address IN (SELECT address FROM tuser2)
GROUP BY address
執行時間:4.65s
第一次優化:
加索引。我們可以給address字段加索引。
ALTER TABLE tuser1 ADD INDEX idx_address(address);
ALTER TABLE tuser2 ADD INDEX idx_address(address);
ALTER TABLE tbiguser ADD INDEX idx_address(address);
執行時間0.9s
我們用explain分析sql

發現有兩次都掃描了964147行,就是tbiguser這個大表掃描了兩次。且有臨時表使用。於是我們進行優化
第二次優化
SELECT COUNT(*) num,address FROM tbiguser WHERE address IN (SELECT address FROM tuser1) OR address IN (SELECT address FROM tuser2)
GROUP BY address
執行時間0.65s

沒有臨時表了,大表也只掃描了一次。
另外我嘗試這樣查詢:
SELECT COUNT(*) num,address FROM tbiguser WHERE address IN (SELECT address FROM tuser1 UNION ALL SELECT address FROM tuser2)
GROUP BY address
執行時間12s。
SELECT COUNT(x.id),x.address
FROM
(SELECT DISTINCT b.* FROM tuser1 a,tbiguser b WHERE a.address=b.address UNION
ALL SELECT DISTINCT b.* FROM tuser2 a,tbiguser b WHERE a.address=b.address) X
GROUP BY x.address;
執行時間5.8s
根據實踐發現,sql查詢優化沒有定式,不同的數據量下相同的sql表現是不一樣的,需要靈活運用。


