帶你了解極具彈性的Spark架構的原理
摘要:相比MapReduce僵化的Map與Reduce分階段計算相比,Spark的計算框架更加富有彈性和靈活性,運行性能更佳。
本文分享自華為雲社區《Spark架構原理》,作者:JavaEdge。
相比MapReduce僵化的Map與Reduce分階段計算相比,Spark的計算框架更加富有彈性和靈活性,運行性能更佳。
Spark的計算階段
- MapReduce一個應用一次只運行一個map和一個reduce
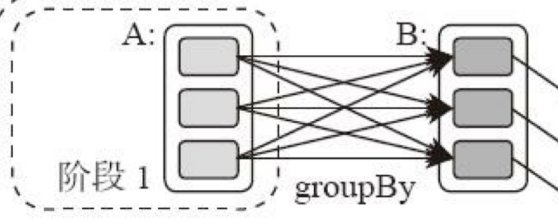
- Spark可根據應用的複雜度,分割成更多的計算階段(stage),組成一個有向無環圖DAG,Spark任務調度器可根據DAG的依賴關係執行計算階段
邏輯回歸機器學習性能Spark比MapReduce快100多倍。因為某些機器學習算法可能需要進行大量迭代計算,產生數萬個計算階段,這些計算階段在一個應用中處理完成,而不是像MapReduce那樣需要啟動數萬個應用,因此運行效率極高。
DAG,有向無環圖,不同階段的依賴關係是有向的,計算過程只能沿依賴關係方向執行,被依賴的階段執行完成前,依賴的階段不能開始執行。該依賴關係不能有環形依賴,否則就死循環。
典型的Spark運行DAG的不同階段:
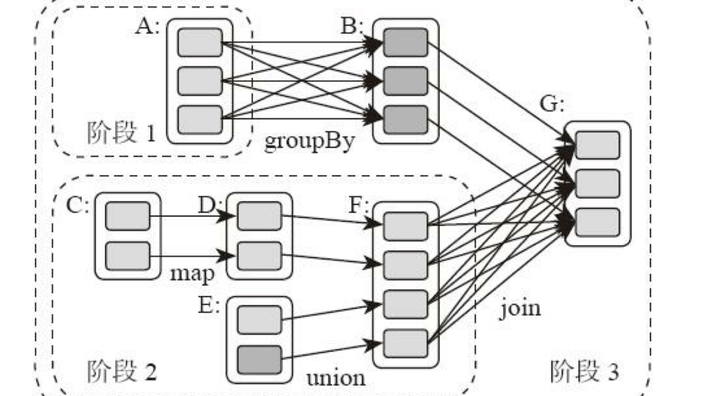
整個應用被切分成3個階段,階段3需要依賴階段1、2,階段1、2互不依賴。Spark執行調度時,先執行階段1、2,完成後,再執行階段3。對應Spark偽代碼:
rddB = rddA.groupBy(key) rddD = rddC.map(func) rddF = rddD.union(rddE) rddG = rddB.join(rddF)
所以Spark作業調度執行的核心是DAG,整個應用被切分成數個階段,每個階段的依賴關係也很清楚。根據每個階段要處理的數據量生成任務集合(TaskSet),每個任務都分配一個任務進程去處理,Spark就實現了大數據的分佈式計算。
負責Spark應用DAG生成和管理的組件是DAGScheduler,DAGScheduler根據程序代碼生成DAG,然後將程序分發到分佈式計算集群,按計算階段的先後關係調度執行。
那麼Spark劃分計算階段的依據是什麼呢?顯然並不是RDD上的每個轉換函數都會生成一個計算階段,比如上面的例子有4個轉換函數,但是只有3個階段。
你可以再觀察一下上面的DAG圖,關於計算階段的劃分從圖上就能看出規律,當RDD之間的轉換連接線呈現多對多交叉連接的時候,就會產生新的階段。一個RDD代表一個數據集,圖中每個RDD裏面都包含多個小塊,每個小塊代表RDD的一個分片。
一個數據集中的多個數據分片需要進行分區傳輸,寫入到另一個數據集的不同分片中,這種數據分區交叉傳輸的操作,我們在MapReduce的運行過程中也看到過。
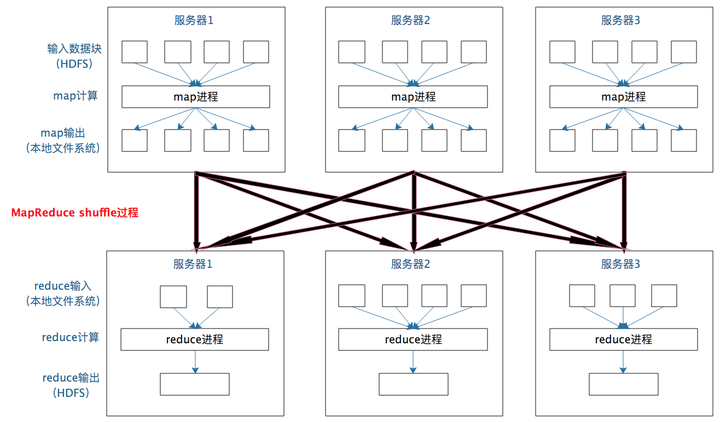
是的,這就是shuffle過程,Spark也需要通過shuffle將數據進行重新組合,相同Key的數據放在一起,進行聚合、關聯等操作,因而每次shuffle都產生新的計算階段。這也是為什麼計算階段會有依賴關係,它需要的數據來源於前面一個或多個計算階段產生的數據,必須等待前面的階段執行完畢才能進行shuffle,並得到數據。
計算階段劃分的依據是shuffle,不是轉換函數的類型,有的函數有時有shuffle,有時沒有。如上圖例子中RDD B和RDD F進行join,得到RDD G,這裡的RDD F需要進行shuffle,RDD B不需要。
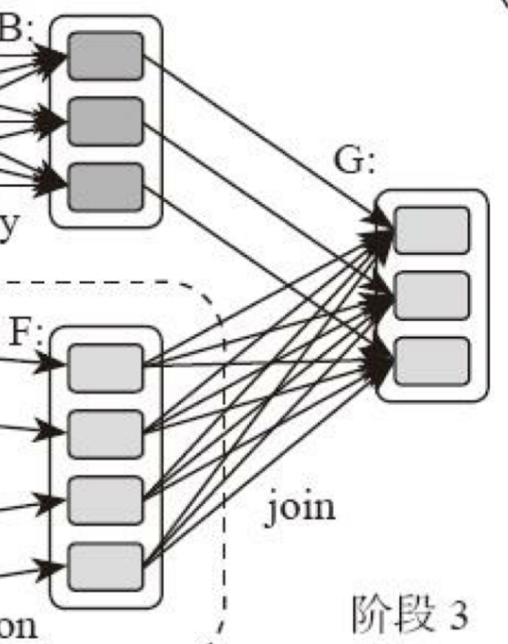
因為RDD B在前面一個階段,階段1的shuffle過程中,已進行了數據分區。分區數目和分區K不變,無需再shuffle:
- 這種無需進行shuffle的依賴,在Spark里稱作窄依賴
- 需要進行shuffle的依賴,被稱作寬依賴
類似MapReduce,shuffle對Spark也很重要,只有通過shuffle,相關數據才能互相計算。
既然都要shuffle,為何Spark就更高效?
本質上看,Spark算是一種MapReduce計算模型的不同實現。Hadoop MapReduce簡單粗暴根據shuffle將大數據計算分成Map、Reduce兩階段就完事。但Spark更細,將前一個的Reduce和後一個的Map連接,當作一個階段持續計算,形成一個更優雅、高效地計算模型,其本質依然是Map、Reduce。但這種多個計算階段依賴執行的方案可有效減少對HDFS的訪問,減少作業的調度執行次數,因此執行速度更快。
不同於Hadoop MapReduce主要使用磁盤存儲shuffle過程中的數據,Spark優先使用內存進行數據存儲,包括RDD數據。除非內存不夠用,否則儘可能使用內存, 這也是Spark性能比Hadoop高的原因。
Spark作業管理
Spark裏面的RDD函數有兩種:
- 轉換函數,調用以後得到的還是一個RDD,RDD的計算邏輯主要通過轉換函數完成
- action函數,調用以後不再返回RDD。比如count()函數,返回RDD中數據的元素個數;saveAsTextFile(path),將RDD數據存儲到path路徑下。Spark的DAGScheduler在遇到shuffle的時候,會生成一個計算階段,在遇到action函數的時候,會生成一個作業(job)
RDD裏面的每個數據分片,Spark都會創建一個計算任務去處理,所以一個計算階段含多個計算任務(task)。
作業、計算階段、任務的依賴和時間先後關係:
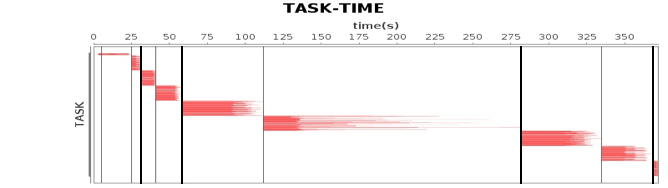
橫軸時間,縱軸任務。兩條粗黑線之間是一個作業,兩條細線之間是一個計算階段。一個作業至少包含一個計算階段。水平方向紅色的線是任務,每個階段由很多個任務組成,這些任務組成一個任務集合。
DAGScheduler根據代碼生成DAG圖後,Spark任務調度就以任務為單位進行分配,將任務分配到分佈式集群的不同機器上執行。
Spark執行流程
Spark支持Standalone、Yarn、Mesos、K8s等多種部署方案,原理類似,僅是不同組件的角色命名不同。
Spark cluster components:
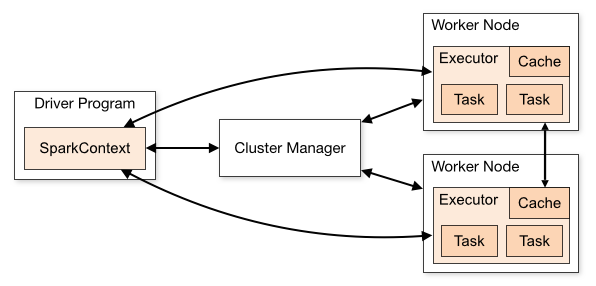
首先,Spark應用程序啟動在自己的JVM進程里(Driver進程),啟動後調用SparkContext初始化執行配置和輸入數據。SparkContext啟動DAGScheduler構造執行的DAG圖,切分成最小的執行單位-計算任務。
然後,Driver向Cluster Manager請求計算資源,用於DAG的分佈式計算。Cluster Manager收到請求後,將Driver的主機地址等信息通知給集群的所有計算節點Worker。
Worker收到信息後,根據Driver的主機地址,跟Driver通信並註冊,然後根據自己的空閑資源向Driver通報自己可以領用的任務數。Driver根據DAG圖開始向註冊的Worker分配任務。
Worker收到任務後,啟動Executor進程執行任務。Executor先檢查自己是否有Driver的執行代碼,若無,從Driver下載執行代碼,通過Java反射加載後開始執行。
總結
相比 Mapreduce,Spark的主要特性:
- RDD編程模型更簡單
- DAG切分的多階段計算過程更快
- 使用內存存儲中間計算結果更高效
Spark在2012年開始流行,那時內存容量提升和成本降低已經比MapReduce出現的十年前強了一個數量級,Spark優先使用內存的條件已經成熟。
參考

