[報告] Microsoft :Application of deep learning methods in speech enhancement
Application of deep learning methods in speech enhancement
語音增強中的深度學習應用
按:
本文是DNS,AEC,PLC等國際級語音競賽的主辦方——Microsoft Research Labs音頻與聲學研究組(Audio and Acoustics Research Group)於2021年發表的Sound capture and speech enhancement for speech-enabled devices中節選的一章,總結了該組今年來在語音增強領域的工作。該報告的作者為Ivan Tashev和Sebastian Braun。本篇所有圖片均源自該報告及其引文。
1. (基於時頻域監督學習的)語音增強模塊
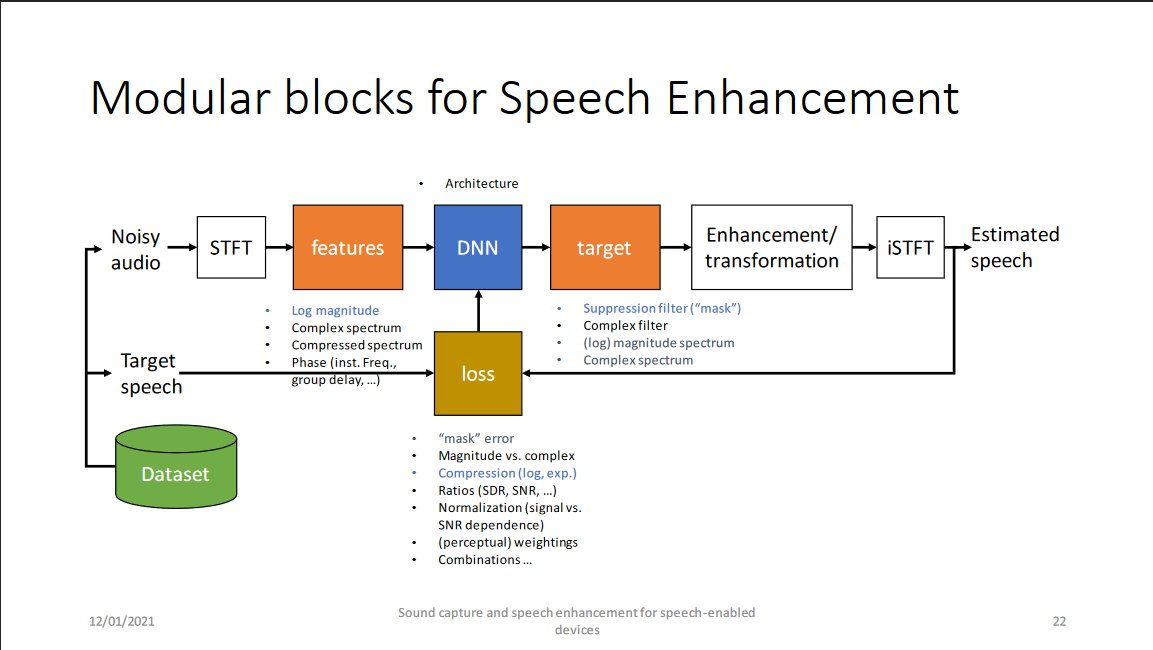
該模塊主要展示了時頻域語音增強的流程,包括短時傅里葉變換(STFT)、特徵提取、神經網絡、預測目標、增強/變換(過程)、短時傅里葉反變換(iSTFT)和損失函數幾部分。其中自圖中第二行開始只在訓練階段進行,本圖建議與該組之前的一篇工作中的圖(見下圖)結合使用。
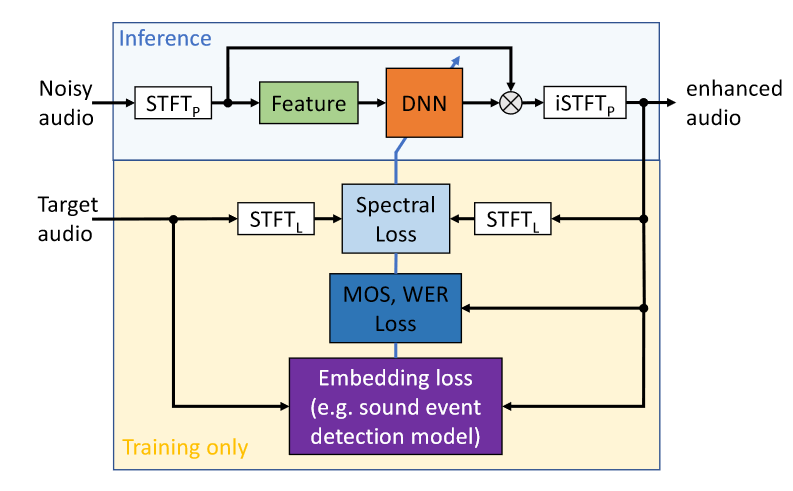
這裡主要有以下幾點可以討論:
- STFT: 由於噪聲模態的多樣性導致語音增強任務天然與語音分離任務有區別,利用傅里葉變換基函數將噪聲和語音成分變換到特定的空間中區分模式可能更利於網絡的訓練和魯棒性;此外,由於混響情況下時域算法的劣勢以及陣列增強中可能的與傳統波束形成技術的級聯;當然還有從傳統語音增強技術中發展而來的習慣;還有最最重要地,目前DNS Challenge的比賽結果。儘管有一些如demucs等優秀的基於時域的語音增強算法,基於時頻域的語音增強算法可能更具優勢(tips:此處為個人見解)。
- 特徵提取:特徵提取部分除了直接的複數譜和幅度譜,微軟特別提到了對數功率譜和(冪律)壓縮複數譜,在說明這兩個特徵之前,需要說明請注意在報告中預測目標並沒有對應的對數幅度譜或者壓縮複數譜,而是原始STFT域的譜或掩蔽,這點與之前網絡輸出與輸入對應的一些文獻是有區別的,其想表達的是輸入經過壓縮變換(不論是對數壓縮還是指數壓縮)的特徵將有助於系統性能。
這裡簡要說明一下對數功率譜和(冪律)壓縮複數譜,其中對數幅度譜的使用見於該組的這篇和這篇,定義為\(P = log10(|X(k, n)|^2)\)P = torch.log10(torch.norm(x_stft, dim=-1) + 1e-9);
而冪律壓縮複數譜可參考這篇,定義為\(X_{cprs}=\frac{X(k,n)}{|X(k,n)|}|X(k,n)|^{c}\)x_mag = torch.norm(x_stft, dim=-1) + 1e-9 x_cprs_mag = x_mag ** c x_cprs = torch.stack((x_stft[..., 0] / x_mag * x_cprs_mag, x_stft[..., 1] / x_mag * x_cprs_mag), dim=-1) - 損失函數:報告中推薦的是壓縮譜損失,其他損失包括mask的距離、能量損失(SDR/SI-SDR)、譜距離、感知加權損失和(以上幾項或以上幾項和其他項的)聯合損失。
損失函數分別定義和測評在文獻和文獻中,其中一部分見下圖
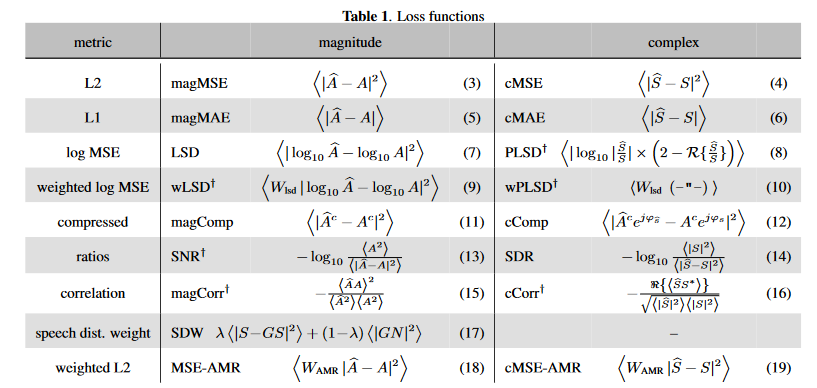
推測壓縮譜損失推薦的是幅度正則的壓縮譜損失(Magnitude-regularized compressed spectral loss):\(\mathcal{L}=\frac{1}{\sigma_S^{c}}(\lambda\sum_{k,n}{|S^c-\widehat{S}^c|^2+(1-\lambda\sum_{k,n}{||S|^c-|\widehat{S}|^c|^2})})\),其中\(\sigma_S\)是純凈語音有聲段的能量,壓縮譜的操作與上文定義一致,\(c\)和\(\lambda\)微軟推薦都為0.3。

2. 訓練數據的生成與增廣
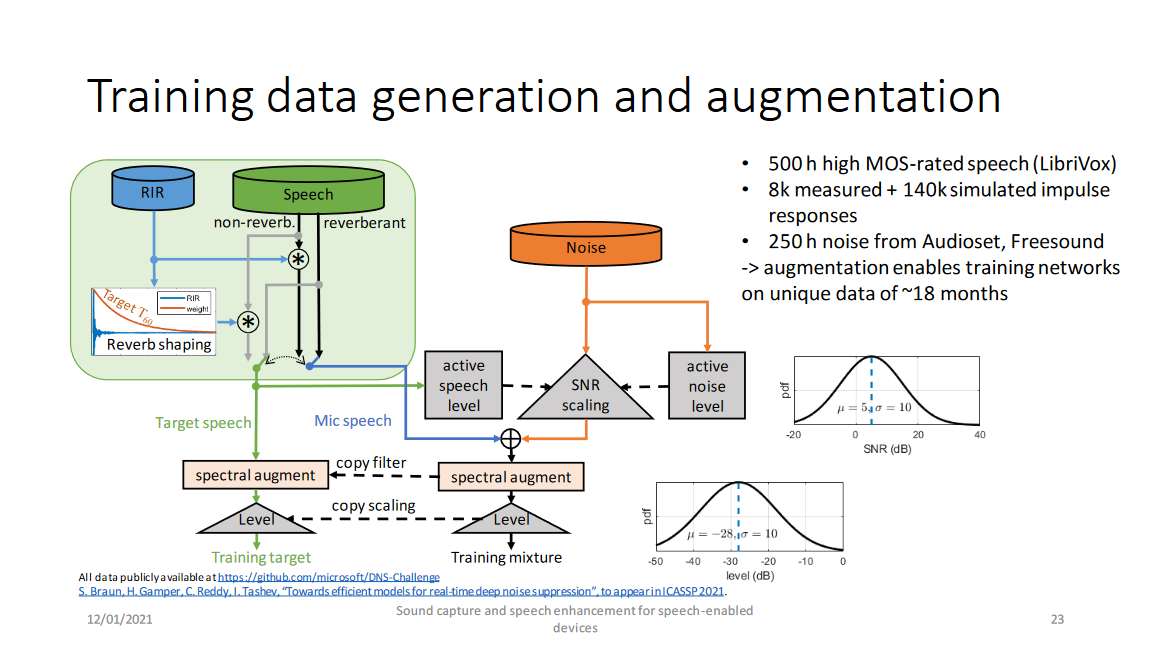
微軟推薦的數據生成方式如上圖,先不考慮混響情況,純凈語音和噪聲分別計算其能量,根據信噪比混合得到帶噪數據,而後<帶噪數據,純凈語音>用相同的濾波器進行譜增廣,最後調節語音音量的動態範圍。需要注意的是:
- 純凈語音要進行清洗,選擇MOS高的,排除「臟」數據
- 每條預料要足夠長(微軟推薦10s一句,根據其測評在其模型、特徵和loss下至少應長於5s,當條件改變句子最短長度也可能變化)
- 該報告推薦的信噪比按均值5 dB,方差10 dB的高斯分佈隨機選取
- 該報告推薦的dBFS音量增廣按均值-28 dB,方差10 dB的高斯分佈隨機選取
- 譜增廣是指RNNoise中使用的濾波器:\(H(z)=\frac{1+r_1z^{-1}+r_2z^{-2}}{1+r_3z^{-1}+r_4z^{-2}}\),其中\(r_i\sim\mathcal{U}(-\frac{3}{8},\frac{3}{8})\)。但是該報告引用文獻中指出由於數據量重足,譜增廣是不必要的
最後考慮混響情況(圖中綠色區域):和其他文章一樣,房間衝激響應(RIR)卷積純凈語音得到混響語音。而為了使語音聽起來自然,目標語音仍帶少量混響,具體的實現上是令語音與經加權函數加權的RIR卷積,其中加權函數的定位為:\(w_{RIR}(t)=exp(-(t-t_0)\frac{6log(10)}{0.3}), if\quad t \ge t_0,(otherwise\quad w_{RIR}(t)=1)\)
3. 有效的網絡架構
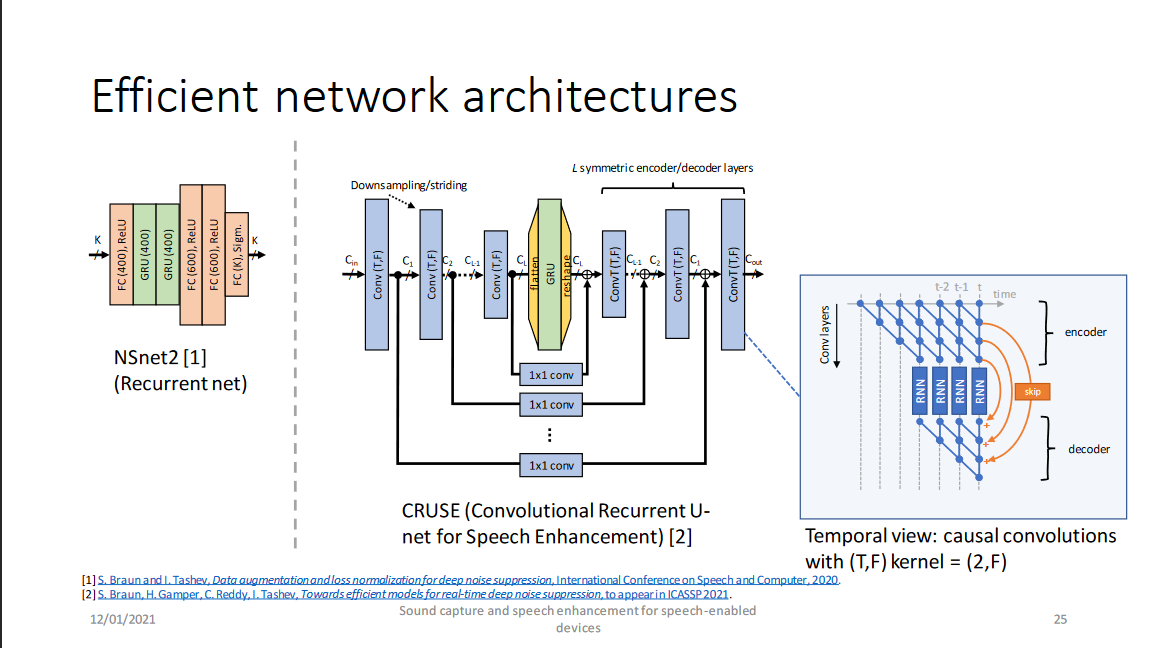
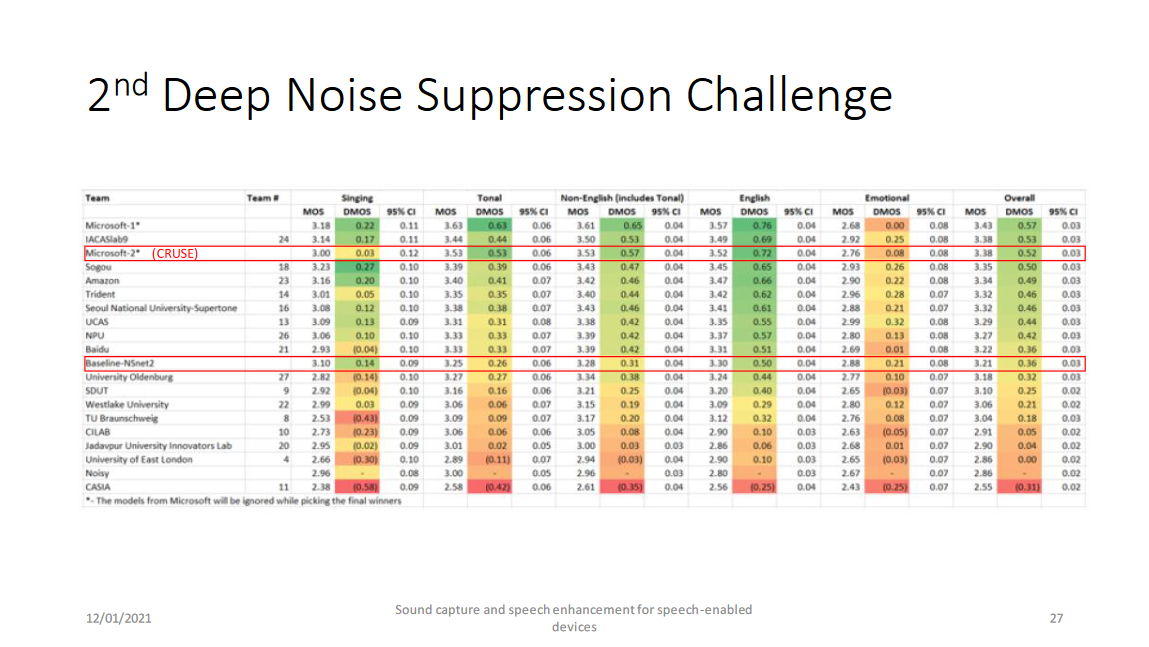
微軟提供了兩個網絡架構,分別為NSNet2(DNS Challenge的baseline)和CRUSE(DNS Challenge中微軟提交的比賽方案Microsoft-2)。
以上兩個網絡分別是RNNoise(by Valin)-style的幅度譜域模型和GCRN(by Tan)-style的複數譜域模型,RNNoise和GCRN將在之後的博客中將進行詳細介紹,這兩個網絡的介紹請參見博客和博客中介紹。最後是他們的結果: