數倉建設 | ODS、DWD、DWM等理論實戰(好文收藏)
本文目錄:
一、數據流向
二、應用示例
三、何為數倉DW
四、為何要分層
五、數據分層
六、數據集市
七、問題總結
導讀
數倉在建設過程中,對數據的組織管理上,不僅要根據業務進行縱向的主題域劃分,還需要橫向的數倉分層規範。本文作者圍繞企業數倉分層展開分析,希望對你有幫助。
因文章太長,本文不是完結版,文末可獲取完整PDF版

從事數倉相關工作的人員都知道數倉模型設計的首要工作之一就是進行模型分層,可見模型分層在模型設計過程中的重要性,確實優秀的分層設計是一個數倉項目能否建設成功的核心要素,讓數據易理解和高復用是分層的核心目標。
一、數據流向
二、應用示例

三、何為數倉DW
Data warehouse(可簡寫為DW或者DWH)數據倉庫,是在數據庫已經大量存在的情況下,它是一整套包括了etl、調度、建模在內的完整的理論體系。 數據倉庫的方案建設的目的,是為前端查詢和分析作為基礎,主要應用於OLAP(on-line Analytical Processing),支持複雜的分析操作,側重決策支持,並且提供直觀易懂的查詢結果。目前行業比較流行的有:AWS Redshift,Greenplum,Hive等。 數據倉庫並不是數據的最終目的地,而是為數據最終的目的地做好準備,這些準備包含:清洗、轉義、分類、重組、合併、拆分、統計等
1. 主要特點
-
面向主題
-
操作型數據庫組織面向事務處理任務,而數據倉庫中的數據是按照一定的主題域進行組織。 -
主題是指用戶使用數據倉庫進行決策時所關心的重點方面,一個主題通過與多個操作型信息系統相關。
-
-
集成
-
需要對源數據進行加工與融合,統一與綜合 -
在加工的過程中必須消除源數據的不一致性,以保證數據倉庫內的信息時關於整個企業的一致的全局信息。(關聯關係)
-
-
不可修改
-
DW中的數據並不是最新的,而是來源於其他數據源 -
數據倉庫主要是為決策分析提供數據,涉及的操作主要是數據的查詢
-
-
與時間相關
-
處於決策的需要數據倉庫中的數據都需要標明時間屬性
-
與數據庫的對比
-
DW:專門為數據分析設計的,涉及讀取大量數據以了解數據之間的關係和趨勢 -
數據庫:用於捕獲和存儲數據
四、為何要分層
數據倉庫中涉及到的問題:
-
為什麼要做數據倉庫? -
為什麼要做數據質量管理? -
為什麼要做元數據管理? -
數倉分層中每個層的作用是什麼?
在實際的工作中,我們都希望自己的數據能夠有順序地流轉,設計者和使用者能夠清晰地知道數據的整個聲明周期,比如下面左圖。 但是,實際情況下,我們所面臨的數據狀況很有可能是複雜性高、且層級混亂的,我們可能會做出一套表依賴結構混亂,且出現循環依賴的數據體系,比如下面的右圖。
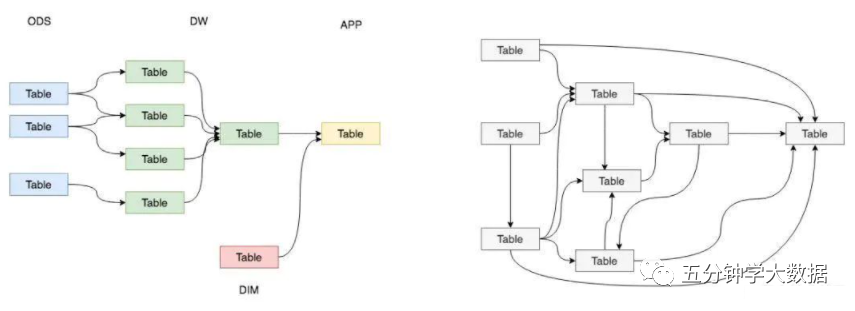
為了解決我們可能面臨的問題,需要一套行之有效的數據組織、管理和處理方法,來讓我們的數據體系更加有序,這就是數據分層。數據分層的好處:
-
清晰數據結構:讓每個數據層都有自己的作用和職責,在使用和維護的時候能夠更方便和理解 -
複雜問題簡化:將一個複雜的任務拆解成多個步驟來分步驟完成,每個層只解決特定的問題 -
統一數據口徑:通過數據分層,提供統一的數據出口,統一輸出口徑 -
減少重複開發:規範數據分層,開發通用的中間層,可以極大地減少重複計算的工作
五、數據分層
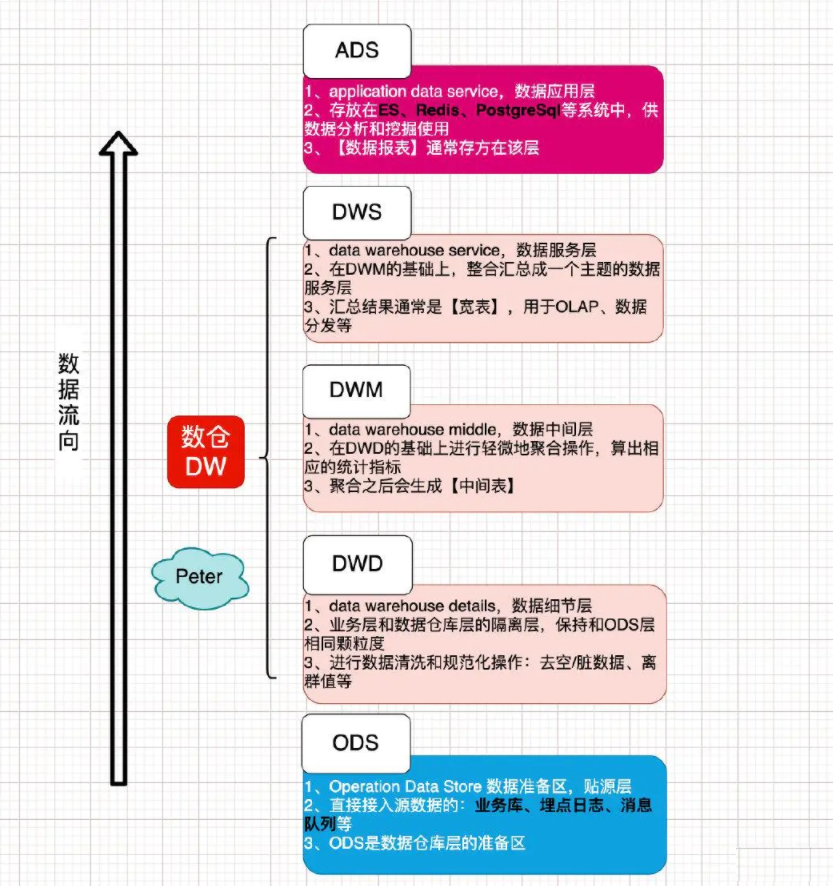
每個公司的業務都可以根據自己的業務需求分層不同的層次;目前比較成熟的數據分層:數據運營層ODS、數據倉庫層DW、數據服務層ADS(APP)。
1. 數據運營層ODS
數據運營層:Operation Data Store 數據準備區,也稱為貼源層。數據源中的數據,經過抽取、洗凈、傳輸,也就是ETL過程之後進入本層。該層的主要功能:
-
ODS是後面數據倉庫層的準備區 -
為DWD層提供原始數據 -
減少對業務系統的影響
在源數據裝入這一層時,要進行諸如去噪(例如有一條數據中人的年齡是 300 歲,這種屬於異常數據,就需要提前做一些處理)、去重(例如在個人資料表中,同一 ID 卻有兩條重複數據,在接入的時候需要做一步去重)、字段命名規範等一系列操作。 但是為了考慮後續可能需要追溯數據問題,因此對於這一層就不建議做過多的數據清洗工作,原封不動地接入原始數據也可以,根據業務具體分層的需求來做。這層的數據是後續數據倉庫加工數據的來源。數據來源的方式:
-
業務庫
-
經常會使用sqoop來抽取,例如每天定時抽取一次。 -
實時方面,可以考慮用canal監聽mysql的binlog,實時接入即可。
-
-
埋點日誌
-
日誌一般以文件的形式保存,可以選擇用flume定時同步 -
可以用spark streaming或者Flink來實時接入 -
kafka也OK
-
-
消息隊列:即來自ActiveMQ、Kafka的數據等。
2. 數據倉庫層DW
數據倉庫層從上到下,又可以分為3個層:數據細節層DWD、數據中間層DWM、數據服務層DWS。
1) 數據細節層DWD
數據細節層:data warehouse details,DWD(數據清洗/DWI) 該層是業務層和數據倉庫的隔離層,保持和ODS層一樣的數據顆粒度;主要是對ODS數據層做一些數據的清洗和規範化的操作,比如去除空數據、臟數據、離群值等。為了提高數據明細層的易用性,該層通常會才採用一些維度退化方法,將維度退化至事實表中,減少事實表和維表的關聯。
2) 數據中間層DWM
數據中間層:Data Warehouse Middle,DWM該層是在DWD層的數據基礎上,對數據做一些輕微的聚合操作,生成一些列的中間結果表,提升公共指標的復用性,減少重複加工的工作。
簡答來說,對通用的核心維度進行聚合操作,算出相應的統計指標
3) 數據服務層DWS
數據服務層:Data Warehouse Service,DWS(寬表-用戶行為,輕度聚合)該層是基於DWM上的基礎數據,整合匯總成分析某一個主題域的數據服務層,一般是寬表,用於提供後續的業務查詢,OLAP分析,數據分發等。一般來說,該層的數據表會相對較少;一張表會涵蓋比較多的業務內容,由於其字段較多,因此一般也會稱該層的表為寬表。
-
用戶行為,輕度聚合對DWD -
主要對ODS/DWD層數據做一些輕度的匯總。
3. 數據應用層ADS
數據應用層:Application Data Service,ADS(APP/DAL/DF)-出報表結果。該層主要是提供給數據產品和數據分析使用的數據,一般會存放在ES、Redis、PostgreSql等系統中供線上系統使用;也可能存放在hive或者Druid中,供數據分析和數據挖掘使用,比如常用的數據報表就是存在這裡的。
4. 事實表 Fact Table
事實表是指存儲有事實記錄的表,比如系統日誌、銷售記錄等。事實表的記錄在不斷地增長,比如電商的商品訂單表,就是類似的情況,所以事實表的體積通常是遠大於其他表。
5. 維表層Dimension(DIM)
維度表(Dimension Table)或維表,有時也稱查找表(Lookup Table),是與事實表相對應的一種表;它保存了維度的屬性值,可以跟事實表做關聯,相當於將事實表上經常重複出現的屬性抽取、規範出來用一張表進行管理。維度表主要是包含兩個部分:
-
高基數維度數據:一般是用戶資料表、商品資料表類似的資料表,數據量可能是千萬級或者上億級別 -
低基數維度數據:一般是配置表,比如枚舉字段對應的中文含義,或者日期維表等;數據量可能就是個位數或者幾千幾萬。
6. 臨時表TMP
每一層的計算都會有很多臨時表,專設一個DWTMP層來存儲我們數據倉庫的臨時表
六、數據集市
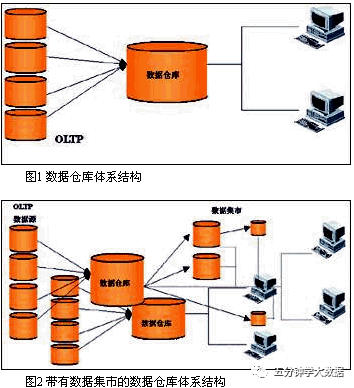
狹義ADS層;廣義上指hadoop從DWD DWS ADS 同步到RDS的數據數據集市(Data Mart),也叫數據市場,數據集市就是滿足特定的部門或者用戶的需求,按照多維的方式進行存儲,包括定義維度、需要計算的指標、維度的層次等,生成面向決策分析需求的數據立方體。從範圍上來說,數據是從企業範圍的數據庫、數據倉庫,或者是更加專業的數據倉庫中抽取出來的。數據中心的重點就在於它迎合了專業用戶群體的特殊需求,在分析、內容、表現,以及易用方面。數據中心的用戶希望數據是由他們熟悉的術語表現的。帶有數據集市的數據倉儲結構
區別數據倉庫
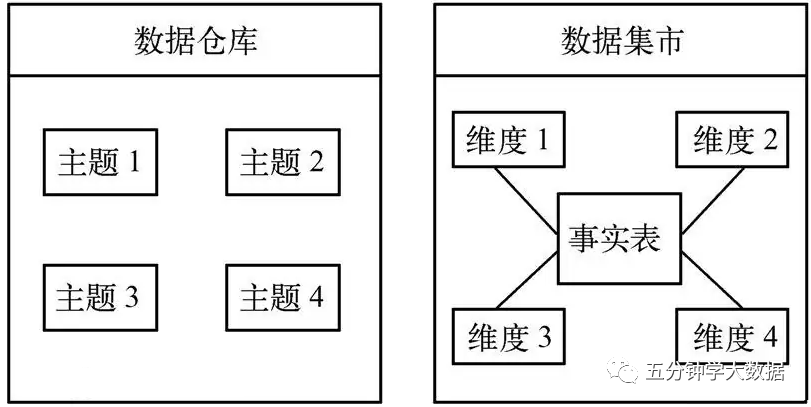
數據集市就是企業級數據倉庫的一個子集,它主要面向部門級業務,並且只面向某個特定的主題。為了解決靈活性與性能之間的矛盾,數據集市就是數據倉庫體系結構中增加的一種小型的部門或工作組級別的數據倉庫。數據集市存儲為特定用戶預先計算好的數據,從而滿足用戶對性能的需求。數據集市可以在一定程度上緩解訪問數據倉庫的瓶頸。 理論上講,應該有一個總的數據倉庫的概念,然後才有數據集市。實際建設數據集市的時候,國內很少這麼做。國內一般會先從數據集市入手,就某一個特定的主題(比如企業的客戶信息)先做數據集市,再建設數據倉庫。數據倉庫和數據集市建立的先後次序之分,是和設計方法緊密相關的。而數據倉庫作為工程學科,並沒有對錯之分。 在數據結構上,數據倉庫是面向主題的、集成的數據的集合。而數據集市通常被定義為星型結構或者雪花型數據結構,數據集市一般是由一張事實表和幾張維表組成的。
七、問題總結
1. ODS與DWD區別?
問:還是不太明白 ods 和 dwd 層的區別,有了 ods 層後感覺 dwd 沒有什麼用了。
答:站在一個理想的角度來講,如果 ods 層的數據就非常規整,基本能滿足我們絕大部分的需求,這當然是好的,這時候 dwd 層其實也沒太大必要。但是現實中接觸的情況是 ods 層的數據很難保證質量,畢竟數據的來源多種多樣,推送方也會有自己的推送邏輯,在這種情況下,我們就需要通過額外的一層 dwd 來屏蔽一些底層的差異。
問:我大概明白了,是不是說 dwd 主要是對 ods 層做一些數據清洗和規範化的操作,dws 主要是對 ods 層數據做一些輕度的匯總?
答:對的,可以大致這樣理解。
2. APP層幹什麼的?
問:感覺DWS層是不是沒地方放了,各個業務的DWS表是應該在 DWD還是在 app?
答:這個問題不太好回答,我感覺主要就是明確一下DWS層是幹什麼的,如果你的DWS層放的就是一些可以供業務方使用的寬表表,放在 app 層就行。如果你說的數據集市是一個比較泛一點的概念,那麼其實 dws、dwd、app 這些合起來都算是數據集市的內容。
問:那存到 Redis、ES 中的數據算是 app層嗎?
答:算是的,我個人的理解,app 層主要存放一些相對成熟的表,能供業務側使用的。這些表可以在 Hive 中,也可以是從 Hive 導入 Redis 或者 ES 這種查詢性能比較好的系統中


