坐實大數據資源調度框架之王,Yarn為何這麼牛
摘要:Yarn的出現伴隨着Hadoop的發展,使Hadoop從一個單一的大數據計算引擎,成為大數據的代名詞。
本文分享自華為雲社區《Yarn為何能坐實資源調度框架之王?》,作者: JavaEdge。
Hadoop主要組成:
- 分佈式文件系統HDFS
- 分佈式計算框架MapReduce
- 分佈式集群資源調度框架Yarn
Yarn的出現伴隨着Hadoop的發展,使Hadoop從一個單一的大數據計算引擎,成為一個集存儲、計算、資源管理為一體的完整大數據平台,進而發展出自己的生態體系,成為大數據的代名詞。
在MapReduce應用程序的啟動過程中,最重要的就是把MapReduce程序分發到大數據集群的服務器,Hadoop 1中,這個過程主要是通過TaskTracker和JobTracker通信完成。
方案的缺點
服務器集群資源調度管理和MapReduce執行過程耦合在一起,如果想在當前集群中運行其他計算任務,比如Spark或者Storm,就無法統一使用集群中的資源。
Hadoop早期,大數據技術就只有Hadoop,這缺點不明顯。但隨大數據發展,各種新計算框架出現,我們不可能為每種計算框架部署一個服務器集群,而且就算能部署新集群,數據還是在原來集群的HDFS上。所以需要把MapReduce的資源管理和計算框架分開,這也是Hadoop2最主要變化:將Yarn從MapReduce中分離出來,成為一個獨立的資源調度框架。
Yarn,Yet Another Resource Negotiator,另一種資源調度器。在Hadoop社區決定將資源管理從Hadoop1中分離出來,獨立開發Yarn時,業界已有一些大數據資源管理產品,比如Mesos,所以Yarn開發者索性管自己的產品叫「另一種資源調度器」。比如Java的Ant就是「Another Neat Tool」縮寫,另一種整理工具。
Yarn架構
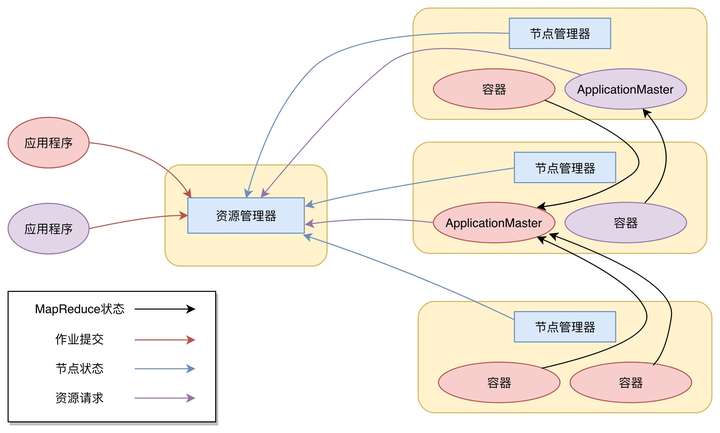
Yarn包括:
節點管理器(Node Manager)
NodeManager進程,負責具體服務器上的資源和任務管理,在集群的每一台計算服務器上都會啟動,和HDFS的DataNode進程一起出現
資源管理器(Resource Manager)
ResourceManager進程,負責整個集群的資源調度管理,通常部署在獨立的服務器
資源管理器包括兩個主要組件:
調度器
就是個資源分配算法,根據Client應用程序提交的資源申請和當前服務器集群的資源狀況進行資源分配。
Yarn內置的資源調度算法
包括Fair Scheduler、Capacity Scheduler等,也可以自行開發供Yarn調用。
Yarn進行資源分配的單位是容器(Container),每個容器包含了一定量的內存、CPU等計算資源,默認配置下,每個容器包含一個CPU核心。容器由NodeManager進程啟動和管理,NodeManger進程會監控本節點上容器的運行狀況並向ResourceManger進程彙報。
應用程序管理器
應用程序管理器負責應用程序的提交、監控應用程序運行狀態等。應用程序啟動後需要在集群中運行一個ApplicationMaster,ApplicationMaster也需要運行在容器裏面。每個應用程序啟動後都會先啟動自己的ApplicationMaster,由ApplicationMaster根據應用程序的資源需求進一步向ResourceManager進程申請容器資源,得到容器以後就會分發自己的應用程序代碼到容器上啟動,進而開始分佈式計算。
Yarn的工作流程
1、向Yarn提交應用程序,包括
- MapReduce ApplicationMaster
- 我們的MapReduce程序
- MapReduce Application啟動命令
2、ResourceManager進程和NodeManager進程通信,根據集群資源,為用戶程序分配第一個容器,並將MapReduce ApplicationMaster分發到這個容器,並在容器里啟動MapReduce ApplicationMaster
3、MapReduce ApplicationMaster啟動後立即向ResourceManager進程註冊,並為自己的應用程序申請容器資源。
4、MapReduce ApplicationMaster申請到需要的容器後,立即和相應的NodeManager進程通信,將用戶MapReduce程序分發到NodeManager進程所在服務器,並在容器中運行,運行的就是Map或者Reduce任務。
5、Map或者Reduce任務在運行期和MapReduce ApplicationMaster通信,彙報自己的運行狀態,若運行結束,MapReduce ApplicationMaster向ResourceManager進程註銷並釋放所有的容器資源。
MapReduce若想在Yarn運行,需開發遵循Yarn規範的MapReduce ApplicationMaster,其他大數據計算框架也能開發遵循Yarn規範的ApplicationMaster,這樣在一個Yarn集群中就能同時並發執行不同的大數據計算框架,實現資源的統一調度管理。
為何HDFS是系統,而MapReduce和Yarn是框架
框架遵循依賴倒轉原則:高層模塊不能依賴低層模塊,它們應共同依賴一個抽象,這個抽象由高層模塊定義,由低層模塊實現。
高、低層模塊的劃分:調用鏈上,前面的是高層,後面的是低層。以Web應用為例,用戶請求到Server後:
- 最先處理用戶請求的是Web容器Tomcat,通過監聽80端口,把HTTP二進制流封裝成Request對象
- 然後Spring MVC框架,提取Request對象里的用戶參數,根據請求的URL分發給相應的Model對象處理
- 最後應用程序代碼處理用戶請求
Tomcat相比Spring MVC就是高層模塊,Spring MVC相比應用程序也是高層模塊。雖然Tomcat會調用Spring MVC,因為Tomcat要把Request交給Spring MVC處理,但Tomcat並未依賴Spring MVC,那Tomcat如何做到不依賴Spring MVC,卻能調用Spring MVC?
Tomcat和Spring MVC都依賴J2EE規範,Spring MVC實現了J2EE規範的HttpServlet抽象類,即DispatcherServlet,並配置在web.xml中。這樣,Tomcat就能調用DispatcherServlet處理用戶發來的請求。
同樣Spring MVC也不需要依賴我們寫的Java代碼,而是通過依賴Spring MVC的配置文件或Annotation抽象,來調用我們的Java代碼。所以,Tomcat或者Spring MVC都可以稱作是框架,它們都遵循依賴倒轉原則。
類似的,實現MapReduce編程接口、遵循MapReduce編程規範就能被MapReduce框架調用,在分佈式集群中計算大規模數據;實現了Yarn的接口規範,比如Hadoop2的MapReduce,就能被Yarn調度管理,統一安排服務器資源。所以MapReduce和Yarn都是框架。
HDFS就不是框架,使用HDFS就是直接調用HDFS提供的API接口,HDFS作為底層模塊被直接依賴。
總結
Yarn,大數據資源調度框架,調度的是大數據計算引擎本身,不像MapReduce或Spark編程,每個大數據應用開發者都需根據需求開發自己的MapReduce程序或者Spark程序。
大數據計算引擎所使用的Yarn模塊,也早被這些計算引擎開發者做出來供使用。普通大數據開發者沒有機會編寫Yarn相關程序。


