數據結構篇_知識點板塊_第七章查找
數據結構篇為本人考研時所寫筆記,包括知識點和編程思想兩大板塊,筆記內容依據王道數據結構考研書所寫,但比書本上知識更加生動形象,願本篇章能對您有所幫助
七、查找
(一)基本查找方法
- 基本概念:
① 查找表(又稱查找結構):用於查找的數據集合
② 靜態查找表(順序查找,折半查找,分塊查找):不需要進行動態插入或刪除的查找表
③ 動態查找表(二叉排序樹,二叉平衡樹,B-,B+):與上反之(不要被動態靜態誤導了,並不是鏈表和順序表的意思)
④ 關鍵字:數據元素中唯一標識該元素的某個數據項的值,基於關鍵字查找結果是唯一的
⑤ 一次查找長度:需要比較的關鍵字次數
⑥ 平均查找長度(ASL):所有查找過程中進行關鍵字比較次數的平均值
- 一般線性表順序查找:
① 哨兵:將值a賦給查找表中最後一個元素,則在for循環中中間判斷條件是判斷是否等於a而不必判斷數組是否會越界
② 哨兵好處:避免很多不必要的判斷語句,從而提高程序的效率
③ ASL:
(1) 查找成功時平均長度:
(2) 查找成功時平均長度(等概率時):ASL=(n+1)/2
(3) 查找不成功時平均長度:n+1
④ 注意對線性的鏈表只能進行順序查找
⑤ 順序表查找指的是在順序存儲結構上進行查找(錯)(順序存儲指的就是數組之的數據結構,但是 順序表並不一定是用數組實現的,例如鏈表即也可在鏈式存儲結構上實現)
- 有序線性表順序查找(一般線性表順序查找的一種優化):
① 概念:查找之前知道表的關鍵字(數值)是有序的
② 有序線性表的判定樹:
(1) 樹中圓形結點:有序線性表中存在的元素
(2) 樹中矩形結點:失敗結點;若有n個結點,則相應有n+1個查找失敗結點(即類似於二叉數查找失敗時所畫的空結點)

③ 時間複雜度:O(n)
④ ASL:
(1) 查找成功時平均長度與一般線性表一樣
(2) 查找不成功時平均長度(等概率時):n/2 + n/(n+1)(到達失敗結點的長度等於父結點所在層數)
-
一般線性表順序查找的另一種優化:當被查概率不等時把被查概率大的放在靠前的位置(類似於哈夫曼編碼的思想),但這會時ASL_不成功增大,故怎麼優化還應依情況而定
-
折半查找(二分查找):
① 折半查找判定樹(二叉數):
(1) 判定樹:將折半查找過程用二叉樹來描述(折半查找的性能分析可以用二叉判定樹來衡量)
(2) 判定樹是一顆平衡二叉樹

(3) 圓形結點:表示一個記錄
(4) 結點中的值:該記錄的關鍵字值
(5) 方形結點:樹最下面的葉結點,表示查找不成功的情況
(6) 查找成功時:查找長度為根節點到目標結點
查找失敗時:查找長度為根節點到對應失敗結點的父結點
(7) 左結點值<根值<右結點值(同二叉排序樹)
(8) 若有序序列有n個元素,則對應判定樹有n個圓形非葉結點和n+1個方形葉結點
(9) 注意:
(1 當向下取整(mid=(low+high)/2):判定樹必須右子樹結點數-左子樹結點數=0/1
(2 當向上取整(mid=(low+high)/2):判定樹必須左子樹結點數-右子樹結點數=0/1(考試時看清是向上還是向下取整)
(10) 在查找不成功時和給定值進行關鍵字的比較次數最多為樹的高度
② 要求必須是順序存儲結構且元素按關鍵字有序排列
③ 時間複雜度:O(log_2 n)
④ ASL:
(1) 查找成功時:
(h不包括失敗結點)
-
K分查找:

-
分塊查找(索引順序查找):

① 基本思想:將查找表分為若千子塊。塊內的元素可以無序,但塊之間是有序的,即第一個塊中的最大關鍵字小於第二個塊中的所有記錄的關鍵字,第二個塊中的最大關鍵字小於第三個塊中的所有記錄的關鍵字,以此類推。再建立一個索引表,索引表中的每個元素含有各塊的最大關鍵字和各塊中的第一個元素的地址,索引表按關鍵字有序排列
② 分塊查找的過程分為兩步:
(1) 第一步是在索引表中確定待查記錄所在的塊,可以順序查找或折半查找索引表
(2) 第二步是在塊內順序查找(因為可能無序故只能順序查找)
③ ASL:
(1) ASL=索引查找平均長度(L_I)+塊內查找平均長度(L_S)
(2) 長度為n的查找表均勻地分為b塊,每塊有s個記錄:
(1 等概率都使用順序查找:
(若s=
,則min(ASL)=
+1(求導取極值得出的))
(2 索引表用折半查找:
(3 當都用折半查找時效率最高,具體數據看題(時間效率介於順序查找和二分查找之間)
- 若查找表是動態表,則一般用鏈式存儲較方便
| 優點 | 缺點 | 適用於 | |
|---|---|---|---|
| 一般線性表順序查找有序表的順序查找 | ① 對數據元素存儲和表中記錄的有序性沒要求② 順序存儲或鏈式存儲皆可 | 當數值較多時,平均查找長度大 | 長度較小的表和查找較少但改動較多的表 |
| 折半查找 | 查找效率高 | 要求必須是順序存儲結構且元素按關鍵字有序排列 | 一經建立就很少改動又經常需要查找的線性表 |
| 分塊查找 | ① 在表中插入或刪除記錄時只要在該記錄所屬塊內操作② 塊內記錄存放隨意故易插入和刪除 | 要增加一個輔助數組的存儲空間 | 有分塊特點的記錄(如學生登記表可按系號分塊) |
(二)B樹(多路平衡查找樹)和B+樹
考前結合王道選擇看一下
1)B樹
-
階:B樹(可以為空樹)中所有結點的孩子個數最大值
-
B樹為滿足下列特性的m叉樹:
① 樹中每個結點至多有m棵子樹,即至多含有m-1個關鍵字。
② 若根結點不是終端結點,則至少有兩棵子樹(保證絕對平衡,即沒高度差)
③ 除根結點外的所有非葉結點至少有向上取整(m/2)棵子樹,即至少含有向上取整(m/2)-1個關鍵字
④ 綜上:
(1) 根結點的子樹數∈[2,m]
(2) 關鍵字數∈[1,m-1]
(3) 其他結點的子樹數∈[向下取整(m/2),m]
(4) 關鍵字數∈[向下取整(m/2)-1,m-1]
⑤ 結點中的關鍵字是有序的,且結點滿足:子樹0<關鍵字1<子樹1<關鍵字2…(即左結點值<根值<右結點值)
⑥ 所有的葉結點都出現在同一層次上,並且不帶信息(可以視為外部結點或類似於折半查找判定樹的杳找失敗結點,實際上這些結點不存在,指向這些結點的指針為空)
⑦ 對於任一結點,所有子樹高度都相同
⑧ n個關鍵字的B樹必有n+1個葉子結點
⑨ 綜上所述B樹是所有結點的平衡因子均等於0的多路平衡查找樹,與③都是為了保證查找效率

(外部結點又稱葉子結點/失敗結點,外部結點上面一層的結點又稱終端結點)
-
計算B樹高度時應注意是否包括最後的葉子結點
-
對於n>=1,包含n個關鍵字,高度為h,階數為m的B樹:
① 
② 

2)B+樹
- B+樹需滿足以下條件:
① 每個分支結點最多有m棵子樹(孩子結點)
② 非葉根結點至少有兩棵子樹,其他每個分支結點至少有向下取整(m/2)棵子樹
③ 結點的子樹個數與關鍵字個數相等
④ 所有葉結點包含全部關鍵字及指向相應記錄的指針,葉結點中將關鍵字按大小順序排列並且相鄰葉結點按大小順序相互鏈接起來
⑤ 所有分支結點(可視為索引的索引)中僅包含它的各個子結點(即下一級的索引塊)中關鍵字的最大值及指向其子結點的指針
- 無論查找成功與否,每次查找都是一條從根結點到葉結點的路徑(即都要走到最小面),因為只有底層結點才包含信息,故對於B+樹而言只有查找到最下面一層結點才是成功的
| B樹與B+樹主要差別 | ||
|---|---|---|
| m階B樹 | m階B+樹 | |
| 類比 | 二叉查找樹的進化–>m叉查找樹 | 分塊查找的進化–>多級分塊查找 |
| 關鍵字與分叉 | n個關鍵字對應n+1個分叉(子樹) | n個關鍵字對應n個分叉 |
| 結點包含的信息 | 所有結點中都包含記錄的信息 | n個關鍵字對應n個分叉只有最下層葉子結點才包含記錄的信息(可使樹更矮) |
| 查找方式 | 不支持順序查找。查找成功時,可能停在任何一層結點,查找速度「不穩定」 | 支持順序查找。查找成功或失敗都會到達最下一層結點,查找速度「穩定」 |
| 相同點 | 除根節點外,最少向下取整(m/2)個分叉(確保結點不要太空)任何一個結點的子樹都要一樣高(確保「絕對平衡”) |
3)B-樹(多路平衡查找樹)
- 適合在磁盤等直接存取設備上組織動態的查找表
(三)散列表
-
典型的空間換時間的算法
-
基本概念:
① 散列函數(又稱哈希函數):一個把查找表中的關鍵字映射成該關鍵字對應的地址的函數
② 散列表(又稱哈希表):根據關鍵字而直接進行訪問的數據結構(散列表建立了關鍵字和存儲地址之間的一種直接映射關係)
③ 衝突:當兩個或兩個以上不同關鍵字映射到同一地址(解決衝突的常用方法是:線性探測法,多重散列法,鏈地址法)
④ 衝突解決技術可以分為兩類:開散列方法(也稱為拉鏈法/鏈地址法)和閉散列方法(也稱為開地址方法)。這兩種方法的不同之處在於:開散列法把發生衝突的關鍵碼存儲在散列表主表之外,而閉散列法把發生衝突的關鍵碼存儲在表中另一個槽內
⑤ 線性探測是出現衝突後開始向後探測一個位置,所以從第二個關鍵字若和第一個衝突時映射時要做1次探測
⑥ 同義詞:發現碰撞的不同關鍵字
-
時間複雜度(理想情況):O(1)(哈希表的查找效率主要取決於哈希表造表時所選取的哈希函數和處理衝突的方法)
-
散列表和索引表的區別:
(1) 散列存儲是直接將關鍵字的值做一個映射到存儲地址
(2) 索引存儲則是另外使用關鍵字來構建一個索引表
A. 散列函數的構造
- 構造散列函數需注意:
① 散列函數的定義域必須包含全部需要存儲的關鍵字,而值域的範圍則依賴於散列表的大小或地址範圍。
② 散列函數計算出來的地址應該能等概率、均勻地分佈在整個地址空間中,從而減少衝突的發生
③ 散列函數應盡量簡單,能夠在較短的時間內計算出任一關鍵字對應的散列地址
-
散列函數選擇兩條標準:簡單和均勻
-
一些函數分析:
①  :不能當作散列函數,因為該函數的返回值不確定,這樣無法進行正常的查找(並不是隨機就是好)
:不能當作散列函數,因為該函數的返回值不確定,這樣無法進行正常的查找(並不是隨機就是好)
②  :能夠作為散列函數,但不是一個好的散列函數,因為所有關鍵字都映射到同一位置,造成大量的衝突機會。
:能夠作為散列函數,但不是一個好的散列函數,因為所有關鍵字都映射到同一位置,造成大量的衝突機會。
a. 直接地址法
-
直接取關鍵字的某個線性函數值為散列地址,散列函數為
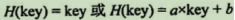
-
適合關鍵字的分佈基本連續的情況;若關鍵字分佈不連續,空位較多,則會造成存儲空間的浪費
b. 除數餘數法
-
一般取不大於表長但最接近或等於表長的質數p(又稱素數(不能被除自身和1外的數整除)(合數是指在大於1的整數中除了能被1和本身整除外,還能被其他數(0除外)整除的數。與之相對的是質數,而1既不屬於質數也不屬於合數)),散列函數為
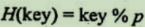
-
此方法關鍵是取好P
c. 數字分析法
-
設關鍵字是r進制數(如十進制數),而r個數碼在各位上出現的頻率不一定相同,可能在某些位上分佈均勻一些,每種數碼出現的機會均等:而在某些位上分佈不均勻,只有某幾種數碼經常出現,此時應選取數碼分佈較為均勻的若干位作為散列地址
-
這種方法適合於己知的關鍵字集合,若更換了關鍵字,則需要重新構造新的散列函數
d. 平方取中法
-
取關鍵字的平方值的中間幾位作為散列地址,具體取幾位視情況而定
-
適合用於數據量過大的情況
B. 處理衝突方法
- 要完全(不是安全)避免衝突需滿足:
① 關鍵字集合U不大於散列表長m
② 選擇合適的散列函數(例如選擇
就不合適)
a. 開放地址法
-
數學遞推公式:

( )
) -
di一般有四種取法:

 )
)① di中i表示當前元素H(key)衝突後依次H(key)+di(從0開始)比較後的衝突次數,如若分別與H(key)+0、1、-1位置衝突共衝突三次則下一次即為H(key)+d3=H(key)+4(以平方探測法為例)
② 線性探測法:
(1) di=0,1,2…
(2) 空位置的判斷也要算成一次比較
(3) 缺點:易造成大量元素的散列地址「聚集」(或堆積(由同義詞之間或非同義詞之間發生衝突(不是僅同義詞之間)))(對存儲效率、散列函數、裝填因子均不會有影響,但會直接影響平均查找長度)起來,減低查找效率
(4) 
③ 平方探測法(二次探測法):(2021考了)
(1) di=0,1,-1,4,-4…
(2) 
④ 再散列法(雙散列法、再哈希法)
(1) 除了原始散列函數H(key)外,多準備幾個散列函數,當散列函數衝突時,用下一個散列函數計算一個新地址,直到不衝突為止
⑤ 偽隨機序列法:
(1) di=偽隨機序列
- 注意:在開放定址的情形下,不能隨便物理刪除表中的已有元素,因為若刪除元素,則會截斷其他具有相同散列地址的元素的查找地址。因此,要刪除一個元素時,可給它做一個刪除標記,進行邏輯刪除。但這樣做的副作用是:執行多次刪除後,表面上看起來散列表很滿,實際上有許多位置未利用,因此需要定期維護散列表,要把刪除標記的元素物理刪除。
b. 拉鏈法(鏈接法,chaining)
-
將所有同義詞存儲在一個線性鏈表中,這個線性鏈表由其散列地址唯一標識
-
適用於經常進行插入和刪除的情況
-
若限定在鏈首插入,則插入任一個元素的時間是相同的
-

-
注意:有的教材會把「空指針」的判斷算作一次比較,具體參考真題是怎麼計算的

| 開放地址法和拉鏈法比較 | ||
|---|---|---|
| 開放地址法 | 拉鏈法 | |
| 放置位置 | 將所有結點均存放在散列中 | 將互為同義詞的結點鏈成一個單鏈表,而將此表的頭指針放在散列表中(所以拉鏈法的圖結點不在散列表中) |
| 優點 | 拉鏈法相比較下的優點:① 簡單無堆積② 動態申請表長③ 空間可節省(α可大於1(開放地址法為減少衝突要求α較小)) | |
| 缺點 | 拉鏈法缺點:① 當結點規模較小時,指針域要佔用額外空間,此時還是開放地址法省空間 |
C.散列查找及性能分析
-
散列表的查找效率取決於三個因素:散列函數、處理衝突的方法和裝填因子
-
裝填因子(一般記為α):定義一個表的裝滿程度(
 )
) -
散列表的平均查找長度依賴於散列表的裝填因子α,而不直接依賴於n或m
-
α越大,表示裝填的記錄越「滿」,發生衝突的可能性越大,反之發生衝突的可能性越小
 )
)(四)ASL綜述
- 設一個查找集合中已有n個數據元素,每個元素的查找概率為p_i,查找成功的數據比較次數為G (i=1, 2,…, n);不在此集合中的數據元素分佈在由這n個元素的間隔構成的n+1個子集合內,每個子集合元素的查找概率為q_j,查找不成功的數據比較次數為c_j(j=0, 1,…,n)。因此,對某一特定查找算法的查找成功的ASL和查找失敗的ASL,是綜合考慮還是分開考慮呢?
答:
-
上述兩種考慮的計算結果是不同的,考試中一定要仔細閱讀題目的要求,以免失誤
-
散列表平均查找成功長度除以排序個數,平均查找失敗長度除以散列表長度


