使用Harr特徵的級聯分類器實現目標檢測
前言
最近在學習人臉的目標檢測任務時,用了Haar人臉檢測算法,這個算法實現起來太簡潔了,讀入個.xml,調用函數就能用。但是深入了解我發現這個算法原理很複雜,也很優秀。究其根源,於是我找了好些篇相關論文,主要讀了2001年Paul Viola和Michael Jones在CVPR上發表的一篇可以說是震驚了計算機視覺的文章,《Rapid Objection Dection using a Boosted Cascade of Simple Features》。這個算法最大的特點就是快!在當時,它能夠做到實時演示人臉檢測效果,這在當時的硬件情況下是非常震驚的,且還具有極高的準確率。同時在2011年,這篇論文在科羅多拉的會議上獲得了「十年內影響最為深遠的一篇文章」。在我們知道這篇文章有多麼的NB之後,接下來我們來細細的品味這篇文章的技術細節。
根據論文Abstract描述,該論文主要有三個巨大貢獻:
- 第一個貢獻是引入了「積分圖」的圖像表示方法,它能夠加快檢測時的計算速度;
- 第二個貢獻是提出了一個基於AdaBoost的學習算法,它能夠從大量的數據中提取少量且有效的特徵來學習一個高效的分類器;
- 第三個貢獻是提出了注意力級聯的算法,它能夠讓分類器更多聚焦於object-like區別,而不是與被檢測目標無關的背景圖像等區域,也是極大的加快了目標檢測速度。
總結起來就是,Haar級聯算法實際上是使用了boosting算法中的AdaBoost算法,Harr分類器用AdaBoost算法構建了一個強分類器進行級聯,而再底層特徵特區上採用的是更加高效的矩形特徵以及積分圖方法,即:
Haar分類器 = Haar-like特徵 + 積分圖法 + AdaBoost算法 + 級聯
1. Haar-like特徵提取
注意:由於原論文中對於Haar-like特徵的描述過少,很多細節不完整,這部分將會詳細介紹論文中沒有講的算法細節。
1.1 基本Haar特徵
Haar-like是一種非常經典的特徵提取算法,尤其是它與AdaBoost組合使用時對人臉檢測有着非常不錯的效果。雖然一般提及到Haar-like的時候,都會和AdaBoost、級聯分類器、人臉檢測、積分圖一起出現,但是Haar-like本質上只是一種特徵提取算法。它涉及到了三篇經典論文,尤其是第三篇論文,讓它快速發展。
最原始的Haar-like特徵是在《A general framework for object detection》中提出的,它定義了四個基本特徵結構,如下圖所示:
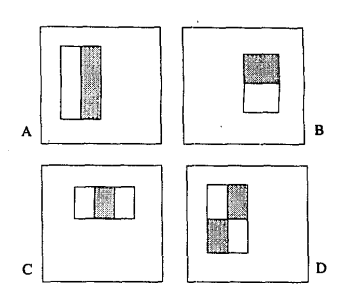
可以將這個它們理解成為一個窗口,這個窗口將在圖像中做步長為1的滑動,最終遍歷整個圖像。它的整體遍歷過程是:當一次遍歷結束後,窗口將在寬度或長度上,窗口將在寬度或長度上成比例的放大,再重新之前遍歷的步驟,直到放大到最後一個比例後結束(放大的最大比例一般是與原圖像相同大小比例)。
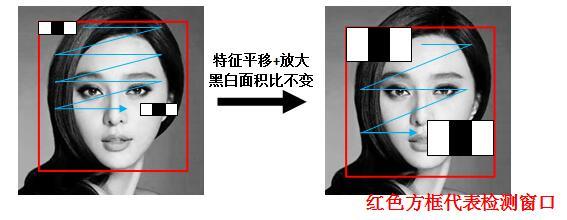
例子:以x3特徵為例,在放大+平移過程中白:黑:白面積比始終是1:1:1。首先在紅框所示的檢測窗口中生成大小為3個像素的最小x3特徵;之後分別沿着x和y平移產生了在檢測窗口中不同位置的大量最小3像素x3特徵;然後把最小x3特徵分別沿着x和y放大,再平移,又產生了一系列大一點x3特徵;然後繼續放大+平移,重複此過程,直到放大後的x3和檢測窗口一樣大。這樣x3就產生了完整的x3系列特徵。
同樣,通過我們上文中關於Haar-like特徵的遍歷過程可知,Haar特徵可以在檢測窗口中由放大+平移產生(黑:白區域面積比始終保持不變)。那麼這些通過放大 + 平移的子特徵總共有多少個呢?Rainer Lienhart在他的論文中給出了解釋:假設檢測窗口大小為\(W*H\),矩陣特徵大小為\(w*h\),X和Y為表示矩形特徵在水平和垂直方向能放大的最大比例係數:
Y = [\frac{H}{h}]
\]
其中\(W\)和\(H\)是整個圖像的寬高,\(w\)和\(h\)是Harr窗口的初始寬高,可以放大的倍數為\(X·Y\)。
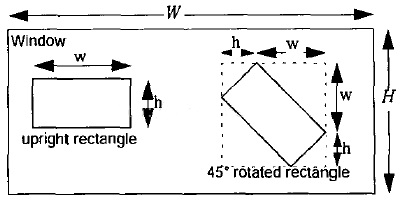
根據以上,在檢測窗口Window中,一般矩形特徵(upright rectangle)的數量為:
\]
以x3的特徵(即特徵大小的pixel為1×3)為例來解釋這個公式:
- 特徵框豎直放大1倍,即無放大,豎直方向有(H-h+1)個特徵
- 特徵框豎直放大2倍,豎直方向有(H – 2h + 1)個特徵
- 特徵框豎直放大3倍,豎直方向有(H – 3h + 1)個特徵
- 如此到豎直放大Y = floor(H/h)倍,豎直方向有1個特徵,即(H-Y*h+1)
那麼豎直方向總共有:
(H – h + 1) + (H – 2h + 1) + (H – 3h + 1) + …… + (H – Y*h + 1) = Y[H + 1 – h(1 + Y)/2]個特徵。水平方向同理可得。
考慮到水平和豎直方向縮放是獨立的,當x3特徵在24*24大小的檢測窗口時,此時(W=H=24,w=3,h=1,X=8,Y=24),一共能產生27600個子特徵。
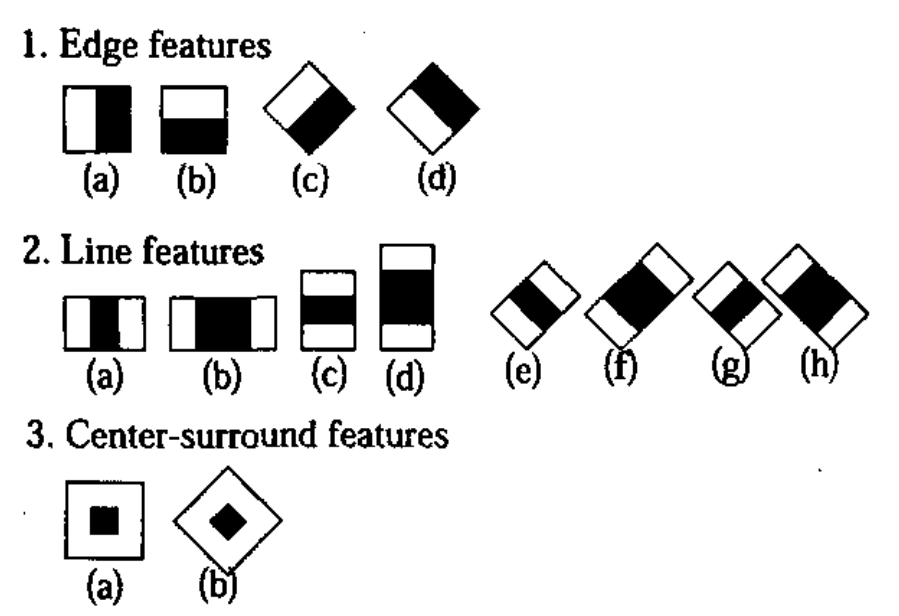
1.2 擴展Haar特徵
在基本的四個Haar特徵基礎上,文章《An entended set of Haar-like features for rapid objection detection》將原來的4個特徵拓展為14個。這些拓展特徵主要增加了旋轉性,能夠提取到更豐富的邊緣信息。比如:如果一張要檢測的人臉不是人臉,是一張側臉的時候,此時基本的四個Haar特徵就沒法對其進行有效的特徵提取,於是其提出了以下拓展的Haar-like特徵:
1.3 Haar特徵值的計算
關於Haar特徵的計算,按照Opencv代碼,Haar特徵值 = 整個Haar區域像素和 x 權重 + 黑色區域內像素和 x 權重。
\]
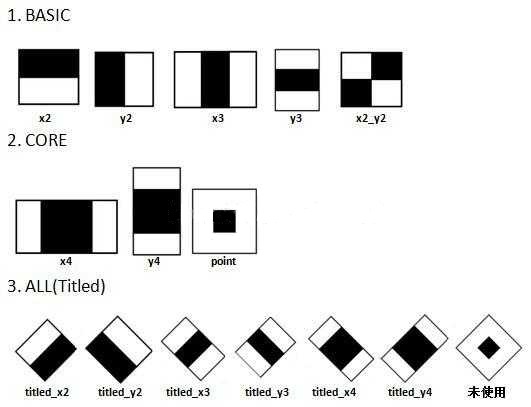
比如上圖中的x3和y3特徵,其\(weight_{all}=1,weight_{black}=-3\),上圖中的\(point\)特徵,\(weight_{all}=1,weight_{black}=-9\);其餘11種特徵均為\(weight_{all}=1,weight_{black}=-2\)。
所以,對於x2特徵的特徵值 = (黑 + 白) * 1 + 黑 * (-2) = 白 – 黑,對於Point特徵值 = (黑 + 白) * 1 + 黑 (-9) = 白 – 8 * 黑。這個就是很多文章種所提到的」特徵值=白色區域像素和減去黑色區域像素和」。
為什麼要這樣設置這種加權相減呢?由於有些特徵它的黑白面積不相等,有的特徵黑白面積相等,設置權值可以抵消黑白面積不等而帶來的影響,保證所有Haar特徵的特徵值在灰度分佈絕對均勻的圖中為0(比如圖像所有像素相等,那麼它的特徵值就會是0)。
接下來我們再對特徵值的含義進行一個解釋。以MIT人臉庫中2706個大小為20*20的人臉正樣本圖像為數據,計算下圖中位置的Haar特徵值,結果如圖所示:
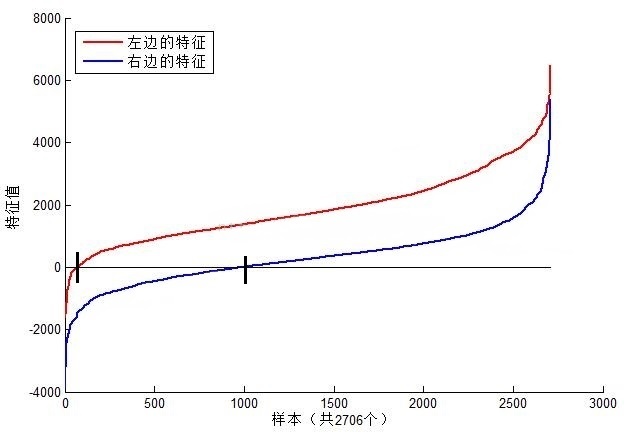
上圖中左邊特徵結果為紅色,右邊為藍色。可以看到,2個不同的Haar特徵在同一組樣本中具有不同的特徵值分佈,左邊特徵計算出的特徵值基本都大於0,而右邊特徵的特徵值基本均勻分佈於0兩側(分佈越均勻對樣本的區分度越小)。正是由於樣本中Haar特徵值分佈不同,導致了不同Haar特徵分類效果不同。顯而易見,對樣本區分度越大的特徵分類效果越好,即紅色曲線對應的左邊的Haar特徵分類效果好於右邊的Haar特徵。同時,我們結合人臉可以知道,這個特徵可以表示眼睛要比臉頰的顏色要深,因為能夠很有效的進行區分。
總結之下,我們可以知道:
- 在檢測窗口通過平移 + 放大可以產生一系列的Haar特徵(也就是說,黑白面積比例相同,但是大小不同的特徵可以算作多個特徵),這些特徵由於位置和大小不同,分類效果也各異。
- 通過計算Haar特徵的特徵值,可以有效將圖像矩陣映射為1維特徵值,有效實現了降維。
1.4 Haar特徵的保存
在OpenCV的XML文件中,每一個Haar特徵都被保存在2~3個形如:
\]
的標籤,其中x和y代表Haar矩形左上角坐標(以檢測窗口的左上角為原點),width和height表示矩形的寬和高,weight表示權重值。
1.5 Haar特徵值標準化
由上圖中兩個特徵計算的特徵值可以發現,一個1218大小的Haar特徵計算出的特徵值變換範圍從-2000 ~ +6000,跨度非常的大。這種跨度大的特性不利於量化評定特徵值,所以需要進行數據標準化來壓縮特徵值範圍。假設當前檢測窗口中的圖像為i(x,y),當前檢測窗口為wh大小。OpenCV中標準化步驟如下:
-
計算檢測窗口中間部分(w – 2) * (h – 2)的圖像灰度值和灰度值平方和
\[sum = \sum i(x,y), sqsum = \sum i^2(x,y)
\] -
計算平均值:
\[mean = \frac{sum}{w*h} \\
sqmean = \frac{sqsum}{w*h}
\] -
計算標準化因子
-
\[varNormFactor = \sqrt{sqmean – mean^2}
\] -
標準化特徵值:
\[normValue = \frac{featureValue}{varNormFactor}
\]
注意:在檢測和訓練時,數據標準化的方法一定要一致,否則可能由於標準化不同帶來的誤差導致模型無法工作。
2. 積分圖計算
與Haar緊密相連的就是積分圖了,它源自於這篇論文《Rapid Object Dection using a boosted cascade of simple features》,它使用積分圖的方法快速計算了Haar特徵。在上文中我們提到過,當x3特徵在24*24大小的檢測窗口(W=H=24,w=3,h=1,X=8,Y=24)滑動時,一共能產生27600個子特徵。在計算這些特徵值時,我們會有很多次重複且無效的計算,那麼積分圖的提出就是為了讓其計算的更加高效。積分圖只需要遍歷一次圖像就可以求出圖像中所有區域像素和的快速算法,大大提高了圖像特徵值計算的效率。
積分圖主要的思想是將圖像從起點開始到各個點所形成的矩形區域像素之和作為一個數組的元素保存在內存中,當要計算某個區域的像素和時可以直接索引數組的元素,不用重新計算這個區域的像素和,從而加快了計算(這有個相應的稱呼,叫做動態規划算法)。積分圖能夠在多種尺度下,使用相同的時間(常數時間)來計算不同的特徵,因此大大提高了檢測速度。
積分圖是一種能夠描述全局信息的矩陣表示方法。積分圖的構造方式是:位置(𝑖,𝑗)處的值𝑖𝑖(𝑖,𝑗)是原圖像(𝑖,𝑗)左上角方向所有像素𝑓(𝑘,𝑙)的和:
\]
積分圖構建算法:
-
用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
-
使用ii(i,j)表示一個積分圖像,初始化ii(-1,i) = 0;
-
逐行掃描圖像,遞歸計算每個像素(i,j)行方向的累加和s(i,j)和積分圖像ii(i,j)的值
\[s(i,j) = s(i,j-1) + f(i,j) \\
ii(i,j) = ii(i-1.j) + s(i,j)
\] -
掃描圖像一遍,當到達圖像右下角像素時,積分圖ii就構建好了。
積分圖構建好之後,圖像中的任何矩陣區域的累加和都可以通過簡單運算得到如圖所示:
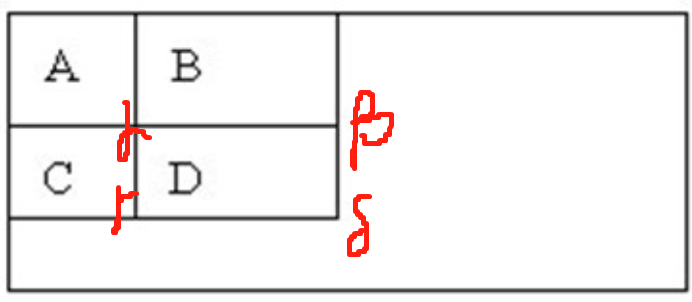
設D的四個頂點分別為α,β,γ,δ則D的像素和可以表示為
\]
而Haar-like特徵值無非就是兩個矩陣像素和的差,可以在常數時間內完成。
3. AdaBoost
Boosting方法是一種重要的集成學習技術,能夠將預測精度僅比隨即猜測略高的弱學習器增強為預測精度高的強學習器,這在直接構造學習器非常困難的情況下,為學習算法設計提供了一種有效的新思路和新方法,其中AdaBoost算法應用最廣。
AdaBoost的全稱是 Adaptive Boosting(自適應增強)的縮寫,它的自適應在於:前一個基本分類器被錯誤分類的樣本的權重會增大,而正確分類的樣本的權重會減小,並再次用來訓練下一個基本分類器。這樣一來,那麼被分錯的數據,在下一輪就會得到更大的關注,所以,分類問題被一系列的弱分類器「分而治之」。同時,對弱分類器的組合,AdaBoost採用加權多數表決的方法,即加大分類器誤差率小的弱分類器的權值,使其在表決中其較大作用,減小分類誤差率大的弱分類器的權值,使其在表決中起較小的作用。AdaBoost的過程中的兩個關鍵點是要把握兩個權重的更新方法,一個是迭代時數據的權重更新,一個是迭代時分類器的權重更新【即下圖中的模型係數】
算法步驟如下(下圖來自李航的《統計學習方法》一書):


鑒於如果要寫AdaBoost的例題講解會佔用很長的篇幅,而網上的資料及書籍很多,我就貼在下面了,如果想要真正理解AdaBoost算法訓練過程,請看以下李航老師的《統計學習方法》中的案例或者下列網站:
如果你看完了其中一篇博客,我相信你已經能夠理解AdaBoost算法了。那麼對於下面這張圖中的分類器學習算法
4. AdaBoost級聯分類器
4.1 弱分類器結構
Haar特徵和弱分類器的關係很簡單,一個完成的弱分類器包括:
- 若干個Haar特徵 + 和Haar特徵數量相等的弱分類器閾值
- 若干個LeftValue
- 若干個RightValue
這些元素共同構成了弱分類器,卻一不可。比如Haarcascade_frontalface_alt2.xml的弱分類器Depth=2,包含了2種形式,我們以下圖為例:其包含2個Haar特徵、1個LeftValue、2個RightValue和2個弱分類器閾(t1和t2)
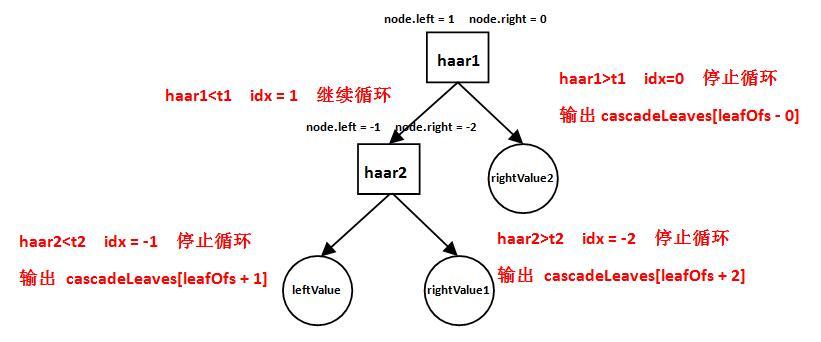
由圖可知,它的工作方式如下:
- 計算第一個Haar特徵的特徵值haar1,與第一個弱分類器閾值t1對比,當haar1<t1時,進入步驟2;當haar1>t1時,該弱分類器輸出rightValue2並結束。
- 計算第二個Haar特徵值haar2,與第二個弱分類器閾值t2對比,當haar2<t2時輸出leftValue;當haar2>t2時輸出rightValue1。
即弱分類器的工作方式:通過計算出的Haar特徵值與弱分類器閾值對比,從而選擇最終輸出leftValue和rightValue值中的哪一個。
4.2 強分類器結構
在OpenCV中,強分類器是由多個弱分類器「並列」而成,即強分類器中的弱分類器是兩兩互相獨立的。在檢測目標時,每個弱分類器獨立運行並輸出cascadeLeaves[leafOfs – idx]值,然後把當前強分類器中每一個弱分類器的輸出值相加,即:
\]
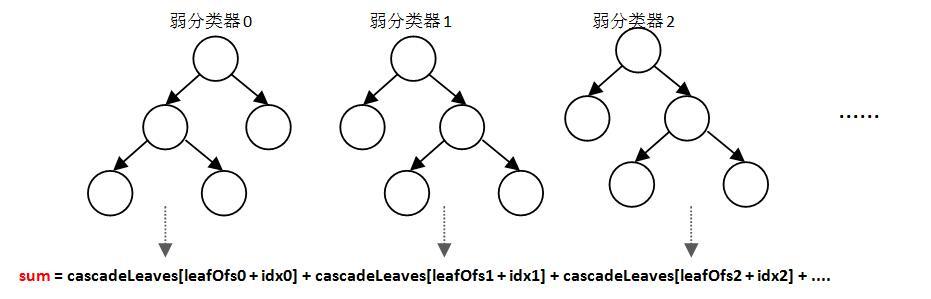
注意:leafOfs表示當前弱分類器中leftValue和rightValue在該數組中存儲位置的偏移量,idx表示在偏移量leafOfs基礎上的leftValue和rightValue值的索引,cascadeLeaves[leafOfs – idx]就是該弱分類器的輸出.
之後與本級強分類器的stageThreshold閾值對比,當且僅當結果sum>stageThreshold時,認為當前檢測窗口通過了該級強分類器。當前檢測窗口通過所有強分類器時,才被認為是一個檢測目標。可以看出,強分類器與弱分類器結構不同,是一種類似於「並聯」的結構,我稱其為「並聯組成的強分類器」。
-
縮小圖像就是把圖像按照一定比例逐步縮小然後滑動窗口檢測,如下圖所示;
-
放大檢測窗口是把檢測窗口長寬按照一定比例逐步放大,這時位於檢測窗口內的Haar特徵也會對應放大,然後檢測。

4.3 如何搜索目標
當檢測窗口大小固定時,為了找到圖像中不同位置的目標,需要逐次移動檢測窗口(窗口中的Haar特徵相應也隨之移動),這樣就可以遍歷到圖像的每一個位置;而為了檢測到不同大小的目標,一般有兩個做法:逐步縮小圖像 or 逐步放大檢測窗口。
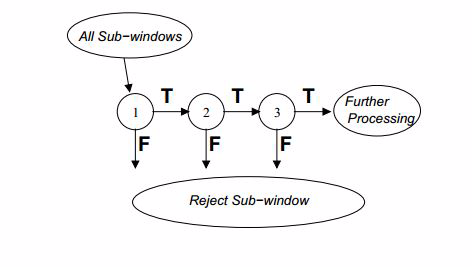
4.4 級聯分類器
級聯分類模型是樹狀結構可以用下圖表示:
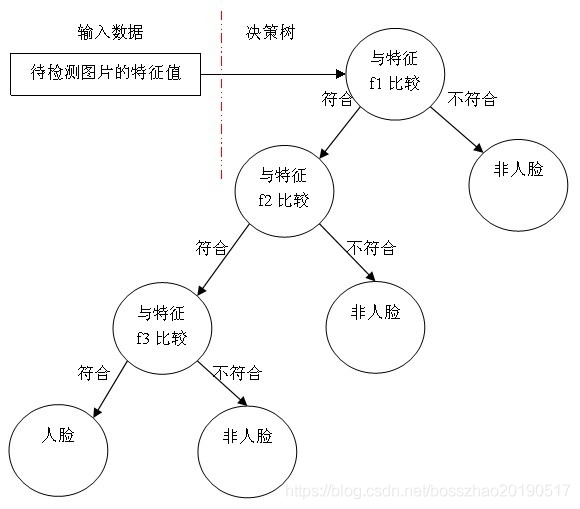
其中每一個stage都代表一級強分類器。當檢測窗口通過所有的強分類器時才被認為是正樣本,否則拒絕。實際上,不僅強分類器是樹狀結構,強分類器中的每一個弱分類器也是樹狀結構。由於每一個強分類器對負樣本的判別準確度非常高,所以一旦發現檢測到的目標位負樣本,就不在繼續調用下面的強分類器,減少了很多的檢測時間。因為一幅圖像中待檢測的區域很多都是負樣本,這樣由級聯分類器在分類器的初期就拋棄了很多負樣本的複雜檢測,所以級聯分類器的速度是非常快的;只有正樣本才會送到下一個強分類器進行再次檢驗,這樣就保證了最後輸出的正樣本的偽正(false positive)的可能性非常低。
4.5 級聯分類器的訓練
4.5.1 弱分類器的訓練步驟
級聯分類器是如何訓練的呢?首先需要訓練出每一個弱分類器,然後把每個弱分類器按照一定的組合策略,得到一個強分類器,我們訓練出多個強分類器,然後按照級聯的方式把它們組合在一塊,就會得到我們最終想要的Haar分類器。
一個弱分類器就是一個基本和上圖類似的決策樹,最基本的弱分類器只包含一個Haar-like特徵,也就是它的決策樹只有一層,被稱為樹樁(stump)。
以24×24的圖像為例,如果直接用27600個特徵使用AdaBoost訓練,工作量是巨大的。所以必須有個篩選的過程,篩選出T個優秀的特徵值(即最優弱分類器),然後把這個T個最優弱分類器傳給AdaBoost進行訓練。
現在有人臉樣本2000張,非人臉樣本4000張,這些樣本都經過了歸一化,大小都是20×20的圖像。那麼,對於78,460中的任一特徵\(f_i\),我們計算該特徵在這2000人臉樣本、4000非人臉樣本上的值,將這些特徵值排序,然後選取一個最佳的特徵值,在該特徵值下,對於特徵\(f_i\)來說,樣本的加權錯誤率最低。
在確定了訓練子窗口中(20×20的圖像)的矩形特徵數量(78,460)和特徵值後,需要對每一個特徵\(f\),訓練一個弱分類器\(h(x,f,ρ,Θ)\) :
h(x,f,ρ,Θ) =\left\{
\begin{aligned}
1,ρf(x)<ρΘ \\
0,other \\
\end{aligned}
\right.
\]
其中f為特徵,\(\theta\)為閾值,p指示不等號的方向,x代表一個檢測的子窗口。對每個特徵f,訓練一個弱分類器\(h(x,f,ρ,Θ)\),就是確定f的最優閾值\(\theta\),使得這個弱分類器對所有訓練樣本分類誤差最低。
弱分類器訓練的具體步驟:
1、對於每個特徵 𝑓,計算所有訓練樣本的特徵值,並將其排序:
2、掃描一遍排好序的特徵值,對排好序的表中的每個元素,計算下面四個值:
-
計算全部正例的權重和𝑇+;
-
計算全部負例的權重和𝑇−;
-
計算該元素前之前的正例的權重和𝑆+;
-
計算該元素前之前的負例的權重和𝑆−;
-
選取當前元素的特徵值\(F_{k,j}\)和它前面的一個特徵值\(F_{k,j-1}\)之間的數作為閾值,所得到的弱分類器就在當前元素處把樣本分開 —— 也就是說這個閾值對應的弱分類器將當前元素前的所有元素分為人臉(或非人臉),而把當前元素後(含)的所有元素分為非人臉(或人臉)。該閾值的分類誤差為:
\[e = min(S^+ + (T^- – S^-),S^- + (T^+ – S^+))
\]
於是,通過把這個排序表從頭到尾掃描一遍就可以為弱分類器選擇使分類誤差最小的閾值(最優閾值),也就是選取了一個最佳弱分類器。
由於一共有78,460個特徵、因此會得到78,460個最優弱分類器,在78,460個特徵中,我們選取錯誤率最低的特徵,用來判斷人臉,同時用此分類器對樣本進行分類,並更新樣本的權重
4.5.2 強分類器的訓練步驟
-
給定訓練樣本集\(x_i,y_i\),i=1,2,4,5…N,共N個樣本,\(y_i\)取值為0(負樣本)或者1(正樣本);設正樣本的數量為\(n_1\),負樣本的數量為\(n_2\);T為訓練的最大循環次數;
-
初始化樣本權重為\(\frac{1}{n_1+n_2}\),即為訓練樣本的初始概率分佈
-
for t = 1,…T:
-
權重歸一化:
\[w_{t,i} = \frac{w_{t,i}}{\sum_{j-1}^{n}w_{t,j}}
\] -
對每一個特徵j,訓練一個分類器\(h_j\);每個分類器只使用一種Haar特徵進行訓練,分類誤差為:
\[ε_j = \sum_i{w_j|h_j(x_i) – y_i|}
\] -
從上一個步驟確定的分類器中,找出一個具有最小分類誤差的弱分類器\(h_t\)。
-
更新每個樣本對應的權重
\[w_{t+1,i} = w_t,i\beta_t^{1-e_i}
\]如果樣本\(x_i\)被正確分類,則\(e_i=0\),否則\(e_i=1\),而
\[\beta_t = \frac{ε_t}{1-ε_t}
\]
-
-
最終形成的強分類器為:
\[h(x)=\left\{
\begin{aligned}
1,\sum_{t=1}^Tα_th_t(x) \geq \frac{1}{2}\sum_{t=1}^Tα_t \\
0,otherwise\end{aligned}
\right.
\]其中,\(α_t = log\frac{1}{\beta_t}\)
在使用Adaboost算法訓練分類器之前,需要準備好正、負樣本,根據樣本特點選擇和構造特徵集。由算法的訓練過程可知,當弱分類器對樣本分類正確,樣本的權重會減小;而分類錯誤時,樣本的權重會增加。這樣,後面的分類器會加強對錯分樣本的訓練。最後,組合所有的弱分類器形成強分類器,通過比較這些弱分類器投票的加權和與平均投票結果來檢測圖像。
4.5.3 強分類器級聯及訓練
為了提高人臉檢測的速度和精度,最終的分類器還需要通過幾個強分類器級聯得到。在一個級聯分類系統中,對於每一個輸入圖片,順序通過每個強分類器,前面的強分類器相對簡單,其包含的弱分類器也相對較少,後面的強分類器逐級複雜,只有通過前面的強分類檢測後的圖片才能送入後面的強分類器檢測,比較靠前的幾級分類器可以過濾掉大部分的不合格圖片,只有通過了所有強分類器檢測的圖片區域才是有效人臉區域。
這也對應了前文提到的該論文所提到的第三個重要貢獻,第三個成果是在一個在級聯結構中連續結合更複雜的分類器的方法,通過將注意力集中到圖像中有希望的地區,來大大提高了探測器的速度。在集中注意力的方法背後的概念是,它往往能夠迅速確定在圖像中的一個對象可能會出現在哪裡。更複雜的處理僅僅是為這些有希望的地區所保留。
訓練過程如下:

根據論文來看,AdaBoost訓練出來的強分類器一般具有較小的誤識率,但是檢測率不高。正確率就是TPR,誤檢率是FDR。
FalsePositiveRate = \frac{FP}{FP+TN},代表將真實負樣本劃分為正樣本的概率
\]
較小的誤識率的意思就是給我一個人臉特徵,我把它判別為人臉特徵的概率很高。檢測率不是很高的意思就是給我一個不是人臉的特徵,我將它劃分為人臉特徵的概率很高。
一般情況下,高檢測率會導致高誤識率,這是強分類閾值的劃分導致的,要提高強分類器的檢測率就要降低閾值,要降低強分類器的誤識率就要提高閾值,這是個矛盾的事情。據參考論文的實驗結果,增加分類器個數可以在提高強分類器檢測率的同時降低誤識率,所以級聯分類器在訓練時要考慮如下平衡,一是弱分類器的個數和計算時間的平衡,二是強分類器檢測率和誤識率之間的平衡。
另外在檢測的過程中,因為TPR較高,所以一旦檢測到某區域不是目標就可以直接停止後續檢測。由於在人臉檢測應用中非人臉區域佔大部分,這樣大部分檢測窗口都能夠很快停止,是分類速度得到很大的提高。
從上面所述內容我們可以總結Haar分類器訓練的步驟:
- 尋找TP和FP作為訓練樣本
- 計算每個Haar特徵在當前權重下的Best split threshold+leftvalue+rightvalue,組成了一個個弱分類器
- 通過WSE尋找最優的弱分類器
- 更新權重
- 按照minHitRate估計stageThreshold
- 重複上述1-5步驟,直到falseAlarmRate到達要求,或弱分類器數量足夠。停止循環,輸出stage。
- 進入下一個stage訓練
5. 總結
寫了好多了,這篇博客其實對《Rapid Objection Dection using a Boosted Cascade of Simple Features》的一個學習筆記,但是由於這篇論文在很多地方都交代的不是很清晰,而這個算法的原理又相當複雜,所以在學習的過程中我還額外看了一些與這篇論文相關的paper,以及借鑒了國內國外相關資料。關於這個算法,我覺得這篇論文中還有一些很細節的地方沒有講清楚,而我覺得這些細節也是能否成功復現這篇論文的關鍵點。比如如何有必要的對重疊的檢測結果窗口進行合併,同時剔除零散分佈的錯誤檢測窗口,該功能就是NMS(Non-maximum suppresion),解決這種情況所用到的並查集(Union-Set)算法,是一種數據結構,我目前還在學習思考這一塊兒的內容。再者,雖然我知道了AdaBoost、級聯分類器的整體訓練過程,但是具體到復現那個層次來描述整個算法的訓練過程,我我還需要繼續的去學習源代碼。
學習完這篇算法的細節後,我進一步明白了,真的不要當一個調參俠。這個算法的python實現就那麼幾行,參數是那些個,實現起來可能很簡單也很帥。但是這個算法的源代碼的複雜程度、原理的精妙性,才是我們應該去重點關心的。尤其是搞人工智能這個領域的。
~:如果您發現文章中有出錯的地方,歡迎您指正。同時也歡迎您在留言區討論問題,共同學習。私信可E-mail:[email protected].
6. 參考文獻
[2] OpenCV AdaBoost + Haar目標檢測技術內幕(上)
[3] OpenCV AdaBoost + Haar目標檢測技術內幕(下)
[4] Python+OpenCV圖像處理(九)——Haar特徵描述算子
[5] Face Detection with Haar Cascade
[6] Face Detection with Haar Cascade — Part II
[7] Rapid Object Detection using a Boosted Cascade of Simple Features中英版

