【譯】Data exchange between tasks(任務之間的數據交換)
- 2019 年 10 月 4 日
- 筆記
Flink中的數據交換基於以下設計原則
1.用於數據交換的控制流(即:為了啟動交換而傳遞的消息)是接收者啟動的,就像原始MapReduce一樣
2.用於數據交換的數據流,即通過線路的實際數據傳輸由IntermediateResult的概念抽象,並且是可插入的。 這意味着系統可以使用相同的實現支持流數據傳輸和批量數據傳輸。
數據交換涉及許多實例,例如:
JobManager是主節點,負責調度任務,恢復和協調,並通過ExecutionGraph數據結構保存工作的全貌。
TaskManagers,工作節點。 TaskManager(TM)在線程中同時執行許多任務。 每個TM還包含一個CommunicationManager(CM – 在任務之間共享)和一個MemoryManager(MM – 也在任務之間共享)。 TM可以通過復用的TCP連接相互交換數據,這些連接是在需要時創建的。
請注意,在Flink中,通過網絡交換數據的是TaskManagers,而不是任務,即,通過一個網絡連接復用生活在同一TM中的任務之間的數據交換。

ExecutionGraph:執行圖是一種數據結構,包含有關作業計算的「基本事實」。 它由表示計算任務的頂點(ExecutionVertex)和表示任務生成的數據的中間結果(IntermediateResultPartition)組成。 頂點鏈接到它們通過ExecutionEdges(EE)消耗的中間結果:

這些是JobManager中的邏輯數據結構。 它們具有運行時等效結構,負責TaskManagers中的實際數據處理。 IntermediateResultPartition的運行時等價物稱為ResultPartition。
ResultPartition(RP)表示BufferWriter寫入的一大塊數據,即由單個任務生成的一大塊數據。 RP是結果子分區(RS)的集合。 這是為了區分指向不同接收器的數據,例如,在用於reduce或join的分區shuffle的情況下。
ResultSubpartition(RS)表示由operator創建的數據的一個分區,以及將此數據轉發給接收operator的邏輯。 RS的具體實現確定了實際的數據傳輸邏輯,這是可插拔的機制,允許系統支持各種數據傳輸。 例如,PipelinedSubpartition是一個支持流數據交換的流水線實現。 SpillableSubpartition是一種支持批量數據交換的阻塞實現。
InputGate:接收端RP的邏輯等效項。 它負責收集數據緩衝區並將其上傳到上游。
InputChannel:接收端RS的邏輯等價物。 它負責收集特定分區的數據緩衝區。
Buffer: See https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=53741525
序列化器和反序列化器可靠地將類型化記錄轉換為原始位元組緩衝區,反之亦然,處理跨越多個緩衝區的記錄等。
Control flow for data exchange

圖片代表一個簡單的map-reduce作業,具有兩個並行任務。我們有兩個TaskManagers,每個都有兩個任務(一個map任務和一個reduce任務)在兩個不同的節點中運行,一個JobManager在第三個節點中運行。我們專註於啟動任務M1和R2之間的轉移。使用粗箭頭表示數據傳輸,使用細箭頭表示消息。首先,M1生成ResultPartition(RP1)(箭頭1)。當RP可供使用時(我們將在稍後討論),它會通知JobManager(箭頭2)。 JobManager通知該分區的預期接收者(任務R1和R2)分區已準備就緒。如果尚未安排接收器,這實際上將觸發任務的部署(箭頭3a,3b)。然後,接收器將從RP請求數據(箭頭4a和4b)。這將在本地(情況5a)或通過TaskManagers(5b)的網絡堆棧啟動任務(箭頭5a和5b)之間的數據傳輸。當RP決定通知JobManager其可用性時,該過程留下一定程度的自由度。例如,如果RP1在通知JM之前完全自行生成(並且可能寫入文件),則數據交換大致對應於Hadoop中實現的批處理交換。如果RP1在產生第一條記錄後立即通知JM,我們就會進行流數據交換。 Transfer of a byte buffer between two tasks
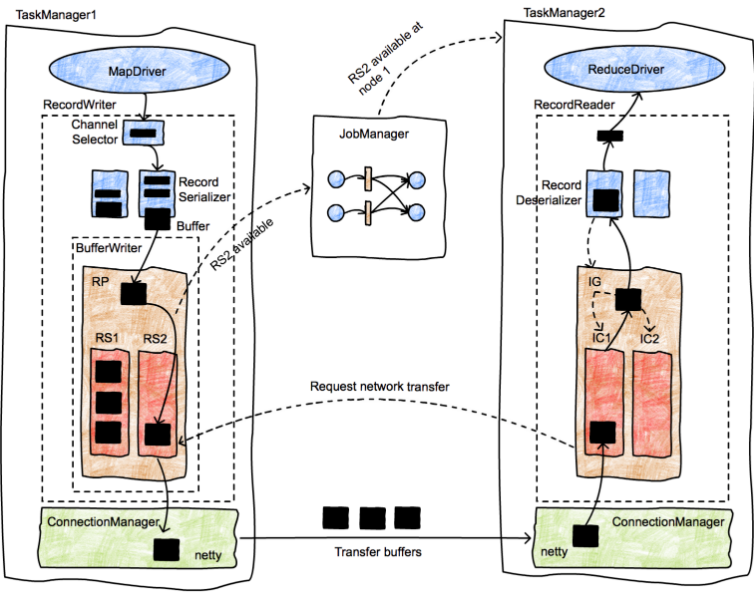
這張圖片更詳細地展示了數據記錄從生產者發送到消費者的生命周期。最初,MapDriver生成傳遞給RecordWriter對象的記錄(由收集器收集)。 RecordWriters包含許多序列化程序(RecordSerializer對象),每個消費者任務可能會使用這些記錄。例如,在shuffle或broadcast中,將有與消費者任務數量一樣多的序列化器。 ChannelSelector選擇一個或多個序列化程序來放置記錄。例如,如果廣播記錄,它們將被放置在每個序列化器中。如果記錄是散列分區的,則ChannelSelector將評估記錄上的哈希值並選擇適當的序列化程序。
序列化程序將記錄序列化為二進制表示形式,並將它們放在固定大小的緩衝區中(記錄可以跨越多個緩衝區)。這些緩衝區移交給BufferWriter並寫入ResultPartition(RP)。 RP由幾個子分區(ResultSubpartitions-RSs)組成,為特定的消費者收集緩衝區。在圖片中,緩衝區的目的地是第二個reducer(在TaskManager 2中),它被放置在RS2中。由於這是第一個緩衝區,RS2可供使用(請注意,此行為實現了流式shuffle),並通知JobManager事實。
JobManager查找RS2的使用者,並通知TaskManager 2有可用的數據塊。到TM2的消息向下傳播到應該接收此緩衝區的InputChannel,後者又通知RS2可以啟動網絡傳輸。然後,RS2將緩衝區移交給TM1的網絡堆棧,然後TM1將其交給netty進行運輸。網絡連接長時間運行並存在於TaskManagers之間,而不是單個任務。
一旦TM2接收到緩衝區,它就會通過一個類似的對象層次結構,從InputChannel(接收方等效於IRPQ)開始,進入InputGate(包含幾個IC),最後進入RecordDeserializer,從緩衝區生成類型化記錄並將它們交給接收任務,在本例中為ReduceDriver。
原文鏈接:https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
